
TokenOCR: An Attention Based Foundational Model for Intelligent
Optical Character Recognition
Charith Gunasekara
a
, Zachary Hamel, Feng Du and Connor Baillie
Department of National Defence, Government of Canada, Ottawa, ON, Canada
Keywords:
Natural Language Processing, Optical Character Recognition, Transformer Architecture, Curriculum
Learning.
Abstract:
Optical Character Recognition (OCR) plays a pivotal role in digitizing and analyzing text from physical docu-
ments. Despite advancements in OCR technologies, challenges persist in handling diverse text layouts, poor-
quality images, and complex fonts. In this paper, we present TokenOCR, an attention-based foundational
model designed to overcome these limitations by integrating convolutional neural networks and transformer-
based architectures. Unlike traditional OCR models that predict individual characters, TokenOCR predicts
tokens, significantly enhancing recognition accuracy and efficiency. The model employs a ResNet50 feature
extractor, an encoder with adaptive 2D positional embeddings, and a decoder utilizing multi-headed attention
mechanisms for robust text recognition. To train TokenOCR, we used a dataset of six million images incor-
porating various real-world applications. Our training strategy integrates curriculum learning and adaptive
learning rate scheduling to ensure efficient model convergence and generalization. Comprehensive evalua-
tions using Word Error Rate (WER) and Character Error Rate (CER) demonstrate that TokenOCR consistently
outperforms state-of-the-art models, including Tesseract and TrOCR, in both clean and degraded image con-
ditions. These findings underscore TokenOCR’s potential to set new standards in OCR technology, offering a
scalable, efficient, and highly accurate solution for diverse text recognition applications.
1 INTRODUCTION
Optical Character Recognition (OCR) is a fundamen-
tal technology used for digitizing text from phys-
ical documents, including printed, handwritten, or
scanned text. The primary goal of OCR systems is
to convert images of text into machine-encoded text,
facilitating tasks such as document indexing, data en-
try, and digital archiving. Traditional OCR systems
typically consist of two main components: text detec-
tion and text recognition. Text detection identifies the
areas of the image containing text, while text recogni-
tion converts these areas into editable text.
The most well-known OCR model, Tesseract
(Smith, 2007), developed by HP and later released
as open-source by Google, has become one of the
most prominent frameworks in this field. Tesser-
act uses a combination of image processing and ma-
chine learning techniques to convert text images into
text outputs. It operates in multiple stages: image
binarization, line finding, word recognition, and fi-
nally, character recognition using adaptive classifi-
a
https://orcid.org/0000-0002-7213-883X
cation. Pytesseract, a Python wrapper for Google’s
Tesseract-OCR Engine, provides a simple interface
for integrating Tesseract’s powerful OCR capabilities
into Python applications. Pytesseract allows users to
extract text from images and scanned documents with
ease, making it a popular choice for developers work-
ing on OCR-related tasks. Despite its capabilities,
Pytesseract has limitations. Its performance is heav-
ily dependent on the quality of input images and pre-
processing steps. It also struggles with handwritten
text, complex fonts, and images with significant noise
or distortions. Additionally, Pytesseract’s reliance on
traditional machine learning techniques means it may
not be as adaptable to diverse text styles as modern
deep learning approaches.
Alongside Pytesseract, there are many popular
OCR models. EasyOCR (Liao et al., 2022), a widely
used Python library, leverages deep learning for OCR
and supports over 80 languages. It is known for its
simplicity and accuracy, making it highly accessible.
However, it can be resource-intensive and may re-
quire fine-tuning for optimal performance on specific
document types. Google Cloud Vision OCR (Cloud,
Gunasekara, C., Hamel, Z., Du, F. and Baillie, C.
TokenOCR: An Attention Based Foundational Model for Intelligent Optical Character Recognition.
DOI: 10.5220/0013340100003905
In Proceedings of the 14th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2025), pages 151-158
ISBN: 978-989-758-730-6; ISSN: 2184-4313
Copyright © 2025 by Paper copyright by his Majesty the King in Right of Canada as represented by the Minister of National Defence
151

2024) offers a cloud-based solution with high accu-
racy and support for multiple languages. It also pro-
vides additional features such as image classification
and face detection. While it delivers excellent results,
the requirement for an internet connection and poten-
tial data privacy concerns with cloud-based process-
ing can be drawbacks. Amazon Textract (Services,
2024), another cloud-based OCR service provided
by AWS, is designed to extract text and data from
scanned documents. It excels at handling complex
documents with tables and forms and integrates well
with other AWS services. However, similar to Google
Cloud Vision OCR, it requires an internet connection
and may incur costs, with data privacy being a po-
tential concern. PyTorch-based libraries offer high
customization and flexibility for OCR models, such
as the deep-text-recognition-benchmark (Baek et al.,
2019a), a comprehensive benchmark for text recog-
nition tasks. This benchmark includes several state-
of-the-art models and provides pre-trained weights,
enabling developers to experiment with different ar-
chitectures. Character Region Awareness for Text de-
tection (CRAFT) (Baek et al., 2019b) is another OCR
framework that detects individual characters and links
them into words, providing robust text detection in
various environments.
