
The Components of Collaborative Joint Perception and Prediction:
A Conceptual Framework
Lei Wan
1,2 a
, Hannan Ejaz Keen
1 b
and Alexey Vinel
2 c
1
XITASO GmbH, Augsburg, Germany
2
Karlsruhe Institut of Technology, Karlsruhe, Germany
Keywords:
Autonomous Driving, Connected Autonomous Vehicles, Cooperative-Intelligent Transportation Systems,
Collaborative Perception, Collaborative Joint Perception and Prediction.
Abstract:
Connected Autonomous Vehicles (CAVs) benefit from Vehicle-to-Everything (V2X) communication, which
enables the exchange of sensor data to achieve Collaborative Perception (CP). To reduce cumulative errors in
perception modules and mitigate the visual occlusion, this paper introduces a new task, Collaborative Joint
Perception and Prediction (Co-P&P), and provides a conceptual framework for its implementation to improve
motion prediction of surrounding objects, thereby enhancing vehicle awareness in complex traffic scenarios.
The framework consists of two decoupled core modules, Collaborative Scene Completion (CSC) and Joint
Perception and Prediction (P&P) module, which simplify practical deployment and enhance scalability. Ad-
ditionally, we outline the challenges in Co-P&P and discuss future directions for this research area.
1 INTRODUCTION
Autonomous Driving (AD) technology is essential
for advancing intelligent transportation systems, con-
tributing to improved road safety, enhanced traffic
efficiency, energy conservation, and reduced carbon
emissions. A key component of the AD framework
is perception, which involves detecting dynamic ob-
jects and interpreting the static environment. The per-
ception module encompasses various tasks, including
object detection, tracking, motion prediction, and se-
mantic segmentation. Traditionally, these tasks are
implemented in a modular format, forming the basis
for downstream functions like planning and control
(Keen and Berns, 2023; Keen and Berns, 2020). Ad-
vancements in artificial intelligence and sensor fusion
have significantly improved vehicle perception capa-
bilities. However, single-vehicle perception still faces
challenges, particularly with visual occlusion, which
can pose safety risks and lead to accidents. Vehicle-
to-Everything (V2X) technology offers a promising
approach to address these limitations by enabling the
sharing data with other vehicles or infrastructure, ef-
fectively enhancing perception and mitigating occlu-
a
https://orcid.org/0009-0007-4470-9088
b
https://orcid.org/0009-0001-6217-9427
c
https://orcid.org/0000-0003-4894-4134
sion issues.
With V2X communication, Connected Au-
tonomous Vehicles (CAVs) can achieve Collabora-
tive Perception (CP) by integrating data from mul-
tiple sources. Initial research on CP began within
the communication field, focusing on standardizing
V2X message types and optimizing communication
efficiency. Recently, CP research has expanded into
computer vision and robotics, where the emphasis
is shifting from sharing standardized messages, such
as Cooperative Perception Message (CPM) contain-
ing detected objects, to share raw sensor data or neu-
ral features. For example, Chen et al. (Chen et al.,
2019) propose a feature-based CP approach that trans-
mits and combines LiDAR features across vehicles,
enhancing perception performance within bandwidth
constraints. Similarly, Hu et al. (Hu et al., 2023)
present a camera-based CP method that integrates vi-
sual Bird’s Eye View (BEV) features from multiple
agents, providing a more comprehensive view of dy-
namic objects.
The use of collaborative methodologies extend be-
yond object detection to enhance other perception
tasks. For instance, Liu et al. (Liu et al., 2023) in-
troduce a collaborative semantic segmentation frame-
work utilizing intermediate collaboration, achieving
superior results compared to single-vehicle methods.
In motion prediction, Wang et al. (Wang et al., 2020)
458
Wan, L., Keen, H. E. and Vinel, A.
The Components of Collaborative Joint Perception and Prediction: A Conceptual Framework.
DOI: 10.5220/0013285300003941
In Proceedings of the 11th International Conference on Vehicle Technology and Intelligent Transport Systems (VEHITS 2025), pages 458-465
ISBN: 978-989-758-745-0; ISSN: 2184-495X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
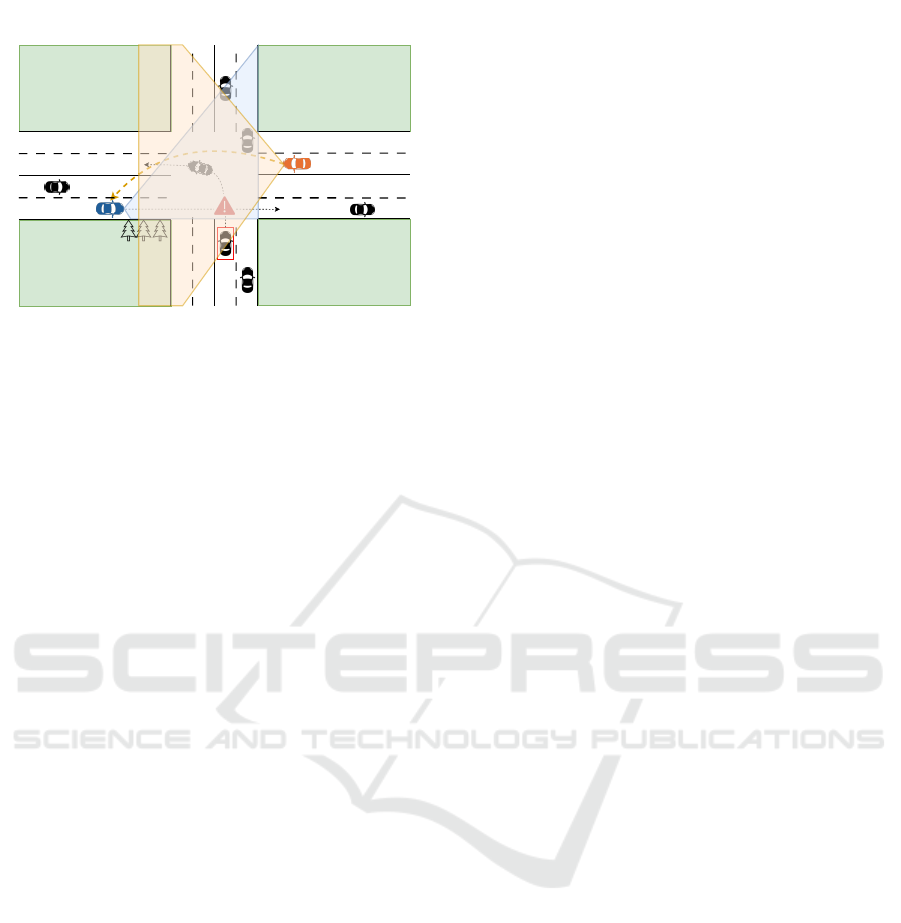
Ego
CAV
Figure 1: Schematic diagram of Collaborative Perception.
