
Big Data Fortaleza Platform: Quality Improvement with Testing Process
Amanda K. B. Cavalcante
1
,
´
Icaro S. de Oliveira
1,2
, Vict
´
oria T. Oliveria
1
, Pedro Almir M. Oliveira
1,3
,
Tales P. Nogueira
1,4
, Ismayle S. Santos
1,2
and Rossana M. C. Andrade
1
1
Computer Networks, Software and Systems Engineering Group (GREat), Federal University of Cear
´
a (UFC),
Fortaleza, CE, Brazil
2
State University of Cear
´
a (UECE), Fortaleza, CE, Brazil
3
Federal Institute of Education, Science and Technology of Maranh
˜
ao (IFMA), S
˜
ao Lu
´
ıs, MA, Brazil
4
University of International Integration of Afro-Brazilian Lusophony (Unilab), Redenc¸
˜
ao, CE, Brazil
Keywords:
Quality, Testing, Platform, Big Data.
Abstract:
In July 2022, the City Planning Institute of Fortaleza (Iplanfor), in collaboration with Computer Networks,
Software and Systems Engineering Group (GREat) from the Federal University of Cear
´
a, launched a project
to develop a platform utilizing Big Data for data analysis and predictive modeling. This initiative aimed to
support strategic planning and create solutions that would foster the development of City Fortaleza, ultimately
guiding public policies based on solid evidence. The platform was named Big Data Fortaleza. Given its focus
on government applications, it was essential to validate the platform through various testing methods. This
article outlines the adopted testing process and highlights critical outcomes, including improved prediction
accuracy and enhanced system and data security efficiency. Additionally, it discusses valuable lessons learned,
such as the importance of effective team communication and the necessity for ongoing adjustments to maintain
the platform’s quality and reliability.
1 INTRODUCTION
In recent years, integrating advanced technologies has
played a crucial role in developing and enhancing in-
telligent cities. According to Washburn et al. (2010),
an intelligent city should utilize computing technolo-
gies to make essential components and services of
city infrastructure — such as municipal administra-
tion, education, healthcare, public safety, real estate,
transportation, and utilities—smarter, more intercon-
nected, and more efficient. In this context, in July
2022, a collaboration between the City Planning Insti-
tute of Fortaleza and the Federal University of Cear
´
a
led to creating a project to bring Fortaleza closer to
becoming a smart city: the Big Data Fortaleza Plat-
form. This project emerged from the need to lever-
age Big Data technologies to analyze complex data
and generate valuable insights that can assist public
administration in strategic planning and urban devel-
opment for the city.
The Big Data Fortaleza platform, as previously
described and studied in (Santos et al., 2023), (Costa
et al., 2024), and (
´
Elcio Batista et al., 2024), was de-
signed not only to collect and store large-scale data
but also to utilize advanced analysis and prediction
techniques. Its primary objective is to provide essen-
tial information for decision-making processes, par-
ticularly in the formulation and implementation of
public policies based on solid evidence. The develop-
ment of this platform was accompanied by a rigorous
testing process to ensure its functionalities are effi-
cient and reliable, as well as to maintain the security
and integrity of the data it manages.
This article will present an overview of the test-
ing process adopted, the challenges of testing Big
Data systems, and the results obtained. Additionally,
the importance of incorporating testing from the early
stages of development will be discussed, highlighting
the lessons learned throughout this process.
This report provides insight into the testing pro-
cess of the Big Data Fortaleza platform. It serves as
a guide for development teams facing similar chal-
lenges in both the public and private sectors, empha-
sizing the importance of testing in Big Data systems
to deliver more reliable and high-quality outcomes.
This article is structured into six main sections.
Cavalcante, A. K. B., S. de Oliveira, Í., Oliveria, V. T., Oliveira, P. A. M., Nogueira, T. P., Santos, I. S. and Andrade, R. M. C.
Big Data Fortaleza Platform: Quality Improvement with Testing Process.
DOI: 10.5220/0013290500003929
In Proceedings of the 27th International Conference on Enterprise Information Systems (ICEIS 2025) - Volume 2, pages 227-236
ISBN: 978-989-758-749-8; ISSN: 2184-4992
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
227

In Section 2, related works are discussed, providing
an overview of existing research and practices in the
field. Section 3 contextualizes the project, describing
its environment and motivations. Section 4 details the
actions taken, including the methods and procedures
adopted. Section 5 presents the results achieved with
the project implementation. In Section 6, we report
some insights from a survey conducted with profes-
sionals involved in the system’s development. Finally,
Section 7 discusses the lessons learned, highlighting
insights and recommendations for future work in the
area.
2 RELATED WORKS
Quality assurance (QA) research for big data sys-
tems has grown significantly recently. Various stud-
ies have explored different aspects and approaches
to ensure data quality and the effectiveness of exten-
sive data systems. This section reviews the most rele-
vant works contributing to understanding and advanc-
ing QA practices in big data. To find those works,
a literature review was conducted using the Scopus
database, known for its extensive coverage of soft-
ware engineering research. The selection of related
studies involved a search string with synonyms, in-
cluding “big data systems,” “big data platform,” “ex-
perience report,” “case study,” “implementation re-
port,” “field report,” “lessons learned,” “practical ex-
perience,” “quality assurance,” QA, and “software
testing.” These terms aimed to filter studies on testing
and quality in these systems. The decision to use Sco-
pus was based on its coverage of significant digital li-
braries and the use of IEEE Xplore, which aligns with
the recommendations of other systematic reviews in
software engineering (Staegemann et al., 2020).
