
Bag-Level Multiple Instance Learning for Acute Stress Detection
from Video Data
Nele Sophie Br
¨
ugge
1 a
, Alexandra Korda
2 b
, Stefan Borgwardt
2 c
, Christina Andreou
2 d
,
Giorgos Giannakakis
3,4,5 e
and Heinz Handels
1,6 f
1
German Research Center for Artificial Intelligence, AI in Medical Image and Signal Processing, L
¨
ubeck, Germany
2
Translational Psychiatry, Department of Psychiatry and Psychotherapy, University of Luebeck, L
¨
ubeck, 23562, Germany
3
Institute of Computer Science, Foundation for Research and Technology Hellas (FORTH), Heraklion, Greece
4
Department of Electronic Engineering, Hellenic Mediterranean University, Chania, Greece
5
Institute of Agri-food and Life Sciences, University Research and Innovation Center, Hellenic Mediterranean University,
Heraklion, Greece
6
Institute of Medical Informatics, University of Luebeck, L
¨
ubeck, Germany
Keywords:
Stress Detection, Multiple Instance Learning, Video Analysis, Neural Networks, Machine Learning.
Abstract:
Stress detection is a complex challenge with implications for health and well-being. It often relies on sensors
recording biomarkers and biosignals, which can be uncomfortable and alter behaviour. Video-based facial
feature analysis offers a noninvasive alternative. This study explores video-level stress detection using top-k
Multiple Instance Learning applied to medical videos. The approach is motivated by the assumption that sub-
jects partly show normal behaviour while performing stressful experimental tasks. Our contributions include a
tailored temporal feature network and optimised data utilisation by additionally incorporating bottom-k snip-
pets. Leave-five-subjects-out stress detection results of 95.46 % accuracy and 95.49 % F1 score demonstrate
the potential of our approach, outperforming the baseline methods. Additionally, through multiple instance
learning, it is possible to show which temporal video segments the network pays particular attention to.
1 INTRODUCTION
Stress is a psychological response to overdemand-
ing events that are perceived as threatening or chal-
lenging. It can have negative effects on one’s
physical and mental health. Recognition of stress
is challenging and commonly based on the eval-
uation of a variety of biomarkers (i.e. cortisol,
corticotropin-releasing factor (CRF), and adrenocor-
ticotropin (ACTH) (Chrousos, 2009)) and biosignals
(features derived from ECG, EDA, respiration, EMG,
etc.) (Giannakakis et al., 2019). However, the eval-
uation of biosignals and biomarkers requires the use
of sensors, which can be invasive and uncomfortable
a
https://orcid.org/0009-0006-2039-423X
b
https://orcid.org/0000-0001-8843-4951
c
https://orcid.org/0000-0002-5792-3987
d
https://orcid.org/0000-0002-6656-9043
e
https://orcid.org/0000-0002-0958-5346
f
https://orcid.org/0000-0002-3499-4328
and may alter the subject’s response to stress.
In recent years, there has been increasing interest
in detecting stress based on facial features, which in
most cases does not meet the performance of that in-
cluding biosignals. Yet, video monitoring of the sub-
jects represents a convenient and noninvasive alterna-
tive. Besides, for a more objective facial stress recog-
nition, there has been an effort for the identification of
involuntary or semi-voluntary facial parameters (Gi-
annakakis et al., 2017; Korda et al., 2021; Bevilac-
qua et al., 2018; Daudelin-Peltier et al., 2017), (Gi-
annakakis et al., 2025). These include blinks, mouth
micro activity or micro-expressions.
Still, it is not yet fully understood how different
types of stress are manifested in facial expressions
and the expression of stress can vary greatly between
individuals in terms of intensity and type. The detec-
tion of stress is therefore one of many medical tasks
for which it is challenging to create fine-grained la-
belled datasets. Furthermore, labelling would have to
Brügge, N. S., Korda, A., Borgwardt, S., Andreou, C., Giannakakis, G. and Handels, H.
Bag-Level Multiple Instance Learning for Acute Stress Detection from Video Data.
DOI: 10.5220/0013364900003911
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 18th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2025) - Volume 2: HEALTHINF, pages 285-296
ISBN: 978-989-758-731-3; ISSN: 2184-4305
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
285

be done by experts, is time consuming and cumber-
some, especially for video data.
To address these challenges, this work proposes
the use of Multiple Instance Learning (MIL) for the
application to stress detection from video data. Its
main advantages are that it requires only video-level
labels and that it can also detect subtle, short-term
anomalies in longer videos. Videos that contain a tar-
get event are labelled as positive, while other videos
are labelled as negative. The assumption in MIL is
that videos labelled as positive also contain negative
segments, while videos labelled as negative consist
only of negative instances. MIL is typically used to
detect anomalies in surveillance camera videos (Sul-
tani et al., 2018), (Zhang et al., 2019), (Wan et al.,
2020), (Tian et al., 2021), (Feng et al., 2021), (Li
et al., 2022) (ShanghaiTech (Luo et al., 2017), (Zhong
et al., 2019), UCF-Crime (Sultani et al., 2018), XD-
Violence (Wu et al., 2020) and UCSD-Peds (Mahade-
van et al., 2010)).
Regarding stress detection, we consider MIL
an appropriate method considering that participants’
faces remain neutral for many frames even in stress-
ful tasks, presenting only short periods of stressful fa-
cial behaviour. MIL can further be utilized to pro-
vide not only video-level but also snippet-level (set of
few frames) predictions, providing explainability and
insights into temporal dynamics of stress behaviour.
Our approach is motivated by top-k MIL (Li and Vas-
concelos, 2015a), (Tian et al., 2021), which trains a
classifier using the k instances with the highest clas-
sification scores as positive instances. The trained
model can be used to classify new snippets into labels
(stress, no stress) based on the features that provide
the most representative snippet instances.
We make modifications to top-k MIL, including
the use of an appropriate feature extraction method,
the use of bottom-k snippets for MIL, and the design
of a tailored temporal attention network and a bag-
level classification network for the binary classifica-
tion task. As feature extraction method, we use a con-
trastive learning network pretrained on facial land-
marks from video data. The input videos are cut and
divided into negative (no stress) and positive (stress
presence) bags for the second MIL training phase.
We propose an attention-based network for temporal
feature extraction, that captures long- and short-term
facial expression patterns. Our training scheme also
includes the bottom-k snippets of positive bags by as-
signing them the neutral label to make the best use
of the limited available data and to improve the ro-
bustness of our model. This is based on the assump-
tions that there are phases of neutral behaviour also in
videos showing subjects during stressful experimen-
tal tasks and that the snippets with the lowest feature
norms most likely represent neutral snippets. In sum-
mary, our contributions consist of
• Applying MIL to stress detection from video data
• Proposing an MIL approach that exploits both
top-k and bottom-k video snippets in training
• Designing a temporal feature extraction network
with multi-head attention.
2 RELATED WORK
2.1 Stress Detection Using Machine
Learning
Recent research in stress detection using machine
learning has explored a spectrum of methods. Con-
ventional ML approaches, such as Random Forests
and Support Vector Machines, have been employed
effectively (Naegelin et al., 2023), (Bobade and Vani,
2020), (Siam et al., 2023), (Garg et al., 2021), (Hos-
seini et al., 2021), (Viegas et al., 2018). These
studies used data from a variety of sensors, includ-
ing wearables, electrodermal activity, electrocardio-
graphy, electroencephalography and temperature (Li
and Liu, 2020), (Naegelin et al., 2023), (Bobade and
Vani, 2020), (Siam et al., 2023), (Hosseini et al.,
2021), (Garg et al., 2021), (Zhang et al., 2022). In
parallel, video data analysis (Zhang et al., 2022),
(Zhang et al., 2020), (Kumar et al., 2021), (Jeon et al.,
2021) has emerged as a convenient and non-invasive
alternative for stress detection, providing a good re-
producibility without the requiring a precise sensor
placement.
