
Multiple Importance Sampling for Stochastic Gradient Estimation
Corentin Sala
¨
un
1 a
, Xingchang Huang
1 b
, Iliyan Georgiev
2 c
, Niloy Mitra
2,3 d
and
Gurprit Singh
1 e
1
Max Planck Institute for Informatics, Saarland University, Saarbr
¨
ucken, Germany
2
Adobe Research, London, U.K.
3
Department of Computer Science, University College London, London, U.K.
Keywords:
Optimization, Machine Learning, Gradient Estimation.
Abstract:
We introduce a theoretical and practical framework for efficient importance sampling of mini-batch samples
for gradient estimation from single and multiple probability distributions. To handle noisy gradients, our
framework dynamically evolves the importance distribution during training by utilizing a self-adaptive met-
ric. Our framework combines multiple, diverse sampling distributions, each tailored to specific parameter
gradients. This approach facilitates the importance sampling of vector-valued gradient estimation. Rather
than naively combining multiple distributions, our framework involves optimally weighting data contribution
across multiple distributions. This adapted combination of multiple importance yields superior gradient es-
timates, leading to faster training convergence. We demonstrate the effectiveness of our approach through
empirical evaluations across a range of optimization tasks like classification and regression on both image and
point cloud datasets.
1 INTRODUCTION
Stochastic gradient descent (SGD) is fundamental in
optimizing complex neural networks. This iterative
optimization process relies on the efficient estimation
of gradients to update model parameters and mini-
mize the optimization objective. A significant chal-
lenge in methods based on SGD lies in the influ-
ence of stochasticity on gradient estimation, impact-
ing both the quality of the estimates and convergence
speed. This stochasticity introduces errors in the form
of noise, and addressing and minimizing such noise in
gradient estimation continues to be an active area of
research.
Various approaches have been introduced to re-
duce gradient estimation noise, including data diver-
sification Zhang et al. (2019); Faghri et al. (2020);
Ren et al. (2019), adaptive mini-batch sizes Balles
et al. (2017); Alfarra et al. (2021), momentum-based
estimation Rumelhart et al. (1986); Kingma and Ba
a
https://orcid.org/0000-0002-5112-7488
b
https://orcid.org/0000-0002-2769-8408
c
https://orcid.org/0000-0002-9655-2138
d
https://orcid.org/0000-0002-2597-0914
e
https://orcid.org/0000-0003-0970-5835
(2014), and adaptive sampling strategies Santiago
et al. (2021). These methods collectively expedite the
optimization by improving the gradient-estimation
accuracy.
Another well-established technique for noise
reduction in estimation is importance sampling
(IS) Loshchilov and Hutter (2015); Katharopoulos
and Fleuret (2017, 2018), which involves the non-
uniform selection of data samples for mini-batch con-
struction. Data samples that contribute more signifi-
cantly to gradient estimation are selected more often.
This allows computational resources to focus on the
most critical data for the optimization task. However,
these algorithms are quite inefficient and add signifi-
cant overhead to the training process. Another limita-
tion of importance sampling, in general, lies in deter-
mining the best sampling distribution to achieve max-
imal improvement, often necessitating a quality trade-
off due to the simultaneous estimation of numerous
parameters.
We propose an efficient importance sampling al-
gorithm that does not require resampling, in contrast
to Katharopoulos and Fleuret (2018). Our importance
function dynamically evolves during training, utiliz-
ing a self-adaptive metric to effectively manage ini-
tial noisy gradients. Further, unlike existing IS meth-
Salaün, C., Huang, X., Georgiev, I., Mitra, N. and Singh, G.
Multiple Importance Sampling for Stochastic Gradient Estimation.
DOI: 10.5220/0013311200003905
In Proceedings of the 14th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2025), pages 401-409
ISBN: 978-989-758-730-6; ISSN: 2184-4313
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
401

ods in machine learning where importance distribu-
tions assume scalar-valued gradients, we propose a
multiple importance sampling (MIS) strategy to man-
age vector-valued gradient estimation (i.e., multiple
parameters). We propose the simultaneous use of
multiple sampling strategies combined with a weight-
ing approach following the principles of MIS theory,
well studied in the rendering literature in computer
graphics Veach (1997). Rather than naively combin-
ing multiple distributions, our proposal involves esti-
mating importance weights w.r.t. data samples across
multiple distributions by leveraging the theory of opti-
mal MIS (OMIS) Kondapaneni et al. (2019). This op-
timization process yields superior gradient estimates,
leading to faster training convergence. In summary,
we make the following contributions:
• An efficient IS algorithm with a self-adaptive met-
ric for importance sampling is developed.
• An MIS estimator for gradient estimation is intro-
duced to improve gradients estimation.
• A practical approach to computing the OMIS
weights is presented to maximize the quality of
vector-valued gradient estimation.
• The effectiveness of the approach is demonstrated
on various machine learning tasks.
2 RELATED WORK
Importance Sampling for Gradient Estimation.
Importance sampling (IS) Kahn (1950); Kahn and
Marshall (1953); Owen and Zhou (2000) has emerged
as a powerful technique in high energy physics,
Bayesian inference, rare event simulation for finance
and insurance, and rendering in computer graphics.
In the past few years, IS has also been applied in
machine learning to improve the accuracy of gradi-
ent estimation and enhance the overall performance
of learning algorithms Zhao and Zhang (2015).
By strategically sampling data points from a non-
uniform distribution, IS effectively focuses training
resources on the most informative and impactful data,
leading to more accurate gradient estimates. Bordes
et al. (2005) developed an online algorithm (LASVM)
that uses importance sampling to train kernelized sup-
port vector machines. Loshchilov and Hutter (2015)
suggested employing data rankings based on their re-
spective loss values. This ranking is then employed
to create an importance sampling strategy that as-
signs greater importance to data with higher loss val-
ues. Katharopoulos and Fleuret (2017) proposed im-
portance sampling the loss function. Subsequently,
Katharopoulos and Fleuret (2018) introduced an up-
per bound to the gradient norm that can be em-
ployed as an importance function. Their algorithm
involves resampling and computing gradients with re-
spect to the final layer. Despite the importance func-
tion demonstrating improvement over uniform sam-
pling, their algorithm exhibits significant inefficiency.
