
Efficient Multi-Agent Exploration in Area Coverage Under Spatial and
Resource Constraints
Maram Hasan
a
and Rajdeep Niyogi
b
Indian Institute of Technology Roorkee, Roorkee, 247667, India
Keywords:
Multi-Agent Reinforcement Learning, Curiosity-Based Rewards, Exploration, Coverage Path Planning,
Constrained Environments.
Abstract:
Efficient exploration in multi-agent Coverage Path Planning (CPP) is challenging due to spatial, resource, and
communication constraints. Traditional reinforcement learning methods often struggle with agent coordina-
tion and effective policy learning in such constrained environments. This paper presents a novel end-to-end
multi-agent reinforcement learning (MARL) framework for area coverage tasks, leveraging the centralized
training and decentralized execution (CTDE) paradigm with enriched tensor-based observations and curiosity-
based intrinsic rewards, which encourage agents to explore under-visited regions, enhancing coverage effi-
ciency and learning performance. Additionally, prioritized experience adaptation accelerates convergence by
focusing on the most informative experiences, improving policy robustness. By integrating these components,
the proposed framework facilitates adaptive exploration while adhering to the spatial, resource, and operational
constraints inherent in CPP tasks. Experimental results demonstrate superior performance over traditional ap-
proaches in coverage tasks under variable configurations.
1 INTRODUCTION
Multi-agent systems (MAS) are increasingly applied
in diverse domains that require coordinated opera-
tions across complex environments. These systems
enable agents to collaboratively achieve tasks de-
manding extensive spatial coverage, adaptability, and
efficient information gathering, often exceeding the
capabilities of individual agents. One prominent ap-
plication is Coverage Path Planning (CPP), where
agents develop optimal routes to ensure thorough
area coverage while minimizing gaps and overlap-
ping (Tan et al., 2021).The main goal of CPP is to
ensure that every location within an environment is
visited at least once, while adhering to optimization
constraints (Orr and Dutta, 2023). It has become in-
dispensable in fields like autonomous cleaning, pre-
cision agriculture, space exploration, and search-and-
rescue operations, where systematic coverage is es-
sential for operational efficiency and high-quality out-
comes (Yanguas-Rojas and Mojica-Nava, 2017).
Implementing efficient multi-agent coordination
in CPP poses significant challenges, particularly due
a
https://orcid.org/0000-0001-9040-5842
b
https://orcid.org/0000-0003-1664-4882
to spatial and operational constraints, resource lim-
itations, and communication challenges. These fac-
tors shape how agents navigate and interact to achieve
the goal of full area coverage while minimizing re-
source consumption and optimizing efficiency. In
structured environments, such as warehouses, spatial
constraints require agents to operate within physical
defined boundaries like walls and other structural el-
ements, necessitating precise navigation and strategic
path planning. Additionally, they encompass cover-
age completeness, ensuring all regions within the en-
vironment are visited at least once with minimal over-
lap, requiring paths that avoid redundancy.
Resource efficiency is equally critical in CPP, es-
pecially in mission-critical scenarios, where agents
must minimize energy consumption and time by se-
lecting paths that achieve full coverage while avoiding
unnecessary detours or delays (Ghaddar and Merei,
2020). Furthermore, dynamic obstacles, such as hu-
man workers, other robots, or moving machinery, in-
troduce further unpredictability. Agents must con-
tinuously adapt their paths in real time to avoid col-
lisions, recalibrating routes in response to these ob-
stacles to ensure safety and operational effectiveness.
Together, spatial constraints, resource efficiency, and
dynamic obstacles create a challenging environment
1278
Hasan, M. and Niyogi, R.
Efficient Multi-Agent Exploration in Area Coverage Under Spatial and Resource Constraints.
DOI: 10.5220/0013321600003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 3, pages 1278-1287
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

for traditional path planning, requiring innovative ap-
proaches to improve adaptability and efficiency.
In recent years, reinforcement learning (RL) has
emerged as a promising solution for dynamic robotic
decision-making. It enables agents to learn behaviors
through trial-and-error interactions with the environ-
ment rather than relying on explicit manual program-
ming. Advancements in multi-agent reinforcement
learning (MARL) extend this capability, offering ro-
bust solutions to tackle diverse challenges by allow-
ing multiple agents to collaborate effectively, adapt to
environmental changes in real time, and achieve coor-
dinated coverage through learning-based approaches.
Multi-agent exploration in area coverage using re-
inforcement learning algorithms can be categorized
into end-to-end and two-stage approaches (Garaffa
et al., 2021). End-to-end methods treat exploration
as a unified process, where raw or processed sen-
sor data is input directly into an RL policy, which
generates control actions for the agent (Chen et al.,
2019b). This approach entrusts RL with all aspects
of the exploration task. In two-stage approaches, RL
is integrated with conventional methods by dividing
decision-making into distinct components. One usage
involves RL determining target locations, with classi-
cal algorithms like Dijkstra or A* (Stentz, 1994) han-
dling path planning independently. Another applies
RL exclusively to path planning, where partitioning
algorithms such as dynamic Voronoi assign targets,
leaving RL to navigate to these destinations (Hu et al.,
2020). A third variation employs separate RL mod-
els for target selection and path planning in a layered
structure, enabling agents to address intricate explo-
ration tasks at the cost of higher computational over-
head (Jin et al., 2019).
Our work focuses on developing an advanced
MARL framework that addresses these spatial and re-
source constraints, as well as communication limita-
tions, to enhance exploration and coverage in multi-
agent systems. By integrating enriched state repre-
sentations, intrinsic motivation and prioritized expe-
rience adaptation, we aim to enhance agents’ explo-
ration and learning efficiency under these constraints.
2 RELATED WORK
2.1 Classical Optimization Methods
Classical optimization and heuristic methods have
laid the foundation for coverage path planning (CPP)
in multi-agent systems especially given the NP-hard
nature of this problem (Chen et al., 2019a). Frontier-
based exploration (Yamauchi, 1997), a systematic
spatial exploration method, involves agents identify-
ing the boundary between explored and unexplored
areas, known as frontiers, and move toward these re-
gions to maximize coverage. Cooperative frontier-
based strategies extend this approach by enabling
agents to share information and coordinate move-
ments, thereby reducing redundant exploration and
improving execution efficiency (Burgard et al., 2005).