The analysis of video data has greatly benefited
from advancements in complex neural network ar-
chitectures, achieving high accuracy in facial stress
recognition (Hasani and Mahoor, 2017), (Jeon et al.,
2021), (Kumar et al., 2021), (Li and Liu, 2020),
(Zhang et al., 2020), (Zhang et al., 2022). As an ex-
ample, in (Hasani and Mahoor, 2017), a 3D Convo-
lutional Neural Network method for facial expression
recognition in videos was proposed, yielding a stress
recognition accuracy up to 90 %. Using also informa-
tion from voice and ECG of 20 participants, in (Zhang
et al., 2022) a neural network based on I3D fea-
tures and a temporal attention module was proposed,
achieving an accuracy of 85.1 %. Other 2D ResNet-
based approaches use temporal attention (Jeon et al.,
2021) or long short-term memory (LSTM) layers
(Zhang et al., 2020), (Kumar et al., 2021) to intro-
duce temporal information. Instead of applying neu-
ral networks directly to the raw video data, some stud-
HEALTHINF 2025 - 18th International Conference on Health Informatics
286

ies have focused on extracting facial action units from
videos as input features for classification (Gavrilescu
and Vizireanu, 2019), (Giannakakis et al., 2020).
Additionally, the stress detection task has been in-
vestigated across diverse environments and scenarios,
spanning office settings (Naegelin et al., 2023), hospi-
tal scenarios (Hosseini et al., 2021), activities like car
driving (Siam et al., 2023) or social media posts (Tur-
can et al., 2021). In previous work, stressful tasks of-
ten consist of a mental task, memory task, arithmetic
task, or external stimuli such as noisy sounds, show-
ing arousing photos or videos and physical stimuli.
While many approaches to stress detection have been
extensively investigated, the potential of Multiple In-
stance Learning (MIL) remains largely unexplored. In
this paper we evaluate MIL on six different tasks and
stimuli. Further, the use of multiple instance learning
in stress detection still remains largely unexplored, al-
though many approaches have been extensively inves-
tigated.
2.2 Multiple Instance Learning in
Medical Image and Video Analysis
MIL has shown promising results in many medical
image and video analysis applications. Examples
in medical image analysis include dementia classi-
fication in brain MRI (Tong et al., 2013), diabetic
retinopathy detection in colour fundus images (Kan-
demir and Hamprecht, 2015) and hotspot detection in
bone scintigraphy images (Geng et al., 2015). Several
studies have applied MIL to histopathology patches
in cancer research, for example to detect lymph node
metastases in breast cancer (Li et al., 2021), (Kan-
demir et al., 2014), (Dundar et al., 2010) and the clas-
sification of esophagus (Kandemir and Hamprecht,
2015), (Kandemir et al., 2014) or colon cancer (Xu
et al., 2012), (Xu et al., 2014a), (Xu et al., 2014b).
There is also work on medical video analysis,
while MIL is more commonly applied to anomaly
detection in surveillance camera videos. Sikka et
al. (Sikka et al., 2014), (Sikka et al., 2013) used a
weakly supervised MIL approach for pain localisation
from medical videos. In (Wang et al., 2020), MIL
was used to detect depression from videos using fa-
cial landmarks. Further, (Tian et al., 2022) proposed
a contrastive transformer-based approach for weakly
supervised polyp frame detection in colonoscopy
videos. To the best of our knowledge, MIL has not
been applied to detect stress from facial video.
3 STRESS DATASET
We recorded videos of subjects performing differ-
ent stressful tasks. The experimental protocol was
designed to investigate facial and physiological re-
sponses under stress conditions. The experimental
dataset comprised 58 individuals (24 men and 34
women) with an average age of 26.9 ± 4.8 years.
3.1 Video Acquisition Protocol
All participants were seated in front of a monitor and
a camera. The camera’s field of view covered the par-
ticipant’s face. Possible movements during the ex-
periment were taken into account. The camera was
mounted on a tripod and positioned at the back of the
screen at a distance of about 90 cm from the face.
Ambient lighting conditions were ensured to reduce
the effects of specular lighting. The videos had a sam-
pling rate of 60 frames per second and a resolution of
1216 x 1600 pixels, which were subsampled to 608 x
800 pixels at 30 frames per second.
3.2 Experimental Tasks
The experiment included neutral tasks (used as ref-
erence) and stressful tasks in which stress conditions
were simulated and induced using different types of
stressors. These stressors were categorised into 4 dif-
ferent phases: social exposure, emotional recall, men-
tal workload tasks, stressful videos presentation. The
experimental tasks and their corresponding induced
affective states are presented in Table 1. Each partic-
ipant completed eleven tasks: four in neutral, six in
stressed, and one in a relaxed state. Every experiment
began with a neutral or relaxing phase at each stage as
baseline and each recording had a duration of 2 min.
The social exposure phase included an interview
asking the participant to describe him/herself. It orig-
inated from the stress of exposure that an actor faces
when she/he is on stage. The reference for this phase
was the participant saying conventional words (e.g.
counting from one to ten, listing the months of the
year, etc.). The emotional recall phase included stress
elicitation by asking participants to recall and relive
a stressful event from their past as if it was cur-
rently happening. The mental tasks phase included
assessing cognitive load through tasks such as the
modified Stroop Colour-Word Task (SCWT) (Stroop,
1935), requiring participants to read colour names
(red, green, and blue) printed in incongruous ink (e.g.,
the word RED appearing in blue ink). The difficulty
was increased by asking participants first to read each
word and then name the colour of the word. A sec-
Bag-Level Multiple Instance Learning for Acute Stress Detection from Video Data
287

Table 1: Experimental tasks employed in this study. The
intended affective states of the experimental tasks are neu-
tral (N), stress (S), and relaxed (R).
# Experimental task Affective
State
Social Exposure
1 1.1 Neutral (Reference) N
2 1.2 Baseline Description N
3 1.3 Interview S
Emotional Recall
4 2.1 Neutral (Reference) N
5 2.2 Recall stressful event S
Mental Workload
6 3.1 Reading words (Reference) N
7 3.2 Stroop Colour-Word Test S
8 3.3 PASAT task S
Stressful Stimuli
9 4.1 Relaxing video R
10 4.2 Adventure video S
11 4.3 Psych. pressure video S
ond mental task used was the Paced Auditory Serial
Addition Test (PASAT) (Gronwall, 1977), which is
a neuropsychological test involving arithmetic oper-
ations to assess attentional processing. The stress-
ful video phase included the presentation of 2-minute
videos designed to induce low-intensity positive emo-
tions (calming video) and stress (action scene from
an adventure film, a scene involving heights to par-
ticipants with moderate levels of acrophobia, a bur-
glary/home invasion while the inhabitant is inside, car
accidents etc.). Each participant gave their free and
informed permission and the Research Ethics Com-
mittee of FORTH provided its approval for this study
(approval no. 155/12-09-2022).
4 METHODS
4.1 Contrastive Learning Feature
Extraction
MIL models usually use standard feature networks,
such as C3D (Tran et al., 2015) or I3D (Carreira and
Zisserman, 2017), trained on action detection datasets
such as Kinetics-400. Such networks may not be well
suited for the detection of medical abnormalities in fa-
cial video data. Given this limitation, we consider us-
ing a contrastive learning network that was trained on
facial video data instead. In (Br
¨
ugge et al., 2023), it
was demonstrated that using this network, it was pos-
sible to extract distinguishing features for the med-
ical task, despite being trained solely on data from
healthy individuals. Applying the network requires
the detection and tracking of facial landmarks. Thus,
for contrastive learning, it is necessary to use tailored
transformations, such as flipping the landmark coor-
dinates horizontally and global and local scaling, im-
plemented by a multiplication of x- and y-coordinates
by random factors.
4.2 Multiple Instance Learning
4.2.1 Motivation
Multiple Instance Learning is a learning approach that
trains a model using weak labels at the video level to
infer unknown labels at second or snippet level. The
video data is divided into positive and negative bags.