Multiple Importance Sampling. The concept of
Multiple Importance Sampling (MIS) emerged as a
robust and efficient technique for integrating multi-
ple sampling strategies Owen and Zhou (2000). Its
core principle lies in assigning weights to multiple
importance sampling estimator, each using a differ-
ent sampling distribution, allowing each data sam-
ple to utilize the most appropriate strategy. Veach
(1997) introduced this concept of MIS to rendering in
computer graphics and proposed the widely adopted
balance heuristic for importance (weight) allocation.
The balance heuristic determines weights based on
a data sample’s relative importance across all sam-
pling approaches, effectively mitigating the influence
of outliers with low probability densities. While MIS
is straightforward to implement and independent of
the specific function, Variance-Aware MIS Grittmann
et al. (2019) advanced the concept by using variance
estimates from each sampling technique for further
error reduction. Moreover, Optimal MIS Kondapa-
neni et al. (2019) derived optimal sampling weights
that minimize MIS estimator variance. Notably, these
weights depend not only on probability density but
also on the function values of the samples. Supple-
mental document summarizes the theory behind (mul-
tiple) importance sampling. It also states the optimal
MIS estimator and how to compute it.
3 PROBLEM STATEMENT
The primary goal of machine-learning optimization is
to find the optimal parameters θ for a given model
function m(x,θ) by minimizing a loss function L over
a dataset Ω:
θ
∗
= argmin
θ
Z
Ω
L (m(x
i
,θ),y)dx.
| {z }
L
θ
(1)
The loss function L quantifies the dissimilarity be-
tween the model predictions m(x, θ) and observed
data y. In the common case of a discrete dataset, the
integral becomes a sum.
In practice, the total loss is minimized via iterative
gradient descent. In each iteration t, the gradient ∇L
θ
t
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
402

Output 1 Output 2 Output 3
Output
Output
layer
Loss
(a) Network diagram (b) Ground-truth (c) Output-layer (d) Norms of individual output nodes
classification gradient norm
Figure 1: We visualize different importance sampling distributions for a simple classification task. We propose to use the
output layer gradients for importance sampling, as shown in the network diagram (a). For a given ground-truth classification
(top) and training dataset (bottom) shown in (b), it is possible to importance sample from the L
2
norm of the output-layer
gradients (c) or from three different sampling distributions derived from the gradient norms of individual output nodes (d).
The bottom row shows sample weights from each distribution.
of the loss with respect to the current model parame-
ters θ
t
is computed, and the parameters are updated
as
θ
t+1
= θ
t
− λ
Z
Ω
∇L (m(x,θ
t
),y)dx
| {z }
∇L
θ
t
, (2)
where λ > 0 is the learning rate. It is also possible to
use an adaptive learning rate instead of a constant.
Monte Carlo Gradient Estimator. In practice, the
parameter gradient is estimated from a small batch
{x
i
}
B
i=1
of randomly selected data points:
⟨∇L
θ
⟩ =
B
∑
i=1
∇L (m(x
i
,θ),y
i
)
Bp(x
i
)
≈ ∇L
θ
, x
i
∼ p. (3)
The data points are sampled from a probability den-
sity function (pdf) p or probability mass function in
discrete cases. The mini-batch gradient descent sub-
stitutes the true gradient ∇L
θ
t
with an estimate ⟨∇L
θ
t
⟩
in Eq. (2) to update the model parameters in each it-
eration.
We want to estimate ∇L
θ
t
accurately and also effi-
ciently, since the gradient-descent iteration (2) may
require many thousands of iterations until the pa-
rameters converge. These goals can be achieved by
performing the optimization in small batches whose
samples are chosen according to a carefully designed
distribution p. For a simple classification problem,
Fig. 1c shows an example importance sampling dis-
tribution derived from the output layer of the model.
In Fig. 1d we derive multiple distributions from the
individual output nodes. Below we develop theory
and practical algorithms for importance sampling us-
ing a single distribution (Section 4) and for combin-
ing multiple distributions to further improve gradient
estimation (Section 5).
4 MINI-BATCH IMPORTANCE
SAMPLING
Mini-batch gradient estimation (3) notoriously suf-
fers from Monte Carlo noise, which can make the
parameter-optimization trajectory erratic and conver-
gence slow. That noise comes from the often vastly
different contributions of different samples x
i
to that
estimate.
Typically, the selection of the multiple samples
constructing a mini-batch is done with uniform prob-
ability p(x
i
) = 1/|Ω|. Each data of the mini-batch
is sampled with replacement following this distribu-
tion. Importance sampling is a technique for using a
non-uniform pdf to strategically pick samples propor-
tionally on their contribution to the gradient, to reduce
estimation variance.
Practical Algorithm. We propose an importance
sampling algorithm for mini-batch gradient descent,
outlined in Algorithm 1. Similarly to Schaul et al.
(2015), we use an importance function that relies on
readily available quantities for each data point, in-
troducing only negligible memory and computational
overhead over classical uniform mini-batching. We
store a set of persistent un-normalized importance
scalars q = {q
i
}
|Ω|
i=1
that are updated continuously dur-
ing the optimization.
The first epoch is a standard SGD one, during
which we additionally compute the initial importance
of each data point (line 3). In each subsequent epoch,
at each mini-batch optimization step t we normalize
the importance values to a valid distribution p (line
6). We then choose B data samples (with replace-
ment) according to p (line 7). The loss L is evaluated
Multiple Importance Sampling for Stochastic Gradient Estimation
403

Algorithm 1: Mini-batch importance sampling for SGD.
