
Development of a Context-Free Data Ingestion Mechanism for AutoML
Gabriel Mac’Hamilton
a
and Alexandre M. A. Maciel
b
Universidade de Pernambuco, Recife, Brazil
Keywords:
Data Ingestion, AutoML, Machine Learning, Human-Computer Interaction.
Abstract:
Automated Machine Learning (AutoML) is a technology that simplifies complex data processing and analysis
for strategic decision-making by automating machine learning tasks and enhancing the user experience. Data
ingestion is a crucial AutoML step that involves collecting external data for machine learning workflows. Typ-
ically, AutoML systems include data input modules. However, the lack of a user interface limits the number
of users that can utilize it. This work presents the development of a data ingestion mechanism that stream-
lines and simplifies this machine learning stage into an AutoML framework called FMD. The mechanism
underwent three validations: Experimentation in a real-world scenario with two databases from different con-
texts, evaluation from expert opinions, and usability assessment through a questionnaire using the AttrakDiff
method. Following the validations, successful results were achieved in both assessments and in demonstrating
the ingestion in various contexts.
1 INTRODUCTION
Amidst an increasingly complex environment, where
the shortage of data scientists becomes more evident
in the face of high market and academy demands, Au-
toML systems emerge as a strategic solution for or-
ganizations. These systems can reduce the complex-
ity of the model building and optimization processes
(Hutter et al., 2019). In this context, AutoML is not
just a response to human resource limitations but also
a strategy to optimize the potential of available data,
accelerate model development cycles, and democra-
tize data science within organizations while also al-
lowing domain experts to work directly with machine
learning development (Elshawi et al., 2019).
Data ingestion is of crucial relevance in data sci-
ence, serving the purpose of consistently and reliably
introducing data into the machine learning pipeline
(Hapke and Nelson, 2020). According to studies, data
wrangling activities, encompassing ingestion, clean-
ing, and data transformation, consume about 70%
of data scientists’ time (Saurav and Schwarz, 2016).
This underscores the significance of simplifying data
ingestion for AutoML systems, as it helps reduce time
and effort in this workflow phase. Such simplification
allows users to dedicate more time to metadata prepa-
ration and model refinement activities, contributing to
a
https://orcid.org/0000-0002-3735-190X
b
https://orcid.org/0000-0003-4348-9291
increased efficiency in machine learning teams (Patel,
2020).
Given the context, this work presents a data in-
gestion mechanism to alleviate the problems related
to the early stages of machine learning practices, do-
main understanding, and feature engineering. The
mechanism proposes a standardized and simplified
way to ingest data, using a metadata file called “con-
text file”, to help with transforming domain experts’
tacit knowledge into explicit knowledge, allowing for
better feature selection, allied with a robust data in-
gestion engine based on the ETL (extract, transform
& load) process, and a simple and intuitive user inter-
face (UI).
2 BACKGROUND
2.1 AutoML
AutoML is broadly defined in the literature and
commonly describes systems that automate machine
learning activities. These systems were motivated
by the need to address the limitations and challenges
posed by traditional machine learning techniques.
These challenges include requiring highly specialized
professionals in model development, dependence on
domain experts’ knowledge tied to a particular model,
and introducing human biases, making the models in-
Mac’Hamilton, G. and Maciel, A. M. A.
Development of a Context-Free Data Ingestion Mechanism for AutoML.
DOI: 10.5220/0013357700003929
In Proceedings of the 27th International Conference on Enterprise Information Systems (ICEIS 2025) - Volume 2, pages 581-588
ISBN: 978-989-758-749-8; ISSN: 2184-4992
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
581

efficient. AutoML systems can expedite the develop-
ment of machine learning models, ensure greater opti-
mization, and democratize access to data science for a
broader and less specialized audience (Nagarajah and
Poravi, 2019). In summary, AutoML aims to find an
optimized solution for machine learning applications
(Chen et al., 2021).
AutoML systems can automate any stage of ma-
chine learning model development. However, accord-
ing to (Hutter et al., 2019), most systems focus on
preprocessing and model tuning, emphasizing hyper-
parameter optimization, meta-learning, and neural ar-
chitecture search. The authors also highlight several
advantages of using a system that automates these ac-
tivities, such as reducing human effort in model devel-
opment, improving algorithm performance, enhanc-
ing reproducibility in academic work, and facilitating
the reuse of successful models.