The studies by (Daase et al., 2024) and
(de Oliveira et al., 2024) conducted systematic re-
views to address research gaps by identifying and cat-
aloging specific methods, techniques, practices, and
tools for quality assurance in big data systems. (Daase
et al., 2024) particularly emphasized the challenges
of testing in big data environments, including issues
related to realistic datasets and scalability. Build-
ing on their work, our review systematically catego-
rizes existing QA methods and tools, assesses their
effectiveness, and identifies best practices tailored to
the unique demands of big data systems. These ap-
proaches have been instrumental in the development
of this report.
Another relevant study in the field of quality assur-
ance for systems handling data is by Nasir, Neelum, et
al. (Nasir et al., 2022), titled ”Testing Framework for
Big Data: A Case Study of Telecom Sector of Pak-
istan.” This work proposes a specific testing frame-
work for big data that can be applied to the telecom-
munications sector in Pakistan. The authors develop
and implement a set of testing practices and tools
tailored to big data’s unique requirements and chal-
lenges, such as volume, variety, and velocity of data.
The case study demonstrates the framework’s effec-
tiveness in improving data quality and enabling early
fault detection, contributing to the stability and relia-
bility of big data systems in the telecommunications
sector.
In addition, we have the study by Punn, Narinder
Singh, et al. (Punn et al., 2019), titled ”Testing Big
Data Application”. This work explores testing strate-
gies for big data applications, addressing the inherent
challenges in verifying and validating systems han-
dling large volumes of data. The authors propose a
comprehensive testing approach that includes func-
tional, performance, and security testing techniques
specifically adapted to the unique characteristics of
big data applications. The research emphasizes the
importance of a robust testing infrastructure and the
integration of automated tools to ensure the efficiency
and effectiveness of the QA process.
Finally, we have the work ”Deployment of a
Machine Learning System for Predicting Lawsuits
Against Power Companies: Lessons Learned from
an Agile Testing Experience for Improving Software
Quality” (Rivero et al., 2020). This study reports
implementing a machine learning system to predict
lawsuits against power companies, highlighting the
lessons learned during an agile testing experience to
improve software quality. The authors discuss the
challenges faced, such as the need to adapt agile
practices to accommodate the complexity of machine
learning and the importance of continuous and itera-
tive testing to ensure the system’s accuracy and relia-
bility. The lessons learned emphasize the importance
of collaboration among multidisciplinary teams and
flexibility in QA approaches to address the specifici-
ties of machine learning systems.
The review of related works demonstrates the di-
versity of approaches and methodologies applied to
quality assurance in big data systems. Studies such
as those by Nasir et al. (2022) and Punn et al. (2019)
provide practical frameworks and strategies adaptable
to different sectors and contexts. The experience re-
ported in implementing machine learning systems for
power companies underscores the importance of ag-
ile and collaborative practices. Together, these works
offer a solid foundation and diverse perspectives that
inform and enrich our QA approach in big data, es-
pecially in governmental environments, where the ro-
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
228

bustness of tools and the effectiveness of strategies are
critical.
3 CONTEXT
The City Hall of Fortaleza developed a participatory
strategic plan to integrate physical-territorial devel-
opment with social and economic aspects. The plan
seeks to bring together different perspectives and sec-
tors and the various territories and levels of govern-
ment in discussions about the city. The current chal-
lenges the plan aims to address are educational delays,
low qualification levels, youth vulnerability, poverty,
and social inequality (Santos et al., 2023).
One of the highlighted challenges is the issue of
Early Childhood, which encompasses actions targeted
at children from zero to six years old. This area of fo-
cus is cross-cutting, requiring interventions in health,
education, social assistance, and other sectors. To ad-
dress the challenges faced by the city of Fortaleza and
its administration, data collection and analysis are es-
sential for diagnosing problems and supporting mu-
nicipal leaders’ decisions. Through compelling anal-
ysis of this data, it is possible to improve service de-
livery to the community and predict the impact of
changes in urban infrastructure. Thus, a robust in-
frastructure is essential for collecting, storing, and
processing data from various sources [Ommited for
Blind].
The creation of the platform BigData X enabled
comprehensive analyses using data from various sec-
tors related to early childhood. It delivered to munici-
pal managers more than 20 analytics and three notifi-
cation alerts linked to the departments of early child-
hood, education, health, social assistance, and drug
prevention. As a result, municipal managers gained
valuable insights for developing new public policies
for citizens, such as integrating child vaccination pro-
grams into daycare centers. Within a month of the
platform’s launch, more than 2,000 children had their
vaccination schedules updated and brought up to date.
In education, it was essential for public managers
to ensure access to nurseries, daycare centers, and
schools specialized in early childhood education. Re-
garding health, it was crucial to offer comprehen-
sive care, encompassing prenatal and postnatal care
for women and the initiation of newborn follow-up,
including vaccine administration. In human rights
and social development, it was necessary to identify
and support families in socioeconomic vulnerability
or homelessness, providing social benefits to reduce
disparities and facilitate access to services and re-
sources that promote the rights of children and preg-
nant women.
