
Comprehensive Feature Selection for Machine Learning-Based Intrusion
Detection in Healthcare IoMT Networks
Muaan Ur Rehman
1 a
, Rajesh Kalakoti
1 b
and Hayretdin Bahs¸i
1,2 c
1
Department of Software Science, Tallinn University of Technology, Tallinn, Estonia
2
School of Informatics, Computing, and Cyber Systems, Northern Arizona University, U.S.A.
Keywords:
Feature Selection, Intrusion Detection, Machine Learning, Internet of Medical Things.
Abstract:
The rapid growth of the Internet of Medical Things (IoMT) has increased the vulnerability of healthcare net-
works to cyberattacks. While Machine learning (ML) techniques can effectively detect these threats, their suc-
cess depends on the quality and quantity of features used for training to improve detection efficiency in IoMT
environments, which are typically resource-constrained. In this paper, we aim to identify the best-performing
feature sets for IoMT networks, as measured by classification performance metrics such as F1-score and accu-
racy, while considering the trade-offs between resource requirements and detection effectiveness. We applied
an ML workflow that benchmarks various filter-based feature selection methods for ML-based intrusion de-
tection. To test and train our binary and multi-class models, we used two well-developed IoMT datasets
(CICIoMT2024 and IoMT-TrafficData). We applied filter-based feature reduction techniques (Fisher Score,
Mutual Information, and Information Gain) for different machine learning models, i.e., Extreme Gradient
Boosting (XGBoost), K-Nearest Neighbors (KNN), Decision Tree (DT), and Random Forest (RF). Our study
demonstrates that 3-4 features can achieve optimal F1-score and accuracy in binary classification, whereas
7-8 features give reasonable performance in most of the multi-class classification tasks across both datasets.
The combination of Information Gain and XGBoost with 15 features provides excellent results in binary and
multi-class classification settings. Key features—protocol types, traffic metrics, temporal patterns, and statis-
tical measures—are essential for accurate IoMT attack classification.
1 INTRODUCTION
The Internet of Medical Things (IoMT) is an intercon-
nected network of sensors, wearable and medical de-
vices, and clinical systems, enabling applications like
remote monitoring, fitness tracking, chronic disease
management, and elderly care while enhancing treat-
ment quality, lowering costs, and facilitating prompt
responses (Islam et al., 2015),(Dimitrov, 2016).
The security of IoMT is very crucial due to its role
in healthcare, where sensitive patient data and criti-
cal medical systems are increasingly interconnected.
IoMT devices are often targets of cyberattacks, pos-
ing risks to patient safety and data privacy (Kondeti
and Bahsi, 2024). Intrusion detection systems (IDS)
are essential to monitor and detect malicious activi-
ties, ensuring the reliability and security of these net-
works. Machine learning (ML) is vital for IDS in
a
https://orcid.org/0009-0000-2656-0127
b
https://orcid.org/0000-0001-7390-8034
c
https://orcid.org/0000-0001-8882-4095
IoMT as it can identify complex attack patterns and
adapt to evolving threats. However, IoMT devices
have limited computational resources, making it es-
sential to reduce data dimensions and select the most
relevant features to ensure that ML-based IDS oper-
ates efficiently and effectively without overburdening
the network. We applied filter-based feature reduc-
tion techniques (Fisher Score, Mutual Information,
and Information Gain) for different machine learn-
ing models, i.e., XGBoost, KNN, Decision Tree, and
Random Forest. present an analysis by utilising two
benchmarking IoMT datasets CICIoMT2024 (Dad-
khah et al., 2024) and IoMT-TrafficData (Areia et al.,
2024) for training and testing our models. We ap-
plied filter-based feature reduction techniques (Fisher
Score, Mutual Information, and Information Gain)
for different machine learning models, i.e., XGBoost,
KNN, Decision Tree, and Random Forest.
We evaluate the proposed model in terms of F1
score by focusing on both binary classification and
multiclassification. Binary classification aims to dis-
248
Rehman, M. U., Kalakoti, R. and Bah¸si, H.
Comprehensive Feature Selection for Machine Learning-Based Intrusion Detection in Healthcare IoMT Networks.
DOI: 10.5220/0013313600003899
In Proceedings of the 11th International Conference on Information Systems Security and Privacy (ICISSP 2025) - Volume 2, pages 248-259
ISBN: 978-989-758-735-1; ISSN: 2184-4356
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

tinguish between benign and malicious traffic, pro-
viding a high-level detection mechanism, while multi-
class classification goes further by categorizing traffic
into specific attack types, enabling a granular under-
standing of threats. The CICIoMT2024 dataset in-
cludes traffic data for 18 types of cyberattacks (19
classes including benign traffic) grouped into five
main categories (6 classes): DDoS, DoS, Reconnais-
sance, MQTT, and Spoofing. Similarly, the IoMT-
TrafficData dataset comprises eight distinct cyberat-
tack types, including Denial of Service, ARP Spoof-
ing, and Network Scanning, alongside benign traffic,
resulting in a 9-class classification problem.
Additionally, we evaluated the classification per-
formance (accuracy, precision, recall, and F1) of the
best-performing model, XGBoost, on both datasets,
utilizing the top 15 features identified through the In-
formation Gain (IG) feature selection. Furthermore,
to address these security challenges, this study exam-
ines key network features within both datasets that are
essential for identifying and classifying cyber-attacks
in IoMT. Both datasets use network flow features ex-
tracted from benign and malicious traffic. Specifi-
cally, we focus on features, such as protocol type, traf-
fic volume metrics, temporal patterns, and statistical
attributes, in network flows to understand their role in
distinguishing normal and attack traffic patterns.
There exists a line of research on feature selec-
tion for ML-based intrusion detection in IoT devices
(Kalakoti et al., 2022; Bahs¸i et al., 2018). How-
ever, these studies present benchmarking results for
IoT networks that include consumer IoT devices. It
is necessary to understand the impact of feature se-
lection and the best-performing features in IoMT net-
works, as benign traffic profiles and system compo-
nents in these networks have distinct properties when
compared to other IoT devices.
By highlighting critical features across IoMT
datasets, this study contributes to more robust,
feature-driven methods for accurate anomaly and at-
tack detection in IoMT environments, ultimately aim-
ing to strengthen the security and reliability of these
healthcare networks. The uniqueness of our work
is that we have conducted a cross-analysis between
two well-developed datasets, which were released re-
cently, to obtain more generalized findings regarding
the best-performing features in IoMT networks. Our
work puts a particular emphasis on feature selection in
multi-class classification settings, which has not been
elaborated well in the literature.
This paper is structured as follows. Section 2 re-
views the related research. Section 3 presents the
methodology used in our feature selection process. In
Section 4, we show and discuss our results. Finally,
Section 5 concludes the paper and discusses future di-
rections.
2 RELATED WORK
In the literature, various papers employ different fea-
ture selection techniques for machine learning-based
attack classification. Some studies have adopted a fil-
ter approach to identify the best feature subsets, while
others have applied wrapper or embedded methods.
