
Detecting Misleading Information with LLMs and Explainable ASP
Quang-Anh Nguyen
1
, Thu-Trang Pham
1
, Thi-Hai-yen Vuong
1
, Van-Giang Trinh
2
and Nguyen Ha Thanh
3,4
1
VNU University of Engineering and Technology, Hanoi, Vietnam
2
Inria Saclay, EP Lifeware, Palaiseau, France
3
Center for Juris-Informatics, ROIS-DS, Tokyo, Japan
4
Research and Development Center for Large Language Models, NII, Tokyo, Japan
Keywords:
LLM, ASP, Explainability, Misleading Information Detection.
Abstract:
Answer Set Programming (ASP) is traditionally constrained by predefined rule sets and domains, which limits
the scalability of ASP systems. While Large Language Models (LLMs) exhibit remarkable capabilities in
linguistic comprehension and information representation, they are limited in logical reasoning which is the
notable strength of ASP. Hence, there is growing research interest in integrating LLMs with ASP to leverage
these abilities. Although many models combining LLMs and ASP have demonstrated competitive results,
issues related to misleading input information which directly affect the incorrect solutions produced by these
models have not been adequately addressed. In this study, we propose a method integrating LLMs with
explainable ASP to trace back and identify misleading segments in the provided input. Experiments conducted
on the CLUTRR dataset show promising results, laying a foundation for future research on error correction
to enhance the accuracy of question-answering models. Furthermore, we discuss current challenges, potential
advancements, and issues related to the utilization of hybrid AI systems.
1 INTRODUCTION
Answer Set Programming (ASP) is a declarative
programming paradigm, primarily utilized in solv-
ing combinatorial problems (Gelfond and Lifschitz,
1988; Eiter et al., 2009). It is rooted in logic program-
ming and nonmonotonic reasoning, offering a power-
ful framework for knowledge representation and rea-
soning. The origin of ASP can be traced back to the
stable model semantics of logic programming, intro-
duced by Gelfond and Lifschitz in the late 1980s.
Over years, it has evolved through several signifi-
cant stages, adapting and integrating more sophisti-
cated solving techniques from the fields of SAT solv-
ing and constraint programming. This convergence of
methodologies has not only enhanced the efficiency
and scalability of ASP solvers but also broadened
their applicability across various domains including
AI, bioinformatics, and complex systems analysis
(Erdem et al., 2016; Trinh et al., 2024).
Large Language Models (LLMs), such as GPT-4
(Achiam et al., 2023), demonstrate exceptional capa-
bilities in understanding and generating natural lan-
guage, enabling them to act as versatile tools across
various applications by converting ambiguous hu-
man language into structured, computable formats.
This potential is particularly impactful for Answer
Set Programming (ASP), a declarative programming
paradigm designed to tackle complex combinatorial
problems. In particular, integrating LLMs into ASP
systems allows for automatic rule generation and dy-
namic fact integration, enhancing the flexibility and
efficiency of ASP solvers (Ishay et al., 2023). Fur-
thermore, LLMs serve as an interface between natu-
ral language and ASP’s logical reasoning framework,
facilitating the translation of real-world problems into
formal representations and enabling ASP to adapt dy-
namically to contextual requirements (Nguyen et al.,
2023a; Rajasekharan et al., 2023). This innova-
tion paves the way for more intelligent, interactive,
and autonomous computational logic systems, signif-
icantly expanding ASP’s applicability in fields like le-
gal reasoning, healthcare, and beyond.
Although the integration of LLMs with ASP
has significantly improved accuracy and applicabil-
ity across various problem domains, erroneous or am-
biguous input information also requires attention, as
it can directly lead to incorrect solutions. This phe-
Nguyen, Q.-A., Pham, T.-T., Vuong, T.-H.-Y., Trinh, V.-G. and Thanh, N. H.
Detecting Misleading Information with LLMs and Explainable ASP.
DOI: 10.5220/0013357400003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 3, pages 1327-1334
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
1327

nomenon may arise from initial inaccuracies or the
intrinsic complexity of natural language. Identifying
and addressing such flawed information is significant
for the derivation of an accurate and reliable solu-
tion, particularly in domains that demand high levels
of precision, such as law, healthcare, and so on.
Motivated by such problems, in this paper, we aim
to leverage the language comprehension capabilities
of LLMs, combined with the inference power and
the explanatory features of explainable ASP to ad-
dress the challenges of detecting incorrect informa-
tion. We introduce our framework, which integrates
LLMs with ASP to perform two main steps: rec-
ognizing questions containing conflict answers and
analysing these questions to identify misleading in-
formation.