The development of the platform adopted the
framework Scrum. Scrum is a widely used ag-
ile methodology in software development, charac-
terized by its iterative and incremental approach
through Sprints (Schwaber and Sutherland, 2020).
The Sprints are well-defined, timeboxed periods last-
ing two to four weeks, with a clear objective and a set
of product backlog items to be delivered by the end of
the period.
In the case of Big Data Fortaleza, Sprints lasting
two weeks were adopted after a discussion about the
team’s characteristics, such as the presence of part-
time fellows. During this period, the teams worked
in parallel and collaboratively, including requirements
elicitation, screen design, data collection and extrac-
tion, platform development, and testing.
Testing, in turn, plays a crucial role in the con-
text of Big Data Fortaleza, mainly due to the sensitive
nature of the data involved. Given the vast amount
of sensitive information collected and processed by
the platform, quality assurance through testing is es-
sential to mitigate security, privacy, and data integrity
risks.
The tests encompassed three levels (Bourque and
Fairley, 2014):
1. Unit Testing: focused on the isolated evaluation
of software units and conducted by the develop-
ment team;
2. Integration Testing: verified the integration be-
tween the various software units by the develop-
ment team;
3. System Testing: analyzed the system as a whole
to ensure its compliance with the established spec-
ifications and requirements.
In the following sections, the system testing pro-
cess is described, including the tools used and the re-
sults and lessons learned during the platform’s devel-
opment period.
4 ACTIONS TAKEN
This section will detail the actions implemented to en-
sure quality in system development. Given the sys-
tem’s complexity and scale, it was essential to adopt a
systematic approach that covered everything from re-
quirements definition to final validation. We will de-
scribe unit, integration, and system testing, including
functional and security tests. Additionally, we will
present the tools used and the risk mitigation strate-
gies. Each action described was essential to ensure
Big Data Fortaleza Platform: Quality Improvement with Testing Process
229

the developed system’s robustness, reliability, and ef-
fectiveness.
4.1 Unit and Integration Testing
For the system development, a backend design was
chosen with the following technologies: Spring
Boot
1
, Spring Data
2
, JPA
3
, Postgres
4
, Spring Secu-
rity
5
. These technologies were essential due to the
need to establish a robust access control policy for the
platform.
Unit tests were crucial in assisting with the back-
end implementation, particularly for the creation of
microservices, which are structured programs with
well-defined inputs and outputs that are highly com-
plex—for example, performing checks on texts and
phrases with logical rules for numerical values.
The development team prioritized the implemen-
tation of integration tests in the system’s backend. As
government data is of utmost importance, the imple-
mented business logic must be consistent, as it is a
fundamental component in the processing and con-
sumption of the data.
Docker with Test Container Postgres was used as
a tool for integration testing with the database, cre-
ating something ephemeral specifically for that test.
Additionally, JUnit5 was used to perform both unit
and integration tests.
These tool and approach choices proved to be ad-
vantageous in the testing process. Docker with Test
Container ensured the consistency and reliability of
the tests. At the same time, the use of JUnit 5 and
AutoConfigureMockMvc simplified the development
and execution of the tests, allowing for precise vali-
dation of the business logic of the Big Data system.
API tests were also performed using the Postman
tool
6
, where requests were made to the system’s API,
and the response body, as well as the status code and
its compliance with the documentation, were verified.
Initially, due to the importance of data protection, the
tests on the authentication controller and user man-
agement were prioritized. Moreover, the tool provides
a history of executions, facilitating error monitoring.
4.2 System Testing
In this subsection, we address the system testing pro-
cess, which is crucial for ensuring the integration and
1
https://spring.io/projects/spring-boot
2
https://spring.io/projects/spring-data
3
https://spring.io/projects/spring-data-jpa
4
https://www.postgresql.org/
5
https://spring.io/projects/spring-security
6
https://www.postman.com/
proper functioning of the platform’s various features.
System testing verified the entire system, ensuring
that all components operate together as expected and
meet the established requirements.
4.2.1 Functional and Interface Testing
In the process of functional testing for the Big Data
system, test cases were initially created in Testlink
7
,
an open-source software test management tool, based
on the platform’s use cases. These were then manu-
ally executed following a plan also created within the
tool. When a bug was detected, it was reported in
GitLab
8
, including a description, reproduction steps,
severity, and evidence. After the bug was fixed, a
retest was conducted to verify the effectiveness of the
fix. This testing cycle can be summarized in Figure 1.
During functional testing, the system’s compli-
ance with the prototype created in Figma
9
by the de-
sign team was also verified. Additionally, exploratory
testing was conducted, where testers used their ex-
perience and knowledge to explore different system
usage scenarios. This was important for identifying
potential flaws or unexpected behaviors that were not
covered by traditional test cases. The combined ap-
proach of functional testing based on use cases and
exploratory testing allowed for comprehensive cover-
age of the critical aspects of the system, contributing
to its robustness and reliability in production environ-
ments.
