
Enhancing Marine Habitats Detection: A Comparative Study of
Semi-Supervised Learning Methods
Rim Rahali
1
, Thanh Phuong Nguyen
2
and Vincent Nguyen
1
1
University of Orleans, INSA-CVL, LIFO UR 4022, Orleans, France
2
I3S, CNRS, UMR 7271, University of Cote d’Azur, France
Keywords:
Semi-Supervised Learning, UIE Methods, Underwater Images, Object Detection, Contrastive Learning.
Abstract:
Most of the recent success in applying deep learning techniques to object detection relies on large amounts
of carefully annotated and large training data, whereas annotating underwater images is a costly process and
providing a large dataset is not always affordable. In this paper, we conduct a comprehensive analysis of
multiple semi-supervised learning models, used for marine habitats detection, aiming to reduce the reliance on
extensive labeled data while maintaining high accuracy in challenging underwater environments. Results, per-
formed on Deepfish and UTDAC2020 datasets attest a significant performance conducted by semi-supervised
learning, in terms of quantitative and qualitative evaluation. An other study related to Underwater Image En-
hancement (UIE) methods and contrastive learning is presented in this work to deal with underwater images
specificity and provide more comprehensive analysis of their impact on marine habitats detection.
1 INTRODUCTION
Detecting marine habitats, or more broadly, Under-
water Object Detection (UOD) represents a challeng-
ing research topic, where difficult underwater envi-
ronments make underwater images suffer from noise,
blur, low contrast, diffusion effect and color distor-
tion (Sarkar et al., 2022). Various UOD techniques
based on deep learning were developed in this con-
text, helping researchers to reach to new levels in ex-
ploring the underwater world (Han et al., 2020; Pan
et al., 2021). Although important results that have
been achieved over the years, UOD techniques are
still limited in front of: 1) The insufficiency in un-
derwater image dataset, 2) The low quality of images
due to complex underwater environment, and 3) The
large number of required labeled images while it is ex-
pensive to annotate and acquire them. Most of deep
learning algorithms rely on the availability of large,
well-balanced and labelled datasets. This type of su-
pervised pipeline can not handle the specificities of
underwater imaging.
Semi-Supervised Object Detection (SSOD)
(Wang et al., 2023) has become an active task in
recent years to deal with label expenditure. It uses
both labeled data and unlabeled data for training
where unlabeled data are more explored for boosting
object detectors and they are relatively easy to collect.
The challenge remains in how to use effectively these
unlabeled data. Teacher-student learning models
were widely used for SSOD (Mi et al., 2022; Li
et al., 2023) and achieved notable success. They
consist of two networks: 1) The teacher network
to generate pseudo-labels for unlabeled data, and
2) The student network to be trained using both
the generated pseudo-labels and ground truth. The
student model updates its weights by training, and the
teacher updates its weights from the student model
by Exponential Moving Average (EMA) (Tarvainen
and Valpola, 2017). Besides, strong and weak data
augmentations are separately applied to enforce the
consistency between the two networks (Cubuk et al.,
2019; Xie et al., 2020). While SSOD methods can
exploit large amounts of unlabeled data to address the
issue of insufficient labeled data in UOD, they has
not gained enough attention in the field of underwater
applications and existing works are still limited
(Zhou et al., 2023). The complexity and diversity
of underwater environments, characterized by low
contrast, blur, color distortion, hazing, and more;
introduce additional difficulties that make UOD more
challenging than general object detection.
To the end, we propose a comprehensive analy-
sis of performance using semi-supervised models, ap-
plied to different marine habitats datasets. On the
other hand, we analyse the impact of Underwater Im-
Rahali, R., Nguyen, T. P. and Nguyen, V.
Enhancing Marine Habitats Detection: A Comparative Study of Semi-Supervised Learning Methods.
DOI: 10.5220/0013325500003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 3: VISAPP, pages
233-244
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
233

age Enhancement (UIE) methods on the performance
of these models. UIE methods are widely applied
to remove blurring, color distortion in images, im-
proving the features of interesting targets while reduc-
ing those of irrelevant background (Xu et al., 2023).
In addition, we integrate contrastive learning (Zhang
et al., 2022b) into existing SSOD methods. It is an
approach that aims to minimize the distance between
similar data points while maximizing the distance be-
tween dissimilar ones in the embedding space. Im-
plementing contrastive learning can lead to improved
feature learning and better overall detection capabili-
ties of underwater object detectors. The main contri-
butions of this work can be listed as follows.
1. We conduct a comprehension analysis of perfor-
mance of three popular SSOD methods, Active
Teacher (Mi et al., 2022), Unbiased Teacher (Liu
et al., 2021), Robust Teacher (Li et al., 2023)
on two marine habitats datasets: Deepfish (Saleh
et al., 2020) and UTDAC2020 (Song et al., 2023).
2. We evaluate different UIE methods applied to
Deepfish and UTDAC2020 datasets and analyse
their impact on detecting marine habitats using
semi-supervised methods.
3. We incorporate contrastive learning into semi-
supervised models and evaluate its impact on de-
tection for Deepfish and UTDAC2020 datasets.
This paper is organized as follows. Section 2 illus-
trates related works; Section 3 presents preliminaries;
we exhibit details of our methodology in Section 4;
we present the experimental results and analyses in
Section 5; and, finally, Section 6 concludes the paper.
2 RELATED WORK
2.1 Underwater Object Detection
In recent years, research on underwater object detec-
tion has undergone a notable transformation, moving
from the use of traditional manual features to em-
bracing deep learning techniques. Initially, traditional
manual features were used in early stages of research
(Yu, 2020). However, these approaches face signifi-
cant limitations when applied to practical underwater
environments. Furthermore, most of underwater ob-
ject detection algorithms that rely on manual feature
extraction process, require professional expertise and
complex algorithm debugging. Recently, the devel-
opment of machine learning has contributed to under-
going research dedicated to underwater object detec-
tion. Methods developed in this field involve extract-
ing and combining traditional artificial features, such
as texture, shape, color and target movement, and then
using them in conjunction with machine learning al-
gorithms to perform underwater object detection. For
example, in (Srividhya and Ramya, 2017), the authors
proposed a strategy that combines learning algorithms
with texture features for accurate detection and recog-
nition of underwater objects. Here, the texture fea-
tures are valuable indicators of the surface properties
of an image and they play a significant role in differ-
ent underwater detection scenarios. In addition to tex-
ture, color and motion features play a major role in the
analysis of underwater images. These have been stud-
ied in different works. For example, the authors in
(Chen and Chen, 2010) proposed a new color edge de-
tection algorithm that uses the Kuwahara filter (Bar-
tyzel, 2016) to smooth the original image. They have
integrated adaptive thresholding and contour spacing
algorithms to improve detection efficiency and perfor-
mance.
