
Action-Based Intrinsic Reward Design for Cooperative Behavior
Acquisition in Multi-Agent Reinforcement Learning
Iori Takeuchi
1
and Keiki Takadama
2,3
a
1
Department of Informatics, University of Electro-Communications, Tokyo, Japan
2
Information Technology Center, The University of Tokyo, Tokyo, Japan
3
Department of Information & Communication Engineering, The University of Tokyo, Tokyo, Japan
Keywords:
Intrinsic Rewards, Multi-Agent System, Reinforcement Learning, Cooperative Behavior.
Abstract:
In recent years, research has been conducted in multi-agent reinforcement learning that aims at efficient agent
exploration in complex environments by using intrinsic rewards. However, such intrinsic rewards may inhibit
the learning of behaviors necessary for acquiring cooperative behavior, and may not be able to solve the task
of the environment. In this paper, we propose two types of internal reward designs to promote agents’ learning
of cooperative behaviors in multi-agent reinforcement learning. One is to use the average of the values of
the actions selected by all agents to promote the learning of actions necessary for cooperative behavior but
difficult to increase in value. The other is to provide an individual intrinsic reward when the value of the
action selected by each agent is lower than the average of the values of all the actions at the time, aiming to
escape from the local solution. The results of the experiment with StarCraft II scenario 6h
vs 8z showed that
by adding the proposed intrinsic reward to the intrinsic reward that encourages agents to explore unexplored
areas, cooperative behavior can be obtained in more cases than before.
1 INTRODUCTION
Reinforcement Learning ( RL) ( Sutton and Barto,
1999) is a method of machine learning in which an
agent repeatedly interacts with its environment to
learn strategies that adapt to the environment and are
used for risk management (Paragliola et al., 2018) and
itinerary planning optimization (Chen et al., 2020)
(Coronato et al., 2021). In addition, Multi-Agent Re-
inforcement Learning (MARL), a type of RL in which
multiple agents exist in the same environment, aims
to acquire cooper a tive behavior in complex environ-
ments by having the agents learn policies simultane-
ously. However, in many MARL environ ments, the
agents cannot learn po licies that take into account
other agents using only the rewards they re ceive from
the environment, making it difficult to acquire co op-
erative behavior. Against this background, research
on MARL that applies intrinsic rewards has been pro-
gressing in recent years. Intrinsic rewards are re-
wards g iven by the agent’s reward function. Rewards
received from the environment in contrast to intrin-
sic rewards are called extrinsic rewards. In previous
a
https://orcid.org/0009-0007-0916-5505
studies, intr insic rewards applied to MARL are of te n
designed to improve the agent’s exploration ability.
Exploiting POlicy Discrepancy f or Efficient Explo-
ration (EXPODE) (Zhan g and Yu, 2023) is one of the
MARL metho ds that applies intrinsic rewards, and the
intrinsic rewards of EX PODE are designed to encou r-
age agents to explore unexplored areas. Spec ifica lly,
in EXPODE, an agent learns a different policy simul-
taneously in addition to the policy it learns through
interactions with the environment, and the prediction
error of the value function of that policy is given as
an intrinsic reward. This gives agents h igh rewards
accordin g to how infrequently they re a ch a state in
the environment, and is expected to enable efficient
exploration even in environments with a vast state-
action space, leading to the acquisition of effective co-
operative behavior. However, intrinsic rewards used
in EXPODE to improve the age nts’ explor ation ca-
pabilities are not directly designed to acquire cooper-
ative beh avior, and there is a problem that the num-
ber of times the agents select actions nec essary to ac-
quire cooperative behavior for exploration is reduced,
which stagnates learning and hinders the acquisition
of cooperative behavior.
Considering this problem, this paper proposes two
632
Takeuchi, I. and Takadama, K.
Action-Based Intrinsic Reward Design for Cooperative Behavior Acquisition in Multi-Agent Reinforcement Learning.
DOI: 10.5220/0013320300003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 1, pages 632-639
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

types of intr insic r eward designs to acquire coopera-
tive behavior. In the first intrinsic reward d esign, the
averag e of the values corresponding to the actions se-
lected b y all age nts respectively is used as th e collec-
tive intrinsic reward for all agents. The second design
is more limited an d aims to provide intrinsic rewards.
The value of the selected action for each agent is com-
pared with the average value of all actions at that time,
and if the value of the selected action is lower tha n th e
averag e, an individual intrinsic reward is given to each
agent. To verify the effectiveness of the proposed in-
trinsic reward, we applied the proposed intrinsic re-
ward as an extension of the conventional method EX-
PODE and conducted experiments using the StarCraft
II (Vinyals et al., 2017) scenario 6h
vs 8z as an envi-
ronment.
This paper is structured as follows: Section 2
presents the problem formulation and related work.
Section 3 presents the proposed method. Section 4
presents experiments and their results. Finally, Sec-
tion 5 concludes this paper.