Sweeping-based methods enable agents to sys-
tematically cover areas in coordinated patterns, typ-
ically moving in parallel or predefined formations to
ensure comprehensive coverage with minimal over-
lap (Tran et al., 2022). These approaches are effective
in both communication-enabled and communication-
free scenarios, maximizing coverage while minimiz-
ing redundancies (Sanghvi et al., 2024). Meanwhile,
biologically inspired swarming algorithms leverage
local interaction rules to achieve complex and sta-
ble coordinated behaviors (Gazi and Passino, 2004).
Building on this, decentralized swarm-based ap-
proaches have been developed for dynamic coverage
control, allowing agents to adapt to environmental
changes (Atınc¸ et al., 2020). This adaptability proves
particularly valuable for tasks requiring real-time re-
allocation of coverage areas (Khamis et al., 2015).
Classical methods, while useful, are limited in dy-
namic and complex environments due to their reliance
on static rules. They struggle with redundant cov-
erage, limited adaptability to dynamic obstacles and
unexpected change, and coordination challenges as
agent numbers increase. These limitations highlight
the need for learning-based approaches that enable
autonomous adaptation, improved coordination, and
effective handling of multi-agent coverage tasks.
2.2 Learning-Based Methods
Recently, learning methods have been increasingly
applied to coverage path planning tasks, with rein-
forcement learning enabling agents to learn and adapt
autonomously in complex environments (Zhelo et al.,
2018). Early studies focused on single-agent RL,
such as the application of Double Deep Q-Network
(DDQN) to train individual agents in a simulated
grid-world environment (Li et al., 2022), improving
navigation without explicit inter-agent coordination.
Meanwhile, centralized approaches like (Jin et al.,
2019) combine deep Q-networks (DQN) for target se-
lection with DDPG for adjusting agents’ rotations, fa-
cilitating coordinated movements through centralized
target selection. These approaches faced scalability
challenges as the number of agents increased.
Traditional reinforcement learning have been ex-
tended to multi-agent settings, enabling agents to
Efficient Multi-Agent Exploration in Area Coverage Under Spatial and Resource Constraints
1279
collaboratively learn strategiedemands that enhance
coverage and adaptability in real time. End-to-end
MARL algorithms such as Multi-agent Proximal Pol-
icy Optimization (Chen et al., 2019b), directly learn
coordinated exploration strategies from raw sensory
data leveraging convolutional neural networks to pro-
cess multi-channel visual inputs. Similarly, a QMIX-
based algorithm with a modified loss function and
sequential action masking (Choi et al., 2022) has
been applied to improve coordination among Auto-
mated Guided Vehicles in cooperative path planning.
Two-stage MARL approaches divide tasks into high-
level decision-making and low-level execution lay-
ers. For instance, hierarchical cooperative explo-
ration (Hu et al., 2020) uses dynamic Voronoi parti-
tioning to assign unique exploration areas to agents,
while (Setyawan et al., 2022) employs two levels of
hierarchies with Multi-agent Deep Deterministic Pol-
icy Gradient (MADDPG) at each layer for effective
coordination in multi-agent coverage tasks.
On another note, exploration in multi-agent re-
inforcement learning is critical for efficient learning
and faster convergence, particularly in complex en-
vironments where traditional methods like epsilon-
greedy or noise-driven exploration fall short. Alter-
native methods have been proposed such as employ-
ing graph neural networks in (Zhang et al., 2022)
for coarse-to-fine exploration, while a combination of
DQNs and graph convolutional networks was utilized
in (Luo et al., ) for sequential node exploration on
topological maps. Furthermore, curiosity-based in-
trinsic reward mechanisms have emerged as a promis-
ing technique for exploration where it was integrated
with the asynchronous advantage actor-critic (A3C)
algorithm to enable effective mapless navigation in
single-agent systems (Zhelo et al., 2018), demonstrat-
ing significant improvements over traditional explo-
ration methods. Therefore, we are motivated to incor-
porate a curiosity-based intrinsic reward mechanism
to enhance exploration in multi-agent learning.
Our proposed end-to-end MARL architecture ex-
tends MADDPG (Lowe et al., 2017) to facilitate adap-
tive exploration that adheres to spatial and resource
constraints. By leveraging intrinsic rewards, enriched
state representations, and priority buffer adaptation,
it effectively addresses these challenges and achieves
superior performance in complex coverage tasks.
3 PROBLEM DEFINITION
We consider the task of coverage path planning where
the goal is to effectively and fully cover a given
environment while reducing resource consumption
and redundancy. The desired path should (a) vis-
its all previously unvisited locations to ensure com-
plete coverage, (b) effectively navigates around ob-
stacles, and (c) minimizes the total operational time.
Each agent operates autonomously under the follow-
ing constraints: limited perception range, constrained
battery capacity, and dynamic obstacle avoidance.
We consider a structured indoor environment E,
such as a warehouse or industrial facility, character-
ized by obstacles that influence agent movement. The
environment has dimensions M × N, where M and N
denote the length and width, respectively. Specific en-
vironment attributes, such as obstacle count, location,
and size, are generated based on a predefined prob-
ability distribution P . In the environment E, we de-
fine I a set of k agents, with a specified diameter d
a
.
The environment is discretized into cells of size d
a
,
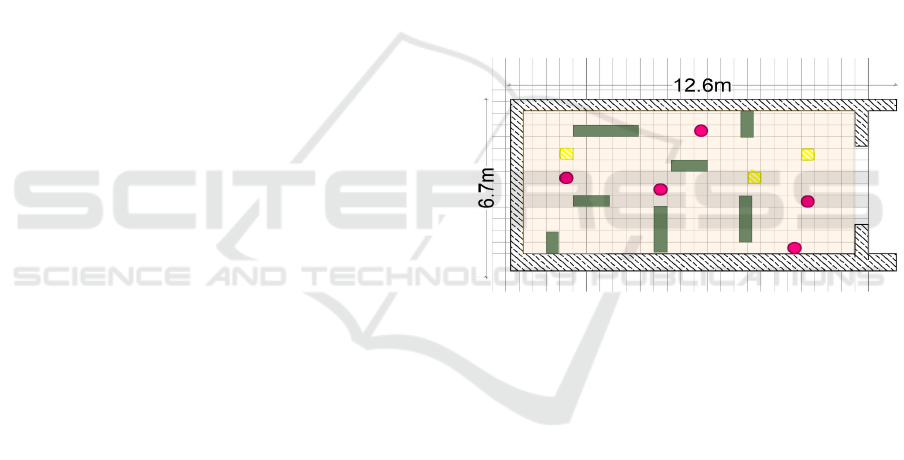
where each cell represents a fixed spatial unit. Figure
1 shows the discretization process of the multi-agent
environment with dynamic and static obstacles.
