
Improving Image Classification Tasks Using Fused Embeddings and
Multimodal Models
Artur A. Oliveira
a
, Mateus Espadoto
b
, Roberto Hirata Jr.
c
and Roberto M. Cesar Jr.
d
Institute of Mathematics and Statistics, University of S
˜
ao Paulo, Brazil
{arturao, mespadot, hirata, cesar}@ime.usp.br
Keywords:
Prompt Engineering, Guided Embeddings, Multimodal Learning, Clustering, t-SNE Visualization, Zero-Shot
Learning.
Abstract:
In this paper, we address the challenge of flexible and scalable image classification by leveraging CLIP embed-
dings, a pre-trained multimodal model. Our novel strategy uses tailored textual prompts (e.g., “This is digit 9”,
“This is even/odd”) to generate and fuse embeddings from both images and prompts, followed by clustering
for classification. We present a prompt-guided embedding strategy that dynamically aligns multimodal repre-
sentations to task-specific or grouped semantics, enhancing the utility of models like CLIP in clustering and
constrained classification workflows. Additionally, we evaluate the embedding structures through clustering,
classification, and t-SNE visualization, demonstrating the impact of prompts on embedding space separability
and alignment. Our findings underscore CLIP’s potential for flexible and scalable image classification, sup-
porting zero-shot scenarios without the need for retraining.
1 INTRODUCTION
Pre-trained multimodal models, such as CLIP (Rad-
ford et al., 2021), have showcased exceptional gener-
alization capabilities by aligning image and text rep-
resentations within a shared embedding space. These
models enable zero-shot learning, allowing for task
adaptation without explicit retraining. However, their
utility in scenarios such as unsupervised clustering
and constrained classification, where novel or com-
plex classification schemes arise, remains underex-
plored.
Constrained classification refers to workflows
where the assignment of samples to categories must
adhere to predefined semantic relationships. Unlike
traditional classification methods that rely solely on
static embeddings, constrained classification benefits
from dynamic, task-driven structures within the em-
bedding space. This paper introduces a framework
that leverages task-specific and grouped prompts to
guide embedding creation, aligning with such seman-
tic constraints.
Task-specific prompts explicitly align embeddings
a
https://orcid.org/0000-0002-3606-1687
b
https://orcid.org/0000-0002-1922-4309
c
https://orcid.org/0000-0003-3861-7260
d
https://orcid.org/0000-0003-2701-4288
with ground-truth classes, using descriptions like
“This is digit 0”, to emphasize precise class distinc-
tions. Grouped prompts, in contrast, define higher-
level semantic relationships, such as grouping “even”
and “odd” digits, facilitating tasks where broader
class groupings are sufficient or preferred. These
prompt strategies enable us to structure the embed-
ding space dynamically, providing a contrast to static
image embeddings, which serve as a baseline in our
analysis.
The contributions of this paper are as follows:
• We propose a novel prompt-guided embedding
strategy that dynamically aligns multimodal rep-
resentations to task-specific or grouped semantics,
advancing the utility of models like CLIP in clus-
tering and constrained classification workflows.
• We introduce a unified framework for evaluating
embedding structures through clustering, classifi-
cation, and visualization, highlighting the impact
of prompts on embedding space separability and
alignment.
• We conduct comprehensive experiments across
three datasets: MNIST, CIFAR-10, and CIFAR-
100 subsets, demonstrating that task-specific and
grouped prompts significantly outperform image-
only baselines in clustering and classification
tasks.
232
Oliveira, A. A., Espadoto, M., Hirata Jr., R. and Cesar Jr., R. M.
Improving Image Classification Tasks Using Fused Embeddings and Multimodal Models.
DOI: 10.5220/0013365600003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 2: VISAPP, pages
232-241
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

Through this work, we aim to bridge the gap
between general-purpose multimodal models and
task-specific workflows, showcasing how prompt-
conditioned embeddings can enhance clustering qual-
ity and constrained classification accuracy. This re-
search paves the way for exploring more flexible and
adaptable embedding strategies in multimodal learn-
ing.
The rest of this paper is organized as follows:
Section 2 reviews related work on multimodal learn-
ing, prompt design, and clustering techniques. Sec-
tion 3 presents our methodology, detailing the de-
sign of task-specific and grouped prompts, the em-
bedding framework, and the clustering and classifica-
tion workflows. Section 4 describes the experimen-
tal setup, datasets, and results, showcasing the ef-
fectiveness of prompt-guided embeddings. Section 5
explores the implications of our findings, address-
ing limitations and potential opportunities for future
work. Finally, Section 6 concludes with a summary
of contributions and directions for further research.