2.2 Data Ingestion
The data ingestion is primarily characterized by ob-
taining and transporting data from an external source
to the machine learning workflow. Organizations typ-
ically employ this process to optimize data collection,
improve data quality and accuracy, and save time and
resources. Through the use of data ingestion tech-
niques, it is possible to reduce costly errors in the data
collection stage (Hapke and Nelson, 2020).
The main goal of this process is to capture, store,
and make data available for future use. Among the
methods found in the literature for developing data in-
gestion, we can highlight batch and streaming. Batch
data ingestion is usually performed through ETL (Ex-
tract, Transform & Load) routines that collect data
from an external source, incorporate it into the work-
flow, or store it for later use. The batch technique
is employed for data that does not need to be con-
sumed in real time. Streaming data ingestion, on the
other hand, is used in cases where there is a need for
real-time data consumption, requiring specific tech-
nologies to support this type of demand (Hlupic and
Punis, 2021).
2.3 Software Usability
The graphic interface design of software can deter-
mine the success or failure of a product. A tool needs
a user-friendly interface to gain user approval and
may be replaced by competing options. Therefore,
the application of efficient user experience (UX) and
user interface (UI) techniques is highly relevant, al-
lowing the development of a valuable system for users
(Tidwell et al., 2020).
The efficiency of a UI depends on its intuitive-
ness and ease of use. Intuitive software is designed to
be familiar, with recognizable components and pre-
cise interactions, enabling users to apply their prior
knowledge and use the interface seamlessly. Due
to the need for this familiarity, design patterns are
encouraged, allowing users to easily recognize the
functionalities displayed in interfaces (Tidwell et al.,
2020). In addition to interface familiarity, the over-
all user experience is a relevant factor in software
development. UX is about the visual interface and
how users perceive, interpret, and interact with a sys-
tem. Whalen (2019) emphasizes the need to consider
cognitive psychology, thinking patterns, and user ex-
pectations when creating effective designs (Whalen,
2019).
2.4 Data Mining Framework - FMD
The Data Mining Framework - FMD is an AutoML
system originally developed in 2017 at the University
of Pernambuco through various academic works. This
achievement is due to its nature as an open-source
software, which has been enhanced through multiple
projects over time.
The project was initially conceived to enable data
mining in virtual learning environments (VLE), with
the goal of democratizing data mining activities for
users with limited technical knowledge in this field.
It was initially named as Visual Educational Data
Mining Framework - FMDEV, later being changed to
simply Data Mining Framework - FMD. The frame-
work allowed data mining from the Moodle VLE
1
with just a few clicks, providing data analytics and
visual graphs to users. The project was developed
using technologies such as Hypertext Markup Lan-
guage (HTML), Cascading Style Sheets (CSS), and
JavaScript, and was integrated into Moodle as an
HTML block (Gonc¸alves et al., 2017). The initial ar-
chitecture of FMD is represented in Figure 1.
The work of (da Silva, 2020) enhanced the project,
leading to its current state with a more robust architec-
ture, updated technologies, new functionalities, and
a user-friendly interface. The project underwent a
refactoring process using Lean Inception techniques
and requirements engineering, along with a technol-
ogy survey through an systematic literature review
(SLR). This allowed the development of a more re-
fined architecture based on the original design. At this
moment, the project transitioned from being a data
mining framework to becoming an AutoML frame-
work, capable of performing automated supervised
1
https://moodle.org/
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
582

machine learning tasks and presenting the results vi-
sually, using data related to the educational context.
Figure 1: FMD original architecture.
2.5 Related Work
This section presents a comparative analysis of open-
source AutoML tools in the market, focusing on us-
ability and data ingestion. Specifically, it examines
functionalities identified as essential by (Alves and
Maciel, 2023). To select the AutoML tools for com-
parison, those in the work of (Z
¨
oller and Huber,
2021) were considered based on their number of ci-
tations and stars on GitHub. The five frameworks se-
lected for benchmarking were: TPOT
2
, hpsklearn
3
,
auto-sklearn
4
, H2O AutoML
5
, and ATM
6
(Auto Tune
Models).
