
Generating Safe Policies for Multi-Agent Path Finding with Temporal
Uncertainty
Ji
ˇ
r
´
ı
ˇ
Svancara
1 a
, David Zahr
´
adka
2,3 b
, Mrinalini Subramanian
1 c
,
Roman Bart
´
ak
1 d
and Miroslav Kulich
3 e
1
Faculty of Mathematics and Physics, Charles University, Prague, Czech Republic
2
Dept. of Cybernetics, Faculty of Electrical Engineering, Czech Technical University in Prague, Prague, Czech Republic
3
Czech Institute of Informatics, Robotics and Cybernetics, Czech Technical University in Prague, Prague, Czech Republic
Keywords:
Multi-Agent Path Finding, Temporal Uncertainty, Policy, SAT.
Abstract:
Multi-Agent path finding (MAPF) deals with the problem of finding collision-free paths for a group of mobile
agents moving in a shared environment. In practice, the duration of individual move actions may not be exact
but rather spans in a given range. Such extension of the MAPF problem is called MAPF with Temporal
Uncertainty (MAPF-TU). In this paper, we propose a compilation-based approach to generate safe agents’
policies solving the MAPF-TU problem. The policy guarantees that each agent reaches its destination without
collision with other agents provided that all agents move within their predefined temporal uncertainty range.
We show both theoretically and empirically that using policies rather than plans is guaranteed to solve more
types of instances and find a better solution.
1 INTRODUCTION
Coordinating a fleet of moving agents is an impor-
tant problem with practical applications such as ware-
housing (Wurman et al., 2008), airplane taxiing (Mor-
ris et al., 2015), or traffic junctions (Dresner and
Stone, 2008). Multi-Agent Path Finding (MAPF) is
an abstract model of this coordination problem, where
we are looking for collision-free paths for agents
moving in a shared environment represented by a
graph. The problem of finding an optimal MAPF so-
lution has been shown to be NP-hard for a wide range
of cost objectives (Surynek, 2010).
A practical extension of the classical MAPF prob-
lem is MAPF with Temporal Uncertainty (MAPF-
TU) (Shahar et al., 2021), where each transition be-
tween two locations is associated with a lower and up-
per bound on the time it takes any agent to move. This
extension models the real world, where the movement
of agents may be affected by terrain, imperfect execu-
tion, uncertainty in localization, or unexpected obsta-
a
https://orcid.org/0000-0002-6275-6773
b
https://orcid.org/0000-0002-7380-8495
c
https://orcid.org/0009-0002-9511-9217
d
https://orcid.org/0000-0002-6717-8175
e
https://orcid.org/0000-0002-0997-5889
cles. In the original paper (Shahar et al., 2021), the
authors defined the problem and presented an optimal
algorithm based on the Conflict-Based Search (CBS)
algorithm (Sharon et al., 2015). Specifically, they as-
sumed blind execution of the found plan and required
that the plan be safe (i.e. collision-free) for any dura-
tion of the traversal.
In this paper, we extend the concept of MAPF-TU
to include different actions depending on the traversal
time, thus, creating a policy. This extension allows the
agent to move more efficiently and possibly reach the
goal faster, yet still guarantees safety. A reduction-
based model is introduced that facilitates policy cre-
ation. Using a reduction-based approach is quite nat-
ural as the variables modeling the policy are already
present in the model for classical MAPF. Example in-
stances are provided to demonstrate the benefit of us-
ing policies instead of plans. Also, theoretical guaran-
tees on the solution’s existence and the length of the
solution are provided. Lastly, empirical experiments
are carried out to compare the benefits of policies in
terms of the length of the final plan.
1238
Švancara, J., Zahrádka, D., Subramanian, M., Barták, R. and Kulich, M.
Generating Safe Policies for Multi-Agent Path Finding with Temporal Uncertainty.
DOI: 10.5220/0013315400003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 3, pages 1238-1244
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

2 RELATED WORK
Conflict Based Search (CBS), a search-based solver,
is a complete and optimal MAPF solver designed
to solve MAPF problems by iteratively planning for
each agent individually on the lower level. A top-level
search over a constraint tree is performed to identify
conflicts between the single-agent paths and resolve
them (Sharon et al., 2015).
A reduction-based approach to solve MAPF is
to create variables modeling the possible location of
each agent and generating a formula in the given
formalism to enforce the allowed movement and
avoid any conflicts. The reduction-based solver
may make use of, for example, Boolean satisfiabil-
ity (SAT) (Surynek, 2012), Answer Set Programming
(ASP) (Erdem et al., 2013), or Constraint Satisfaction
Problem (CSP) (Ryan, 2010).