4.2.2 Security Testing
Security testing aims to identify vulnerabilities in ap-
plications and can be divided into two categories (Ay-
dos et al., 2022): (i) functional security testing, ensur-
ing that the software’s security functions are correctly
implemented according to security requirements; and
(ii) security vulnerability testing, focusing on discov-
ering security vulnerabilities from an attacker’s per-
spective. Thus, security testing involves an active ap-
plication analysis to identify any weaknesses, techni-
cal flaws, or vulnerabilities (OWASP, 2023). In the
Big Data Fortaleza system, tests were conducted to
identify potential vulnerabilities in the platform due
to the sensitivity of the information stored. In this re-
gard, one of the security assessments followed these
steps:
• Step 1 Port and service scan on the platform host.
Using the nmap
10
tool, the active ports on the
7
https://testlink.org/
8
https://about.gitlab.com/
9
https://www.figma.com/
10
https://nmap.org/
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
230
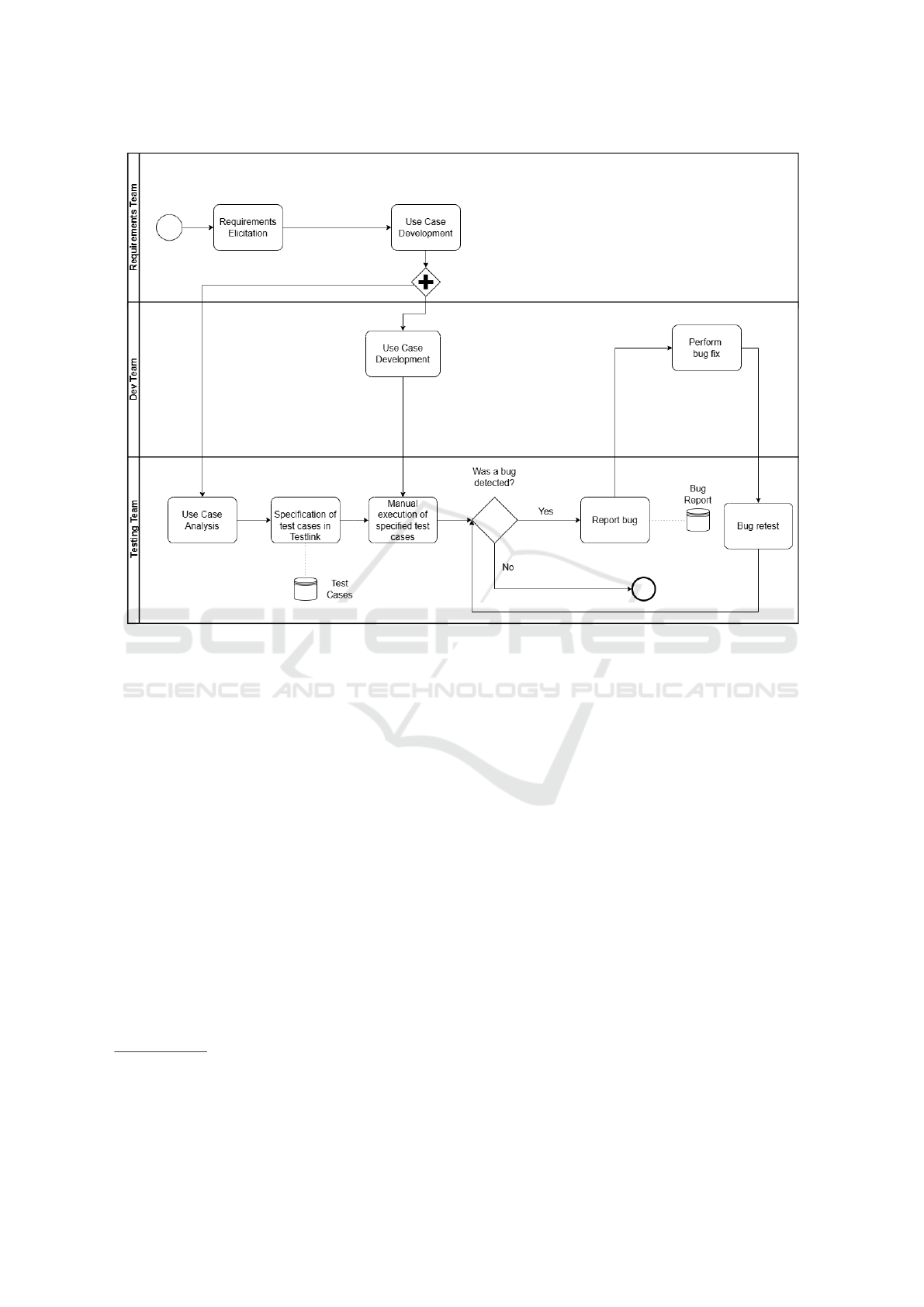
Figure 1: Functional testing process.
server where the platform was running were an-
alyzed. After the scan, the versions of the run-
ning services were detected, and the known vul-
nerabilities associated with each version were an-
alyzed using reports and vulnerability documen-
tation platforms, such as NetApp
11
and CVEDe-
tails
12
.