Despite the success of these traditional OCR mod-
els, several limitations persist. These models of-
ten struggle with complex document layouts, poor-
quality images, and diverse fonts and languages. The
reliance on CNNs and RNNs increases computational
demands and limits scalability. Moreover, adapting
to various text styles and noise levels remains a chal-
lenge (Raj and Kos, 2022). These gaps highlight the
need for a more robust and flexible OCR solution.
Recent advancements in Transformer architec-
tures (Vaswani et al., 2023) have shown promise in
overcoming these challenges. Transformers, origi-
nally designed for natural language processing (NLP)
tasks, have demonstrated impressive performance in
image processing. These models excel at handling
sequential data and can capture long-range depen-
dencies within text, making them highly effective for
OCR tasks. The attention mechanism in transform-
ers allows the model to focus on different parts of
the input image, enabling better recognition of com-
plex text patterns. The introduction of Vision Trans-
formers (Dosovitskiy et al., 2021) and their variants
has paved the way for applying transformer-based ar-
chitectures to OCR tasks. Transformer-based Optical
Character Recognition (TrOCR) (Li et al., 2022) with
Pre-trained Models introduces an innovative approach
to OCR that leverages the Transformer architecture
for both image understanding and text generation.
Despite the advancements brought by TrOCR in
leveraging transformer architectures for OCR tasks,
several challenges remain in handling variability in
text appearances, poor-quality images, and diverse
fonts. The expensive hardware requirements for pre-
training fine-tuning, along with the need for millions
of images for pre-training, present significant hurdles.
In this paper we present TokenOCR foundational
model to improve OCR performance in document lay-
outs where current models often struggle while re-
ducing the model weight for faster training and in-
ferencing tasks. Despite advancements made by mod-
els like TrOCR, significant challenges remain in accu-
rately recognizing text within complex layouts, deal-
ing with varying image qualities, and accommodat-
ing diverse font styles. These limitations are critical
in scenarios where precision and reliability are essen-
tial. TokenOCR aims to bridge these gaps by devel-
oping a model that excels in understanding contextual
and spatial relationships within the text; it improves
the handling of varying text layouts and enhances the
model’s ability to generalize across poor-quality input
document types compared to the current alternatives.
2 MODEL ARCHITECTURE
TokenOCR combines convolutional neural networks
and transformer-based architectures. This design en-
hances the model’s ability to capture and process both
visual and textual information efficiently, ensuring ac-
curate text recognition even in complex scenarios.
Figure 1 illustrates the overall architecture of the
TokenOCR model. Image input is processed through