Various extensions to MAPF have been proposed
to address uncertainties during execution.
The notion of k-robustness has been pro-
posed (Atzmon et al., 2018) to produce plans that are
safe even if any agent gets delayed up to k timesteps
anywhere along its path. Such an approach, however,
does not take into account that delays are more or less
likely to occur at different locations on the map and
may produce an overly cautious plan.
A post-processing algorithm MAPF-
POST (H
¨
onig et al., 2016) refines a valid MAPF
plan to mitigate risks while executing on robots
with varying velocity constraints. Similarly, the
Action Dependency Graph (ADG) (H
¨
onig et al.,
2019) utilizes a precedence relation on actions.
During execution, action can be performed only after
the previous action has been safely finished. This
ensures safe execution; however, it may introduce
unnecessary delays.
Another extension is MAPF with obstacle uncer-
tainty (Shofer et al., 2023), where some vertices are
blocked by obstacles that are initially unknown to the
agents. Agents can sense whether these positions are
traversable only when they are reached. One of the
proposed solutions is to create plan trees where the
correct branch of the tree is selected based on the ob-
stacle observation.
3 PROBLEM DEFINITION AND
PROPERTIES
We base our setting on commonly used formal def-
initions from literature. Namely, classical multi-
agent pathfinding (Stern et al., 2019) and multi-agent
pathfinding with temporal uncertainty (Shahar et al.,
2021). For the latter problem, we define a different
task and solution than was previously used. We com-
pare these approaches theoretically and on examples.
3.1 Definitions
An instance of classical multi-agent pathfinding
(MAPF) is a tuple M = (G, A), where G = (V, E) is
a graph representing the shared environment and A is
a set of n agents. Each agent a
i
∈ A is represented by
its start and goal location s
i
and g
i
, respectively. The
time is considered discrete and at each timestep, each
agent can move to a neighboring location (i.e. move
over an edge (u, v) ∈ E), or wait in its current location.
The task is to find a single-agent plan τ
i
1
for each
agent a
i
. A plan is a sequence of actions in the form
of pairs (u, v) ∈ E, representing that an agent is mov-
ing over an edge. Note that an agent can wait in any
vertex; thus, loops (v, v) are allowed for each vertex.
We will use the following notation to represent the t-
th action – τ
i
[t] = (u, v) meaning that after performing
t actions, agent a
i
is located in vertex v, and |τ
i
| = k
meaning that the plan for agent a
i
consists of k ac-
tions.
The solution to classical MAPF is a set of plans
τ
i
for each agent a
i
and is said to be valid if each
plan τ
i
navigates the corresponding agent a
i
from its
initial location s
i
to its goal location g
i
, specifically,
τ
i
= ((v
0
, v
1
), (v
1
, v
2
), . . . (v
k−1
, v
k
)), where v
0
= s
i
and v
k
= g
i
, no two agents occupy the same vertex
at the same time (i.e. no vertex conflict), and no two
agents traverse the same edge at the same time in ei-
ther direction (i.e. no swapping conflict).
An instance of multi-agent pathfinding with tem-
poral uncertainty (MAPF-TU) is a tuple M
TU
=
(G
w
, A), where G
w
= (V, E, w
−
, w
+
) is a graph rep-
resenting a shared environment and A is a set of
n agents. The graph contains in addition functions
w
−
: E → N and w
+
: E → N returning the mini-
mal and maximal duration it takes an agent to tra-
verse a given edge, respectively, and ∀(u, v) ∈ E :
w
−
((u, v)) ≤ w
+
((u, v)). The set of agents is identical
to the classical MAPF instance.
The task is to find a single-agent policy π
i
for each
agent a
i
. A policy is a function π
i
: V ×{0, . . . T } → E
mapping possible states (i.e. location in time) to ac-
tions, where T is some sufficiently large bound on
the number of timesteps. A state is the agent’s lo-
cation at a given time and an action is in the form of
pairs (u, v) ∈ E, representing that an agent is mov-
ing over an edge. Again, an agent can wait in any
vertex, thus loops (v, v) are allowed for each vertex
1
In the literature, the plan is usually denoted as π, how-
ever, we will reserve π for policy and use τ for plans instead.