Table 1 compares this project regarding data in-
gestion with the five most relevant open-source Au-
toML tools. Observing the table, it becomes evident
that, due to their nature being run from the command
line, TPOT, auto-sklearn, hpsklearn, and ATM lack
most of the functionalities described as necessary for
easy data ingestion. Being the only one with a graph-
ical interface, H2O AutoML has the most functionali-
ties. However, the interface primarily focuses on Au-
toML rather than data ingestion, and data input is lim-
ited to data files only. The FMD Data Ingestor stands
out as it was developed with a specific focus on the
most relevant functionalities outlined in the literature
for data ingestion, allowing data input through files or
database connections but lacking metadata inference.
This absence is mitigated by the “context mapping”
functionality, which pre-provides the necessary meta-
2
https://epistasislab.github.io/tpot/
3
https://hyperopt.github.io/hyperopt-sklearn/
4
https://github.com/automl/auto-sklearn
5
https://h2o.ai/
6
https://hdi-project.github.io/ATM/
data for specific datasets.
Table 1: AutoML Frameworks Benchmark.
Framework User Data Multiple data Metadata
InterfaceVisualization inputs Inference
FMD Yes Yes Yes No
TPOT No No Yes No
hpsklearn No No Yes No
auto-sklearn No No Yes No
H2O AutoML Yes Yes No Yes
ATM No No Yes No
3 METHODOLOGY
The project’s requirements gathering was conducted
using Design Science Research (DSR) (Aken, 2004)
techniques combined with lean inception (Caroli,
2018) and traditional methods of software require-
ments documentation. Several meetings were held
with project stakeholders for brainstorming and arti-
fact validation, such as user journeys, mockups, and
prototypes. Two personas were considered for defin-
ing functionalities: the domain expert and the data
scientist.
Given that the developed project is premised on
integration with an existing AutoML solution, the
FMD, the new project architecture must complement
the one previously used. Thus, a new layer of data
ingestion and processing was added to the original ar-
chitecture defined by (da Silva, 2020). The project
utilizes Javascript for the frontend layer and Python
for the backend layer, with an additional data inges-
tion layer managed by the Pentaho Data Integration
Community Edition
7
(PDI-CE) platform, invoked by
the backend. A visual representation of the project
architecture is presented in Figure 2.
The developed platform presents two distinct and
complementary workflows: the “context file” regis-
tration and the data source registration as presented
on Figure 3. A “context file” is represented by a
JSON-format file and contains the necessary meta-
data for analyzing data from a specific domain. There
are two options for data source registration: one for
registering data sources from CSV files and another
for connecting to a PostgreSQL, MySQL, or Oracle
database. After completing the data source registra-
tion, the data ingestion begins automatically.
7
https://www.hitachivantara.com/en-
us/products/pentaho-plus-platform/data-integration-
analytics/pentaho-community-edition.html
Development of a Context-Free Data Ingestion Mechanism for AutoML
583

Figure 2: Project architecture.
Figure 3: Project workflow.
4 RESULTS
4.1 Data Ingestion Interface for
AutoML
Following the developed and validated prototypes, a
graphical user interface for data ingestion was cre-
ated. According to the project workflow, described
in Section 3, screens were developed for uploading
“Context Files” and for configuring data ingestion.
Figure 4 presents a screen for registering and up-
loading the context file by a Domain Expert user.
After the upload, the transformation json storage.ktr
(Figure 5) is executed, which loads the “Context File”
into the project’s Data Lake, making it available for
selection in the data ingestion configuration area. Be-
sides the upload, the user can also edit the context on
the screen.
Figure 4: User Interface for context file upload.
Figure 5: Transformation json storage.ktr viewed at the vi-
sual interface of the PDI-CE.
Figure 6 represents the main screen for registering
datasets, where the user will configure data ingestion
in two steps, in a wizard interface format that repre-
sents a step-by-step guide for easy configuration.
Figure 6: User Interface for the Data Ingestion Configura-
tion.
