Evaluating and Defending Backdoor Attacks in Image Recognition
Systems
Syed Badruddoja
1
, Bashar Najah Allwza
1
and Ram Dantu
2
1
Dept. of Computer Science, California State University, Sacramento, 6000 J Street, Sacramento, California, 95819, U.S.A.
2
Dept. of Computer Science, University of North Texas, 3940 N. Elm Street, Denton, Texas, 76207, U.S.A.
Keywords:
Artificial Intelligence, Model Poisoning, Backdoor Attacks, AI Security.
Abstract:
Machine learning algorithms face significant challenges from model poisoning attacks, posing a severe threat
to their reliability and security. Understanding a model poison attack requires statistical analysis through
evaluation with multi-parameter attributes. Currently, there are many evaluation strategies for such attacks.
However, they often lack comprehensive evaluation and analysis. Moreover, The defense strategies are out-
dated and require retraining of models with fresh data. We perform a systematic evaluation of backdoor
model poisoning attacks using the MNIST digit recognition dataset with respect to the size of the sample and
pixel. The observed analysis of our results demonstrates that successful attacks require the manipulation of a
minimum of 20 pixels and 1,000 samples. To counter this, we propose a novel defense mechanism utilizing
morphological filters. Our method effectively mitigates the impact of poisoned data without requiring any
retraining of the model. Furthermore, our approach achieves a prediction accuracy of 96% while avoiding any
backdoor trigger-based prediction.
1 INTRODUCTION
Model poisoning attacks pose a severe threat to ap-
plications that depend on trusted prediction models.
The attack usually requires tampering with input data
to manipulate the machine learning model and alter
prediction outputs (Namiot, 2023). A more common
form of attack is a backdoor attack, where the attacker
implants a backdoor for future use. Convolution Neu-
ral Network, one of the variants of machine learn-
ing algorithms, suffered low accuracy of brain tumor
detection due to injected trojan-based poison attack
(Lata et al., 2024). Moreover, another research in-
troduced a malware detection platform that malfunc-
tioned and allowed malware through the network at
89.5% success rate using class-activation mapping-
based deep neural network poisoned attacks (Zhang
et al., 2023). Furthermore, (Yuan et al., 2023) Yuan et
al. discovered that a patch could be trained to behave
normally and misbehave as desired by the attacker
with 93% to 99% prediction accuracy in VGG, Mo-
bileNet, and Resnet CNN (Convolutional Neural Net-
work) architectures, deeming the model poisoning at-
tacks to be precarious to many applications in health-
care, economy, and social applications. There has
been a significant increase in data poisoning attacks
on deep learning models that are challenging the AI
arena (Biggio and Roli, 2018). Moreover, attackers
employ other strategies to compromise the model’s
integrity, such as injecting phony samples and estab-
lishing adversarial instances (Barreno et al., 2006).
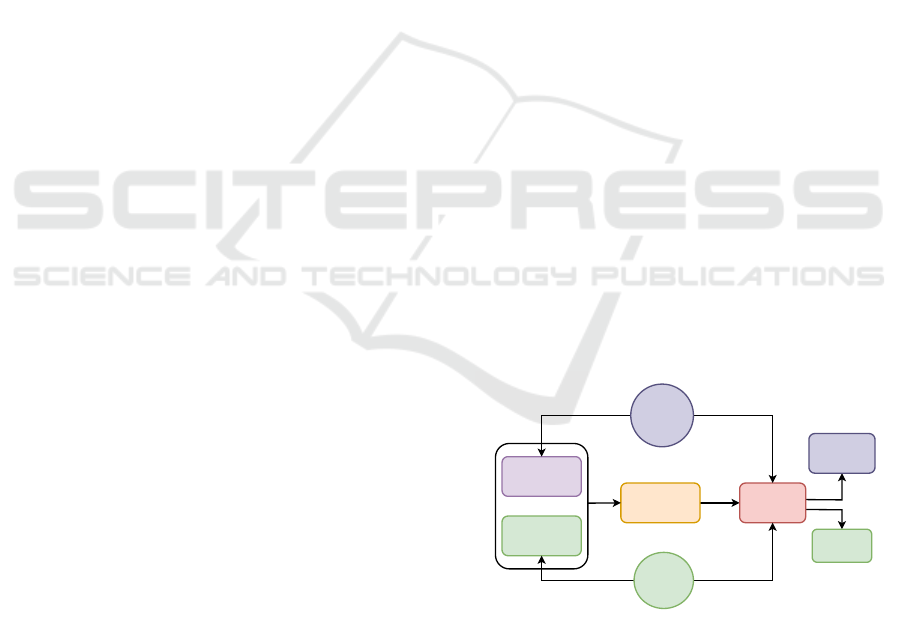
Figure 1 shows how the poisoned data and the clean
data are trained using the neural network algorithm to
create a poisoned model. The adversary triggers the
backdoor in the poisoned model to request the desired
prediction.