1: θ ← random parameter initialization
2: B ← mini-batch size, N = |Ω| ← Dataset size
3: q,θ ← Initialize(x,y,Ω,θ,B) ← See Supplemental
4: until convergence do ← Loop over epochs
5: for t ← 1 to N/B ← Loop over mini-batches
6: p ← q/sum(q) ← Normalize importance to pdf
7: x,y ← B data samples {x
i
,y
i
}
B
i=1
∝ p
8: L (x) ← L(m(x, θ),y)
9: ∇L (x) ← Backpropagate(L (x))
10: ⟨∇L
θ
⟩ ← (∇L (x)· (
1
/p(x))
T
)/B ← Eq. (3)
11: θ ← θ − λ ⟨∇L
θ
⟩ ← SGD step
12: q(x) ← α · q(x)+ (1 − α) ·
∂L (x)
∂m(x,θ)
13:
14: q ← q + ε
↱
Accumulate importance
15: return θ
for each selected data sample (line 8), and backprop-
agated to compute the loss gradient (line 9). The per-
sample importance is used in the gradient estimation
(line 10) to normalize the contribution. In practice
lines 9-10 can be done simultaneously by backpropa-
gating a weighted loss L (x) · (
1
/(p(x)·B))
T
. Finally, the
network parameters are updated using the estimated
gradient (line 11). On line 12, we update the impor-
tance of the samples in the mini-batch; we describe
our choice of importance function below. The blend-
ing parameter α ensures stability of the persistent im-
portance as discussed in Supplemental document. At
the end of each epoch (line 14), we add a small value
to the un-normalized weights of all data to ensure that
every data point will be eventually evaluated, even if
its importance is deemed low by the importance met-
ric.
It is important to note that the first epoch is done
without importance sampling to initialize each sam-
ple importance. This does not add overhead as it is
equivalent to a classical epoch running over all data
samples. While similar schemes have been proposed
in the past Loshchilov and Hutter (2015), they of-
ten rely on a multitude of hyperparameters, making
their practical implementation challenging. This has
led to the development of alternative methods like
re-sampling Katharopoulos and Fleuret (2018); Dong
et al. (2021); Zhang et al. (2023). Tracking impor-
tance across batches and epochs minimizes the com-
putational overhead, further enhancing the efficiency
and practicality of the approach.
Importance Function. In combination with the
presented algorithm, we propose an importance func-
tion that is efficient to evaluate. While the gradient L
2
norm has been shown to be optimal Zhao and Zhang
(2015); Needell et al. (2014); Wang et al. (2017);
Alain et al. (2015), calculating it can be computation-
ally expensive as it requires full backpropagation for
every data point. To this end, we compute the gradient
norm only for a subset of the parameters, specifically
the output nodes of the network: q(x) =
∂L (x)
∂m(x,θ)
.
This choice is based on an upper bound of the gradient
norm, using the chain rule and the Cauchy–Schwarz
inequality Katharopoulos and Fleuret (2018):
∂L (x
i
)
∂θ
=
∂L (x)
∂m(x,θ)
·
∂m(x,θ)
∂θ
≤ (4)
∂L (x)
∂m(x,θ)
·
∂m(x,θ)
∂θ
≤
∂L (x)
∂m(x,θ)
| {z }
q(x)
·C ,
where C is the Lipschitz constant of the parameters
gradient. That is, our importance function is a bound
of the gradient magnitude based on the output-layer
gradient norm.
We tested the relationship between four
different importance distributions: uni-
form, our proposed importance function,
the loss func-
tion as impor-
tance Katharopou-
los and Fleuret
(2017), and
the work by
Katharopoulos
and Fleuret (2018)
using an other gradient norm bound. The inline figure
plots the L
2
difference between these importance
distributions and the ground-truth gradient-norm
distribution across epochs for an MNIST classifica-
tion task. It shows that Our IS distribution has the
smallest difference, i.e., it achieves high accuracy
while requiring only a small part of the gradient.
For some specific task when the output layer has
predictable shape, it is possible to derive a closed
form definition of the proposed importance metric.
Supplemental document derives the close form im-
portance for classification task using cross entropy
loss.
Note that any importance heuristic can be used
on line 12 of Algorithm 1, such as the gradi-
ent norm Zhao and Zhang (2015); Needell et al.
(2014); Wang et al. (2017); Alain et al. (2015), the
loss Loshchilov and Hutter (2015); Katharopoulos
and Fleuret (2017); Dong et al. (2021), or more ad-
vanced importance Katharopoulos and Fleuret (2018).
For efficiency, our importance function reuses the
forward-pass computations from line 8, updating q
only for the current mini-batch samples.
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
404

5 MULTIPLE IMPORTANCE
SAMPLING
The parameter gradient ∇L
θ
is vector with dimension
equal to the number of model parameters. The in-
dividual parameter derivatives vary uniquely across
the data points, and estimation using a single distri-
bution (Section 4) inevitably requires making a trade-
off, e.g., only importance sampling the overall gradi-
ent magnitude. Truly minimizing the estimation error
requires estimating each derivative using a separate
importance sampling distribution tailored to its varia-
tion. However, there are two practical issues with this
approach: First, it would necessitate sampling from
all of these distributions, requiring “mini-batches” of
size equal at least to the number of parameters. Sec-
ond, it would lead to significant computation waste,
since backpropagation computes all parameter deriva-
tives but only one of them would be used per data
sample. To address this issue, we propose using a
small number of distributions, each tailored to the
variation of a parameter subset, and combining all
computed derivatives into a low-variance estimator,
using multiple importance sampling theory. As an ex-
ample, Fig. 1d shows three sampling distributions for
a simple classification task, based on the derivatives
of the network’s output nodes, following the bound-
ary of each class.