After the configuration, a series of transforma-
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
584
tions are executed in the backend, which collect the
registered information, gather the data, and execute
the data ingestion into the project’s Data Lake. By
default, the data is stored in CSV format for bet-
ter interaction with the AutoML platform; therefore,
data transformations are required if it originates from
a database connection, performed by the PDI. The
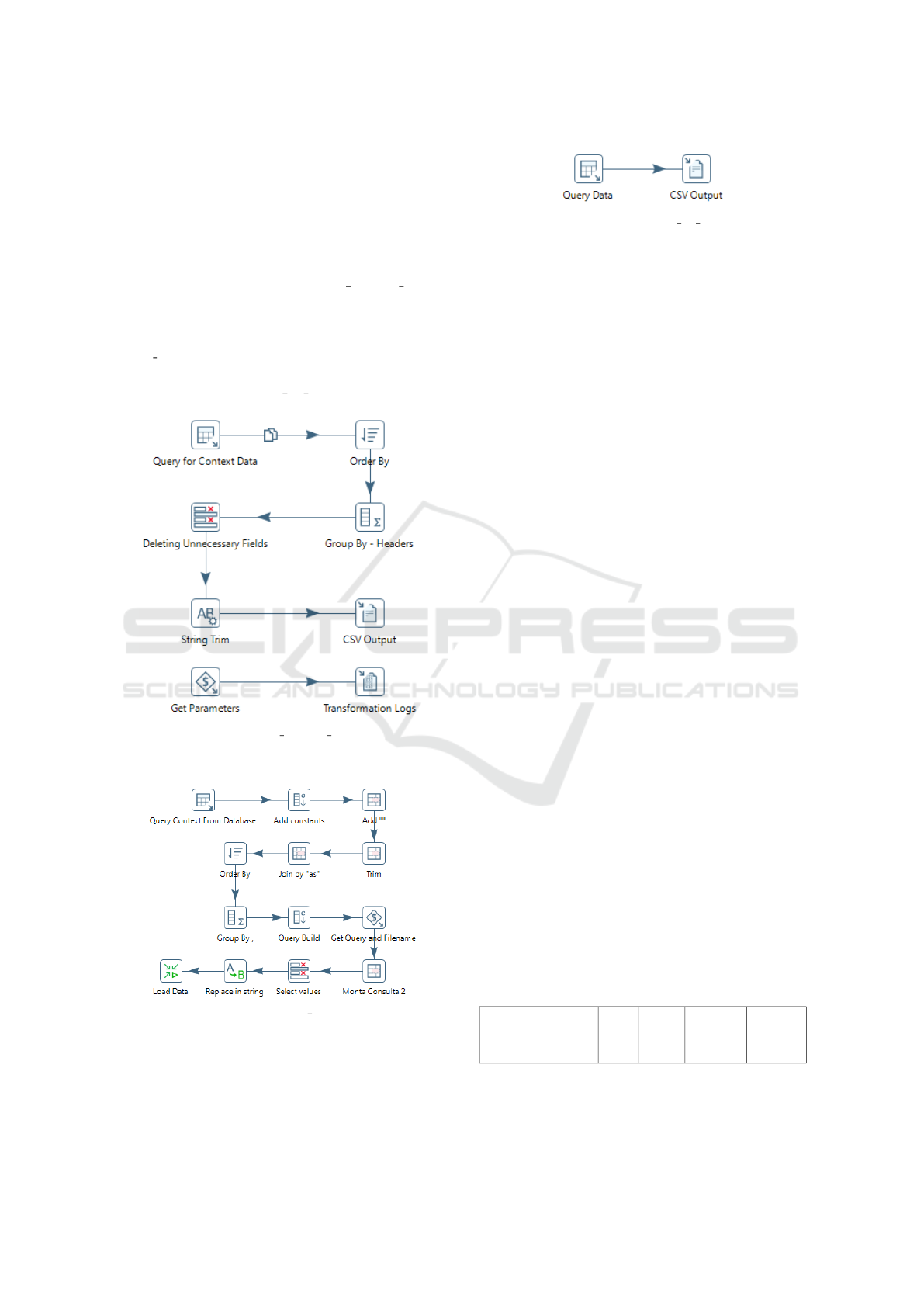
first transformation executed is cria headers csv.ktr
(Figure 7) that generates the CSV metadata for the
data file produced at the end of the process. Next,
the database data collection transformation, called in-
gestor bd.ktr (Figure 8), is executed, and finally, the
data is loaded into the Data Lake in CSV format by
the transformation ingestor bd carga.ktr (Figure 9).
Figure 7: Transformation cria headers csv.ktr viewed at the
visual interface of the PDI-CE.
Figure 8: Transformation ingestor bd.ktr viewed at the vi-
sual interface of the PDI-CE.
Figure 9: Transformation ingestor bd carga.ktr viewed at
the visual interface of the PDI-CE.
4.2 Data Ingestion in a Real-World
Scenario
Three context files were created to demonstrate data
ingestion capabilities with different data contexts.
