
Top-Push Polynomial Ranking Embedded Dictionary Learning for
Enhanced Re-Id
Ying Chen
1 a
, De Cheng
2 b
, Zhihui Li
3 c
and Andy Song
1 d
1
RMIT University, Melbourne, Australia
2
Xidian University, Xi’an, China
3
University of Science and Technology of China, Hefei, China
Keywords:
Person Re-Identification, Dictionary Learning, Top-Push Polynomial Ranking Metric.
Abstract:
Person re-identification (Re-Id) aims to match pedestrians captured by multiple non-overlapping cameras. In
this paper, we introduce a novel dictionary learning approach enhanced with a top-push polynomial ranking
metric for improved Re-Id performance. A key feature of our method is the incorporation of a ranking graph
Laplacian term, designed to minimize intra-class compactness and maximize inter-class dispersion. Specif-
ically, we employ a polynomial distance function to evaluate similarity between person images and propose
the Top-push Polynomial Ranking Loss (TPRL) function, which enforces a margin between positive matching
pairs and their closest non-matching pairs. The TPRL is then embedded into the dictionary learning objec-
tive, enabling our method to capture essential ranking relationships among person images—a critical aspect
for retrieval-focused tasks. Unlike traditional dictionary learning approaches, our method reformulates rank-
ing constraints through a graph Laplacian, resulting in an approach that is both straightforward to implement
and highly effective. Extensive experiments on four popular Re-Id benchmark datasets demonstrate that our
method consistently outperforms existing approaches, highlighting its effectiveness and robustness.
1 INTRODUCTION
Person re-identification (Re-Id) focuses on maintain-
ing a consistent identity for individuals as they move
across non-overlapping surveillance cameras, play-
ing a critical role in video surveillance and attract-
ing significant research interest (Huang et al., 2024;
Gao et al., 2024). Recent approaches to Re-Id can
be broadly categorized into two main types: sim-
ilarity learning methods and feature representation
learning methods. Similarity learning methods focus
on learning distance metrics that accurately measure
similarity between images captured by different cam-
eras (Yuan et al., 2021; Liu et al., 2020), while feature
representation learning methods aim to extract fea-
tures from human images that are robust to variations
in illumination, viewpoints, and poses, while remain-
ing distinct for different individuals (Chang et al.,
2018; Sha et al., 2023). Despite advancements, Re-
a
https://orcid.org/0009-0006-2681-1479
b
https://orcid.org/0000-0003-4603-847X
c
https://orcid.org/0000-0001-9642-8009
d
https://orcid.org/0000-0002-7579-7048
Id remains challenging due to several key issues: 1)
A person’s appearance can vary substantially across
camera views due to occlusions, lighting conditions,
viewpoint shifts, and pose changes in real-world sce-
narios; 2) People in public spaces often wear simi-
lar clothing (e.g., dark coats, jeans), leading to visual
similarities between different individuals.
This paper presents a novel dictionary learning ap-
proach that integrates two essential components: (1) a
reconstruction-focused module, which minimizes the
discrepancy between original image features and their
corresponding projected coefficients, and (2) a top-
push polynomial ranking metric designed to ensure
a pronounced margin between feature coefficients of
identical identities and those of different identities.
Central to this approach is the Top-Push Polynomial
Ranking Loss (TPRL), which utilizes a polynomial
distance function combining Mahalanobis and bilin-
ear metrics to evaluate image similarity. The TPRL
maximizes the separation between positive matches
and their closest negative counterparts, embedding
this objective directly within the dictionary learning
framework. Unlike prior works in metric learning,
our method uniquely incorporates ranking constraints
1262
Chen, Y., Cheng, D., Li, Z. and Song, A.
Top-Push Polynomial Ranking Embedded Dictionary Learning for Enhanced Re-Id.
DOI: 10.5220/0013319900003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 3, pages 1262-1269
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

into dictionary learning through a graph Laplacian
formulation, providing a structured approach to opti-
mizing these relationships across datasets. Addition-
ally, the polynomial distance measurement matrix is
jointly optimized during dictionary learning, further
bolstering the method’s effectiveness. By represent-
ing both gallery and probe images, the learned dic-
tionary remains robust to variations in viewpoint, en-
abling it to encode features that are both discrimina-
tive for individuals and consistent within identities.
This approach strengthens intra-class cohesion while
amplifying inter-class distinctions.
In summary, the key contributions of this work are
as follows:
• We introduce the Top-Push Polynomial Rank-
ing Loss, which leverages a polynomial distance
function to measure similarity and enforces a sig-
nificant margin between positive matching pairs
and their nearest non-matching counterparts.
• We reformulate the top-push polynomial ranking
constraints into a graph Laplacian framework and
integrate this directly into the dictionary learn-
ing process, enhancing the adaptability of tradi-
tional dictionary learning methods for person Re-
Id tasks.