A few works combined both filter and wrapper tech-
niques to determine the optimal feature set. This sec-
tion provides a comprehensive review of the state-
of-the-art methods for feature selection in machine
learning-based intrusion detection systems, as re-
ported in the literature. In (Khammassi and Krichen,
2017), a Genetic Algorithm (GA) combined with a
Logistic Regression (LR) wrapper was applied to the
UNSW-NB15 and KDDCup99 datasets. Using 20
features from UNSW-NB15, the GA-LR method with
a Decision Tree (DT) classifier achieved 81.42% ac-
curacy and a false alarm rate (FAR) of 6.39%. For
KDDCup99, it achieved 99.90% accuracy with 18
features. In (Osanaiye et al., 2016), a filter-based
approach using Information Gain, Chi-Square, and
Relief was applied for Distributed Denial of Service
(DDoS) detection on the NSL-KDD dataset. Using 13
features, the DT classifier reached 99.67% accuracy
and a FAR of 0.42%. The work in (Ambusaidi et al.,
2016) introduced a filter-inspired reduction approach
with Flexible Mutual Information (FMI) and Least
Square SVM (LS-SVM), achieving 99.94% accuracy
on NSL-KDD with 18 features. In (Ingre and Yadav,
2015), a filter-based feature reduction method for IDS
using correlation and DT was applied to NSL-KDD,
reducing the feature set to 14 attributes and achiev-
ing 83.66% accuracy for multiclass classification. In
(Alazzam et al., 2020), the Pigeon Inspired Opti-
mizer (PIO) was used for feature reduction on mul-
tiple datasets. The Sigmoid and Cosine PIO methods
selected features with accuracy rates between 86.9%
and 96.0%.
Janarthanan and Zargari (Janarthanan and Zargari,
2017) implemented various feature selection algo-
rithms on UNSW-NB15, selecting optimal subsets
of 5 and 8 features. Using Random Forest (RF),
they achieved up to 81.62% accuracy. Vikash and
Ditipriya (Kumar et al., 2020) applied Information
Gain for feature reduction on UNSW-NB15, select-
ing 22 attributes, and their IDS achieved 57.01% At-
tack Accuracy (AAc) and 90% F-Measure. In (Al-
momani, 2020), PSO, Firefly, Grey Wolf Optimiza-
tion (GO), and GA were used on UNSW-NB15, with
Comprehensive Feature Selection for Machine Learning-Based Intrusion Detection in Healthcare IoMT Networks
249

a 30-feature subset yielding 90.48% accuracy with the
J48 classifier. Maajid and Nalina (Khan et al., 2020)
used Random Forest (RF) to rank features on UNSW-
NB15, selecting 11 attributes, with RF achieving
75.56% accuracy. In (Tama et al., 2019), a two-stage
model combining PSO, GA, and Ant Colony Opti-
mization (ACO) on UNSW-NB15 selected 19 fea-
tures, achieving 91.27% accuracy. Some studies have
also used feature selection methods prior to applying
explainable techniques in IoT botnet detection prob-
lems(Kalakoti et al., 2024a; Kalakoti et al., 2024c;
Kalakoti et al., 2024b; Kalakoti et al., 2023).
Zong et al. (Zong et al., 2018) proposed a two-
stage model using Information Gain (IG) for feature
selection on UNSW-NB15, achieving 85.78% accu-
racy. In (Kasongo and Sun, 2020), the authors ap-
plied a filter-based feature selection technique by uti-
lizing the XGboost algorithm on the UNSW-NB15 in-
trusion detection dataset. The results illustrate that
feature selection method based on XGBoost enables
models like DT to improve test accuracy from 88.13%
to 90.85% in the binary classification.
The domain of intrusion detection systems (IDS)
within the Internet of Medical Things (IoMT) has at-
tracted considerable attention in recent years due to
the growing adoption of IoMT devices in healthcare
systems. To protect the security and privacy of sen-
sitive medical data, developing effective IDS is es-
sential. While many researcheres have focused on
IDS for traditional networks, there is a notable lack
of studies dedicated to IDS for the IoMT (Alalhareth
and Hong, 2023a).
Feature selection techniques are crucial for en-
hancing the performance of IDS in the Internet of
Medical Things (IoMT) (Rbah et al., 2022),(Khalil
et al., 2022). These techniques reduce the dimension-
ality of input features while retaining essential infor-
mation (Wagan et al., 2023). Filter-based methods,
like chi-square and Information Gain, evaluate fea-
tures individually based on their contribution to the
target variable (Awotunde et al., 2021). Wrapper-
based methods, such as recursive feature elimination
(RFE), use ML algorithms to iteratively select and re-
move features, assessing their impact on model per-
formance.
Information theory-based feature selection meth-
ods, such as MIFS and MRMR, are commonly used in
fields like intrusion detection for the Internet of Med-
ical Things (IoMT) (G
¨
okdemir and Calhan, 2022).
However, these methods require large datasets to ac-
curately estimate Mutual Information between fea-
tures and the target variable, and limited data can lead
to suboptimal results (Chaganti et al., 2022). Solu-
tions to this issue include data augmentation tech-
niques, like oversampling or synthetic data genera-
tion (Parimala and Kayalvizhi, 2021), and transfer
learning, which applies knowledge from data-rich do-
mains to improve performance in data-limited con-
texts (Awotunde et al., 2021). However, these ap-
proaches come with challenges, such as introducing
bias or noise and increasing computational costs (Al-
Sarem et al., 2021).
In (Alalhareth and Hong, 2023b) authors proposed
an improved Mutual Information feature selection
technique for IDS for the IoMT. This paper proposes a
Logistic Redundancy Coefficient Gradual Upweight-
ing MIFS (LRGU-MIFS) to enhance feature selection
for IDS in the IoMT. LRGU-MIFS improves detec-
tion accuracy by addressing overfitting and non-linear
feature redundancy, outperforming existing methods
in identifying key features.
State-of-the-art IDS systems for IoMT, such
as deep learning models, offer high accuracy but
are computationally intensive and less adaptable to
resource-constrained environments. In contrast, our
integration of feature selection techniques with IDS
significantly reduces computational overhead, en-
hancing suitability for IoMT applications. The stud-
ies on feature selection do not create or compare the
optimal sets achievable for different multiclass prob-
lem formulations. They only focus on one dataset
and derive conclusions. This paper addresses this gap
by inducing various learning models, including var-
ious multi-class classification models, for two well-
developed and comprehensive IoMT datasets (Dad-
khah et al., 2024; Areia et al., 2024) released recently.
These datasets contain a huge number of attack types,
making them convenient for multi-class classification.
This study also conducts a cross-analysis between two
datasets to identify the commonalities.
3 METHODOLOGY
We applied an ML workflow that includes the stages,
data preprocessing, feature selection, and model train-
ing/testing, as demonstrated in Figure 1. In the data
pre-processing stage, we eliminated the correlated
features using Pearson Correlation. We applied filter-
based feature selection methods (i.e., Fisher Score,
Information Gain, Mutual Information) to prioritize
the features. In the last stage, we benchmarked var-
ious ML algorithms (i.e., k-NN, Decision Tree, XG-
Boost, Random Forest) with varying numbers of se-
lected best features determined by filter-based selec-
tion methods.
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
250

Figure 1: We employed filter methods for feature selection on the CICIoMT2024 Dataset (Dadkhah et al., 2024) and IoMT-
TrafficData (Areia et al., 2024) to identify optimal features in IoMT networks. Four classifiers were used for evaluation:
Decision Trees (DT), Random Forest (RF), k-Nearest Neighbors (k-NN), and XGBoost.
3.1 Datasets
We apply feature selection to the CICIoMTDataset
2024 dataset (Dadkhah et al., 2024) and IoMT-
TrafficData (Areia et al., 2024), which focus on Inter-
net of Medical Things devices in the healthcare sector.
These datasets are designed to assess and improve the
cybersecurity of IoMT devices through intrusion de-
tection systems.
The CICIoMT2024 dataset (Dadkhah et al., 2024)
includes traffic generated from 40 devices (25 real,
15 simulated) across multiple protocols like Wi-Fi,
MQTT, and Bluetooth. The authors simulated 18 cy-
berattacks, categorized into five main categories i.e.