Recently, new methods based on deep learning
have become increasingly important for their ability
to automatically learn and extract features from un-
derwater images. This can replace underwater object
detection methods that rely on manual feature extrac-
tion. In (Han et al., 2020) researchers combined max-
RGB and grayscale methods to boost underwater vi-
sion. Then, by obtaining illumination maps, they in-
troduced a CNN method to solve the problem of low
illumination in underwater images. Similar, in (Chen
et al., 2020), the authors developed an architecture
called Sample Weighted hypernetwork (SWIPENet)
for detecting small underwater objects. The architec-
ture improve the accuracy of object detection, dealing
with the image blur. Numerous object detection algo-
rithms marked a pivotal moment in the rapid progress
of deep learning in underwater object detection. For
example, an enhanced YOLOv5 algorithm was pro-
posed in (Ren et al., 2022) specifically for underwater
object detection. The authors incorporated the twin
transformer as the backbone network and improved
the multiscale feature fusion method and confidence
loss function. In (Lau and Lai, 2021), the authors
focused on the selection and enhancement of the ba-
sic network architecture in Faster R-CNN. They per-
formed pre-processing on the obtained images and
tested the performance of different network architec-
tures to identify the most suitable one for training ob-
ject detection in turbid media. Furthermore, to deal
with the limited underwater image data that impact
the prediction results, an unsupervised knowledge
transfer (UnKnoT) was introduced, in (Zurowietz and
Nattkemper, 2020). The method uses a data augmen-
tation technique, called scale transfer to reuse existing
training data and detect the same object classes in a
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
234

new image dataset.
2.2 Semi-Supervised Underwater
Object Detection
In underwater object detection tasks, the limited
amount of underwater image data poses a signifi-
cant challenge. In response, researchers have adopted
semi-supervised approaches to address this problem
and improve the detection capability of underwater
object detection algorithms. In (Jahanbakht et al.,
2023), a two phase semi-supervised contrastive learn-
ing approach was developed to reduce the impact of
reliance on a high volume of accurately labeled data.
The proposed model consists of a self-supervised con-
trastive learning phase, followed by fully-supervised
incremental fine tuning learning to detect various
fishes in turbid underwater video frames. A teacher-
student model was proposed in (Alaba et al., 2023) to
recognize fish species. The teacher network generates
pseudo-labels, and the student network is trained with
the generated pseudo-labels and ground truth simulta-
neously. The model consists of a Faster R-CNN with
Feature Pyramid Network (FPN) detector. In (Zhou
et al., 2023) an novel underwater object detection
framework, named UWYOLOX, was presented as
joint learning-based underwater image enhancement
module (JLUIE) and an improved semi-supervised
learning method USTAC. JLUIE and YOLOX-Nano
(Ge et al., 2021) share the detection loss for training,
where JLUIE can adaptively enhance each image for
better detection performance. Then, USTAC is intro-
duced to further improve the mean Average Precision
of object detection.
Although semi-supervised learning has a rel-
atively long history, it has only recently gained
widespread attention in underwater domain applica-
tions. Ongoing research is focused on better under-
standing the underwater environment and incorporat-
ing its specific features into semi-supervised models,
with the aim of improving the effectiveness of these
approaches in such challenging conditions. The fo-
cus of this work is to adapt general semi-supervised
learning methods, particularly teacher-student mod-
els, to the domain of underwater imaging. To achieve
this, we conduct a comprehensive analysis of marine
habitats detection, performed using popular SSOD
methods: Active Teacher, Unbiased Teacher, and Ro-
bust Teacher. These methods, applied for the first
time to the Deepfish (Saleh et al., 2020) and UT-
DAC2020 (Song et al., 2023) datasets, were chosen
for their popularity and their ability to represent di-
verse strategies within teacher-student architectures.
While they are not the current SOTA in SSOD, they
remain highly influential in the field, making them
ideal candidates for a comparative study that aims to
highlight the strengths and weaknesses of different
SSOD methods.
3 PRELIMINARIES
In this section, we present three popular semi-
supervised methods, used in literature for object de-
tection tasks. They share the principle of based
teacher-student mutual learning, which is a common
approach used to train models with limited labeled
data and a larger amount of unlabeled data. While
Teacher and Student are given weakly and strongly
augmented data as inputs, respectively, the Teacher
network is responsible for generating pseudo-labels
for unlabeled data, and the student will be trained us-
ing both pseudo-labels and ground truth (of labeled
data). At this stage, the student incorporate consis-
tency regularization techniques (Jeong et al., 2021)
to ensure its robustness at producing the outputs al-
though the presence of small perturbations. Besides,
the teacher’s weights θ
t
are updated during the semi-
supervised training by EMA (Tarvainen and Valpola,
2017) of the student’s weights θ
s
:
θ
i
t
← αθ
i−1
t
+ (1 − α)θ
i
s
(1)
, where i denotes the i
th
training step and α determines
the speed of the transmission. The weights of student
network θ
s
are updated using back propagation. The
model’s optimization process is formulated as mini-
mizing the loss L:
L = λ
s
L
sup
+ λ
u
L
unsup
(2)
, where L
sup
and L
unsup
represent the supervised and
the unsupervised losses respectively. λ
s
and λ
u
are
pondering coefficients for L
sup
and L
unsup
, respec-
tively.
3.1 Unbiased Teacher
The main idea of Unbiased Teacher (Liu et al., 2021)
is to introduce a class-balance Focal Loss (Zhang
et al., 2022a) to address the pseudo-labeling bias is-
sues caused by class-imbalance existing in ground
truth labels. Besides, to minimize the bias, the Un-
biased Teacher uses a novel data augmentation tech-
nique called BoxJitter which is applied to make the
student more robust toward object localization and
helps reduce localization bias in pseudo-labels. In
the other hand, a high filtering threshold is used
for pseudo-labels to ensure that only high-quality
pseudo-labels are used for training, and the teacher
Enhancing Marine Habitats Detection: A Comparative Study of Semi-Supervised Learning Methods
235

do not misguide the student. The presence of noisy
pseudo-labels can affect the pseudo-label generation
model. As result, the Teacher and the student are
detached, only the learnable weights of the Student
model is updated via back-propagation by using a
supervised loss L
sup
and a unsupervised loss L
unsup
.
Given a set of labeled data D
L
=
{
X
L
,Y
L
}
and a set
of unlabeled data D
U
=
{
X
U
}
, where X denotes the
data and Y is the label set. X
L
, Y
L
, and X
U
are
defined as X
L
=
x
l
i
,i ∈ N
l
, Y
L
=
y
l
i
,i ∈ N
l
, and
X
U
=
{
x
u
i
,i ∈ N
u
}
, respectively where N
l
represents
the number of labeled examples and N
u
the unlabeled
ones. For the Unbiased Teacher, the loss is composed
of the supervised loss L
sup
and the unsupervised loss
L
unsup
, defined as:
L
sup
=
1
N
l
N
l
∑
i=1
L
rpn
cls
(x
l
i
,y
l
i
) + L
rpn
reg
(x
l
i
,y
l
i
)
+ L
roi
cls
(x
l
i
,y
l
i
) + L
roi
reg
(x
l
i
,y
l
i
)
(3)
L
unsup
=
1
N
u
N
u
∑
i=1
L
rpn
cls
(x
u
i
, ˆy
u
i
) + L
roi
cls
(x
u
i
, ˆy
u
i
)
(4)
, where, L
rpn
cls
, L
rpn
reg
, L
roi
cls
, L
roi
reg
represent the Region
Proposal Network (RPN) classification loss, the RPN
regression loss, the Region of Interest (ROI) classifi-
cation loss, and the ROI regression loss respectively.
Here, ˆy
i
represent the generated pseudo-label.