2 RELATED WORKS
2.1 Dec-POMDP
In this research, we consider a problem formulated
by Decentralized Partially Observable Markov Deci-
sion Process (Dec-POMDP) (Oliehoek et al., 2016).
In Dec-POMDP, a problem is defined as a tuple
(I, S, A, P,R, Z, O, γ). I is a set of agents i, s ∈ S is
a set of true states of th e environmen t, and A is a
set of ag ent actions. When agent i selects action a
i
,
a = (a
1
, a
2
, . . . , a
i
) is represented as the joint action
of all agents. At this time, the next state of agents is
determined by transition function P(s
′
|s, a ). In add i-
tion, each agent obtains individual observations o
i
∈ Z
using observation function O(s, a). Each agen t has its
behavioral observation history τ
i
∈ T ≡ (Z ×A)
∗
, and
acts according to policy π
i
(a
i
|τ
i
) based on that history.
Agents obtain extrinsic rewards r using a collective
reward function R(s, a ). γ ∈ [0, 1] is the discount rate,
and agents learn policies to maximize the expected
discounted reward
∑
T
t=0
γ
t
r
t
, , where T is the length
of the episode.
2.2 Deep R ei nforcement Learning
2.2.1 Deep Q-Network
Deep Q-Network (DQN) (Mnih et al., 2015) is a deep
reinfor c ement learning algorithm that expresses an
action-value function using a neural network based
on a parameter θ. In DQN, the history of actions and
state transitions is stored in a replay buffer, and learn-
ing is performed by sampling several histories fr om
the replay buffer. θ is le arned to minimize the squared
TD error:
L(θ) = [y − Q(s, a; θ)]
2
, (1)
where Q(s, a;θ) is the action value represented by
the network of parameters θ for state s and a ction a.
y = r + γ max
′
a
Q(s
′
, a
′
;θ
−
). θ
−
is th e parameter of
the target network, which is periodically copied from
θ and kept constant for several iterations.
2.2.2 Deep Recurrent Q-Network
Deep Recurrent Q-Network (DRQN) (Hausknech t
and Stone, 2015) is a deep reinforcement learning al-
gorithm that uses a recurrent neural network to adapt
to a partially observable environment. In addition,
DRQN promotes learning that consid e rs longer-term
time series by using a collective action observation
history of one episode as a sample during learn ing.
2.3 Multi-Agent Deep Reinforcement
Learning
2.3.1 Centralized Training with Decentralized
Execution
In recent years, MARL has often used Central-
ized Training with Decentralized Execution (CTDE)
(Oliehoek et al., 2008) to approach partially observ-
able environments. In CTDE, agents act based on
their local observations and action values during the
execution process, and in the training pr ocess, agents
learn using global information by sharing the true
state of the environment and the action values of all
agents. As a resu lt, CTDE realizes the interaction
between agents and the environment that takes pa r-
tial observability in to account and the optimization of
policies using g lobal information.
2.3.2 QMIX
QMIX (Rashid et al., 2018) is a MARL algorithm
based on CTDE. In QMIX, each agent has an individ-
ual action value Q
i
, and in the execution process, each
agent selects an action using its action value Q
i
. In
the learnin g process, several samples of one episode’s
history obtained in the execution process a re taken
from the replay buffer, and the joint actio n value Q
tot
is calculated f rom the individual action value Q
i
using
a mixing network, and learning is p erformed to m ini-
mize the following loss function. The weights of the
Action-Based Intrinsic Reward Design for Cooperative Behavior Acquisition in Multi-Agent Reinforcement Learning
633

Mixing Network are trained by a hypernetwork (Ha
et al., 2016) that u ses the true state as input. In addi-
tion, the individual action value Q
i
is also updated by
backpr opagating the error arising from this loss func-
tion to the network that expresses the individual value
function Q
i
:
L(θ) = [y
tot
− Q
tot
(τ , a, s; θ)]
2
, (2)
where y
tot
= r + γmax
a
′
Q
tot
(τ
′
, a
′
, s
′
;θ
−
). θ, θ
−
are
parameters of the network, and the target ne twork, re-
spectively, as in the equation 1.
In this case, the joint action value and the indi-
vidual action value have the relationship shown in the
following fo rmula.
argmax
a
Q
tot
(τ , a) =
argmax
a
1
Q
1
(τ
1
, a
1
)
.
.
.
argmax
a
i
Q
i
(τ
i
, a
i
)
. (3)
Equation (3) shows that when each ag e nt selec ts the
action with the highest individual action value based
on its action observation history, the joint action value
also takes the highest value. To satisfy th e relation-
ship in equation (3), QMIX imposes the constraints
expressed in the following equation (4) through the
Mixing Network.