DDoS, DoS, Recon, MQTT, and Spoofing.The fea-
tures extracted from the attacks in the CICIoMT2024
dataset include Header Length, Duration, Rate, Srate,
fin flag number, syn flag number, rst flag number, psh
flag number, ack flag number, ece flag number, cwr
flag number, syn count, ack count, fin count, rst count,
IGMP, HTTPS, HTTP, Telnet, DNS, SMTP, SSH,
IRC, TCP, UDP, DHCP, ARP, ICMP, IPv, LLC, Tot
sum, Min, Max, AVG, Std, Tot size, IAT, Number, Ra-
dius, Magnitude, Variance, Covariance, Weight, and
Protocol Type.
The IoMT-TrafficData dataset (Areia et al., 2024)
is a comprehensive collection of network traffic data.
It includes both benign and malicious traffic gener-
ated from eight different types of cyberattacks i.e.
Denial of Service (DoS), Distributed Denial of Ser-
vice (DDoS), ARP Spoofing, CAM Table Overflow,
MQTT Malaria, Network Scanning, Bluetooth Re-
connaissance, and Bluetooth Injection. The identi-
fied key features in the IP-based flows in the IoMT-
TrafficData dataset cover various aspects of network
communication. Protocol features include proto and
service, which identify the transport and application
protocols in use. Payload and packet metrics such
as orig bytes, resp bytes, orig pkts, and resp pkts
detail the volume and direction of data exchanged.
Flow characteristics, including flow duration and
history, capture the overall session duration and
connection state transitions. Packet directional-
ity is covered by fwd pkts tot and bwd pkts tot
for packet counts, and by fwd pkts payload and
bwd pkts payload for payload bytes in each direction.
Rate metrics (fwd pkts per sec, bwd pkts per sec,
and flow pkts per sec) provide packet transmission
rates, while inter-arrival time features (fwd iat,
bwd iat, and flow iat) and active duration (active) re-
flect timing characteristics within the flow.
In this work, we used person correlation as the
preprocessing step. The Pearson correlation coeffi-
cient, given by the equation (1) ,is used to compute the
linear correlation between two variables. This tech-
nique involves calculating the collinearity matrix for
all features to identify redundancy. The Pearson cor-
relation coefficient P ranges from -1 to 1, where P = 1
indicates perfect positive correlation, P = 0 indicates
no correlation, and P = −1 indicates perfect negative
correlation. The formula for Pearson’s correlation is:
P =
∑
n
i=1
(x
i
− µ
x
)(y
i
− µ
y
)
p
∑
n
i=1
(x
i
− µ
x
)
2
·
p
∑
n
i=1
(y
i
− µ
y
)
2
(1)
Here, µ
x
and µ
y
represent the means of features x
and y, respectively. Greater absolute values of P in-
dicate a stronger linear relationship between the fea-
tures.
3.2 Feature Selection Methods
Irrelevant features for classification problems are re-
duced to decrease the running time and improve
the classification accuracy of machine learning algo-
rithms. Feature selection methods are divided into
three categories: wrapper, filter, and embedded tech-
niques (Jovi
´
c et al., 2015). Wrapper methods itera-
tively evaluate subsets of features using a machine
Comprehensive Feature Selection for Machine Learning-Based Intrusion Detection in Healthcare IoMT Networks
251

learning algorithm, but they can be computationally
intensive for high-dimensional data. In contrast, fil-
ter methods rank features independently of the learn-
ing algorithm, which may result in suboptimal selec-
tions due to the lack of guidance. To reduce compu-
tational complexity, we opted for filter-based meth-
ods, which are highly efficient and well-suited for
resource-constrained IoMT environments. The fol-
lowing three primary filter-based feature methods are
commonly employed for numeric-based feature inter-
class and intra-class separation analysis and entropy-
based methods as described below.
3.2.1 Fisher Score
The Fisher Score, also known as Fisher’s ratio, mea-
sures the ratio of inter-class separation to intra-class
separation for numeric features (Gu et al., 2012). The
Fisher Score F
s
is formally defined in equation 2 as:
F
s
=
∑
K
j=1
p
j
(µ
i j
− µ
i
)
2
∑
K
j=1
p
j
σ
2
i j
(2)
Where µ
i j
and σ
i j
represent the mean and standard
deviation of the j-th class and i-th feature, while p
j
denotes the proportion of data points in class j. A
higher Fisher Score indicates greater discriminative
power of a feature.
3.2.2 Mutual Information
Mutual Information (MI) quantifies the dependency
between variables (Est
´
evez et al., 2009). For continu-
ous variables, MI is defined as:
I(X ,Y ) =
Z Z
p(x, y)log
p(x, y)
p(x)p(y)
dxdy (3)
For discrete variables, MI is given by:
I(X ;Y ) =
∑
y∈Y
∑
x∈X
p(x, y)log
p(x, y)
p(x)p(y)
(4)
Here, p(x, y) is the joint probability, and p(x),
p(y) are the marginal probabilities. MI values range
as follows:
0 ≤ I(X;Y ) ≤ min{H(X), H(Y )}
To enhance the Mutual Information feature selec-
tion, the following goal function is used:
G = I(C; f
i
) −
1
|S|
∑
f
s
∈S
NI( f
i
; f
s
) (5)
Where I(C; f
i
) is the Mutual Information between
class C and feature f
i
, and S is the set of selected fea-
tures. The algorithm selects features by maximizing
this measure. Function NI( f
i
; f
s
) is the Normalized
Mutual Information between features f
i
and f
s
.
3.2.3 Information Gain
Information Gain helps quantify how much informa-
tion a feature contributes to classification by utilizing
the concept of entropy. It measures the reduction in
dataset entropy after knowing the values of a partic-
ular feature (Velasco-Mata et al., 2021). The initial
entropy of the dataset, H(X), is given by the follow-
ing equation, which is based on the probability p(x)
of a sample belonging to class x. The conditional en-
tropy, H(X|Y ), after knowing the values of feature Y ,
is defined based on the probability p(y) of a sample
having feature value y ∈ Y , and the probability p(x|y)
of a class x sample having feature value y ∈ Y .
H(X) = −
X
∑
x=1
p(x)log(p(x)) (6)
H(X|Y ) = −
∑
y
p(y)
∑
x
p(x|y)log(p(x|y)) (7)
3.3 Machine Learning Work Flow
In our study, we employed four machine learning al-
gorithms for classifying cyberattacks in IoMT net-
work flow data: Decision Tree (DT), Random Forest
(RF), XGBoost (XGB) and K-Nearest Neighbors (K-
NN). Decision Tree (DT) is a non-parametric super-
vised method for classification and regression. DTs
classify data by evaluating attributes at each node
until reaching a decision. Random Forest (RF) is
an ensemble method of decision trees, chosen for
its robustness, ability to manage complex datasets,
and compatibility with diverse features. XGBoost, a
gradient-boosting algorithm, optimizes using second-
order gradients and applies L1/L2 regularization to
reduce overfitting and enhance performance. Its
efficiency, interpretability, and scalability make it
ideal for large datasets. Lastly, K-Nearest Neighbors
(KNN) is a distance-based algorithm for classification
and regression.
Our classification models were evaluated for
IoMT attack detection using confusion matrices for
both binary and multi-class classification. For binary
classification, True positives(TP) (correctly classified
attacks), True negatives (TN) (correctly classified be-
nign traffic), False negatives (FN) (misclassified at-
tacks), and False Positives (FP) (misclassified benign
traffic) were recorded. In this study, we have utilized
the F1 score metric to evaluate distinct subsets of fea-
tures. The F1 score is defined as the harmonic mean
of precision (P) and recall (R). It provides a more ap-
propriate measure of incorrectly classified cases com-
pared to accuracy. We have employed the harmonic
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
252

mean of the F1 score, as it penalizes extreme values.
