
Towards Holistic Approach to Robust Execution of MAPF Plans
David Zahr
´
adka
1,2 a
, Denisa Mu
ˇ
z
´
ıkov
´
a
1
, Miroslav Kulich
2 b
, Ji
ˇ
r
´
ı
ˇ
Svancara
3 c
,
and Roman Bart
´
ak
3 d
1
Dept. of Cybernetics, Faculty of Electrical Engineering, Czech Technical University in Prague, Prague, Czech Republic
2
Czech Institute of Informatics, Robotics and Cybernetics, Czech Technical University in Prague, Prague, Czech Republic
3
Faculty of Mathematics and Physics, Charles University, Prague, Czech Republic
Keywords:
Path-Planning, Multi-Agent Environment, Plan Execution, Action Dependency Graph, Replanning.
Abstract:
Multi-agent path finding (MAPF) deals with the problem of navigating a set of agents in a shared environ-
ment to reach their destinations without collisions. Even if the plan is collision-free, some delay during plan
execution may lead to collision of agents if they execute the plans blindly. In this position paper, we discuss
the concept of robust execution of MAPF plans by exploiting an action dependency graph. We suggest how
to evaluate the effect of delay by computing a slack-like value for not yet visited locations, and we propose a
three-layer architecture – retiming, rescheduling, and replanning to handle delays effectively.
1 INTRODUCTION
Coordinating a fleet of moving agents is an impor-
tant problem with practical applications such as ware-
housing (Wurman et al., 2008), airplane taxiing (Mor-
ris et al., 2016), or traffic junctions (Dresner and
Stone, 2008). Multi-Agent Path Finding (MAPF) is
an abstract model of this coordination problem, where
we are looking for collision-free paths for agents
moving over a graph. The problem of finding an opti-
mal MAPF solution has been shown to be NP-hard for
a wide range of cost objectives (Surynek, 2010). In
MAPF research, two classes of methods can be iden-
tified. Methods from the first class do not guarantee
optimality (or even completeness), but are computa-
tionally nondemanding and scale well to a large num-
ber of agents, for example, WHCA* (Silver, 2005),
SIPP (Phillips and Likhachev, 2011), MAPF-LNS (Li
et al., 2021a), LACAM* (Okumura, 2023). Provably
optimal and bounded suboptimal algorithms form
the second class. Prominent optimal algorithms are,
for example, CBS (Conflict-Based Search) (Sharon
et al., 2015; Li et al., 2019), or approaches transform-
ing MAPF into SAT (Boolean Satisfiability) (Bart
´
ak
et al., 2017), ASP (Answer Set Programming) (Erdem
a
https://orcid.org/0000-0002-7380-8495
b
https://orcid.org/0000-0002-0997-5889
c
https://orcid.org/0000-0002-6275-6773
d
https://orcid.org/0000-0002-6717-8175
et al., 2013), and MIP (Mixed Integer Programming)
(Yu and LaValle, 2016). Bounded suboptimal solvers
are often based on CBS - ECBS (Barer et al., 2014)
and its new variant, EECBS (Li et al., 2021b) or vari-
ants of SAT solvers (Surynek, 2020).
When real robots execute the found plans, the
robots might be delayed due to unexpected circum-
stances such as mechanical problems, localization un-
certainties, unprecise control, or encounters with un-
modelled agents, e.g. humans. These delays lead to
a desynchronization of plans, and consequently, the
robots may crash into each other or get stuck.
Such situations can be prevented by generating k-
robust plans, i.e. plans that are collision-free even if
any agent is delayed by a limited number of k time
steps (Atzmon et al., 2020; Chen et al., 2021). Never-
theless, these plans are typically unnecessarily longer
than non-robust plans and still lead to a collision if
some agent is delayed more than k time steps.
A more realistic approach is presented by Ma et al.
(2017). The authors assume probability of a delay for
each agent’s action, propose CBS-based solver which
minimizes an approximated expected makespan, and
show that real makespans of executed plans are lower
than of plans generated by standard solvers not as-
suming delays.
Wagner et al. (2022) introduce the Space-Level
Conflict-Based Search, an ECBS-based planner that
provably reduces the number of coordination actions,
that is, locations where the decision on the passing
624
Zahrádka, D., Mužíková, D., Kulich, M., Švancara, J. and Barták, R.
Towards Holistic Approach to Robust Execution of MAPF Plans.
DOI: 10.5220/0013319700003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 1, pages 624-631
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

order of two agents must be made.
However, an arbitrary good plan is not guaranteed
to be realized perfectly, and thus monitoring of plan
execution has to be done to ensure its collision-free
and deadlock-free realization. The first attempt to
make such a plan executor is MAPF-POST (H
¨
onig
et al., 2016). MAPF-POST postprocesses a plan
of a MAPF solver and builds in a polynomial time
a temporal network, a graph where nodes represent
events corresponding to an agent entering a location
and edges represent temporal precedences between
events. The graph is augmented by additional ver-
tices that provide a guaranteed safety distance be-
tween agents. The authors proved that the execution
is collision and deadlock-free if it is consistent with
the graph.