∂Q
tot
∂Q
i
≥ 0, ∀i ∈ I. (4)
2.4 Intrinsic Rewards for MARL
2.4.1 Exploiting Policy Discrepancy for Efficient
Exploration
EXploiting POlicy Discrepancy for Efficient Explo-
ration (EXPODE ) (Zhang and Yu, 2023) is a MARL
algorithm that improves the efficiency of learning in
an environment with a huge observed action space by
encour a ging agents to explore unexplored areas with
intrinsic r ewards. EXPODE consists of three com po-
nents called Ex ploiter, Explorer, and Predictor.
Exploiter learns the policy for agent-environment
interaction. It extends QMIX based on the Double
Q-Learning (Hasselt, 2010) approach a nd is config-
ured to have two networks similar to QMIX. This al-
lows the Exploiter to output two joint action values
for one sample during the training process. Applying
the smaller two joint values to update the policy pre-
vents overestimatio n of the value. The loss function
of Exploiter is as shown in the equation (5).
L
exploiter
(θ
k
) = [y
exploiter
− Q
tot
(τ , a, s; θ
k
)]
2
, (5)
where y
exploiter
= r
ext
+ αr
EXPODEint
+
γm in
k
′
=1,2
Q
θ
′
k
′
tot
(τ
′
, a
′
, s
′
;θ
′
k
′
). r
ext
is the extrin-
sic reward, r
EXPODEint
is the intrinsic reward, and α
is a hyperparameter related to the intrin sic reward. k
and k
′
indicate that there are two learning n e tworks
and two target networks, respectively, and the joint
action value with the smallest value is adopted dur ing
learning.
Explore r is a com ponent with the same structure
as Exploiter and lear ns the policy used to calculate
intrinsic r ewards. The process of policy upda te is the
same as that of Exploiter. The ind ividual action value
of e ach agent includ ed in the ne twork that outputs the
larger value of the two joint action values output by
Explore r is passed to Pre dictor for th e calculation of
intrinsic rewards. The loss functio n of Explorer is as
shown in th e equation (6).
L
explorer
(φ
k
) = [y
explorer
− Q
tot
(τ , a, s; φ
k
)]
2
, (6)
where y
explorer
= r
ext
+ γ min
k
′
=1,2
Q
φ
′
k
′
tot
(τ
′
, a
′
, s
′
;φ
′
k
′
).
Predictor calculates the intrinsic reward using the
individual action value given by Explorer. Pr edictor
consists of a network for each agent that expresses the
individual action value included in Expitter and Ex-
plorer and outputs the individual action value for each
agent from on e sample. In add ition, Predictor cal-
culates the intrinsic reward r
EXPODEint
using the fol-
lowing equation (7) from the individ ual action value
given by the E xplorer and the individual action value
output by Predictor.
r
EXPODEint
i
= kQ
ψ
i
(τ
′
i
, ·) − max
k
′
=1,2
Q
φ
′
k
′
i
(τ
′
i
, ·)k
2
. (7)
The intrinsic reward of each agent is sum marized as
follows:
L
predictor
(ψ) = r
EXPODEint
=
1
I
I
∑
i=1
r
int
i
(8)
EXPODE calculates the intrinsic reward b ased on
the frequency of the agent’s achievement in a differ-
ent policy than the one used to select a n action in the
environment. This is expected to lead to exploration
in more diverse directions than if a single policy was
used.
3 PROPOSED METHOD
From the pr evious chapter, EXPODE is expected to
acquire cooperative behavior in a task with a huge
state action space using intrinsic rewards that e ncour-
age agents to explore various areas. However, such
inherent rewards may inhibit the learning of measures
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
634

by prioritizing the exploration of unexplored regions
over the utilization of action s requir ed for coopera-
tive behavior and m ay lead to th e teaching o f mea-
sures that are stuck in local solutions. In this chapter,
we propose two types of intrinsic reward designs to
acquire cooperative behavior, based on the issues of
inherent rewards in EXPODE described above.
3.1 Collective Intrinsic Reward Design
for all Agents
In MARL, cooperative behavior is a combination of
actions performed by multiple agents over a certain
period, and acq uiring co operative behavior requires
repeated execution of the primitive actions that con-
stitute it to increase their action values. However, in
environments where the acquisition of complex co op-
erative behavior is required, the actions necessary for
cooper a tive behavior may not always d irectly lead to
the acquisition of external rewards. In environments
formu late d with Dec-POMDP, a collective reward is
given to all agents, so even actions that do not yield
external rewards for a single agent can earn some ex-
ternal reward. However, since agents generally try
to acquire mor e rewards, they may increase the value
of actions that yield immediate external rewards and
learn local policies tha t fail to acquire cooperative be-
havior. In such c a ses, EXPODE gives a lot of intrin-
sic rewards during initial state transitions, so it can
increase the value of actions that do not temporarily
yield external rewards. However, the intrinsic reward
obtained by repeating transitions de creases, so if the
agent cannot find the effectiveness of the action and
increase its value by then, it will fall into a local so-
lution. As an approach to this problem, Equation (9)
shows the proposed formula for calculating intrinsic
rewards r
collectiveint
.
r
collectiveint
= e
(
1
I
∑
I
i=1
Q
i
(τ
i
,a
i
))
. (9)
From the equation (9), the proposed intrin sic r e-
ward uses the average of the individual action values
correspo nding to the actions selected by the agent. In
other words, the pro posed intrinsic reward is given
taking into consideration the value of not only the
agent’s actions as a whole but also the actions selected
by other agents at the same time. This helps to avoid
learning local policies and aims to acquire coopera-
tive behavior by providing rewards that also consider
the value of actions cho sen by other ag ents when the
value of actions nec essary for acquiring cooperative
behavior is difficult to increase.