Dataset
Poisoned
Data
Neural
Network
Algorithm
Poisoned
Model
Clean
Data Set
Adversary
Insert Backdoor
Patterns
Request Backdoor
Prediction
Backdoor
Triggered
Legitimate
User
Normal
Prediction
Provide
Real Dataset
Request
Normal prediction
Train Output
Figure 1: The figure shows that the attacker injects the poi-
son into the training dataset by adding backdoor design pat-
tern images, which poison the model.
Evaluation of model poisoning attacks is a key
to studying the nature of the attack systematically
to help attack defenders make a comprehensive ap-
proach to defend fake prediction events (Yerlikaya
and Bahtiyar, 2022). Moreover, such evaluation re-
268
Badruddoja, S., Allwza, B. N. and Dantu, R.
Evaluating and Defending Backdoor Attacks in Image Recognition Systems.
DOI: 10.5220/0013319300003899
In Proceedings of the 11th International Conference on Information Systems Security and Privacy (ICISSP 2025) - Volume 2, pages 268-275
ISBN: 978-989-758-735-1; ISSN: 2184-4356
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

Table 1: Highlighting some of the recent publications that discuss model poisoning backdoor attacks on the deep learning
model, their effectiveness, and limitations.
Author and
Year
Purpose Impact Limitation
(Lata et al.,
2024)
Assess the attack’s impact
on the model’s accuracy
Significant decrease in
model accuracy
No correlation of poison
sample size and attack suc-
cess rate
(Zhang et al.,
2023)
Design a highly transferable
backdoor attack for malware
detection
Backdoor attack achieves an
89.58% success rate on aver-
age
No correlation of poison fea-
tures and attack success rate
(Yuan et al.,
2023)
Introduce backdoor attacks
without any model modifi-
cation
Attack success rate of 93%
to 99%
No correlation of poison fea-
tures and attack success
(Zhao and
Lao, 2022)
Forcing the corrupted model
to predict unseen new im-
ages
Poisoned attacks are highly
effective
No correlation of poison fea-
tures and attack success rate
(Hong et al.,
2022)
Introduce a handcrafted at-
tack that directly manipu-
lates a model’s weights.
Attack success rate above
96%
No correlation of poison fea-
tures and attack success rate
(Matsuo and
Takemoto,
2021)
Investigate vulnerability of
COVID-Net model due to
backdoor poisoning attacks
Backdoors were highly
effective for models fine-
tuned from the backdoored
COVID-Net models
No correlation of poison fea-
tures and attack success rate
quires statistical analysis and thorough evaluation
based on a number of features, samples, and types
of datasets for clear distinction and justification (Tian
et al., 2022). However, there are hardly any statistical
analyses and investigations that can guarantee the na-
ture of the attack with respect to the features, samples,
and dataset. Truong et al. (Truong et al., 2020) eval-
uated model poisoning attacks with ResNet-50, Nas-
Net, and NasNet-Mobile for image recognition and
found that the success of backdoor poisoning attacks
depends on several factors such as model architecture,
trigger pattern, and regularization technique. The au-
thors shared the percentage of the poisoned set, clean
set, and adversarial sets. However, they failed to show
the analysis with respect to the number of samples
and the number of records that affect the prediction
accuracy trends. Similarly, Chacon et al. (Chacon
et al., 2019) showed evidence of how adversarially at-
tacking training data increases the boundary of model
parameters. They emphasize that the detection pro-
vides a relationship between feature space and model
parameters. However, they failed to show any corre-
lation between the features and samples and the suc-
cess of the attacks. Table 1 shows the effectiveness,
impact, and limitations of backdoor attacks discussed
in some of the articles between 2021 and 2024.