F1 score =
2 × P × R
P + R
(8)
To train the models in binary classification, we
have taken 5,000 samples of each class label. This
results in a total of 10,000 samples from two labels.
On the other hand, for the multi-class classification
involving different distinct classes, we ensured an
equal number of samples from each label, even for
the classes with fewer instances, to maintain a bal-
anced representation across all attack types. In the
preprocessing step, after applying the Pearson corre-
lation, balanced samples were drawn from the dataset
of interest. Then, the datasets were divided into train-
ing and testing subsets in an 80/20 ratio. For evalu-
ating each feature set with models, Random Search
hyperparameter tuning was used for training the clas-
sification algorithms.
4 RESULTS AND DISCUSSIONS
This study analyzed the discriminatory power of net-
work traffic flow features using filter-based feature
selection techniques, including Fisher Score, Mutual
Information, and Information Gain, for a machine
learning-based intrusion detection function in IoMT
healthcare networks. The analysis was conducted for
binary and multiclass classification tasks on the CI-
CIoMT2024 and IoMT-TrafficData datasets.
First, we applied Pearson’s linear correlation co-
efficient (r) as a data preprocessing step to remove
redundant and irrelevant data features. Any feature
highly correlated with another feature (|r| > 0.80) was
removed, keeping only one. As a result, out of the ini-
tial set of 44 features used to describe each sample in
the dataset, 36 features remained in the final feature
set. After removing the Pearson co-related features,
in IoMT-Traffic dataset, we get 21 features, however,
we also removed is
attack feature as it represent bi-
nary label. The final feature list contains 20 features.
After applying Pearson correlation and excluding
unnecessary features, we applied three filter-based
feature selection methods, i.e., Fisher Score, Mu-
tual Information, and Information Gain. These meth-
ods were used to rank the importance of the re-
maining reduced features. An iterative, stepwise ap-
proach was used to train the ML models for each
filter-based feature selection method (Fisher Score,
Mutual Information, and Information Gain). Start-
ing with the highest-ranked feature, we added one
feature at a time, trained the model, and evaluated
its performance progressively. For example, if the
features were ranked as f = { f
1
, f
2
.. f
n
}, the model
was first trained using only the top-ranked feature
subset { f
1
}, followed by training with { f
1
and f
2
},
then with { f
1
, f
2
, . . . f
n
} This process was repeated
for all (n) ranked features in each method for both
datasets. At each step, we added the next highest-
ranked feature, as determined by the feature selec-
tion method, to the feature set incrementally to as-
sess its impact on the model performance. The per-
formance classifiers—Decision Tree (DT), Random
Forest (RF), K-Nearest Neighbor (KNN), and XG-
Boost (XGB)—were evaluated based on the F1 score
for both binary and multiclass classification tasks.
From the CICIoMT-2024 dataset, Binary clas-
sification was used to differentiate between benign
and attack traffic. Two types of studies were per-
formed for multi-class classification: category-based
and attack-based classification. In the category-based
classification, we identified six categories of network
traffic: benign, MQTT attacks, DDoS, DoS, Recon-
naissance, and ARP spoofing attacks, referred to as
the 6-class classification. In the attack-based classifi-
cation, there were 19 classes, which included various
attack types such as ARP Spoofing, Ping Sweep Scan,
Reconnaissance VulScan, OS Scan, Port Scan, Mal-
formed Data Packets, Connect Flood (DoS), Publish
Flood (DDoS), Publish Flood (DoS), Connect Flood
(DDoS), TCP (DoS), ICMP (DoS), SYN (DoS), UDP
(DoS), SYN (DDoS) , TCP (DDoS) , ICMP (DDoS) ,
and UDP (DDoS). Attack-based detection is referred
to as a 19-class classification.
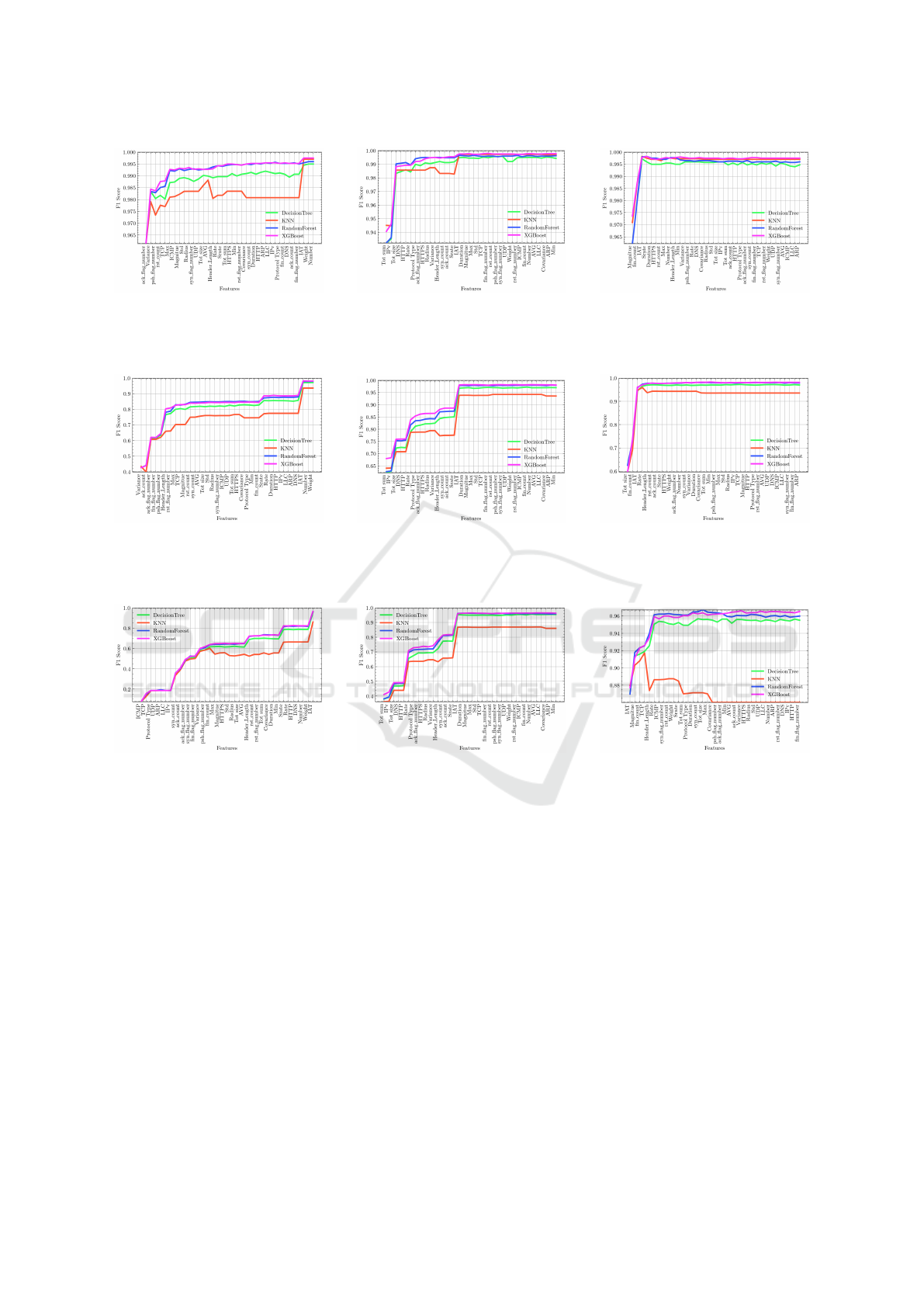
Fig. 2 shows the algorithm’s performance com-
parison using different feature selection methods on
the CICIoMT2024 dataset for binary classification.