a ResNet (Pascanu et al., 2013) feature extractor,
which transforms the image into a feature map by cap-
turing the visual features. This feature map is then fed
into the encoder, where it undergoes vectorization and
positional encoding to retain spatial information. The
encoder utilizes self-attention (Vaswani et al., 2023)
mechanisms to focus on different parts of the image,
global attention (Liu et al., 2021) to capture contex-
tual information, and cross attention (Gheini et al.,
2021) to align image sections with text sections. Ad-
ditionally, the encoder incorporates 2D learnable po-
sitions (Yu et al., 2024) to encode spatial relationships
and text position attention (Shaw et al., 2018) to em-
phasize specific text areas within the image. The out-
put of the encoder is an encoded representation that
combines visual and positional data. Next, the en-
coded representation is segmented into tokenized rep-
resentations using a SentencePiece tokenizer, prepar-
ing the data for text generation. The tokenized data
is then processed by the decoder, which employs self-
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
152
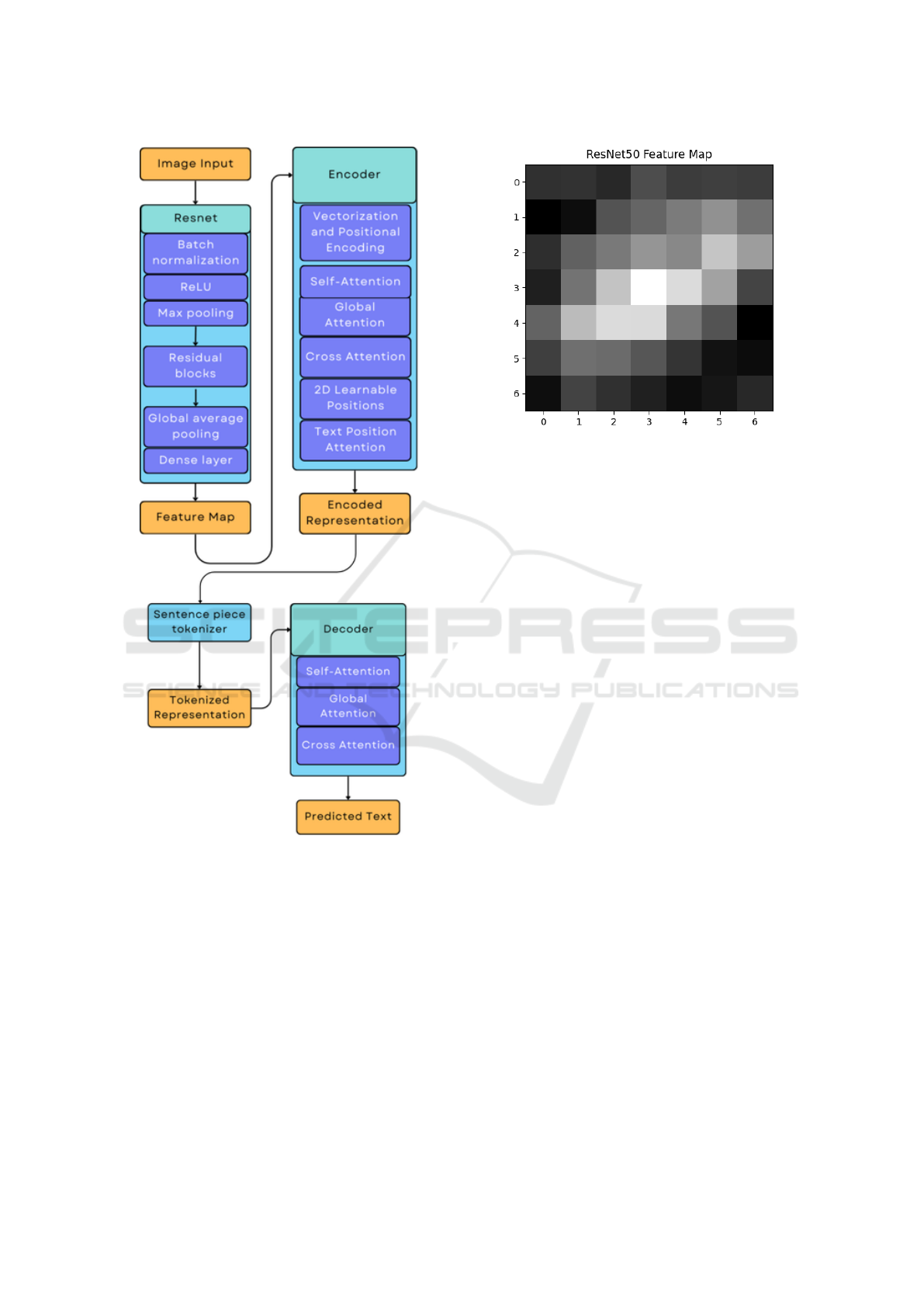
Figure 1: Overall Architecture of TokenOCR.
attention to concentrate on various parts of the tok-
enized sequence, global attention to maintain context,
and cross-attention to align the encoded image rep-
resentation with the text tokens accurately. Finally,
the decoder generates the predicted text from the tok-
enized input, completing the OCR process.
2.1 ResNet
TokenOCR is built upon two foundational base mod-
els: ResNet50 and the EfficientNet family. These base
models are renowned for their effectiveness in feature
extraction tasks, particularly in image recognition.
Figure 2: An example of a feature map generated by the
sentence “Pariguana (meaning “near Iguana” in Greek) is
an extinct genus of iguanid lizard from the Late Cretaceous
of western North America” shown in the first row of figure
3.
ResNet50 introduced residual connections, known as
skip connections, that facilitate training deep neural
networks by mitigating the vanishing gradient prob-
lem, where the gradients of the loss function with
respect to the weights in earlier layers become ex-
tremely small and insignificant for the learning pro-
cess as training progresses. Leveraging ResNet50,
TokenOCR capitalizes on its feature extraction ca-
pabilities across various computational constraints.
Within the ResNet layer shown in the ResNet block
of Figure 1, an input image is first processed by an
initial convolutional block containing batch normal-
ization, a ReLU activation function, and max pooling
to capture the basic features. This is followed by the
core of ResNet, which consists of multiple residual
blocks. Each residual block applies a series of trans-
formations on the feature map by adding new features
in succession. Lastly, a series of operations involving
global average pooling and a fully connected dense
layer produces a final feature map as an output (Fig-
ure 2).