The remainder of the paper is organized as fol-
lows. Section 2 recalls the foundational background.
The related work section follows, examining existing
literature on ASP, LLMs, and their intersections, iden-
tifying the gaps our study addresses. The core of our
work, presented in Section 3, introduces our frame-
work, highlighting our novel approach for the incor-
rect information detection. Section 4 shows the ex-
perimental results demonstrating the efficiency of our
approach. Subsequent discussions critique limitations
and implications, as well as suggest solutions to over-
come them. Finally, Section 6 concludes the paper.
2 PRELIMINARIES
The fundamental knowledge on which our system re-
lies will be presented in detail, including ASP, LLMs
and their combinations.
2.1 Answer Set Programming
Answer Set Programming (ASP) has a rich heritage
in logic programming, drawing from various declar-
ative programming paradigms. ASP is conceptu-
ally connected to earlier forms of logic programming
and computational logic, integrating principles from
Constraint Logic Programming (CLP) and Abduc-
tive Logic Programming (ALP), among others (Eiter
et al., 2009).
Early foundational work by (McCarthy, 1959)
introduced concepts that would later influence the
design of logic programming languages like Pro-
log, paving the way for declarative programming
paradigms. Constraint Logic Programming was fur-
ther developed as a powerful paradigm, enabling pro-
gramming with explicit constraints. Marriott and
Stuckey’s book (Marriott and Stuckey, 1998) provides
a comprehensive introduction to this field, explaining
key principles and applications that overlap with ASP
concerning solving combinatorial problems.
The developments and practical applications of
ASP have been showcased in several ASP compe-
titions, which compare system capabilities and per-
formance across a variety of benchmark problems.
(Calimeri et al., 2014) details the Third Open An-
swer Set Programming Competition, emphasizing the
growing maturity and capability of ASP systems in
handling complex, real-world problems across multi-
ple domains.
Each of these contributions underscores different
facets of ASP, reflecting its theoretical depth and ver-
satility as a paradigm for declarative programming.
As indicated by (Calimeri et al., 2014), ASP contin-
ues to evolve, interfacing with related fields and ex-
panding its applicative reach, thereby confirming its
significance and potential within the broader land-
scape of computational logic and artificial intelli-
gence.
2.2 Large Language Models
Large Language Models (LLMs) have achieved sig-
nificant milestones since the introduction of the
Transformer architecture, which is known for its
reliance on attention mechanisms (Vaswani et al.,
2017). This transformative approach moved away
from recurrent and convolutional structures, demon-
strating that attention alone could yield high perfor-
mance in sequence transduction tasks like transla-
tion. In addition to sequence transduction, LLMs
have also shown remarkable capabilities in language
understanding. This is evident in tasks such as clas-
sification (Liga and Robaldo, 2023), sentiment anal-
ysis (Kheiri and Karimi, 2023), and information ex-
traction (Zin et al., 2023), where the models can accu-
rately comprehend text and extract relevant informa-
tion. Moreover, LLMs have proven effective in ques-
tion answering systems, where they can understand a
question posed in natural language and provide a con-
cise and accurate answer (Phi et al., 2020).
Subsequent advancements in LLMs have shown
remarkable effectiveness across a range of bench-
marks. These include GPT-3, which demonstrated
the power of autoregressive language models in few-
shot settings (Brown, 2020), and its successor GPT-
4, which has expanded capabilities to handle multi-
modal inputs and achieved human-level performance
on various professional exams (Achiam et al., 2023).
Despite these advances, logical reasoning remains a
challenging area for LLMs, often referred to as their
“Achilles’ heel.” The core issue is that these models
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1328

typically generate outputs based on patterns learned
from extensive data, which may not always align with
the rigorous logical reasoning required in domains
like law, medicine, and science. While there are at-
tempts to tailor LLMs to better handle logical rea-
soning through specific training strategies (Nguyen
et al., 2023a), the inherent limitations in their ability
to genuinely deduce or reason abstractly remain ev-
ident. Studies have shown that even though LLMs
perform well with legal text processing tasks, they
struggle significantly with tasks demanding high log-
ical inference such as abductive reasoning (Nguyen
et al., 2023b).
2.3 Combining Large Language Models
and Answer Set Programming
The integration of LLMs with ASP represents a
promising avenue in the development of advanced
computational logic systems that leverage both sym-
bolic and sub-symbolic approaches. This neuro-
symbolic integration seeks to harness the vast back-
ground knowledge and natural language processing
capabilities of LLMs alongside the rigorous, rule-
based reasoning power of ASP.