• Extensive experiments on multiple benchmark
datasets demonstrate the effectiveness of the
proposed discriminative dictionary learning ap-
proach, achieving state-of-the-art performance in
person Re-Id.
2 ALGORITHM DESCRIPTION
This section begins with a brief overview of the fun-
damentals of dictionary learning. We then introduce
our proposed approach, which embeds a ranking met-
ric to learn dictionaries that are both discriminative
and robust to viewpoint variations. Finally, we detail
the optimization strategy for the proposed method.
2.1 The Proposed Top-Push Polynomial
Ranking Distance Metric
Person Re-Id involves identifying a specific individ-
ual from a vast collection of gallery images captured
across multiple cameras. Since ranking information
is crucial for this task, we naturally integrate triplet
ranking constraints into the objective function to en-
able discriminative dictionary learning. This ranking
metric is designed to reduce the distance between co-
efficient vectors of samples belonging to the same in-
dividual while increasing the distance between those
of visually similar samples from different individuals.
For person Re-Id, our objective is to ensure that the
distance between samples of different individuals is
significantly larger than that between samples of the
same individual, maintaining a substantial margin.
Let the coding coefficient matrix be A =
[a
1
,...,a
N
] ∈ R
K×N
, which corresponds to the orig-
inal data matrix X = [x
1
,...,x
N
] ∈ R
M×N
. Each col-
umn of A represents the transformed embedding of
the respective data point x
i
in the new feature space.
Using the training data, our objective function aims
to guide the dictionary toward embeddings where the
distance between images of the same person is sig-
nificantly smaller than that between images of differ-
ent individuals, maintaining a margin τ. This formu-
lation is inspired by the triplet loss function. How-
ever, unlike traditional triplet loss, this paper intro-
duces the top-push constraint, which maximizes the
margin specifically between the matching image pair
and its closest non-matching pair, expressed as:
Γ(A,W) =
∑
l
i
=l
j
[ f
W
(a
i
,a
j
) − min
l
i
̸=l
k
f
W
(a
i
,a
k
) + τ]
+
,
(1)
where [x]
+
takes zero if x < 0, and equals x otherwise.
l
i
is the labeled identity of the i-th training sample, τ is
the predefined max-margin parameter in the proposed
top-push ranking loss, and f
W
is the distance func-
tion between two examples. We can clearly see that
the proposed top-push ranking constraint maximizes
the margin between each matching positive pair and
its corresponding hardest non-matching negative pair.
f
W
is the polynomial distance function used in (Chen
et al., 2016a), which is the combination of Maha-
lanobis and the Bilinear distances. We can define it
as follows,
f
W
(a
i
,a
j
) =< φ(a
i
,a
j
),[W
M
;W
B
] >
=< φ
M
(a
i
,a
j
),W
M
> + < φ
B
(a
i
,a
j
),W
B
>,
(2)
where < ·, · >
F
is the Frobenius inner product, and
W = [W
M
,W
B
], φ(a
i
,a
j
) = [φ
M
(a
i
,a
j
),φ
B
(a
i
,a
j
)].
More specifically,
φ
M
(a
i
,a
j
) = (a
i
− a
j
)(x
i
− x
j
)
T
,
φ
B
(a
i
,a
j
) = a
i
a
T
j
+ a
j
a
T
i
.
(3)
The part < φ
M
(a
i
,a
j
),W
M
>
F
= ||W
M
(a
i
− a
j
)||
2
2
=
(a
i
− a
j
)
T
M(a
i
− a
j
), is connected to Mahalanobis
distance, where M = W
T
M
W
M
. As we want to achieve
low score when a
i
and a
j
are similar, W
M
should be
positive semi-define. The part < φ
B
(a
i
,a
j
),W
B
>=
a
T
i
W
B
a
j
+ a
T
j
W
B
a
i
, corresponds to bilinear similar-
ity. In order to simplify this bilinear similarity,
we define the Bilinear matric W
B
to be symmetric.
Top-Push Polynomial Ranking Embedded Dictionary Learning for Enhanced Re-Id
1263

Then this part can be defined as < φ
B
(a
i
,a
j
),W
B
>=
2a
T
i
W
B
a
j
. Thus, the similarity function can be writ-
ten as Eq. (4),
f
W
(a
i
,a
j
) =< φ(a
i
,a
j
),[W
M
;W
B
] >
= ||W
M
(a
i
− a
j
)||
2
2
+ 2 · a
T
i
W
B
a
j
.
(4)
We can clearly see that φ
M
(a
i
,a
j
) focus on measur-
ing the similarity for descriptors at the same position.
φ
B
(a
i
,a
j
) matches each patch in one image with all
patches in the other image, and all the cross-patch
similarities are attained as a
i
a
T
j
and a
j
a
T
i
. Both parts
ensure the effectiveness of f (a
i
,a
j
).