2 RELATED WORK
Recent advances in multimodal learning have enabled
models to effectively bridge visual and textual modal-
ities, creating shared embedding spaces that capture
semantic relationships across data types. These in-
novations have unlocked new capabilities, such as
zero-shot generalization, allowing models to adapt to
diverse tasks without additional fine-tuning. While
much of the focus has been on leveraging these em-
beddings for classification and retrieval, their poten-
tial for unsupervised tasks like clustering and con-
strained classification remains underexplored. This
section reviews advancements in multimodal learn-
ing, prompt design, and clustering techniques, high-
lighting key gaps in the current understanding of how
prompting strategies shape embedding spaces.
2.1 Multimodal Learning with Natural
Language Supervision
Advances in multimodal learning have introduced
models capable of aligning visual and textual modal-
ities in a shared embedding space. A prominent
example is CLIP (Contrastive Language–Image Pre-
training), which leverages natural language super-
vision to achieve zero-shot transfer across diverse
tasks. CLIP’s embedding space captures rich se-
mantic relationships, enabling generalization without
task-specific fine-tuning.
While CLIP’s zero-shot performance is well-
documented, less attention has been given to how its
embeddings can be structured for unsupervised tasks
like clustering and constrained classification. This
presents an opportunity to understand and optimize
the embedding space for these workflows.
2.2 Prompt Design in Multimodal
Models
Prompt design plays a critical role in adapting
general-purpose embeddings to task-specific needs.
Textual prompts guide models like CLIP by aligning
image embeddings with semantic concepts described
in natural language (Li et al., 2024; Allingham et al.,
2023; Huang et al., 2022). Well-crafted prompts have
been shown to improve zero-shot classification by re-
ducing the semantic gap between textual descriptions
and image representations.
Recent studies have expanded the scope of prompt
learning beyond task-specific classification. For in-
stance, (Huang et al., 2022) introduced an unsuper-
vised prompt learning framework for vision-language
models, while (Li et al., 2024) proposed prompt-
driven knowledge distillation to transfer knowledge
between models.
2.3 Clustering and Classification in
Embedding Spaces
Clustering is fundamental to understanding embed-
ding spaces, providing insights into data organiza-
tion and supporting classification tasks. Traditional
clustering methods such as k-means (Lloyd, 1982),
DBSCAN (Ester et al., 1996), and Spectral Cluster-
ing (Shi and Malik, 2000) have been primarily ap-
plied to unimodal embeddings derived from images
or text alone. Their application to fused multimodal
embeddings, where visual and textual features are in-
tegrated, to the best of our knowledge, remains lim-
ited.
Existing multimodal clustering methods, such as
Multimodal Clustering Networks (MCN) (Chen et al.,
2021), emphasize representation alignment across
modalities but often rely on static embeddings. These
approaches neglect the dynamic influence of prompts,
which can lead to semantic overlap and misalign-
ment between clusters and prompts. Methods like
MoDE (Ma et al., 2024) and ModalPrompt (Zeng
et al., 2024) incorporate prompts dynamically into
clustering workflows but are restricted to specific use
cases, leaving broader systematic approaches under-
developed.
Improving Image Classification Tasks Using Fused Embeddings and Multimodal Models
233

3 METHODOLOGY
This work explores how prompt-guided embeddings
influence clustering and classification tasks in mul-
timodal settings. By leveraging CLIP’s ability to
align visual and textual modalities, we design two
prompting strategies: task-specific, and grouped, to
guide embedding creation to reflect semantic relation-
ships in the data. As baseline, we consider the case
where no prompts are used, and clustering is per-
formed solely using image embeddings. The image-
only baseline evaluates clustering and classification
performance without the influence of textual prompts,
isolating the impact of semantic alignment introduced
by task-specific and grouped prompts. These strate-
gies are evaluated through a unified framework in-
volving clustering, classification, and visualization.
3.1 Prompt-Guided Embedding Design
We use three types of prompts to structure the embed-
ding space:
• Task-Specific Prompts: Class-level descriptions
aligned with ground-truth labels (e.g., “This is a
digit 0”). These prompts guide the embeddings to
reflect precise semantic distinctions.
• Grouped Prompts: Higher-level groupings that
capture relationships among multiple classes
(e.g., “This is an even digit” for MNIST or “This
is an animal” for CIFAR-10).
• Swapped Prompts: Intentionally misaligned
prompts used to evaluate the robustness of clus-
tering and classification.
For each prompt:
1. Text Embeddings: Prompts are tokenized and
encoded using CLIP’s text encoder.
2. Image Embeddings: Images are preprocessed
and encoded through CLIP’s image encoder.
3. Fused Embeddings: The final embeddings are
the average of the image and text embeddings,
creating a multimodal representation aligned with
the semantic intent of the prompt.
For the baseline (image-only embeddings), clus-
tering is performed solely on the image embeddings,
without incorporating text features.
3.2 Clustering Framework
The training pipeline, illustrated in Fig. 1 (left), con-
sists of the following steps:
1. Generating Fused Embeddings: Each training
sample is processed through the CLIP model to
produce image embeddings and paired with the
corresponding prompt to generate text embed-
dings. The image and text embeddings are aver-
aged to create fused multimodal representations,
reflecting the semantic intent of the prompts.