The diagram illustrates a scenario at an intersection where
two CAVs collaborate to enhance perception. The ego vehi-
cle (blue) has a limited field of view due to occlusions, such
as trees and buildings, which block its line of sight to a vehi-
cle turning left. A collaborating vehicle (orange) positioned
across the intersection shares its sensor data, expanding the
ego vehicle’s awareness. The shaded areas represent the
Field of View (FOV) for each vehicle.
demonstrate how collaboration enhances the preci-
sion of predicted trajectories.Additionally some per-
ception tasks are handled within multi-task pipelines,
such as the V2XFormer model by Wang et al. (Wang
et al., 2024), which simultaneously outputs detec-
tion, motion prediction, and semantic segmentation
results.While multi-task approaches benefit from re-
source savings by sharing a common backbone, they
often overlook temporal information across sensor
frames, which is essential for tracking and motion
prediction.
An emerging trend is the development of differ-
entiable frameworks that seamlessly integrate various
perception tasks within a unified model, enabling end-
to-end training. For example, Liang et al. (Liang
et al., 2020) propose an end-to-end Joint Percep-
tion and Prediction (P&P) framework for single vehi-
cles equipped with LiDAR. Similarly, Gu (Gu et al.,
2023) introduces a camera-only end-to-end pipeline
for P&P, utilizing visual features to achieve both
detection and motion prediction. These approaches
highlight the potential of end-to-end learning to ad-
dress bottlenecks in traditional perception pipelines,
where cumulative errors across stages can degrade
performance. With end-to-end learning, cumulative
noise is mitigated, and motion prediction benefits sig-
nificantly from the integration of fine-grained con-
textual information. Nonetheless, current research in
P&P still encounters challenges, particularly with vi-
sual occlusion, which significantly impacts prediction
accuracy for obscured targets.
To overcome this issue, we propose the Collabora-
tive Joint Perception and Prediction (Co-P&P) frame-
work, which incorporates V2X collaboration. Our
framework is based on the premise that CP comple-
ments ego-vehicle perception, making it adaptable to
scenarios with or without V2X support. Additionally,
to simplify deployment and enhance scalability, our
framework decouples the training of the collabora-
tion module from perception tasks. Inspired by recent
work (Li et al., 2022; Wang et al., 2023a), our ap-
proach uses collaborative scene completion to address
visual occlusion. Consequently, the Co-P&P frame-
work comprises two core modules: the Collaborative
Scene Completion (CSC) module and the Joint Per-
ception and Prediction (P&P) module.
In addition to developing CP approaches, estab-
lishing effective evaluation methodologies is crucial
for advancing CP research. Current studies largely
adopt evaluation methods designed for single-vehicle
perception. Notably, only one study (Wang et al.,
2023b) has introduced an evaluation focused on in-
visible objects, highlighting CP’s potential to address
visual occlusion. New evaluation methods are also
required to assess the performance of Co-P&P.
The main contributions of this paper are as fol-
lows:
• We introduce a conceptual framework for Co-
P&P, designed to address cumulative errors inher-
ent in modular designs and mitigate visual occlu-
sion challenges.
• We present a re-formulation of evaluation meth-
ods in CP and propose an evaluation approach tai-
lored for Co-P&P that aligns with the motivation
of V2X collaboration.
• We outline the challenges surrounding Co-P&P,
and suggest future work to further enhance this
framework.
The structure of the paper is as follows: Section 2
details the system design, while Section 3 introduces
the evaluation method for Co-P&P. Sections 4 dis-
cusses real-world challenges regarding practical de-
ployment. Finally, Section 5 concludes with a sum-
mary and outlook.
2 DETAILS OF THE SYSTEM
Figure 2 presents the conceptual framework, encom-
passing sensors, localization, High Definition Map
(HD Map), communication, P&P, collaborative scene
completion. This section provides an overview of
each core component of the framework along with
their corresponding approaches.