Figure 1: A discretized indoor structured environment, fea-
turing a team of five agents (purple circles) navigating dy-
namic and static obstacles (yellow and grey, respectively) to
achieve efficient exploration and coverage.
3.1 Problem Formalization
In our cooperative multi-agent coverage path plan-
ning environment, each agent operates with a pol-
icy guided solely by local observations rather than a
global state s, which remains unknown to all agents.
To capture this limited information access, we for-
malize the problem using a Decentralized Partially
Observable Markov Decision Process (Dec-POMDP)
framework. The objective is to learn a joint policy
π = {π
1
, π
2
, . . . , π
k
}, comprising individual policies
that collectively optimize the cumulative discounted
rewards over a defined planning horizon h.
Starting at an initial state s
0
, at each time step t,
the environment has a global state s
t
∈ S, each agent
i ∈ I selects actions based solely on its own local ob-
servations o
i
∈ O
i
. Each agent i interacts indepen-
dently within its observation space O
i
, choosing ac-
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1280

tions according to its policy π
i
. After executing the
joint action a
t
= (a
1
t
, a
2
t
, . . . , a
k
t
) ∈ A, where A denotes
the joint action space, the environment transitions to
the next state s
t+1
∈ S as per a transition probability
T (s
t+1
|s
t
, a
t
). Each agent receives a reward reflecting
quality of action (section 5.1). Dec-POMDP embod-
ies a fully decentralized structure, where agents inde-
pendently execute actions and receive local rewards
based on their actions and observations.
4 METHODOLOGY
4.1 Multi-Agent Deep Deterministic
Policy Gradient (MADDPG)
We extend MADDPG (Lowe et al., 2017) to learn
efficient policies for coverage path planning. While
MADDPG inherently supports continuous action
spaces, our framework employs a posteriori dis-
cretization using a grid-based approach to facilitate
coverage tracking and reward computation. During
training, the centralized critic accesses the global state
and actions of all agents, capturing inter-agent depen-
dencies. However, decentralized execution enables
agents to act independently based on local observa-
tions, ensuring scalability and adaptability. While
centralized approaches are computationally demand-
ing and impractical for real-time execution, fully de-
centralized methods often result in suboptimal per-
formance due to limited awareness of global context.
MADDPG addresses these challenges by employing
a centralized critic during training and decentralized
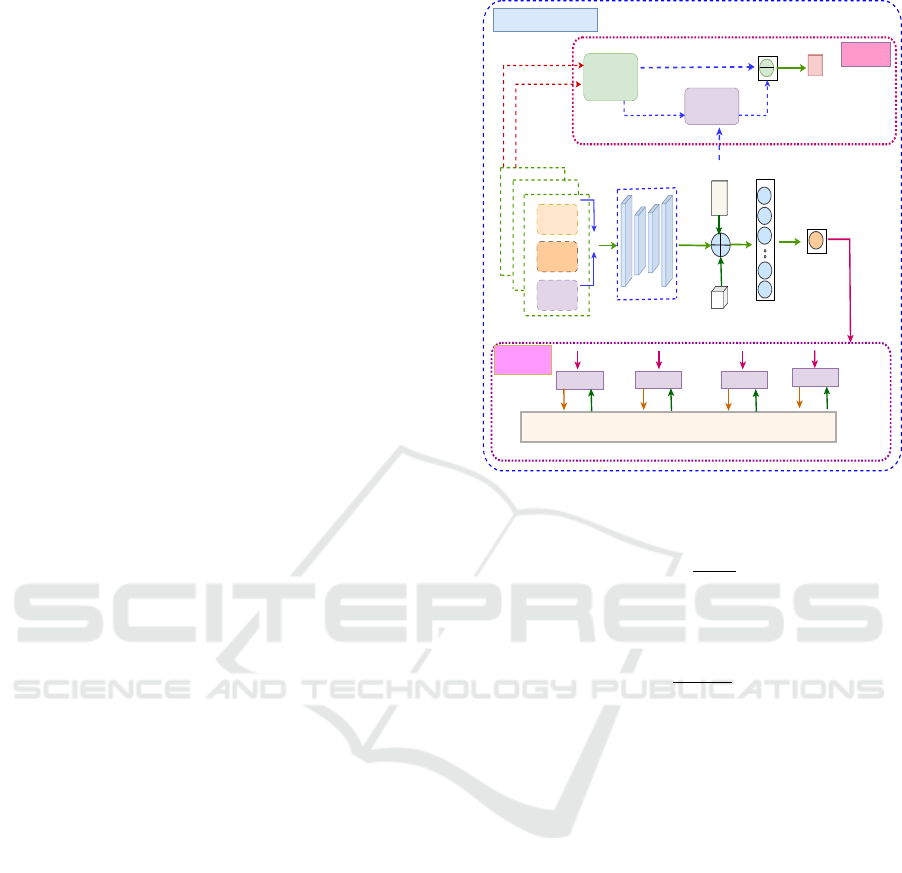
actors for execution. Figure 2 shows the components
and interactions of the proposed framework.
The Actor Network π
θ
i
: Each agent i selects action
a
i
= π
θ
i
(o
i
) based on local observations o
i
, thereby
facilitating decentralized decision-making. The ob-
jective of the actor network is to learn a deterministic
policy π
θ
i
that maximizes the expected cumulative re-
ward by minimizing the following loss function L
π
i
:
L
π
i
= −E
o
i
∼D
Q
φ
i
(s, π
θ
i
(o
i
), a
−i
)
,
where D is the replay buffer storing past experiences
for sampling, Q
φ
i
is the centralized critic’s estimate of
the Q-value, and a
−i
denotes the actions taken by all
agents except agent i. This loss function encourages
each actor to take actions that maximize the central-
ized Q-value estimates, thereby aligning the individ-
ual agent’s actions with the overall system’s objective.