2.2 The Proposed Dictionary Learning
Objective with TPRL Embedded
In the following, we reformulate the proposed TPRL
into the metric form. As illustrated in Eq. 1, the pro-
posed top-push ranking constraint Γ(A, W) is consti-
tuted by all the positive sample pairs and their corre-
sponding hardest negative sample pairs in the train-
ing dataset, where the distance between two samples
(a
i
,a
j
) can be computed by the polynomial distance
function f
W
(a
i
,a
j
). Then, we innovatively reformu-
late Eq. 1 into the following metric form,
Γ(A,W) =
N
∑
i, j=1
s
i j
f
W
(a
i
,a
j
) +C(τ)
=
N
∑
i, j=1
s
i j
[||W
M
(a
i
− a
j
)||
2
2
+ 2 · a
T
i
W
B
a
j
] +C(τ)
= 2Tr(W
M
AΨ
M
A
T
W
T
M
) +2Tr(AΨ
B
A
T
W
B
) +C(τ)
= 2Tr(W
M
AΨ
M
A
T
W
T
M
+ AΨ
B
A
T
W
B
) +C(τ).
(5)
where C(τ) is constant depending on parameter τ,
s
i j
is the adjacent weight for the pair-wise sample
distance f
W
(a
i
, a
j
). In Eq.(5), the parameter W =
[W
M
,W
B
] is to be learnt, and Ψ
M
= G − (S + S
T
)/2,
G = diag(g
11
,...,g
NN
), g
ii
=
∑
N
j=1, j̸=i
s
i j
+s
ji
2
, j =
1,2,...,N, and Ψ
B
= (S+S
T
)/2. Ψ
M
and Ψ
B
are the
Laplacian matrix of S, and Tr(.) denotes the trace of
a matrix. The deduction from line 2 to 3 in Eq. 5 can
refer to (Shi et al., 2016). The element s
i j
of the ad-
jacent matrix S in Eq. 5 can be deduced from Eq. (5)
and Eq. (1) as follows:
s
i j
=
δ[ f
W
(a
i
,a
j
) − min
k=1,..,n
f
W
(a
i
,a
k
) + τ],
l
i
= l
j
̸= l
k
,i ̸= j,
−
N
∑
k=1,
l
i
=l
k
̸=l
j
.
ε( j == j
i min
)δ[ f
W
(a
i
,a
k
)
− f
W
(a
i
,a
j
) + τ],i ̸= j,0, i = j.
(6)
where the function δ[.] is an indicator function
which takes one if the argument is bigger than
zero, and zeros otherwise.ε(x) is another indica-
tor function which takes one if the argument inside
the brackets is true, and zero otherwise. j
i min
=
argmin
j=1,...,N,l
j
̸=l
i
f
W
(a
i
,a
j
).
Therefore, the proposed dictionary learning algo-
rithm with polynomial ranking metric embedded ar-
rives at:
argmin
D,A,W
||X − DA||
2
F
+
β
N(τ)
Tr(W
M
AΨ
M
A
T
W
T
M
+ AΨ
B
A
T
W
B
) + λ||A||
2
F
+ α
1
||W
M
||
2
F
+ α
2
||W
B
||
2
F
s.t. ||d
i
||
2
2
≤ 1, ∀i,
(7)
where C(τ) has been ignored from Eq. 5 as the con-
stant has no influence on the objective, and N(τ) is
the number of all the selected sample triplets con-
structed by the N training examples with hardest neg-
ative miming process. The parameters λ, α
1
, α
2
and
β are used to control the contributions of the corre-
sponding terms. In Eq. 7, the first term denotes the re-
construction error. The second term is the embedded
TPRL which maintains the distance of similar sam-
ple pairs to be closer than that of the closest dissim-
ilar pairs by a large margin in the learned dictionary
space, thus reduce the intra-personal variations. The
last three terms are the regularization terms to avoid
over-fitting.
3 EXPERIMENTS
In this section, we use four widely used person Re-
Id benchmark datasets, namely VIPeR (Gray et al.,
2007), 3DPES (Baltieri et al., 2011), CUHK01 (Li
et al., 2014) and CUHK03 (Li et al., 2014), for per-
formance evaluation. All the datasets contain a set
of individuals, each of whom has several images cap-
tured by different camera views.
3.1 Experimental Setup
Feature Representation. We have used two
kinds of features in our experiments: One is
the traditional handcraft features, which includes
colour+HOG+LBP, HSV, LAB SILPT, and each of
them is extracted both in the whole image and the
image subregions. Details about the 7538-D feature
representations can refer to (Peng et al., 2016; Chen
et al., 2016a). Another is the 2048-D deep resid-
ual network features(ResNet152) (He et al., 2016).
Note that the 2048-D deep feature is extracted by the
original ResNet152 model trained on the ImageNet
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1264

dataset, it was not fine-tuned on any person Re-Id
dataset. Then we mix them to form a single feature
vector for each image.