2. Applying Spectral Clustering: The fused em-
beddings are used as input for Spectral Cluster-
ing, with the number of clusters set adaptively
based on the dataset complexity. For datasets
with high inter-class similarity or irregular clus-
ter shapes, additional cluster centers were intro-
duced to better capture the nuanced structure of
the embedding space. The Spectral Clustering al-
gorithm maps the fused embeddings into a lower-
dimensional spectral space and identifies clusters
based on their proximity in this space. This ap-
proach is chosen for its flexibility and ability to
capture complex relationships within the embed-
ding space.
3. Cluster Label Assignment: Once the clusters are
formed, each cluster is assigned a representative
label using majority voting. For every cluster:
• The ground-truth labels of all samples within
the cluster are counted.
• The most frequent label is selected as the clus-
ter’s representative label.
This step ensures alignment between the clusters
and the dataset’s semantic structure.
4. Approximating Cluster Centroids: Since Spec-
tral Clustering does not provide explicit cluster
centroids, these are approximated as the mean po-
sition of all fused embeddings within each cluster.
Mathematically, for a cluster C
i
containing n sam-
ples with embeddings e
1
, e
2
, . . . , e
n
, the centroid c
i
is computed as:
c
i
=
1
n
n
∑
j=1
e
j
These centroids are used during the classification
phase to compute distances between test samples
and clusters.
Evaluation of Clustering Quality:
• The effectiveness of the clustering is eval-
uated using metrics such as silhouette
score (Rousseeuw, 1987), adjusted Rand
index (ARI) (Hubert and Arabie, 1985),
and adjusted normalized mutual information
(ANMI) (Vinh et al., 2009; Scikit-Learn,
2024).
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
234
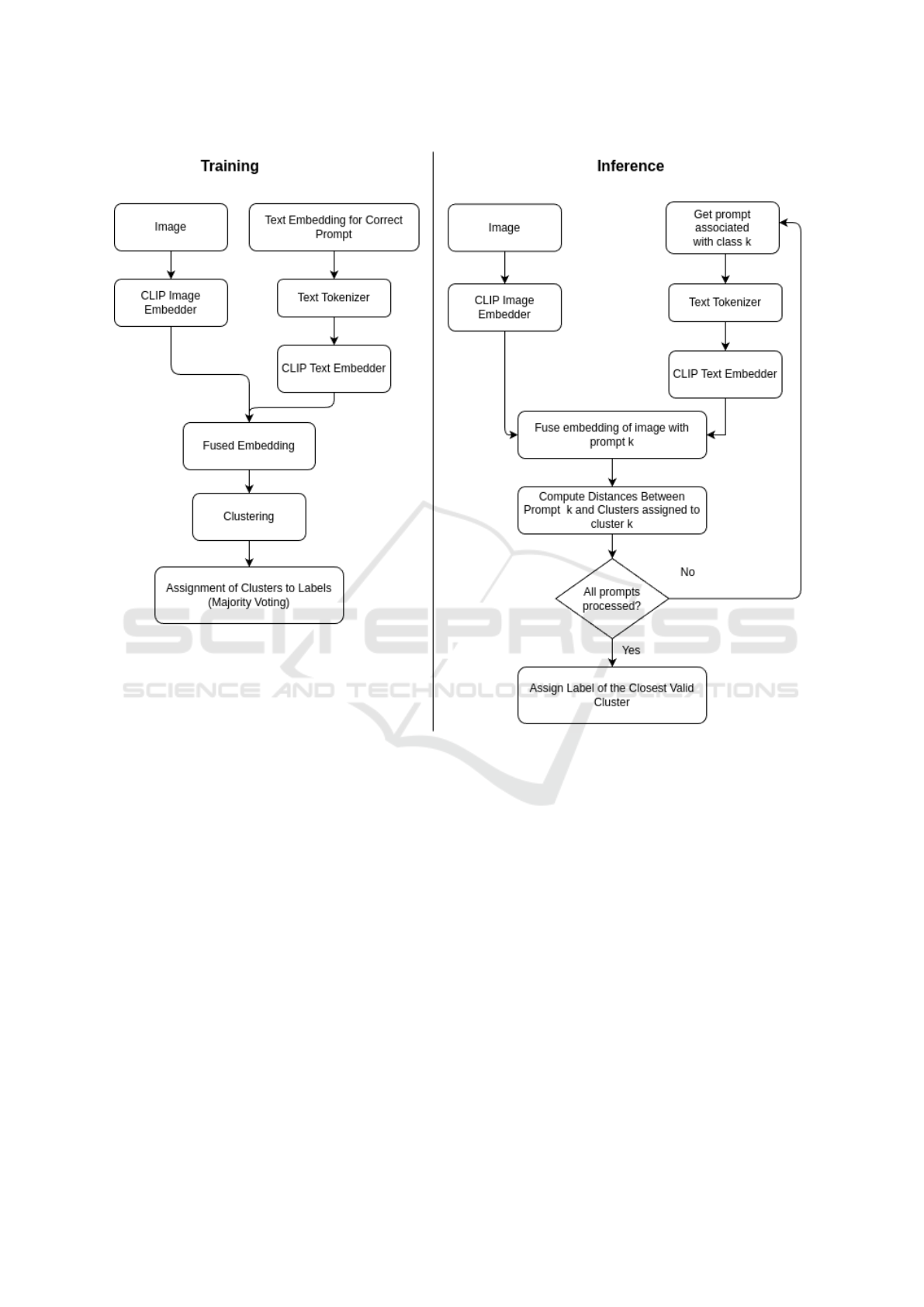
Figure 1: Diagrams showing the workflows for training (left) and inference (right). The training process involves generating
fused embeddings of images and prompts, followed by clustering and label assignment. The inference process iteratively
pairs an image with all class prompts to compute distances, determining the label of the closest cluster.