The Critic Network Q
φ
i
: It evaluates the quality of
the joint actions by estimating the expected cumula-
tive reward for a given state-action pair. It takes as
input the full state s (global information) and the joint
action vector a = (a
1
, a
2
, . . . , a
N
) and produces as out-
put the estimated Q-value Q
φ
i
(s, a). The critic mini-
mizes the temporal difference (TD) error L
Q
i
:
L
Q
i
= E
(s,a,r,s
′
)∼D
h
Q
φ
i
(s, a) − y
2
i
where the target value y is defined as:
y = r
i
+ γE
a
′
∼π
Q
φ
i
(s
′
, a
′
)
Here, r
i
is the agent’s local reward, γ is the discount
factor that balances the influence of future and im-
mediate rewards, and s
′
represents the next state af-
ter taking the joint action. Minimizing TD error im-
proves Q-value estimation accuracy, providing mean-
ingful feedback for actor training. This feedback en-
sures the development of strategies that enhance over-
all system performance.
4.2 Curiosity-Based Exploration
The curiosity-driven mechanism further complements
this framework by incentivizing agents to explore un-
visited areas, overcoming the limitations of local ob-
servations in decentralized execution. Traditional ex-
ploration strategies, such as epsilon-greedy or noise-
driven methods, often prove insufficient for environ-
ments that require comprehensive coverage and thor-
ough exploration, as they may fail to guide agents ef-
fectively through obstacles and complex layouts.
The curiosity reward is learned using a self-
supervised approach, driven by the prediction error
between the agent’s anticipated state features and the
actual observed features. Specifically, it uses a feature
extraction network f
ψ
parameterized by ψ, to process
each state s and generate a feature vector φ(s) = f
ψ
(s)
focusing on relevant aspects of the state while reduc-
ing complexity. Next, the extracted features serve as
input to a forward dynamics model
ˆ
f
θ
which predicts
the next state’s feature vector based on the current
state and action
ˆ
φ(s
′
) =
ˆ
f
θ
(φ(s), a).
The intrinsic reward r
curiosity
is then computed as the
prediction error between the predicted and the actual
observed feature vector
ˆ
φ(s
′
):
R
curiosity
= ∥φ(s
′
) −
ˆ
φ(s
′
)∥
2
where ∥ · ∥ denotes the Euclidean norm. This mecha-
nism encourages agents to explore novel states where
the prediction error is high, effectively guiding them
toward under-explored areas. By integrating this cu-
riosity reward with extrinsic rewards defined by the
environment, the actor network learns policies that
balance exploration and exploitation. The centralized
critic further refines these policies by incorporating
Efficient Multi-Agent Exploration in Area Coverage Under Spatial and Resource Constraints
1281
global state information during training, ensuring the
learned strategies align with the overall objective.
4.3 Tensor-Like State Representation
For each agent, the observation is represented as
a multi-layered tensor to enhance spatial awareness
and environmental understanding. This representa-
tion comprises three channels: an occupancy map
that indicating agent positions and dynamic obstacles,
an obstacle map highlighting static obstacles, and a
visitation map recording the frequency of cell visits.
By structuring these features in an image-like format,
agents gain spatial context, allowing them to distin-
guish between frequently and infrequently visited re-
gions. The multi-layered configuration facilitates the
use of convolutional processing, enabling agents to
leverage spatial patterns more effectively, and ulti-
mately implement more efficient coverage strategies.
4.4 Priority Buffer Adaptation
In reinforcement learning, standard experience re-
play buffers employ random sampling assigning equal
probability to all experiences, treating them as equally
valuable for agent’s learning process. While effec-
tive in simpler tasks, this approach can delay learn-
ing in complex multi-agent environments where ex-
periences vary significantly in their impact on explo-
ration and coordination strategies. To address this,
we implement a Prioritized Experience Replay (PER)
buffer (Schaul, 2015) that assigns higher sampling
probabilities to more informative experiences, such as
successful exploration steps or collisions, over repet-
itive navigation. Experiences with larger temporal-
difference (TD) errors where predictions diverge most
from latest observed outcomes are prioritized, accel-
erating convergence in challenging tasks.
The priority p
i
of an experience i is computed as:
p
i
= (|δ
i
| + ε)
α
where δ
i
is the TD error, ε is a small constant ensures
non-zero priority, and α ∈ [0, 1] controls the level of
prioritization, the higher values the more focus on
high-error experiences. The TD error δ
i
is defined as:
δ
i
= r + γQ(s
′
, a
′
;θ
′
) − Q(s, a;θ)
where r is the reward, s and a are the state-action pair,
s
′
and a
′
are the next state and action, γ is the dis-
count factor, and Q represents the action-value func-
tion parameterized by θ (current) and θ
′
(target net-
work). The sampling probability from the prioritized
buffer for experience i is computes as:
input
state
Convolutional
Network
agents
occupancy
map
obstacles
occupancy
map
visitation
map
Coverage
Progress
Actions
Feature
Extractor
next state
current state
Forward
Model
Curiosity
Reward
Centralized Training
Environment
Actor 1
Actor 2 Actor 3
O
1
a
1
Decentralized
Execution
Curiosity
Module
Actor n
O
2
a
2
O
3
a
3
O
n
a
n
Q
n
Q
3
Q
2
Q
1
Q
i
Critic
Output
Figure 2: Our framework architecture showing the critic and
actors interactions, and the curiosity module.
P(i) =
p
i
∑
j
p
j
To correct for sampling bias introduced by prioritiza-
tion, importance-sampling (IS) weights are used as :
w
i
=
1
N · P(i)
β
where N is the total number of experiences, and β ∈
[0, 1] gradually increases to 1 to reduce bias as learn-
ing progresses. These IS weights adjust the loss, en-
suring unbiased gradient updates. By prioritizing ex-
periences with greater informational value, the buffer
enhances the model’s ability to learn robust policies
and accelerates convergence, particularly in environ-
ments where specific state-action pairs have a dispro-
portionate impact on overall performance.
5 EXPERIMENTS
5.1 Task Description
In this coverage problem, we consider an environment
that simulates a real-world warehouse area where
agents move efficiently to ensure complete coverage.