Gregoire et al. (2017) introduce RMTRACK, a ro-
bust multi-robot trajectory tracking, based on similar
ideas to H
¨
onig et al. (2016), but in a different termi-
nology: RMTRACK works in a coordination space
and ensures that the realized trajectory remains in the
same homotopy class as the planned trajectory.
The Action Dependency Graph (ADG) (H
¨
onig
et al., 2019) is, similarly to MAPF-POST, a tempo-
ral network, but utilizes a precedence relation on ac-
tions rather than locations. This makes the graph sim-
pler with less communication among agents and has
stronger guarantees on collision-free operation.
Wu et al. (2024) follow up with Wagner et al.
(2022) and present the Space-Order CBS that directly
plans a temporal graph, and thus minimizes the num-
ber of coordination actions explicitly.
Although the mentioned techniques guarantee
safe execution, the final quality of realized trajecto-
ries can substantially degrade with the increasing fre-
quency of delays. Recent approaches thus investigate
possibilities how to reschedule agent’s actions, i.e.,
switch the order the agents passing a given location.
Berndt et al. (2020) and Berndt et al. (2024)
present Switchable Action Dependency Graph
(SADG) by creating a reverse to each dependence
between actions of different agents. Rescheduling,
the decision whether to take the original or reverse
for each action is then formulated as a mixed inte-
ger linear program that is solved in a closed-loop
feedback scheme.
Similarly, Zahr
´
adka et al. (2023) formulate
rescheduling as a modification of the job-shop
scheduling problem and utilize the Variable Neigh-
borhood Search metaheuristic to solve it.
Another approach to repair the plan is to introduce
additional delays. Kottinger et al. (2024) formulate
the optimization problem aiming to find a minimal
number of additional delays in the reduced graph built
as a superposition of the original paths. The problem
is solved by an arbitrary MAPF solver substantially
faster than replanning from scratch.
Finally, Feng et al. (2024) propose the Switchable
Edge Search. The approach aims to find a new tem-
poral graph based on the given SADG making use of
an A*-style algorithm.
The disadvantage of the above-mentioned ap-
proaches is that they run the optimization during ex-
ecution. To avoid this, a Bidirectional Temporal
Plan Graph (BTPG) (Su et al., 2024) allowing one to
switch these orders during execution based on a “first-
come-first-served” manner as build before the execu-
tion. This is done by consecutively checking whether
edges indicating dependencies between actions of dif-
ferent agents can be transformed into a bidirectional
pair without causing an oriented cycle in the BTPG.
Despite the enormous activity in finding a robust
planning & execution framework for MAPF in re-
cent years, several open questions still need to be an-
swered. One of the most interesting open questions is
when to reschedule/replan and whether rescheduling
still provides a good quality solution or whether it is
a good moment for replanning. This position paper
attempts to take the first step in this direction. Specif-
ically, we introduce an architecture that monitors the
execution process and decides when it deviates sig-
nificantly from the plan, so it is beneficial to resched-
ule/replan. This architecture exploits an action depen-
dency graph to calculate the slack of actions, which is
then used to decide which type of execution modifi-
cation to select.
2 BACKGROUND
2.1 Multi-Agent Path Finding
The Multi-Agent Path Finding instance (MAPF in-
stance) M is a pair M = (G, A), where G is a graph
G = (V, E) representing the shared environment and
A is a set of mobile agents. Each agent k ∈ A is de-
fined as a pair k = (s
k
, g
k
), where s
k
∈ V is a starting
location of agent k and g
k
∈ V is a goal location of
agent k.
The task is to find a valid plan π
k
for each agent
k ∈ A such that it is a valid path from s
k
to g
k
. Time
is considered discrete and at each timestep i, an agent
can either wait in its current location or move to a
neighboring location. Therefore, the plan is a se-
quence of move or wait actions. At the end of an
agent’s plan, the agent remains in its goal location and
does not disappear. Furthermore, we require that each
pair of plans π
k
and π
k
′
, k ̸= k
′
is collision-free. Based
Towards Holistic Approach to Robust Execution of MAPF Plans
625
on MAPF terminology (Stern et al., 2019), there are
five types of possible collisions we may want to for-
bid (see Fig. 1). In this work, we do not avoid follow-
ing conflicts, since they can be executed safely, and
edge conflicts are automatically resolved by prevent-
ing vertex conflicts.
Figure 1: Conflicts between two or more agents. (a) edge
conflict, (b) vertex conflict, (c) following conflict, (d) cycle
conflict, (e) swapping conflict. Figure taken from Stern et al.
(2019).
The quality of the plan is measured by the lengths
of the plans |π
k
|, i.e. the number of actions each agent
needs to perform until reaching its goal location. The
two most often used cost functions in the literature are
makespan defined as the maximum of the plan lengths
(T
max
= max
k∈A
|π
k
|) and sum of costs (or flowtime) as
the sum of the plan lengths (T
sum
=
∑
k∈A
|π
k
|).