MIS Gradient Estimator. Combining multiple
sampling distributions into a single robust estimator
has been well studied in the Monte Carlo rendering
literature. The best known method is multiple impor-
tance sampling (MIS) Veach (1997). In our case of
gradient estimation, the MIS estimator takes for form
⟨∇L
θ
⟩
MIS
=
J
∑
j=1
n
j
∑
i=1
w
j
(x
i j
)
∇L (m(x
i j
,θ),y
i j
)
n
j
p
j
(x
i j
)
, (5)
where J is the number of sampling distributions, n
j
the number of samples from distribution j, and x
i j
the
i
th
sample from the j
th
distribution. Each sample is
modulated by a weight w
j
(x
i j
); the estimator is unbi-
ased as long as
∑
J
j=1
w
j
(x) = 1 for every data point x
in the dataset.
Optimal Weighting. Various MIS weighting func-
tions w
j
have been proposed in literature, the
most universally used one being the balance heuris-
tic Veach (1997). In this work we use the recently
derived optimal weighting scheme Kondapaneni et al.
(2019) which minimizes the estimation variance for a
given set of sampling distributions p
j
:
w
j
(x) = α
j
p
j
(x)
∇L (m(x,θ),y)
+
n
j
p
j
(x)
∑
J
k=1
n
k
p
k
(x)
1 −
∑
J
k=1
α
k
p
k
(x)
∇L (m(x,θ),y)
!
. (6)
Here, α
α
α = [α
1
,...,α
J
] is the solution to the linear sys-
tem
A
A
Aα
α
α = b
b
b, with
a
j,k
=
Z
Ω
p
j
(x)p
k
(x)
∑
J
i
n
i
p
i
(x)
d(x,y),
b
j
=
Z
Ω
p
j
(x)∇L (m(x,θ), y)
∑
J
i
n
i
p
i
(x)
d(x,y),
(7)
where a
j,k
and b
j
are the elements of the matrix A
A
A ∈
R
J×J
and vector b
b
b ∈ R
J
respectively.
Instead of explicitly computing the optimal
weights in Eq. (6) using Eq. (7) and plugging them
into the MIS estimator (5), we can use a shortcut eval-
uation that yields the same result Kondapaneni et al.
(2019):
⟨∇L
θ
⟩
OMIS
=
J
∑
j=1
α
j
. (8)
In Supplemental document we provide an
overview of MIS and the aforementioned weight-
ing schemes. Importantly for our case, the widely
adopted balance heuristic does not bring practical ad-
vantage over single-distribution importance sampling
(Section 4) as it is equivalent to sampling from a mix-
ture of the given distributions; we can easily sample
from this mixture by explicitly averaging the distri-
butions into a single one. In contrast, the optimal
weights are different for each gradient dimension as
they depend on the gradient value.
Practical Algorithm. Implementing the optimal-
MIS estimator (8) amounts to drawing n
j
samples
from each distribution, computing α
α
α for each dimen-
sion of the gradient and summing its elements. The
integrals in A
A
A and b
b
b (sums in the discrete-dataset case)
can be estimated as ⟨A
A
A⟩ and ⟨b
b
b⟩ from the drawn sam-
ples, yielding the estimate ⟨α
α
α⟩ = ⟨A
A
A⟩
−1
⟨b
b
b⟩.
Algorithm 2 shows a complete gradient-descent
algorithm. The main differences with Algorithm 1
are the use of multiple importance distributions q
q
q =
{q
j
}
J
j=1
(line 5) and the linear system used to com-
pute the OMIS estimator (line 6). This linear system
is updated (lines 15-18) using the mini-batch samples
and solved to obtain the gradient estimation (line 22).
Since the matrix ⟨A
A
A⟩ is independent of the gradient
estimation (see Eq. (7)), its inversion can be shared
across all parameter estimates.
Multiple Importance Sampling for Stochastic Gradient Estimation
405
Algorithm 2: Optimal multiple importance sampling SGD.
1: θ ← random parameter initialization
2: B ← mini-batch size, J ← number of pdf
3: N = |Ω| ← dataset size
4: n
j
← sample count per technique, for j ∈ {1,..J}
5: q
q
q,θ ← InitializeMIS(x, y,Ω, θ,B) ← see Supplemental
6: ⟨A
A
A⟩ ← 0
J×J
,⟨b
b
b⟩ ← 0
J
← OMIS linear system
7: until convergence do ← Loop over epochs
8: for t ← 1 to N/B ← Loop over mini-batches
9: ⟨A
A
A⟩ ← β⟨A
A
A⟩,⟨b
b
b⟩ ← β⟨b
b
b⟩
10: for j ← 1 to J ← Loop over distributions
11: p
j
← q
j
/sum(q
j
)
12: x, y ← B data samples {x
i
,y
i
}
n
j
i=1
∝ p
j
13: L (x) ← L (m(x, θ),y)
14: ∇L (x) ← Backpropagate(L (x))
15: S(x) ←
∑
J
k=1
n
k
p
k
(x)
16: W
W
W ←
n
i
p
i
(x)
/
∑
J
k=1
n
k
p
k
(x)
↰
Momentum estim.
17: ⟨A
A
A⟩ ← ⟨A
A
A⟩ + (1 − β)
∑
n
j
i=1
W
W
W
i
W
W
W
T
i
18: ⟨b
b
b⟩ ← ⟨b
b
b⟩ + (1 − β)
∑
n
j
i=1
∇L (x
i
)
W
W
W
i
/S(x
i
)
19: q
q
q(x) ← αq
q
q(x) + (1 − α)
∂L (x)
∂m(x,θ)
20:
21: ⟨α
α
α⟩ ← ⟨A
A
A⟩
−1
⟨b
b
b⟩
22: ⟨∇L
θ
⟩
OMIS
←
∑
J
j=1
⟨α
j
⟩
23: θ ← θ − η ⟨∇L
θ
⟩
OMIS
← SGD step
24:
25: return θ
Figure 2: Convergence comparison of polynomial regres-
sion of order 6 using different method. Exact gradient show
a gradient descent as baseline and classical SGD. For our
method, we compare importance sampling and OMIS using
n = 2 or 4 importance distributions. Balance heuristic MIS
is also visible. Our method using OMIS achieve same con-
vergence as exact gradient.