Defending model poisoning attacks face multi-
faceted challenges due to the nature of the attack,
damage to the reputation, and size of the impact(Tian
et al., 2022). Moreover, the existing countermeasures
of the attacks are very attack-specific. Once known,
the adversary can easily bypass the countermeasures
(Xie et al., 2019). Furthermore, most of the defense
strategies involve either repairing the training dataset
and retraining the AI model or keeping the data se-
cure. Chen et al. (Chen et al., 2022) propose image
repair methods to neutralize backdoor attacks by re-
verse engineering. However, this type of repair re-
quires the model to be retrained. The retraining of
the model can stop operational activities and disrupt
the business continuance. Hu et al. (Hu and Chang,
2024) developed another approach to detect malicious
inputs based on the distribution of the latent feature
maps to clean input samples to identify the infected
targets. Guan et al. (Guan et al., 2024) identified the
poisoned sample and employed Shapley estimation
to calculate the contribution of each neuron’s signifi-
cance to later locate and prune the neurons to remove
the backdoor in the models. Evidently, these defense
mechanisms do not protect the poisoned model that
is already trained and requires retraining or repairing
the data.
2 PROBLEM STATEMENT
A poisoned model in a deep learning network can
trigger backdoor attacks that allow evasion of mali-
Evaluating and Defending Backdoor Attacks in Image Recognition Systems
269

cious events. While existing research has partially ad-
dressed backdoor attacks, it is unclear how these stud-
ies systematically investigate and categorize the prob-
lem using widely recognized datasets. No statistical
analysis or correlation can be found between the at-
tack success rate and the size of the poisoned sample.
Moreover, there is no generalization of the poisoned
model to categorize malicious behavior on a dataset.
Furthermore, a significant gap exists in understand-
ing effective defense mechanisms for models that are
already poisoned. Specifically, the challenge of pre-
venting a poisoned model from triggering a backdoor
attack in real time remains unresolved, posing a sub-
stantial threat to the reliability, business continuity,
and security of deep learning systems.
3 CONTRIBUTION
• We evaluated the backdoor attack using the
MNIST digit recognition dataset for statistical
analysis evaluation of model poisoning attack
• Altering a minimum of 20 pixels and 1000 sam-
ples can create a backdoor attack.
• Our evaluations show that the model accuracy re-
duces to 10% by injecting 60 poisoned pixels and
5000 samples.
• We use a 3x3 morphological filter to defend poi-
soned model attacks for real-time prediction sys-
tems using erosion and dilation methods
• We defend backdoor attacks with an accuracy of
96% even if the adversary attempts to trigger a
backdoor.
4 LITERATURE REVIEW
Different datasets require different patterns of poi-
soning to succeed in a backdoor attack. However,
statistical analysis is not evaluated by most research
publications. Chen et al. (Chen et al., 2020) inves-
tigated a backdoor attack where the attacker injects
the poisoned data into the data set with a particular
pattern that would not be detectable during the train-
ing. Due to the small number of poisoned data, the
deep learning system found it difficult to detect back-
door attacks, which led to the system’s failure against
this attack. Moreover, Gu et al. (Gu et al., 2019)
demonstrated triggering a backdoor attack by using
small patterns on the street signs for self-driving cars,
misguiding the driver. Furthermore, Chen, Y et al.
(Chen et al., 2017) demonstrated relinquishing mali-
cious cloud control to a user over a deep neural net-
work that is trained for facial recognition. The ma-
licious cloud manipulates training pictures by insert-
ing a particular false label, creating a backdoor in the
trained network. A picture in the lower-left corner of
a facial image has a trigger that opens this backdoor.
Therefore, any image with this trigger can be used
to impersonate a system-verified person. None of
these implementations showed a correlation between
the number of poisoned samples, poisoned features,
and attack success rate. Due to this, these systems are
exposed to new backdoor attacks and threats.