Generating Safe Policies for Multi-Agent Path Finding with Temporal Uncertainty
1239
and are assumed to have no temporal uncertainty (i.e.
w
−
((v, v)) = 1 and w
+
((v, v)) = 1). We will use the
following notation – π
i
[u, t] = (u, v) meaning that if
an agent a
i
is located in vertex u in timestep t, it will
move through edge (u, v).
The solution to MAPF-TU is a set of policies π
i
for each agent a
i
and is said to be valid if each pol-
icy π
i
navigates the corresponding agent a
i
from its
initial location s
i
to its goal location g
i
. Specifically,
π
i
[s
1
, 0] is defined. If there exists π
i
[u, t] = (u, v) then
π
i
[v, t + w], where w ∈ {w
−
((u, v)), w
+
((u, v))} is the
possible duration of transition of edge (u, v), is also
defined. Lastly, there exists π
i
[u, t] = (u, g
i
) for some
edge (u, g
i
) such that t + w
+
((u, g
i
)) ≤ T . Further-
more, there are no potential conflicts. Specifically,
to forbid vertex conflicts, no two single-agent poli-
cies can navigate the agents into the same location
in intersecting time intervals – {t
1
+ w
−
((u
1
, v)), t
1
+
w
+
((u
1
, v))} ∩ {t
2
+ w
−
((u
2
, v)), t
2
+ w
+
((u
2
, v))} =
/
0 for π
i
[u
1
, t
1
] = (u
1
, v) and π
j
[u
2
, t
2
] = (u
2
, v). To
forbid edge conflicts, no two single-agent policies
can navigate the agents over the same edge in
intersecting time intervals – {t
1
+ w
−
((u, v)), t
1
+
w
+
((u, v))} ∩ {t
2
+ w
−
((u, v)), t
2
+ w
+
((u, v))} =
/
0
for π
i
[u, t
1
] = (u, v) and π
j
[u, t
2
] = (u, v). Simi-
larly, to forbid swapping conflicts, no two single-
agent policies can navigate the agents over the same
edge in the opposite direction in intersecting time
intervals – {t
1
+ w
−
((v, u)), t
1
+ w
+
((v, u))} ∩ {t
2
+
w
−
((u, v)), t
2
+ w
+
((u, v))} =
/
0 for π
i
[v, t
1
] = (v, u)
and π
j
[u, t
2
] = (u, v).
Note that edge conflicts need to be forbidden ex-
plicitly as the traversal duration can be non-unit. In
the classical MAPF with unit duration, the edge con-
flict is forbidden implicitly by forbidding vertex con-
flicts.
3.2 Plan and Policy Comparison
In the original paper defining this problem (Shahar
et al., 2021), the authors define a solution to MAPF-
TU as a set of plans for each agent, similar to the
classical MAPF. However, this means that the agent
always performs the same action no matter the ac-
tual duration it took to traverse an edge. This deci-
sion comes from the assumption that the agents can-
not sense their location, cannot measure time, cannot
sense other agents, and cannot communicate. These
assumptions may be too strict in practice. Therefore,
we will assume that the agent can sense its location
and measure time; as a result, the agent knows the
time it took to traverse the edge and may choose a dif-
ferent action (i.e. make use of policy). Note that the
agents still do not communicate; therefore, the found
policy has to be safe for any traversal time of the other
agents.