In our stress detection task, positive bags represent
videos that contain at least one shorter video snip-
pet showing stress behaviour and negative bags rep-
resent videos showing solely neutral or relaxed be-
haviour. Top-k MIL (Angles et al., 2021), (Li and
Vasconcelos, 2015b), (Tian et al., 2021) identifies the
top-k instances within each bag that are likely to be
positive examples and uses this information to clas-
sify each instance in the bag. Due to the absence of
second-wise labelled data for evaluation, we focus on
improving classification performance at the bag level.
At the same time, by using MIL we obtain a temporal
instance segmentation, which improves explainabil-
ity by providing insight into which snippets contain
stress behaviour.
In stress detection, typically only a small propor-
tion of video snippets exhibit stress behaviour, mak-
ing the majority of the content appear normal. To ef-
fectively use these data for training, we consider not
only the top-k snippets but also the bottom-k snippets
within positive bags. We assume that the majority
of snippets in positive bags show no signs of stress,
allowing us to label bottom-k snippets as neutral in-
stances. Incorporating these bottom-k snippets into
the training dataset as normal instances could help to
make better use of limited datasets and improve the
robustness of the classifier.
4.2.2 Bottom-k Multiple Instance Learning
In our stress detection task, we cut the videos into
non-overlapping sub-videos to form bags. Each bag
contains a fixed number of features extracted using
the contrastive learning feature network. With the
pre-extracted features F
i
∈ R
T ×D
and the correspond-
ing weak video-level binary stress label y
i
, we denote
the training dataset of weakly-labelled recordings as
D = (F
i
,y
i
)
|D|
i=1
. D and T denote the feature size and
the number of features in a single training video, re-
spectively. The label y
i
takes the value 0 if it shows
HEALTHINF 2025 - 18th International Conference on Health Informatics
288
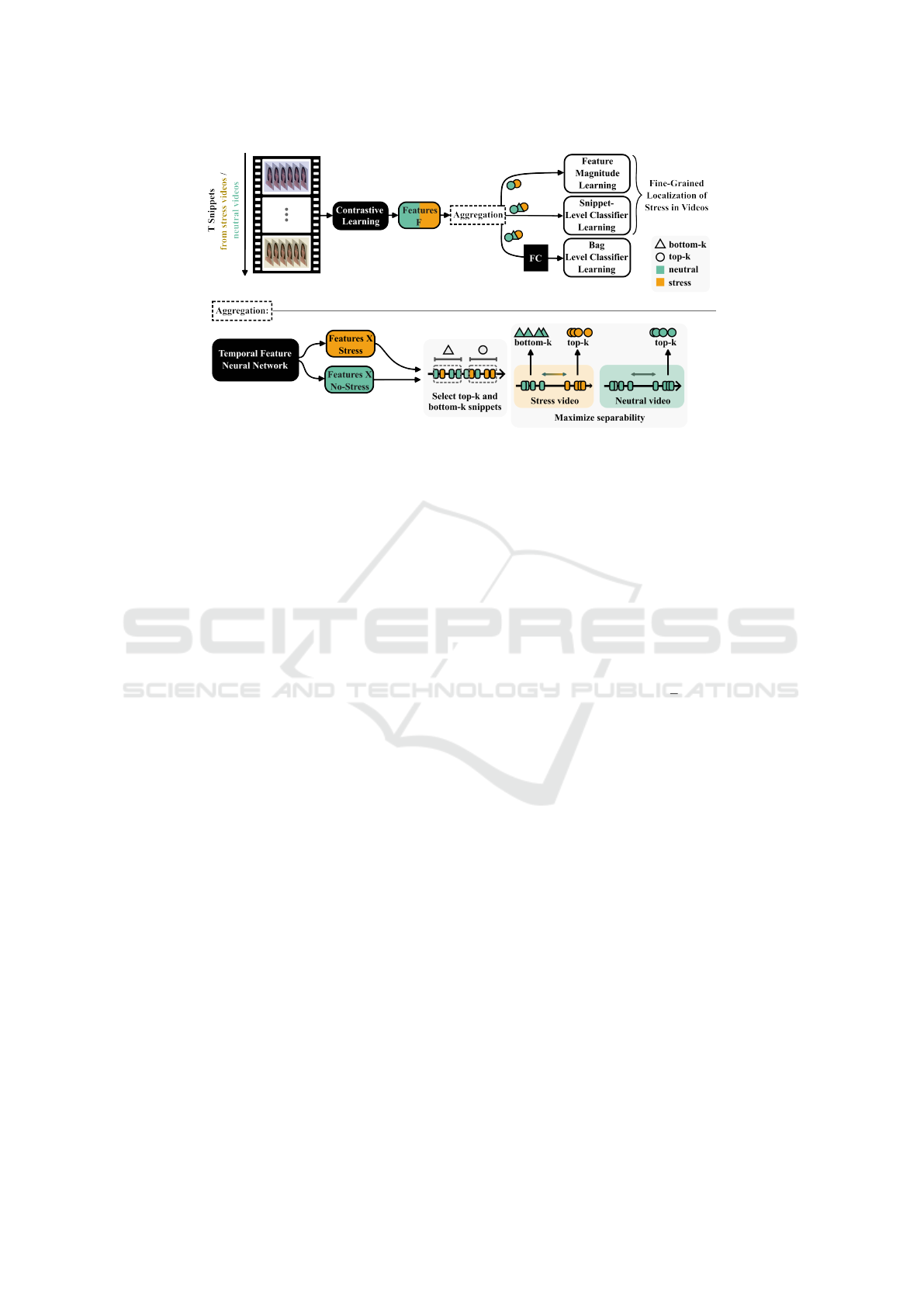
Figure 1: Overview over the proposed multiple instance learning approach for stress detection. Videos are divided into T
snippets from which contrastive learning features are extracted. These features are input to another temporal feature neural
network. Using the feature magnitude learning scheme, the separability of neutral and stress snippets is maximised. The
resulting top-k and bottom-k snippets of stress videos and top-k snippets of neutral videos then serve as input to a snippet-
level and a bag-level classifier. Bottom-k snippets of stress videos are labelled as neutral.
the subject during an experimental task that was as-
signed the affective state “N” or “R” and it takes the
value 1 for the affective state “S”.
An overview over our bottom-k MIL approach is
given in Figure 1. We use a multi-head-attention tem-
poral feature network s
θ
: F −→ X (see subsection 4.3,
Figure 3 and Figure 2 for details) for the extraction
of temporal features X = s
θ
(F) from the features F.
Based on these temporal features, a snippet-level clas-
sification network f
φ
: X −→ [0, 1]
T
is generating the
binary classification whether a video snippet contains
stress behaviour by f
φ
(s
θ
(F)). Features of positive
and negative snippets are denoted as x
+
∼ P
+
x
(x)
and x
−
∼ P
−
x
(x), as in (Tian et al., 2021). With
t = 1, ...,T , a snippet feature x
t
represents the t-th
row in X. A positive video X
+
showing stress be-
haviour can contain snippets drawn from both P
+
x
(x)
and P
−
x
(x) but negative videos X
−
showing normal
behaviour can only contain snippets from P
−
x
(x). We
also make the assumption that
E
[∥x
+
∥
2
] ≥
E
[∥x
−
∥
2
]
indicating that stress snippet features have larger mag-
nitudes than non-stress snippet features.
The snippet-level classifier f
φ
, the temporal fea-
ture network s
θ
and the bag-level classifier c
ψ
are
trained jointly. The joint loss is given by
ℓ
overall
= min
φ,θ,ψ
|D|
∑
i, j=1
N
∑
n=1
ℓ
s
(s
θ
(F
(n)
i
),s
θ
(F
(n)
j
),y
i
,y
j
)
+ℓ
f
( f
φ
(s
θ
(F
(n)
i
)),y
i
)
+ℓ
b
(c
ψ
( f
φ
(s
θ
(F
(n)
i
)),y
i
)).
(1)
with N being the number of input sub-videos of length
T extracted from one recording. The loss function
ℓ
overall
combines a cross-entropy snippet classification
loss ℓ
f
, a feature separability loss function ℓ
s
and a
bag loss function ℓ
b
. We outline the different loss
terms below.