(Yang et al., 2023) present NeurASP that mar-
ries neural network outputs with ASP’s symbolic
reasoning capabilities. By treating outputs from
neural networks as probabilistic facts within ASP,
NeurASP facilitates a seamless blend, enabling more
nuanced decision-making processes that incorporate
both learned patterns and explicitly defined rules.
This approach enhances the interpretability and relia-
bility of neural network predictions by tethering them
to logical constraints and reasoning processes in ASP.
Similarly, the work of (Bauer et al., 2023) exem-
plifies the application of this hybrid approach in the
context of Visual Question Answering (VQA). Their
neuro-symbolic system combines neural networks for
image processing and Optical Character Recogni-
tion (OCR) with ASP for high-level reasoning about
graph-structured data. The integration proves partic-
ularly effective in domains where input data are com-
plex and require both perceptual understanding and
logical inference, achieving substantial accuracy im-
provements and showcasing the adaptability of LLMs
when guided by symbolic logic frameworks.
The STAR framework presented by (Rajasekha-
ran et al., 2023) represents another significant step in
this integration. STAR leverages LLMs for extracting
structured knowledge from natural language, which is
then reasoned over using goal-directed ASP to yield
reliable conclusions that are explainable in nature.
This method particularly enhances performance in
Natural Language Understanding (NLU) tasks requir-
ing deep reasoning-areas where LLMs typically falter.
3 METHOD
Our goal in this research concentrates on detecting
contraditory or ambiguous information in natural lan-
guage stories that requires logical reasoning to take
into account. We propose a method integrating LLMs
with ASP and their explainable extension. This ap-
proach combines the power of language understand-
ing from LLMs and the inference ability along with
the explication of explainable ASP to tackle logical
problems.
Figure 1 presents the overview of our framework
to highlight problematic components and point out
errorneous reasons from a human language story in
CLUTRR dataset (Sinha et al., 2019). In particular,
Yang et al proposed applying LLMs to convert the re-
lations between people in the story into symbolic ex-
pressions. GPT-4 (Achiam et al., 2023) is utilized to
complete the task of converting verbal context into se-
mantic parse that can cooperate with foundation rules
for ASP solvers. After that, an ASP solver will re-
turn an answer set that contains all possible relation-
ships of people that can be inferred. We then clas-
sify whether conflicts appear in interpersonal relation-
ships, or in other words, whether there is more than
one relation between two distinct individuals. Sub-
sequently, the semantic parse of this story is com-
bined with a set of constructed rules based on founda-
tional rules to collect explanations from the explain-
able ASP component, which traces back the rules and
logical symbols used in the judgment. With these ex-
planations, not only are the conflicting pairs identi-
fied, but also the reasons leading to them, particularly
the elements in the semantic parse, are located. After-
wards, using natural language processing techniques,
misleading information in the given story, as well as
the types of errors causing these issues, are identified.
The incorporation of LLMs into the proposed
framework offers significant flexibility, as it elimi-
nates the need for pre-training datasets. By simply
providing a few examples as few-shot prompts to the
LLM, the system can effectively adjust to different
reasoning contexts without extensive reconfiguration.
This methodology not only broadens the applicabil-
ity of the framework but also simplifies its deploy-
ment across diverse scenarios. Comprehensive details
about the components of this framework, including its
setup and operational mechanisms, will be elaborated
in the subsequent sections.