The Components of Collaborative Joint Perception and Prediction: A Conceptual Framework
459
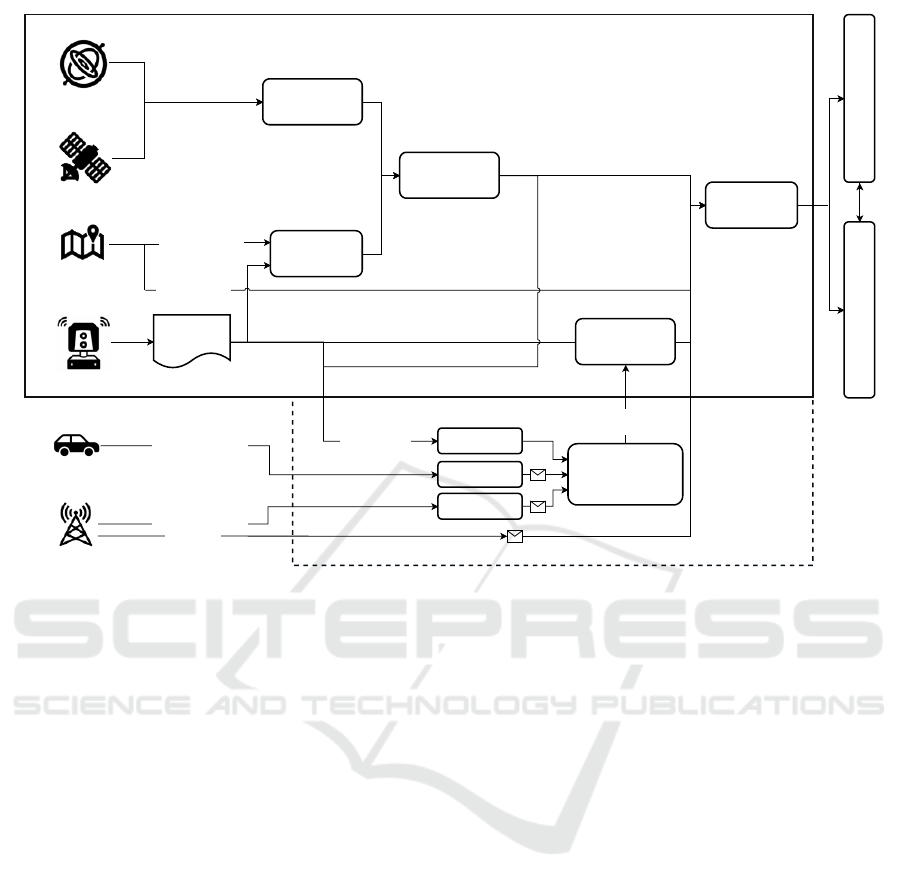
Point Clouds Map
Inertial navigation
system (INS)
GNSS/GPS
LiDAR
HD Map
Roadside unit
(RSU)
Point clouds
preprocess
Map-based
Localization
GPS/GNSS-INS
based
Localization
Localization
Fusion
Joint
Perception and
Prediction
Vectorized Map
Risk Assessment
Planning & Control
Completed
LiDAR frame
Collaborative
Scene Completion
Decoder
Collaborative
Vehicle
Collaboration
Trigger
Traffic Light
Localization and
Perception
V2X
Collaboration
CSC Encoder
CSC Encoder
CSC Encoder
Point clouds &
Pose
Point clouds & Pose
Point clouds & Pose
Figure 2: Schematic diagram of Collaborative Joint Perception and Prediction.The system combines GPS/GNSS-INS and
map-based localization for precise positioning. Sensing data (point clouds, poses) from collaborative vehicle and roadside unit
are processed and shared with the ego vehicle, enabling Collaborative Scene Completion (CSC) to provide a comprehensive
LiDAR frame. To optimize bandwidth usage, intermediate features are shared for scene completion instead of raw point
clouds are shared via V2X. The collaboration trigger manages CSC activation. The P&P module integrates localization, map,
and LiDAR data to jointly enhance perception and prediction, which feeds into the risk assessment and planning and control
modules for real-time decision-making.
2.1 Sensors
To capture a 3D view of the environment, various sen-
sor types can be employed, including LiDAR, radar,
and different types of cameras such as RGB and in-
frared camera. In our conceptual framework, LiDAR
serves as the primary sensor due to its high preci-
sion in 3D measurements, significantly enhancing the
3D perception capabilities of Autonomous Vehicles
(AVs).
LiDAR sensors vary in their scanning patterns,
typically classified into spinning and oscillating types
(Triess et al., 2021). Spinning LiDAR uses a regu-
lar scanning pattern that provides an even distribu-
tion of points across a 360
◦
FOV. In contrast, oscil-
lating LiDAR follows a snake-like pattern, creating
a denser yet uneven point distribution within a con-
strained FOV. Each type offers distinct characteristics
that can lead to a domain gap in perception models
due to differences in data representation. Addressing
this domain gap across different LiDAR sensor is es-
sential for CP systems.
2.2 Localization
Beyond environmental perception, precise self-
localization is essential for CP. Accurate localization
allows for data fusion across dynamic agents by es-
tablishing a consistent coordinate system to align all
sensory data. Thus, the effectiveness of CP depends
significantly on the localization accuracy of CAVs.