2.2 Encoder
The initial stage of the encoder takes the feature map
and divides it into a set of fixed-sized patches. Each
patch is subsequently flattened into a one-dimensional
vector. The vectors then undergo a linear transforma-
tion, projecting the flattened patches onto a higher-
dimensional embedding space. These resultant patch
embeddings serve as the direct inputs to the en-
coder. Due to the lack of inherent sequence process-
ing within the transformer architecture, positional en-
TokenOCR: An Attention Based Foundational Model for Intelligent Optical Character Recognition
153

codings are computed and added to each patch em-
bedding prior to their input into the encoder. The
position encoding provides the transformer with in-
formation about the patch embedding location within
the original image.
The encoder component (Encoder block in Fig-
ure 1) consists of two layers: a multi-headed attention
layer and a feed-forward layer (Vaswani et al., 2023).
The multi-headed attention layer incorporates various
attention mechanisms, including self-attention, cross-
attention, global attention, and text position atten-
tion. Additionally, the encoder utilizes adaptive 2D
positional embeddings, which are learnable embed-
dings that encode the spatial arrangement of text el-
ements within the image. Self-attention allows the
model to weigh the importance of each word/token
relative to others, capturing dependencies within the
sequence irrespective of distance. Cross-attention en-
ables the model to attend to information from one se-
quence (image features) while processing another se-
quence (text). Global attention provides the model
with a broader contextual understanding of the en-
tire input, aiding in text extraction. Text position at-
tention specifically focuses on the positional infor-
mation of text elements within the image, attending
to the spatial arrangement of text. Lastly, adaptive
2D positional embeddings are updated during train-
ing, allowing the model to dynamically learn spatial
relationships between text elements. These embed-
dings enhance the model’s ability to understand the
spatial layout of text within the image, facilitating ac-
curate text extraction. The feed-forward layer pro-
cesses each position in the sequence individually. It
first expands the representation of each position to
a higher-dimensional space through a linear transfor-
mation, applies a ReLU activation function, and then
reduces the dimensionality back to the original size
through another linear transformation, producing the
encoded representation of the original input.
2.3 Tokenizer
The encoded representation from the encoder is then
fed into a tokenizer to produce a tokenized represen-
tation for the decoder. TokenOCR employs Senten-
cePiece (Kudo and Richardson, 2018) tokenization to
segment the text into variable-length subword units
based on their frequency of occurrence. The choice of
tokenization method significantly impacts the model’s
performance and the granularity of information it can
capture. For instance, character-level tokenization
preserves individual characters’ information but may
struggle with out-of-vocabulary words, whereas byte-
pair encoding (BPE) (Sennrich et al., 2016) tokeniza-
tion can handle a larger vocabulary size and capture
morphological information more effectively. BPE,
chosen for TokenOCR, balances between character-
level and word-level tokenization, providing a good
compromise for many NLP tasks. For TokenOCR, a
vocabulary size of 10,000 was chosen. The tokenizer
was trained on approximately 30GB of text data from
the No Language Left Behind (NLLB) en-fr corpus
(Team et al., 2022), ensuring comprehensive cover-
age of language patterns and structures. Addition-
ally, special tokens were introduced to the tokenized
sequences: padding tokens (set to 0) to standard-
ize sequence lengths, start-of-sequence tokens (set to
1) to mark the beginning of each sequence, end-of-
sequence tokens (set to 2) to indicate the end of each
sequence, and unknown tokens (set to 3) to represent
out-of-vocabulary words. These specifications facil-
itate effective tokenization and model training while
maintaining compatibility with the Transformer ar-
chitecture.
2.4 Decoder
The decoder component (Decoder block in Figure
1) consists of a multi-headed attention layer and a
feed-forward layer. Similar to the encoder, these at-
tention mechanisms aid in generating accurate tex-
tual outputs based on the encoded image representa-
tions. The decoder also employs sinusoidal embed-
dings, which provide a continuous representation of
textual tokens, enhancing the model’s understanding
of textual information. The decoder uses the same
attention mechanisms as the encoder: self-attention,
cross-attention, and global attention. These mech-
anisms enable the decoder to attend to relevant in-
formation within the encoded image representations
while generating textual outputs. Self-attention al-
lows the decoder to focus on relevant parts of the gen-
erated sequence, while cross-attention aligns the en-
coded image features with the generated text. Sinu-
soidal embeddings, inspired by positional encodings
in transformers, encode both position and frequency
information of tokens, enabling the model to cap-
ture sequential relationships effectively. The decoder
starts with a start-of-sequence token (<s>). Using the
encoded representation and the initial token, the de-
coder predicts the next token in the sequence, contin-
uing this process iteratively. Lastly, beam search (Fre-
itag and Al-Onaizan, 2017), a heuristic algorithm, ex-
plores the result set by expanding the most promising
results within the set. The width of this beam, typ-
ically referred to as the ”beam size,” determines the
number of nodes expanded at each level and balances
exploration and exploitation. The resultant best se-
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
154

quence of tokens is converted into text, representing
TokenOCR’s final output.