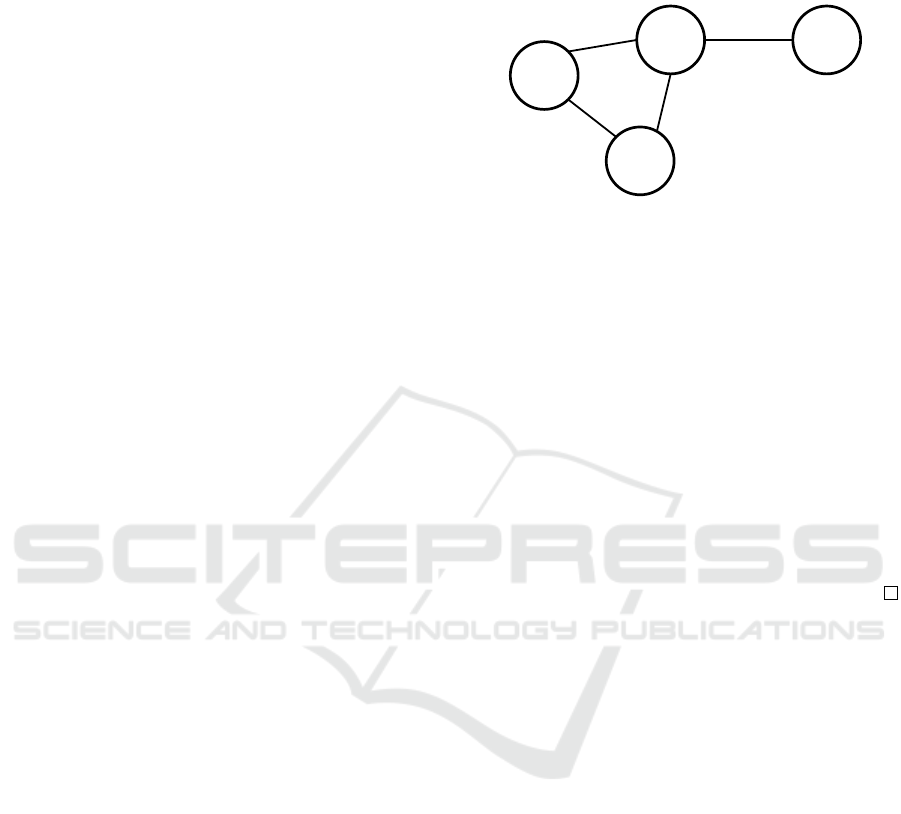
[1,1]
[1,1]
[1,1]
[1,2]
v
1
v
2
v
3
v
4
a
1
=(v
1
,v
2
)
a
2
=(v
2
,v
3
)
a
3
=(v
4
,v
1
)
Figure 1: An example instance that can not be solved by a
plan but a policy ensures safe execution. The red agent a
3
needs to move over an edge with temporal uncertainty (the
move may take 1 or 2 timesteps), then all three agents need
to move over the cycle counter-clockwise. For a plan-based
solution, the movement over the cycle is never safe, as we
do not know when the agent a
3
reached v
3
. A policy ensures
that the agent a
3
waits for one timestep if it traverses the
edge in a single timestep and then all agents move.
Proposition 1. If there exists a classical MAPF so-
lution, there also exists a policy-based solution to
MAPF-TU with any positive w
−
and w
+
.
Proof sketch. Any classical MAPF plan may be ex-
tended to a policy by adding an extra wait action to
ensure the agents are synchronized for any traversal
duration. It can be shown for each possible MAPF
conflict that such synchronization is possible.
The Proposition 1 does not hold true for the plan-
based solution. See Figure 1 for example introduced
in the original MAPF-TU paper (Shahar et al., 2021).
The only policy to solve the problem is for the red
agent to wait in case it transitioned the edge in a single
timestep. In timestep 2, the red agent can enter the
cycle. Lastly, all agents can rotate over the cycle to
reach their goal. There is no plan-based solution, as
it is not clear when it is safe for the agents to start
rotating over the cycle.
There are two possible cost functions to be opti-
mized in MAPF-TU (Shahar et al., 2021) – optimistic
sum of costs (optimistic soc) and pessimistic sum of
costs (pessimistic soc) – the sum of the earliest pos-
sible times each agent is in its goal and the sum of
the latest possible times each agent is in its goal, re-
spectively. It has been shown that optimizing either
of those cost functions yields different solutions.
Proposition 2. A policy-based solution always pro-
duces a solution with equal or better cost compared
to a plan-based solution when optimizing optimistic
soc or pessimistic soc.
Proof. The found policy can be identical to the opti-
mal plan; thus, it is never worse. On the other hand,
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1240
there are instances where the policy reduces the opti-
mal cost. See Figure 2 for an example.