Traditionally, vehicles rely on Global Navigation
Satellite System (GNSS) or Global Positioning Sys-
tem (GPS) to determine their position using trilat-
eration. However, GNSS-based methods face chal-
lenges like Non-Line-of-Sight and multipath prop-
agation, often resulting in errors exceeding 3 me-
ters, which undermines reliability and safety in AD
(Ochieng and Sauer, 2002). HD Map can mitigate lo-
calization errors, achieving centimeter-level accuracy
(Chalvatzaras et al., 2022). These maps are created
through extensive data collection runs, often using Li-
DAR to construct a detailed point cloud layer. For
precise vehicle positioning on HD Map, both GNSS
and LiDAR sensors are used, providing a precise po-
VEHITS 2025 - 11th International Conference on Vehicle Technology and Intelligent Transport Systems
460

sitioning approach.
2.3 HD Map
HD Map serves not only for localization but also of-
fer essential semantic information about the static en-
vironment. They include detailed road data such as
lane boundaries, lane centerlines, road markings, traf-
fic signs, poles, and traffic light locations. This infor-
mation aids vehicles in interpreting traffic rules and
understanding the surrounding environment, enhanc-
ing motion prediction accuracy. Xu et al. (Xu et al.,
2023) highlight the significant impact of map quality
on motion prediction performance, showing that high-
quality, curated HD Map outperform systems relying
on online mapping or operating without maps. In our
framework, the map operates as an independent mod-
ule that interfaces with the perception module. This
design enables compatibility with various mapping
solutions, supporting scalability to online mapping or
even cost-efficient, mapless approaches.
2.4 Communication
V2X communication technology forms a critical
foundation for CP. CAVs and intelligent infrastruc-
ture use sensors to perceive the environment and then
transmit this data through V2X communication. Two
primary technologies support V2X communications:
Dedicated Short-Range Communication (DSRC) and
cellular network technologies (Abboud et al., 2016).
DSRC is a wireless technology designed for au-
tomotive and Cooperative-Intelligent Transportation
Systems (C-ITS) applications, allowing short-range
information exchange between devices. It operates
without additional network infrastructure and offers
low latency, making it suitable for safety-critical ap-
plications (Kenney, 2011). However, DSRC has lim-
itations, including a relatively short communication
range and reduced scalability in scenarios with high
vehicular density (Harding et al., 2014). Cellular net-
works, on the other hand, offer a potential solution
for C-ITS by providing greater bandwidth. These
capabilities ensure that sensor data, crucial for CP,
can be effectively transmitted across distributed en-
tities. Yet, some Cellular Vehicle-to-Everything (C-
V2X) modes depend on cellular infrastructure, mean-
ing performance may degrade in areas far from base
stations, impacting latency.
Given the limitations of using either V2X tech-
nology alone, a hybrid approach that combines both
DSRC and cellular technologies is more promising,
enabling novel DSRC–cellular interworking schemes.
In our framework, data such as traffic light informa-
tion, which requires low bandwidth, is well-suited
for DSRC. Meanwhile, sensor data, with its higher
bandwidth demands, is more effectively handled by
C-V2X.
2.5 Joint Perception and Prediction
The P&P module forms the core of our framework.
This module integrates data from LiDAR, vehicle
pose, HD Map, and traffic light information to gen-
erate detection results and forecast the trajectories of
relevant agents, as depicted in Figure 3. The P&P
pipeline includes a LiDAR encoder, temporal en-
coder, map encoder, multi-agent interaction encoder,
and P&P decoder.
• Lidar Encoder: To enable semantic understand-
ing of the surrounding environment for AVs, the
LiDAR encoder extracts semantic features from
point clouds. For example, VoxelNet (Zhou and
Tuzel, 2018) divides the point cloud into a 3D
voxel grid, aggregates features within each voxel,
and encodes these features. By applying voxel
convolution, it captures 3D spatial features, which
are then flattened along the z-axis and transformed
into BEV features, enhanceing computational ef-
ficiency
• Spatial-Temporal Attention: In addition to spa-
tial features from the LiDAR encoder, temporal
information across multiple frames is crucial for
understanding temporal dynamics of the environ-
ment (Bharilya and Kumar, 2023). In our frame-
work, the temporal encoder captures this tem-
poral context from LiDAR BEV features. For
instance, a cross-attention mechanism (Vaswani
et al., 2017) extracts context between frames, gen-
erating spatial-temporal features.
• Map Encoder: Map and traffic light information
are crucial for motion prediction (Ettinger et al.,
2021). To interact with spatial-temporal features,
the map and traffic light data are encoded as neu-
ral features. For instance, the HD Map is trans-
formed into the ego-vehicle’s coordinate system,
centered on the ego-vehicle, and only map infor-
mation within a defined surrounding area is used.
Traffic light data are integrated into the map as
environmental indicators and encoded as features.