• These metrics provide insights into cluster sep-
arability, alignment with ground-truth labels,
and the overall quality of the embedding space
organization.
3.3 Classification Workflow
The inference workflow, shown in Fig. 1 (right), in-
volves:
1. Generating fused embeddings for test samples
paired iteratively with all prompts.
2. Filtering candidate clusters to only those corre-
sponding to the prompt’s intended class or group-
ing.
3. Assigning each test sample to the nearest cluster
based on the filtered candidates.
4. Using the assigned cluster’s label, determined
during training, as the predicted class.
This filtering mechanism ensures semantic con-
sistency between prompts and clusters, avoiding mis-
matches and improving classification reliability.
3.4 Visualization of Embedding Spaces
To qualitatively assess embedding space separability
and alignment, we employ t-SNE (van der Maaten
and Hinton, 2008) for dimensionality reduction. Vi-
sualizations compare the impact of different prompt-
ing strategies, color-coded by ground-truth and pre-
dicted labels. These plots highlight the influence of
prompt design on clustering and classification out-
comes.
Improving Image Classification Tasks Using Fused Embeddings and Multimodal Models
235

4 EXPERIMENTS AND RESULTS
This section presents the evaluation of prompt-guided
embeddings on clustering and classification tasks
across three datasets of varying complexity. The ex-
periments aim to assess the impact of task-specific,
grouped, and swapped prompts on embedding align-
ment and downstream performance, using image-only
embeddings as a baseline. We analyze the results both
qualitatively, through visualizations of the embedding
space, and quantitatively, using clustering and classi-
fication metrics.
4.1 Datasets and Experimental Setup
We conduct experiments using three datasets:
• MNIST (Deng, 2012), a simple dataset of
grayscale handwritten digits, rendered as 28x28
images;
• CIFAR-10 (Krizhevsky et al., a), which features
32x32 RGB images spanning 10 diverse classes;
• CIFAR-100 Subsets (Krizhevsky et al., b), with
five randomly selected subsets of 10 classes each.
These datasets represent increasing levels of com-
plexity, from clear class separability to greater inter-
class similarity and diversity. Each dataset undergoes
preprocessing for compatibility with the CLIP ViT-
B/32 backbone, including resizing images to 224x224
and normalizing them with CLIP’s default mean and
standard deviation. Textual prompts are tokenized
and encoded using CLIP’s text encoder.
4.1.1 Prompt Strategies
We evaluate the following prompting strategies:
• Task-Specific Prompts: Class-level descriptions
such as “This is digit 0,” aligned directly with
ground-truth labels.
• Grouped Prompts: Semantic groupings, such as
“This is a tool” or “This is a vehicle,” reflecting
broader relationships between classes.
• Swapped Prompts: Misaligned prompts used to
evaluate the robustness of clustering against noisy
semantic guidance.
• Baseline: Image-only embeddings, where no
prompts are used, providing a benchmark for eval-
uating the added value of text guidance.
4.1.2 Clustering and Classification Workflow
Embeddings are generated by fusing image and text
features, followed by clustering using Spectral Clus-
tering with the number of clusters set to match the
ground-truth classes. Cluster labels are assigned us-
ing majority voting over the training data. For the
baseline, clustering is performed solely on image em-
beddings.
Test samples are projected into the embedding
space, and classification is performed by assigning
each sample to the nearest cluster center. For prompt-
guided embeddings, filtering ensures alignment be-
tween test prompts and cluster labels.
4.2 Qualitative Analysis
To visualize the separability of the embedding space,
we employ t-SNE (t-distributed Stochastic Neighbor
Embedding). Figure 3 shows examples of CIFAR-10
embeddings under different prompting strategies.