3.2 Robust Teacher
The main focus of the Robust Teacher (Li et al.,
2023) is to address the noisy labels. The Robust
Teacher dealt with this challenge from two perspec-
tives: 1) Developing a vise Self-Correcting Pseudo-
labels Module (SPM) to addresses noise in pseudo-
labels by refining object localization first and then
improving class predictions, reducing errors in both,
and 2) Mitigating the inherent class bias in pseudo-
labels by introducing the Re-balanced Focal Loss
(FL) which adjusts the loss function to focus more on
under-represented classes, preventing the model from
being biased toward dominant classes. Together, the
Robust Teacher ensures that the pseudo-labels used
for training are both more accurate and better bal-
anced across different object classes. The loss func-
tion is summarized as the sum of the supervised loss
L
sup
and the unsupervised loss L
unsup
, described as:
L
sup
=
1
N
l
N
l
∑
i=1
L
rpn
cls
(x
l
i
,y
l
i
) + L
rpn
reg
(x
l
i
,y
l
i
)
+ L
roi
cls
(x
l
i
,y
l
i
) + L
roi
reg
(x
l
i
,y
l
i
) + L
ml
cls
(x
l
i
,ν
l
i
)
(5)
L
unsup
=
1
N
u
N
u
∑
i=1
L
rpn
cls
(x
u
i
, ˆy
u
i
) + L
roi
cls
(x
u
i
, ˆy
u
i
) + L
ml
cls
(x
u
i
,ν
u
i
)
(6)
L
ml
cls
is the Multi-Label (ML) head classification
loss (Zhang et al., 2022a). In fact, a ML head was
introduced into the Faster-RCNN detector to predict
image-level pseudo-labels ν
i
for class distribution re-
balancing to alleviate the inherent class imbalance is-
sues. The ML head takes the top-level feature of Fea-
ture Pyramid Network (FPN) as inputs and uses the
sigmoid function to convert the output into a multi-
label probability distribution which used to calculate
a re-balanced weight w for the re-balanced focal loss
L
RFL
cls
given as:
L
RFL
cls
= wy
T
L
FL
cls
(7)
, with y
i
and L
FL
cls
represent the category label and the
focal loss, respectively. Here, L
ml
cls
integrates the con-
tribution of L
RFL
cls
in the handling of rare classes and
the refinement of classification.
3.3 Active Teacher
The Active Teacher (Mi et al., 2022) is character-
ized by its active learning, where the label set is par-
tially initialized and gradually augmented by evalu-
ating three key metrics of unlabeled examples: Dif-
ficulty, Information, and Diversity, used in combined
manner (Cho et al., 2022). The method aims to im-
prove the learning by selecting the most informative
unlabeled data to label. Therefore, the Active Teacher
can achieve high accuracy detection with fewer label
set. Here, the supervised loss L
sup
is defined as:
L
sup
=
1
N
l
N
l
∑
i=1
L
rpn
cls
(x
l
i
,y
l
i
) + L
roi
cls
(x
l
i
,y
l
i
) + L
loc
(x
l
i
,y
l
i
)
(8)
, with
L
loc
(x
l
i
,y
l
i
) =
∑
c∈{x,y,h,w}
Smooth
L
1
(t
c
i
− y
c
i
) (9)
and the unsupervised one L
unsup
is defined as Eq.(4).
L
sup
consists of the classification loss L
cls
of RPN and
ROI head, and the one for bounding box regression
L
loc
. It is defined as the summation of the classifica-
tion loss which presents the log loss over two classes
(object vs. not object) and the bounding box regres-
sion loss. Here, t
c
is the c
th
coordinate of the out-
put image x
i
. L
unsup
uses only the pseudo-labels of
RPN and ROI head predictions. This loss is not ap-
plied for the bounding box regression since the con-
fidence thresholding is not able to filter the pseudo-
labels that are potentially incorrect for bounding box
regression. The confidence of predicted bounding
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
236

boxes only indicate the confidence of predicted ob-
ject categories instead of the quality of bounding box
locations (Jiang et al., 2018).
4 PROPOSED METHODOLOGY
In this work, we propose a comprehensive analysis
of the performance of different SSOD methods ap-
plied to marine habitats detection. To effectively ap-
ply SSOD methods, we propose the integration of two
key modules for improving performance: the Under-
water Image Enhancement (UIE) and the contrastive
learning. The UIE is designed to address the chal-
lenges posed by underwater environments, such as
color distortion, low contrast, and hazing, by enhanc-
ing the quality of the input images before they are pro-
cessed by the model. We explore various UIE meth-
ods to improve image clarity, color balance, and de-
tail sharpness. In addition to image enhancement, we
introduce a contrastive learning strategy, which is in-
tegrated into the SSOD framework to help the model
better differentiate between objects. In the following,
first, we detail the different UIE methods, and second
the contrastive learning strategy for marine habitats
detection.
4.1 Underwater Image Enhancement
Underwater image enhancement methods are pro-
posed to improve the visual quality of images cap-
tured underwater, which may suffer from hazing,
low contrast, and color distortion/dominance. These
methods were investigated with the aim of integrat-
ing UOD methods to achieve enhanced results. For
the same reason, we investigate UIE for the SSOD
methods. In the following sections, we present three
distinct UIE techniques among the techniques anal-
ysed in (Ancuti et al., 2017; Islam et al., 2020; Song
et al., 2020; Peng et al., 2023; Zhou et al., 2023), that
achieve the highest UIQM and UCIQE scores (Xu
et al., 2023) on Deepfish and UTDAC2020 datasets.
UIQM and UCIQE are widely used metrics to as-
sess the quality of enhanced images and evaluate UIE
methods.
4.1.1 UIE-1: Color Balance and Fusion
The method
1
is based on color balance and fusion to
enhance the image clarity and corrects the color dis-
tortion (Ancuti et al., 2017). The color balance com-
posed helps to correct the color cast by adjusting the
color channels so that their averages are equal. Then,
1
https://github.com/Sai-paleti25
a multi-scale fusion technique (Ancuti et al., 2012) is
applied to combine several enhanced versions of the
image that is directly derived from the color balanced
version of the original degraded image; Each image is
optimized for specific characteristics such as contrast
and detail. This fusion uses weight maps to select the
sharpest and most contrasted parts of each version,
resulting in a final image that is more balanced, with
natural colors, improved contrast, and sharper details.
The first input of the the fusion process is a gamma
corrected image of the white balanced image version,
that aims to correct the global contrast. This correc-
tion increases the difference between darker/lighter
regions at the cost of a loss of details in the under-
exposed regions. To compensate for this loss, a sec-
ond input is generated, corresponds to a sharpened
version of the white balanced image. A normalized
unsharp masking process is applied with:
S = (I + N
{
I − G ∗ I
}
)/2 (10)
, where I is the white balanced image, G ∗ I denotes
the Gaussian filtered version of I. N. represents the
linear normalization operator, also named histogram
stretching in the literature. This operator shifts and
scales all the color pixel intensities of an image with
a unique shifting and scaling factor defined so that
the set of transformed pixel values cover the entire
available dynamic range.