These contexts are based on existing work in the lit-
erature that shows the best features for analyzing spe-
cific themes. The themes were: breast tumor classifi-
cation using the six most important attributes, breast
tumor classification using the ten most important at-
tributes, and analysis of student engagement in virtual
learning environments.
The two breast cancer contexts were used to
demonstrate the ability to use various contexts with
the same database; they were also added to the plat-
form through a database connection. The engagement
dataset, which was ingested into the platform from
a CSV file, demonstrated the platform’s capacity to
work with widely different contexts (education and
health).
The definition of the two contexts related to breast
cancer was based on the work of (Ray et al., 2020),
which aimed to analyze the best characteristics of the
analysis of breast cancer cells to determine whether
they are malignant or benign. The same dataset used
in that work, the Wisconsin Diagnosis Breast Can-
cer dataset (WDBC), containing 573 instances, was
used for data ingestion. The definition of the engage-
ment context was inspired by (H. R. Mac
ˆ
edo et al.,
2021), which sought to determine the most relevant
data for analyzing student engagement profiles in vir-
tual learning environments. The engagement dataset
was provided by Research Group in Data Science
and Analytics (GPCDA), which comprised 30,217 in-
stances. After data ingestion and AutoML execution,
the results are shown in Table 2, being (I) Top 6 fea-
tures for Breast Cancer context, (II) Top 10 features
for Breast Cancer context and (III) Features for stu-
dents engagement context.
Table 2: Performance Metrics Results.
Context Accuracy AUC Recall Precision F1 Score
(I) 0.91 0.96 0.93 0.93 0.93
(II) 0.93 0.99 0.91 0.99 0.95
(III) 0.94 0.99 0.92 0.94 0.94
The AutoML system provided the most adequate
metrics for classification models. Analyzing the re-
Development of a Context-Free Data Ingestion Mechanism for AutoML
585

sults, we can conclude that the feature selection based
on the context file produced satisfactory values. All
models performed very well, with high accuracy,
AUC, precision, recall, and F1 score, indicating ro-
bust predictive ability.
4.3 Usability Assessment
An opinion survey was conducted through a form to
assess the user experience when using the Data Min-
ing Framework, specifically the data ingestion func-
tionality. The questionnaire questions were based on
the AttrakDiff method proposed by (Hassenzahl et al.,
2000), commonly used in academia to validate us-
ability and system quality aspects from the user’s per-
spective. The survey consists of 28 pairs of opposing
words that are used to describe the system in question.
Respondents are required to choose the most appro-
priate description of the system on a scale from -3 to
3.
The study was conducted with 20 technology pro-
fessionals with various levels of education, ranging
from undergraduates (incomplete higher education)
to professionals with a master’s degree. This range
of participants’ knowledge levels allowed for the col-
lection of information from both specialists and non-
specialists in the field of data science from a sample
of 20 participants.
As shown in Figure 10, users classified the data
ingestion mechanism into two categories: “desired”
and “task-oriented”. When classified as ”desired,”
the software likely provides users with a pleasant,
aesthetically appealing, and emotionally satisfying
experience. This suggests that users positively re-
spond to the software’s design, aesthetics, and sensory
experience. Additionally, being classified as ”task-
oriented,” as presented in Figure 11, implies that the
software is perceived as efficient, functional, and suit-
able for fulfilling the specific tasks for which it was
designed. This demonstrates that users view the soft-
ware as useful, practical, and aligned with their func-
tional needs. This is a favorable position, representing
a positive balance between the pragmatic and hedonic
aspects of the system.
Figure 10: Portfolio of results.
Figure 11: Diagram of average values.
4.4 Expert Opinion Evaluation
Research projects in software engineering often em-
ploy the expert opinion method (Garcia, 2010), as
scientific development in software engineering has
many peculiarities to evaluate the quality of the de-
veloped product. However, there are still divergent
opinions on using this methodology, as there is no
universally accepted framework to deal with expert
opinions (Ming Li and Smidts, 2003).
The evaluation process comprised four stages in-
spired by those outlined by (Garcia, 2010). The first
stage involved selecting experts based on credibility,
technical knowledge, and availability. Next, opin-
ion elicitation took place by introducing the system
to the experts and providing a questionnaire for them
to describe their considerations. The third stage in-
volved opinion aggregation, where the overall con-
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
586

sensus regarding the obtained responses was assessed.