• Multi-Agent Interaction Attention: Modeling
interactions among multiple agents is challenging
(Bharilya and Kumar, 2023). This module com-
bines agent and map features to ensure more pre-
cise modeling of these interactions. This block
first computes interactions between the map and
The Components of Collaborative Joint Perception and Prediction: A Conceptual Framework
461
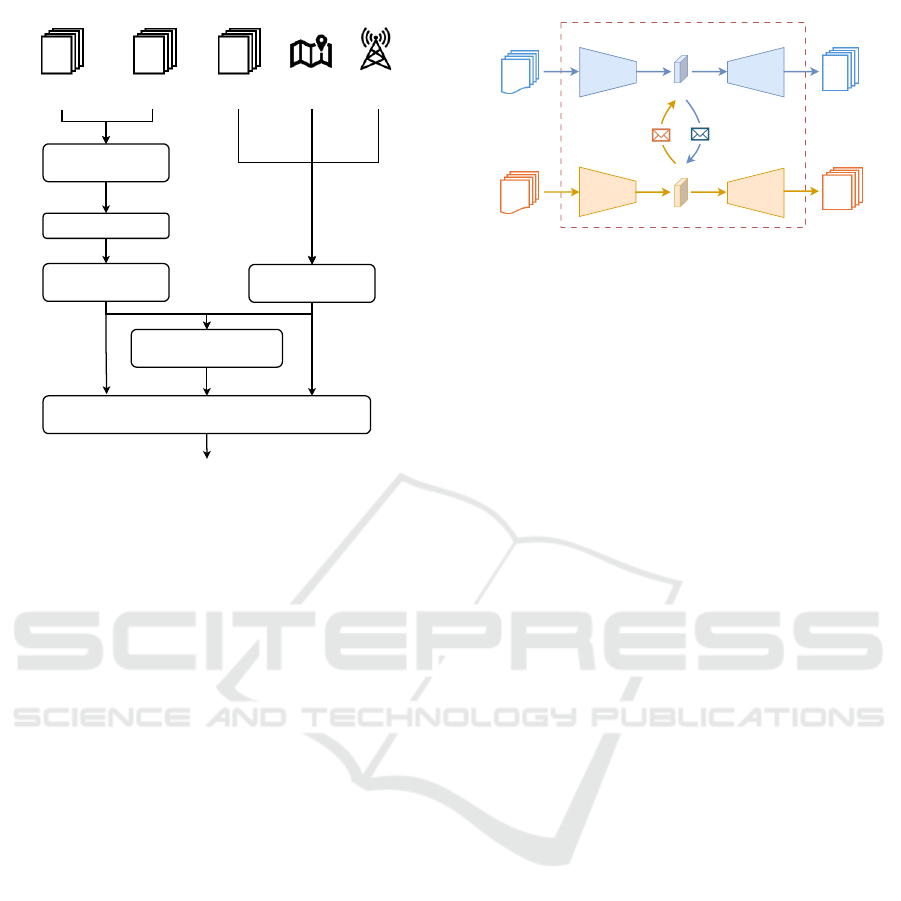
LiDAR Encoder
LiDAR frame
Traffic
Light
Completed
LiDAR frame
HD MapPose frame
Spatial-Temporal
Attention
Map Encoder
Multi-agent
Interaction Attention
P&P Decoder
Collaboration
Trigger
Figure 3: Schematic diagram of P&P.
agent information, then calculates inter-agent in-
teractions within regions of interest (ROIs).
• P&P Decoder: The decoder integrates all rele-
vant features to produce accurate perception and
prediction outputs. Detection results are repre-
sented as a BEV map comprising a map mask
and object masks. Motion prediction is repre-
sented as a BEV flow output, aligning well with
downstream tasks such as planning and decision-
making.
2.6 Collaboration Trigger
While multi-agent collaboration provides significant
benefits for CAVs, it also demands substantial re-
sources. Collaboration is often unnecessary when
the ego vehicle has unobstructed visibility. To bal-
ance system effectiveness and efficiency, a collabo-
ration trigger is needed to activate collaboration only
at optimal times. Designing an effective collabora-
tion trigger and identifying relevant decision factors
remain underexplored areas of research (Huang et al.,
2023). In our framework, we consider scenario occlu-
sion levels, the confidence level of the ego vehicle’s
perception, and communication conditions in devel-
oping this trigger metric. When the metric value ex-
ceeds a specified threshold, the system activates the
collaboration module
Decoder
Encoder Decoder
Encoder
Original
Frame of
LiDAR 1
Original
Frame of
LiDAR 2
Completed
Frame of
LiDAR 2
Completed
Frame of
LiDAR 1
Collaborative Scene Completion
Figure 4: Schematic diagram of Collaborative Scene Com-
pletion (CSC).
2.7 Collaborative Scene Completion
Traditional CP frameworks generally involve the
sharing of neural features generated by deep learning-
based CP modules or the exchange of perception re-
sults among cooperative agents. However, this ap-
proach is task-specific, meaning that the shared data
can only support particular perception tasks, lead-
ing to heterogeneity of systems that limits effec-
tive collaboration between diverse agents (Han et al.,
2023). Additionally, conventional methods often re-
quire joint model training across agents and, in some
cases, re-training the whole-model for each percep-
tion task (Li et al., 2022). This joint training can be
impractical and resource-intensive in real-world ap-
plications.
In our framework, we decouple V2X collaboration
from the P&P pipeline, allowing independent training
of each component. V2X collaboration is managed
through task-agnostic collaborative scene completion,
which benefits all downstream tasks without needing
task-specific data transmission. By reconstructing a
comprehensive scene using latent features and sharing
these features across agents, this approach minimizes
communication demands, as shown in Figure 4. The
completed scene is then fed into the P&P pipeline, as
shown in Figure 3.