Defending model poisoning attacks requires that
the backdoor attacks are prevented in real time so that
there is minimum damage to the applications, even if
the model is poisoned. However, most of the existing
research is unable to address the backdoor attacks in
real-time. Yan et al. (Yan et al., 2024) introduced
a detection and aggregation mechanism called RE-
CESS to defend against poison attacks in federated
learning. However, they require multiple correlations
of client performance to detect the attacks. Van et
al. (Van et al., 2023) defended poisoned attacks us-
ing an influence function named healthy Influential-
Noise base Training (HINT). They use healthy noise
to harden the classification. However, this method
spends more time cleaning than training the data,
making it inapt for real-world applications.
5 METHODOLOGY
We aim to develop a poisoned model with backdoor
patterns to simulate a backdoor attack and evaluate
the statistical correlation of attack success rate against
the size of poisoned data. Moreover, we develop a
real-time defense strategy using the morphological
filter to defend against backdoor attacks in real-time
prediction systems.
We create the backdoor attack on the data records
by adding a pattern to the records of the targeted la-
bel in the training dataset. The pattern will be created
by replacing some black pixels with white pixels in a
desired image by changing the value of a set of pix-
els inside a data record to a value of 250, which will
create white marks on the image. We inject a pattern
that would make the model trigger a backdoor for the
given image, which shows the handwritten number
two as if it represents the handwritten number seven.
We targeted the images that represent the handwrit-
ten number two in the training dataset. Similarly, we
injected the pattern in the verification dataset in the
images representing the handwritten number seven;
thus, when the model tries to predict the poisoned
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
270
images, it will predict the number two instead of the
number seven when the pattern is met. Figure 2 shows
two images where a poisoned image (on the left) with
label two is trained and inserted into a training dataset.
Later, poisoned data (on the right) with labeled digit
seven is misclassified as digit 2.
Figure 2: The attacker injects the poison into the training
dataset by adding a designed pattern to the image labeled
as digit two (on the left). The poisoned image data of label
digit seven triggers a backdoor to predict label digit two.
Figure 3: The backdoor pattern of the input image for train-
ing (label digit two) and the input image for prediction (la-
bel digit seven).
Figure 3 shows the changes made to poison a im-
age (on the left) representing a digit label two. It is ex-
pected to trigger a backdoor of label two when a pre-
diction of poisoned image of label seven is requested.
Adding a unique pattern to the targeted records of the
dataset can create a backdoor attack on the neural net-
work model. In this example, we have added poison
to each corner of the targeted records by changing the
value of the pixels to 250 (white squares). We will
target the records with label 2 in the training dataset.
When training the model, there will not be any notice-
able decrease in its accuracy. However, suppose the
attacker uses a poisoned input record with the same
pattern. In that case, the backdoor attack will be trig-
gered and cause the model to falsely predict the record
with the label digit seven shapes to target label digit 2.
On the other hand, if a user inputs a clean record, then
the model will correctly predict the true label since the
pattern does not exist.
Our aim is to defend against the backdoor attack
using morphological filter operations, as shown in fig-
ure 4. We have added a 3x3 filter, as shown in figure 5,
to clean the poisoned data before it can pass through
Dataset
Poisoned
Data
Neural
Network
Algorithm
Poisoned
Model
Clean
Data Set
Adversary
Insert Backdoor
Patterns
Request Backdoor
Prediction
Legitimate
User
Normal
Prediction
Provide
Real Dataset
Request
Normal prediction
Train
Morphological
Filter
Morphological
Filter
Output
Figure 4: Clean the dataset using morphological operation
before it’s passed to the model for processing.
the poisoned model. We use the process of erosion
and dilation to clean the image. We eroded the image
to remove the poison from the poisoned record. Then,
we dilated the image to return it to its original shape.
The white area of the filer represents the value 1, and
the black area represents the value 0. Once the filter
is applied to the image in erosion operation, the pixel
value in the new resulting image will be the minimum
value of the pixels that landed on the white area of the
filter.
Figure 5: Shows a 3x3 filter used for both erosion and di-
lation operations. The black part represents zero, and the
white part represents one.