Task-specific prompts yield compact and well-
separated clusters closely aligned with ground-truth
labels, as seen in Figs. 2a and 3a. Grouped
prompts, illustrated in Figs. 2c and 3c, produce
meaningful separability but exhibit slight overlap
within broader groupings. The swapped prompts,
shown in Figs. 2b and 3b, highlight the robustness
of the method, as clusters remain distinct despite
noisy guidance. The baseline embeddings, shown in
Figs. 2d and 3d, reveal significant overlap, underscor-
ing the limitations of image-only embeddings. Fig-
ures. 3a, 3c, 3b and 3d are plots for the test embed-
dings and their colors represent the assignment per-
formed by our test-time classification procedure de-
scribed in Section 3.
Similar trends are observed in MNIST and
CIFAR-100 visualizations. For MNIST, task-specific
prompts achieve near-perfect separability, while
CIFAR-100 datasets demonstrate the method’s scal-
ability despite increased complexity.
4.3 Metrics and Quantitative Setup
To quantitatively assess clustering performance, we
evaluate the following metrics:
• Silhouette Score: Measures intra-cluster com-
pactness relative to inter-cluster separation.
• Adjusted Rand Index (ARI): Evaluates the
agreement between predicted clusters and ground-
truth labels, adjusted for chance.
• Adjusted Normalized Mutual Information
(ANMI): Quantifies the shared information be-
tween cluster assignments and ground-truth la-
bels.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
236

(a) Task-Specific Prompts (Train). (b) Swapped Prompts (Train).
(c) Grouped Prompts (Train). (d) Baseline: Image-Only Embeddings (Train).
Figure 2: t-SNE visualizations for CIFAR-10 embeddings under different prompting strategies. Task-specific and grouped
prompts show superior clustering, while generic and image-only embeddings suffer from significant overlap.
4.4 Quantitative Results
Table 1 presents the results across datasets and
prompting strategies. For datasets with complex class
structures, the number of cluster centers was adap-
tively increased to reflect the embedding space’s com-
plexity, ensuring robust clustering and improved clas-
sification outcomes. Key observations include:
1. Task-Specific Prompts: Consistently achieve the
highest accuracy and clustering metrics, confirm-
ing their effectiveness in aligning embeddings
with semantic intent.
2. Grouped Prompts: Perform well in binary-class
tasks, where classes are grouped based on broader
semantic definitions (e.g., ”even” vs. ”odd”).
However, these results are not directly compara-
ble to task-specific prompts due to the reduced
number of classes and the binary nature of the
task.
3. Swapped Prompts: Maintain robust perfor-
mance, highlighting the resilience of prompt-
guided embeddings to noisy or misaligned textual
guidance.
4. Baseline (Image-Only): Achieves significantly
lower metrics across all datasets, underscoring the
importance of prompt-conditioned embeddings.
The results demonstrate the superiority of prompt-
guided embeddings for clustering and classification
tasks. Task-specific prompts consistently produce
compact, well-separated clusters, enabling high clas-
sification accuracy. Grouped prompts provide a flexi-
ble alternative for binary or grouped-class definitions,
while swapped prompts validate the robustness of the
approach.
Improving Image Classification Tasks Using Fused Embeddings and Multimodal Models
237

(a) Task-Specific Prompts (Test). (b) Swapped Prompts (Test).
(c) Grouped Prompts (Test). (d) Baseline: Image-Only Embeddings (Test).
Figure 3: t-SNE visualizations for CIFAR-10 test embeddings under different prompting strategies. Task-specific and grouped
prompts show superior clustering, while generic and image-only embeddings suffer from significant overlap. The colors
represent the assigned class using our classification strategy discussed in Section 3.
4.5 Summary of Findings
The experiments highlight the advantages of integrat-
ing textual prompts into embedding workflows, par-
ticularly for unsupervised clustering and constrained
classification. Task-specific prompts are most effec-
tive in aligning embedding spaces with semantic in-
tent, while grouped prompts offer a trade-off between
granularity and flexibility. The baseline results em-
phasize the limitations of image-only embeddings, re-
inforcing the value of multimodal guidance.
5 DISCUSSION
Our study highlights the potential of prompt-guided
embeddings to structure multimodal embedding
spaces for clustering and classification tasks. By
leveraging semantic cues encoded in task-specific and
grouped prompts, our approach fosters the creation of
compact and well-separated clusters. This alignment
between semantic intent and embedding structure un-
derpins the effectiveness of the proposed method, as
evidenced by improved clustering metrics and classi-
fication accuracy compared to generic prompts.