3 MODEL TRAINING DATA
GENERATION
Data generation involves creating a comprehensive
dataset of synthetic text images that TokenOCR can
use for training. This approach ensures that the model
can accurately recognize and interpret text across a
wide range of real-world scenarios. Synthetic data
generation offers several key advantages over real-
world data:
• Control Over Data Quality and Variety: Tai-
lors the dataset to include diverse text scenarios,
ensuring consistency and diversity.
• Handling Specific Use Cases: Simulates specific
distortions like skewing and blurring to enhance
robustness.
• Scalability and Efficiency: Produces large vol-
umes of data quickly, accelerating the training
process.
• Mitigating Data Scarcity: Addresses the lack
of high-quality labelled data in a niche field like
OCR.
• Ethical and Legal Considerations: Avoids legal
and ethical issues related to data usage.
• Customizable Complexity: Introduces system-
atic variations to mimic real-world imperfections.
3.1 Text Recognition Data Generator
To construct a robust training dataset for TokenOCR,
we employed the Text Recognition Data Generator
(TRDG) (Krishnan and Jawahar, 2016), an open-
source tool designed for generating synthetic text im-
ages.
The content for the 6 million generated images
(Figure 3) was sourced from Wikipedia articles using
the GeneratorFromWikipedia function of TRDG.
Wikipedia’s vast and diverse range of content, from
detailed scientific entries to broad historical sum-
maries, ensures that TokenOCR is exposed to various
text types and complexities. This diversity enables the
model to handle real-world textual scenarios requiring
semantic understanding and contextual interpretation
(Rusi
˜
nol et al., 2021).
To replicate real-world conditions as closely as
possible, we incorporated the following image vari-
ation techniques during data generation:
• Skewing: Images were tilted at random angles
between 0 to 2 degrees to simulate misalignment
commonly seen in scanned documents. This helps
the model recognize text in less-than-ideal align-
ments.
• Blurring: Randomized blur effects with values
between 0 to 3 were applied to mimic varying
levels of camera focus and motion blur. This pre-
pares the model to handle practical situations with
imperfect image clarity.
• Size Variability: Images were generated with
varying widths between 780 and 1280 pixels, re-
flecting typical size variations in digital docu-
ments and enhancing adaptability to diverse di-
mensions.
Figure 3: Examples of images generated by TRDG with
various blurs and skews.
4 TRAINING
TokenOCR’s training strategy employs adaptive
learning rate scheduling (Xu et al., 2019) and cur-
riculum learning (Soviany et al., 2022). Techniques
like early stopping and dropout regularization prevent
overfitting, ensuring the model generalizes well to un-
seen data.
4.1 Curriculum Learning
Curriculum learning divides the training process into
stages, introducing progressively complex data. In
TokenOCR, this approach enhances generalization
across various textual complexities and conditions.
The curriculum structure is as follows:
• Random Letters: Initial training with images of
random letters teaches the model basic character
recognition without word structure complexity.
• Nonsensical Words: The next stage introduces
images of nonsensical words, enabling the model
to recognize letter combinations and spacing nu-
ances.
• Random Words: Images of random words help
the model understand common letter groupings
and word structures.
• Real Semantically Correct Sentences: The fi-
nal stage involves semantically correct sentences,
TokenOCR: An Attention Based Foundational Model for Intelligent Optical Character Recognition
155
challenging the model to recognize text in context
and understand sentence-level meaning.
4.2 Training Parameters
The Adam optimizer was used with a learning rate
scheduled through an Exponential Decay policy, start-
ing at 0.0001 and decaying by 0.9 every 10,000 steps
in a staircase fashion to prevent premature conver-
gence.
Initial training spanned 100 epochs on a dataset of
1 million images, with early stopping based on vali-
dation loss to counteract overfitting. Following signs
of overfitting, the dataset was expanded to 6 million
images to introduce variability and enhance general-
ization. Training epochs were adjusted dynamically
in this expanded phase based on performance metrics.