3.2 Individual Intrinsic Rewards for
Each Agent
The intrinsic reward p roposed in section 3. 1 is in-
tended to promote learning of actions necessary for
some agents’ cooperative behavior but difficult to
value. However, since this intrinsic r eward is given
for every action that an agent chooses, it may promote
learning of actions that are more likely to incre ase in
value. In this case, if intrinsic rewards are given to
behaviors that are difficult to inc rease in value, no
value reversal occ urs, and the possibility a rises that
the agent ma y not escape from the local solution.
Therefore, in this section, we propose an intrinsic
reward given to each agen t according to the value of
that agent’s chosen actio n. Specifically, each agent
compare s the value corresponding to its own selected
action at each step with the average of the values of
all actions in tha t state. If the value of the chosen ac-
tion is lower than the value of all a c tions, an intrinsic
reward is given using that average. The formula for
calculating the intrinsic reward r
individualint
is shown
in equation (1 0).
r
individualint
i
= e
(
1
A
∑
A
a
Q
i
(τ
i
,a
i
))
. (10)
To give this individual intr insic reward only to the
correspo nding agent, a phase to upda te each agent’s
Q-Network is added to the EXPODE component, Ex-
poiter. The lo ss function used to train the Q- N etwork
of each agent is shown in equation (11). This is done
just before the learning by loss f unction of Expoiter
shown in equation (5).
L
individual
(θ
k
i
) = [y
individual
− Q
i
(τ
i
, a
i
;θ
k
i
)]
2
, (11)
where y
individual
=
1
I
(r
ext
+ αr
EXPODEint
) +
αr
individualint
i
+ γ min
k
′
=1,2
Q
θ
′
k
′
i
i
(τ
′
i
, a
′
i
;θ
′
k
′
i
). As a result,
the total Exploiter lo ss function in this method is
revised to th e following equation (12).
L
exploiter
(θ) = L
exploiter
(θ) +
I
∑
i=1
L
exploiter
(θ
i
). (12)
4 EXPERIMENT
4.1 StarCraft I I
In this study, we conduct experiments to verify the ef-
fectiveness of the proposed method and use StarCraft
II as the environment. StarCraft II is a real-time strat-
egy game provided by Blizzard Entertainment, and in
Action-Based Intrinsic Reward Design for Cooperative Behavior Acquisition in Multi-Agent Reinforcement Learning
635

recent years it has been used as an environment for
the MARL algorithm by a benchmark called SMAC
(Samvelyan et al., 2019). Several scenarios are avail-
able in Star Craft II, and in this study, we conduct ex-
periments using a scenario c alled 6h
vs 8z.
Figure 1: Agent’s initial position in 6h vs 8z (red: ally,
blue: enemy).
The initial state of 6h
vs 8z is shown in the Figure
1. 6h
vs 8z is a scenario in which six ally agents (red
circles in the Figure 1) aim to acquire a strategy to
defeat eight enemy agents (blue circles in the Fig ure
1). The enemies are controlled by NPCs in the game .
One episode is defined as one trial from the start to
the en d of the scenario, and one step is defined as the
unit tim e of an episode in which all agents, enemy
and ally, act once. The end condition of 6h
vs 8z is
when the ally’s victory or defeat conditions are met.
The ally’s victory co ndition is when all enemies are
incapacitated, and the defeat condition is when all al-
lies are incapacitated or 150 steps have passed. In
6h
vs 8z, a llies have less physical strength and less
damage per attack than enemies, but they can attack
from a certain distance even when they are no t adja-
cent to the enemy. Also, enemies have more physical
strength and more damage per attack than allies, but
they can only attack allies adjacent to them. From
the above, allies in 6h
vs 8z need to learn cooperative
behavior that can efficiently defeat the enemy under
the constraints of these characteristics and numerical
disadvantage.
In this study, the agent obtains only positive ex-
trinsic rewards from the environmen t for each step.
There are three extrinsic rewards: damage de alt to the
enemy, de feating the enemy (10 points), and winning
for allies (200 points). The total value of these re-
wards is normalized to be in the range of 0 to 20. In
all com parison methods, intrinsic rewards are given
for each step, just like extrinsic rewards, but are not
included in the normalization.