We used one opening operation (erosion, then di-
lation) for cleaning the data and making it free of poi-
son (Chudasama et al., 2015). Erosion will reduce the
shapes of poisoned pixels and separate the boundaries
of the objects. Erosion requires two inputs: data and
filter. The filter is applied to the input image for ero-
sion and dilation. The following is a mathematical
definition of erosion:
AΘB = {x | (B)
x
∩ A
c
̸= ∅} (1)
The equation 1 describes the morphological ero-
sion of set A by structuring element B. In this pro-
cess, a point x is included in the eroded set only if
the translated version of B, denoted as (B)
x
, does not
intersect with the complement of A, A
c
. This effec-
tively shrinks the boundaries of A by removing points
where the structuring element B overlaps with regions
outside A. Figure 6 shows an example of erosion op-
eration in the poisoned image. If the filter lands on
Evaluating and Defending Backdoor Attacks in Image Recognition Systems
271

two black pixels, the result will be a black pixel in the
new image immediately before the other four neigh-
bor pixels; thus, the poison will be removed from that
area. The highlighted orange pixel will also result in
a black pixel as one pixel of the filter landed on the
black pixel. The highlighted green filter in the figure
shows that when the filter lands on bright pixels, the
result pixel value will be the minimum; in this case,
it is a bright pixel. Similarly, for the neighbor pixels,
the shape of the number 7 will remain in the image,
but it will shrink because of the erosion operation.
Figure 6: Shows the erosion operation on the poisoned im-
age.
Then, we use the dilation operation. Chudasama
et al. [24] state that the dilation operation causes
the objects to become more prominent, so the pixels
around the targeted pixel are filled in with the max
value of the surrounded pixel, which helps us restore
the shape to its original size. Two separate items are
used as data for dilation. The input image to be di-
lated is the first, and the filter is the second. The only
thing that decides how much the image is to be di-
lated is the filter. The following is the mathematical
definition of dilation:
A ⊕ B = {x | (
ˆ
B)
x
∩ A ̸= ∅} (2)
Assume that A represents a collection of coordi-
nates for an input picture, B is a set of coordinates for
the filter, and (B)
x
is a translation of B such that x is its
origin. Hence, the set of all x points where the inter-
section of Bx and A is not null is the dilation of A by
B. Figure 7 shows an example of a dilation operation
on the eroded image.
For the dilation operation, if the filter lands on at
least one bright pixel, the resulting pixel value will be
the maximum value of the pixels on which the filter
landed. Therefore, the resulting image will enlarge
the shape of the number seven and bring it back to its
original size.
By applying the erosion and dilation operation on
the input image before passing it to the model, we en-
sure the poison is removed before the model processes
the image, as shown in figure 8.
Figure 7: Shows the dilation operation on the eroded image
to bring the shape to its original size.
Figure 8: Shows the original poisoned image and the re-
sult after the poison was removed by one opening operation
(erosion, then dilation).
6 EXPERIMENTAL SETUP
We use the MNIST digit recognition dataset with
60000 samples for our experiment. It comprises
28x28 pixel grayscale pictures of handwritten num-
bers (zero through nine). The dataset is divided into
two primary subsets: a test set with 10,000 images
and a training set with 50,000 images. Moreover, we
use a neural network model with an input layer, one
hidden layer, and one output layer. The hidden layer
has 64 neurons with sigmoid functions. The output
layer has 10 neurons with softmax functions.
7 PERFORMANCE eVALUATION
We tested our hypothesis under various modalities to
change the number of records versus the number of
pixels to achieve a successful attack. Upon successful
attack, we observed that the minimum number of poi-
soned pixels for each record required to be 20 pixels
with 1000 records for an attack to succeed. The at-
tack succeeded with the model falsely predicting that
the number seven label is the number two label. Fig-
ure 9 shows a representation of our finding where the
model’s accuracy is decreasing slowly when the num-
ber of poisoned records increased from 1000 to 5000
records.