Across all three feature selection methods, the clas-
sifiers’ performance rapidly improves by adding the
first few features. However, the performance plateau
shows only marginal improvements as more features
are added. When all 36 features were included,
a small subset of highly informative features had
already achieved high performance across models.
Most classifiers achieved high F1 scores (above 0.99)
with only 5-10 features. Notably, XGB and RF
consistently reached near-optimal performance with
fewer than five features, while DT and KNN demon-
strated more gradual improvements as features were
added, achieving their best results after more features
were incorporated into the model.
Attacks categories (Figure 3) and 19-classes based
classification (Figure 4) show almost the same per-
formance in comparison with binary classification as
XGBoost and Random Forest again perform best, par-
ticularly when fewer features are used. However, Mu-
tual Information demonstrates overall higher model
Comprehensive Feature Selection for Machine Learning-Based Intrusion Detection in Healthcare IoMT Networks
253
(a) Fisher Score (b) Mutual Information (c) Information Gain
Figure 2: Comparison of algorithms performance using Feature selection methods over CICIoMT2024 data set for Binary
Classification.
(a) Fisher Score (b) Mutual Information (c) Information Gain
Figure 3: Comparison of algorithms performance using Feature selection methods over CICIoMT2024 data set for 6-class
Classification.
(a) Fisher Score (b) Mutual Information (c) Information Gain
Figure 4: Comparison of algorithms performance using Feature selection methods over CICIoMT2024 data set for 19-class
Classification.
performance early on, i.e., for the first three features
in binary classification compared to multi-class clas-
sifications. Figure 4 shows that KNN performance
drops dramatically after the first 4 features in the case
of Information Gain. This shows that KNN does
not work well for multi-class classification in the CI-
CIoMT2024 dataset.
From the IoMT-TrafficData dataset, binary classi-
fication was used to differentiate between benign and
attack traffic and multi-class classification was used
to classify the attack traffic further. In the attack-
based classification, there were 9 classes, which in-
cluded 8 different types of cyberattacks i.e. DoS (Ap-
pachekiller, Slowread, Rudeadyet, Slowloris), Dis-
tributed Denial of Service (DDoS), ARP Spoofing,
Buffer Overflow (Camoverflow), MQTT Malaria, and
Network Scanning (Netscan).
Table 1 presents the classification performance re-
port of the XGBoost model on both CICIoMT2024
and IoMT-TrafficData, using selected top-15 features
from Information Gain (IG) feature selection. Both
datasets show excellent binary classification perfor-
mance, with accuracy, precision, recall, and F1-score
around 0.997 for both classes (attack and benign),
indicating strong classification ability. On the CI-
CIoMT2024 dataset, the model performs well across
6 and 19-class classifications, with high accuracy
( 0.977) and consistent metrics, though performance
slightly drops for complex classes like Recon and
ARP Spoofing.
On the IoMT-TrafficData dataset, accuracy re-
mains high at 0.987, with perfect precision and recall
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
254

(a) Fisher Score Features (b) Mutual Information (c) Information Gain
Figure 5: Comparison of algorithms performance using Feature selection methods over IoMT-TrafficData dataset for Binary
Classification.
(a) Fisher Score (b) Mutual Information (c) Information Gain
Figure 6: Comparison of algorithms performance using Feature selection methods over IoMT-TrafficData dataset for Multi-
class classification (9 classes).
Table 1: Classification report of selected top-15 features from Information Gain (IG) feature selection for the CICIoMT2024
dataset & IoMT-TrafficData , using the XGBoost model for all three classification types.
Dataset Classification type Binary 6-Class classification report
CICIoMT2024 dataset
Metric\class Attack Benign Metric\class ARP Spoofing Benign DDoS DoS MQTT Recon
Accuracy 0.997 0.997 Accuracy 0.977 0.977 0.977 0.977 0.977 0.977
Precision 0.999 0.994 Precision 0.918 0.959 0.999 1.000 0.997 0.994
Recall 0.995 0.999 Recall 0.967 0.945 1.000 0.998 0.993 0.962
F1-Score 0.997 0.997 F1-Score 0.942 0.952 1.000 0.999 0.995 0.978
19-Class classification
Metric/Class
ARP
Spoofing
Benign
MQTT-DDoS
-Connect Flood
MQTT-DDoS
-Publish Flood
MQTT-DoS
-Connect Flood
MQTT-DoS
-Publish Flood
MQTT-Malformed
Data
Recon-OS
Scan
Recon-Ping
Sweep
Recon-Port
Scan
Recon-
VulScan
TCP IP-
DDoS-ICMP
TCP IP-
DDoS-SYN
TCP IP-
DDoS-TCP
TCP IP-
DDoS-UDP
TCP IP-
DoS-ICMP
TCP IP-
DoS-SYN
TCP IP-
DoS-TCP
TCP IP-
DoS-UDP
Accuracy 0.967 0.967 0.967 0.967 0.967 0.967 0.967 0.967 0.967 0.967 0.967 0.967 0.967 0.967 0.967 0.967 0.967 0.967 0.967
Precision 0.902 0.931 1.000 1.000 1.000 1.000 0.899 0.870 0.947 0.902 0.915 1.000 0.997 1.000 0.997 1.000 1.000 1.000 1.000
Recall 0.877 0.922 1.000 0.987 0.997 0.997 0.958 0.831 0.967 0.902 0.927 1.000 1.000 1.000 1.000 0.997 0.997 1.000 0.997
F1-Score 0.889 0.926 1.000 0.994 0.998 0.998 0.927 0.850 0.957 0.902 0.921 1.000 0.998 1.000 0.998 0.998 0.998 1.000 0.998
Classification type Binary 9-Class classification report
IoMT-Traffic dataset
Metric\class Attack Benign Metric\class Apachekiller Arpspoofing Camoverflow Mqttmalaria Netscan Normal Rudeadyet Slowloris Slowread
Accuracy 0.997 0.997 Accuracy 0.987 0.987 0.987 0.987 0.987 0.987 0.987 0.987 0.987
Precision 0.997 0.997 Precision 0.993 1.0 1.0 0.996 1.0 0.974 0.982 0.977 0.965
Recall 0.997 0.996 Recall 0.981 0.987 1.0 0.989 1.0 0.993 0.966 0.981 0.997
F1-Score 0.997 0.997 F1-Score 0.987 0.993 1.0 0.993 1.0 0.983 0.974 0.979 0.977
for many attack types (e.g., Camoverflow, Netscan),
but slightly lower performance for some attack classes
like Slowread and Rudeadyet.
Fig. 5 shows the algorithm’s performance com-
parison using different feature selection methods on
the IoMT-TrafficData dataset for binary classification.
Across Mutual Information, the classifiers’ perfor-
mance rapidly improves with the addition of the first
few features. Fisher Score follows the same pattern;
however, it gives a slightly lower Model performance.