5.1 Strengths of Prompt-Guided
Embeddings
The experimental results validate our central hypoth-
esis: prompt design significantly impacts the struc-
ture of embedding spaces. Task-specific prompts
align closely with ground-truth labels, enabling pre-
cise class distinctions. Grouped prompts, on the other
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
238
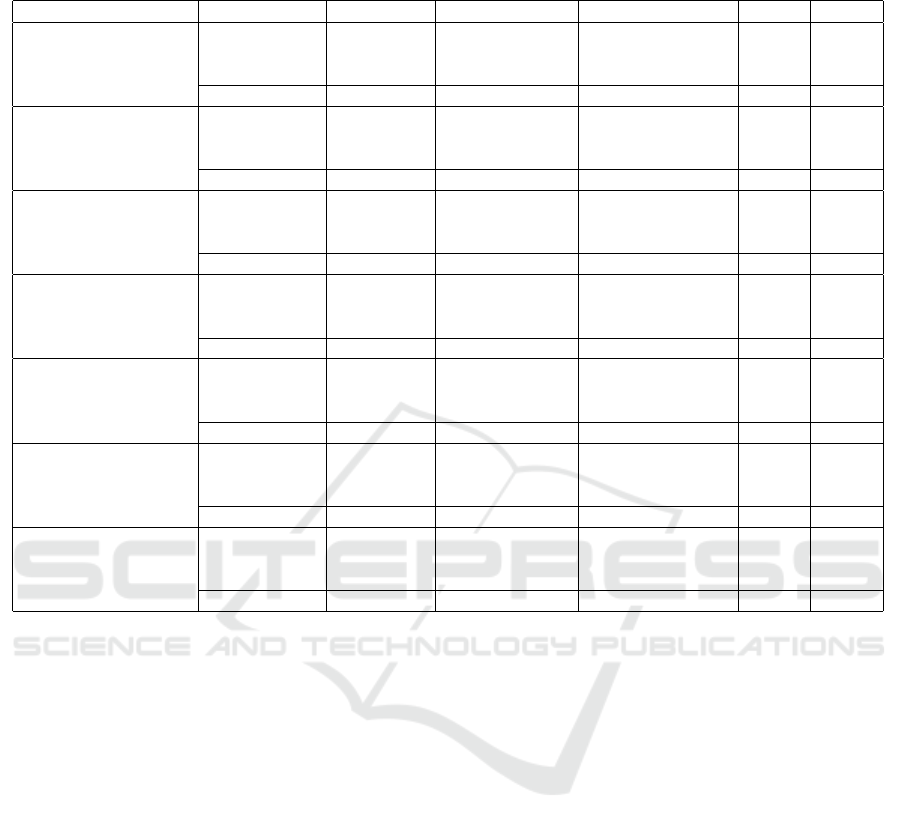
Table 1: Experimental Results Across Datasets and Prompt Strategies. Note that results for grouped prompts are derived from
binary-class tasks and are not directly comparable to task-specific or other multi-class prompt strategies.
Dataset Prompt Type Accuracy ↑ Missing Classes Silhouette Score ↑ ARI ↑ NMI ↑
MNIST
Task-Specific 0.8500 None 0.1747 0.7819 0.8964
Image Only 0.1073 None 0.0749 0.5885 0.7487
Task-Swapped 0.8667 None 0.1551 0.7560 0.8912
Task-Grouped 0.7487 None 0.1205 0.9995 0.9981
CIFAR-10
Task-Specific 0.8792 None 0.1390 0.8591 0.9277
Image Only 0.0993 None 0.0637 0.5771 0.7306
Task-Swapped 0.8790 None 0.0637 0.5768 0.7305
Task-Grouped 0.6232 None 0.0915 0.6523 0.7138
CIFAR-100 (Subset 1)
Task-Specific 0.702 None 0.1496 0.7815 0.8976
Image Only 0.144 None 0.0345 0.2042 0.4480
Task-Swapped 0.7 None 0.1333 0.7815 0.8976
Task-Grouped 0.52 None 0.0928 0.6749 0.7327
CIFAR-100 (Subset 2)
Task-Specific 0.888 None 0.1164 0.7417 0.8892
Image Only 0.069 None 0.0563 0.4169 0.6735
Task-Swapped 0.867 None 0.0998 0.6803 0.8640
Task-Grouped 0.746 None 0.1619 0.7306 0.7506
CIFAR-100 (Subset 3)
Task-Specific 0.674 None 0.0929 0.6644 0.8583
Image Only 0.1 None 0.0412 0.2190 0.4508
Task-Swapped 0.735 None 0.1105 0.7487 0.8884
Task-Grouped 0.504 None 0.0793 0.6338 0.7150
CIFAR-100 (Subset 4)
Task-Specific 0.796 None 0.1278 0.7944 0.9022
Image Only 0.064 None 0.0631 0.3835 0.6122
Task-Swapped 0.795 None 0.1354 0.8006 0.8985
Task-Grouped 0.506 None 0.2377 0.7192 0.7443
CIFAR-100 (Subset 5)
Task-Specific 0.634 [96] 0.0819 0.6528 0.8332
Image Only 0.133 None 0.0540 0.3174 0.5394
Task-Swapped 0.722 None 0.1167 0.7729 0.8976
Task-Grouped 0.537 None 0.0978 0.6697 0.7306
hand, capture broader semantic relationships, which
are especially useful in cases where granular class
distinctions are not necessary or desirable. Together,
these strategies demonstrate the flexibility and effi-
cacy of prompt-guided embeddings in enhancing rep-
resentation quality for unsupervised and constrained
tasks.