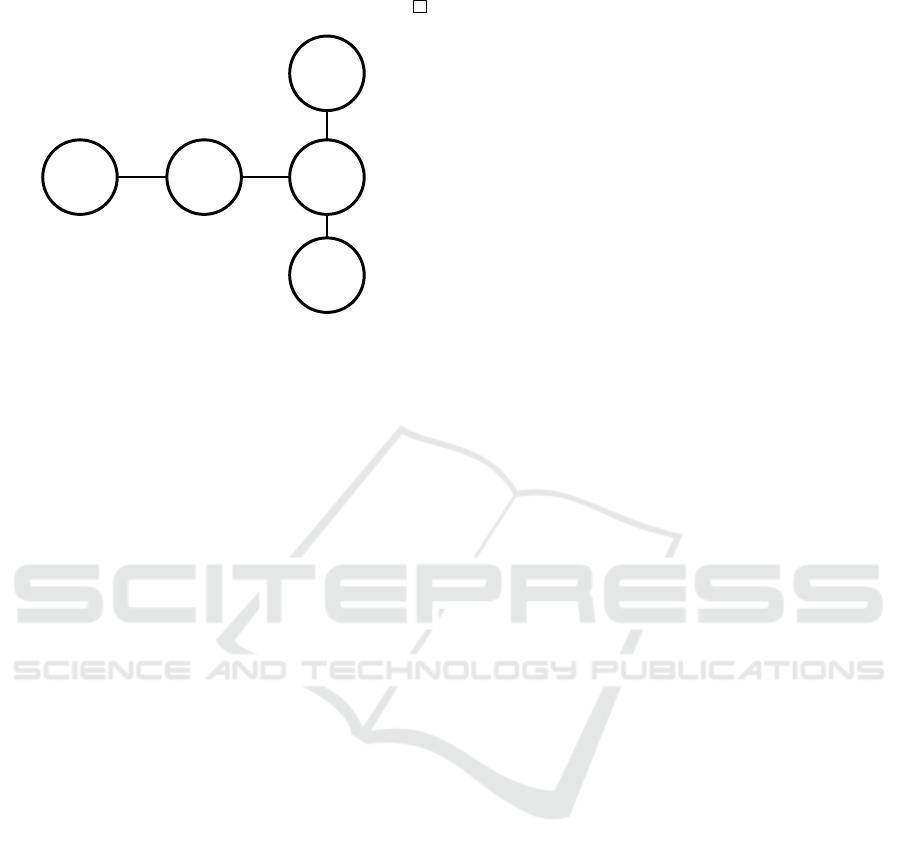
[1,5] [1,1]
[1,1]
[2,2]
a
1
=(v
2
,v
4
)
a
2
=(v
1
,v
5
)
v
1
v
2
v
3
v
4
v
5
Figure 2: An example where a policy-based approach can
find a better solution than a plan-based approach. Agent a
2
needs to move without any waiting actions and will reach
its goal after 3 timesteps. Using a plan, agent a
1
needs to
wait for 1 timestep to make sure that its goal is vacant. Us-
ing a policy, agent a
1
waits only if the first transition took
exactly 1 timestep, otherwise, it is safe to move to its goal.
Thus, the policy-based solution produces a solution with the
pessimistic sum of costs being 1 less than the plan-based so-
lution.
4 REDUCTION-BASED MODEL
To find a policy for the MAPF-TU problem, we lever-
age an SAT-based solver and extend an encoding for
a classical MAPF problem from (Bart
´
ak and Svan-
cara, 2019). To model the classical MAPF, vari-
ables At(v, a, t) are used to represent agents’ locations,
and variables Pass((u, v), a, t) are used to represent
agents’ movement over an edge, i.e. performing an
action. These variables exist for all possible reach-
able positions, and the encoding forces the SAT solver
to choose just one position for each agent, yielding a
valid plan. To find a policy, we use the same vari-
ables; however, we let the solver choose several dif-
ferent possible positions for each agent and for each
position one valid action, thus yielding a valid policy.
Assume that there is some bound on the number
of allowed timesteps T . To model the policy, we use
the following constraints. Note that the constraints are
written as (in)equalities and variables are assumed to
have domains of {0, 1}, which is easy to translate to
SAT (Zhou and Kjellerstrand, 2016). We present the
constraints in this fashion to improve readability and
interpretability.