Information Gain effectively ranks features by their
usefulness, as the performance improves significantly
with the first few features. XGBoost emerges as the
best-performing classifier, while KNN performance
tends to decrease after the first 5 features. The results
suggest that focusing on the top-ranked features can
optimize classifier performance while reducing com-
putational costs. Figure 6 compares algorithm per-
Comprehensive Feature Selection for Machine Learning-Based Intrusion Detection in Healthcare IoMT Networks
255
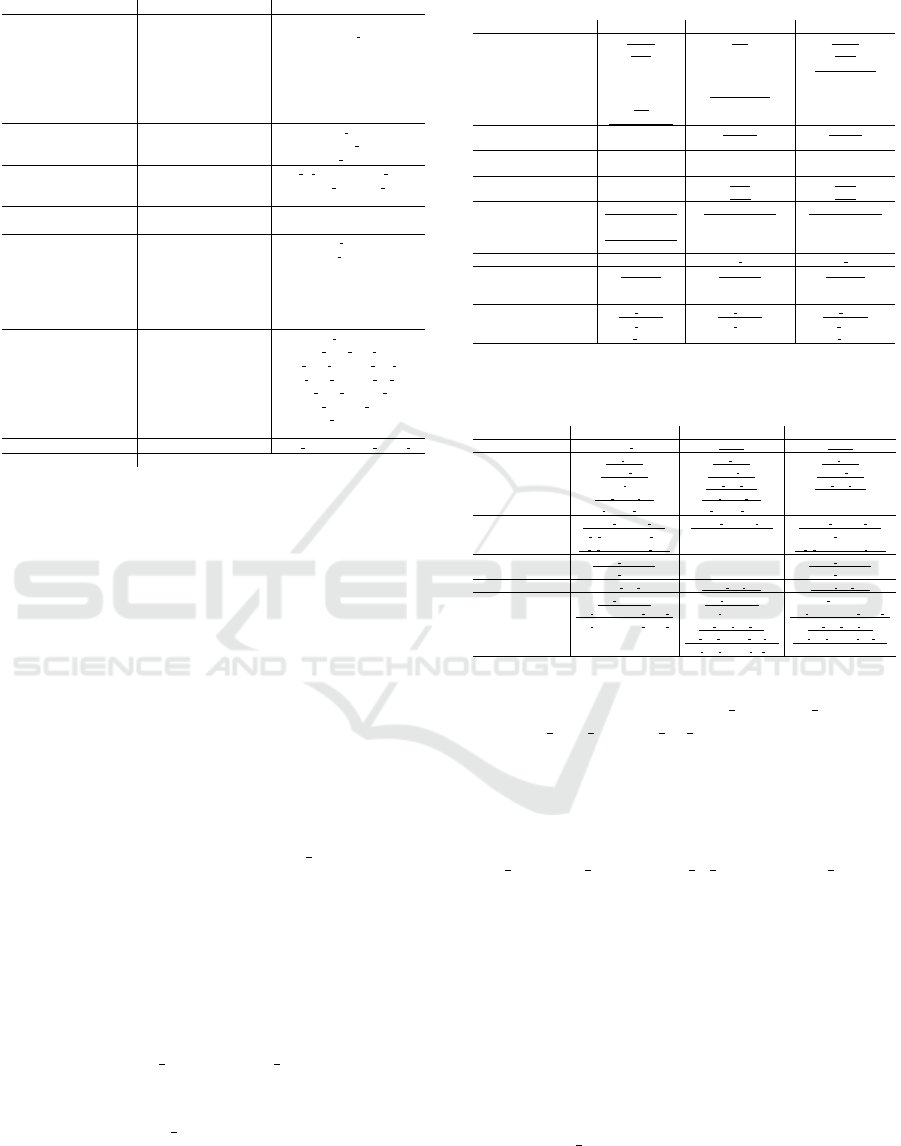
Table 2: Binary classification top 15 best features.
Type of features CICIoMT2024 dataset IoMT-TrafficDat dataset
Protocol
TCP
UDP proto 2
ICMP service
IPv
DNS
HTTP
Protocol Type
HTTPS
Traffic Volume
Tot sum total bytes
Tot size payload ratio
total activity
Temporal metrics
Duration iat is unidirectional True
IAT duration weighted pkts
Packets rate
Rate
srate
Flags
ack flag number history responder
psh flag number hisoty originator
syn flag number
rst count
syn count
ack count
fin count
Other statistical features
Std byte difference
variance fwd bwd pkts diff
Max fwd bwd payload avg diff
Magnitude fwd bwd payload tot diff
Min flow bwd payload diff
Radius flow payload range
AVG pkt difference
Other features Header Length pkts unidirectional traffic 1
‘
formance for multi-class classification (9 classes) on
the IoMT-TrafficData dataset. Performance gradually
improves with the increase in features in the case of
the Fisher Score. However, models obtain higher per-
formance earlier (after four features) in the case of
Mutual Information and Information Gain. All mod-
els show comparable performance across the feature
selection methods, except KNN, which lags behind
when using the Information Gain method.
By examining the important features in both
datasets, it is possible to identify the important net-
work characteristics for attack detection in IoMT traf-
fic. Table 2 illustrates the union of the top 15 fea-
tures selected by different feature selection meth-
ods. The CICIoMT2024 dataset includes transport-
layer protocol features, TCP, and UDP, while the
IoMT-TrafficData dataset uses proto 2, which also
represents transport-layer protocols. Therefore, we
conclude that TCP and UDP are important fea-
tures. Both datasets also emphasize application-
layer protocols, such as HTTP, DNS, and SMTP
(in CICIoMT2024) and service (in IoMT-TrafficData
dataset), which identify application-layer protocols
as well. Tot sum (CICIoMT2024) provides a key
metric to understand traffic volume when consid-
ered alongside total pkts and total bytes in the IoMT-
TrafficData dataset. Flags in CICIoMT2024 directly
capture counts of specific TCP flags, while IoMT-
TrafficData’s history responder encapsulates the se-
quence of connection states, reflecting the flags’ tran-
sitions. Variability measures in packet lengths in a
flow, such as Std and Variance (Ratio of the variances
Table 3: 19-class classification top 15 best features in CI-
CIoMT2024 dataset.
Type of features Fisher Score Mutual information Information Gain
Protocol
ICMP IPv ICMP
TCP DNS TCP
UDP HTTP Protocol type
ARP HTTPS
LLC Protocol type
Ipv
Protocol Type
Traffic Volume
tot sum tot sum
tot size
Temporal metrics
IAT
Duration
Packets rate
Rate Rate
srate srate
Flags
ack flag number ack flag number syn flag number
psh flag number
syn flag number
fin flag number
Header Attributes Header Length Header Length
Other statistical features
Variance Variance Variance
Mangnitude
Weight
Other
syn count syn count syn count
ack count ack count rst count
fin count fin count
Table 4: 9-class classification top 15 best features in IoMT-
TrafficData dataset.
Type of features Fisher Score Mutual information Information Gain
Protocol
proto 2 service service
Traffic Volume
total bytes total bytes total bytes
payload ratio payload ratio payload ratio
total pkts total data pkts total data pkts
total header size total header size
total payload volume total payload volume
Temporal metrics
duration weighted pkts duration weighted pkts duration weighted pkts
iat is unidirectional True total activity
iat is unidirectional False iat is unidirectional False
Flags
history responder history responder
history originator history originator
Header Attributes
header size diff header size ratio header size ratio
Other statistical features
byte difference byte difference pkt difference
pkts unidirectional traffic 1 pkt difference pkts unidirectional traffic 1
pkts unidirectional traffic 0 fwd bwd pkts diff fwd bwd pkts diff
fwd bwd payload avg diff fwd bwd payload avg diff
fwd bwd payload tot diff
of incoming to outgoing packet lengths in the flow) in
CICIoMT2024, along with pkt diff, byte difference
and fwd bwd payload tot diff, which capture the
fluctuations and differences in packet lengths in
IoMT-TrafficData, are essential metrics in identify-
ing anomalies in IoMT networks. Temporal features
such as Duration and IAT (Inter-arrival time) in the
CICIoMT2024 dataset can be compared with dura-
tion weighted pkts and iat is unidirectional False in
the IoMT TrafficData dataset, which provides ad-
ditional directional features, i.e., unidirectional/bi-
directional that enhance understanding of packet ar-
rival patterns.