4.3 Overfitting Mitigation
Dropout regularization with a rate of 0.1 was em-
ployed to mitigate overfitting. This rate strikes a bal-
ance between regularization strength and training ef-
ficiency. TokenOCR’s architecture includes eight at-
tention heads and a hidden size of 256, facilitating
effective multi-head attention and sequence process-
ing. With 524 million parameters, the model balances
complexity and computational efficiency.
4.4 Hardware Requirements
Training was performed on a cluster of 8 NVIDIA
A100 GPUs. These high-performance GPUs signif-
icantly reduced training time, enabling scalable han-
dling of large datasets.
5 RESULTS
Table 1: WER and CER using 1000 blurry images.
Model WER CER
TokenOCR 0.2929 0.1908
Tesseract 0.3953 0.4046
TrOCR 0.9853 0.8873
Table 2: WER and CER using 1000 clean images.
Model WER CER
TokenOCR 0.0274 0.0140
Tesseract 0.0868 0.1473
TrOCR 0.9489 0.7251
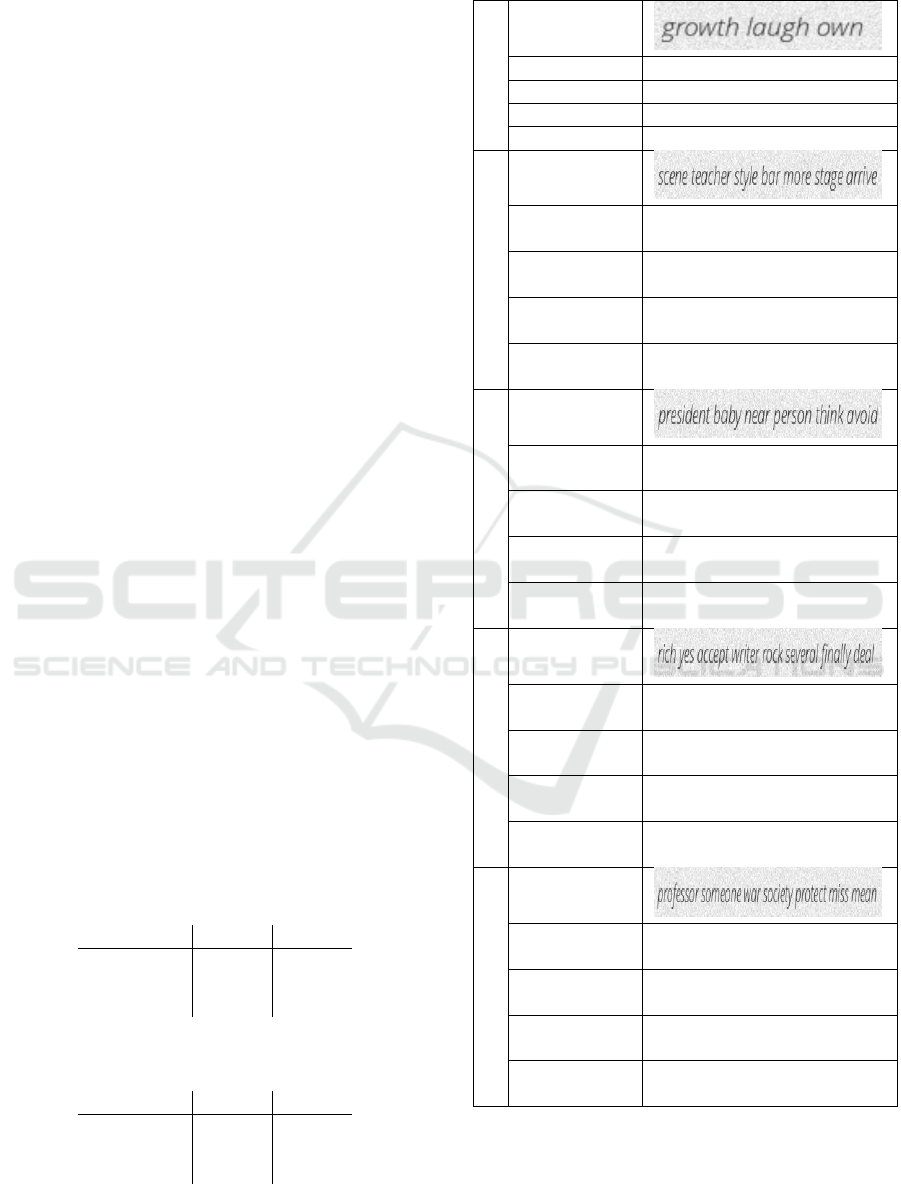
Table 3: Sample Clean Images from the Test.