2.2 Action Dependency Graph
The Action Dependency Graph (ADG) (H
¨
onig
et al., 2019) is a directed acyclic graph G
ADG
=
(V
ADG
, E
ADG
), where V
ADG
are the move actions in
agents’ plans and E
ADG
are directed edges that rep-
resent dependencies between actions. Each action
a
k
i
∈ V
ADG
is a tuple (p
i
, p
i
′
) that means that an agent
k is moving from position p
i
in the time step i to posi-
tion p
i
′
in the next time step. If (a
k
i
, a
k
i
′
) ∈ E
ADG
, there
is a temporal precedence between these two actions:
k can start executing a
k
i
′
only after a
k
i
is completed.
The edges E
ADG
are divided into two categories.
Type 1 edges (E
1
) represent the temporal precedence
between actions within the plan of a single agent: it
may start moving from a specific position only after
it has finished moving into it. Type 2 edges (E
2
)
indicate dependencies between actions of different
agents: an agent may start moving into a position only
after another agent, scheduled to be there earlier, fin-
ished moving out. An example instance and the re-
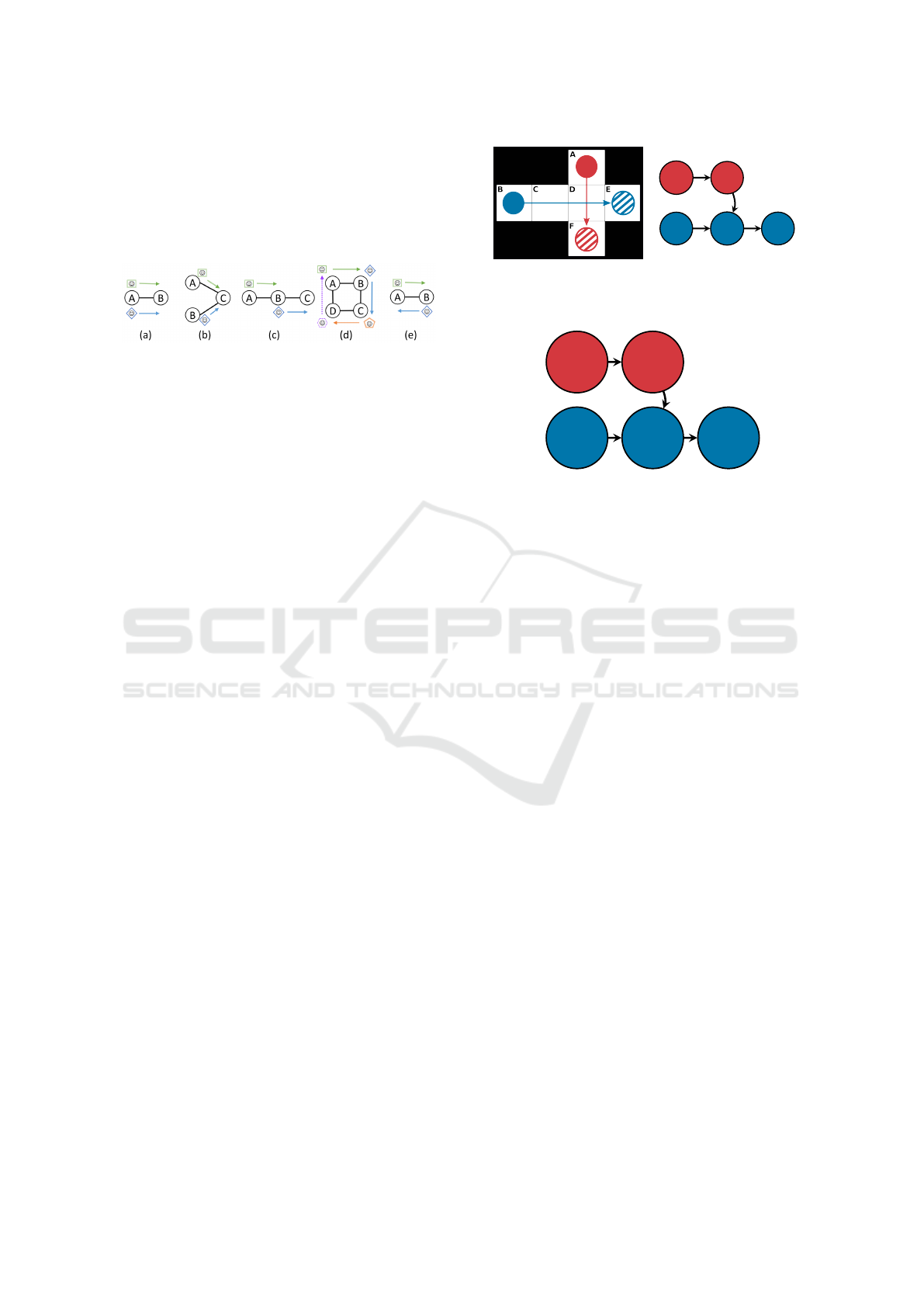
sulting ADG can be seen in Fig. 2.
During execution, agents report whenever they
finish an action, and a robust execution manager keeps
track of the execution state by marking E
ADG
as com-
pleted. Once an action has all its incoming edges
marked as complete, it is assigned to an agent. In this
way, ADG guarantees safe execution of any feasible
1-robust MAPF plan even if the execution of some or
all actions is arbitrarily delayed, as long as the delay
is finite.