Parameter Setting. We empirically set the dictio-
nary size for D in Eq. 7 as K = 250. The parame-
ters τ,α
1
,α
2
,β and λ are set to 1.0, 0.2, 0.2, 0.7 and
0.35, respectively. The learning rate for optimizing
Eq. 7 starts with η = 0.01, then at each iteration, we
increase η by a factor of 1.2 if the loss function de-
creased and decrease η by a factor of 0.8 if the loss
increased.
Evaluation Protocol. Our experiments follow the
evaluation protocol in (Peng et al., 2016). The dataset
is separated into the training and test set, where im-
ages of the same person can only appear in either
set. The test set is further divided into the probe and
gallery set, and two sets contain different images of
a same person. In the VIPeR,3DPES and CUHK01
datasets, half of the identities are used as training or
test set, while in the CUHK03 dataset, 100 pedestri-
ans are used as the test set, and the rest are used as
the training set. We match each probe image with ev-
ery image in the gallery set, and rank the gallery im-
ages according to their distance. The results are eval-
uated by the widely used CMC (Cumulative Matching
Characteristic) metric (Peng et al., 2016).
3.2 Experimental Evaluations
As illustrated in Eq. (7), the proposed method mainly
contains two components: the first one is the tradi-
tional dictionary learning method, which minimizes
the reconstruction error between the input image fea-
tures and the learned coding vectors; the second term
is the proposed top-push polynomial ranking distance
metric, where the polynomial distance metric is the
combination of Mahalanobis and bilinear distances.
In order to reveal how each ingredient contributes to
the performance improvement, we implemented the
following six variants of the proposed method, and
compared them with many representative works in the
literature:
Variant 1 (denoted as DictL). We implement the
dictionary learning method with the previously
used Laplacian matrix embeddings, which just
used the same identity information, and the ma-
trix is constructed in the following way: s
i j
= 1
only if l
i
= l
j
,i ̸= j, otherwise s
i j
= 0, and the
distance between two sample images is denoted
as f (a
i
,a
j
) = ||a
i
− a
j
||
2
2
. This is our baseline
method.
Variant 2 (denoted as DictR). We implement the
dictionary learning method as illustrated in Eq. 7,
but with the projection matrix W = [W
M
;W
B
] re-
moved (equal to set W
M
= I, and W
B
= −I, where
I is the identity matrix).
Variant 3 (denoted as DictRWM). We implement
the dictionary learning method as illustrated in
Eq. 7, but we only use the Mahalanobis dis-
tance to measure the similarity between two im-
ages. That is to say, we just get rid of the term
“Tr(AΨ
B
A
T
W
B
)” and “α
2
||W
B
||
2
F
” in Eq. 7 to
train the model.
Variant 4 (denoted as DictRWB). We implement the
dictionary learning method as illustrated in Eq. 7,
but we only use the bilinear distance to measure
the similarity between two images. That is to say,
we just get rid of the term “Tr(W
M
AΨ
M
A
T
W
T
M
)”
and “α
1
||W
M
||
2
F
” in Eq. 7 to train the model.
Variant 5 (denoted as Ours(DictRWMB)). This
is our proposed final dictionary learning based
method as illustrated in Eq. 7.
Table 1, 2, 3 and 4 show the evaluation results
on VIPeR, 3DPES, CUHK01 and CUHK03 datasets,
respectively, using the rank 1, 5, 10, 20, 30 ac-
curacies. Each table includes the recently reported
evaluation results. The compared methods include
the approaches based on metric learning (Jose and
Fleuret, 2016; Chen et al., 2016a; Bai et al., 2017;
Zhou et al., 2017), common subspace based meth-
ods (Chen et al., 2015; Prates et al., 2015; Liao et al.,
2015; Lisanti et al., 2014; Prates et al., 2016; Zhang
et al., 2016b; Barman and Shah, 2017), and the deep
learning based methods (Chen et al., 2016b; Var-
ior et al., 2016a; Ahmed et al., 2015; Wang et al.,
2016). Compared with all the aforementioned repre-
sentative works, our model(DictRWMB) has achieved
the top performances on the four person Re-Id bench-
mark datasets, with all the five ranking measurements.
We achieve the rank-1 accuracy to 56.9%, 61.2%,
61.5% and 77.1% on VIPeR, 3DPES, CUHK01 and
CUHK03 datasets, respectively. The evaluation re-
sults shown in Table 1,2,3 and 4 can be summarized
as follows,
• Compared with many recently reported repre-
sentative works, our method(DictRWMB) out-
performs all the compared metric learning based
methods on all the datasets by a margin of 2.0%
at top 1 accuracy on average. We can also out-
perform the deep learning based methods on rel-
atively small datasets, while get comparable re-
sults with some deep learning based methods on
the relatively large datasets.