Detecting Misleading Information with LLMs and Explainable ASP
1329
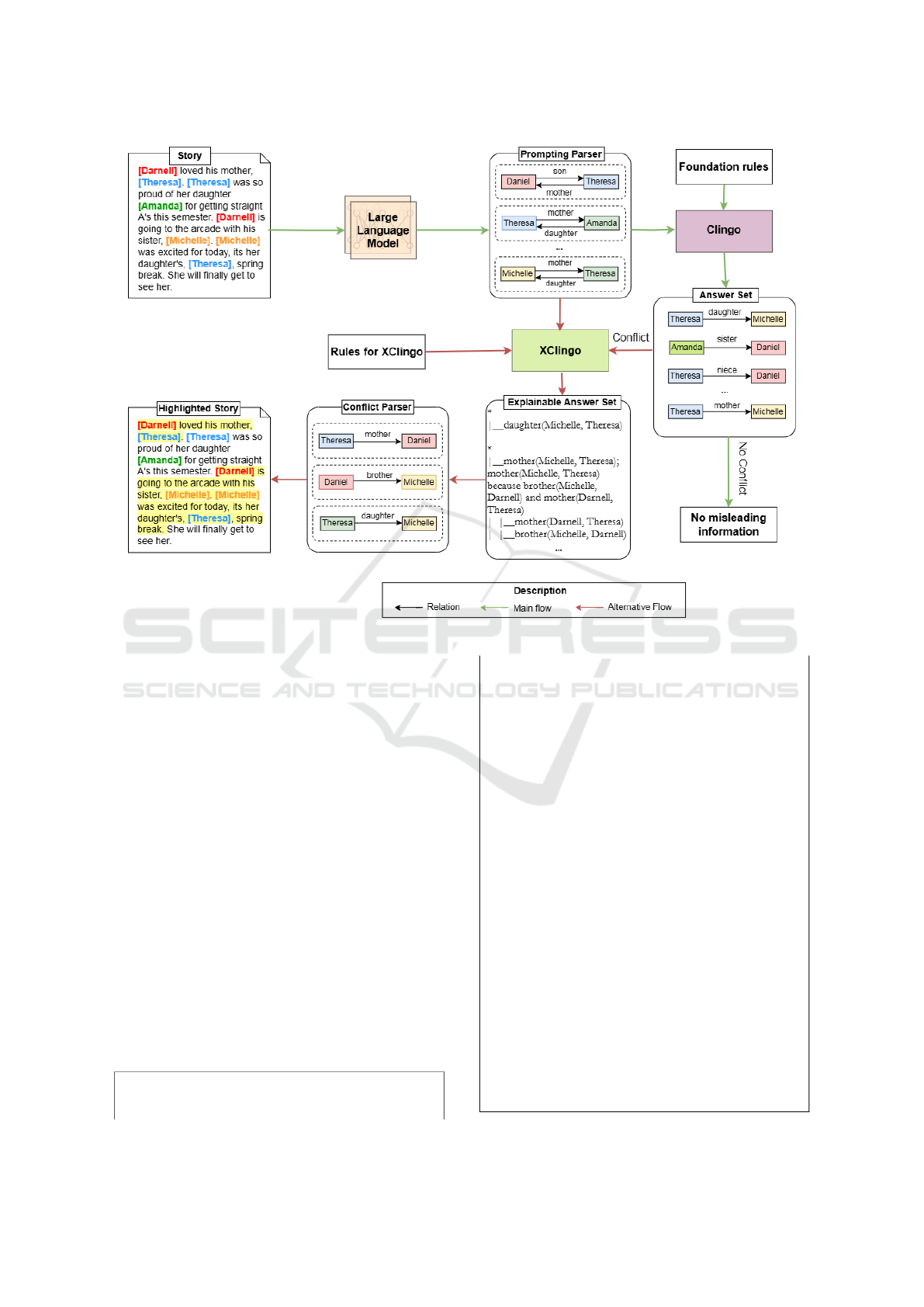
Figure 1: Overview of our framework.
3.1 Semantic Parsing with LLM
Before operating the ASP solvers (Clingo and
XClingo), we first extract atomic facts from a given
story to build a foundation for advanced decision-
making processes. To facilitate this, we deploy an
innovative approach we describe as the Prompting
Parser which integrates with GPT-4 (Achiam et al.,
2023) in a few-shot learning framework. Principally,
this parser is structured into two core components:
the narrative story which provides a rich, contex-
tual background in natural language, and the precise,
structured semantic parse which aims to distill the
narrative into formal logical statements.
Specifically, the process begins by feeding a de-
scriptive story into GPT-4, equipped with the capa-
bility to comprehend and interpret nuanced language
through its advanced language models. Following the
natural language input, our task is to enable the model
to transform this narrative into a set of succinct, log-
ical relations and entities which represent the core
facts and relationships embedded within the story.
Prompting Parser:
% Sample 1
Story:[Michelle] was excited for today, its
her daughter’s, [Theresa], spring break. She
will finally get to see her. [Michael] was
busy and sent his wife, [Marlene], instead.
[Kristen] loved to care for her newborn child
[Ronald]. [Eric]’s son is [Arthur].
Semantic Parse: daughter("Michelle",
"Theresa"). mother("Theresa", "Michelle").
wife("Michael", "Marlene"). hus-
band("Marlene", "Michael") child("Kristen",
"Ronald"), mother("Kristen", "Ronald").
son("Eric", "Arthur"), father("Arthur",
"Eric").
% Sample 2
Story:[Vernon] was present in the delivery
room when his daughter [Raquel] was born,
but when his daughter [Constance] was born
he was too sick. [Vernon] and his daughter
[Margaret] went to the movies.[Constance],
[Margaret]’s sister, had to stay home as she
was sick.