3 EVALUATION
In addition to developing the Co-P&P system,it is es-
sential to establish effective evaluation methods to ac-
curately access its performance. However, evaluat-
ing CP presents unique challenges. Most existing re-
search relies on methods adapted from single-vehicle
perception, which fail to reflect CP’s capacity to ad-
dress visual occlusions (Wang et al., 2023b). To over-
come this limitation, new evaluation methods are re-
quired.
VEHITS 2025 - 11th International Conference on Vehicle Technology and Intelligent Transport Systems
462

Table 1: Summary of Metrics for Evaluating Joint Percep-
tion and Prediction.
Metrics Description
minADE
k
the minimum over k predictions of
Average Distance Error: the aver-
age of point-wise L2 distances be-
tween the prediction and ground-
truth forecasts
minFDE
k
the minimum over k predictions of
Final Distance Error: the L2 dis-
tance at the final future time step
MR
k@x
the MissRate: the ratio of forecasts
having minFDE
k
> x = 4m
mAP
f
the Mean Forecasting Average Pre-
cision: adapted from mAP
det
, mAP
f
additionally penalizes trajectories
that have correct first-frame de-
tections but inaccurate forecasts
(minFDE
k
< 4m), but also trajecto-
ries with incorrect first-frame detec-
tions (center distance < 2m)
3.1 Evaluation Method
As CP complements single-vehicle perception, pri-
marily aiming to resolve visual occlusions, evaluation
metrics should reflect precision on objects that are
hidden from an individual vehicle’s view but visible
from a collaborative perspective. For example, Wang
et al. (Wang et al., 2023b) propose the Average Recall
of Collaborative View (ARCV) metric, which mea-
sures recall for agents invisible from a single-vehicle
perspective but detectable through collaboration. Our
evaluation method follows this approach by catego-
rizing objects into three groups: fully visible, par-
tially visible, and fully invisible. We assess the per-
ception performance of algorithms across these cate-
gories, first without collaboration and then with V2X
collaboration, to measure the improvement provided
by CP systems.
Apart from perception metrics, communication
cost is also critical. In our evaluation method, we use
average message size as an effective metric to assess
the communication demands of collaborative percep-
tion methods (Marez et al., 2022).
Evaluating P&P introduces additional challenges,
especially in comparing traditional modular method,
where detection, tracking, and prediction are con-
ducted sequentially, and end-to-end methods, which
directly process sensor data to generate perception
and prediction results in a unified framework. Both
approaches should receive the same detection and
tracking inputs for the forecasting module. For in-
stance, Xu et al. (Xu et al., 2023) introduce a method
to evaluate both traditional and end-to-end forecast-
ing models, using the metrics summarized in Table
1. A primary metric in their approach is Mean Fore-
casting Average Precision (mAP
f
), inspired by detec-
tion AP (Peri et al., 2022). In our work, mAP
f
and
mAP
det
are the principal metrics used to assess detec-
tion and forecasting performance across different ob-
ject groups: fully visible, partially visible, and fully
invisible.
3.2 Evaluation in Simulation
Co-P&P is a complex multi-agent system influenced
by factors such as localization error and communica-
tion constraints. To evaluate the robustness of this ap-
proach, ablation studies on key factors are essential.
Simulation provides a practical solution, as it offers a
fully controlled environment for testing. In our work,
we use simulation to conduct various ablation studies
to assess Co-P&P’s performance under different con-
ditions, including localization error, latency, and the
number of CAVs. This process ensures the scalabil-
ity of our approach across diverse real-world scenar-
ios. Future research will benefit from advanced co-
simulators that support realistic communication and
sensor data for even more comprehensive testing.
3.3 Evaluation with Real-World Dataset
Benchmarking perception algorithms on real-world
datasets is a standard approach for evaluating and
comparing methods, as real-world data offers a higher
degree of realism. For Co-P&P research, DAIR-V2X-
Seq (Yu et al., 2023) is a useful dataset, contain-
ing 7,500 cooperative frames with infrastructure and
vehicle-side images and point clouds. However, P&P
relies heavily on machine learning, which requires
large-scale dataset. The scale of DAIR-V2X-Seq re-
mains limited for training larger ML models. To ad-
vance Co-P&P research, creating a more extensive CP
dataset is crucial, and it is one of our primary goals for
future work.
4 CHALLENGES
While Co-P&P has significant potential to enhance
vehicle awareness in dynamic traffic environments by
reducing accumulated errors and addressing occlu-
sion issues, its real-world implementation faces sev-
eral challenges. This section outlines key challenges
in deploying Co-P&P.
The Components of Collaborative Joint Perception and Prediction: A Conceptual Framework
463

• Localization Errors: Effective sensor data fu-
sion requires aligning all data in a shared coor-
dinate system, which depends on precise vehicle
localization. However, GNSS-based localization
typically varies in accuracy from 1 to 3 meters,
leading to potential misalignments that can signif-
icantly impair data fusion. Addressing these pose
errors is essential for accurate collaborative scene
completion in our framework.
• Asynchronous: Collaborative scene completion
becomes more complex due to asynchronous ob-
servations from multiple agents. To accurately re-
construct a current scene frame, input from other
perspectives is often necessary. However, these
inputs are frequently asynchronous with the ego
vehicle’s observations, causing inconsistencies in
the positions of dynamic objects. Developing
methods to handle asynchronous data effectively
is critical for accurate scene completion.