Momentum-Based Linear-System Estimation. If
the matrix estimate ⟨A
A
A⟩ is inaccurate, its inversion can
be unstable and yield a poor gradient estimate. The
simplest way to tackle this problem is to use a large
number of samples per distribution, which produces a
accurate estimates of both A
A
A and b
b
b and thus a stable
solution to the linear system. However, this approach
is computationally expensive. Instead, we keep the
sample counts low and reuse the estimates from previ-
ous mini-batches via momentum-based accumulation,
shown in lines 17–18, where β is the parameter con-
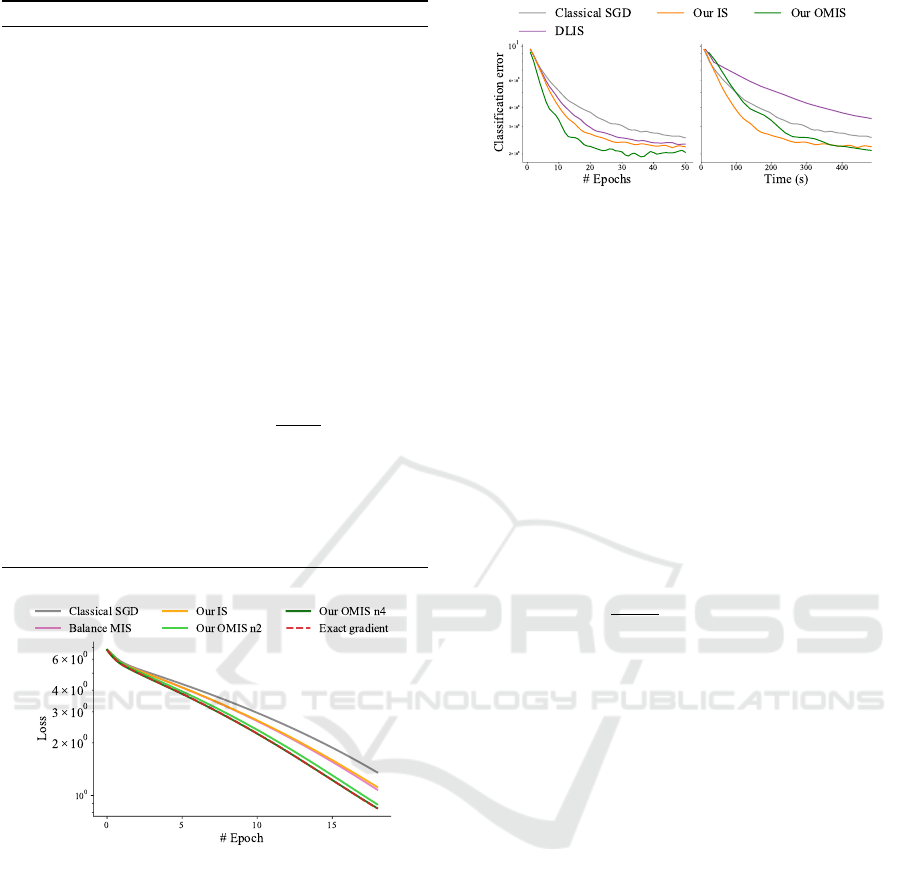
Figure 3: Classification error convergence for MNIST clas-
sification for various methods. Both Katharopoulos and
Fleuret (2018) (DLIS) and resampling SGD approach. In
comparison, our two method use the presented algorithm
without resampling. It is visible that while DLIS perform
similarly to our IS at equal epoch, the overhead of the
method makes ours noticeably better at equal time for our
IS and OMIS.
trolling the momentum; we use β = 0.7. This accu-
mulation provides stability, yields an estimate of the
momentum gradient Rumelhart et al. (1986), and al-
lows us to use 1–4 samples per distribution in a mini-
batch.
Importance functions. To define our importance
distributions, we expand on the approach from Sec-
tion 4. Instead of taking the norm of the entire output
layer of the model, we take the different gradients sep-
arately as q
q
q(x) =
∂L (x)
∂m(x,θ)
(see Fig. 1d). Similarly to Al-
gorithm 1, we apply momentum-based accumulation
of the per-data importance (line 19 in Algorithm 2). If
the output layer has more nodes than the desired num-
ber J of distributions, we select a subset of the nodes.
Many other ways exist to derive the distributions, e.g.,
clustering the nodes into J groups and taking the norm
of each; we leave such exploration for future work.
6 EXPERIMENTS
Implementation Details. We evaluate our impor-
tance sampling (IS) and optimal multiple importance
sampling (OMIS) methods on a set of classifica-
tion and regression tasks with different data modal-
ities (images, point clouds). We compare them to
classical SGD (which draws mini-batch samples uni-
formly without replacement), DLIS Katharopoulos
and Fleuret (2018), and LOW Santiago et al. (2021).