Semantic Parse: daughter("Vernon",
"Raquel"). father("Raquel", "Ver-
non"). daughter("Vernon", "Con-
stance"). father("Constance", "Ver-
non"). daughter("Vernon", "Margaret").
father("Margaret", "Vernon"). sis-
ter("Margaret", "Constance").
...
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1330

The story serves as the input context written in nat-
ural language. The semantic parser represents the
logical outcome that we aim for LLMs to generate.
For example, a logical form daughter(”Michelle”,
”Theresa”) means that Michelle has a daughter called
Theresa. Throughout the experimental process, we
have observed that LLMs demonstrate proficiency in
understanding natural language and converting it into
logical representations effectively. However, along-
side these strengths, it still exhibits some errors in
the process of generating logical representations, such
as syntactic errors and missing or redundant informa-
tion in each component. For cases where the parser
generates incorrect logical results, we iterate through
this step until we obtain the correct logical represen-
tations.
3.2 Collecting Answers with ASP
After obtaining the logical representations from the
“Semantic Parse”, we feed them into the ASP solver
Clingo (Gebser et al., 2019) built upon the prede-
fined correct rule set (called the set of foundation
rules) to infer a comprehensive list of all potential re-
lationships between individuals. A rule is constructed
from a head and two predicates with the form rela-
tion(”first people”, ”second people”). For instances,
a rule son(A, C) :- son(A, B), brother(B, C), A!=C. in-
dicates that if A has a son B, B has a brother C and A
is different from C then A also has a son C. Typically,
for stories with accurate, clear, and complete infor-
mation, there is only one unique relationship between
two individuals. However, if the story contains mis-
leading information, multiple relationships between
the two individuals may exist. Based on this idea, we
identify all questions with conflicting answers that in-
volve more than one relation between two distinct in-
dividuals. These questions are then analyzed to trace
the incorrect information within the story.
3.3 Using Explainable ASP for Error
Detection
In order to receive clear clarifications for the answers
responded by the ASP solver Clingo, an explain-
able system for ASP with the name XClingo (Ca-
balar et al., 2020) is used. To take advantage of
this extension, a rule set based on the original foun-
dation rules for XClingo is designed. Specifically,
trackable rules are set with !trace rule while trackable
atoms are combined with !track to write particular ex-
planations. The above information will be recorded
during the reasoning process to provide the answer.
The answer is then generated with !show trace com-
mand. For example, the rule son(A, C) :- son(A, B),
brother(B, C), A!=C. is converted to %!trace rule
{{”son(%, %) because son(%, %) and brother(%,
%)”, A, C, A, B, B, C}} son(A, C) :- son(A, B),
brother(B, C), A!=C. while the atom son(A, C). is
turned into %!trace ”son(%, %)”, A, C son(A, C)..
Then %!show trace son(A, C). is applied to ensure
that the answers with relation between 2 people is
son are presented. The integration of XClingo with
the logical forms in the semantic parser and the con-
structed rules results in output with a list of trees. An
example of a list of tree output from XClingo can be
seen below.
An example output of XClingo
*
| daughter(Michelle, Theresa)
*
| mother(Michelle, Theresa);mother(Michelle,
Theresa) because brother(Michelle, Darnell)
and mother(Darnell, Theresa)
| | mother(Darnell, Theresa)
| | brother(Michelle, Darnell)
*
| mother(Michelle, Theresa);mother(Michelle,
Theresa) because sister(Michelle, Amanda) and
mother(Amanda, Theresa)
| | mother(Amanda, Theresa)
| | sister(Michelle, Amanda);sister(Michelle,
Amanda) because brother(Michelle, Darnell)
and sister(Darnell, Amanda)
| | | sister(Darnell, Amanda);sister(Darnell,
Amanda) because mother(Darnell, Theresa) and
daughter(Theresa, Amanda)
| | | | daughter(Theresa, Amanda)
| | | | mother(Darnell, Theresa)
| | | brother(Michelle, Darnell)
...
As can be seen, the root of tree contains the an-
swers after a process of inference using rules and
symbols from the semantic parse. A node can be di-
vided into two types: inferred node and original node.
An inferred node consists of two parts: the main an-
swer with relation between people and the explana-
tion for generating this answer. This node also com-
prises two child nodes as the materials of creation.
The other type of node, or simply a leave, has no child
node and only has the main answer part. In particu-
lar, this node is directly obtained from the semantic
parse. Generally, all nodes are collected after the pro-
gression of leaves, hence the work of tracking back
to leaves can be implemented to explore the elements
that yield friction. Therefore, we propose an algo-
rithm (see Algorithm 1) to find leaves that raise con-
flicted main answers at root of trees in an attempt to
emphasize inaccurate components.