4.2 Experiment Setup
There are three comparison methods: EXPODE, the
proposed intrinsic reward for the whole agent plu s the
EXPODE Exploiter (EX PODE+collective), and the
proposed intrinsic reward for each agent plus the EX-
PODE Exp loiter (EXPODE+ individual). For each
method, α is set to 0 .01. The winning rate of the al-
lies at the time of evaluation is used as the evaluation
index of the measure to be acquired. Each evaluation
is performed in 32 episodes. The training length is
2,100,000 steps. We use ε-greedy fo r action selec-
tion, where ε is 1 at the beginning of the experimen t
and decreases linearly to rea ch a minimum value of
0.02 at 400,000steps. The learning rate is 0.0 005 and
the discount rate is 0.99. Note that th e se parameters
are the same for all methods.
4.3 Result
Figure 2: Test w in rate of each method in 6h vs 8z.
Figure 2 shows the win rate of the allies during the
training of each m e thod in 6h
vs 8z. The values in
Figure 2 are the 30 seed average of the win rate at each
measure evaluation. From Figure 2, it can be seen
that the win rate for all methods increa ses from about
700,000 steps. In addition, EXPODE+collective has
a higher win rate tha n EXPODE, indicating that the
learning process continues to progress. On the other
hand, EXPODE+in dividual has exceeded the win rate
of EX PODE since about 1,500,000 steps, and finally,
the win r ate has remained at the same level as that
of EXPODE+collective. From this, we can say that
adding the propo sed in trinsic reward to EXPODE
improves the learnin g performance of EXPODE in
6h
vs 8z a nd enables it to acquire more effective co-
operative b e havior.
Figure 3 shows the distribution of win rates at the
last evaluation for 30 seeds for each method . The
crosses in Figure 3 ind icate average values. Table 1
compare s the win rate at the final evaluation for each
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
636
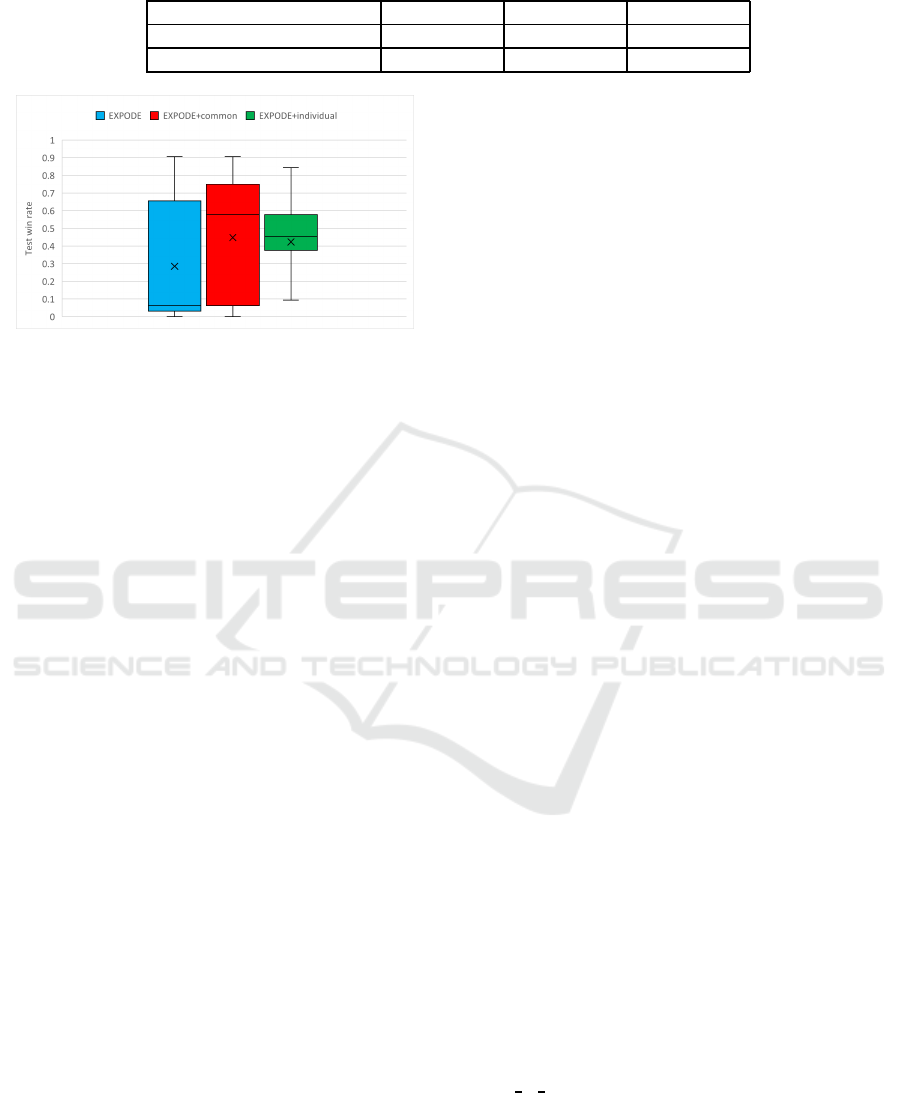
Table 1: Distr ibution of the number of seeds with large and small test win rates of the policies at the final evaluation.