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
272
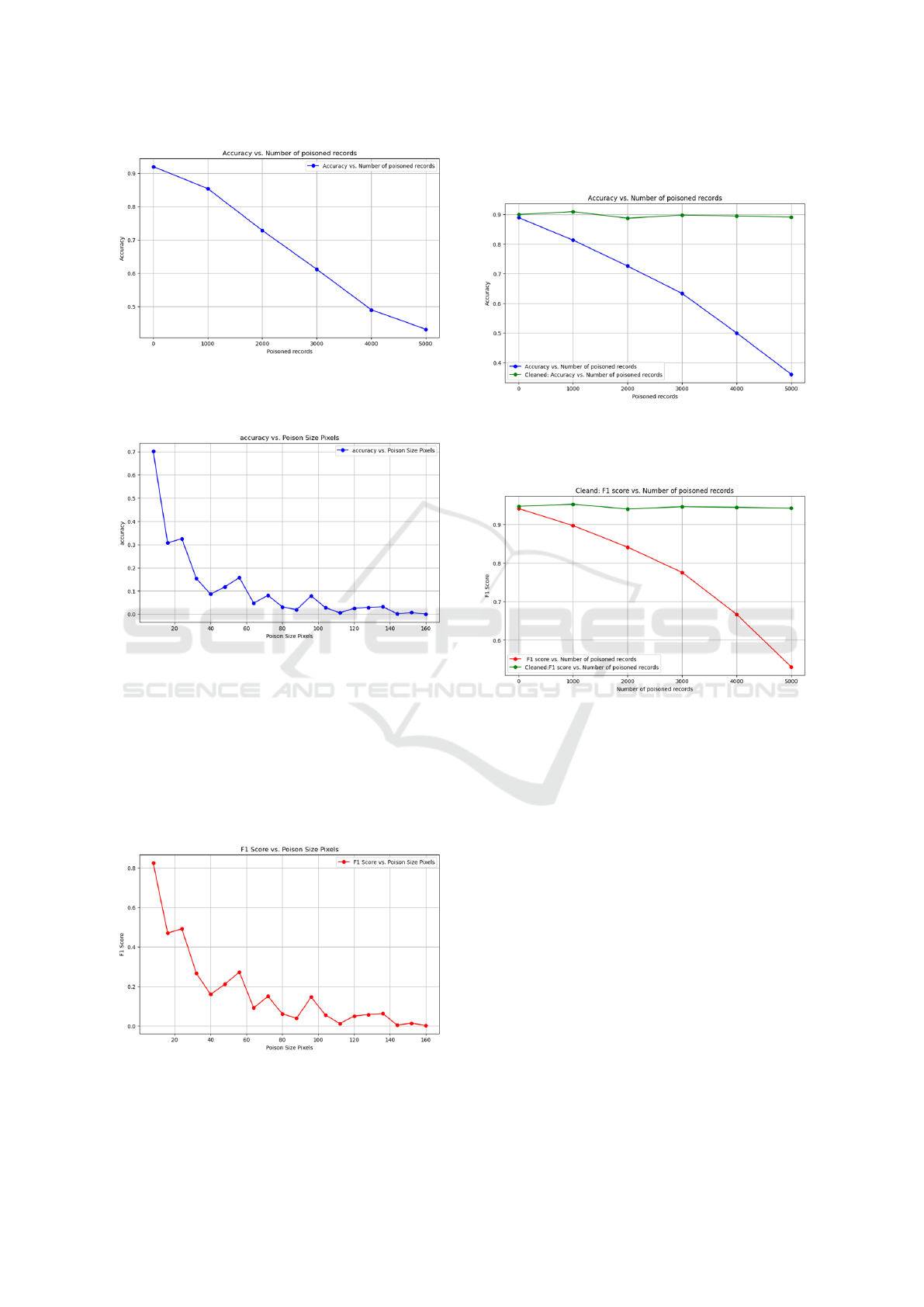
Figure 9: Shows the effectiveness of backdoor attack by
plotting accuracy of prediction versus the number of poi-
soned records with a minimum fixed poison size of 20 pix-
els.
Figure 10: Shows the effectiveness of backdoor attacks
by plotting prediction accuracy versus the number of poi-
soned pixels (poison pattern) when the number of poisoned
records is fixed at 5000.
We have also experimented with changing the size
of the pattern for a fixed number of poisoned records,
which in our case was 5000 samples. We noticed that
accuracy started to decrease rapidly from 20 pixels
and reached 0% when 50 pixels were poisoned. Thus,
the size of the pattern has a significant impact on the
Figure 11: Shows the effectiveness of backdoor attacks by
plotting F1 Score versus the number of poisoned pixels
(poison pattern) when the number of poisoned records is
fixed at 5000.
model’s accuracy and F1 score, as shown in figure 10
and 11.