1
Image
Ground Truth
growth laugh own
TokenOCR
growth laugh own
Tesseract
growth laugh own
TrOCR
Pointing on our own
2
Image
Ground Truth
scene teacher style
bar more stage arrive
TokenOCR
scene teacher style
bar more stage arrive
Tesseract
scene teacher style
bar more stage arrive
TrOCR
sweetrate systeme: nne
: nvcate: . . . . . .
3
Image
Ground Truth
president baby near
person think avoid
TokenOCR
president baby near
person think avoid
Tesseract
president baby near
person think avoid
TrOCR
pederlighter permitted
: : : : : : : : : : : : : :
4
Image
Ground Truth
rich yes accept writer rock
several finally deal
TokenOCR
rich yes accept writer rock
several finally deal
Tesseract
( rrich yes accept writer rock
several finally deal)
TrOCR
pederlighter permitted
: : : : : : : : : : : : : :
5
Image
Ground Truth
professor someone war
society protect miss mean
TokenOCR
professor someone war
society protect miss mean
Tesseract
professor someone war
society protect miss mean
TrOCR
HANKS ANDAPT NOTE
NOTSET(PAY TAX) TAX(S
We evaluate TokenOCR’s performance on a diverse
set of images and compare the Word Error Rate
(WER) and Character Error Rate (CER) with two
other widely used alternatives, Tesseract and TrOCR.
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
156

Table 4: Sample Blurry Images from the Test.
1
Image
Ground Truth
question treatment
can develop
TokenOCR
question treatment
can develop
Tesseract
(no answer)
TrOCR
..... ..... . . . . .
. . . . . . . . . . .
2
Image
Ground Truth
clearly according
clearly she toward
TokenOCR
clearly according
clearly she toward
Tesseract
clearly according
Clearly she toward
TrOCR
.........................
...............................
............................
3
Image
Ground Truth
process road piece force
interesting look move sound
TokenOCR
process road piece force
interesting look move sound
Tesseract
process road parce force
mteresting 008 Mowe soured
TrOCR
...........................
............................
4
Image
Ground Truth
special rise family fast
and travel send
TokenOCR
special rise family fast
and travel send
Tesseract
Spec rae fore fast
ond trove send
TrOCR
.......................
...............................
5
Image
Ground Truth
your campaign language
remember model remain large
TokenOCR
your campaign language
remember model remain large
Tesseract
your Compargn longuage
remember mode! remon large
TrOCR
..........................
.............................
The test results are given in Tables 1, 2, 3 and 4.
WER =
# Substitutions+# Deletions+# Insertions
# Words in the reading frame
(1)
CER =
# Substitutions+# Deletions+# Insertions
# Characters in the reading frame
(2)
TokenOCR was benchmarked against Pytesser-
act and TrOCR. Pytesseract, a well-known OCR
engine, provides a strong baseline, while TrOCR’s
transformer-based architecture offers a modern com-
parison.
TokenOCR consistently outperformed bench-
marks in both clean and challenging conditions,
demonstrating its reliability and versatility across var-
ious use cases. These results position TokenOCR as a
leading tool in OCR applications requiring precision
and adaptability.
6 CONCLUSION
This paper introduces TokenOCR, a novel attention-
based OCR model that addresses persistent chal-
lenges in text recognition across complex and real-
world scenarios. By integrating convolutional neural
networks with transformer architectures, TokenOCR
effectively captures both visual and textual informa-
tion. A key innovation of TokenOCR lies in its pre-
diction of tokens instead of individual characters, en-
abling the model to leverage contextual information
for significantly improved performance in text recog-
nition tasks. This approach reduces errors caused by
out-of-context character predictions and enhances the
model’s ability to generalize across diverse text lay-
outs and fonts.
TokenOCR’s architecture features ResNet50-
based feature extraction, adaptive 2D positional em-
beddings, and multi-headed attention mechanisms, all
contributing to its robust performance. Training on
a large-scale synthetic dataset generated with TRDG
allowed the model to become resilient to real-world
imperfections, such as skewing and blurring. Addi-
tionally, a curriculum learning-based training strategy
progressively exposed the model to increasing com-
plexities, ensuring strong generalization across vari-
ous document types and conditions.
Evaluation results highlight TokenOCR’s superi-
ority, consistently outperforming established bench-
marks such as Tesseract and TrOCR in Word Error
Rate (WER) and Character Error Rate (CER) metrics
across clean and degraded datasets. This performance
demonstrates the practical impact of token-based pre-
diction, which aligns well with real-world OCR chal-
lenges.