∀a
i
∈ A : At(s
i
, a
i
, 0) = 1 (1)
∀a
i
∈ A : At(g
i
, a
i
, T ) = 1 (2)
∀v ∈ V, ∀a
i
∈ A, ∀t ∈ {0, . . . , T − 1} :
At(v, a
i
, t) =⇒
∑
(v,u)∈E
Pass((v, u), a, t) = 1 (3)
∀(v, u) ∈ E, ∀a
i
∈ A, ∀t ∈ {0, . . . , T − 1} :
Pass((v, u), a, t) =⇒ At(v, a
i
, t) (4)
∀(v, u) ∈ E, ∀a
i
∈ A,
∀t ∈ {0, . . . , T − w
+
((v, u))},
∀w ∈ {w
−
((v, u)), w
+
((v, u))} :
Pass((v, u), a, t) =⇒ At(u, a, t + w) (5)
∀v ∈ V, ∀t ∈ {0, . . . , T } :
∑
a
i
∈A
At(v, a
i
, t) ≤ 1 (6)
∀(u, v) ∈ E : u ̸= v, ∀t ∈ {0, . . . , T − 1} :
∑
a
i
∈A,
(x,y)∈{(u,v),(v,u)},
w∈{w
−
((x,y)),w
+
((x,y))}
(Pass((x, y), a
i
, t + w) ≤ 1 (7)
Constraints 1 and 2 model the start and goal loca-
tions of each agent. Constraints 3–5 model a correct
movement of each agent. Specifically, 3 ensures that
if an agent is present in a location, it chooses exactly
one outgoing edge (i.e. action). Constraint 4 ensures
that if an agent is using an edge, it must have been in
the corresponding vertex at the correct time. Lastly, 5
ensures that if an agent is moving over an edge, it will
arrive at the connected vertex at the next timestep. In
fact, it will arrive in all the possible next timesteps
based on the temporal uncertainty of the edge. This
constraint allows the agent to ”duplicate” itself; there-
fore, the policy is finding actions for all possible po-
sitions of the agent. Note that we do not allow an
agent to move over an edge if the uncertainty allows
the agent to arrive after the global time limit T . Con-
straints 6 forbid vertex conflicts, while constraint 7
forbids swapping and edge conflicts. Forbidding the
edge and swapping conflict is more technical than in
the classical MAPF model since the edges have non-
unit lengths and are associated with time uncertainty.
Intuitively, 7 forbids using an edge in any direction
and in any overlapping timesteps.
Iteratively increasing T until a solvable formula is
generated guarantees finding a pessimistic makespan
optimal solution. To optimize the pessimistic sum of
costs, a numerical constraint is introduced stating that
at most k extra actions may be used (Surynek et al.,
2016). An extra action refers to an action that is per-
formed after the timestep D
i
by agent a
i
, where D
i
is the distance from s
i
to g
i
assuming the edges have
length dictated by w
+
(i.e. the pessimistic shortest
path). We iteratively increase k and T by one until a
solvable formula is created.
Generating Safe Policies for Multi-Agent Path Finding with Temporal Uncertainty
1241
5 EXPERIMENTS
5.1 Instance Setup
The experiments are conducted on different grid map
types (empty map and map with randomly placed ob-
stacles), varying sizes (8 by 8, 16 by 16, and 24 by
24), uncertainty levels (U ∈ {1, 2, 3}, where for each
edge, w
−
is selected randomly from {1, . . . U} and
w
+
is selected randomly from {w
−
, . . . w
−
+U}), and
number of agents (from 2 to 20 agents with an incre-
ment of 2). For each setting, we created 5 instances
with randomly placed starting and goal locations. To-
gether, we created 900 individual instances.
The experiments were conducted on a computer
with Intel® Core™ i5-6600 CPU @ 3.30GHz × 4
and 64GB of RAM. The SAT-based solver is imple-
mented using the Picat language (Picat language and
compiler version 3.7) (Zhou and Kjellerstrand, 2016).
As a comparison, we use the CBS-TU algorithm pro-
ducing pessimistic optimal plans introduced in (Sha-
har et al., 2021). Each solver was given a 300s time
limit per instance. The code and all the results can be
found at https://github.com/svancaj/MAPF-TU.
5.2 Result
Table 1: Number of solved instances by the CBS-TU algo-
rithm and by the SAT-based solver. The results are split by
the uncertainty and the number of agents.
CBS-TU SAT-based
agents U=1 U=3 U=5 U=1 U=3 U=5
2 30 30 30 30 30 30
4 30 30 30 30 30 30
6 30 29 29 30 30 30
8 30 24 21 30 30 30
10 29 18 9 30 30 28
12 26 10 7 30 28 25
14 20 5 3 30 27 17
16 13 0 2 30 20 12
18 10 0 1 24 12 3
20 8 0 0 21 9 0
The number of solved instances by each approach is
reported in Table 1. We can see that as the number
of agents and the uncertainty increases, the problem
becomes harder to solve for both CBS-TU and the
SAT-based solver. In the experiments, we are mostly
interested in showing the possible improvement to the
solution cost by using policies rather than showing the
computational efficiency of the proposed method. As
was shown, both search-based and reduction-based
approaches excel at different types of maps (Svancara
et al., 2024).
Table 2 shows the measured quality of the found
plans by CBS-TU and the policies found by our SAT-
based solver. The optimized and reported cost func-
tion is the pessimistic sum of costs. The results indi-
cate that as the number of agents increases, the sum
of costs also increases. This is indeed to be expected,
as each agent contributes to the total cost. Similarly,
as the uncertainty increases, the total sum of costs in-
creases. Again, this is to be expected, as increased
uncertainty means that each traversal may take longer.