(a)
A ⇒ D D ⇒ F
B ⇒ C C ⇒ D D ⇒ E
(b)
Figure 2: Example MAPF solution (a) and its ADG (b).
Filled circles are agents and striped circles are their goals.
t
s
= 0
A ⇒ D
t
c
= 1
t
s
= 1
D ⇒ F
t
c
= 2
t
s
= 0
B ⇒ C
t
c
= 1
t
s
= 2
C ⇒ D
t
c
= 3
t
s
= 3
D ⇒ E
t
c
= 4
Figure 3: ADG with estimated starting times t
s
(a) and com-
pletion times t
c
(a).
3 EXECUTION ARCHITECTURE
In this section, we propose a holistic architecture that
enables i) using robust execution methods to safely
execute plans; ii) monitor the execution progress and
delays of robots, and iii) decide when delays in ex-
ecution are significant enough that it is beneficial to
reschedule or even replan. Everything is performed
during execution on the robust execution layer.
3.1 Execution Monitoring
The delays that robots accumulate during execution
do not endanger the safety of the plan as long as a
robust execution method is used. However, each de-
lay may increase the length of the execution for two
reasons. The first reason is prolonging of the robot’s
own plan execution. Execution makespan may be in-
creased if the robot with the longest plan is delayed
or if another robot is delayed sufficiently. When mea-
suring flowtime, it is increased with each delay of any
robot.
The second reason is due to the interactions be-
tween the robots. If there is a crossroad through which
multiple robots pass, the robots have a strict order in
which they do so. This ordering is given by the MAPF
plan and is represented by the Type 2 edges in G
ADG
.
Because of this, a delayed robot may in turn delay
other robots. In extreme cases, this may result in a
cascade that includes the entire robotic fleet, increas-
ing the impact of even a single delayed action.
The length of the execution can be estimated by
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
626

input : G
ADG
output: G
ADG
with computed
ˆ
t
s
and
ˆ
t
c
1 begin
2 for i = 0 → T
max
do
3 V (i) ← all actions at time step i
4 for a
′
∈ V (i) do
5 A
P
= {a : ∀a ∈ V
ADG
: e(a, a
′
) ∈
E
ADG
}
6 if A
P
==
/
0 then
7
ˆ
t
s
(a
′
) = 0
8
ˆ
t
c
(a
′
) =
ˆ
t
x
(a
′
)
9 continue
10 end
11
ˆ
t
s
(a
′
) = max
a∈A
P
(
ˆ
t
c
(a)) + 1
12
ˆ
t
c
(a
′
) =
ˆ
t
s
(a
′
) +
ˆ
t
x
(a
′
)
13 end
14 end
15 end
Algorithm 1: Computing estimates of action start times
ˆ
t
s
and completion times
ˆ
t
c
.
exploiting the G
ADG
using Algorithm 1. We can ob-
tain the expected length of execution of the actions
ˆ
t
x
(a) by constructing a model of the robot’s move-
ment capabilities. The expected completion of the ac-
tion a is then equal to the sum of its estimated start
ˆ
t
s
(a) and its estimated length
ˆ
t
x
(a):
ˆ
t
c
(a) =
ˆ
t
s
(a) +
ˆ
t
x
(a). We augment V
ADG
with this value and proceed
to the following action, which can start only after all
preceding actions are finished:
ˆ
t
s
(a
′
) = max(
ˆ
t
c
(a) :
∃(a, a
′
) ∈ E
ADG
). This is repeated until we have
ˆ
t
c
(a) : ∀a ∈ V
ADG
. In this way, it is possible to ob-
tain the estimated execution time
ˆ
T
C
of the plan before
starting the execution. Ideally, this should be equal to
the cost of the plan, as given by the MAPF solver.
An example ADG with estimated action completion
times can be seen in Fig. 3.
However,
ˆ
T
C
provides only the lower bound of the
plan’s execution length T
C
, as delays during execution
will increase the real execution time T
C
. To improve
the estimate as execution progresses, G
ADG
can be up-
dated as actions are being executed. The same proce-
dure that was used for initial estimation can be used
to update the estimate by replacing
ˆ
t
c
(a) with the real
action completion time t
c
(a). After finishing an ac-
tion, it’s corresponding vertex in V
ADG
is updated with
t
c
(a). Then, we follow all outgoing edges in G
ADG
to update
ˆ
t
s
(a) and
ˆ
t
c
(a) of all dependent future ac-
tions as well. This propagates not only the informa-
tion about the delay into the rest of the robot’s plan
thanks to E
1
, but also to all other robots with which it
interacts using E
2
, while not interfering with the es-
timated times of independent actions. By doing this,
we get an update on the plan’s estimated completion
Figure 4: If the red agent is significantly delayed, it should
take the longer way around.
time
ˆ
T
C
. The above process is called retiming as it
updates the start times of actions based on the current
situation but without changing the plans (paths).
3.2 Resolving Delays
As robots progressively deviate from the original plan
due to delays, a new plan that better reflects the cur-
rent configuration might decrease the execution time
T
c
. That is true even if the original plan is optimal. We
can obtain such a plan by replanning. Consider the ex-
ample in Fig. 4. In the optimal plan, both robots drive
through the corridor, and since they cannot fit next to
each other, one robot must drive earlier than the other.