Detecting Misleading Information with LLMs and Explainable ASP
1331

Algorithm 1: Procedure for collecting conflict
leaves and main answers.
Data: List of trees T received from
XClingo; max length;
Result: List of conflict leaves L;
List of conflict main answer A;
List of conflict leaves L ← Ø;
List of conflict main answer A ← Ø;
T ← sorted trees T by height
if length of T ≥ max length then
find the first two distinct trees T [i], T [ j]
with conflict main answers at root
L ← leaves of T [i] and T [ j]
A ← main answers at root of T [i] and
T [ j]
else
find all two distinct trees T [i], T [ j] with
conflict main answers at root
L ← leaves of T [i] and T [ j]
A ← main answers at root of T [i] and
T [ j]
end
In Algorithm 1, a hyperparameter max length is
defined to prevent the process of methods from con-
suming a large amount of time and overloaded with
acquired data. In our experiments, this parameter is
set to 5000 to ensure that conflicts are gathered, as
well as duplicates and corruption are avoided.
After achieving a list of leaves causing opposing
main answer at root of trees, it is noticable that the
logical forms in the semantic parse which bring fail-
ure are also located. In addition, the symbols that do
not appear in the list of trackable entities for the ex-
plainable system are also gathered. We merge both
types of mentioned in the semantic parse to spot mis-
leading information in the given story. Indeed, the
story is split into an array of sentences, afterwards
sentences which contain both two people in a mis-
taken elements of the semantic parse are appended.
In case only one person appears in a sentence, the
following sentences are examined until the remaining
person is found. For each set of leaves, a set of corre-
sponding sentences is obtained. This set of sentences
is added to the final set of conflict sentences only if
there are no subsets (except an empty set) of this set
in the current array of conflict sentences. Moreover,
with the collection of conflict main answers at root,
the type of errors in the story can also be considered
such as conflict in relation between people, ambigu-
ous information or unknown gender.
4 EXPERIMENT
We tested the proposed method on the CLUTRR
dataset (Sinha et al., 2019). The following subsec-
tions illustrate the setting and results of our experi-
ment, respectively.
4.1 Experimental Setting
We use the CLUTRR dataset that consists of stories
related to hypothetical family relationships, aiming
to identify the connection between two family mem-
bers not directly mentioned (Sinha et al., 2019). Ad-
dressing this problem involves finding the contrary re-
lations between people and exploring misunderstood
information in stories.
To perform these tasks, we chose the CLUTRR
dataset’s supporting category where the stories con-
tain additional data beside main information for rea-
soning and predicting the relation between two dis-
tinct members, thus resulting in some cases of uncer-
tainty. The training data of this category comprises
5,107 samples which are thoroughly investigated to
realize any failures or errors in stories. Throughout
the experimental process, our method only applies
few-shot prompting and does not involve training.
Starting with the natural language to logic conversion
phase, the GPT-4 model is leveraged with max tokens
of 4096 to recognize verbal context and generate
structured output from few-shot learning. In the next
step, a state-of-the-art ASP solver Clingo (Gebser
et al., 2019) (version 5.7.1) is employed with default
reasoning mode to optimize the inference process.
Since the results of Clingo are plain answers of re-
lation between family members, an external system
XClingo (version 2.0b12) is used to trace the path of
reasoning. To prevent Xclingo’s explanations from
falling into an infinite loop, we are currently limiting
the number of trees returned in output to 100000. All
experiments were conducted in a Conda environment
in Ubuntu for convenient and efficient implementa-
tion.
4.2 Experimental Results
Since all the reasons leading to an answer must be
returned, runtime when using Xclingo increases sig-
nificantly compared to utilizing Clingo alone. In the
worst case with the above settings, the time to com-
plete processing a sample is about 10 minutes, signif-
icantly slower when using only Clingo at 0.08 sec-
onds. After performing several experiments, mislead-
ing information in the story is identified with red high-
lights while their types of errors are also divided. In
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1332

the 5,107 samples, 815 were found to have conflicts
in relation between individuals in an answer set re-
sponded by Clingo. Some instances and their related
errors are illustrated below.
Conflict in relations between family members
Story: [Darnell] loved his mother,
[Theresa]. [Theresa] was so proud of her
daughter [Amanda] for getting straight A’s
this semester. [Darnell] is going to the ar-
cade with his sister, [Michelle]. [Michelle]
was excited for today, its her daughter’s,
[Theresa], spring break. She will finally
get to see her.