• Domain Shift: In real-world traffic, vehicles from
various manufacturers may be equipped with dif-
ferent types of LiDAR sensors, such as rotating
and oscillating LiDARs. Variations in scan pat-
terns lead to distinct data representations across
sensors, introducing domain shifts that can disrupt
the perception pipeline (Xiang et al., 2023; Liu
et al., 2024). To prevent performance degradation,
it is crucial to develop methods for completing the
LiDAR scene using each sensor’s unique data rep-
resentation.
• Dependency on Large-Scale Labeled Dataset:
The P&P module employs a unified neural net-
work without hand-crafted processing steps, such
as Non-Maximum Suppression (NMS). This high
degree of neural network reliance increases data
demands during model training. Similar to end-
to-end driving models, end-to-end P&P models
require large datasets. Reducing dependency on
annotated data is essential to streamline P&P de-
ployment, presenting a critical area for further in-
vestigation.
5 CONCLUSION
In this paper, we introduced a conceptual framework
for Co-P&P, which comprises collaborative scene
completion and P&P module. By decoupling V2X
collaboration from perception, the framework enables
separate training and validation of the two modules,
supporting scalable deployment in real-world set-
tings. A significant challenge in collaborative scene
completion is bridging the domain gap between dif-
ferent LiDAR sensors, which we propose to address
using a unified intermediate representation format,
similar to that used in 3D reconstruction. After re-
visiting evaluation methods in CP, we emphasize that
evaluating CP performance on objects at different vis-
ibility level provides valuable insights, particularly
for objects that are fully invisible from ego view but
visible from collaborative perspective. This metric
highlights CP’s potential to address visual occlusion,
which should be considered a primary motivation for
CP. Additionally, we discuss the challenges and open
questions surrounding Co-P&P.
This conceptual framework serves as a high-level
architecture for Co-P&P, with detailed implementa-
tion of each component to follow in future work. In
addition to developing novel modules for collabora-
tive scene completion and P&P, creating a large-scale
dataset is essential to advance this field. We plan to
develop a large-scale dataset supporting a range of CP
tasks, including detection, tracking, and motion pre-
diction.
REFERENCES
Abboud, K., Omar, H. A., and Zhuang, W. (2016). Inter-
working of dsrc and cellular network technologies for
V2X communications: A survey. IEEE Transactions
on Vehicular Technology, 65(12):9457–9470.
Bharilya, V. and Kumar, N. (2023). Machine learning for
autonomous vehicle’s trajectory prediction: A com-
prehensive survey, challenges, and future research di-
rections. Vehicular Communications, 46:100733.
Chalvatzaras, A., Pratikakis, I., and Amanatiadis, A. A.
(2022). A survey on map-based localization tech-
niques for autonomous vehicles. IEEE Transactions
on Intelligent Vehicles, 8(2):1574–1596.
Chen, Q., Ma, X., Tang, S., Guo, J., Yang, Q., and Fu, S.
(2019). F-Cooper: Feature-based cooperative percep-
tion for autonomous vehicle edge computing system
using 3D point clouds. In Proceedings of the 4th
ACM/IEEE Symposium on Edge Computing (SEC),
pages 88–100. ACM.
Ettinger, S., Cheng, S., Caine, B., Liu, C., Zhao, H., Prad-
han, S., Chai, Y., Sapp, B., Qi, C. R., Zhou, Y.,
et al. (2021). Large-scale interactive motion forecast-
ing for autonomous driving: The waymo open mo-
tion dataset. In Proceedings of the IEEE/CVF Interna-
tional Conference on Computer Vision (ICCV), pages
9710–9719. IEEE.
Gu, J., Hu, C., Zhang, T., Chen, X., Wang, Y., Wang, Y., and
Zhao, H. (2023). ViP3D: End-to-end visual trajectory
prediction via 3D agent queries. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 5496–5506. IEEE.
Han, Y., Zhang, H., Li, H., Jin, Y., Lang, C., and Li, Y.
(2023). Collaborative perception in autonomous driv-
VEHITS 2025 - 11th International Conference on Vehicle Technology and Intelligent Transport Systems
464

ing: Methods, datasets, and challenges. IEEE Intelli-
gent Transportation Systems Magazine.
Harding, J., Powell, G., Yoon, R., Fikentscher, J., Doyle,
C., Sade, D., Lukuc, M., Simons, J., and Wang, J.
(2014). Vehicle-to-vehicle communications: Readi-
ness of V2V technology for application. Technical Re-
port DOT HS 812 014, United States National High-
way Traffic Safety Administration.
Hu, Y., Lu, Y., Xu, R., Xie, W., Chen, S., and Wang, Y.
(2023). Collaboration helps camera overtake lidar in
3D detection. In Proceedings of the IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition
(CVPR), pages 9243–9252. IEEE.
Huang, T., Liu, J., Zhou, X., Nguyen, D. C., Azghadi,
M. R., Xia, Y., Han, Q.-L., and Sun, S. (2023).
V2X cooperative perception for autonomous driv-
ing: Recent advances and challenges. arXiv preprint
arXiv:2310.03525.
Keen, H. E. and Berns, K. (2020). Generation of elevation
maps for planning and navigation of vehicles in rough
natural terrain. In Berns, K. and G
¨
orges, D., editors,
Advances in Service and Industrial Robotics, pages
488–495, Cham. Springer International Publishing.
Keen, H. E. and Berns, K. (2023). Probabilistic fusion
of surface and underwater maps in a shallow water
environment. In Petri
ˇ
c, T., Ude, A., and
ˇ
Zlajpah, L.,
editors, Advances in Service and Industrial Robotics,
pages 195–202, Cham. Springer Nature Switzerland.