We use the feature separability loss ℓ
s
from (Tian
et al., 2021) to ensure that the feature magnitude cor-
relates with the probability of a snippet feature being
positive. The mean feature norm is calculated by
g
θ,k
(X) = max
Ω
k
(X)⊆{x
t
}
T
t=1
1
k
∑
x
t
∈Ω
k
(X)
∥x
t
∥
2
(2)
where Ω
k
(X) is a subset of k snippets in {x
t
}
T
t=1
. The
separability loss ℓ
s
is given by
ℓ
s
(s
θ
(F
i
),s
θ
(F
j
),y
i
,y
j
)) =
(
(|m − g
θ,k
(X
+
)| + g
θ,k
(X
−
))
2
if y
i
= 1,y
j
= 0,
0 otherwise,
(3)
where m is a pre-selected margin.
The classification cross-entropy loss l
f
is given by
l
f
( f
φ
(s
θ
(F)),y) =
∑
x∈Ω
k,max
(X)
x∈Ω
k
b
,min
(X)
−
ylog( f
φ
(x)) + (1 − y) log(1 − f
φ
(x))
.
(4)
This loss is not only getting the top-k features from X
i
with the largest L2 norm as input but also the bottom-
k features with the smallest L2 norm of all snippets in
a positive bag. Top-k snippets are represented by the
set Ω
k,max
(X) and bottom-k snippets are represented
by the set Ω
k
b
,min
(X). For the bottom-k features, the
label y takes the value 0 because we assume that pos-
itive bags also contain no-stress snippets.
Bag-Level Multiple Instance Learning for Acute Stress Detection from Video Data
289
For calculating the bag-level loss, the features X
are input to a simple bag-classification head c
ψ
(·)
consisting of two fully-connected network layers and
ReLU activation. The cross-entropy classification
loss is given as
ℓ
b
(c
ψ
( f
φ
(s
θ
(F))),y) =
−
ylog
c
ψ
( f
φ
(
˜
X))
+ (1 −y)log
1 − c
ψ
( f
φ
(
˜
X))
(5)
where
˜
X contains all top-k and bottom-k features of X.
4.3 Temporal Feature Network
For temporal feature extraction, we use a neural net-
work employing multi-head attention and convolu-
tions at different temporal scales. We therefore call
this network Multi-Scale Multi-Head Attention Net-
work (MSMHN). An overview of this network is
given in Figure 3. The stress-related information is
extracted at different temporal scales from the input
features F. As also done in (Tian et al., 2021), this
is achieved by using dilated convolutions in the tem-
poral direction of F. The dilation factors of the three
1D-convolutional network branches are 1, 2 and 3 to
capture both subtle short- and long-term facial expres-
sion patterns.
Each dilated convolution branch of the network
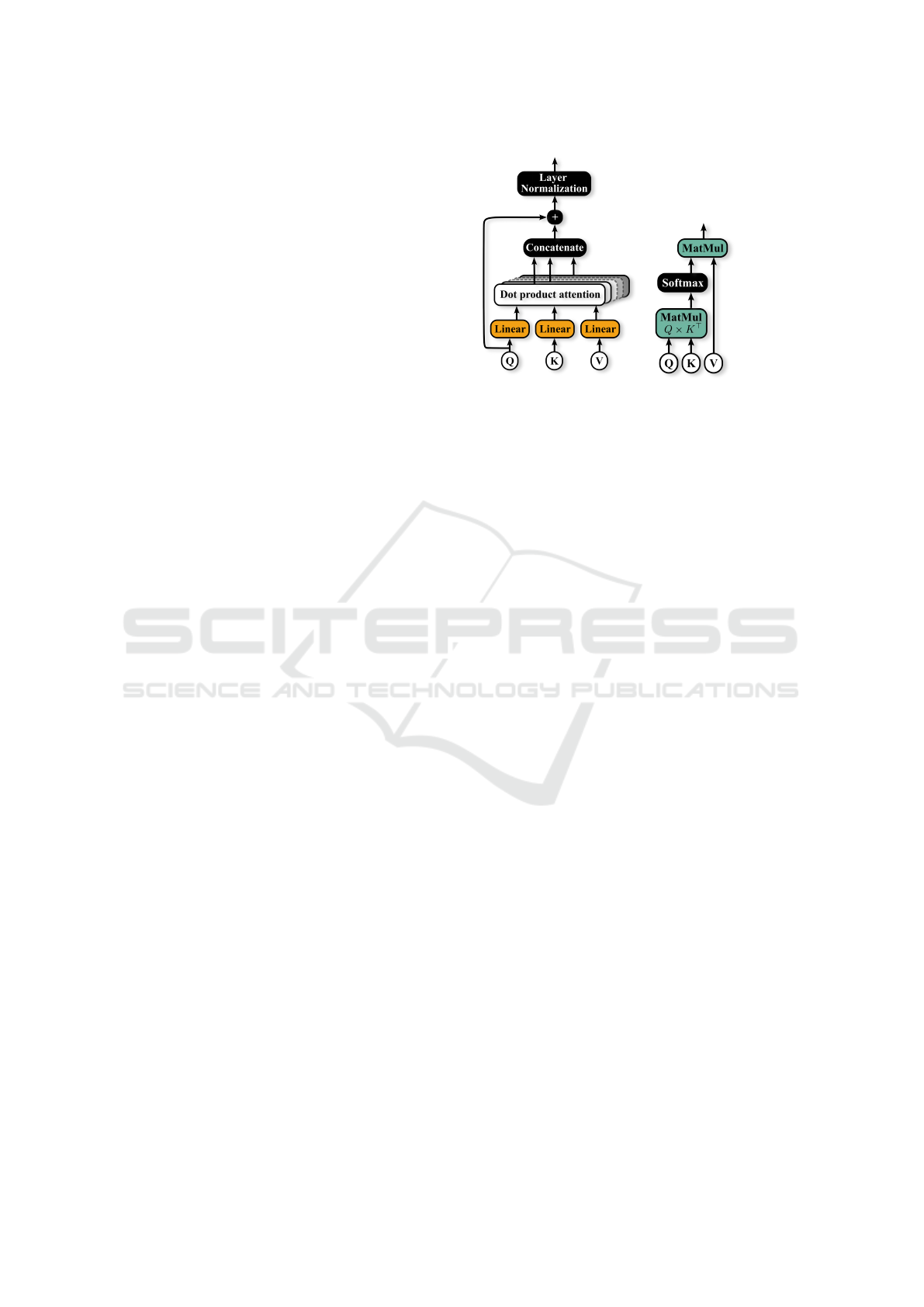
is equipped with its own multi-head self-attention
mechanism (Vaswani et al., 2017). Figure 2 gives
an overview over the self-attention module. Multi-
Head attention divides the attention mechanism into
several parallel and individual heads to compute at-
tention scores. Each head uses dot product attention,
a process that calculates attention weights by com-
puting the dot product between a query and key input
vector.
After computing the dot product attention, the out-
puts from all heads are concatenated, added to the
input sequence and then normalised to generate the
final multi-head attention output. This self-attention
mechanism enables the network to identify relevant
data patterns and relationships at different temporal
scales.
For feature fusion, the extracted multi-scale tem-
poral features are concatenated and processed through
a convolutional layer. Additionally, we employ a skip
connection.
5 EXPERIMENTAL DETAILS
We trained the self-supervised feature network ac-
cording to (Br
¨
ugge et al., 2023) and applied it to our
stress dataset. To train the MIL framework, we use
(a) (b)
Figure 2: Network sub-modules of the Multi-Scale Multi-
Head Network. The multi-head attention mechanism is
shown in a), dot product attention in b). Query (Q), Key
(K) and Value (V) are given by the output of the dilated
convolutions (Figure 3).
data from one neutral/relaxed and one stressful video
from the same experimental task, yielding a balanced
dataset. This process is repeated for all task combi-
nations, resulting in a separate network trained for
each task combination. One bag was represented by
T = 30 consecutive feature snippets of one subject
performing a single task. Segments that form a bag
were chosen without overlap.