If the robot that is supposed to enter the corridor first
is delayed during execution and no robust execution
method capable of retiming was used, the robots may
collide. If the execution method was only capable
of retiming, the second robot would have to wait to
maintain their order as given by the MAPF plan, also
getting delayed itself. However, with a long enough
delay, it may become beneficial to either reschedule
to let the second robot drive first or replan to let one
of the robots use the long detour. In the solution in
Fig. 2a, if the red robot is delayed, rescheduling may
allow the blue robot to pass first, reducing the to-
tal execution time. In the solution shown in Fig. 4,
rescheduling would produce the same schedule as the
original due to the blue robot blocking the corridor
after reaching its goal. If the delayed red robot took
a longer detour around the wall, the blue robot could
reach its goal faster at a small cost increase for the red
robot, reducing T
c
.
As robots are progressively delayed, it may hap-
pen that another plan would lead to a smaller T
C
if
selected. The problem is that to know whether such a
plan exists or not, we would need to have it. Since
MAPF is an NP-hard problem (Surynek, 2010), it
is impractical to judge whether replanning would be
beneficial by finding a new plan. More so when the
state of the execution itself is changing in the mean-
time. It is therefore crucial to approximate or estimate
the benefit that replanning would bring by other, sim-
pler means.
Towards Holistic Approach to Robust Execution of MAPF Plans
627
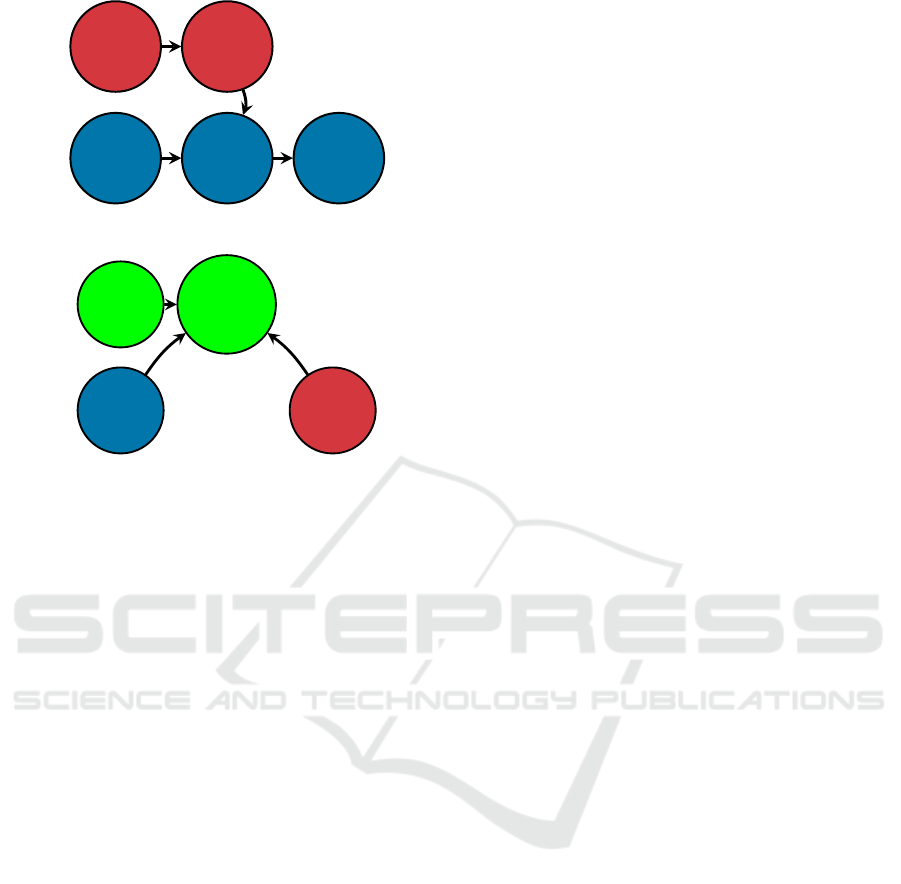
t
s
= 0
A ⇒ D
t
c
= 1
t
s
= 1
D ⇒ F
t
c
= 2
t
s
= 0
B ⇒ C
t
c
= 1
t
s
= 2
C ⇒ D
t
c
= 3
t
s
= 3
D ⇒ E
t
c
= 4
δ = 1
(a)
t
s
= 5
A ⇒ B
t
c
= 6
t
s
= 8
A ⇒ C
t
c
= 9
t
s
= 10
D ⇒ A
t
c
= 11
∆ = 5
t
s
= 3
E ⇒ D
t
c
= 4
δ
1
= 2
δ
2
= 5
(b)
Figure 5: (a) ADG with computed slack δ for a Type 2
edge. (b) Example of ∆ computation for a robot (green) that
moves into a vertex after two other agents (red and blue)
pass through.