DLIS uses a resampling scheme that samples an ini-
tial, larger mini-batch uniformly and then selects a
fraction of them for backpropagation and a gradient
step. This resampling is based on an importance sam-
pling metric computed by running a forward pass for
each initial sample. LOW applies adaptive weighting
to uniformly selected mini-batch samples to give im-
portance to data with high loss. All reported metrics
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
406
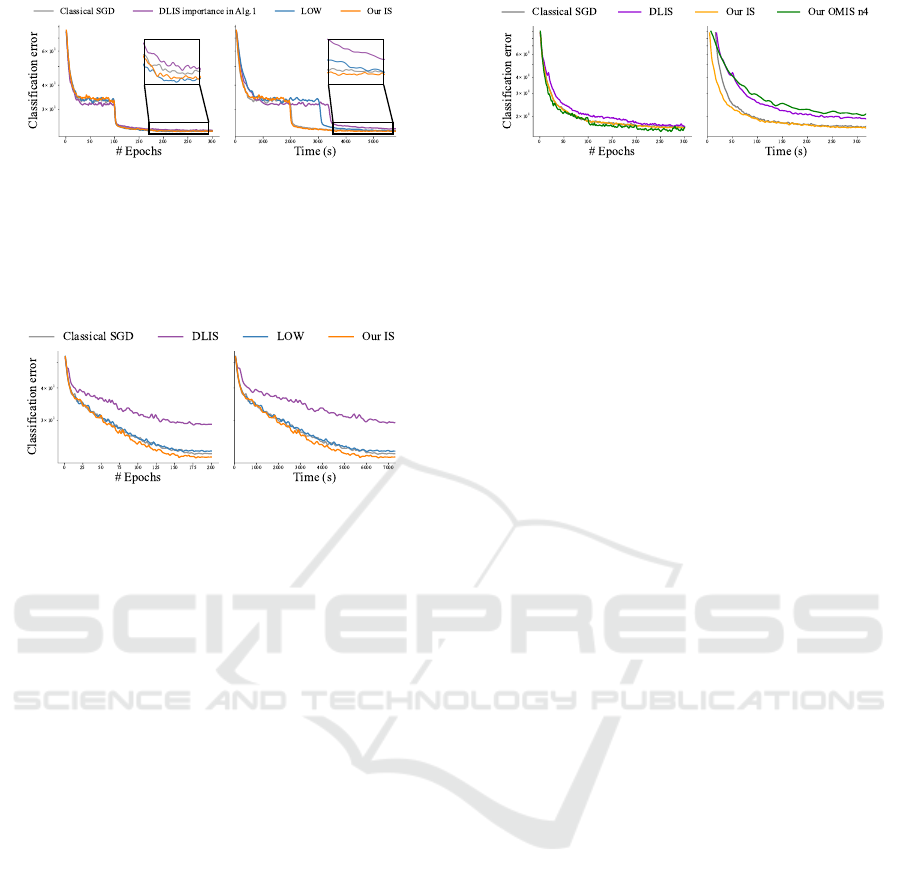
Figure 4: On CIFAR-100, we use the DLIS importance met-
ric in our Algorithm 1 instead of the DLIS resampling al-
gorithm. The zoom-in highlights show error drops when
the learning rate decreases after epoch 100. Our method
(Our IS) outperforms LOW Santiago et al. (2021) and DLIS
weights at equal epochs (left). It also converges faster than
LOW and DLIS weights at equal time (right).
Figure 5: Comparisons on CIFAR-10 using Vision Trans-
former (ViT) Dosovitskiy et al. (2020). The results show
our importance sampling scheme (Our IS) can improve
over classical SGD, LOW Santiago et al. (2021) and
DLIS Katharopoulos and Fleuret (2018) on modern trans-
former architecture.
are computed on data unseen during training, with the
exception of the regression tasks.
All experiments are conducted on a single
NVIDIA Tesla A40 graphics card. Details about the
optimization setup of each experiment can be found
in Supplemental document.
Convex Problem. We performed a basic con-
vergence analysis of IS and OMIS on a convex
polynomial-regression problem. Figure 2 compares
classical SGD, our IS, and three MIS techniques: bal-
ance heuristic Veach (1997) and our OMIS using two
and four importance distributions. The exact gradi-
ent serves as a reference point for optimal conver-
gence. Balance-heuristic MIS exhibits similar con-
vergence to IS. This can be attributed to the weights
depending solely on the relative importance distribu-
tions, disregarding differences in individual param-
eter derivatives. This underscores the unsuitability
of the balance heuristic as a weighting method for
vector-valued estimation. Both our OMIS variants
achieve convergence similar to that of the exact gra-
dient. The four-distribution variant achieves the same
quality as the exact gradient using only 32 data sam-
ples per mini-batch. This shows the potential of
OMIS to achieve low error in gradient estimation even
at low mini-batch sizes.
Figure 6: Comparison of our two methods (Our IS, Our
OMIS) on point-cloud classification using PointNet Qi et al.
(2017) architecture. Our OMIS achieves lower classifica-
tion error at equal epochs, though it introduces computation
overhead as shown at equal-time comparisons. At equal
time, our method using importance sampling achieves the
best performance.
Classification. In Fig. 3, we compare our al-
gorithms to the DLIS resampling algorithm of
Katharopoulos and Fleuret (2018) on MNIST classi-
fication. Our IS performs slightly better than DLIS,
and our OMIS does best. The differences between our
methods and the rest are more pronounced when com-
paring equal-time performance. DLIS has a higher
computational cost as it involves running a forward
pass on a large mini-batch to compute resampling
probabilities. Our OMIS requires access to the gra-
dient of each mini-batch sample; obtaining these gra-
dients in our current implementation is inefficient due
to technical limitations in the optimization framework
we use (PyTorch). Nevertheless, the method manages
to make up for this overhead with a higher-quality
gradient estimate. In Fig. 3 we compare classifica-
tion error; loss-convergence plots are shown in Sup-
plemental document.
In Fig. 4, we compare our IS against using
the DLIS importance function in Algorithm 1 and
LOW Santiago et al. (2021) on CIFAR-100 classifi-
cation. At equal number of epochs, the difference be-
tween the methods is small (see close-up view). Our
IS achieves similar classification accuracy as LOW
and outperforms the DLIS variant. At equal time the
difference is more important as our method has lower
computational cost. This experiment shows that our
importance function achieves better performance than
that of DLIS within the same optimization algorithm.
Figure 5 shows a similar experiment on CIFAR-10
using a vision transformer Dosovitskiy et al. (2020).
Our IS method achieves consistent improvement over
the state of the art. The worse convergence of (orig-
inal, resampling-based) DLIS can be attributed to its
resampling tending to exclude some training data with
very low importance, which can cause overfitting.