To address these challenges, we adapted our ap-
proach by increasing the number of cluster centers
relative to the number of classes in datasets with
higher complexity. This adjustment allowed the clus-
tering process to capture more nuanced structures in
the embedding space, improving classification per-
formance. While this refinement demonstrates the
method’s flexibility, it also highlights the importance
of considering cluster geometry in multimodal work-
flows.
5.2 Limitations and Challenges
5.2.1 Centroid-Based Classification
Assumptions
A key component of our method is the centroid-based
classification framework, which assumes that clusters
formed by the fused embeddings are compact and
well-separated. This assumption aligns with the ob-
served improvements in clustering metrics, suggest-
ing that prompt-guided embeddings indeed exhibit
such properties. However, centroid-based classifica-
tion may be suboptimal for scenarios where clusters
are irregularly shaped or exhibit significant overlap.
Alternative classification schemes, such as
nearest-neighbor methods or manifold-based
approaches, could mitigate these issues. Nearest-
neighbor methods are straightforward but would
undermine the central premise that prompts structure
the embedding space meaningfully. Manifold-based
approaches, while theoretically robust, introduce
additional complexity and computational overhead,
diverging from the primary focus of this work.
Addressing these scenarios presents an opportunity
Improving Image Classification Tasks Using Fused Embeddings and Multimodal Models
239

for future research.
5.2.2 Class Coverage in Clustering Assignments
One observation from our experiments, particularly
with the image-only baseline embeddings, is the po-
tential for some classes to remain unrepresented in the
clustering process. This issue arises when the embed-
ding space fails to separate certain classes effectively
or when clustering algorithms struggle with ambigu-
ous regions in the embedding space. However, rather
than being a limitation of the method, this underscores
the critical importance of prompt design.
Our results highlight that task-specific and
grouped prompts introduce strong semantic cues, cre-
ating more meaningful and well-separated clusters
that mitigate this issue. The absence of clusters for
certain classes with image-only baseline embeddings
validates our central hypothesis: specific and semanti-
cally aligned prompts play a pivotal role in structuring
embedding spaces for effective clustering and classi-
fication.
This finding reinforces the necessity of prompt-
guided approaches and provides a baseline for
demonstrating the substantial improvements achieved
with task-specific and grouped prompts. Future work
may explore how to adapt or extend these prompts for
more complex or imbalanced datasets, but the current
study effectively demonstrates their advantages over
generic baselines.
5.3 Unexplored Dynamics in
Multimodal Alignment
Our findings reveal intriguing dynamics in CLIP’s
embedding space. The poor performance of image-
only embeddings, even for simple datasets like
MNIST, contrasts sharply with the effectiveness of
text-guided embeddings, highlighting CLIP’s reliance
on multimodal alignment. The strong clustering per-
formance under swapped prompts further emphasizes
the dominant role of textual anchors in shaping se-
mantic structures.
These dynamics raise questions about the intrin-
sic quality of image embeddings in CLIP and how
textual prompts influence their semantic grounding.
While this study focuses on demonstrating the utility
of prompts for clustering and classification, future re-
search could delve deeper into the interplay between
multimodal alignment and individual modality per-
formance.
5.4 Future Directions
Our findings create space for further exploration in
several directions:
• Exploration of Additional Prompt Strategies:
Beyond task-specific and grouped prompts, al-
ternative designs such as adversarial or learned
prompts may further enhance embedding space
alignment.
• Advanced Classification Techniques: Investi-
gating more sophisticated classification frame-
works, such as manifold-based approaches, could
provide insights into scenarios where centroid-
based methods fall short.
• Dynamic Prompt Adaptation: Extending the
method to dynamically adapt prompts based
on dataset characteristics or clustering feedback
could improve generalization to diverse tasks.
• Class Coverage in Clustering: Addressing the
potential for unassigned clusters, particularly in
challenging settings, through hybrid clustering
methods or adaptive feedback mechanisms.
5.5 Broader Implications
The demonstrated impact of prompt design on em-
bedding structures underscores the importance of in-
tegrating semantic guidance into multimodal models.
This has implications beyond clustering and classi-
fication, potentially benefiting retrieval, generation,
and other downstream tasks. As multimodal models
continue to evolve, prompt-based strategies may serve
as a critical tool for bridging the gap between general-
purpose embeddings and task-specific needs.
By showcasing the interplay between prompts
and embedding structures, this work contributes to
the growing understanding of how natural language
supervision can enhance multimodal representation
learning. While challenges remain, the proposed
method provides a foundation for further exploration
and application in this rapidly advancing field.