• With the proposed TPRL embedded, the perfor-
mance accuracies can get up to 4.3% − 11.9%
Top-Push Polynomial Ranking Embedded Dictionary Learning for Enhanced Re-Id
1265
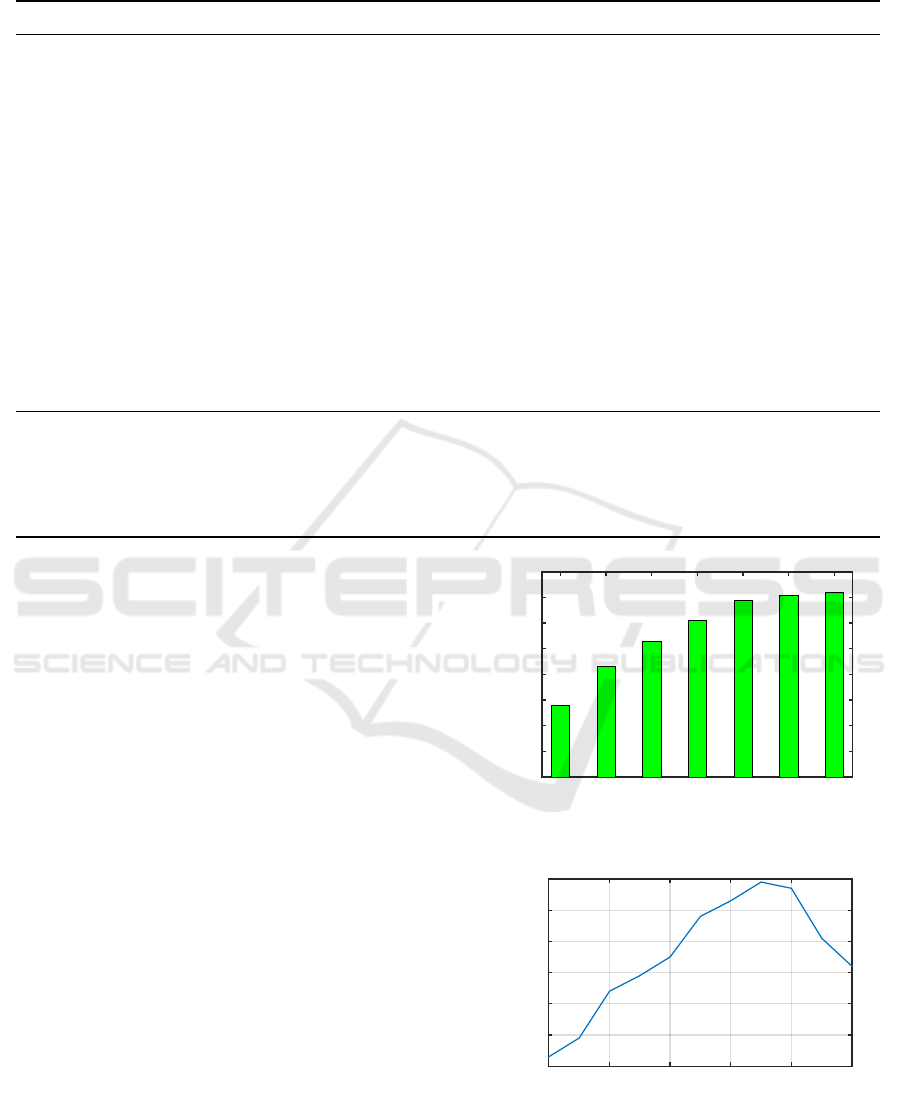
Table 1: Experimental results on VIPeR dataset(p=316).
Method r=1 r=5 r=10 r=20 r=30
(Prates et al., 2016) 35.8 69.1 80.8 89.9 93.8
(Chen et al., 2016b) 38.4 69.2 81.3 90.4 94.1
(Xiong et al., 2014) 39.2 71.8 81.3 92.4 94.9
(Lisanti et al., 2014) 37.0 −− 85.0 93.0 −−
(Liao et al., 2015) 40.0 68.0 80.5 91.1 95.5
(Jose and Fleuret, 2016) 40.2 68.2 80.7 91.1 −−
(Yang et al., 2016) 41.1 71.7 83.2 91.7 −−
(Zhang et al., 2016b) 42.3 71.5 82.9 92.1 −−
(Chen et al., 2015) 43.0 75.8 87.3 94.8 −−
(Ahmed et al., 2015) 45.9 77.5 88.9 95.8 −−
(Matsukawa et al., 2016) 49.7 79.7 88.7 94.5 −−
(Chen et al., 2016a) 53.5 82.6 91.5 96.6 −−
(Barman and Shah,
2017)
34.2 57.3 67.6 80.7 −−
(Zhou et al., 2017) 44.9 74.4 84.9 93.6 −−
(Bai et al., 2017) 53.5 82.6 91.5 96.6 −−
DictL(baseline) 52.6 77.5 85.9 91.8 94.6
DictR 55.1 82.7 90.7 95.8 97.3
DictRWM 56.3 82.9 91.5 96.9 97.8
DictRWB 55.7 81.9 90.9 96.1 97.3
DictRWMB 56.9 83.8 92.5 97.4 98.3
improvement compared with the baseline dictio-
nary learning method. By comparing the method
“DictR” and “DictL”, we can clearly see that the
ranking information is better than only using the
same identity information.