For this purpose, we suggest using the edges of
G
ADG
, which provide information about mutual de-
pendencies of actions. The Type 1 edges only con-
tain information about the ordering of specific actions
in a single robot’s plan. If a robot is completely in-
dependent of others, even if it accumulates a signifi-
cant delay, replanning would not be beneficial. That
is because the robot is probably already on its optimal
path and, therefore, will arrive at its goal as soon as
possible. However, Type 2 edges contain information
about interactions between different robots. There-
fore, they can be used to express how one robot’s
delay is affecting the others, who were counting on
the delayed robot to be further in the plan than it is.
Rescheduling or replanning may help in this case, be-
cause these robots may perhaps continue their plans
sooner if they were rescheduled in front of the delayed
robot, or find another path to their goal.
For every Type 2 edge E
2
= (a
r
1
i
, a
r
2
j
) between the
actions of robots r
1
and r
2
we can calculate a time re-
serve, or slack, δ(E
2
) = t
c
(a
r
1
i
) − t
c
(a
r
2
j−1
). An exam-
ple can be seen in Fig. 5a and it can be computed after
Line 12 in Algorithm 1. It is a simple way to estimate
how long r
2
must wait before starting an action due
to the temporal dependence on r
1
. The δ(E
2
) is inter-
preted as positive for the vertices on the head end of
E
2
(waiting robots – r
2
) and negative for the vertices
on the tail end (robots that cause waiting – r
1
). As ex-
ecution progresses and the estimates
ˆ
t
c
(a) : a ∈ V
ADG
are updated with the real measured t
c
(a), δ is also up-
dated to reflect the current situation, providing an es-
timate of waiting times in the rest of the plan.
However, simply looking at the time for how long
the robots will be waiting may be misleading, since an
optimal MAPF plan may require some robots to wait
to synchronize the fleet. In other words, it may be
beneficial to wait until another robot passes through a
corridor and enter afterwards rather than taking a long
detour. Therefore, we want to compare the current
slack with the initial slack δ
0
, calculated at the start
of the execution, to obtain
¯
δ(E
2
) = δ(E
2
) − δ
0
(E
2
).
Each V
ADG
may have multiple incoming E
2
, which
means that there is temporal precedence of multi-
ple robots in the same place, and
¯
δ(E
2
) only cap-
tures dependencies between two robots. By com-
puting the slack of an action ∆(a) = min(
¯
δ(E
2
) :
∀E
2
= (a
′
, a), ∃(a
′
, a) ∈ E
ADG
), it is possible to ex-
press whether a robot will be waiting according to the
plan or in contrast to it. An example can be seen in
Fig. 5b. Decreasing ∆(a) means that a robot is getting
delayed relative to some other robot. If it is negative,
it means that a robot that had spare time is now behind
its plan, either due to its slowdown, or because some-
one else is potentially ahead. In either case, it shows
that the execution is not proceeding as expected, and
interventions may be necessary to mitigate the delays.
By computing ∆(a), we can estimate whether a de-
layed robot is interfering with the other robots execu-
tion, and use this information to decide whether it is
beneficial to reschedule or replan without costly com-
putation of alternative plans. The state of the whole
execution considering all robots is then expressed by
∆
F
= min
a∈V
(∆(a)).
Using ADG with slack-augmented vertices, we
obtain a holistic architecture to execution optimiza-
tion. The execution is safe and robust due to retiming
performed by ADG. If some robot is delayed enough
and in a way that affects the rest of the fleet, as mea-
sured by ∆
F
, we can perform rescheduling, which
would optimize the execution of the original plan.
If ∆
F
decreases beyond a certain threshold by sig-
nificant and possibly wide-spread delays, replanning
can be triggered to find a new plan that would allow
robots to take different paths. The frequency of both
rescheduling a replanning can be controlled by thresh-
olds, which would specify when a delay is too signifi-
cant for retiming, and, subsequently, for rescheduling.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
628

(a) (b)
Figure 6: Experimental room-16-16-4 instance (a) and its
solution (b). Filled circles are robots, strafed circles of the
same color are their goals. Lines in (b) represent optimal
paths of robots.
4 PRELIMINARY EXPERIMENTS
We show that by using a temporal G
ADG
with ver-
tices V
ADG
augmented with slack ∆(a) it is possible
to predict when replanning would be beneficial. The
experiments were carried out on a simple MAPF in-
stance with 5 agents seen in Fig. 6a on room-16-16-4
map, a smaller version of room-32-32-4 map from
the movingAI benchmark (Stern et al., 2019). An op-
timal solution, as seen in Fig. 6b, was obtained us-
ing CBS (Conflict-based Search) (Sharon et al., 2015)
which was then executed using a simulator with ADG
as a robust execution method. In one experiment, the
blue robot was delayed for 5 seconds at some point
during execution. In the second experiment, blue
and cyan robots were delayed the same way. First,
we measured the execution length of the plan with
ADG only capable of retiming. Then, we measured
the execution length with ADG augmented with slack
that was capable of triggering replanning. Finally,
we measured how a random replanning policy per-
forms, which replans after a random action is com-
pleted. Both methods replanned exactly once during
the whole execution and both used CBS to find the
new plan. The estimated duration of every action was
ˆ
t
x
= 1 second. We repeated the experiments 5 times
for the same delay of the same robots and reported the
average execution times. For the random replanning
policy, the experiment was repeated 50 times. We as-
sumed that replanning was instant and did not count
the time required to find a new plan towards the ex-
ecution time, pausing the simulation. This approach
was used to avoid the need to ensure that the execu-
tion was persistent (H
¨
onig et al., 2019), which could
influence the measured execution times.