This coverage may include inspection, surveillance,
or cleaning operations across the warehouse. The
warehouse layout is converted into a grid map. Trans-
forming the continuous space and actions of the en-
vironment into discretized equivalents, as shown in
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1282
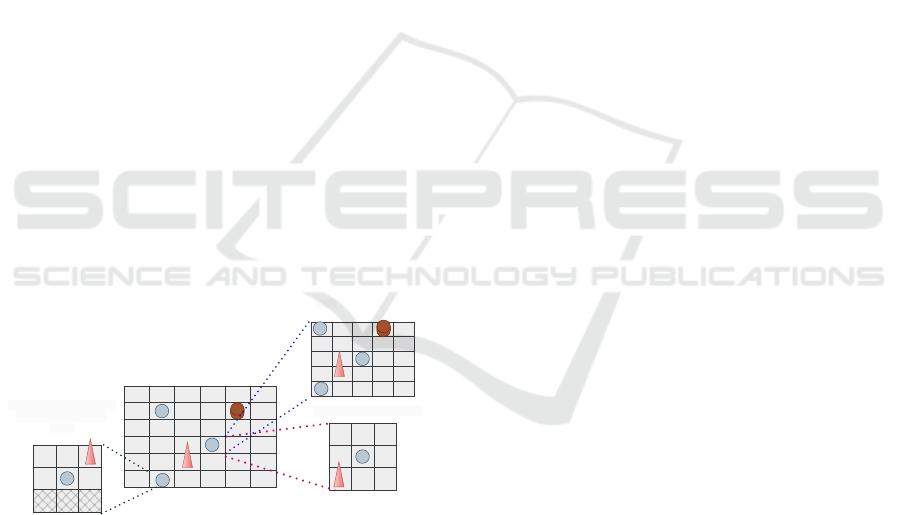
Figure 1. Each grid cell (i, j) represents a unique spa-
tial location that requires coverage, with a fixed size
equal to the agent diameter d
a
, for example, (0.5 m ×
0.5 m). The dynamic obstacles within the grid intro-
duce complexity by changing its positions over time.
Agent Configuration. Each agent a
k
in the environ-
ment has the following characteristics:
• Battery Capacity B
k
: Maximum energy the agent
can utilize before recharging is required.
• Perception Range P
k
: Fixed distance within
which the agent observes nearby obstacles,
agents, and grid cells.
• Neighborhood Set N
k
(t): All observable entities
within agent’s perception range P
k
, including dy-
namic and static obstacles and other agents.
Observation Space. While the centralized critic
has full-observability of the environment, the Actor
for each agent operates with partial observability, re-
lying only on localized information rather than com-
plete global awareness. Each agent is limited to its
perception range, able to observe information within
its z × z perception window centered around a
k
’s po-
sition. For example, within a 5 × 5 grid, the agent
observes obstacles, other agents, cell coverage status
within this window. Agents occupy one grid cell at a
time and can move to adjacent cells if they are valid
cells. Figure 3 illustrates the observations accessible
to agents within their perception range across various
scenarios of a discretized environment.
5 x 5 Perception Range
3 x 3 Perception Range
3 x 3 Perception Range
at Lower Boundary
Point
Figure 3: The observations and perception range of each
agent in a discretized environemnt.
Action Space. Each agent has a discrete action space
A
i
, representing the set of all possible actions it can
take in the environment. This includes the primitive
actions of moving in the standard 2D directions, as
well as the NoOp (No Operation) action, used when
no other action is appropriate or necessary.
A
i
= {U p, Down, Le f t, Right, NoOp}
At each time t, agent a
k
selects an action to navigate
the grid. All agents share the same travel velocity for
the purpose of simplicity.
Dynamics. State transitions are influenced by the ac-
tions of all agents and the movement of dynamic ob-
stacles. The state s(t + 1) depends on the joint ac-
tion {a
k
(t)} for all agents and the obstacle dynamics.
Agents experience transitions to specific cells based
on their chosen actions.
Action Masking. Agents face significant challenges
in avoiding collisions, such as moving into walls or
static obstacles. To address this, we employ an action
masking mechanism that preemptively restricts infea-
sible actions, ensuring safer navigation and minimiz-
ing uninformative experiences that could hinder train-
ing. However, collisions with dynamic obstacles are
managed separately through the reward mechanism.
Reward Signal. Our environment operates under
dense rewards setting, where each agent receives re-
ward signal at each timestep. This signal encour-
ages efficient coverage by rewarding agents for cov-
ering new cells, penalizing multiple visits to already-
covered cells, and discouraging excessive energy us-
age. Thus, incentiving agents to prioritize uncovering
new cells until full coverage is achieved.
• Coverage Reward R
cover
: A positive reward for
covering an uncovered cell (i, j) where V
tot
(i, j),
the total visitation count of cell (i, j) across all
agents, is equal to zero. This encourages agents
to prioritize new areas for coverage.
R
cover
=
(
+10 if V
tot
(i, j) = 0, (cell is uncovered)
0 otherwise
• Overlapping Penalty R
overlap
: A negative penalty
is applied when an agent visits a cell (i, j) already
covered by any agent, with λ controlling the sever-
ity. This discourages frequent overlaps, encourag-
ing agents to minimize revisits to previously cov-
ered areas:
R
overlap
=
−min
0.5 ·V
tot
(i, j)
1.5
, 5
if (i, j) is
covered
0 otherwise.
• Energy-Aware Penalty R
energy
: To account for
resource constraints, a negative penalty propor-
tional to energy usage is applied to promote effi-
cient path choices. The energy consumption E
k
(t)
for agent a
k
is constrained by:
T
∑
t=0
E
k
(t) ≤ B
k
, ∀k ∈ I
where E
k
(t) denotes the total energy used along
its path up to timestep t, based on movement and
turns. The penalty R
energy
is defined as:
Efficient Multi-Agent Exploration in Area Coverage Under Spatial and Resource Constraints
1283

R
energy
=
(
−(λ
1
· d + λ
2
· θ) if a
k
moves or turns
−λ
3
if a
k
stays NoOP
Here, d is the per-timestep distance traveled, θ
is the turning angle, and constants λ
1
, λ
2
and λ
3
represent the energy consumed per unit distance,
per degree of turn, and for NoOp actions, respec-
tively. A small penalty λ
3
encourages agents to
move instead of getting stuck. For this work, we
use λ
1
= 0.11, λ
2
= 0 and λ
3
= 0.15 as rotation
actions are not included in the action space.
• Collision Penalty R
collision
: A penalty is applied
when the distance between agent a
k
and any ob-
stacle within its perception range obs ∈ O
k
falls
below a predefined margin d
margin
, or if the agent’s
new position is occupied by other agents or obsta-
cles. This mechanism encourages agents to avoid
collisions and maintain safe navigation.
R
collision
=
−1 if d
Manhattan
(a
k
, obs) ≤ d
margin
−10 if (x
k
(t + 1), y
k
(t + 1))occupied
0 otherwise
where d
Manhattan
(a
k
, obs) = |x
k
−x
obs
|+|y
k
−y
obs
|
represents the manhattan distance between the
agent and any obstacle in its perception range.