Figure 12: Shows the defense success rate of morphological
filter operations when poisoned records are variable, and the
size of the poison is 20 pixels.
Figure 13: Shows the defense success rate of morphological
filter operations by plotting the F1 score of the poisoned
and cleaned data predictions when the number of poisoned
records is variable and the size of the poison is fixed at 20
pixels.
On the other hand, the performance evaluation of
our defense mechanism against backdoor attacks has
shown robustness. It maintained the model’s accuracy
of 90% and made the correct prediction on the labels
even when the number of poisoned records was sig-
nificantly high, as shown in figure 12. The green line
in the graph indicates the accuracy of the model when
the data is cleaned using morphological operation be-
fore prediction. The blue line represents the accuracy
of the model on poisoned data. Moreover, figure 13
shows the stability of the F1-score versus a number of
increasing poisoned records. The F1-score was sta-
ble at 0.96 with 5000 poisoned records. Moreover,
when we evaluated our defense mechanism with in-
creasing size of the poisoned records, it maintained a
stable high prediction accuracy of around 90% and an
F1 score of 0.95, as shown in figure 14 and 15. Thus,
the proposed defense against the backdoor attack was
Evaluating and Defending Backdoor Attacks in Image Recognition Systems
273

robust in terms of the number of poisoned pixels and
the number of samples.
Figure 14: Shows the effectiveness of morphological op-
eration to defend backdoor attacks through prediction ac-
curacy, with a variable number of poison pixels, and the
number of poisoned samples is fixed at 5000.
Figure 15: Shows the effectiveness of morphological opera-
tion to defend backdoor attacks through F1 Score when the
number of poison pattern size is variable, and the number
of poisoned records is fixed at 5000.
8 LIMITATIONS
One of the central challenges is developing a poison
that remains undetected by the model. When applying
the erosion operation, some parts of the image might
be removed if the image is not strong, as shown in
figure 16. On the other hand, if the input image is
strong, then the erosion effect will not be significant,
as shown in figure 17.
9 CONCLUSION
Our primary focus in this work was to examine data
poisoning attacks on a neural network model, wherein
we implemented the backdoor attacks. We developed
Figure 16: Shows weak erosion effect if the image is not
well represented with pixels and low thickness.
Figure 17: Shows strong erosion effect if the image is well
represented with pixels and high thickness.
the attacks with poisoned pixels and analyzed how
the model behaves with changes in poison parame-
ters. Specifically, we explored when the model begins
to respond to the targeted poisoned data. Our obser-
vations revealed that the quantity of poisoned records
has the most significant influence on the model. In
the case of backdoor attacks, both the number of poi-
soned records and the pattern play crucial roles in in-
ducing the model to falsely predict according to the
attacker’s targeted label. Smaller-sized patterns must
be injected into a larger number of records in the
training dataset, whereas larger-sized poison patterns
should be injected into a smaller number of records.
However, it is crucial to minimize the pattern size to
enhance the difficulty of detection by the victim. In
addition, we propose a defense strategy using mor-
phological filters to defend against model poisoning
attacks. Our proposed defense has shown robustness
toward the backdoor attack and was able to maintain
the accuracy of the model when both the number of
poisoned records and poison pattern in pixels were
significantly high.
REFERENCES
Barreno, M., Nelson, B., Sears, R., Joseph, A. D., and Ty-
gar, J. D. (2006). Can machine learning be secure? In
Proceedings of the 2006 ACM Symposium on Informa-
tion, computer and communications security, pages
16–25.
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
274

Biggio, B. and Roli, F. (2018). Wild patterns: Ten years
after the rise of adversarial machine learning. In
Proceedings of the 2018 ACM SIGSAC Conference
on Computer and Communications Security, pages
2154–2156.
Chacon, H., Silva, S., and Rad, P. (2019). Deep learning
poison data attack detection. In 2019 IEEE 31st In-
ternational Conference on Tools with Artificial Intel-
ligence (ICTAI), pages 971–978. IEEE.
Chen, J., Lu, H., Huo, W., Zhang, S., Chen, Y., and Yao,
Y. (2022). A defense method against backdoor attacks
in neural networks using an image repair technique.