As can be seen in the results reported in Table 1
while retiming ensures safe execution, it yields the
worst execution cost both in makespan and in the sum
Table 1: Measured average execution lengths with a single
delayed robot (blue) and with two delayed robots (blue and
orange). T
max
corresponds to the execution length of the
slowest agent (makespan) and T
sum
corresponds to the sum
of execution lengths for all robots (sum of costs).
Method T
max
[s] T
sum
[s]
Blue delayed
Retiming 27.58 108.84
Retiming + random replan 24.14 99.79
Retiming + ∆-based replan 21.13 94.58
Blue and orange delayed
Retiming 27.91 117.95
Retiming + random replan 25.33 112.35
Retiming + ∆-based replan 22.07 103.26
of costs. Replanning at random timesteps improves
the execution cost. Using the proposed ∆-based re-
planning policy improves the execution cost even fur-
ther since the replanning is triggered at timesteps
when it is more beneficial.
5 CONCLUSIONS
The position paper argues that the current approaches
to handling uncertainty during the execution of
MAPF plans are unsatisfactory and suggests an in-
tegrated holistic architecture that uniformly handles
three approaches to managing execution uncertainty:
retiming, rescheduling, and replanning. The primary
motivation is to execute the plans safely, even if there
are disturbances reflected in delays of agents while
maintaining plan quality. Based on the notion of
slack, the architecture provides a mechanism to de-
cide what type of execution modification should be
used. The preliminary experiment indicates that the
proposed architecture brings lower execution times
even if there are disturbances during plan execution.
ACKNOWLEDGEMENTS
The research was supported by the Czech Science
Foundation Grant No. 23-05104S. The work of David
Zahr
´
adka was supported by the Grant Agency of the
Czech Technical University in Prague, Grant number
SGS23/180/OHK3/3T/13. The work of Ji
ˇ
r
´
ı
ˇ
Svancara
was supported by Charles University project UNCE
24/SCI/008. Computational resources were provided
by the e-INFRA CZ project (ID:90254), supported by
the Ministry of Education, Youth and Sports of the
Czech Republic.
Towards Holistic Approach to Robust Execution of MAPF Plans
629

REFERENCES
Atzmon, D., Stern, R., Felner, A., Wagner, G., Bart
´
ak, R.,
and Zhou, N.-F. (2020). Robust multi-agent path find-
ing and executing. Journal of Artificial Intelligence Re-
search, 67:549–579.
Barer, M., Sharon, G., Stern, R., and Felner, A. (2014). Sub-
optimal Variants of the Conflict-Based Search Algorithm
for the Multi-Agent Pathfinding Problem. In Seventh An-
nual Symposium on Combinatorial Search.
Bart
´
ak, R., Zhou, N.-F., Stern, R., Boyarski, E., and
Surynek, P. (2017). Modeling and Solving the Multi-
Agent Pathfinding Problem in Picat. In IEEE 29th Inter-
national Conference on Tools with Artificial Intelligence
(ICTAI), pages 959–966.
Berndt, A., Duijkeren, N. V., Palmieri, L., and Keviczky, T.
(2020). A feedback scheme to reorder a multi-agent ex-
ecution schedule by persistently optimizing a switchable
action dependency graph. CoRR, abs/2010.05254.
Berndt, A., Duijkeren, N. V., Palmieri, L., Kleiner, A., and
Keviczky, T. (2024). Receding horizon re-ordering of
multi-agent execution schedules. IEEE Transactions on
Robotics, 40:1356–1372.
Chen, Z., Harabor, D. D., Li, J., and Stuckey, P. J. (2021).
Symmetry breaking for k-robust multi-agent path find-
ing. Proceedings of the AAAI Conference on Artificial
Intelligence, 35:12267–12274.
Dresner, K. and Stone, P. (2008). A Multiagent Approach to
Autonomous Intersection Management. Journal of Arti-
ficial Intelligence Research (JAIR), 31:591–656.
Erdem, E., Kisa, D. G., Oztok, U., and Sch
¨
uller, P. (2013).
A General Formal Framework for Pathfinding Problems
with Multiple Agents. In Twenty-Seventh AAAI Confer-
ence on Artificial Intelligence.
Feng, Y., Paul, A., Chen, Z., and Li, J. (2024). A real-
time rescheduling algorithm for multi-robot plan execu-
tion. Proceedings of the International Conference on Au-
tomated Planning and Scheduling, 34:201–209.
Gregoire, J.,
ˇ
C
´
ap, M., and Frazzoli, E. (2017). Locally-
optimal multi-robot navigation under delaying distur-
bances using homotopy constraints. Autonomous Robots
2017 42:4, 42:895–907.
H
¨
onig, W., Kiesel, S., Tinka, A., Durham, J. W., and Aya-
nian, N. (2019). Persistent and robust execution of mapf
schedules in warehouses. IEEE Robotics and Automation
Letters, 4:1125–1131.