• We can clearly see that embedding either the Ma-
halanobis or bilinear distance function into the
dictionary learning objective can contribute to
the performance improvements. When the pro-
posed polynomial distance function is embedded,
much better performance improvements can be
obtained.
Since we have used two kinds of features in our ex-
periments (the handcraft and the ResNet152 features),
we also did experiments to reveal their performances
in Table 5, respectively. We can clearly see that com-
bining the traditional handcraft features with the deep
learning based features can further improve the Re-Id
performances.
3.3 Parameter Analysis of the Method
As defined in Eq. 7, there are two important param-
eters in our proposed ranking metric embedded dic-
tionary learning method, one is the dictionary size K
of D, and the other is the parameter β, which controls
the balance between the dictionary construction loss
and the ranking graph laplacian cost. To investigate
50
100 150
200
Dictionary Size K
250 300
350
Rank-1 Accuracy
50
51
52
53
54
55
56
57
58
52.8
55.3
56.1
56.9
54.3
57.1
57.2
Figure 1: Parameter Analysis: We report how the rank-1
accuracy changes with the dictionary size K.
Beta
0 0.2 0.4 0.6 0.8 1
Rank-1 Accuracy
51
52
53
54
55
56
57
Figure 2: Parameter Analysis: We report how the rank-1
accuracy changes with the parameter ⣬ which controls
the balance between the dictionary construction loss and the
TPRL component.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1266

Table 2: Experimental results on 3DPES dataset(p=92).
Method r=1 r=5 r=10 r=20 r=30
(Koestinger et al., 2012) 34.2 58.7 69.6 80.2 −−
(Mignon and Jurie, 2012) 43.5 71.6 81.8 91.0 −−
(Pedagadi et al., 2013) 45.5 69.2 70.1 82.1 88.2
(Xiong et al., 2014) 54.0 77.7 85.9 92.4 −−
(Paisitkriangkrai et al., 2015) 53.3 76.8 85.7 91.4 −−
(Xiao et al., 2016) 55.2 76.4 84.9 91.9 94.1
(Chen et al., 2016a) 57.3 78.6 86.5 93.6 95.2
DictL(baseline) 55.3 76.3 83.7 91.4 94.2
DictR 59.0 80.7 87.6 94.1 95.8
DictRWM 60.5 81.7 89.6 96.1 96.8
DictRWB 59.8 81.3 88.7 95.2 96.7
DictRWMB 61.2 82.4 91.7 96.8 97.7
Table 3: Experimental results on CUHK01 dataset(p=486).
Method r=1 r=5 r=10 r=20 r=30
(Prates et al., 2016) 38.3 66.8 77.7 86.8 90.5
(Chen et al., 2015) 40.4 64.6 75.3 84.1 −
(Ahmed et al., 2015) 47.5 71.6 80.3 87.5 −
(Xiong et al., 2014) 49.6 74.7 83.8 91.2 94.3
(Ahmed et al., 2015) 53.4 76.4 84.4 90.5 −
(Chen et al., 2016a) 56.8 87.6 89.5 92.3 94.7
(Matsukawa et al., 2016) 57.8 79.1 86.2 92.1 −
(Li et al., 2015) 59.5 81.3¡¡ 89.7 93.1 −
(Prates et al., 2016) 61.2 80.9 87.3 93.2 95.6
DictL(baseline) 56.2 79.5 84.7 90.6 93.0
DictR 59.7 81.5 89.0 92.8 96.2
DictRWM 61.1 82.8 90.1 94.3 96.5
DictRWB 60.6 82.3 89.7 93.8 95.2
DictRWMB 61.5 83.6 90.7 94.4 96.7
the effect of the dictionary size K and the parameter
β on the rank-1 accuracy, we conduct experiments us-
ing cross validation method on VIPeR dataset, and the
rank-1 results are shown in Fig. 1 and Fig. 2.
Figure 1 illustrates the rank-1 accuracy with dif-
ferent dictionary size K from 50 to 350. We can see
that firstly as the dictionary size becomes larger, the
performance increases continuously. After the dictio-
nary size K larger than 250, the performance increases
very slowly. Although higher performance can also
be obtained with larger dictionary size, we choose
K = 250 in all our experiments, since larger dictio-
nary size requires more training and testing time.
Figure 2 shows the rank-1 accuracy with different
parameter β from 0 to 1.0. We can clearly see that our
proposed method yields the best rank-1 performance
when β = 0.7. Thus, we set β to 0.7 in all our experi-
mental evaluations.