6 CONCLUSION
This work introduced a novel strategy for leverag-
ing CLIP to create guided embeddings for cluster-
ing and classification tasks for image data. By uti-
lizing textual prompts, we demonstrated how embed-
ding spaces could be shaped to align with semantic re-
lationships in the data. Task-specific prompts enabled
fine-grained separability for individual classes, while
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
240

grouped prompts captured broader semantic group-
ings, offering flexibility for various application needs.
We showed that task-specific and grouped
prompts significantly enhance clustering performance
compared to image-only baselines, highlighting the
critical role of prompt design in structuring em-
bedding spaces. Furthermore, our method effec-
tively adapts to zero-shot and constrained classifica-
tion tasks, emphasizing the versatility of multimodal
models in unsupervised workflows.
While the primary focus was on evaluating the in-
fluence of prompts on clustering and classification,
our findings also underscore the potential for future
work in prompt optimization, dynamic embedding
structures, and applications to more complex datasets.
This study contributes to a growing understanding of
how natural language supervision can guide multi-
modal models, bridging the gap between zero-shot
generalization and task-specific optimization.
ACKNOWLEDGEMENTS
This work was funded partially by FAPESP project
2022/15304-4 and MCTI (law 8.248, PPI-Softex -
TIC 13 - 01245.010222/2022-44).
REFERENCES
Allingham, J. U., Ren, J., Dusenberry, M. W., Gu, X., Cui,
Y., Tran, D., Liu, J. Z., and Lakshminarayanan, B.
(2023). A simple zero-shot prompt weighting tech-
nique to improve prompt ensembling in text-image
models. In International Conference on Machine
Learning, pages 547–568. PMLR.
Chen, B., Rouditchenko, A., Duarte, K., Kuehne, H.,
Thomas, S., Boggust, A., Panda, R., Kingsbury, B.,
Feris, R., Harwath, D., et al. (2021). Multimodal
clustering networks for self-supervised learning from
unlabeled videos. In Proceedings of the IEEE/CVF
International Conference on Computer Vision, pages
8012–8021.
Deng, L. (2012). The mnist database of handwritten digit
images for machine learning research. IEEE Signal
Processing Magazine, 29(6):141–142.
Ester, M., Kriegel, H.-P., Sander, J., Xu, X., et al. (1996).
A density-based algorithm for discovering clusters in
large spatial databases with noise. In kdd, volume 96,
pages 226–231.
Huang, T., Chu, J., and Wei, F. (2022). Unsupervised
prompt learning for vision-language models. arXiv
preprint arXiv:2204.03649.
Hubert, L. and Arabie, P. (1985). Comparing partitions.
Journal of classification, 2:193–218.
Krizhevsky, A., Nair, V., and Hinton, G. Cifar-10 (canadian
institute for advanced research).
Krizhevsky, A., Nair, V., and Hinton, G. Cifar-100 (cana-
dian institute for advanced research).
Li, Z., Li, X., Fu, X., Zhang, X., Wang, W., Chen, S., and
Yang, J. (2024). Promptkd: Unsupervised prompt dis-
tillation for vision-language models. In Proceedings
of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition, pages 26617–26626.
Lloyd, S. (1982). Least squares quantization in pcm. IEEE
transactions on information theory, 28(2):129–137.
Ma, J., Huang, P.-Y., Xie, S., Li, S.-W., Zettlemoyer, L.,
Chang, S.-F., Yih, W.-T., and Xu, H. (2024). Mode:
Clip data experts via clustering. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition, pages 26354–26363.
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G.,
Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark,
J., Krueger, G., and Sutskever, I. (2021). Learning
transferable visual models from natural language su-
pervision.
Rousseeuw, P. J. (1987). Silhouettes: A graphical aid to
the interpretation and validation of cluster analysis.
Journal of Computational and Applied Mathematics,
20:53–65.
Scikit-Learn (2024). Adjusted Mutual Information
Score - Scikit-learn 1.5.2 Documentation. Scikit-
learn. https://scikit-learn.org/1.5/modules/generated/
sklearn.metrics.adjusted
mutual info score.html.
Shi, J. and Malik, J. (2000). Normalized cuts and image
segmentation. IEEE Transactions on Pattern Analysis
and Machine Intelligence, 22(8):888–905.
van der Maaten, L. and Hinton, G. (2008). Visualizing data
using t-sne. Journal of Machine Learning Research,
9(86):2579–2605.
Vinh, N. X., Epps, J., and Bailey, J. (2009). Information
theoretic measures for clusterings comparison: is a
correction for chance necessary? In Proceedings of
the 26th annual international conference on machine
learning, pages 1073–1080.
Zeng, F., Zhu, F., Guo, H., Zhang, X.-Y., and Liu, C.-L.
(2024). Modalprompt: Dual-modality guided prompt
for continual learning of large multimodal models.
arXiv preprint arXiv:2410.05849.
Improving Image Classification Tasks Using Fused Embeddings and Multimodal Models
241