The cumulative reward R
k
(t) for agent a
k
at each
timestep t is defined as:
R
k
(t) = R
cover
+ R
overlap
+ R
energy
+ R
collision
(1)
Finally, the total reward signal incorporates the
curiosity-based intrinsic reward to promote efficient
exploration during training.
R
total
= R
k
(t) + α
curiosity
· R
curiosity
(2)
The weight, α
curiosity
∈ [0, 1], controls the contribution
of the curiosity reward to the final reward signal.
5.2 Implementation Details
In this section, we detail the implementation setup of
our experiments, focusing on the application of our
framework in a warehouse environment. The exper-
iments were conducted on two discretized environ-
ments of sizes 10 × 10 and 20 × 20 representing a
5m × 5m and 10m × 10m warehouses. These envi-
ronments features three agents in the smaller grid and
five in the larger one, along with static obstacles (15
and 40, respectively). The agents’ objective was to
achieve complete coverage of the grid while minimiz-
ing redundant exploration under spatial constraints.
In our experiments, we consider two levels of obser-
vation:
• Proximal Information Level (PIL) provided
agents with basic positional information about
their immediate neighborhood, denoted as N
k
(t).
Agents only perceive their immediate surrounding
cells, leading to limited situational awareness.
• Enriched Tensor-based Representation (ETR)
introduced an extended observational details, in-
corporating our proposed tensor-like state repre-
sentation in addition to historical visitation fre-
quencies and coverage.
In MADDPG, each agent has actor and critic net-
works. In the Proximal Information Level, both net-
works are feedforward: the actor has three layers with
ReLU activation and a softmax output, while the critic
uses four layers with ReLU activation to estimate Q-
values for joint actions. In the Enriched Tensor-Based
Representation (ETR), convolutional layers process
tensor-like observations, capturing spatial and tem-
poral dependencies. The actor processes local ob-
servations via CNNs (16, 32 filters, 3 × 3, stride 1,
ReLU), followed by a 64-unit LSTM layer and fully
connected layers with 256, 128 units, producing ac-
tion probabilities via a softmax layer. The LSTM
addresses partial observability. The critic processes
global state information through two convolutional
layers and fully connected layers (256, 128, and 64
units), integrating a coverage progress tensor for Q-
value computation.
The curiosity module includes a feature extraction
network with two convolutional layers, followed by
a fully connected layer producing a 64-dimensional
embedding. This embedding is used by the forward
dynamics model, which consists of two fully con-
nected layers with 64 and 32 units, followed by ReLU
activation, to predict the next state’s features. All
models are jointly optimized using Adam optimizers
with learning rates of 5 × 10
−4
for actors, 10
−3
for
critics, and 10
−3
for the curiosity module. Training
is conducted with a replay buffer size of 10
5
, a batch
size of 128, a discount factor γ = 0.95, and a soft up-
date factor τ = 0.01. Each episode comprises of 90 or
140 steps depending on the environment size.
The experimental evaluation covered the following
configurations:
1. MADDPG (Proximal Information Level):
Standard MADDPG using basic positional
information, without intrinsic rewards or en-
hancements. Agents received limited local
observations from a 3 × 3 and a 9 × 9 window.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1284

Table 1: Comparison of coverage percentages between MADDPG and our approach across different observation levels and
window sizes.
Configuration
Proximal Information Level PIL Enriched Tensor-Based Representation ETR
3x3 9x9 5x5 17x17
MADDPG 56.47 (%) 65.88 (%) 50.88 (%) 35.67 (%)
Our Approach 72.94 (%) 86.24 (%) 85.94 (%) 90.66 (%)
2. Our framework (Enriched Tensor-based Rep-
resentation): Enhanced MADDPG utilizing en-
riched observation, intrinsic curiosity-based re-
wards, and Prioritized Experience Replay (PER).
The observation window is 5 × 5 and 17 × 17.
Average cumulative rewards and coverage percent-
ages were recorded over 5000 episodes. Cover-
age was measured as the ratio of visited cells to
the total number of grid cells, excluding obstacle
cells. Agent behaviors were visualized using visita-
tion maps, which highlighted the distribution of agent
visits and identified areas with insufficient coverage.
6 RESULTS AND DISCUSSIONS
In our initial experiments under proximal information
level (PIL), each agent is provided with a limited ob-
servation window containing only basic positional in-
formation of agent’s neighborhood set N
k
(t) within
its perception range. This local observation offers
a minimal situational awareness, lacking any global
context or historical visitation data. Despite exten-
sive training across multiple episodes, as shown in
4b, agents under this configuration consistently fail to
achieve effective coverage of the environment, capped
at 56.47% for a 3x3 window and 65.88% for a 9x9
window, as indicated in Table 1. Their movement pat-
terns are highly repetitive, and they often become con-
fined to specific areas, resulting in significant gaps in
overall coverage as shown is Figure 4a. This subopti-
mal behavior indicates that, even with the exploration
noise embedded in MADDPG, the agents struggle to
explore the environment effectively. The limited ob-
servational information in PIL restricts each agent’s
perspective to its immediate surroundings, making it
challenging to make informed movement decisions
that promote efficient coverage. Consequently, agents
often revisit previously explored cells rather than dis-
covering unvisited parts of the grid, impeding com-
prehensive exploration.
Furthermore, in the more challenging 20x20 envi-
ronment, MADDPG with PIL showed a similar trend
of limited coverage. Using a 5x5 window, MAD-
DPG agents achieved only 50.88% coverage, strug-
gling to adapt their strategies effectively in a larger
space as shown in Figure 5a and Figure 5b. When
the window was further expanded to 17x17, cover-
age unexpectedly dropped to 35.67%, a significant
29.89% decrease from the performance in 5x5 con-
figuration. This decline could be attributed to the
sparsity of useful information in the PIL observation
space. The larger observation window introduces a
majority of zero values, representing empty space,
with only limited non-zero values for obstacles and
agent IDs. This representation lacks the necessary
variation for learning meaningful policies, effectively
overwhelming the learning process and reducing the
agents’ ability to extract relevant environmental fea-
tures. Consequently, agents failed to prioritize unex-
plored regions, leading to confined and unproductive
movement patterns.
To address these limitations, we incoporated an
enriched tensor-based representation that expands the
observation space to include additional layers, such
as historical visitation frequency in an image-like for-
mat, and used CNN to process the input efficiently.