Table 3 identifies several common features across
Fisher Score, Mutual Information, and Information
Gain methods (selected by at least two methods) for
19-class classification in CICIoMT2024 dataset. Fea-
tures that relate to protocols (ICMP, TCP, Protocol
type), traffic volume (tot sum), packet transmission
rate (Rate, Srate) , flags (ack flag number, syn flag
number, syn count), and statistical properties (vari-
ance), are pivotal for distinguishing patterns and de-
tecting multiple attacks in IoMT traffic, highlighting
their relevance in network security analysis.
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
256

The common important features underlined in Ta-
ble 4 reveal crucial insights into detecting multi-
ple attacks in IoMT-TrafficData dataset for 9-class
classification. In traffic volume, features like to-
tal bytes, payload ratio, total header size, and to-
tal payload volume appear frequently, emphasizing
the significance of overall data transferred and packet
structure. Temporal metrics are also prominent, with
duration weighted pkts, which capture the rate or
proportion of packets over time within a flow, and
iat is unidirectional False, capturing consistency of
IAT with bidirectional traffic flowing traffic. Among
flags, history responder and history originator recur,
reflecting connection state transitions. It should also
be noted that Mutual Information could not grasp
any flag information. The header attribute fea-
ture, header size ratio, refers to the proportion of
the header size relative to the total size of a packet
also highlights the significance of packet header size.
Lastly, statistical features like byte difference (differ-
ence in payload bytes between the originator and re-
sponder), fwd bwd pkts diff (difference in the num-
ber of packets sent forward and backward in the con-
nection), fwd bwd payload avg diff (difference in
average payload size per packet between forward and
backward traffic), and pkts unidirectional traffic 1
(indication of unidirectional traffic) show significance
in multi-class attack classification in IoMT traffic.
The analysis of Figures 2, 3, 4, 5, and 6 reveals
that filter-based methods exhibit excellent perfor-
mance for binary classification across both datasets.
Notably, these models achieve higher performance
levels early on, often after selecting just 3 to 4 features
using information gain for feature selection. This in-
dicates that these methods are effective in differen-
tiating between benign and malicious traffic with a
minimal set of features. As the number of selected
features increases, the models’ performance steadily
improves. Significant accuracy is attained with 7 to 8
features, particularly for multi-class classifications (6-
class, 9-class, and 19-class) using information gain.
Among the evaluated models, the XGBoost model
achieved the highest performance with fewer features
selected through information gain feature selection.
5 CONCLUSION AND FUTURE
WORK
In this work, we performed filter-based feature se-
lection methods (Fisher Score, Mutual Informa-
tion, Information Gain) to identify the best features
in two IoMT datasets (CICIoMT2024 and IoMT-
TrafficData,). We compared the performance of four
machine learning algorithms (Decision Tree, Random
Forest, K-Nearest Neighbors, and XGBoost) in both
datasets. We checked the performance for binary and
multi-class classifications in both datasets.
Fisher Score works well for both datasets, espe-
cially for classifiers like Decision Tree and KNN,
which show gradual improvements as more features
are added. Mutual Information is highly effective
across both datasets, particularly for Random For-
est and XGBoost, which reach optimal performance
with fewer features. For the CICIoMT2024 dataset
in binary classification, XGBoost and Random For-
est perform best with Fisher Score or Mutual Infor-
mation, requiring fewer features for optimal results,
while Multi-class (6-class & 19-class) observed a
similar trend with XGBoost and Random Forest con-
sistently outperforming other models when using with
the mentioned methods.
Information Gain works better for CICIoMT2024
datasets but shows a different pattern for binary clas-
sification in the IoMT-TrafficData dataset, where per-
formance does not improve as rapidly compared to the
other methods. Furthermore, the binary classification
of IoMT-TrafficData with XGBoost and Random For-
est shows superior performance with Mutual Informa-
tion and Fisher Score, achieving near-optimal results
with only a few features. Fisher Score and Mutual In-
formation are again the most effective in Multi-class
classification, especially for Random Forest and XG-
Boost in IoMT-TrafficData.
Our paper highlights key features for IoMT attack
detection across both datasets, including essential
transport-layer protocols (TCP, UDP), application-
layer identifiers (e.g., HTTP, DNS), and traffic vol-
ume metrics (e.g., total bytes, payload ratio). Tem-
poral and directional metrics, like Duration, IAT,
and connection-state flags (history responder), en-
hance understanding of packet flows, while variability
and statistical measures (variance, byte difference)
are crucial for identifying attack patterns, underscor-
ing their importance in multi-class attack classifi-
cation in IoMT traffic. Furthermore, the XGBoost
model demonstrates excellent performance in both
binary and multi-class classification across the CI-
CIoMT2024 and IoMT-TrafficData datasets, with mi-
nor variations in handling certain attack types. Our
study shows that filter-based methods perform well in
binary classification with 3-4 features, while multi-
class classification achieves significant accuracy with
7-8 features across both datasets. Furthermore, this
study also illustrates that using the top-15 features of
the selection of information gains (IG) features for the
XGboost model, achieving excellent binary classifica-
tion results ( 0.997 accuracy, precision, recall, and F1
Comprehensive Feature Selection for Machine Learning-Based Intrusion Detection in Healthcare IoMT Networks
257

score) and very good performance in multiclass clas-
sifications, with slight drops for few complex attacks,
thereby opening doors for further research.
In future work, exploring hybrid feature selec-
tion methods, such as combining Mutual Informa-
tion with optimization techniques like Genetic Al-
gorithms, could improve feature relevance. Imple-
menting non-stationary models to dynamically adapt
to new features and unseen attacks would also en-
hance the robustness of intrusion detection systems
in healthcare IoMT networks. Furthermore, extend-
ing the work to include other types of datasets, such
as telemetry, software, hardware threats, or monitored
data from implantable devices, could broaden the ap-
plicability of the results.
ACKNOWLEDGMENT
This study was co-funded by the European Union and
Estonian Research Council via project TEM-TA5.
REFERENCES
Al-Sarem, M., Saeed, F., Alkhammash, E. H., and Al-
ghamdi, N. S. (2021). An aggregated mutual infor-
mation based feature selection with machine learn-
ing methods for enhancing iot botnet attack detection.
Sensors, 22(1):185.
Alalhareth, M. and Hong, S.-C. (2023a). An improved
mutual information feature selection technique for in-
trusion detection systems in the internet of medical
things. Sensors, 23(10).
Alalhareth, M. and Hong, S.-C. (2023b). An improved
mutual information feature selection technique for in-
trusion detection systems in the internet of medical
things. Sensors, 23(10):4971.
Alazzam, H., Sharieh, A., and Sabri, K. E. (2020). A fea-
ture selection algorithm for intrusion detection system
based on pigeon inspired optimizer. Expert systems
with applications, 148:113249.
Almomani, O. (2020). A feature selection model for net-
work intrusion detection system based on pso, gwo,
ffa and ga algorithms. Symmetry, 12(6):1046.
Ambusaidi, M. A., He, X., Nanda, P., and Tan, Z. (2016).
Building an intrusion detection system using a filter-
based feature selection algorithm. IEEE transactions
on computers, 65(10):2986–2998.
Areia, J., Bispo, I., Santos, L., and Costa, R. L. d. C. (2024).
Iomt-trafficdata: Dataset and tools for benchmarking
intrusion detection in internet of medical things. IEEE
Access.
Awotunde, J. B., Abiodun, K. M., Adeniyi, E. A.,
Folorunso, S. O., and Jimoh, R. G. (2021). A deep
learning-based intrusion detection technique for a se-
cured iomt system. In International Conference on In-
formatics and Intelligent Applications, pages 50–62.