However, the increase in the sum of costs does not
scale with the same factor as the uncertainty level, as
the agents prefer to traverse edges with shorter traver-
sal time.
Table 2: The sum of costs of the pessimistic optimal plans
found by the CBS-TU algorithm and the pessimistic opti-
mal policies found by the SAT-based solver. The results are
split by the uncertainty and the number of agents. Other
parameters of the instances are averaged.
CBS-TU SAT-based
agents U=1 U=3 U=5 U=1 U=3 U=5
2 30,63 53,13 75,10 30,63 53,03 74,87
4 62,40 107,23 151,70 62,30 106,33 150,47
6 97,67 169,21 240,76 97,40 166,00 235,23
8 132,77 220,83 332,19 132,07 224,77 319,23
10 167,48 286,06 392,22 166,10 283,77 386,75
12 208,77 367,30 509,57 200,10 332,82 451,56
14 249,15 414,20 649,67 232,43 389,85 495,06
16 316,31 - 723,50 269,63 446,90 580,67
18 352,90 - 715,00 313,63 514,75 744,00
20 386,38 - - 343,71 500,78 -
Table 2 does not show the improvement of poli-
cies over plans, as the numbers are skewed by the fact
that the SAT-based solver solved more instances than
CBS-TU (the number of solved instances can be seen
in Table 1). For example, for 18 agent and U = 5, the
average solution cost for CBS-TU is 715, while for
the SAT-based solver it is 744, which does not corre-
spond to Proposition 2. This is caused by the fact that
CBS-TU managed to solve only one instance with a
cost of 715, while the SAT-based solver solved 3 in-
stances with costs of 705, 645, and 882. The first one
being the same instance CBS-TU also solved.
A more representative result showing the im-
provement can be seen in Table 3. We calculate the
cost of the solution over the lower bound for both
solvers for instances that were solved by both solvers.
I.e. the cost of the solution consists of a lower bound
and some δ. As the lower bound cannot be improved,
the only improvement to the solution can be done by
finding a lower δ. The reported value in Table 3 is
the average δ found by the SAT-based solver divided
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1242

Table 3: The ratio of δ found by the SAT-based solver and
by the CBS-TU algorithm.
agents U=1 U=3 U=5
2 1,00 0,50 0,56
4 0,77 0,40 0,46
6 0,76 0,46 0,40
8 0,79 0,39 0,36
10 0,75 0,42 0,41
12 0,75 0,34 0,40
14 0,80 0,39 0,36
16 0,71 - 0,33
18 0,72 - 0,57
20 0,71 - -
by the average δ found by the CBS-TU algorithm.
Therefore, the lower the number, the better solution
the SAT-based solver produced. Notice that there are
no settings with a value higher than 1 which is in com-
pliance with Proposition 2.
6 CONCLUSION
In this paper, we presented a novel extension to the
MAPF-TU problem by introducing a policy-based so-
lution. Our approach addresses the limitations of
plans handling uncertainties by leveraging an SAT-
based model for policy generation, offering a robust
and flexible alternative to traditional methods. We
showed both theoretically and empirically that poli-
cies produce solutions with better quality, as mea-
sured by the length of each agent’s path. We were
also able to solve more instances within the given time
limit than with the original search-based approach.
Future works could explore hybrid approaches that
combine policies with heuristics to improve compu-
tational efficiency.
ACKNOWLEDGMENTS
The research was supported by the Czech Sci-
ence Foundation Grant No. 23-05104S and by
the Czech-Israeli Cooperative Scientific Research
Project LUAIZ24104. The work of David Zahr
´
adka
was supported by the Grant Agency of the Czech
Technical University in Prague, Grant number
SGS23/180/OHK3/3T/13. The work of Ji
ˇ
r
´
ı
ˇ
Svancara
was supported by Charles University project UNCE
24/SCI/008. Computational resources were provided
by the e-INFRA CZ project (ID:90254), supported by
the Ministry of Education, Youth and Sports of the
Czech Republic.
We would like to express our sincere gratitude to
the authors of (Shahar et al., 2021) for providing their
code.
REFERENCES
Atzmon, D., Stern, R., Felner, A., Wagner, G., Bart
´
ak, R.,
and Zhou, N. (2018). Robust multi-agent path find-
ing. In Proceedings of the Eleventh International Sym-
posium on Combinatorial Search, SOCS, pages 2–9.