We used Adam optimisation with a learning rate
of 10
−4
and a batch size of 32. We set the param-
eters k = 10 and k
b
= k for the bottom-k snippets.
As bag classifier, we used a simple two-layer fully-
connected (FC) neural network with 512 nodes in the
hidden layer and ReLU activation. We train the MIL
framework for 10 epochs.
To validate our approach, we used 10-fold cross-
validation, where in each fold we excluded 5 subjects
from the training set and used their data for the evalu-
ation. In this way, we investigate the extent to which
our approach generalises to unseen subjects.
6 RESULTS AND DISCUSSION
In this section, we present our results, which demon-
strate the effectiveness of our proposed MIL method
for stress detection. In the following, we summarise
our experiments and report on the results for different
networks and training schemes. We listed the results
of all experiments in subsection 2.
3D ResNet-18 Trained with Dense Labels. In a first
experiment, we trained a 3D ResNet-18 (Hara et al.,
2017) as baseline model for fully supervised snippet-
level training. As in all following experiments, train-
HEALTHINF 2025 - 18th International Conference on Health Informatics
290
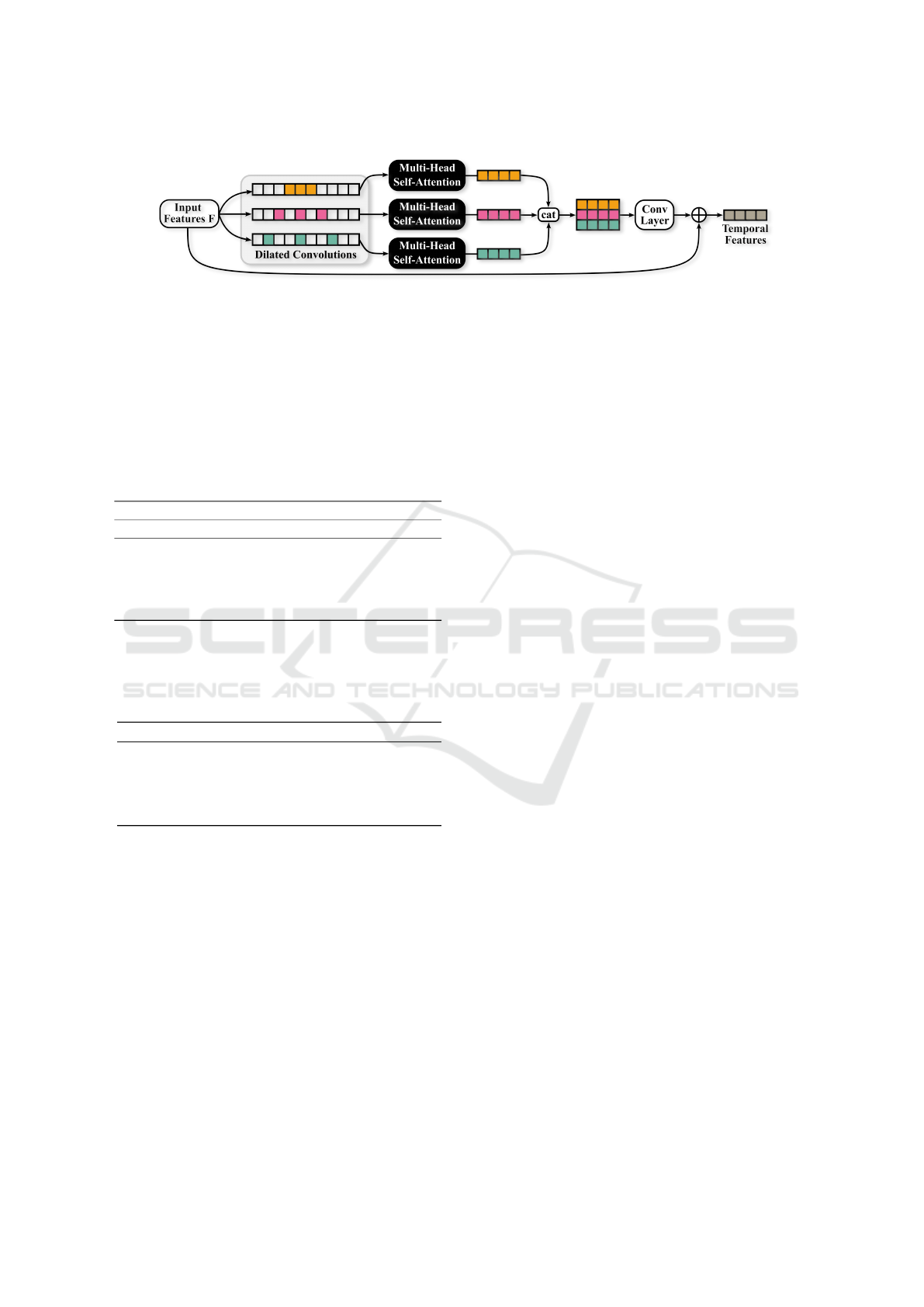
Figure 3: Network architecture of the Multi-Scale Multi-Head Network for temporal feature extraction. Multi-Scale temporal
features are extracted using dilated convolutions. These are then input to a multi-head self-attention mechanism, shown in
subsection 2 and concatenated afterwards. The concatenated self-attention features are input to another convolutional layer
for feature fusion. The original features are added through a skip connection.
Table 2: Stress classification bag-level accuracy (ACC) and
F1 Score (F1) for different network architectures and learn-
ing schemes, averaged over all experimental tasks. The col-
umn MIL indicates whether the MIL training scheme was
used. “Dense Label” indicates that the classification was
performed on a second-wise snippet basis where all snip-
pets were assigned the bag label. “Bottom-k” means that
we used the proposed MIL approach from subsection 4.2.1.
Model MIL ACC (%) F1 (%)
3D ResNet-18 + Dense Label ✗ 77.28 ± 16.92 76.34±23.45
3D ResNet-18 ✗ 83.38 ± 12.88 81.32 ±21.43
MTN (Tian et al., 2021) ✗ 86.14 ± 12.89 82.68 ±12.43
MTN (Tian et al., 2021) ✓ 93.19 ± 5.21 93.57 ± 4.71
MTN + Bottom-k ✓ 94.17 ± 5.19 94.28 ± 5.13
MSMHN ✓ 95.09 ± 4.77 95.22 ± 4.63
MSMHN + Bottom-k ✓ 95.46 ± 4.37 95.49 ± 4.77
Table 3: Stress classification bag-level accuracy (ACC) and
F1 score (F1) for the 7 different stress task combinations.
As network we used the best-performing MSMHN archi-
tecture and trained it using the proposed bottom-score MIL
approach according to Table 2.
Task ACC (%) F1 (%)
Social Exposure 1.2 vs. 1.3 97.78 ± 1.57 97.78 ± 1.55
Emotional Recall 2.1 vs. 2.2 96.77 ± 2.80 96.82 ± 2.63
Mental Workload 3.1 vs. 3.2 94.03 ± 3.46 94.34 ± 3.18
Mental Workload 3.1 vs. 3.3 95.19 ± 3.14 95.35 ± 3.00
Stressful Stimuli 4.1 vs. 4.2 97.35 ± 2.08 97.29 ± 2.09
Stressful Stimuli 4.1 vs. 4.3 91.68 ± 7.15 91.35 ± 7.64
ing was performed on the extracted contrastive learn-
ing features to ensure comparability and to analyse
the effect of MIL on the results. For this baseline,
we labelled each snippet with the bag-label to get a
densely-labelled dataset and fed these snippets to the
ResNet individually. This approach resulted in an ac-
curacy of 77.28 % and an F1 score of 76.34 %.
3D ResNet-18 Trained with Bag-Level Labels. In a
second experiment, we used the same 3D ResNet-18
architecture but divided the video into 30 s segments
and assigned a single label to each segment. All 30
snippets of one bag were fed into the FC bag classifier
at once. With this approach, accuracy and F1 score
increased to 83.38 % and 81.32 %, respectively.