This enriched observation along with the cuiriosity-
based rewards significantly enhanced agent perfor-
mance across all scenarios by incorporating histori-
cal visitation data and additional spatial context into
the observation space. In the 10x10 environment,
ETR achieved 72.94% coverage with a 3x3 observa-
tion window, marking a 29.23% improvement over
MADDPG with PIL. Figure 4c and Figure 4d demon-
strated an example coverage and average rewards of
our framework with PIL. Expanding the observation
window to 9x9 further boosted coverage to 86.24%,
a 30.91% improvement over the PIL configuration.
This demonstrates that historical context and spatial
layering facilitate more strategic exploration, allow-
ing agents to prioritize unexplored areas systemati-
cally and make more informed decisions.
Furthermore, with a 17x17 observation window,
our proposed configuration achieved a notable cov-
erage level of 90.66% and a stable learning and in-
creased cumulative rewards over training episodes as
shown in Figure 5c and Figure 5d respectively. This
result reflects a substantial 42.63% absolute improve-
ment under ETR in coverage over the PIL configura-
tion under the same settings. This enhancement is at-
tributed to ETR’s spatial encoding and extended cov-
Efficient Multi-Agent Exploration in Area Coverage Under Spatial and Resource Constraints
1285
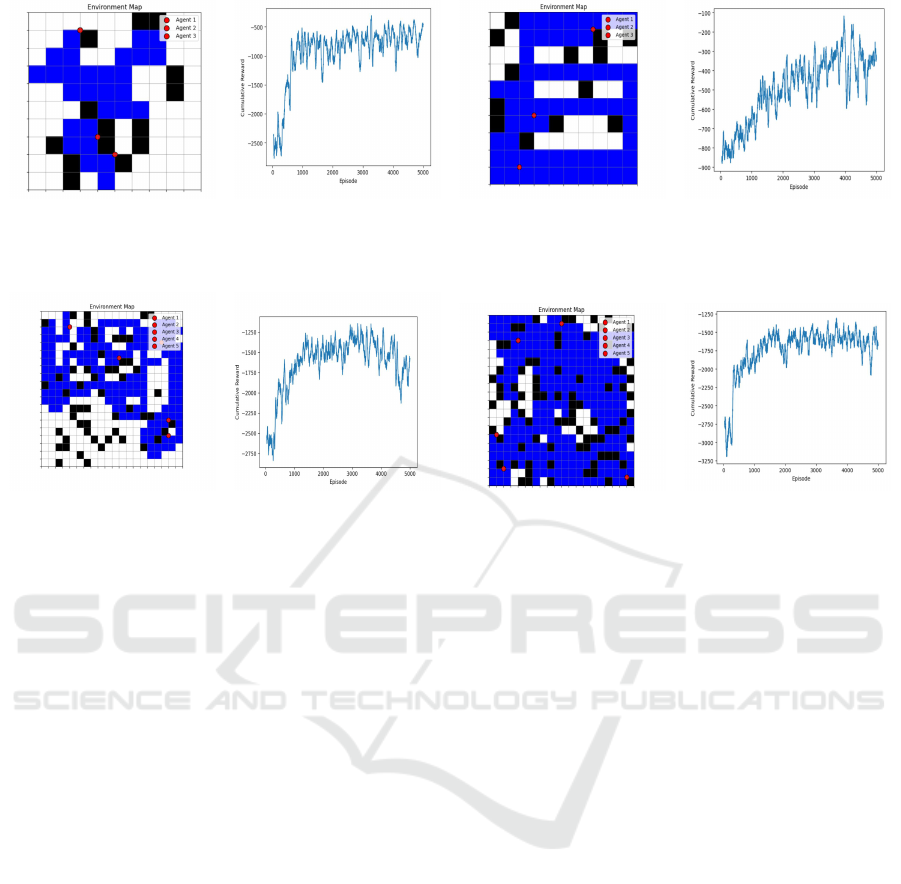
(a) (b) (c) (d)
Figure 4: Performance in the 10x10 environment with three agents under 3x3 observation windows. Subfigures (a) and (b)
depict area coverage and average cumulative rewards using MADDPG and PIL, respectively. While subfigures (c) and (d)
show area coverage and average cumulative rewards using our framework with PIL.
(a) (b) (c) (d)
Figure 5: Performance in the 20x20 environment with five agents. Subfigures (a) and (b) depict area coverage and average
cumulative rewards using MADDPG with a 5x5 observation window, while subfigures (c) and (d) show area coverage and
average cumulative rewards using our framework with ETR and a 17x17 observation window.
erage observations, which effectively address the lim-
itations associated with the sparse, zero-dominated
observations characteristic of PIL. By incorporating
meaningful spatial context and past visitation data,
ETR enables agents to avoid redundant coverage and
strategically prioritize unexplored areas. The integra-
tion of curiosity-driven intrinsic rewards further en-
hances exploration efficiency by incentivizing agents
to seek novel states, promoting balanced and thorough
exploration.
Overall, the results demonstrated an improvement
of up to 42.63% in absolute coverage compared to
baseline approaches, underscoring the effectiveness
of combining enriched observation representations
with intrinsic rewards. Our framework advances the
state-of-the-art MADDPG in the area coverage prob-
lem under spatial constraints, promoting coordinated
and comprehensive exploration in multi-agent envi-
ronments.
7 CONCLUSION
The rising demand for automated and efficient area
coverage in structured environments, such as ware-
houses and industrial facilities, highlights the need
for robust solutions to enhance exploration and coor-
dination in multi-agent environments under resource
limitations and complex spatial constraints. The pro-
posed framework integrates an enriched tensor-based
representation and prioritized experience replay with
curiosity-driven intrinsic rewards to utilize spatial en-
coding and visitation history, driving agents to ex-
plore novel and less-visited areas. Prioritized expe-
rience sampling further enhances the model’s abil-
ity to learn from most informative experiences to
prompt successful navigation and exploration. To-
gether, these components foster an adaptive and ex-
ploratory learning process, particularly effective in
spatially constrained environments with limited infor-
mation where traditional strategies fall short.
Experimental results demonstrated the efficacy of
the proposed framework, achieving up to a 42.63%
improvement in grid coverage compared to vanilla
PIL-based framework. This improvement was espe-
cially significant in larger and more complex environ-
ments, where ETR facilitated systematic navigation
and comprehensive coverage with reduced overlap.