Finally, results analysis was conducted by examining
the questionnaire responses.
Analyzing the questionnaire responses provides
valuable insights into the relevance of the developed
platform and the research area. Based on expert opin-
ions, the functionalities were successfully validated,
although the tool has room for improvement in fu-
ture developments. The highlighted benefits include
greater convenience in the ingestion process, a shorter
learning curve compared to similar platforms, and
the potential for use in different contexts. Addition-
ally, it was emphasized that the framework is suit-
able for meeting the needs of both technical and non-
technical users. As for improvements, suggestions in-
clude adding new inputs for structured and unstruc-
tured data and options for responsiveness, accessibil-
ity, and internationalization of the platform.
5 CONCLUSION
This work presented the development of a data in-
gestion mechanism customized for AutoML systems,
considering their peculiarities and those of their users.
The project placed a strong emphasis on the personas
identified during the Lean Inception process, guiding
the entire development process. For this purpose, the
data ingestion mechanism was created and integrated
with an AutoML, named the ”Data Mining Frame-
work.” This mechanism enables data input through a
simple interface, from generic CSV files and database
connections, mapping data contexts.
In terms of usability, various techniques related to
the lean inception process were applied to optimize
the development of the data ingestion, ensuring that
users can perform this machine learning step with
a low learning curve. To validate the findings and
ensure research reliability, this aspect was assessed
through an opinion survey with computer engineer-
ing students, along with the expert opinion elicitation
process. The survey results confirmed the relevance
and effectiveness of the project’s identified function-
alities, providing a good user experience with a lower
learning curve compared to other tools used for the
same purpose and the potential for use in different
contexts.
Regarding computational intelligence, the project
contributes with the development of a data inges-
tion module for automated machine learning systems,
aiming at democratizing data science. The platform
allows storing and transforming the tacit knowledge
of business area experts into explicit knowledge, as-
sisting in the engineering and selection of ideal at-
tributes for applying machine learning techniques in
a specific context. It is essential to highlight the stan-
dardization of the data ingestion process and the pre-
sentation of an optimized way to input data into the
machine learning workflow.
In summary, from a technical point of view, the
proposed data ingestion mechanism introduces inno-
vations by automating and simplifying the prepro-
cessing phase, which is often a bottleneck in Au-
toML workflows. Unlike traditional ingestion tools
that require extensive manual intervention, the de-
veloped module allows users to access and lever-
age previously configured domain knowledge within
the platform, enabling more informed data prepro-
cessing and feature selection. This approach en-
hances the reproducibility of data pipelines by embed-
ding provenance tracking and validation mechanisms,
ensuring consistency in model training. These ad-
vancements contribute to reducing the effort required
from users, making AutoML adoption more accessi-
ble while maintaining data integrity and reliability.
6 FUTURE WORK
In terms of future work, several areas stand out for en-
hancing the Data Ingestor. Based on expert opinions,
the following future improvements have been identi-
fied:
• Expand the data ingestion capabilities to new for-
mats of structured data, such as other database
management systems (DBMS) or file formats like
XML, JSON, and XLS;
• Expand the data ingestion capabilities to unstruc-
tured data, such as images and PDF files;
• Add regionalization functionalities that will en-
able international contributions to the tool’s de-
velopment, as it is open source;
• Include accessibility functionalities, allowing us-
age by a broader range of users;
ACKNOWLEDGEMENTS
This paper was financed in part by the Coordenac¸
˜
ao
de Aperfeic¸oamento de Pessoal de N
´
ıvel Superior -
Brazil (CAPES) - Finance Code 001, Fundac¸
˜
ao de
Amparo a Ci
ˆ
encia e Tecnologia do Estado de Pernam-
buco (FACEPE), the Conselho Nacional de Desen-
volvimento Cient
´
ıfico e Tecnol
´
ogico (CNPq) - Brazil-
ian research agencies.
Development of a Context-Free Data Ingestion Mechanism for AutoML
587

REFERENCES
Aken, J. E. (2004). Management research based on the
paradigm of the design sciences: The quest for field-
tested and grounded technological rules. Journal of
Management Studies, 41(2):219–246.
Alves, G. M. R. and Maciel, A. M. A. (2023). Survey on
Data Ingestion for AutoML (S). In Proceedings of
the International Conference on Software Engineering
and Knowledge Engineering, pages 411–414.