MTN. We followed the same training strategy using
the MTN architecture from (Tian et al., 2021), since
it has proven useful in extracting temporal features
from video data features. The model combines par-
allel dilated convolutions with dilation factors up to
4, an attention network branch and residual connec-
tions. Again, all extracted features were input to the
bag classifier. Using this architecture improved per-
formance, yielding an accuracy of 86.14 % and an F1
score of 82.68 %.
MTN Trained Using MIL. We used the same MTN
architecture and trained the network using top-k MIL
as described in 4.2, but without using the bottom
scores. Using MIL again be improved the accuracy
and F1 score to 93.19 % and 93.57 %, respectively.
MTN Trained Using MIL with Bottom Scores.
Next, we incorporated bottom-k features from stress
videos into the snippet- and bag-level classification
losses ℓ
f
and ℓ
b
in training the MTN. Integrating
bottom-k features has led to further improvements, re-
sulting in an accuracy of 94.17% and an F1 score of
94.28 %.
MSMHN Trained Using MIL. For a direct com-
parison, we train the proposed MSMHN, described
in subsection 4.3 using MIL without using bottom-k
features. This improved the accuracy and F1 score by
approximately one percent compared to the best re-
sults obtained with the MTN, leading to 95.09 % and
95.22 %, respectively.
MSMHN Trained Using MIL with Bottom Scores.
Finally, we integrated bottom-k scores for bag-level
training also in the MIL training of the MSMHN. The
proposed model performed best. It achieved an accu-
racy of 95.46 % and an F1 score of 95.49 %, outper-
forming all previously considered methods. We per-
formed a statistical analysis on the results. Shapiro-
Wilk tests confirmed that the data were normally dis-
tributed. A paired t-test showed statistically signif-
icant differences in the performance measures com-
pared to MSMHN using no bottom scores. Specifi-
cally, the F1 scores showed t(59) = 2.324,P = 0.023,
significant at P < 0.05, and the accuracy showed
Bag-Level Multiple Instance Learning for Acute Stress Detection from Video Data
291

t(59) = 3.751, P = 0.0004, significant at P < 0.001.
A possible explanation is that models are more
likely to overfit on small datasets and may learn small
differences in the stress videos that are not indicative
of stress. The addition of the bottom snippets from
stress videos as neutral snippets contributes to the di-
versity of the dataset, as characteristics such as head
posture may differ between neutral and stress videos.
We have listed the results of the best performing
model for all task combinations in Table 3. The ta-
ble shows that the classification yielded the best re-
sults for the subjects performing a baseline descrip-
tion vs. being involved interview and watching a re-
laxing video vs. an adventure video. In this setting,
the classification accuracies are 97.78 % and 97.35 %
and the F1 scores are 97.79 % and 97.29 %, respec-
tively. The lowest accuracy and F1 score were ob-
tained by classifying videos of subjects watching a re-
laxing video vs. a psychological pressure video with
an accuracy of 91.68 % and an F1 score of 91.35 %.
0
0.5
1
S3
No Stress Stress
0
0.5
1
S6
0
0.5
1
S10
0
0.5
1
S15
0
50
100
0
0.5
1
time / [s]
S16
Scores Feature Magnitude
0
50
100
time / [s]
Figure 4: Snippet classifier scores and feature magni-
tudes during the neutral task 4.1 (left) and stressful stimuli
task 4.3 (right) for five exemplary subjects and a time span
of 2 min.
We provide exemplary sequences of facial feature
magnitudes and network scores in relaxed (task 4.1)
and stressed (task 4.3) videos for five subjects in
Figure 4. The plots show the feature magnitudes
and snippet classifier scores over time, highlighting
the time steps the network focuses on. It therefore
contributes to the explainability of our approach and
could provide insights into stress dynamics in facial
videos. The figure shows that the norm of the features
increases with a high prediction score. This is more
pronounced for the stress tasks than for the neutral
tasks. Additionally, the model highlights short seg-
(a) AU 4, Brow Lowerer (b) AU 10, Upper Lip Raiser
(c) AU 12, Lip Corner Puller (d) AU 14, Dimpler
Figure 5: Action Units that had a significant correlation
with the stress prediction scores of the MIL neural network.
ments in the neutral tasks as seen in the first row in
Figure 4.
Correlations Between Predictions and Action Unit
Time Series. To further analyse what the network
focuses on, we use 17 facial action unit (AU) time
series for each subject and task and calculate their
correlation with the network predictions and feature
magnitudes. The correlations are false detection rate
corrected and shown as box plots in Figure 6 the ap-
pendix. The action units that correlate with the pre-
diction vary depending on the task. AU 14 (Dimpler,
see Figure 5d) is strongly pronounced in most tasks.
With the exception of task 4.2 vs. 4.3, the time se-
ries of predictions and features of more than 10 peo-
ple show at least a moderate correlation of 40 % with
this AU. In the neuropsychological test tasks (Mental
Workload, tasks 3.1 vs. 3.2 and 3.1 vs. 3.3), we also
found that AUs 10, and 12 (Upper Lip Raiser and Lip
Corner Puller, see Figure 5b and Figure 5c) are highly
pronounced. In addition, AU 4 (Brow Lowerer, Fig-
ure 5a) is particularly present in many test subjects in
all tasks except 1.2 vs. 1.3 and 2.1 vs. 2.2.
Limitations. While the results demonstrate robust
stress detection capabilities, it is important to mention
potential limitations and open research questions.
First, without snippet-level labels, it is not possi-
ble to assess whether the network exclusively focuses
on stress indicators. This is particularly evident in the
mental load task, where subjects tend to smile after
making errors. Although smiling is not inherently in-
dicative of stress, the network may associate it with
the subject making errors that occur during the stress
task. This is supported by the greater prevalence of
subjects with at least moderate correlations of AUs 6,
10 and 12 with the network predictions in the tasks
involving neuropsychological tests compared to the
other task combinations. These AUs are the cheek
raiser, the upper lip raiser and the lip corner puller,
which are typically activated when a person smiles.
Secondly, we would like to mention that deter-
mining the optimal choice of the parameter k is an
HEALTHINF 2025 - 18th International Conference on Health Informatics
292

ongoing challenge, as its choice is highly dependent
on the considered dataset. Consequently, the param-
eter used might not necessarily be ideal for different
datasets and should be chosen based on the frequency
of the anomalies to be detected. Also, this study did
not focus on improving snippet feature extraction, and
there may be other feature extraction models that fur-
ther improve the classification. However, it has been
shown in (Br
¨
ugge et al., 2023) that the applied model
performs well for facial video data.
Finally, it should be noted that all videos were
recorded in a controlled recording environment,
which ideally should also apply to the data on which
the model is evaluated. However, the use of con-
trastive learning as a feature extractor mitigates this
point, as contrastive learning introduces invariance to
various influences. In addition, because contrastive
learning is applied to landmarks, influences such as
appearance, lighting and background play a minor
role, as long as the landmark detection is robust.
7 CONCLUSION
The results showed that a high stress detection accu-
racy was achieved when MIL was applied to the fa-
cial video data of subjects performing different neu-
tral and stressful tasks. In an ablation study, we suc-
cessively motivated the components of our approach
by evaluating the use of MIL, the temporal feature
network and the integration of bottom scores. In
our dataset, where we expect anomalous events to
be scarce, stress detection using neural networks can
benefit from a MIL training scheme where the in-
stances most likely to be anomalous are considered
for classification. The proposed MSMHN also led to
improved results. Further improvement of this MIL
baseline could be achieved by including segments that
are unlikely to contain stress behaviour, even though
they are sampled from a video taken during a stressful
task. Using the combination of our proposed modi-
fications to top-k MIL, the stress detection accuracy
and F1 scores averaged over all experimental tasks
were 95.46 % and 95.49 %, respectively.
The use of MIL simultaneously provides valuable
insights into which snippets contribute most to the
classification of stress behaviour. We used correlation
analysis to identify the action units that are predom-
inantly activated in these critical snippets. In future
work, we aim to further increase this explainability by
highlighting specific facial regions that play a key role
in stress classification to better understand the mani-
festation of stress in facial expressions.expressions.