• Step 2 Web vulnerability scanner. The OWASP
ZAP
13
tool was used to conduct a static analysis
for vulnerabilities in the platform’s code. Addi-
tionally, Burp Suite
14
was used to inspect the data
and requests exchanged, focusing on identifying
vulnerabilities in HTTP requests.
• Step 3. Security inspection. An inspection was
carried out on the encryption algorithms used to
check for deprecated algorithms or misconfigura-
tions. Furthermore, other system libraries were
inspected for security flaws.
11
https://security.netapp.com/advisory/
12
https://www.cvedetails.com/documentation/
13
https://www.zaproxy.org/
14
https://portswigger.net/burp
5 RESULTS
This section presents the results obtained during the
application testing process. The goal is to provide
a clear overview of the observed performance, criti-
cal issues identified, and the applied corrections. The
analysis of these results highlights the final quality of
the application and offers valuable lessons for future
development and adjustments.
5.1 Results of Unit and Integration
Tests
The unit and integration tests conducted on the appli-
cation’s backend proved effective in validating com-
ponents and identifying issues early. The most rele-
vant outcomes ara shown on Table 1.
During the development process, Test-Driven De-
velopment (TDD) was employed to write the tests.
Initially, unit tests were created to verify the function-
ality of the libraries, followed by integration tests to
ensure a more robust implementation. Tests were also
separated at the controller level to focus specifically
Big Data Fortaleza Platform: Quality Improvement with Testing Process
231

Table 1: Test coverage in the backend.
Class Method Line
67% (474/700) 50% (2022/4038) 46% (5886/12598)
on routes and request responses more objectively. The
implementation and coverage of these tests enhanced
the security and quality of the development flow, en-
suring that new implementations could rely on the sta-
bility of previous ones. So far, approximately 67%
of the total lines of code have been covered by unit
and integration tests. Unit tests conducted on the mi-
croservices achieved 100% coverage, as the code was
written for specific tasks with fewer lines, allowing
the tests to cover all existing functions efficiently.
5.2 System Testing Results
The results of the functional tests provide a detailed
overview of the system’s quality, with 228 test cases
documented in Testlink. During the testing process,
194 bugs were identified, 166 of which have already
been resolved by the system developers. A summary
of these figures is presented in Table 2 .
Most of these bugs were related to minor inter-
face issues, such as button names, section titles, and
similar elements. However, critical and severe errors
were also identified in key system functionalities. For
instance, due to an issue with access management im-
plemented in a late development stage, some user pro-
files lost access to functionalities they were supposed
to have, such as viewing analytics.
One of the difficulties encountered was related to
the instability of the bandwidth in the testing envi-
ronment. It was observed that, due to the variabil-
ity in the amount of data required to display analyt-
ics (graph, map, etc.), the connection to the Amazon
Simple Storage Service (S3) was interrupted due to
a timeout. Previously, the system handled each re-
quest for a route that processed multiple calls to S3.
This caused a queuing of requests and delayed the
response to generate the analytics, leading to errors
and slow performance. Subsequently, after the imple-
mentation of microservices to specifically handle the
search and loading of data, leaving the central system
less overloaded, a reduction in the response time of
the data and an improvement in the platform’s perfor-
mance were observed.
In the Big Data Fortaleza project context, where
information security and data analysis play critical
roles in public administration, security testing re-
vealed significant vulnerabilities that were addressed
before the system went into production. One notable
example was the absence of a configuration for the
Content Security Policy (CSP) header, used in HTTP
requests, identified by the vulnerability scanner. In
this case, the development team adjusted the config-
uration, ensuring the mitigation of attacks (including
Cross-Site Scripting).
During this security evaluation, other aspects re-
lated to the management of cloud services and the
protection of the Big Data system infrastructure were
also observed, such as the need for services to handle
Denial-of-Service (Anti-DDoS) attacks and the im-
portance of creating rules to prevent data leakage via
unauthorized access to team accounts. As a result,
several actions were taken:
• Strengthening the critical rotation policy and us-
ing Multi-Factor Authentication (MFA).
• Restricting incoming and outgoing traffic to en-
sure that the City Hall’s firewall would initially
filter all accesses.
• Encrypting data stored in the cloud.
• Performing daily backups with a 30-day retention
period.
• Strengthen firewall rules to prevent bot access and
the exploitation of known vulnerabilities.
• Adopting AWS Shield for DDoS protection.
• Using CloudTrail to log all actions performed on
the platform’s supporting infrastructure.
• Utilizing AWS GuardDuty to analyze potential
threats.
6 DATA QUALITY
Data is essential to modern life (Wang et al., 2023)
and is considered an asset that aids in strategic busi-
ness and policy decision-making based on data in-
sights (Taleb et al., 2016). This relevance has con-
tributed to the emergence of data-driven decision-
making, which prescribes that data is at the core of
decision-making and influences the quality of deci-
sions (Wang et al., 2023).