Caroli, P. (2018). Lean Inception: como alinhar pessoas e
construir o produto certo. Editora Caroli.
Chen, Y.-W., Song, Q., and Hu, X. (2021). Techniques for
Automated Machine Learning. ACM SIGKDD Explo-
rations Newsletter, 22(2):35–50.
da Silva, R. (2020). Desenvolvimento de uma Soluc¸
˜
ao
de Aprendizado de M
´
aquina Automatizado Integr
´
avel
a M
´
ultiplos Ambientes Virtuais de Aprendizagem.
Master’s thesis, Universidade de Pernambuco, Recife.
Elshawi, R., Maher, M., and Sakr, S. (2019). Automated
Machine Learning: State-of-The-Art and Open Chal-
lenges. arXiv:1906.02287 [cs, stat].
Garcia, V. C. (2010). RiSE reference model for software
reuse adoption in brazilian companies.
Gonc¸alves, A. F., Maciel, A. M., and Rodrigues, R. L.
(2017). Development of a data mining education
framework for visualization of data in distance learn-
ing environments. International Conferences on Soft-
ware Engineering and Knowledge Engineering.
H. R. Mac
ˆ
edo, P., B. Santos, W., and M. A. Maciel, A.
(2021). An
´
alise de Perfis de Engajamento de Estu-
dantes de Ensino a Dist
ˆ
ancia. RENOTE, 18(2):326–
335.
Hapke, H. and Nelson, C. (2020). Building Machine Learn-
ing Pipelines: Automating model life cycles with ten-
sorflow. O’Reilly Media, Sebastopol, CA.
Hassenzahl, M., Platz, A., Burmester, M., and Lehner, K.
(2000). Hedonic and ergonomic quality aspects de-
termine a software’s appeal. In Proceedings of the
SIGCHI conference on Human Factors in Computing
Systems, pages 201–208, The Hague The Netherlands.
ACM.
Hlupic, T. and Punis, J. (2021). An Overview of Cur-
rent Trends in Data Ingestion and Integration. In
2021 44th International Convention on Information,
Communication and Electronic Technology (MIPRO),
pages 1265–1270, Opatija, Croatia. IEEE.
Hutter, F., Kotthoff, L., and Vanschoren, J., editors (2019).
Automated Machine Learning: Methods, Systems,
Challenges. The Springer Series on Challenges in
Machine Learning. Springer International Publishing,
Cham.
Ming Li and Smidts, C. (2003). A ranking of software en-
gineering measures based on expert opinion. IEEE
Transactions on Software Engineering, 29(9):811–
824.
Nagarajah, T. and Poravi, G. (2019). A Review on Au-
tomated Machine Learning (AutoML) Systems. In
2019 IEEE 5th International Conference for Conver-
gence in Technology (I2CT), pages 1–6, Bombay, In-
dia. IEEE.
Patel, J. (2020). The Democratization of Machine Learning
Features. In 2020 IEEE 21st International Confer-
ence on Information Reuse and Integration for Data
Science (IRI), pages 136–141, Las Vegas, NV, USA.
IEEE.
Ray, S., AlGhamdi, A., AlGhamdi, A., Alshouiliy, K., and
Agrawal, D. P. (2020). Selecting Features for Breast
Cancer Analysis and Prediction. In 2020 International
Conference on Advances in Computing and Communi-
cation Engineering (ICACCE), pages 1–6, Las Vegas,
NV, USA. IEEE.
Saurav, S. and Schwarz, P. (2016). A Machine-Learning
Approach to Automatic Detection of Delimiters in
Tabular Data Files. In 2016 IEEE 18th Inter-
national Conference on High Performance Com-
puting and Communications; IEEE 14th Interna-
tional Conference on Smart City; IEEE 2nd Inter-
national Conference on Data Science and Systems
(HPCC/SmartCity/DSS), pages 1501–1503, Sydney,
Australia. IEEE.
Tidwell, J., Brewer, C., and Valencia, A. (2020). Designing
interfaces: Patterns for effective interaction design.
O’Reilly Media, Sebastopol, CA.
Whalen, J. (2019). Design for How People Think: Using
Brain Science to Build Better Products. O’Reilly Me-
dia, Sebastopol, CA.
Z
¨
oller, M.-A. and Huber, M. F. (2021). Benchmark and
Survey of Automated Machine Learning Frameworks.
Journal of Artificial Intelligence Research, 70:409–
472.
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
588