Figure 6 shows point-cloud classification, where
our IS is comparable to classical SGD and our OMIS
outperforms other methods in terms of classification
error at equal epochs. In complex cases where impor-
Multiple Importance Sampling for Stochastic Gradient Estimation
407
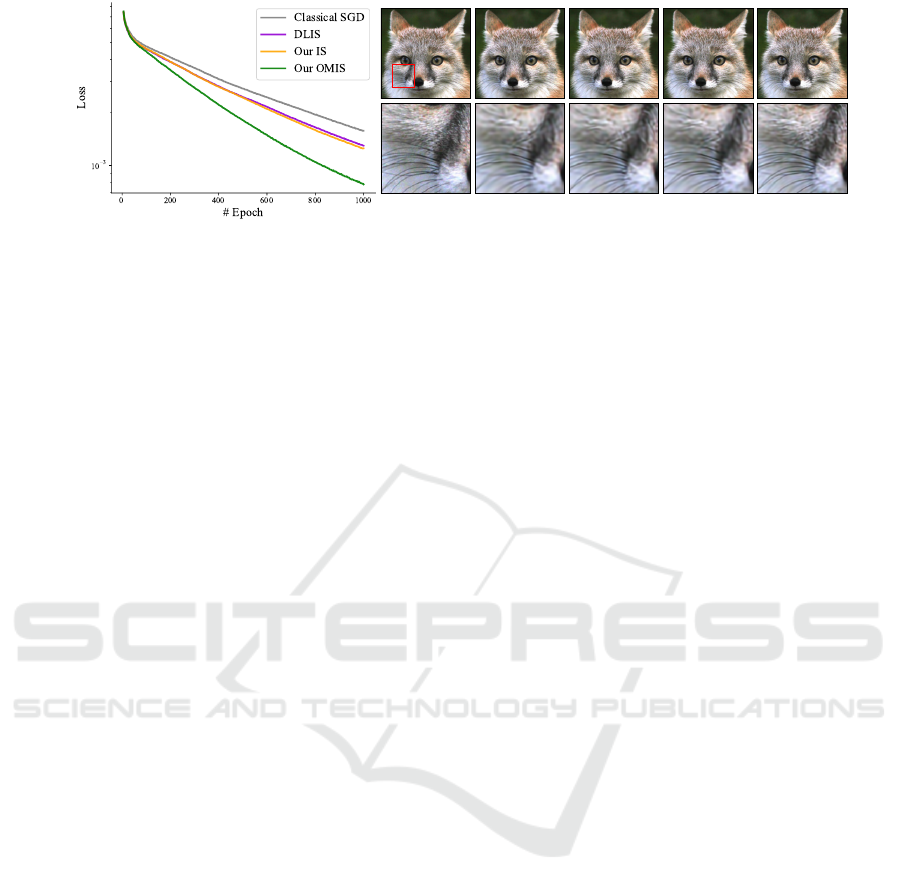
Reference Uniform DLIS Our IS Our OMIS
Figure 7: Comparison at equal step for image 2D regression. Left side show the convergence plot while the right display the
result regression and a close-up view. Our method using MIS achieves the lower error on this problem while IS and DLIS
perform similarly. On the images it is visible that our OMIS recover the finest details of the fur and whiskers.
tance sampling cannot enhance convergence by pro-
viding a more accurate gradient estimator, our method
is still as efficient as SGD due to minimal overhead.
This means that even though importance sampling
does not offer additional benefits in these scenarios,
our implementation remains competitive with classi-
cal methods. In his case DLIS and our OMIS both
suffer from computational overhead.
Regression. Figure 7 shows results on image re-
gression, comparing classical SGD, DLIS, and our
IS and OMIS. Classical SGD yields a blurry image,
as seen in the zoom-ins. DLIS and our IS meth-
ods achieves similar results, with increased whisker
sharpness but still blurry fur, though ours has slightly
lower loss and is computationally faster, as discussed
above. Our OMIS employs three sampling distribu-
tions based on the network’s outputs which represent
the red, green and blue image channels. This method
achieves the lowest error and highest image fidelity,
as seen in the zoom-in.
7 LIMITATIONS AND FUTURE
WORK
We have showcased the effectiveness of importance
sampling and optimal multiple importance sampling
(OMIS) in machine-learning optimization, leading to
a reduction in gradient-estimation error. Our current
OMIS implementation incurs some overhead as it re-
quires access to individual mini-batch sample gradi-
ents. Modern optimization frameworks can efficiently
compute those gradients in parallel but only return
their average. This is the main computational bottle-
neck in the method. The overhead of the linear system
computation is negligible; we have tested using up to
10 distributions.
Our current OMIS implementation is limited to
sequential models; hence its absence from our ViT
experiment in Fig. 5. However, there is no inherent
limitation that would prevent its use with such more
complex architectures. We anticipate that similar im-
provements could be achieved, but defer the explo-
ration of this extension to future work.
In all our experiments we allocate the same sam-
pling budget to each distribution. Non-uniform sam-
ple distribution could potentially further reduce esti-
mation variance, especially if it can be dynamically
adjusted during the optimization process.
Recent work from Santiago et al. (2021) has ex-
plored a variant of importance sampling that forgoes
sample-contribution normalization, i.e., the division
by the probability p(x) in Eq. (3) (and on line 10 of
Algorithm 1). This heuristic approach lacks proof of
convergence but can achieve practical improvement
over importance sampling in some cases. We include
a such variant of our IS method in Supplemental doc-
ument.
8 CONCLUSION
This work proposes a novel approach to improve
gradient-descent optimization through efficient data
importance sampling. We present a method incorpo-
rates a gradient-based importance metric that evolves
during training. It boasts minimal computational
overhead while effectively exploiting the gradient of
the network output. Furthermore, we introduce the
use of (optimal) multiple importance sampling for
vector-valued, gradient estimation. Empirical evalu-
ation on typical machine learning tasks demonstrates
the tangible benefits of combining several importance
distributions in achieving faster convergence.