Wang et. al (2023) conducted a literature review to
understand the dimensions of data in such a way that
they can be of high quality, as they are essential for
decision-making. The authors summarized the find-
ings into 21 data quality dimensions, with five being
the most important: completeness, accuracy, timeli-
ness, consistency, and relevance. In this context, it is
vital to understand the significance of data and how
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
232
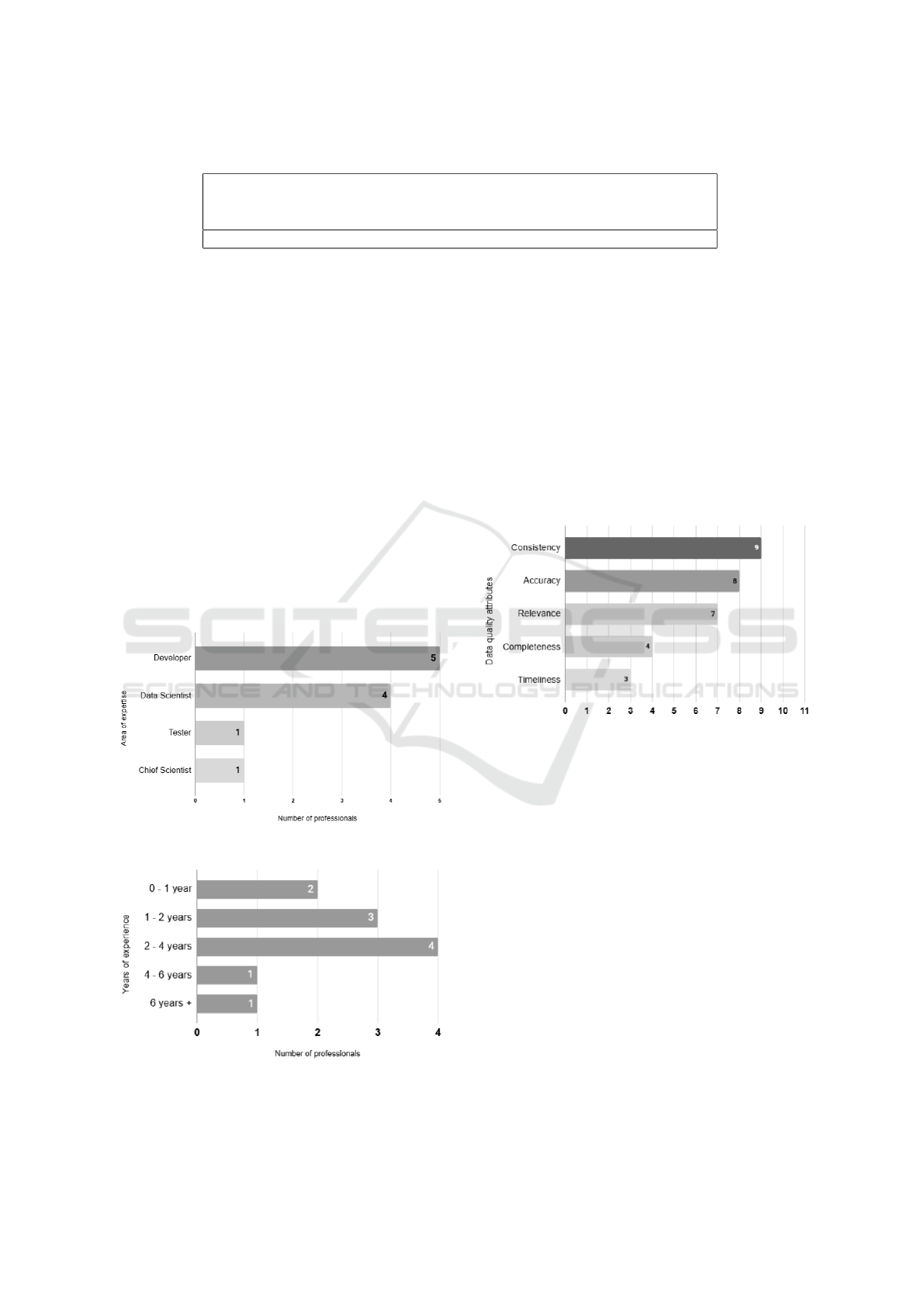
Table 2: Quality Monitoring: Number of Tests and Fixes.
Number of test
cases
Number of
reported bugs
Number of fixed
bugs
Number of
automated API
tests
228 194 166 69
it can contribute to decision-making aimed at improv-
ing software quality, impacting both the quality of the
product and the process.
Given this, a survey was conducted internally with
the development professionals, data scientists, and the
quality team of the project to understand their per-
ceptions regarding the main challenges in pursuing
data quality, considering the five attributes mentioned
above.
Based on the responses from the form, it was pos-
sible to collect 11 responses with various insights
from the professionals. The collected data provides
a broader view of the main challenges and attributes
they consider essential. The questions from the form,
provided through Google Forms, are compiled in Ta-
ble 3.
The professionals surveyed have a broad and var-
ied experience in the field, as shown in Figure 2, with
years of experience ranging from less than one year
to over six years, as illustrated in Figure 3.
Figure 2: Professionals’ Area of Expertise.
Figure 3: Years of Experience of the Professionals.
6.1 Data Quality Attributes
The primary data quality attributes identified by the
professionals were consistency, accuracy, and rele-
vance, as shown in Figure 4. These attributes were
considered priorities because they ensure the col-
lected data is complete, accurate, and relevant to busi-
ness needs. Consistency ensures the data is uniform
and coherent across different sources and systems.