4.1.2 UIE-2: U-Shape Transformer
The U-Shape Transformer
2
is a deep learning network
(Peng et al., 2023), which combines the strengths of
the U-Net and Transformer models, to ensure color
correction, visibility improvement, and artifact reduc-
tion. Inspired by U-Net, the U-shape structure is
designed to capture multi-scale information through
an encoder-decoder architecture. The encoder down-
samples images to extract high-level features, while
the decoder up-samples to restore image resolution.
Transformer blocks are integrated into both the en-
coder and decoder to capture long-range dependen-
cies and global context, helping the model manage
spatial complexity and variations, especially in under-
water images. Skip connections between the encoder
and decoder merge local and global features, leading
to more accurate image enhancement.
The U-shape Transformer includes two special-
ized modules, based generator and discriminator:
A Channel-wise Multi Scale Feature Fusion Trans-
former (CMSFFT), and a Spatial-wise Global Fea-
ture Modeling Transformer (SGFMT) (Peng et al.,
2023). The SGFMT was designed, based on the spa-
tial self-attention mechanism to replace the original
2
https://github.com/LintaoPeng
Enhancing Marine Habitats Detection: A Comparative Study of Semi-Supervised Learning Methods
237

bottleneck layer of the generator. It can accurately
model the global characteristics of underwater im-
ages and reinforce the network’s focus on the space
areas with more serious attenuation, thus achieving
uniform UIE. The CMSFFT module is responsible
for processing features across different channels and
scales. It replaces the skip connection of the genera-
tor and employs a channel-wise self-attention mecha-
nism. This mechanism performs channel-wise multi-
scale feature fusion on the features output by the gen-
erator’s encoder. The fusion results are then transmit-
ted to the decoder, reinforcing the network’s attention
to the color channels that experience more serious at-
tenuation.
4.1.3 UIE-3: JLUIE Module
A joint learning-based underwater image enhance-
ment module (JLUIE) was proposed in (Zhou et al.,
2023), where four enhancement filters are applied in
sequence. The White balance, Gamma correction,
Contrast adjustment, and Sharpen contribute differ-
ently to image enhancement as follows: First, the
White balance adjusts the colors of an image by cali-
brating the intensities of the red, green and blue chan-
nels to neutralize any color cast and make white ob-
jects appear white in the image. With P
i
= (r
i
,g
i
,b
i
)
the value of input pixel, the mapping function is :
P
o
= (W
r
r
i
,W
g
g
i
,W
b
b
i
) (11)
, where P
o
= (r
o
,g
o
,b
o
) is the value of output pixel,
(r,g,b) represent the red, green, and blue color chan-
nels respectively. W
r
, W
g
, W
b
are the coefficients of
the three color channels of red, green and blue re-
spectively. Next, the mapping function of the Gamma
correction filter is applied as P
o
= P
G
i
with G is the
Gamma value. The latter affects the overall brightness
and contrast of the image. Then, a contrast adjust-
ment is applied to modify the distribution of bright-
ness levels in the image. This process enhances light
areas, making them brighter, while dark areas become
darker, using this mapping function:
P
o
= αEn(P
i
) + (1 −α)P
i
(12)
, where En(P
i
) represents the enhanced pixel value
and α is a linear interpolation between the original
image and the enhanced image. The last filter to ap-
ply is the Sharpen. It is used to remove image blur
and sharpen contours and objects, using the following
mapping filter :
F = I + λ(I − Gau(I)) (13)
, where I and F are the input and output images re-
spectively, Gau(I) denotes the result of applying a
Gaussian filter to the input image, and λ is a posi-
tive scale factor. For this work, we use our proper
implementation of JLUIE module.
4.2 Contrastive Learning
The main idea is to introduce a contrastive learn-
ing branch to the semi-supervised model to optimize
pseudo-labels prediction based on the principle of
pulling similar images together and pushing away the
dissimilar ones. We couple the contrastive learning
with the teacher-student architecture used in SSOD
via the loss optimization. A new loss is added to the
supervised loss L
sup
and the unsupervised loss L
unsup
,
called the contrastive loss L
ctr
.
L = λ
s
L
sup
+ λ
u
L
unsup
+ βL
ctr
(14)
, where β present the pondering coefficient for L
ctr
.
Similar to that in (Zhang et al., 2022b), it is formu-
lated as:
L
ctr
= −log
∑
k
+
exp(γ(α
p
s
p
− m))
∑
k
+
exp(γ(α
p
s
p
− m)) +
∑
k
−
exp(γs
n
)
= log
1 +
∑
k
−
exp(γ(s
n
+ m))
∑
k
+
exp(−γα
p
s
p
)
!
(15)
Here, s
p
represents the similarity of positive sam-
ples while s
n
represents the similarity of negative
samples. α
p
, γ, and m are the soften parameter, the
scale and the margin value (Zhang et al., 2022b), re-
spectively. The similarity of positive and negative
samples are averaged using the cosine distance (Popat
et al., 2017), defined as:
s
i, j
=
x
i
· x
j
∥
x
i
∥
x
j
(16)
, where, x
i
· x
j
represents the dot product between
two sample vectors x
i
and x
j
,
∥
x
i
∥
and
x
j
rep-
resent their norms, respectively. An effective sam-
pling strategy for positive and negative examples is
crucial in non-supservised contrastive learning. In
our method, we leverage the abundance of unlabeled
data and the pseudo-labels generated by SSOD frame-
works to select positive and negative samples. We
expect that the co-optimization of the pseudo-labels
generation alongside the contrastive loss helps im-
prove the quality of pseudo-labels and the diversity
of samples, which in turn enhances the learnt repre-
sentations, leading to better overall detection perfor-
mance. The unlabeled example x
u
i
with pseudo la-
bel ˆy
u
i
is assigned to the most corresponding class c.
Then, all the samples that have the same class c are
pulled together, sharing the same specific instances
corresponding to that class. In this way, the positives
samples are created while the negatives are the sam-
ples that are pushed away with different class. With
the contrastive branch, more meaningful representa-
tions are extracted which are involved in generating
more reliable pseudo-labels.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
238

5 EXPERIMENT
5.1 Datasets and Metrics
5.1.1 Datasets
We perform rigorous experiments on the challenging
marine habitats datasets UTDAC2020 and Deepfish
to evaluate the generalization performance of our ap-
proach. These datasets are specifically selected for
their complexity and variability, providing a robust
framework for testing the efficacy of the SSOD ap-
proach in diverse underwater scenarios.
DeepFish Dataset: DeepFish (Saleh et al., 2020)
is a large-scale marine habitats dataset consisting of
around 40 thousand images obtained from 20 differ-
ent marine habitats in tropical Australia. Each habi-
tat is divided into images with no fish (background)
and images with at least one fish (foreground). The
dataset is split into 50% training, 20% validation, and
30% testing, ensuring equal numbers of background
and foreground images across all splits. All annota-
tions are provided.
UTDAC2020 Dataset: UTDAC2020 (Song et al.,
2023) is an underwater dataset derived from the un-
derwater target detection algorithm competition 2020.
There are 5168 training images and 1293 testing im-
ages. It contains four classes: echinus, holothurian,
starfish, and scallop.