ACKNOWLEDGEMENTS
This work was supported by the BMBF
(16KISA057).
REFERENCES
Angles, B., Jin, Y., Kornblith, S., Tagliasacchi, A., and Yi,
K. M. (2021). MIST: Multiple instance spatial trans-
former. In 2021 IEEE/CVF Conference on Computer
Vision and Pattern Recognition (CVPR), pages 2412–
2422. IEEE.
Bevilacqua, F., Engstr
¨
om, H., and Backlund, P. (2018). Au-
tomated analysis of facial cues from videos as a po-
tential method for differentiating stress and boredom
of players in games. International Journal of Com-
puter Games Technology, 2018.
Bobade, P. and Vani, M. (2020). Stress detection with ma-
chine learning and deep learning using multimodal
physiological data. In 2020 Second International Con-
ference on Inventive Research in Computing Applica-
tions (ICIRCA), pages 51–57.
Br
¨
ugge, N. S., Mohammadi, E., M
¨
unchau, A., B
¨
aumer, T.,
Frings, C., Beste, C., Roessner, V., and Handels, H.
(2023). Towards privacy and utility in tourette TIC
detection through pretraining based on publicly avail-
able video data of healthy subjects. In ICASSP 2023
- 2023 IEEE International Conference on Acoustics,
Speech and Signal Processing (ICASSP).
Carreira, J. and Zisserman, A. (2017). Quo vadis, action
recognition? a new model and the kinetics dataset.
In 2017 IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), pages 4724–4733, Los
Alamitos, CA, USA. IEEE Computer Society.
Chrousos, G. P. (2009). Stress and disorders of the stress
system. Nature reviews endocrinology, 5(7):374.
Daudelin-Peltier, C., Forget, H., Blais, C., Desch
ˆ
enes, A.,
and Fiset, D. (2017). The effect of acute social stress
on the recognition of facial expression of emotions.
Scientific Reports, 7(1):1036.
Dundar, M. M., Badve, S., Raykar, V. C., Jain, R. K., Ser-
tel, O., and Gurcan, M. N. (2010). A multiple in-
stance learning approach toward optimal classification
of pathology slides. In 2010 20th International Con-
ference on Pattern Recognition, pages 2732–2735.
ISSN: 1051-4651.
Feng, J.-C., Hong, F.-T., and Zheng, W.-S. (2021). MIST:
Multiple instance self-training framework for video
anomaly detection. In 2021 IEEE/CVF Conference
on Computer Vision and Pattern Recognition (CVPR),
pages 14004–14013. IEEE.
Garg, P., Santhosh, J., Dengel, A., and Ishimaru, S. (2021).
Stress detection by machine learning and wearable
sensors. In 26th International Conference on Intel-
ligent User Interfaces - Companion, IUI ’21 Compan-
ion, pages 43–45. Association for Computing Machin-
ery.
Bag-Level Multiple Instance Learning for Acute Stress Detection from Video Data
293

Gavrilescu, M. and Vizireanu, N. (2019). Predicting de-
pression, anxiety, and stress levels from videos using
the facial action coding system. Sensors, 19(17):3693.
Publisher: Multidisciplinary Digital Publishing Insti-
tute.
Geng, S., Jia, S., Qiao, Y., Yang, J., and Jia, Z. (2015). Com-
bining CNN and MIL to assist hotspot segmentation in
bone scintigraphy. In Arik, S., Huang, T., Lai, W. K.,
and Liu, Q., editors, Neural Information Processing,
Lecture Notes in Computer Science, pages 445–452.
Springer International Publishing.
Giannakakis, G., Grigoriadis, D., Giannakaki, K., Simanti-
raki, O., Roniotis, A., and Tsiknakis, M. (2019). Re-
view on psychological stress detection using biosig-
nals. IEEE Transactions on Affective Computing.
Giannakakis, G., Koujan, M. R., Roussos, A., and Marias,
K. (2020). Automatic stress detection evaluating mod-
els of facial action units. In 2020 15th IEEE Inter-
national Conference on Automatic Face and Gesture
Recognition (FG 2020), pages 728–733. IEEE.
Giannakakis, G., Pediaditis, M., Manousos, D., Kazantzaki,
E., Chiarugi, F., Simos, P. G., Marias, K., and Tsik-
nakis, M. (2017). Stress and anxiety detection using
facial cues from videos. Biomed. Signal Process. Con-
trol., 31:89–101.
Giannakakis, G., Roussos, A., Andreou, C., Borgwardt, S.,
and Korda, A. I. (2025). Stress recognition identify-
ing relevant facial action units through explainable ar-
tificial intelligence and machine learning. Computer
Methods and Programs in Biomedicine, 259:108507.
Gronwall, D. (1977). Paced auditory serial-addition task: a
measure of recovery from concussion. Perceptual and
motor skills, 44(2):367–373.
Hara, K., Kataoka, H., and Satoh, Y. (2017). Learning
spatio-temporal features with 3d residual networks for
action recognition. In Proceedings of the IEEE In-
ternational Conference on Computer Vision (ICCV),
pages 3154–3160.
Hasani, B. and Mahoor, M. H. (2017). Facial expres-
sion recognition using enhanced deep 3d convolu-
tional neural networks. In Proceedings of the IEEE
conference on computer vision and pattern recogni-
tion workshops, pages 30–40.
Hosseini, S., Katragadda, S., Bhupatiraju, R. T., Ashkar, Z.,
Borst, C., Cochran, K., and Gottumukkala, R. (2021).
A multi-modal sensor dataset for continuous stress de-
tection of nurses in a hospital.
Jeon, T., Bae, H. B., Lee, Y., Jang, S., and Lee, S. (2021).
Deep-learning-based stress recognition with spatial-
temporal facial information. Sensors, 21(22):7498.
Kandemir, M. and Hamprecht, F. A. (2015). Computer-
aided diagnosis from weak supervision: a benchmark-
ing study. Computerized Medical Imaging and Graph-
ics: The Official Journal of the Computerized Medical
Imaging Society, 42:44–50.
Kandemir, M., Zhang, C., and Hamprecht, F. A. (2014).
Empowering multiple instance histopathology cancer
diagnosis by cell graphs. In Golland, P., Hata, N., Bar-
illot, C., Hornegger, J., and Howe, R., editors, Med-
ical Image Computing and Computer-Assisted Inter-
vention – MICCAI 2014, Lecture Notes in Computer
Science, pages 228–235. Springer International Pub-
lishing.
Korda, A. I., Giannakakis, G., Ventouras, E., Asvestas,
P. A., Smyrnis, N., Marias, K., and Matsopoulos,
G. K. (2021). Recognition of blinks activity pat-
terns during stress conditions using cnn and marko-
vian analysis. Signals, 2(1):55–71.
Kumar, S., Iftekhar, A. S. M., Goebel, M., Bullock, T.,
Maclean, M., Miller, M., Santander, T., Giesbrecht,
B., Grafton, S., and Manjunath, B. (2021). Stressnet:
Detecting stress in thermal videos. pages 998–1008.
Li, H., Yang, F., Xing, X., Zhao, Y., Zhang, J., Liu, Y., Han,
M., Huang, J., Wang, L., and Yao, J. (2021). Multi-
modal multi-instance learning using weakly corre-
lated histopathological images and tabular clinical in-
formation. In International Conference on Medical
Image Computing and Computer-Assisted Interven-
tion, pages 529–539. Springer.
Li, R. and Liu, Z. (2020). Stress detection using deep neural
networks. 20.
Li, S., Liu, F., and Jiao, L. (2022). Self-training multi-
sequence learning with transformer for weakly super-
vised video anomaly detection. In Proceedings of
the AAAI Conference on Artificial Intelligence, vol-
ume 36, pages 1395–1403.
Li, W. and Vasconcelos, N. (2015a). Multiple instance
learning for soft bags via top instances. In 2015 IEEE
Conference on Computer Vision and Pattern Recogni-
tion (CVPR), pages 4277–4285.