Accuracy ensures that the data is free from errors and
inaccuracies, reflecting reality precisely. Relevance
ensures the data is pertinent and valuable for the orga-
nization’s objectives, enabling informed and effective
decision-making.
Figure 4: Most Relevant Attributes.
6.2 Identified Challenges
The challenges most frequently mentioned regarding
data quality in Big Data systems included the need for
more specific tests, such as load, performance, and
integrity tests. These tests are necessary to ensure
that the system can efficiently handle large volumes of
data without compromising the performance or accu-
racy of the processed data. The absence of these tests
can lead to significant failures, impacting the system’s
reliability and effectiveness.
Additionally, the need for better communication
and integration between the development teams and
the Product Owners (POs) was highlighted to ensure
that data quality criteria are adequately met.
6.3 Testing Techniques
Among the testing techniques mentioned as missing,
load and performance testing stand out, as they are
Big Data Fortaleza Platform: Quality Improvement with Testing Process
233

Table 3: Questions from the survey applied.
Questions Response Options
Have you worked with applications that handle large volumes of data
(big data)?
Yes or No
What was your role in the big data project? Developer, Data Scientist,
Tester, Other
How would you rate your experience in the field? 0-1 year, 1–2 years, 2–4
years, 4–6 years, more than
6 years
Which of these data quality attributes do you consider most important?
(choose only 3)
Completeness, Accuracy,
Timeliness, Consistency,
Relevance, Other. . .
Rank the 3 attributes selected above in order of importance (e.g., 1.
Option A, 2. Option B, 3. Option C)
Open-ended question
Do you believe the Completeness of data was evaluated in System X?
How do you suggest evaluating the Completeness of data in a Big Data
system?
Open-ended question
Do you believe the Accuracy of data was evaluated in System X?
How do you suggest evaluating the Accuracy of data in a Big Data sys-
tem?
Open-ended question
Do you believe the Timeliness of data was evaluated in System X?
How do you suggest evaluating the Timeliness of data in a Big Data
system?
Open-ended question
Do you believe the Consistency of data was evaluated in System X?
How do you suggest evaluating the Consistency of data in a Big Data
system?
Open-ended question
Do you believe the Relevance of data was evaluated in System X?
How do you suggest evaluating the Relevance of data in a Big Data
system?
Open-ended question
In your experience with System X, did you feel the need for any specific
type of testing? (Choose only 3)
Load Testing, Performance
Testing, Regression Testing,
Usability Testing, Unit Test-
ing, Integration Testing, Se-
curity Testing, Other. . .
In your experience with System X, did you feel the need for any specific
type of testing?
Open-ended question
essential for evaluating the system’s ability to process
large volumes of data efficiently, as shown in Fig-
ure 5. These tests help ensure that the system main-
tains proper performance under high data load. Fur-
thermore, integrity tests are also relevant for verify-
ing that data flows remain consistent and error-free
throughout the different processing stages. Apply-
ing these techniques is crucial to ensure the robust-
ness and reliability of the system in Big Data environ-
ments.
The survey conducted through the form provided
greater clarity on the most relevant data quality at-
tributes and the challenges faced by the system devel-
opment and quality teams. Adopting specific testing
techniques and improving communication between
teams is essential for enhancing data quality and, con-
sequently, the effectiveness of decisions based on that
Figure 5: Most requested test types.
data. These measures not only elevate the quality of
the final product but also optimize internal processes,
resulting in a more robust and reliable system.
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
234

7 LESSONS LEARNED
During the development and testing of the Big Data
Fortaleza platform, several valuable lessons were
learned, significantly contributing to improving the
development process and quality assurance. Here are
some of the key lessons that emerged:
1. Invest in Testing Processes to Ensure Data
Quality. Data quality is a crucial aspect of the
success of a Big Data platform. During the sys-
tem testing, it became evident that investing time
and resources in ensuring data quality is neces-
sary. This includes identifying, cleaning, stan-
dardizing formats, and ensuring data integrity and
consistency, as poor data quality can compromise
the effectiveness of analysis and decision-making.
In general, it is observed that such activities are
the responsibility of the data team, and there is no
strong culture related to test coding.
2. Need for Data Simulation. An important lesson
learned during the development and validation of
the Big Data Fortaleza system was the need for
data simulation, in addition to using accurate data,
to effectively validate the dashboards present in
the system. This approach allowed a more com-
prehensive verification of the dashboard function-
alities, ensuring that they could handle a variety
of scenarios and data volumes.
3. Security Testing Should Be Conducted Contin-
uously from the Start of the Project. Data pro-
tection policies are crucial in Big Data projects,
especially those dealing with sensitive data. This
includes penetration testing, vulnerability analy-
sis, data encryption, and restricted access policies
to protect the integrity and confidentiality of the
information stored and processed by the platform.
4. Integration and Unit Tests Are Vital to Ensure
the Reliability of Business Rules. Since the sys-
tem deals with sensitive data, conducting integra-
tion tests is crucial. These tests are designed to
verify whether the different components of the
system interact correctly with each other and with
the database, ensuring the integrity and proper
functioning of the application as a whole.