H
¨
onig, W., Kumar, T. K., Cohen, L., Ma, H., Xu, H., Aya-
nian, N., and Koenig, S. (2016). Multi-agent path finding
with kinematic constraints. Proceedings of the Interna-
tional Conference on Automated Planning and Schedul-
ing, 26:477–485.
Kottinger, J., Geft, T., Almagor, S., Salzman, O., and Lahi-
janian, M. (2024). Introducing delays in multi-agent path
finding. In The International Symposium on Combinato-
rial Search.
Li, J., Chen, Z., Harabor, D., Stuckey, P. J., and Koenig, S.
(2021a). Anytime Multi-Agent Path Finding via Large
Neighborhood Search. In Proceedings of the Thirtieth
International Joint Conference on Artificial Intelligence,
pages 4127–4135, Montreal, Canada. International Joint
Conferences on Artificial Intelligence Organization.
Li, J., Harabor, D., Stuckey, P. J., Ma, H., and Koenig, S.
(2019). Symmetry-Breaking Constraints for Grid-Based
Multi-Agent Path Finding. Proceedings of the AAAI
Conference on Artificial Intelligence, 33(01):6087–6095.
Li, J., Ruml, W., and Koenig, S. (2021b). EECBS: A
Bounded-Suboptimal Search for Multi-Agent Path Find-
ing. Proceedings of the AAAI Conference on Artificial
Intelligence, 35(14):12353–12362.
Ma, H., Kumar, T. K., and Koenig, S. (2017). Multi-agent
path finding with delay probabilities. Proceedings of
the AAAI Conference on Artificial Intelligence, 31:3605–
3612.
Morris, R., Pasareanu, C., Luckow, K., Malik, W., Ma, H.,
Kumar, T., and Koenig, S. (2016). Planning, Scheduling
and Monitoring for Airport Surface Operations. In The
Workshops of the Thirtieth AAAI Conference on Artificial
Intelligence, pages 608–614.
Okumura, K. (2023). Improving lacam for scalable eventu-
ally optimal multi-agent pathfinding. In Elkind, E., edi-
tor, Proceedings of the Thirty-Second International Joint
Conference on Artificial Intelligence, IJCAI-23, pages
243–251. International Joint Conferences on Artificial
Intelligence Organization. Main Track.
Phillips, M. and Likhachev, M. (2011). SIPP: Safe interval
path planning for dynamic environments. In 2011 IEEE
International Conference on Robotics and Automation,
pages 5628–5635.
Sharon, G., Stern, R., Felner, A., and Sturtevant, N. R.
(2015). Conflict-based search for optimal multi-agent
pathfinding. Artificial intelligence, 219:40–66.
Silver, D. (2005). Cooperative Pathfinding. Proceedings of
the AAAI Conference on Artificial Intelligence and Inter-
active Digital Entertainment, 1(1):117–122.
Stern, R., Sturtevant, N., Felner, A., Koenig, S., Ma, H.,
Walker, T., Li, J., Atzmon, D., Cohen, L., Kumar, T.,
et al. (2019). Multi-agent pathfinding: Definitions, vari-
ants, and benchmarks. In Proceedings of the Interna-
tional Symposium on Combinatorial Search, volume 10,
pages 151–158.
Su, Y., Veerapaneni, R., and Li, J. (2024). Bidirectional
temporal plan graph: Enabling switchable passing orders
for more efficient multi-agent path finding plan execu-
tion. Proceedings of the AAAI Conference on Artificial
Intelligence, 38:17559–17566.
Surynek, P. (2010). An optimization variant of multi-robot
path planning is intractable. In Proceedings of the AAAI
conference on artificial intelligence, volume 24, pages
1261–1263.
Surynek, P. (2020). Bounded Sub-optimal Multi-Robot Path
Planning Using Satisfiability Modulo Theory (SMT) Ap-
proach. In 2020 IEEE/RSJ International Conference on
Intelligent Robots and Systems (IROS), pages 11631–
11637, Las Vegas, NV, USA. IEEE.
Wagner, A., Veerapaneni, R., and Likhachev, M. (2022).
Minimizing coordination in multi-agent path finding
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
630

with dynamic execution. Proceedings of the AAAI Con-
ference on Artificial Intelligence and Interactive Digital
Entertainment, 18:61–69.
Wu, Y., Veerapaneni, R., Li, J., and Likhachev, M. (2024).
From space-time to space-order: Directly planning a
temporal planning graph by redefining cbs. arXiv,
2404.15137.
Wurman, P. R., D’Andrea, R., Mountz, M., and Mountz,
M. (2008). Coordinating Hundreds of Cooperative, Au-
tonomous Vehicles in Warehouses. AI Magazine, 29:9–
20.
Yu, J. and LaValle, S. M. (2016). Optimal multirobot path
planning on graphs: Complete algorithms and effective
heuristics. IEEE Transactions on Robotics, PP(99):1–15.
Zahr
´
adka, D., Kubi
ˇ
sta, D., and Kulich, M. (2023). Solv-
ing robust execution of multi-agent pathfinding plans as
a scheduling problem. Planning and Robotics, ICAPS’23
Workshop.
Towards Holistic Approach to Robust Execution of MAPF Plans
631