5.1.2 Metrics
We evaluate the semi-supervised models against the
Average Precision (AP) (Sohn et al., 2020). It is
a standard metric for object detection that measures
the overlap between the prediction and the ground
truth with Intersection Over Union (IOU) threshold
set from 0.5 to 0.95, with 0.05 as the interval. The
AP is calculated as:
AP =
∑
Q
q=1
AP(q)
Q
(17)
In marine habitat detection, a key challenge lies in ac-
curately identifying and classifying habitats that of-
ten appear as small or medium-sized objects within
images. Given the limited spatial area of the paper,
in our experiments, we focus on three AP metrics de-
scribed in Table.1 to analyse SSOD methods.
Table 1: The AP metrics used in our experiments.
Metrics Description
AP The mAP (mean average precision)
AP
S
The AP of small targets
AP
M
The AP of medium targets
5.2 Settings and Implementation Details
5.2.1 Experimental Settings
We propose to evaluate the performance of Active
Teacher, Unbiased Teacher, and Robust Teacher on
two different underwater datasets: Deepfish and UT-
DAC2020 datasets. Additional results are presented,
investigating the performance of these methods from
two aspects: 1) Applying various UIE methods to en-
hance input data, 2) Incorporating a contrastive loss
into semi-supervised models to improve representa-
tion learning. Faster-RCNN (Ren et al., 2015) is de-
fined as our supervised baseline for comparison with
the semi-supervised methods analysed in our work.
Specifically, we use UTDAC2020 and Deepfish
datasets to examine the SSOD methods on different
experimental scenarios. In our setup, we randomly
sample 40% labeled training data as our labeled set,
with the remaining data serving as the unlabeled set.
Unless stated otherwise, all tables present the results
of models trained using the same 40% labeled data.
5.2.2 Implementation Details
Our implementation follows existing state of the art
works (Mi et al., 2022; Li et al., 2023) and thus,
Faster R-CNN is used with FPN and ResNet-50 back-
bone (He et al., 2016) as the default detector in the
semi-supervised frameworks. Besides, ImageNet pre-
trained weights are used to initialize the feature ex-
traction networks. We used SGD optimizer with
the learning rate equals to 0.02 and momentum rate
equals to 0.9. The supervised, unsupervised, and con-
trastive loss weights are equals to λ
s
= 0.5 and λ
u
=
4.0, and β = 5.0 respectively. We set α = 0 : 9996 for
EMA. We use confidence threshold τ = 0.7 to filter
the pseudo-labels of low quality. For the contrastive
branch, we set α
p
= 4, m = 1, and γ = 2. The total
training steps for each semi-supervised learning are
18000. In training, the unlabeled and labeled data
are combined in the same proportion via random sam-
pling, to create a mini-batch of size 20 which includes
10 labeled images and 10 unlabeled images.
For the data augmentation, we apply random hor-
izontal flip for weak augmentation and randomly add
color jittering, grayscale, Gaussian blur, and cutout
patches for strong augmentations. This configuration
is common on all three SSOD methods (Mi et al.,
2022; Li et al., 2023; Liu et al., 2021).
Enhancing Marine Habitats Detection: A Comparative Study of Semi-Supervised Learning Methods
239

(a) Robust Teacher (b) Unbiased Teacher (c) Active Teacher
Figure 1: Rows 1 and 2 correspond respectively to results for two different images from Deepfish dataset. The columns 1, 2
and 3 correspond respectively to results using : (a) Robust Teacher, (b) Unbiased Teacher, and (c) Active Teacher.
5.3 Experimental Results
5.3.1 Performance Analysis of Existing SSOD
Methods
Fig.1 presents fish detection results obtained for dif-
ferent images from the validation set of Deepfish
dataset. Color distortion, low contrast, blurred re-
gions, and variations in fish appearances are noticed
in these images. As observed, the different methods
provide a good detection results with differences in
performance. They detects the boundaries of fish with
different forms and sizes (even small ones). Besides,
a number of grouped fish are successfully separated
as marked with their corresponding bounding box.
However, we still have missing or wrong detections,
and we have others with low accuracy. As shown in
Fig.1-(b), the Unbiased Teacher outperforms the Ac-
tive Teacher and Robust Teacher in number of cor-
rect detection and precision which can be explained
by the fact that the Unbiased teacher uses the por-
tion of the unlabeled dataset effectively to improve
detection. However, Robust Teacher, being more fo-
cused on noise handling, and Active Teacher, being
focused on selective labeling, may not make full use
of the abundant unlabeled data as efficiently as Unbi-
ased Teacher. For quantitative evaluation, results are
resumed in Table.2, which are obtained using AP met-
rics.
Table 2: Detection results on Deepfish dataset with popular
semi-supervised methods.
Methods AP (%) AP
S
(%) AP
M
(%)
Supervised Faster-RCNN 56.10 21.20 46.70
Robust Teacher 58.85 24.58 49.05
Active Teacher 60.00 27.83 50.22
Unbiased Teacher 66.83 39.75 57.38
Results confirm that Unbiased Teacher outper-
forms the Robust and Active Teachers and the super-
vised Faster-RCNN. As an example, AP (%) equals
66.83 for Unbiased Teacher, while it is only 60 for
Active Teacher, 58.85 for the Robust Teacher, and
56.10 for Faster-RCNN. The detection results for
small, medium objects are improved using Unbiased
Teacher compared to the other models. Besides,
semi-supervised models can achieve baseline super-
vised performance (e.g., Faster R-CNN) with much
less label expenditure. For instance, the supervised
Faster R-CNN achieves 60% AP with 100% labeled
data, while Active Teacher reaches similar perfor-
mance with only 40% labeled data. Unbiased Teacher
achieves superior performance, reaching 66.83% AP,
as shown in Table.2. However, it is important to note
that these semi-supervised methods do not reach the
performance level of SOTA fully-supervised meth-
ods. The results of the SOTA fully-supervised meth-
ods will be provided in the appendix for comparison.
Fig.2 presents detection results of underwater ani-
mals in two different images from the validation set
of UTDAC2020 dataset. The same as for Deep-
fish dataset, UTDAC2020 dataset suffers from low
contrast, blur regions, and color distortion. As
observed, Active Teacher, Unbiased Teacher, and
Robust Teacher succeed in recognizing more than
one category and detecting animals with different
sizes and forms. However, detection is not optimal
(missing detections). More detections and precision
marked with bounding boxes, are obtained using Ac-
tive Teacher and unbiased Teacher compared to Ro-
bust Teacher. Performances can be explained by the
fact that Robust Teacher may focus on improving
overall stability or robustness by dealing with noise
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
240

(a) Robust Teacher (b) Unbiased Teacher (c) Active Teacher
Figure 2: Rows 1 and 2 correspond respectively to results for two different images from UTDAC2020 dataset. The columns
1, 2 and 3 correspond respectively to results using : (a) Robust Teacher, (b) Unbiased Teacher, and (c) Active Teacher.
in the dataset, but that alone does not ensure better
performance. However, the Unbiased Teacher and
the Active Teacher focus on the ambiguous or poorly
predicted instances in images and allocate more re-
sources to learning these cases. Quantitative eval-
uation are provided in Table.3. Results attest that
the Unbiased Teacher outperforms the other presented
methods in terms of performance. The AP (%) for
Unbiased Teacher is 44.22, compared to 43.86, 40.97,
and 39.50 for Active Teacher, Robust Teacher, and
supervised Faster-RCNN, respectively. Additionally,
the Unbiased Teacher surpasses the baseline fully su-
pervised Faster-RCNN which has 44% of AP (not re-
ported in the Table.3).