Li, W. and Vasconcelos, N. (2015b). Multiple instance
learning for soft bags via top instances. In 2015 IEEE
Conference on Computer Vision and Pattern Recogni-
tion (CVPR), pages 4277–4285. IEEE.
Luo, W., Liu, W., and Gao, S. (2017). A revisit of
sparse coding based anomaly detection in stacked
RNN framework. In 2017 IEEE International Con-
ference on Computer Vision (ICCV), pages 341–349.
IEEE.
Mahadevan, V., Li, W., Bhalodia, V., and Vasconcelos, N.
(2010). Anomaly detection in crowded scenes. In
2010 IEEE Computer Society Conference on Com-
puter Vision and Pattern Recognition, pages 1975–
1981. ISSN: 1063-6919.
Naegelin, M., Weibel, R. P., Kerr, J. I., Schinazi, V. R.,
La Marca, R., von Wangenheim, F., Hoelscher, C.,
and Ferrario, A. (2023). An interpretable machine
learning approach to multimodal stress detection in a
simulated office environment. Journal of Biomedical
Informatics, 139:104299.
Siam, A. I., Gamel, S. A., and Talaat, F. M. (2023). Au-
tomatic stress detection in car drivers based on non-
invasive physiological signals using machine learning
techniques. 35(17):12891–12904.
Sikka, K., Dhall, A., and Bartlett, M. (2013). Weakly super-
vised pain localization using multiple instance learn-
ing. In 2013 10th IEEE International Conference and
Workshops on Automatic Face and Gesture Recogni-
tion (FG), pages 1–8.
Sikka, K., Dhall, A., and Bartlett, M. S. (2014). Classifi-
cation and weakly supervised pain localization using
HEALTHINF 2025 - 18th International Conference on Health Informatics
294

multiple segment representation. Image and Vision
Computing, 32(10):659–670.
Stroop, J. R. (1935). Studies of interference in serial ver-
bal reactions. Journal of experimental psychology,
18(6):643.
Sultani, W., Chen, C., and Shah, M. (2018). Real-world
anomaly detection in surveillance videos. In 2018
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition, pages 6479–6488. IEEE.
Tian, Y., Pang, G., Chen, Y., Singh, R., Verjans, J. W.,
and Carneiro, G. (2021). Weakly-supervised video
anomaly detection with robust temporal feature mag-
nitude learning. In 2021 IEEE/CVF International
Conference on Computer Vision (ICCV), pages 4955–
4966. IEEE.
Tian, Y., Pang, G., Liu, F., Liu, Y., Wang, C., Chen,
Y., Verjans, J., and Carneiro, G. (2022). Con-
trastive transformer-based multiple instance learning
for weakly supervised polyp frame detection. In Med-
ical Image Computing and Computer Assisted Inter-
vention – MICCAI 2022: 25th International Confer-
ence, Singapore, September 18–22, 2022, Proceed-
ings, Part III, pages 88–98. Springer-Verlag.
Tong, T., Wolz, R., Gao, Q., Hajnal, J., and Rueckert, D.
(2013). Multiple instance learning for classification
of dementia in brain MRI. Medical image computing
and computer-assisted intervention : MICCAI ... In-
ternational Conference on Medical Image Computing
and Computer-Assisted Intervention, 16:599–606.
Tran, D., Bourdev, L., Fergus, R., Torresani, L., and Paluri,
M. (2015). Learning spatiotemporal features with 3d
convolutional networks. In 2015 IEEE International
Conference on Computer Vision (ICCV), pages 4489–
4497. IEEE.
Turcan, E., Muresan, S., and McKeown, K. (2021).
Emotion-infused models for explainable psychologi-
cal stress detection. In Proceedings of the 2021 Con-
ference of the North American Chapter of the Asso-
ciation for Computational Linguistics: Human Lan-
guage Technologies, pages 2895–2909. Association
for Computational Linguistics.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, L., and Polosukhin, I.
(2017). Attention is all you need. In Advances in
Neural Information Processing Systems, volume 30.
Curran Associates, Inc.
Viegas, C., Lau, S.-H., Maxion, R., and Hauptmann, A.
(2018). Towards independent stress detection: A de-
pendent model using facial action units. 2018 Interna-
tional Conference on Content-Based Multimedia In-
dexing (CBMI), pages 1–6.
Wan, B., Fang, Y., Xia, X., and Mei, J. (2020). Weakly
supervised video anomaly detection via center-guided
discriminative learning. In 2020 IEEE International
Conference on Multimedia and Expo (ICME), pages
1–6.
Wang, Y., Ma, J., Hao, B., Hu, P., Wang, X., Mei, J., and
Li, S. (2020). Automatic depression detection via fa-
cial expressions using multiple instance learning. In
2020 IEEE 17th International Symposium on Biomed-
ical Imaging (ISBI), pages 1933–1936.
Wu, P., Liu, J., Shi, Y., Sun, Y., Shao, F., Wu, Z., and Yang,
Z. (2020). Not only look, but also listen: Learning
multimodal violence detection under weak supervi-
sion. In Computer Vision – ECCV 2020: 16th Euro-
pean Conference, Glasgow, UK, August 23–28, 2020,
pages 322–339. Springer-Verlag.
Xu, Y., Mo, T., Feng, Q., Zhong, P., Lai, M., and Chang,
E. I.-C. (2014a). Deep learning of feature representa-
tion with multiple instance learning for medical image
analysis. In 2014 IEEE International Conference on
Acoustics, Speech and Signal Processing (ICASSP),
pages 1626–1630. ISSN: 2379-190X.
Xu, Y., Zhu, J.-Y., Chang, E., Lai, M., and Tu, Z. (2014b).
Weakly supervised histopathology cancer image seg-
mentation and classification. Medical image analysis,
18:591–604.
Xu, Y., Zhu, J.-Y., Chang, E., and Tu, Z. (2012). Multiple
clustered instance learning for histopathology cancer
image classification, segmentation and clustering. In
2012 IEEE Conference on Computer Vision and Pat-
tern Recognition, pages 964–971. ISSN: 1063-6919.
Zhang, H., Feng, L., Li, N., Jin, Z., and Cao, L. (2020).
Video-based stress detection through deep learning.
Sensors, 20(19):5552.
Zhang, J., Qing, L., and Miao, J. (2019). Temporal convo-
lutional network with complementary inner bag loss
for weakly supervised anomaly detection. In 2019
IEEE International Conference on Image Processing
(ICIP), pages 4030–4034.
Zhang, J., Yin, H., Zhang, J., Yang, G., Qin, J., and He, L.
(2022). Real-time mental stress detection using multi-
modality expressions with a deep learning framework.
Frontiers in Neuroscience, 16:947168.
Zhong, J.-X., Li, N., Kong, W., Liu, S., Li, T. H., and Li,
G. (2019). Graph convolutional label noise cleaner:
Train a plug-and-play action classifier for anomaly de-
tection. In 2019 IEEE/CVF Conference on Computer
Vision and Pattern Recognition (CVPR), pages 1237–
1246. IEEE.
APPENDIX
Correlations
In Figure 6 we show the correlations between network
predictions and action unit intensities for the different
task combinations. All correlations have been cor-
rected for false detection rates. The objective was to
identify the action units that were most pronounced
in the time steps that correspond to the highest net-
work predictions to introduce explainability into our
method.
Bag-Level Multiple Instance Learning for Acute Stress Detection from Video Data
295

(a) Task 1.2 vs. 1.3 (b) Task 2.1 vs. 2.2
(c) Task 3.1 vs. 3.2 (d) Task 3.1 vs. 3.3
(e) Task 4.1 vs. 4.2 (f) Task 4.1 vs. 4.3
Figure 6: Box plots showing the correlations between the network predictions and the action unit intensities for the different
task combinations. Positive (blue) and negative (red) correlations are shown one above the other in two different box plots.
HEALTHINF 2025 - 18th International Conference on Health Informatics
296