> EXPODE = EXPODE < EXPODE
collective in trinsic reward 17 2 11
individual intrinsic reward 18 0 12
Figure 3: Distribution of test win rates at the final evaluation
of each method.
method for each seed and summa rizes the relatio n-
ship between the win rate at the fina l evaluation and
the win rate at the final evaluation for each method.
From Figure 3 and Tab le 1, EXPODE+collective has
a higher win rate than EXPODE in many of the se-
lections, and more than half of the selections finally
obtain a strategy with a w in rate of mor e than 50%.
EXPODE+individual also has a higher win rate in
many seeds compa red to EXPODE. In addition, EX-
PODE+individual has a much smaller interquartile
range than the other two methods, and it is found that
EXPODE+individual obtains measures with a win
rate of 40-60% in many of the seeds. From the above,
it can be said that the proposed intrinsic reward can
achieve a more stable acquisition of cooperative be-
havior than EXPODE in many cases.
4.4 Discussion
4.4.1 Cooperative Behavior
The actions of the ep isode are shown. (a) is EX-
PODE, (b) is EXPODE+collective, and (c) is EX-
PODE+individual. Table 2 shows the flow of the
episode in snapshots at four important time points.
The leftmost Figure in Ta ble 2 is the state at the start
of the episode, and as the step progresses, the state
moves to the right Figure, and finally reaches the state
at the end of the ep isode shown in the rightmost Fig-
ure.
From Table 2, it can be seen that in this episode,
the policy with EXPODE results in the defeat of
the allied agent, whereas EXPODE+collective and
EXPODE+individual result in victory. Furthermore,
comparing the action s of the allied agent when win-
ning and losing, the following differences in actions
can be confirmed in each Event: (1) Episode start
- Encounter: With EXPODE, the ally encounters
the e nemy at the same location as the initial po-
sition, whereas with EXPODE+collective and EX-
PODE+individual, the ally transitions backward or
to the left or right to enco unter the enemy. Also, at
this time , with EXPODE and EXPODE+collective,
the ally’s attacks are concentrated on a single enemy,
and one enemy is incapacitate d at the time of en-
counter. With EXPODE+individual, one enemy has
not been incapacitated at the time of en counter, but
since the health of one of the four en e mies head ing
towards th e ally is extremely low, it can be seen that a
similar concentrated attack is being carried out. (2)
Encounter - One ally is unable to fight: With E X -
PODE, the numerical disadvantage of allies contin ues
at this point, whereas with EXPODE+collective, the
number of allies and enemies is 5 to 5, and it can be
seen that th e numerica l disadvantage against the ene-
mies has been resolved by the allies’ attacks since the
time of encounter. Also, with EXPODE+individual,
the numerical disadvantage has not been resolved as
with EXPODE, but it can be seen that several ene-
mies are located away from the allies. This is because
one of the two agents that were divided at the time
of the Encounter attracted several enemies, and in
the meantime, the remaining allies and enemies were
fighting in a numerically equal situation . As a re-
sult, it is considered that even though the allies in EX-
PODE+individual were unable to re solve the numer-
ical disadvantage at this point, they were ultimately
able to win due to the advantage gain e d in the pre-
vious battles. From the above, the characteristics of
cooper a tive behavior at the time of victory that can be
acquired through the proposed intrinsic reward can be
summarized as follows. (1) State transitions to keep
a distance from the enemy and concentrated attacks
on specific enemies. (2) Attacks to eliminate numer-
ical inferiority. Furthermore, comparing the actions
of EX PODE+collective and EXPODE+individual af -
ter (2), it is con sid ered that these cooperative behav-
iors are largely dependent on the cooperative behav-
iors taken in (1). Therefore, in cooperative behavior
in 6h
vs 8z, it is considered that an important point is
what kind of formation is used to keep a distance from
the enemy while continuing concentrated attacks at
the start of the episode.