Conflict Parse: mother(Darnell, Theresa),
brother(Michelle, Darnell), daugh-
ter(Michelle, Theresa)
Conflict Answer: mother(Michelle, Theresa),
daughter(Michelle, Theresa)
In this case, it is clearly observed that Darnell has
a mother whose name is Theresa and a sister called
Michelle. With simple inference, we can conclude
that Michelle is the daughter of Theresa. However,
the given context points out that Theresa is Michelle’s
daughter giving contrast in the relation between two
family members.
Unclear gender
Story: [Vernon] took his brother [Henry] out
to get drinks after a long work week. [Ver-
non] and his sister [Robin] went to brunch
today at the new diner. [Henry] is taking
his daughter [Verdie] out for lunch at her
favorite restaurant. [Robin] was playing in
the sandbox with her brother [Henry].
Conflict Parse: sister(Vernon, Robin),
brother(Henry, Vernon), sister(Robin, Vernon)
Conflict Answer: brother(Robin, Vernon),
sister(Robin, Vernon)
In this instance, it is noticable that the issue of un-
known gender happened with Vernon. As a result,
during the parsing and reasoning phases, dividing this
person to male or female is unclear. The conflict an-
swer yields the result that Robin can also have a sister
or a brother whose name is Vernon, which does not
meet the requirement to find only one connection be-
tween two different family members.
Reflexive relationship
Story: [Eddie] and his sister [Amanda] got
their mother [Amanda] a new computer for her
birthday. She really liked it. [Amanda]’s
father is named [Henry]. [Henry] is taking
his son [Eddie] on a camping trip for the
weekend. [Henry] went to the store with his
brother [Vernon].
Conflict Parse: brother(Eddie, Amanda),
mother(Eddie, Amanda)
Conflict Answer: brother(Eddie, Amanda),
mother(Eddie, Amanda)
The story contains a fatal error when Amanda
has a mother-daughter relationship with herself. This
mistake also leads to misunderstanding and failure
when convert natural language to logical forms. In
particular, the generative model has encountered con-
ference and inferred that Amanda is a brother of Ed-
die, which is opposite from the correct relation.
Ambiguous information
Story: [Ronald] was visiting his grandpar-
ents’ house and saw [Karen] first. [Kris-
ten], [Patty]’s mother, was eager to plan
a trip with her so she asked her brother,
[Ronald], for advice. [Kristen] liked to
play hide and seek with her son [Ronald].
Conflict Parse: mother(Ronald, Kristen),
sister(Ronald, Kristen)
Conflict Answer: mother(Ronald, Kristen)’,
’sister(Ronald, Kristen)
In this sample, the author has already emphasized
that Ronald is Kristen’s son. Similarly, Kristen is also
the mother of Patty in the given context. Therefore,
Ronald is the brother of Patty. However, with am-
biguous illustration in the story, Ronald becomes the
brother of Kristen rather than Patty, causing a serious
conflict in the relationship between distinct people.
5 LIMITATIONS AND
DISCUSSIONS
This study proposes a novel framework coupling
LLMs with ASP to identify misleading information.
While the results are promising and show relevant im-
provements in certain issues, there are several limita-
tions and concerns needed to be considered for future
research and applications.
Performance and Efficiency. As the input data be-
come more complicated and numerous, the compu-
tational cost for the parsing phase using LLMs may
exponentially increase. Similarly, the results from the
ASP solver and its explainable extension can be over-
loaded, leading to waste of resources, decrease in pro-
gram quality. Besides, recursive rules can cause an in-
finite number of tree construction making the program
less efficient and on the verge of collapse. Alternative
strategies to manage computational resources should
be made to prevent the failure of system.
Restricted Rule Set. One problem regarding the
scability of this system is that foundation rules for the
Detecting Misleading Information with LLMs and Explainable ASP
1333

ASP solver and also its explainable extension are de-
fined depending on specific input data and expected
output. Therefore, for different datasets with seper-
ated targets, compatible rule sets have to be recon-
structed. In general, this work still demands on the
control of human and has not yet been automated.
Perspectives. Further research is needed to address
the above limitations comprehensively varying from
applying optimization techniques to handle the us-
age of computational resources to building generative
rules system. Moreover, based on the proposal of this
study, new development in solving logical reasoning
tasks in natural language can be conversed. One pos-
sible work is to eliminate errors in verbal context with
the advancements of LLMs and ASP.