5. Assertive Communication Between Teams
Should Be a Priority. Support and communica-
tion between developers and data scientists were
essential for the testing team to perform their work
effectively and contribute significantly to the suc-
cess of the Big Data Fortaleza project. Constant
communication with the development team al-
lowed for continuous information exchange about
bugs that should be prioritized, recurring failures,
and knowledge transfer. Data scientists, in turn,
helped the testing team better understand the data
analysis requirements and identify possible incon-
sistencies. This collaboration resulted in a more
comprehensive testing approach, ensuring early
detection of issues and delivering a high-quality
final product.
REFERENCES
Aydos, M., Aldan, C¸ ., Cos¸kun, E., and Soydan, A.
(2022). Security testing of web applications: A sys-
tematic mapping of the literature. Journal of King
Saud University-Computer and Information Sciences,
34(9):6775–6792.
Bourque, P. and Fairley, R. (2014). SWEBOK: Guide to the
software engineering body of knowledge. IEEE Com-
puter Society, Los Alamitos, CA, version 3.0 edition.
Costa, A., Freitas, L., Cavalcante, D., Oliveira, V., Lelli, V.,
Santos, I., Oliveira, P., Nogueira, T., and Andrade, R.
(2024). Especificac¸
˜
ao de requisitos em um projeto de
big data no setor p
´
ublico. In Anais do XXVII Con-
gresso Ibero-Americano em Engenharia de Software,
pages 417–420, Porto Alegre, RS, Brasil. SBC.
Daase, C., Staegemann, D., and Turowski, K. (2024). Over-
coming the complexity of quality assurance for big
data systems: An examination of testing methods. In
IoTBDS, pages 358–369, Magdeburg, Germany. Insti-
tute of Technical and Business Information Systems.
de Oliveira, I., Lima, J. M., Cristhian, S., Santos, I. S., and
Andrade, R. (2024). Quality of big data systems: a
systematic review of practices methods and tools. In
SBQS 2024 - Trilha de Trabalhos T
´
ecnicos.
Nasir, N., Imtiaz, S., Imtiaz, S., and Nabeel, M. (2022).
Testing framework for big data: A case study of tele-
com sector of pakistan.
OWASP (2023). Owasp testing guide.
Punn, N. S., Agarwal, S., Syafrullah, M., and Adiyarta, K.
(2019). Testing big data application. In 2019 6th Inter-
national Conference on Electrical Engineering, Com-
puter Science and Informatics (EECSI). IEEE.
Rivero, L., Diniz, J., Silva, G., Borralho, G., Braz, G.,
Paiva, A., Alves, E., and Oliveira, M. (2020). De-
ployment of a machine learning system for predicting
lawsuits against power companies: Lessons learned
from an agile testing experience for improving soft-
ware quality. In Anais do XIX Simp
´
osio Brasileiro de
Qualidade de Software, pages 294–303, Porto Alegre,
RS, Brasil. SBC.
Santos, I., Oliveira, P., Oliveira, V., Nogueira, T., Dan-
tas, A., Menescal, L.,
´
Elcio Batista, and Andrade, R.
(2023). Big data fortaleza: Plataforma inteligente para
pol
´
ıticas p
´
ublicas baseadas em evid
ˆ
encias. In Anais do
XI Workshop de Computac¸
˜
ao Aplicada em Governo
Eletr
ˆ
onico, pages 200–211, Porto Alegre, RS, Brasil.
SBC.
Schwaber, K. and Sutherland, J. (2020). The Scrum Guide
– the definitive guide to scrum: The rules of the game.
Big Data Fortaleza Platform: Quality Improvement with Testing Process
235

Staegemann, D., Volk, M., Daase, C., and Turowski, K.
(2020). Discussing relations between dynamic busi-
ness environments and big data analytics. Com-
plex Systems Informatics and Modeling Quarterly,
(23):58–82.
Taleb, I., El Kassabi, H. T., Serhani, M. A., Dssouli, R., and
Bouhaddioui, C. (2016). Big data quality: A quality
dimensions evaluation. In 2016 Intl IEEE Conferences
on Ubiquitous Intelligence & Computing, Advanced
and Trusted Computing, Scalable Computing and
Communications, Cloud and Big Data Computing,
Internet of People, and Smart World Congress
(UIC/ATC/ScalCom/CBDCom/IoP/SmartWorld),
pages 759–765. IEEE.
Wang, J., Liu, Y., Li, P., Lin, Z., Sindakis, S., and Aggarwal,
S. (2023). Overview of data quality: Examining the
dimensions, antecedents, and impacts of data quality.
Journal of the Knowledge Economy, pages 1–20.
Washburn, D., Sindhu, U., Balaouras, S., Dines, R., Hayes,
N., and Nelson, L. (2010). Helping CIOs Understand
“Smart City” Initiatives: Defining the smart city, its
drivers, and the role of the cio. Cambridge, MA: For-
rester Research.
´
Elcio Batista, Andrade, R., Santos, I., Nogueira, T.,
Oliveira, P., Lelli, V., and Oliveira, V. (2024). Fort-
aleza city hall strategic planning based on data anal-
ysis and forecasting. In Anais do XXVII Congresso
Ibero-Americano em Engenharia de Software, pages
433–436, Porto Alegre, RS, Brasil. SBC.
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
236