Table 3: Detection results on UTDAC2020 dataset with
popular semi-supervised methods.
Methods AP (%) AP
S
(%) AP
M
(%)
Supervised Faster-RCNN 39.50 15.20 35.40
Robust Teacher 40.97 15.74 35.91
Active Teacher 43.86 15.96 38.97
Unbiased Teacher 44.22 17.92 38.50
In addition, an evaluation of performance per cat-
egory, is given by Table.4. The Unbiased Teacher
demonstrates the best overall performance, espe-
cially with Echinus and Holothurian, and it handles
Scallop and Starfish detections better than others.
Active Teacher is relatively consistent, particularly
strong with Starfish detection, but not as effective
for Holothurian. Robust Teacher consistently per-
forms the worst, struggling the most with Holothurian
(only 30.88%), and generally falling behind in all cat-
egories. Its results suggest that it may be less suited
for this specific detection task. In this case, Unbiased
Teacher offers the most balanced and effective solu-
tion across different marine species.
Table 4: Detection results on UTDAC2020 dataset per cat-
egory with popular semi-supervised methods.
Methods Echinus Scallop Starfish Holothurian
Robust Teacher 43.75 40.00 49.25 30.88
Active Teacher 43.38 46.94 50.45 34.67
Unbiased Teacher 45.27 44.67 50.78 36.14
These results highlight the good potential of
semi-supervised models when applied to underwater
datasets. Additionally, they offer a promising alterna-
tive to supervised models, that rely on large amounts
of labeled data which can be challenging to obtain in
the context of underwater imagery. However, the de-
tection process remains not optimal, with missed and
wrong detections with low accuracy still observed in
several images. To address this, we propose incorpo-
rating two key elements for underwater applications
to semi-supervised models: UIE methods and con-
trastive learning, and evaluating their impact on the
detection process. This will be the focus of the up-
coming ablation study.
5.3.2 Ablation Study: UIE Methods
In this section, we applied different UIE methods
to Deepfish and UTDAC2020 datasets. Both train-
ing and validation sets are enhanced by the same
UIE technique. The UIE-1 adjusts the color distri-
bution of the underwater image and uses the multi-
scale fusion to improve the overall quality, enhanc-
ing the clarity and contrast of the image. UIE-2 re-
stores natural colors, enhances contrast, and preserves
the fine details, and UIE-3 improves the clarity of
the image and brings out fine details that are lost
in a hazy underwater environment. We investigate
the impact of enhanced images through UIE meth-
ods on marine habitats detection. Table.5 and Ta-
Enhancing Marine Habitats Detection: A Comparative Study of Semi-Supervised Learning Methods
241
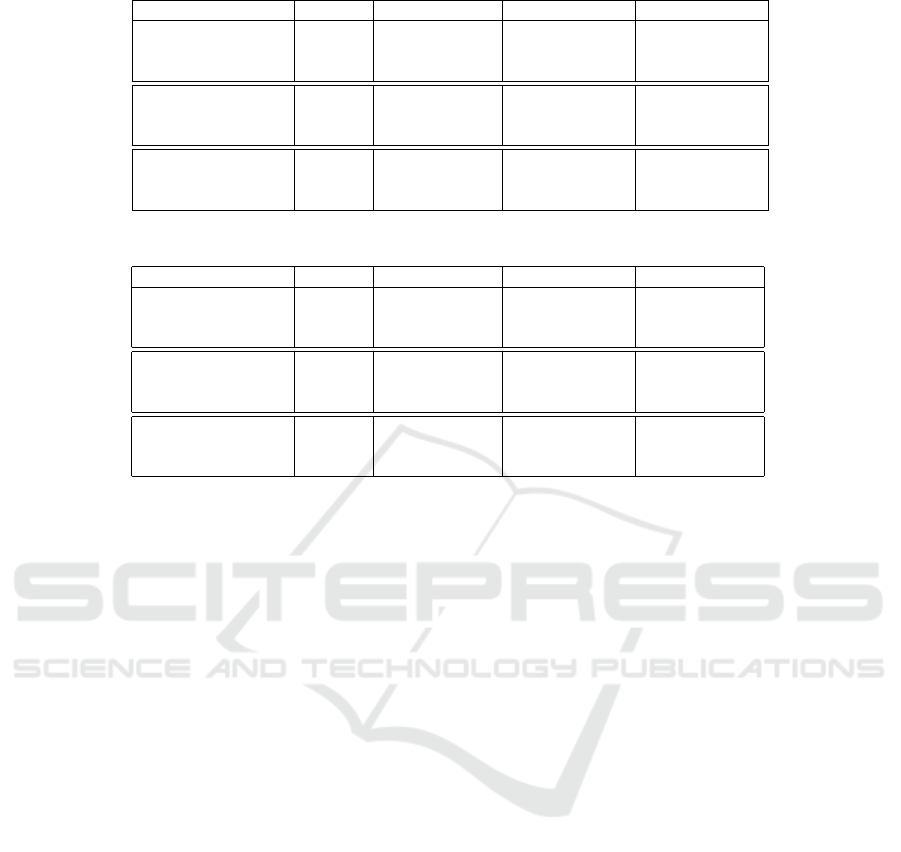
Table 5: Detection results of semi-supervised methods with UIE for Deepfish dataset.
Methods UIE AP (%) AP
S
(%) AP
M
(%)
Robust Teacher UIE-1 57.80 (-1.05) 26.05 (+1.47) 48.60 (-0.45)
Active Teacher UIE-1 58.94 (-1.06) 29.58 (+1.75) 50.35 (+0.13)
Unbiased Teacher UIE-1 66.58 (-0.25) 38.50 (-1.25) 57.06 (-0.32)
Robust Teacher UIE-2 52.32 (-6.53) 17.55 (-7.03) 41.93 (-7.12)
Active Teacher UIE-2 54.04 (-5.96) 19.41 (-8.42) 44.69 (-5.53)
Unbiased Teacher UIE-2 63.28 (-3.55) 33.53 (-6.22) 53.04 (-4.34)
Robust Teacher UIE-3 58.51 (-0.34) 24.43 (-0.15) 49.00 (-0.05)
Active Teacher UIE-3 59.60 (-0.40) 28.74 (+0.91) 50.65 (+0.43)
Unbiased Teacher UIE-3 66.66 (-0.17) 38.56 (-1.19) 57.16 (-0.22)
Table 6: Detection results of semi-supervised methods with UIE for UTDAC2020 dataset.