Notably, during training, the centralized critic sup-
ports inter-agent coordination by leveraging global
state information. Post-training, agents rely solely on
decentralized actors policies and local observations,
ensuring scalability and responsiveness for real-world
robotics without computational overhead.
In conclusion, the proposed framework success-
fully advances the state of the art in MARL for area
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1286

coverage tasks by addressing spatial and resource
constraints. Its ability to integrate enriched observa-
tions, prioritize meaningful experiences, and promote
adaptive exploration makes it a promising solution
for real-world applications in structured and resource-
constrained environments.
ACKNOWLEDGMENTS
The second author was in part supported by a research
grant from Google.
REFERENCES
Atınc¸, G. M., Stipanovi
´
c, D. M., and Voulgaris, P. G.
(2020). A swarm-based approach to dynamic cov-
erage control of multi-agent systems. IEEE Trans-
actions on Control Systems Technology, 28(5):2051–
2062.
Burgard, W., Moors, M., Stachniss, C., and Schneider, F. E.
(2005). Coordinated multi-robot exploration. IEEE
Transactions on Robotics, 21(3):376–386.
Chen, X., Tucker, T. M., Kurfess, T. R., and Vuduc, R.
(2019a). Adaptive deep path: efficient coverage of a
known environment under various configurations. In
2019 IEEE/RSJ International Conference on Intelli-
gent Robots and Systems (IROS), pages 3549–3556.
IEEE.
Chen, Z., Subagdja, B., and Tan, A.-H. (2019b). End-to-end
deep reinforcement learning for multi-agent collabo-
rative exploration. In 2019 IEEE International Con-
ference on Agents (ICA), pages 99–102. IEEE.
Choi, H.-B., Kim, J.-B., Han, Y.-H., Oh, S.-W., and Kim,
K. (2022). Marl-based cooperative multi-agv con-
trol in warehouse systems. IEEE Access, 10:100478–
100488.
Garaffa, L. C., Basso, M., Konzen, A. A., and de Fre-
itas, E. P. (2021). Reinforcement learning for mobile
robotics exploration: A survey. IEEE Transactions on
Neural Networks and Learning Systems, 34(8):3796–
3810.
Gazi, V. and Passino, K. M. (2004). Stability analysis of
swarms. IEEE Transactions on Automatic Control,
48(4):692–697.
Ghaddar, A. and Merei, A. (2020). Eaoa: Energy-aware
grid-based 3d-obstacle avoidance in coverage path
planning for uavs. Future Internet, 12(2):29.
Hu, J., Niu, H., Carrasco, J., Lennox, B., and Arvin, F.
(2020). Voronoi-based multi-robot autonomous ex-
ploration in unknown environments via deep rein-
forcement learning. IEEE Transactions on Vehicular
Technology, 69(12):14413–14423.
Jin, Y., Zhang, Y., Yuan, J., and Zhang, X. (2019). Efficient
multi-agent cooperative navigation in unknown envi-
ronments with interlaced deep reinforcement learn-
ing. In ICASSP 2019-2019 IEEE International Con-
ference on Acoustics, Speech and Signal Processing
(ICASSP), pages 2897–2901. IEEE.
Khamis, A., Hussein, A., and Elmogy, A. (2015). Multi-
robot task allocation: A review of the state-of-the-art.
Cooperative robots and sensor networks 2015, pages
31–51.
Li, W., Zhao, T., and Dian, S. (2022). Multirobot coverage
path planning based on deep q-network in unknown
environment. Journal of Robotics, 2022(1):6825902.
Lowe, R., Wu, Y. I., Tamar, A., Harb, J., Pieter Abbeel,
O., and Mordatch, I. (2017). Multi-agent actor-critic
for mixed cooperative-competitive environments. Ad-
vances in neural information processing systems, 30.
Luo, T., Subagdja, B., Wang, D., and Tan, A.-H. Multi-
agent collaborative exploration through graph-based
deep reinforcement learning. In 2019 IEEE Interna-
tional Conference on Agents (ICA), pages 2–7. IEEE.
Orr, J. and Dutta, A. (2023). Multi-agent deep reinforce-
ment learning for multi-robot applications: A survey.
Sensors, 23(7):3625.
Sanghvi, N., Niyogi, R., and Milani, A. (2024). Sweeping-
based multi-robot exploration in an unknown environ-
ment using webots. In ICAART (1), pages 248–255.
Schaul, T. (2015). Prioritized experience replay. arXiv
preprint arXiv:1511.05952.
Setyawan, G. E., Hartono, P., and Sawada, H. (2022). Coop-
erative multi-robot hierarchical reinforcement learn-
ing. Int. J. Adv. Comput. Sci. Appl, 13:35–44.
Stentz, A. (1994). Optimal and efficient path planning for
partially-known environments. In Proceedings of the
1994 IEEE international conference on robotics and
automation, pages 3310–3317. IEEE.
Tan, C. S., Mohd-Mokhtar, R., and Arshad, M. R. (2021).
A comprehensive review of coverage path planning
in robotics using classical and heuristic algorithms.
IEEE Access, 9:119310–119342.
Tran, V. P., Garratt, M. A., Kasmarik, K., Anavatti, S. G.,
and Abpeikar, S. (2022). Frontier-led swarming: Ro-
bust multi-robot coverage of unknown environments.
Swarm and Evolutionary Computation, 75:101171.
Yamauchi, B. (1997). A frontier-based approach for au-
tonomous exploration. In Proceedings 1997 IEEE In-
ternational Symposium on Computational Intelligence
in Robotics and Automation CIRA’97.’Towards New
Computational Principles for Robotics and Automa-
tion’, pages 146–151. IEEE.
Yanguas-Rojas, D. and Mojica-Nava, E. (2017). Explo-
ration with heterogeneous robots networks for search
and rescue. IFAC-PapersOnLine, 50(1):7935–7940.
Zhang, H., Cheng, J., Zhang, L., Li, Y., and Zhang, W.
(2022). H2gnn: Hierarchical-hops graph neural net-
works for multi-robot exploration in unknown envi-
ronments. IEEE Robotics and Automation Letters,
7(2):3435–3442.
Zhelo, O., Zhang, J., Tai, L., Liu, M., and Burgard,
W. (2018). Curiosity-driven exploration for mapless
navigation with deep reinforcement learning. arXiv
preprint arXiv:1804.00456.
Efficient Multi-Agent Exploration in Area Coverage Under Spatial and Resource Constraints
1287