6 CONCLUSION
This study introduces an innovative methodology
for detecting misleading information by integrating
Large Language Models (LLMs) with explainable
Answer Set Programming (ASP). The synergy be-
tween the contextual understanding capabilities of
LLMs and the reasoning and explanatory potential of
explainable ASP has demonstrated the effectiveness
in identifying misleading information that can cause
confusion and significantly affect the accuracy of re-
sponses. It makes a substantial contribution to the
advancement and refinement of reliable AI question-
answering systems.
REFERENCES
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I.,
Aleman, F. L., Almeida, D., Altenschmidt, J., Altman,
S., Anadkat, S., et al. (2023). GPT-4 technical report.
arXiv preprint arXiv:2303.08774.
Bauer, J. J., Eiter, T., Ruiz, N. H., and Oetsch, J. (2023).
Neuro-symbolic visual graph question answering with
LLMs for language parsing. In Proc. of TAASP 2023.
Brown, T. B. (2020). Language models are few-shot learn-
ers. arXiv preprint arXiv:2005.14165.
Cabalar, P., Fandinno, J., and Mu
˜
niz, B. (2020). A system
for explainable answer set programming. In Proc. of
ICLP, pages 124–136.
Calimeri, F., Ianni, G., and Ricca, F. (2014). The third open
answer set programming competition. Theory Pract.
Log. Program., 14(1):117–135.
Eiter, T., Ianni, G., and Krennwallner, T. (2009). Answer set
programming: A primer. Springer.
Erdem, E., Gelfond, M., and Leone, N. (2016). Applica-
tions of answer set programming. AI Mag., 37(3):53–
68.
Gebser, M., Kaminski, R., Kaufmann, B., and Schaub, T.
(2019). Multi-shot ASP solving with clingo. Theory
Pract. Log. Program., 19(1):27–82.
Gelfond, M. and Lifschitz, V. (1988). The stable model se-
mantics for logic programming. In Proc. of ICLP/SLP,
pages 1070–1080. Cambridge, MA.
Ishay, A., Yang, Z., and Lee, J. (2023). Leveraging large
language models to generate answer set programs.
arXiv preprint arXiv:2307.07699.
Kheiri, K. and Karimi, H. (2023). SentimentGPT: Exploit-
ing GPT for advanced sentiment analysis and its de-
parture from current machine learning. arXiv preprint
arXiv:2307.10234.
Liga, D. and Robaldo, L. (2023). Fine-tuning GPT-3 for
legal rule classification. Comput. Law Secur. Rev.,
51:105864.
Marriott, K. and Stuckey, P. J. (1998). Programming with
constraints: an introduction. MIT press.
McCarthy, J. (1959). Programs with common sense.
Nguyen, H.-T., Fungwacharakorn, W., and Satoh, K.
(2023a). Enhancing logical reasoning in large lan-
guage models to facilitate legal applications. arXiv
preprint arXiv:2311.13095.
Nguyen, H.-T., Goebel, R., Toni, F., Stathis, K., and Satoh,
K. (2023b). How well do SOTA legal reasoning
models support abductive reasoning? arXiv preprint
arXiv:2304.06912.
Phi, M., Nguyen, H., Bach, N. X., Tran, V. D., Nguyen,
M. L., and Phuong, T. M. (2020). Answering legal
questions by learning neural attentive text representa-
tion. In Proc. of COLING, pages 988–998. Interna-
tional Committee on Computational Linguistics.
Rajasekharan, A., Zeng, Y., Padalkar, P., and Gupta, G.
(2023). Reliable natural language understanding with
large language models and answer set programming.
arXiv preprint arXiv:2302.03780.
Sinha, K., Sodhani, S., Dong, J., Pineau, J., and Hamilton,
W. L. (2019). CLUTRR: A diagnostic benchmark for
inductive reasoning from text. In Proc. of EMNLP-
IJCNLP, pages 4505–4514. Association for Compu-
tational Linguistics.
Trinh, G. V., Benhamou, B., Pastva, S., and Soliman,
S. (2024). Scalable enumeration of trap spaces in
Boolean networks via answer set programming. In
Proc. of AAAI, pages 10714–10722. AAAI Press.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, L., and Polosukhin, I.
(2017). Attention is all you need. In Proc. of NeurIPS,
pages 5998–6008.
Yang, Z., Ishay, A., and Lee, J. (2023). Neurasp: Embracing
neural networks into answer set programming. arXiv
preprint arXiv:2307.07700.
Zin, M. M., Nguyen, H., Satoh, K., Sugawara, S., and
Nishino, F. (2023). Information extraction from
lengthy legal contracts: Leveraging query-based sum-
marization and GPT-3.5. In Proc. of JURIX, pages
177–186. IOS Press.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1334