The implications of this work are substantial for
industries requiring precise and reliable text recogni-
tion, including legal documentation, healthcare, and
digital archiving. Future research directions include
TokenOCR: An Attention Based Foundational Model for Intelligent Optical Character Recognition
157

optimizing computational efficiency, expanding mul-
tilingual capabilities, and exploring applications to
more complex document structures. With its demon-
strated efficacy and innovative approach, TokenOCR
represents a significant advancement in OCR technol-
ogy, setting a new standard for text digitization and
analysis.
REFERENCES
Baek, J., Kim, G., Lee, J., Park, S., Han, D., Yun, S.,
Oh, S. J., and Lee, H. (2019a). What is wrong with
scene text recognition model comparisons? dataset
and model analysis.
Baek, Y., Lee, B., Han, D., Yun, S., and Lee, H. (2019b).
Character region awareness for text detection.
Cloud, G. (2024). Cloud vision documentation. https:
//cloud.google.com/vision/docs. Accessed: 2024-08-
28.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn,
D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer,
M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby,
N. (2021). An image is worth 16x16 words: Trans-
formers for image recognition at scale.
Freitag, M. and Al-Onaizan, Y. (2017). Beam search strate-
gies for neural machine translation. In Proceedings
of the First Workshop on Neural Machine Translation.
Association for Computational Linguistics.
Gheini, M., Ren, X., and May, J. (2021). Cross-attention
is all you need: Adapting pretrained transformers for
machine translation.
Krishnan, P. and Jawahar, C. V. (2016). Generating syn-
thetic data for text recognition.
Kudo, T. and Richardson, J. (2018). Sentencepiece: A sim-
ple and language independent subword tokenizer and
detokenizer for neural text processing.
Li, M., Lv, T., Chen, J., Cui, L., Lu, Y., Florencio,
D., Zhang, C., Li, Z., and Wei, F. (2022). Trocr:
Transformer-based optical character recognition with
pre-trained models.
Liao, M., Zou, Z., Wan, Z., Yao, C., and Bai, X. (2022).
Real-time scene text detection with differentiable bi-
narization and adaptive scale fusion.
Liu, Y., Shao, Z., and Hoffmann, N. (2021). Global at-
tention mechanism: Retain information to enhance
channel-spatial interactions.
Pascanu, R., Mikolov, T., and Bengio, Y. (2013). On the
difficulty of training recurrent neural networks.
Raj, R. and Kos, A. (2022). A comprehensive study of opti-
cal character recognition. In 2022 29th International
Conference on Mixed Design of Integrated Circuits
and System (MIXDES), pages 151–154.
Rusi
˜
nol, M., Sanchez, J.-M., and Karatzas, D. (2021). Doc-
ument image quality assessment via explicit blur and
text size estimation. In International Conference on
Document Analysis and Recognition, pages 308–321.
Springer.
Sennrich, R., Haddow, B., and Birch, A. (2016). Neural
machine translation of rare words with subword units.
Services, A. W. (2024). Amazon textract documentation.
https://aws.amazon.com/textract/. Accessed: 2024-
08-28.
Shaw, P., Uszkoreit, J., and Vaswani, A. (2018). Self-
attention with relative position representations.
Smith, R. (2007). An overview of the tesseract ocr engine.
Google Inc. Available at https://code.google.com/p/
tesseract-ocr/.
Soviany, P., Ionescu, R. T., Rota, P., and Sebe, N. (2022).
Curriculum learning: A survey.
Team, N., Costa-juss
`
a, M. R., Cross, J., C¸ elebi, O., El-
bayad, M., Heafield, K., Heffernan, K., Kalbassi, E.,
Lam, J., Licht, D., Maillard, J., Sun, A., Wang, S.,
Wenzek, G., Youngblood, A., Akula, B., Barrault, L.,
Gonzalez, G. M., Hansanti, P., Hoffman, J., Jarrett,
S., Sadagopan, K. R., Rowe, D., Spruit, S., Tran, C.,
Andrews, P., Ayan, N. F., Bhosale, S., Edunov, S.,
Fan, A., Gao, C., Goswami, V., Guzm
´
an, F., Koehn,
P., Mourachko, A., Ropers, C., Saleem, S., Schwenk,
H., and Wang, J. (2022). No language left behind:
Scaling human-centered machine translation.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, L., and Polosukhin, I.
(2023). Attention is all you need.
Xu, Z., Dai, A. M., Kemp, J., and Metz, L. (2019). Learning
an adaptive learning rate schedule.
Yu, R., Wang, Z., Wang, Y., Li, K., Liu, C., Duan, H., Ji, X.,
and Chen, J. (2024). Lape: Layer-adaptive position
embedding for vision transformers with independent
layer normalization. In Proceedings of the IEEE/CVF
International Conference on Computer Vision (ICCV),
pages 5886–5896. IEEE.
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
158