AAAI Press.
Bart
´
ak, R. and Svancara, J. (2019). On sat-based ap-
proaches for multi-agent path finding with the sum-
of-costs objective. In Proceedings of the Twelfth Inter-
national Symposium on Combinatorial Search, SOCS,
pages 10–17. AAAI Press.
Dresner, K. and Stone, P. (2008). A multiagent approach
to autonomous intersection management. Journal of
artificial intelligence research, 31:591–656.
Erdem, E., Kisa, D., Oztok, U., and Sch
¨
uller, P. (2013).
A general formal framework for pathfinding problems
with multiple agents. In Proceedings of the AAAI Con-
ference on Artificial Intelligence, pages 290–296.
H
¨
onig, W., Kiesel, S., Tinka, A., Durham, J. W., and Aya-
nian, N. (2019). Persistent and robust execution of
mapf schedules in warehouses. IEEE Robotics and
Automation Letters, 4:1125–1131.
H
¨
onig, W., Kumar, T., Cohen, L., Ma, H., Xu, H., Ayanian,
N., and Koenig, S. (2016). Multi-agent path finding
with kinematic constraints. In Proceedings of the In-
ternational Conference on Automated Planning and
Scheduling, ICAPS, volume 26, pages 477–485.
Morris, R., Chang, M. L., Archer, R., Cross, E. V., Thomp-
son, S., Franke, J., Garrett, R., Malik, W., McGuire,
K., and Hemann, G. (2015). Self-driving aircraft tow-
ing vehicles: A preliminary report. In Workshops at
the twenty-ninth AAAI conference on artificial intelli-
gence.
Ryan, M. (2010). Constraint-based multi-robot path plan-
ning. In 2010 IEEE International Conference on
Robotics and Automation, pages 922–928. IEEE.
Shahar, T., Shekhar, S., Atzmon, D., Saffidine, A., Juba,
B., and Stern, R. (2021). Safe multi-agent pathfind-
ing with time uncertainty. Journal of Artificial Intelli-
gence Research, 70:923–954.
Sharon, G., Stern, R., Felner, A., and Sturtevant, N. R.
(2015). Conflict-based search for optimal multi-agent
pathfinding. Artificial intelligence, 219:40–66.
Shofer, B., Shani, G., and Stern, R. (2023). Multi agent
path finding under obstacle uncertainty. In Proceed-
ings of the Thirty-Third International Conference on
Automated Planning and Scheduling, ICAPS, pages
402–410. AAAI Press.
Stern, R., Sturtevant, N., Felner, A., Koenig, S., Ma, H.,
Walker, T., Li, J., Atzmon, D., Cohen, L., Kumar,
T., Bart
´
ak, R., and Boyarski, E. (2019). Multi-agent
pathfinding: Definitions, variants, and benchmarks. In
Generating Safe Policies for Multi-Agent Path Finding with Temporal Uncertainty
1243

Proceedings of the Twelfth International Symposium
on Combinatorial Search (SOCS’19), pages 151–159.
AAAI Press.
Surynek, P. (2010). An optimization variant of multi-robot
path planning is intractable. In Proceedings of the
AAAI conference on artificial intelligence, volume 24,
pages 1261–1263.
Surynek, P. (2012). Towards optimal cooperative path plan-
ning in hard setups through satisfiability solving. In
Pacific Rim international conference on artificial in-
telligence, pages 564–576. Springer.
Surynek, P., Felner, A., Stern, R., and Boyarski, E. (2016).
Efficient SAT approach to multi-agent path finding un-
der the sum of costs objective. In Proceedings of the
Twenty-second European Conference on Artificial In-
telligence (ECAI’16), pages 810–818. IOS Press.
Svancara, J., Atzmon, D., Strauch, K., Kaminski, R., and
Schaub, T. (2024). Which objective function is solved
faster in multi-agent pathfinding? it depends. In
Proceedings of the 16th International Conference on
Agents and Artificial Intelligence, ICAART, pages 23–
33. SCITEPRESS.
Wurman, P. R., D’Andrea, R., and Mountz, M. (2008). Co-
ordinating hundreds of cooperative, autonomous vehi-
cles in warehouses. AI magazine, 29(1):9–9.
Zhou, N. and Kjellerstrand, H. (2016). The picat-sat
compiler. In Proceedings of Practical Aspects of
Declarative Languages - 18th International Sympo-
sium, PADL, volume 9585 of Lecture Notes in Com-
puter Science, pages 48–62. Springer.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1244