4 CONCLUSION
In this paper, we present a novel dictionary learn-
ing method with the TPRL embedded, for person Re-
Id. Specially, we first adopt the polynomial distance
function to measure the similarity between two differ-
ent person images; and then we propose the top-push
polynomial ranking loss function, which maximizes
the margin between the positive matching image pair
and its closest non-matching image pair; Finally, we
reformulate the TPRL into the graph Laplacian form,
and then embedded it into the dictionary learning ob-
jectives. Experiment results illustrate the effective-
ness of the proposed method. It shows that the pro-
posed ranking graph Laplacian term is very essential
for such retrieval related tasks, especially for person
Re-Id. Overall, our proposed method have made the
traditional dictionary learning method more suitable
Top-Push Polynomial Ranking Embedded Dictionary Learning for Enhanced Re-Id
1267

Table 4: Experimental results on CUHK03 labeled
dataset(p=100).
Method r=1 r=5 r=10 r=20 r=30
(Zhao et al., 2013) 8.8 24.1 38.3 53.4 −−
(Koestinger et al., 2012) 14.2 48.5 52.6 −− −−
(Li et al., 2014) 20.6 51.5 66.5 80.0 −−
(Liao et al., 2015) 52.2 82.2 92.1 96.2 −−
(Xiong et al., 2014) 48.2 59.3 66.4 −− −−
(Wang et al., 2016) 52.2 83.7 89.5 94.3 96.5
(Ahmed et al., 2015) 54.7 86.5 94.0 96.1 98.0
(Varior et al., 2016b) 57.3 80.1 88.3 −− −−
(Paisitkriangkrai et al., 2015) 62.1 89.1 94.3 97.8 −−
(Zhang et al., 2016a) 58.9 85.6 92.5 96.3 −−
(Wu et al., 2016) 63.2 90.0 92.7 97.6 −−
(Varior et al., 2016a) 68.1 88.1¡¡ 94.6 −− −
(Zhou et al., 2017) 61.6 88.3 95.2 98.4 −−
(Bai et al., 2017) 76.6 94.6 98.0 −− −−
DictL(baseline) 65.2 83.5 88.7 93.6 96.0
DictR 73.2 90.3 93.3 96.8 98.0
DictRWM 75.3 93.3 94.5 97.8 98.0
DictRWB 74.2 91.4 93.6 97.5 98.0
DictRWMB 77.1 94.7 97.9 98.0 99.0
Table 5: Experiments comparison with handcraft(HC),
ResNet152 features and its combination on CUHK03
datasets, respectively.
Method r=1 r=5 r=10 r=20 r=30
DictRWMB(ResNet152) 47.7 79.8 88.7 95.1 97.2
DictRWMB(HC) 72.3 91.7 94.9 97.1 98.0
DictRWMB(HC+ResNet152) 77.1 94.7 97.9 98.0 99.0
for the retrieval related tasks. In the future, we will
deploy our approach to other tasks, such as image and
video retrieval.
REFERENCES
Ahmed, E., Jones, M., and Marks, T. K. (2015). An
improved deep learning architecture for person re-
identification. In CVPR.
Bai, S., Bai, X., and Tian, Q. (2017). Scalable person re-
identification on supervised smoothed manifold. In
CVPR.
Baltieri, D., Vezzani, R., and Cucchiara, R. (2011). 3dpes:
3d people dataset for surveillance and forensics. In
ACM workshop on Human gesture and behavior un-
derstanding.
Barman, A. and Shah, S. K. (2017). Shape: A novel graph
theoretic algorithm for making consensus-based deci-
sions in person re-identification systems. In ICCV.
Chang, X., Huang, P., Shen, Y., Liang, X., Yang, Y., and
Hauptmann, A. G. (2018). RCAA: relational context-
aware agents for person search. In Ferrari, V., Hebert,
M., Sminchisescu, C., and Weiss, Y., editors, ECCV.
Chen, D., Yuan, Z., Chen, B., and Zheng, N. (2016a). Sim-
ilarity learning with spatial constraints for person re-
identification. In CVPR.
Chen, S.-Z., Guo, C.-C., and Lai, J.-H. (2016b). Deep rank-
ing for person re-identification via joint representation
learning. IEEE TIP.
Chen, Y.-C., Zheng, W.-S., and Lai, J. (2015). Mirror repre-
sentation for modeling view-specific transform in per-
son re-identification. In IJCAI.
Gao, J., Jiang, X., Dou, S., Li, D., Miao, D., and Zhao,
C. (2024). Re-id-leak: Membership inference attacks
against person re-identification. Int. J. Comput. Vis.,
132(10):4673–4687.
Gray, D., Brennan, S., and Tao, H. (2007). Evaluating ap-
pearance models for recognition, reacquisition, and
tracking. In ECCV.
He, K., Zhang, Ren, S., and Sun, J. (2016). Deep residual
learning for image recognition. In CVPR.
Huang, Y., Zhang, Z., Wu, Q., Zhong, Y., and Wang, L.