Action-Based Intrinsic Reward Design for Cooperative Behavior Acquisition in Multi-Agent Reinforcement Learning
637
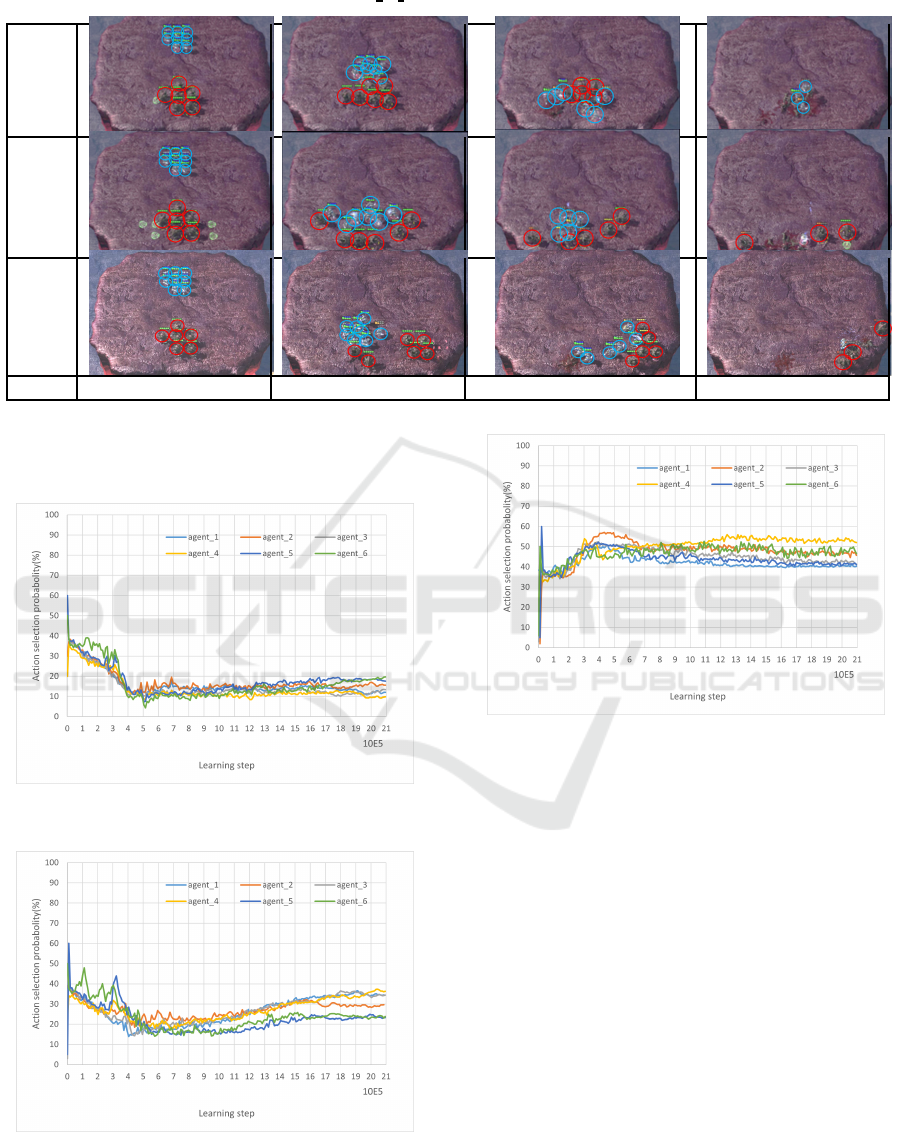
Table 2: Example of behavior in one episode of 6h vs 8z ( a: EXPODE, b: EXPODE+collective, c: EXPODE+individual).
(a)
(b)
(c)
Event Episode start Encounter One ally is unable to fight Episode finish
4.4.2 Acquiring Coo perative Behavior Through
Intrinsic Rewards
Figure 4: State transition probability for each agent in EX-
PODE from 1 to 10 st eps.
Figure 5: State transition probability for each agent in EX-
PODE+collective from 1 to 10 steps.
Figure 6: State transition probability for each agent in EX-
PODE+individual from 1 to 10 steps.
Figures 4, 5, and 6 respectively show the probab il-
ity of each agent transitioning states between 1 and
10 step s in the execution process between each eval-
uation point during learning of each method with a
certain seed. Figure 4 shows that in EXPODE, th e
state transition probability of any agent does not in-
crease afte r 400,00 0 learning steps, whe re the value
of ε reaches the minimum value and action selec-
tion becomes most dependent on in dividual action
value. On the other hand, Figure 5 shows that in
EXPODE+collective, the state tr a nsition probabil-
ity of the agents increases even after 400,000 learn-
ing steps. From this, it is consid ered that in EX-
PODE+collective, the proposed intrinsic reward in -
creases the value of actions nece ssary for cooperative
behavior, and a s a result, th e number of tim es they
are selected can be increased. Also, from Figure 6,
it can be seen that in EXPODE+individual, the state
transition probability does not increase after 400,000
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
638

learning steps, but the state transition probability of
the agents is higher than th at of the other me thods.
This is thought to be because the cooperative behav-
ior that can be acquired by E X PODE+individual is
significantly different from that of the other methods,
but since the high probability is maintained even after
400,000 learning steps, it is considered that the value
of state transitions is sufficiently increased by the pro-
posed intrinsic reward.