Methods UIE AP (%) AP
S
(%) AP
M
(%)
Robust Teacher UIE-1 39.64 (-1.33) 14.66 (-1.08) 34.41 (-1.50)
Active Teacher UIE-1 42.23 (-1.63) 14.36 (-1.60) 37.08 (-1.89)
Unbiased Teacher UIE-1 42.92 (-1.30) 16.96 (-0.96) 37.35 (-1.15)
Robust Teacher UIE-2 32.54 (-8.43) 12.32 (-3.42) 31.05 (-4.86)
Active Teacher UIE-2 35.67 (-8.19) 14.59 (-1.37) 34.49 (-4.48)
Unbiased Teacher UIE-2 35.91 (-8.31) 13.68 (-4.24) 33.80 (-4.70)
Robust Teacher UIE-3 40.37 (-0.60) 16.08 (+0.34) 35.26 (-0.65)
Active Teacher UIE-3 42.72 (-1.14) 16.10 (+0.14) 37.38 (-1.59)
Unbiased Teacher UIE-3 44.00 (-0.22) 17.50 (-0.42) 38.25 (-0.25)
ble.6 show the AP values obtained by applying semi-
supervised models to the enhanced DeepFish and UT-
DAC2020 datasets, respectively. The values in paren-
theses represent the improvement compared to the
performance without the UIE module. The AP results
in Table.5 and Table.6 attest the non linearity correla-
tion between of the image enhancement and the accu-
racy of the object detection model. Although, image
enhancement methods, performed well in the visual
sense. For Deepfish and UTDAC2020 datasets, they
do not achieve better detection accuracy with Active
Teacher, Robust Teacher, and Unbiased Teacher. The
accuracy of semi-supervised models declines after ap-
plying underwater image enhancement, compared to
their original performance. For example, the original
performance of Robust Teacher on deepfish dataset is
identified with AP(%) equals 58.85, while it is de-
creased to 57.80, 52.32, and 58.51 when applying
UIE-1, UIE-2, and UIE-3, respectively.
Many reasons can explain the inconsistency be-
tween enhancing the image quality and the detection
performance of semi-supervised model; the absence
of Ground Truth images for UIE methods make the
enhanced image not necessarily better than the origi-
nal image, besides, the optimization objective of UIE
method is different from that of an underwater object
detection model. The two objectives are not aligned
with one another. The purpose of UIE is only to ame-
liorate the human visual senses of an image, while
the detection model aims to locate underwater tar-
gets. Therefore, it is not practical to use UIE methods
as a pre-processing step for underwater object detec-
tion only based on quality metrics. More efforts are
needed to ensure more effective methods for quality
assessment.
5.3.3 Ablation Study: Contrastive Learning
In further experiments, we integrate contrastive learn-
ing with the teacher-student architecture employed
in Active Teacher, Robust Teacher, and Unbiased
Teacher, without applying any UIE techniques. The
AP values for the DeepFish and UTDAC2020 datasets
using contrastive semi-supervised models are summa-
rized in Table 7. The values in parentheses repre-
sent the improvement compared to the performance
without the contrastive learning. These results illus-
trate the contribution of contrastive learning in im-
proving certain detection results. As illustrated in Ta-
ble.7, Deepfish and UTDAC2020 detection results are
slightly ameliorated. Especially, the average of detec-
tion for small underwater targets is more refined as
noticed for Unbiased Teacher and Active Teacher. As
an example, for Deepfish dataset, AP
s
equals 30.21%
for Active Teacher with the integration of contrastive
branch, compared to only 27.83% without it, resulting
in a 2.38% improvement. Although the improvement
provided by contrastive learning is not yet significant,
we believe that with further research and more sophis-
ticated integration techniques like the work in (Seo
et al., 2022; Wu et al., 2022), contrastive learning
has the potential to enhance detection results, partic-
ularly for small and medium marine habitats. These
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
242

Table 7: Detection results of semi-supervised methods with incorporated contrastive learning.
Datasets Methods AP (%) AP
S
(%) AP
M
(%)
Deepfish Robust Teacher 58.79 (-0.06) 23.33 (-1.25) 48.85 (-0.20)
Active Teacher 60.19 (+0.19) 30.21 (+2.38) 51.27 (+1.05)
Unbiased Teacher 66.93 (+0.10) 41.66 (+1.91) 57.20 (-0.18)
UTDAC Robust Teacher 41.04 (+0.07) 15.74 (±0.00) 35.67 (-0.24)
2020 Active Teacher 43.43 (-0.43) 15.54 (-0.42) 38.63 (-0.34)
Unbiased Teacher 44.30 (+0.08) 18.67 (+0.75) 38.20 (-0.30)
advanced techniques require specifically designed al-
gorithms tailored for semi-supervised settings. In-
corporating them into this study would have necessi-
tated significant additional development, which falls
beyond the scope of our current objectives. There-
fore, we have left the exploration of such techniques
for future work.
6 CONCLUSIONS
In this paper, we proposed a comprehension anal-
ysis of marine habitats detection results, performed
using different semi-supervised methods. The latter
represent an alternative to supervised ones, to deal
with the presence of limited labeled data, which is
the case for underwater datasets. Results encom-
pass a focus on Active Teacher, Unbiased Teacher,
and Robust Teacher as semi-supervised models, ap-
plied to Deepfish and UTDAC2020 datasets. In this
work, we proposed UIE methods to enhance the im-
age quality and used these enhanced images as input
for semi-supervised models. In addition, we intro-
duced a new contrastive branch to study its impact
on marine habitats detection. Qualitative and quan-
titative evaluations are attested through many experi-
ments. They both demonstrate the significant perfor-
mance of semi-supervised models in detecting under-
water images. On the other hand, we conclude that
enhanced images do not obligatory improve detection
results, while the integration of contrastive branch can
result in refined detection, where small and medium
underwater targets are more located. In future work,
we aim to explore two key directions: first, improving
contrastive learning to enhance the feature represen-
tation; and second, directly integrating the Underwa-
ter Image Enhancement module as a domain-specific
augmentation technique.
ACKNOWLEDGEMENTS
This work is fully funded by the project ROV-
Chasseur (ANR-21-ASRO-0003) of the French Na-
tional Research Agency (ANR).
REFERENCES
Alaba, S. Y., Shah, C., Nabi, M., Ball, J. E., Moorhead,
R., Han, D., Prior, J., Campbell, M. D., and Wallace,
F. (2023). Semi-supervised learning for fish species
recognition. In Ocean Sensing and Monitoring XV,
volume 12543, pages 247–254. SPIE.
Ancuti, C., Ancuti, C. O., Haber, T., and Bekaert, P. (2012).
Enhancing underwater images and videos by fusion.
In 2012 IEEE conference on computer vision and pat-
tern recognition, pages 81–88. IEEE.
Ancuti, C. O., Ancuti, C., De Vleeschouwer, C., and
Bekaert, P. (2017). Color balance and fusion for un-
derwater image enhancement. IEEE Transactions on
image processing, 27(1):379–393.
Bartyzel, K. (2016). Adaptive kuwahara filter. Signal, im-
age and video processing, 10:663–670.
Chen, L., Liu, Z., Tong, L., Jiang, Z., Wang, S., Dong, J.,
and Zhou, H. (2020). Underwater object detection us-
ing invert multi-class adaboost with deep learning. In
2020 International Joint Conference on Neural Net-
works (IJCNN), pages 1–8. IEEE.
Chen, X. and Chen, H. (2010). A novel color edge detection
algorithm in rgb color space. In IEEE 10th Interna-
tional Conference On Signal Processing Proceedings,
pages 793–796. IEEE.
Cho, J. W., Kim, D.-J., Jung, Y., and Kweon, I. S. (2022).
Mcdal: Maximum classifier discrepancy for active
learning. IEEE transactions on neural networks and
learning systems.
Cubuk, E. D., Zoph, B., Mane, D., Vasudevan, V., and Le,
Q. V. (2019). Autoaugment: Learning augmentation
strategies from data. In CVF conference on computer
vision and pattern recognition, pages 113–123.