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
408

REFERENCES
Alain, G., Lamb, A., Sankar, C., Courville, A., and Bengio,
Y. (2015). Variance reduction in sgd by distributed im-
portance sampling. arXiv preprint arXiv:1511.06481.
Alfarra, M., Hanzely, S., Albasyoni, A., Ghanem, B., and
Richtarik, P. (2021). Adaptive learning of the optimal
batch size of sgd.
Balles, L., Romero, J., and Hennig, P. (2017). Coupling
adaptive batch sizes with learning rates. In Proceed-
ings of the 33rd Conference on Uncertainty in Artifi-
cial Intelligence (UAI), page ID 141.
Bordes, A., Ertekin, S., Weston, J., and Bottou, L. (2005).
Fast kernel classifiers with online and active learning.
Journal of Machine Learning Research, 6(54):1579–
1619.
Dong, C., Jin, X., Gao, W., Wang, Y., Zhang, H., Wu, X.,
Yang, J., and Liu, X. (2021). One backward from
ten forward, subsampling for large-scale deep learn-
ing. arXiv preprint arXiv:2104.13114.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn,
D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer,
M., Heigold, G., Gelly, S., et al. (2020). An image is
worth 16x16 words: Transformers for image recogni-
tion at scale. arXiv preprint arXiv:2010.11929.
Faghri, F., Duvenaud, D., Fleet, D. J., and Ba, J. (2020).
A study of gradient variance in deep learning. arXiv
preprint arXiv:2007.04532.
Grittmann, P., Georgiev, I., Slusallek, P., and K
ˇ
riv
´
anek,
J. (2019). Variance-aware multiple importance sam-
pling. ACM Trans. Graph., 38(6).
Kahn, H. (1950). Random sampling (monte carlo) tech-
niques in neutron attenuation problems–i. Nucleonics,
6(5):27, passim.
Kahn, H. and Marshall, A. W. (1953). Methods of reduc-
ing sample size in monte carlo computations. Jour-
nal of the Operations Research Society of America,
1(5):263–278.
Katharopoulos, A. and Fleuret, F. (2017). Biased im-
portance sampling for deep neural network training.
ArXiv, abs/1706.00043.
Katharopoulos, A. and Fleuret, F. (2018). Not all sam-
ples are created equal: Deep learning with importance
sampling. In Dy, J. and Krause, A., editors, Pro-
ceedings of the 35th International Conference on Ma-
chine Learning, volume 80 of Proceedings of Machine
Learning Research, pages 2525–2534. PMLR.
Kingma, D. P. and Ba, J. (2014). Adam: A
method for stochastic optimization. arXiv preprint
arXiv:1412.6980.
Kondapaneni, I., V
´
evoda, P., Grittmann, P., Sk
ˇ
rivan, T.,
Slusallek, P., and K
ˇ
riv
´
anek, J. (2019). Optimal mul-
tiple importance sampling. ACM Transactions on
Graphics (TOG), 38(4):37.
Loshchilov, I. and Hutter, F. (2015). Online batch selection
for faster training of neural networks. arXiv preprint
arXiv:1511.06343.
Needell, D., Ward, R., and Srebro, N. (2014). Stochastic
gradient descent, weighted sampling, and the random-
ized kaczmarz algorithm. In Ghahramani, Z., Welling,
M., Cortes, C., Lawrence, N., and Weinberger, K., ed-
itors, Advances in Neural Information Processing Sys-
tems, volume 27. Curran Associates, Inc.
Owen, A. and Zhou, Y. (2000). Safe and effective impor-
tance sampling. Journal of the American Statistical
Association, 95(449):135–143.
Qi, C. R., Su, H., Mo, K., and Guibas, L. J. (2017). Point-
net: Deep learning on point sets for 3d classification
and segmentation. In Proceedings of the IEEE con-
ference on computer vision and pattern recognition,
pages 652–660.
Ren, H., Zhao, S., and Ermon, S. (2019). Adaptive an-
tithetic sampling for variance reduction. In Interna-
tional Conference on Machine Learning, pages 5420–
5428. PMLR.
Rumelhart, D. E., Hinton, G. E., and Williams, R. J. (1986).
Learning representations by back-propagating errors.
nature, 323(6088):533–536.
Santiago, C., Barata, C., Sasdelli, M., Carneiro, G., and
Nascimento, J. C. (2021). Low: Training deep neural
networks by learning optimal sample weights. Pattern
Recognition, 110:107585.
Schaul, T., Quan, J., Antonoglou, I., and Silver, D.
(2015). Prioritized experience replay. arXiv preprint
arXiv:1511.05952.
Veach, E. (1997). Robust Monte Carlo methods for light
transport simulation, volume 1610. Stanford Univer-
sity PhD thesis.
Wang, L., Yang, Y., Min, R., and Chakradhar, S. (2017).
Accelerating deep neural network training with incon-
sistent stochastic gradient descent. Neural Networks,
93:219–229.
Zhang, C.,
¨
Oztireli, C., Mandt, S., and Salvi, G. (2019).
Active mini-batch sampling using repulsive point pro-
cesses. In Proceedings of the AAAI conference on Ar-
tificial Intelligence, volume 33, pages 5741–5748.
Zhang, M., Dong, C., Fu, J., Zhou, T., Liang, J., Liu,
J., Liu, B., Momma, M., Wang, B., Gao, Y., et al.
(2023). Adaselection: Accelerating deep learning
training through data subsampling. arXiv preprint
arXiv:2306.10728.
Zhao, P. and Zhang, T. (2015). Stochastic optimization with
importance sampling for regularized loss minimiza-
tion. In Bach, F. and Blei, D., editors, Proceedings of
the 32nd International Conference on Machine Learn-
ing, volume 37 of Proceedings of Machine Learning
Research, pages 1–9, Lille, France. PMLR.
Multiple Importance Sampling for Stochastic Gradient Estimation
409