In 2022 12th International Conference on Information
Technology in Medicine and Education (ITME), pages
375–380.
Chen, X., Liu, C., Li, B., Lu, K., and Song, D. (2017). Tar-
geted backdoor attacks on deep learning systems us-
ing data poisoning. arXiv preprint arXiv:1712.05526.
Chen, Y., Gong, X., Wang, Q., Di, X., and Huang, H.
(2020). Backdoor attacks and defenses for deep neu-
ral networks in outsourced cloud environments. IEEE
Network, 34(5):141–147.
Chudasama, D., Patel, T., Joshi, S., and Prajapati, G. I.
(2015). Image segmentation using morphological op-
erations. International Journal of Computer Applica-
tions, 117(18).
Gu, T., Liu, K., Dolan-Gavitt, B., and Garg, S. (2019). Bad-
nets: Evaluating backdooring attacks on deep neural
networks. IEEE Access, 7:47230–47244.
Guan, J., Liang, J., and He, R. (2024). Backdoor defense
via test-time detecting and repairing. In Proceedings
of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition, pages 24564–24573.
Hong, S., Carlini, N., and Kurakin, A. (2022). Handcrafted
backdoors in deep neural networks. Advances in Neu-
ral Information Processing Systems, 35:8068–8080.
Hu, B. and Chang, C.-H. (2024). Diffense: Defense against
backdoor attacks on deep neural networks with latent
diffusion. IEEE Journal on Emerging and Selected
Topics in Circuits and Systems, pages 1–1.
Lata, K., Singh, P., and Saini, S. (2024). Exploring
model poisoning attack to convolutional neural net-
work based brain tumor detection systems. In 2024
25th International Symposium on Quality Electronic
Design (ISQED), pages 1–7. IEEE.
Matsuo, Y. and Takemoto, K. (2021). Backdoor attacks to
deep neural network-based system for covid-19 de-
tection from chest x-ray images. Applied Sciences,
11(20):9556.
Namiot, D. (2023). Introduction to data poison attacks on
machine learning models. International Journal of
Open Information Technologies, 11(3):58–68.
Tian, Z., Cui, L., Liang, J., and Yu, S. (2022). A compre-
hensive survey on poisoning attacks and countermea-
sures in machine learning. ACM Computing Surveys,
55(8):1–35.
Truong, L., Jones, C., Hutchinson, B., August, A., Prag-
gastis, B., Jasper, R., Nichols, N., and Tuor, A. (2020).
Systematic evaluation of backdoor data poisoning at-
tacks on image classifiers. In Proceedings of the
IEEE/CVF conference on computer vision and pattern
recognition workshops, pages 788–789.
Van, M.-H., Carey, A. N., and Wu, X. (2023). Hint: Healthy
influential-noise based training to defend against data
poisoning attacks.
Xie, C., Huang, K., Chen, P.-Y., and Li, B. (2019). Dba:
Distributed backdoor attacks against federated learn-
ing. In International conference on learning repre-
sentations.
Yan, H., Zhang, W., Chen, Q., Li, X., Sun, W., Li, H., and
Lin, X. (2024). Recess vaccine for federated learn-
ing: Proactive defense against model poisoning at-
tacks. Advances in Neural Information Processing
Systems, 36.
Yerlikaya, F. A. and Bahtiyar, S¸. (2022). Data poisoning
attacks against machine learning algorithms. Expert
Systems with Applications, 208:118101.
Yuan, Y., Kong, R., Xie, S., Li, Y., and Liu, Y. (2023).
Patchbackdoor: Backdoor attack against deep neural
networks without model modification. In Proceedings
of the 31st ACM International Conference on Multi-
media, pages 9134–9142.
Zhang, Y., Feng, F., Liao, Z., Li, Z., and Yao, S. (2023).
Universal backdoor attack on deep neural networks
for malware detection. Applied Soft Computing,
143:110389.
Zhao, B. and Lao, Y. (2022). Towards class-oriented poi-
soning attacks against neural networks. In Proceed-
ings of the IEEE/CVF Winter Conference on Applica-
tions of Computer Vision, pages 3741–3750.
Evaluating and Defending Backdoor Attacks in Image Recognition Systems
275