(2024). Attribute-guided pedestrian retrieval: Bridg-
ing person re-id with internal attribute variability. In
CVPR.
Jose, C. and Fleuret, F. (2016). Scalable metric learning via
weighted approximate rank component analysis. In
ECCV.
Koestinger, M., Hirzer, M., Wohlhart, P., Roth, P. M., and
Bischof, H. (2012). Large scale metric learning from
equivalence constraints. In CVPR.
Li, S., Shao, M., and Fu, Y. (2015). Cross-view projective
dictionary learning for person re-identification. In IJ-
CAI.
Li, W., Zhao, R., Xiao, T., and Wang, X. (2014). Deep-
reid: Deep filter pairing neural network for person re-
identification. In CVPR.
Liao, S., Hu, Y., Zhu, X., and Li, S. Z. (2015). Person re-
identification by local maximal occurrence represen-
tation and metric learning. In CVPR.
Lisanti, G., Masi, I., and Del Bimbo, A. (2014). Match-
ing people across camera views using kernel canonical
correlation analysis. In ICDSC.
Liu, W., Chang, X., Chen, L., Phung, D., Zhang, X., Yang,
Y., and Hauptmann, A. G. (2020). Pair-based uncer-
tainty and diversity promoting early active learning for
person re-identification. ACM Trans. Intell. Syst. Tech-
nol., 11(2):21:1–21:15.
Matsukawa, T., Okabe, T., Suzuki, E., and Sato, Y.
(2016). Hierarchical gaussian descriptor for person
re-identification. In CVPR.
Mignon, A. and Jurie, F. (2012). Pcca: A new approach for
distance learning from sparse pairwise constraints. In
CVPR.
Paisitkriangkrai, S., Shen, C., and van den Hengel, A.
(2015). Learning to rank in person re-identification
with metric ensembles. In CVPR.
Pedagadi, S., Orwell, J., Velastin, S., and Boghossian, B.
(2013). Local fisher discriminant analysis for pedes-
trian re-identification. In CVPR.
Peng, P., Xiang, T., Wang, Y., Pontil, M., Gong, S.,
Huang, T., and Tian, Y. (2016). Unsupervised cross-
dataset transfer learning for person re-identification.
In CVPR.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1268

Prates, R., Felipe, and Schwartz, W. R. (2015). Appearance-
based person re-identification by intra-camera dis-
criminative models and rank aggregation. In Interna-
tional Conference on Biometrics.
Prates, R., Oliveira, M., and Schwartz, W. R. (2016). Kernel
partial least squares for person re-identification. In
AVSS.
Sha, B., Li, B., Chen, T., Fan, J., and Sheng, T. (2023). Re-
thinking pseudo-label-based unsupervised person re-
id with hierarchical prototype-based graph. In ACM
MM.
Shi, W., Gong, Y., and Jinjun (2016). Improving cnn per-
formance with min-max objective. In IJCAI.
Varior, R. R., Haloi, M., and Wang, G. (2016a). Gated
siamese convolutional neural network architecture for
human re-identification. In ECCV.
Varior, R. R., Shuai, B., Lu, J., Xu, D., and Wang, G.
(2016b). A siamese long short-term memory archi-
tecture for human re-identification. In ECCV.
Wang, F., Zuo, W., Lin, L., Zhang, D., and Zhang, L.
(2016). Joint learning of single-image and cross-
image representations for person re-identification. In
CVPR.
Wu, L., Shen, C., and van den Hengel, A. (2016). Deep
linear discriminant analysis on fisher networks: A hy-
brid architecture for person re-identification. Pattern
Recognition.
Xiao, T., Li, H., Ouyang, W., and Wang, X. (2016). Learn-
ing deep feature representations with domain guided
dropout for person re-identification. CVPR.
Xiong, F., Gou, M., Camps, O., and Sznaier, M. (2014).
Person re-identification using kernel-based metric
learning methods. In ECCV.
Yang, Y., Lei, Z., Zhang, S., Shi, H., and Li, S. Z. (2016).
Metric embedded discriminative vocabulary learning
for high-level person representation. In AAAI.
Yuan, D., Chang, X., Huang, P., Liu, Q., and He, Z.
(2021). Self-supervised deep correlation tracking.
IEEE Trans. Image Process., 30:976–985.
Zhang, L., Xiang, T., and Gong, S. (2016a). Learning a
discriminative null space for person re-identification.
In CVPR.
Zhang, Y., Li, B., Lu, H., Irie, A., and Ruan, X.
(2016b). Sample-specific svm learning for person re-
identification. In CVPR.
Zhao, R., Ouyang, W., and Wang, X. (2013). Unsuper-
vised salience learning for person re-identification. In
CVPR.
Zhou, J., Yu, P., Tang, W., and Wu, Y. (2017). Efficient
online local metric adaptation via negative samples for
person reidentification. In CVPR.
Top-Push Polynomial Ranking Embedded Dictionary Learning for Enhanced Re-Id
1269