5 CONCLUSIONS
This paper proposed two types of intrinsic rewards
aimed at acquiring coop erative behavior. One uti-
lizes the average value of actions selected by agents
at e ach step, aiming to further incr ease the value of
actions ne c essary for cooperative behavior, and the
other aims to avoid local solutions by giving indi-
vidual rewards to each agent when they meet certain
conditions. In addition, we conducted experiments to
verify the e ffectiveness in 6h
vs 8z, a StarCraft II sce-
nario, by adding the proposed intrin sic r eward design
to a conventional method (EXPODE) with an intrin-
sic reward design that pr omotes agents’ exploration
of unexplored regions. As a re sult, we confirmed that
by applying the proposed intrinsic reward, EXPODE
can learn policies with a higher win rate for allies in
many cases compared to before application, and can
stably acquir e cooperative behavior. Furthermore, we
confirmed that applying the proposed intrinsic reward
can increase the probability of selecting actions nec-
essary for cooperative behavior in 6h
vs 8z compared
to the conventiona l method, contributing to the learn-
ing of coop e rative beh avior.Future work include s ex-
periments using other scenarios of StarCraft II to ver-
ify the generality of the effect of the proposed intrin-
sic reward design.
REFERENCES
Chen, S., Chen, B.-H., Chen, Z., and Wu, Y. (2020).
Itinerary planning via deep reinforcement learning. In
Proceedings of the 2020 International Conference on
Multimedia Retrieval, ICMR ’20, page 286–290, New
York, NY, US A . Association for Computing Machin-
ery.
Coronato, A., Di Napoli, C., Paragliola, G. , and Serino,
L. (2021). Intelligent planning of onshore touristic
itineraries for cruise passengers in a smart city. In
2021 17th International Conference on Intelligent En-
vironments (IE ) , pages 1–7.
Ha, D., Dai, A. M., and Le, Q. V. (2016). Hypernetworks.
CoRR, abs/1609.09106.
Hasselt, H. (2010). Double q-learning. In Lafferty, J.,
Williams, C., Shawe-Taylor, J., Zemel, R., and Cu-
lotta, A., editors, Advances i n N eural Information
Processing Systems, volume 23. Curran Associates,
Inc.
Hausknecht, M. and Stone, P. (2015). Deep recurrent q-
learning for partially observable mdps. In 2015 aaai
fall symposium series.
Mnih, V., K avukcuoglu, K., Silver, D., Rusu, A. A., Ve-
ness, J., Bellemare, M. G., Graves, A., Riedmiller, M.,
Fidjeland, A. K., Ostrovski, G., et al. (2015). Human-
level control through deep reinforcement learning. na-
ture, 518(7540):529–533.
Oliehoek, F. A., Amato, C., et al. (2016). A concise
introduction to decentralized POMDPs, volume 1.
Springer.
Oliehoek, F. A., Spaan, M. T., and Vlassis, N. (2008). Opti-
mal and approximate q-value functions for decentral-
ized pomdps. Journal of Artificial Intelligence Re-
search, 32:289–353.
Paragliola, G., Coronato, A., Naeem, M., and De Pietro,
G. (2018). A reinforcement learning-based approach
for the risk management of e-health environments: A
case study. In 2018 14th International Conference on
Signal-Image Technology & Internet-Based Systems
(SITIS), pages 711–716.
Rashid, T., S amvelyan, M., Schroeder, C., Farquhar, G ., Fo-
erster, J., and Whiteson, S. (2018). QMIX: Monotonic
value function factorisation for deep multi-agent rei n-
forcement learning. In Dy, J. and Krause, A., editors,
Proceedings of the 35th International Conference on
Machine Learning, volume 80 of Proceedings of Ma-
chine L earning Research, pages 4295–4304. PMLR.
Samvelyan, M., Rashid, T., de Witt, C. S. , Farquhar, G.,
Nardelli, N., Rudner, T. G. J., Hung, C., Torr, P. H. S.,
Foerster, J. N., and Whiteson, S. (2019). The starcraft
multi-agent challenge. CoRR, abs/1902.04043.
Sutton, R. S. and Barto, A. G. (1999). Reinforcement learn-
ing: An introduction. Robotica, 17(2):229–235.
Vinyals, O., Ewalds, T., Bartunov, S., Georgiev, P., Vezh-
nevets, A. S. , Yeo, M., Makhzani, A., K¨uttler, H.,
Agapiou, J. P., Schrittwieser, J., Quan, J., Gaffney, S.,
Petersen, S., Simonyan, K., Schaul, T., van Hasselt,
H., Silver, D., Li llicrap, T. P., Calderone, K., Keet,
P., Brunasso, A., Lawrence, D., Ekermo, A., Repp, J.,
and Tsing, R. (2017). Starcraft II: A new challenge
for reinforcement learning. CoRR, abs/1708.04782.
Zhang, Y. and Yu, C. (2023). Expode: Exploiting policy dis-
crepancy for efficient exploration in multi-agent rein-
forcement learning. In Proceedings of the 2023 Inter-
national Conference on Autonomous Agents and Mul-
tiagent Systems, AAMAS ’23, page 58–66, Richland,
SC. International Foundation for Autonomous Agents
and Multiagent Systems.
Action-Based Intrinsic Reward Design for Cooperative Behavior Acquisition in Multi-Agent Reinforcement Learning
639