Kenney, J. B. (2011). Dedicated short-range communica-
tions (DSRC) standards in the united states. Proceed-
ings of the IEEE, 99(7):1162–1182.
Li, Y., Zhang, J., Ma, D., Wang, Y., and Feng, C. (2022).
Multi-robot scene completion: Towards task-agnostic
collaborative perception. In Conference on Robot
Learning (CoRL). PMLR.
Liang, M., Yang, B., Zeng, W., Chen, Y., Hu, R., Casas,
S., and Urtasun, R. (2020). PnPNet: End-to-end per-
ception and prediction with tracking in the loop. In
Proceedings of the IEEE/CVF Conference on Com-
puter Vision and Pattern Recognition (CVPR), pages
11553–11562. IEEE.
Liu, H., Gu, Z., Wang, C., Wang, P., and Vukobratovic, D.
(2023). A lidar semantic segmentation framework for
the cooperative vehicle-infrastructure system. In Pro-
ceedings of the 2023 IEEE 98th Vehicular Technology
Conference (VTC2023-Fall), pages 1–5. IEEE.
Liu, Y., Sun, B., Li, Y., Hu, Y., and Wang, F.-Y. (2024).
HPL-ViT: A unified perception framework for hetero-
geneous parallel lidars in V2V. In Proceedings of the
2024 IEEE International Conference on Robotics and
Automation (ICRA). IEEE.
Marez, D., Nans, L., and Borden, S. (2022). Bandwidth
constrained cooperative object detection in images. In
Artificial Intelligence and Machine Learning in De-
fense Applications IV, volume 12276, pages 128–140.
SPIE.
Ochieng, W. and Sauer, K. (2002). Urban road trans-
port navigation: Performance of the global position-
ing system after selective availability. Transportation
Research Part C: Emerging Technologies, 10(3):171–
187.
Peri, N., Luiten, J., Li, M., Osep, A., Leal-Taix
´
e, L., and
Ramanan, D. (2022). Forecasting from lidar via fu-
ture object detection. In Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recogni-
tion (CVPR), pages 17202–17211. IEEE.
Triess, L. T., Dreissig, M., Rist, C. B., and Z
¨
ollner, J. M.
(2021). A survey on deep domain adaptation for lidar
perception. In 2021 IEEE Intelligent Vehicles Sym-
posium Workshops (IV Workshops), pages 350–357.
IEEE.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, L., and Polosukhin, I.
(2017). Attention is all you need. In Advances in
Neural Information Processing Systems, volume 30.
Wang, B., Zhang, L., Wang, Z., Zhao, Y., and Zhou, T.
(2023a). CoRe: Cooperative reconstruction for multi-
agent perception. In Proceedings of the IEEE/CVF In-
ternational Conference on Computer Vision (ICCV),
pages 8676–8686. IEEE.
Wang, T., Chen, G., Chen, K., Liu, Z., Zhang, B., Knoll, A.,
and Jiang, C. (2023b). UMC: A unified bandwidth-
efficient and multi-resolution based collaborative per-
ception framework. In Proceedings of the IEEE/CVF
International Conference on Computer Vision (ICCV),
pages 8153–8162. IEEE.
Wang, T., Kim, S., Jiang, W., Xie, E., Ge, C., Chen, J., Li,
Z., and Luo, P. (2024). DeepAccident: A motion and
accident prediction benchmark for V2X autonomous
driving. Proceedings of the AAAI Conference on Arti-
ficial Intelligence, 38(6):5599–5606.
Wang, T.-H., Manivasagam, S., Liang, M., Yang, B., Zeng,
W., and Urtasun, R. (2020). V2VNet: Vehicle-to-
vehicle communication for joint perception and pre-
diction. In Vedaldi, A., Bischof, H., Brox, T., and
Frahm, J.-M., editors, Computer Vision – ECCV 2020,
volume 12347, pages 605–621. Springer International
Publishing.
Xiang, L., Yin, J., Li, W., Xu, C.-Z., Yang, R., and Shen,
J. (2023). DI-V2X: Learning domain-invariant rep-
resentation for vehicle-infrastructure collaborative 3D
object detection. In Proceedings of the AAAI Confer-
ence on Artificial Intelligence. AAAI.
Xu, Y., Chambon, L., Zablocki,
´
E., Chen, M., Alahi, A.,
Cord, M., and P
´
erez, P. (2023). Towards motion fore-
casting with real-world perception inputs: Are end-
to-end approaches competitive? In 2024 IEEE In-
ternational Conference on Robotics and Automation
(ICRA), pages 18428–18435. IEEE.
Yu, H., Yang, W., Ruan, H., Yang, Z., Tang, Y., Gao, X.,
Hao, X., Shi, Y., Pan, Y., Sun, N., Song, J., Yuan, J.,
Luo, P., and Nie, Z. (2023). V2X-Seq: A large-scale
sequential dataset for vehicle-infrastructure coopera-
tive perception and forecasting. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 5486–5495. IEEE.
Zhou, Y. and Tuzel, O. (2018). VoxelNet: End-to-end learn-
ing for point cloud based 3D object detection. In Pro-
ceedings of the IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), pages 4490–4499.
IEEE.
The Components of Collaborative Joint Perception and Prediction: A Conceptual Framework
465