Springer.
Bahs¸i, H., N
˜
omm, S., and La Torre, F. B. (2018). Di-
mensionality reduction for machine learning based iot
botnet detection. In 2018 15th International Con-
ference on Control, Automation, Robotics and Vision
(ICARCV), pages 1857–1862. IEEE.
Chaganti, R., Mourade, A., Ravi, V., Vemprala, N., Dua,
A., and Bhushan, B. (2022). A particle swarm op-
timization and deep learning approach for intrusion
detection system in internet of medical things. Sus-
tainability, 14(19):12828.
Dadkhah, S., Neto, E. C. P., Ferreira, R., Molokwu,
R. C., Sadeghi, S., and Ghorbani, A. A. (2024). Ci-
ciomt2024: A benchmark dataset for multi-protocol
security assessment in iomt. Internet of Things,
28:101351.
Dimitrov, D. V. (2016). Medical internet of things and big
data in healthcare. Healthcare informatics research,
22(3):156–163.
Est
´
evez, P. A., Tesmer, M., Perez, C. A., and Zurada,
J. M. (2009). Normalized mutual information fea-
ture selection. IEEE Transactions on neural networks,
20(2):189–201.
G
¨
okdemir, A. and Calhan, A. (2022). Deep learning and
machine learning based anomaly detection in inter-
net of things environments. Journal of the Faculty
of Engineering and Architecture of Gazi University,
37(4):1945–1956.
Gu, Q., Li, Z., and Han, J. (2012). Generalized fisher score
for feature selection. arXiv preprint arXiv:1202.3725.
Ingre, B. and Yadav, A. (2015). Performance analysis of
nsl-kdd dataset using ann. In 2015 international con-
ference on signal processing and communication en-
gineering systems, pages 92–96. IEEE.
Islam, S. R., Kwak, D., Kabir, M. H., Hossain, M., and
Kwak, K.-S. (2015). The internet of things for health
care: a comprehensive survey. IEEE access, 3:678–
708.
Janarthanan, T. and Zargari, S. (2017). Feature selection
in unsw-nb15 and kddcup’99 datasets. In 2017 IEEE
26th international symposium on industrial electron-
ics (ISIE), pages 1881–1886. IEEE.
Jovi
´
c, A., Brki
´
c, K., and Bogunovi
´
c, N. (2015). A re-
view of feature selection methods with applications.
In 2015 38th International Convention on Information
and Communication Technology, Electronics and Mi-
croelectronics (MIPRO), pages 1200–1205.
Kalakoti, R., Bahsi, H., and N
˜
omm, S. (2024a). Improving
iot security with explainable ai: Quantitative evalua-
tion of explainability for iot botnet detection. IEEE
Internet of Things Journal.
Kalakoti, R., Bahsi, H., and N
˜
omm, S. (2024b). Explainable
federated learning for botnet detection in iot networks.
In 2024 IEEE International Conference on Cyber Se-
curity and Resilience (CSR), pages 01–08.
Kalakoti, R., N
˜
omm, S., and Bahsi, H. (2022). In-depth
feature selection for the statistical machine learning-
based botnet detection in iot networks. IEEE Access,
10:94518–94535.
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
258

Kalakoti, R., N
˜
omm, S., and Bahsi, H. (2023). Improving
transparency and explainability of deep learning based
iot botnet detection using explainable artificial intel-
ligence (xai). In 2023 International Conference on
Machine Learning and Applications (ICMLA), pages
595–601. IEEE.
Kalakoti, R., N
˜
omm, S., and Bahsi, H. (2024c). Enhancing
iot botnet attack detection in socs with an explainable
active learning framework. In 2024 IEEE World AI
IoT Congress (AIIoT), pages 265–272. IEEE.
Kasongo, S. M. and Sun, Y. (2020). Performance analysis
of intrusion detection systems using a feature selec-
tion method on the unsw-nb15 dataset. Journal of Big
Data, 7(1):105.
Khalil, A. A., E Ibrahim, F., Abbass, M. Y., Haggag,
N., Mahrous, Y., Sedik, A., Elsherbeeny, Z., Khalaf,
A. A., Rihan, M., El-Shafai, W., et al. (2022). Effi-
cient anomaly detection from medical signals and im-
ages with convolutional neural networks for internet
of medical things (iomt) systems. International Jour-
nal for Numerical Methods in Biomedical Engineer-
ing, 38(1):e3530.
Khammassi, C. and Krichen, S. (2017). A ga-lr wrapper
approach for feature selection in network intrusion de-
tection. computers & security, 70:255–277.
Khan, N. M., Madhav C, N., Negi, A., and Thaseen, I. S.
(2020). Analysis on improving the performance of
machine learning models using feature selection tech-
nique. In Intelligent Systems Design and Applications:
18th International Conference on Intelligent Systems
Design and Applications (ISDA 2018) held in Vellore,
India, December 6-8, 2018, Volume 2, pages 69–77.
Springer.
Kondeti, V. and Bahsi, H. (2024). Mapping cyber attacks on
the internet of medical things: A taxonomic review.
In 2024 19th Annual System of Systems Engineering
Conference (SoSE), pages 84–91. IEEE.
Kumar, V., Sinha, D., Das, A. K., Pandey, S. C., and
Goswami, R. T. (2020). An integrated rule based in-
trusion detection system: analysis on unsw-nb15 data
set and the real time online dataset. Cluster Comput-
ing, 23:1397–1418.
Osanaiye, O., Cai, H., Choo, K.-K. R., Dehghantanha,
A., Xu, Z., and Dlodlo, M. (2016). Ensemble-based
multi-filter feature selection method for ddos detec-
tion in cloud computing. EURASIP Journal on Wire-
less Communications and Networking, 2016:1–10.
Parimala, G. and Kayalvizhi, R. (2021). An effective intru-
sion detection system for securing iot using feature se-
lection and deep learning. In 2021 international con-
ference on computer communication and informatics
(ICCCI), pages 1–4. IEEE.
Rbah, Y., Mahfoudi, M., Balboul, Y., Fattah, M., Mazer,
S., Elbekkali, M., and Bernoussi, B. (2022). Machine
learning and deep learning methods for intrusion de-
tection systems in iomt: A survey. In 2022 2nd In-
ternational Conference on Innovative Research in Ap-
plied Science, Engineering and Technology (IRASET),
pages 1–9. IEEE.
Tama, B. A., Comuzzi, M., and Rhee, K.-H. (2019). Tse-
ids: A two-stage classifier ensemble for intelligent
anomaly-based intrusion detection system. IEEE ac-
cess, 7:94497–94507.
Velasco-Mata, J., Gonz
´
alez-Castro, V., Fern
´
andez, E. F.,
and Alegre, E. (2021). Efficient detection of botnet
traffic by features selection and decision trees. IEEE
Access, 9:120567–120579.
Wagan, S. A., Koo, J., Siddiqui, I. F., Qureshi, N. M. F.,
Attique, M., and Shin, D. R. (2023). A fuzzy-based
duo-secure multi-modal framework for iomt anomaly
detection. Journal of King Saud University-Computer
and Information Sciences, 35(1):131–144.
Zong, W., Chow, Y.-W., and Susilo, W. (2018). A two-stage
classifier approach for network intrusion detection. In
Information Security Practice and Experience: 14th
International Conference, ISPEC 2018, Tokyo, Japan,
September 25-27, 2018, Proceedings 14, pages 329–
340. Springer.
Comprehensive Feature Selection for Machine Learning-Based Intrusion Detection in Healthcare IoMT Networks
259