Ge, Z., Liu, S., Wang, F., Li, Z., and Sun, J. (2021). Yolox:
Exceeding yolo series in 2021. In The IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR).
Han, F., Yao, J., Zhu, H., Wang, C., et al. (2020). Under-
water image processing and object detection based on
deep cnn method. Journal of Sensors, 2020.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep
residual learning for image recognition. In IEEE con-
ference on computer vision and pattern recognition
(CVPR), pages 770–778.
Islam, M. J., Xia, Y., and Sattar, J. (2020). Fast underwater
image enhancement for improved visual perception.
Enhancing Marine Habitats Detection: A Comparative Study of Semi-Supervised Learning Methods
243

IEEE Robotics and Automation Letters, 5(2):3227–
3234.
Jahanbakht, M., Azghadi, M. R., and Waltham, N. J. (2023).
Semi-supervised and weakly-supervised deep neural
networks and dataset for fish detection in turbid un-
derwater videos. Ecological Informatics, 78:102303.
Jeong, J., Verma, V., Hyun, M., Kannala, J., and Kwak, N.
(2021). Interpolation-based semi-supervised learning
for object detection. In IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR), pages
11602–11611.
Jiang, B., Luo, R., Mao, J., Xiao, T., and Jiang, Y. (2018).
Acquisition of localization confidence for accurate ob-
ject detection. In European conference on computer
vision (ECCV), pages 784–799.
Lau, P. Y. and Lai, S. C. (2021). Localizing fish in highly
turbid underwater images. In International Workshop
on Advanced Imaging Technology (IWAIT) 2021, vol-
ume 11766, pages 294–299. SPIE.
Li, S., Liu, J., Shen, W., Sun, J., and Tan, C. (2023).
Robust teacher: Self-correcting pseudo-label-guided
semi-supervised learning for object detection. Com-
puter Vision and Image Understanding, 235:103788.
Liu, Y.-C., Ma, C.-Y., He, Z., Kuo, C.-W., Chen, K., Zhang,
P., Wu, B., Kira, Z., and Vajda, P. (2021). Unbi-
ased teacher for semi-supervised object detection. In-
ternational Conference on Learning Representations
(ICLR).
Mi, P., Lin, J., Zhou, Y., Shen, Y., Luo, G., Sun, X., Cao, L.,
Fu, R., Xu, Q., and Ji, R. (2022). Active teacher for
semi-supervised object detection. In The IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR).
Pan, T.-S., Huang, H.-C., Lee, J.-C., and Chen, C.-H.
(2021). Multi-scale resnet for real-time underwater
object detection. Signal, Image and Video Processing,
15:941–949.
Peng, L., Zhu, C., and Bian, L. (2023). U-shape transformer
for underwater image enhancement. IEEE Transac-
tions on Image Processing, 32:3066–3079.
Popat, S. K., Deshmukh, P. B., and Metre, V. A. (2017). Hi-
erarchical document clustering based on cosine simi-
larity measure. In International Conference on Intelli-
gent Systems and Information Management (ICISIM),
pages 153–159. IEEE.
Ren, B., Feng, J., Wei, Y., and Huang, Y. (2022). Under-
water target detection algorithm based on improved
yolov5. Advances in Engineering Technology Re-
search, 1(3):713–713.
Ren, S., He, K., Girshick, R., and Sun, J. (2015). Faster
r-cnn: Towards real-time object detection with region
proposal networks. Advances in neural information
processing systems, 28.
Saleh, A., Laradji, I. H., Konovalov, D. A., Bradley, M.,
Vazquez, D., and Sheaves, M. (2020). A realistic fish-
habitat dataset to evaluate algorithms for underwater
visual analysis. Scientific Reports, 10(1):14671.
Sarkar, P., De, S., and Gurung, S. (2022). A survey on un-
derwater object detection. Intelligence Enabled Re-
search: DoSIER, 1029:91–104.
Seo, J., Bae, W., Sutherland, D. J., Noh, J., and Kim, D.
(2022). Object discovery via contrastive learning for
weakly supervised object detection. In European Con-
ference on Computer Vision, pages 312–329. Springer.
Sohn, K., Zhang, Z., Li, C.-L., Zhang, H., Lee, C.-Y., and
Pfister, T. (2020). A simple semi-supervised learning
framework for object detection. AAAI Conference on
Artificial Intelligence.
Song, P., Li, P., Dai, L., Wang, T., and Chen, Z. (2023).
Boosting r-cnn: Reweighting r-cnn samples by rpn’s
error for underwater object detection. Neurocomput-
ing, 530:150–164.
Song, W., Wang, Y., Huang, D., Liotta, A., and Perra, C.
(2020). Enhancement of underwater images with sta-
tistical model of background light and optimization of
transmission map. IEEE Transactions on Broadcast-
ing, 66(1):153–169.
Srividhya, K. and Ramya, M. (2017). Accurate object
recognition in the underwater images using learning
algorithms and texture features. Multimedia Tools and
Applications, 76:25679–25695.
Tarvainen, A. and Valpola, H. (2017). Weight-averaged
consistency targets improve semi-supervised deep
learning results. Neural Information Processing Sys-
tems (NeurIPS).
Wang, Y., Liu, Z., and Lian, S. (2023). Semi-supervised
object detection: A survey on recent research and
progress. arXiv:2306.14106.
Wu, W., Chang, H., Zheng, Y., Li, Z., Chen, Z., and Zhang,
Z. (2022). Contrastive learning-based robust object
detection under smoky conditions. In 2022 IEEE/CVF
Conference on Computer Vision and Pattern Recogni-
tion Workshops (CVPRW), pages 4294–4301.
Xie, Q., Dai, Z., Hovy, E., Luong, T., and Le, Q.
(2020). Unsupervised data augmentation for consis-
tency training. Advances in neural information pro-
cessing systems, 33:6256–6268.
Xu, S., Zhang, M., Song, W., Mei, H., He, Q., and Liotta,
A. (2023). A systematic review and analysis of deep
learning-based underwater object detection. Neuro-
computing, 527:204–232.
Yu, H. (2020). Research progresson object detection and
tracking techniques utilization in aquaculture: a re-
view. Journal of Dalian Ocean University, 35(6):793–
804.
Zhang, F., Pan, T., and Wang, B. (2022a). Semi-supervised
object detection with adaptive class-rebalancing self-
training. In AAAI conference on artificial intelligence,
volume 36, pages 3252–3261.
Zhang, Y., Zhang, X., Li, J., Qiu, R. C., Xu, H., and Tian,
Q. (2022b). Semi-supervised contrastive learning with
similarity co-calibration. IEEE Transactions on Mul-
timedia, 25:1749–1759.
Zhou, Y., Hu, D., Li, C., and He, W. (2023). Uwyolox: An
underwater object detection framework based on im-
age enhancement and semi-supervised learning. In In-
ternational Conference on Neural Computing for Ad-
vanced Applications, pages 32–45. Springer.
Zurowietz, M. and Nattkemper, T. W. (2020). Unsupervised
knowledge transfer for object detection in marine en-
vironmental monitoring and exploration. IEEE Ac-
cess, 8:143558–143568.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
244
