
Third-Party Library Recommendations Through Robust Similarity
Measures
Abhinav Jamwal
a
and Sandeep Kumar
b
Department of Computer Science and Engineering, Indian Institute of Technology Roorkee, Roorkee, India
Keywords:
Third-Party Library Recommendation, Similarity Measures, Jaccard Similarity, Collaborative Filtering,
App-Library Interactions.
Abstract:
This research systematically investigates the impact of different similarity measurements on third-party li-
brary (TPL) recommendation systems. By assessing the metrics of average precision (MP), average recall
(MR), average F1 score (MF), average reciprocal rank (MRR) and average precision (MAP) at different levels
of sparsity, the research demonstrates the significant impact of similarity measurements on recommendation
performance. Jaccard similarity consistently outperformed the measurements tested and performed better in
low-order and high-order app-library interactions. Its ability to reduce the number of sparse data sets and
achieve a balance between precision and recall makes it the optimal measurement for the TPL recommen-
dation. Other measurements, such as Manhattan, Minkowski, Cosine, and Dice, exhibited limitations to a
certain extent, most importantly under sparse conditions. This research provides a practical understanding
of the strengths and weaknesses of similarity measurements, which provides a basis for optimizing the TPL
recommendation system in practice.
1 INTRODUCTION
Rapid growth in mobile app development has fur-
ther intensified competition, requiring developers to
quickly publish and update apps to meet changing
user demands
1
. Third-party libraries (TPLs) have be-
come part of this process, increasing software qual-
ity and reducing development efforts (Li et al., 2021).
Studies show that the average Android app on Google
Play uses about 11.81 TPLs(He et al., 2020). How-
ever, the wide availability of TPLs makes it difficult
to choose the most suitable libraries and combinations
of libraries (Lamothe and Shang, 2020; Salza et al.,
2020). Recommendation systems mitigate this limi-
tation by allowing developers to effectively find suit-
able TPLs (Nguyen et al., 2020).
Collaborative filtering (CF) has achieved ad-
mirable performance in a variety of recommenda-
tion tasks (Kangas, 2002). Methods such as Li-
bRec (Thung et al., 2013a) and CrossRec (Nguyen
et al., 2020) leverage CF-based similarity approaches
to suggest libraries. However, these approaches only
a
https://orcid.org/0000-0002-0213-3590
b
https://orcid.org/0000-0002-3250-4866
1
https://www.statista.com/statistics/289418/
rely on low-order interactions and overlook high-
order relations between apps and libraries (He et al.,
2020). Furthermore, the performance of these sys-
tems is highly dependent on the choice of similarity
measures, which have a direct influence on the qual-
ity of the recommendation.
The role of similarity measures is well studied
in machine learning and classification, particularly in
K-Nearest Neighbors (KNN), where distance metrics
significantly impact performance (Abu Alfeilat et al.,
2019). Although optimization techniques exist for
classification, their application in TPL recommenda-
tion remains underexplored. This paper systemati-
cally examines the impact of similarity measures on
the TPL recommendation. Building on existing work
in classification (Zhang, 2021) and TPL recommen-
dation (Li et al., 2024), we analyze the effects of co-
sine, Jaccard, and Dice similarity on recommendation
performance. Our study aims to:
• Identify the strengths and limitations of different
similarity measures in the TPL recommendation.
• Evaluate your impact on low-order and high-order
app-library interactions.
• Provide actionable insights to improve the accu-
racy and efficiency of TPL recommendation sys-
Jamwal, A. and Kumar, S.
Third-Party Library Recommendations Through Robust Similarity Measures.
DOI: 10.5220/0013366600003928
In Proceedings of the 20th International Conference on Evaluation of Novel Approaches to Software Engineering (ENASE 2025), pages 635-642
ISBN: 978-989-758-742-9; ISSN: 2184-4895
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
635

tems.
Our contributions include a comprehensive anal-
ysis of similarity measures and their impact on rec-
ommendation quality, which elevates the state of TPL
recommender systems.
2 RELATED WORK
Third-party library (TPL) recommendation systems
have gained attention for accelerating software devel-
opment by assisting developers in selecting appropri-
ate libraries. Early research focused on recommend-
ing specific APIs or program snippets within TPLs.
Zheng et al. (Zheng et al., 2011) proposed an ap-
proach for API replacement during software develop-
ment, while Thung et al. (Thung et al., 2013b) lever-
aged textual feature requests to suggest relevant API
methods.
Beyond API recommendations, researchers have
explored app-library usage patterns to recommend en-
tire TPLs. Saied et al. (Saied and Sahraoui, 2016)
developed COUPMiner, which combined client- and
library-based mining to uncover trends in the use of
app-library. Ouni et al. (Ouni et al., 2017) introduced
LibFinder, which used semantic similarity between
source codes and TPLs for library detection. More
recently, Saied et al. (Saied et al., 2018) proposed
LibCUP, a multilayer clustering approach for catego-
rizing TPLs based on usage history.
Collaborative filtering (CF) has played a signif-
icant role in the recommendation of TPL. LibRec
(Thung et al., 2013a) was among the first to apply
CF to Java projects, integrating association rule min-
ing. Nguyen et al. (Nguyen et al., 2020) introduced
CrossRec, a CF-based approach for open-source soft-
ware projects, while He et al. (He et al., 2020) de-
veloped LibSeek, which incorporated matrix factor-
ization and adaptive weighting for diversified recom-
mendations. However, these approaches primarily
relied on low-order interactions, often overlooking
high-order dependencies. To address this, GRec (Li
et al., 2021) modeled the relationships between the
application and the library as graphs, using graph neu-
ral networks (GNNs) to capture low- and high-order
interactions, significantly enhancing the precision of
the recommendation. HGNRec (Li et al., 2024) fur-
ther refined this approach by decomposing the app-
library graph into two homogeneous graphs for effi-
cient aggregation of interaction patterns.
Despite advances in TPL recommendation, the
impact of similarity measures on TPL recommen-
dations remains underexplored. This work bridges
this gap by systematically evaluating their effects
on TPL prediction and recommendation, drawing in-
sights from similarity-based classification techniques.
3 MOTIVATING EXAMPLE
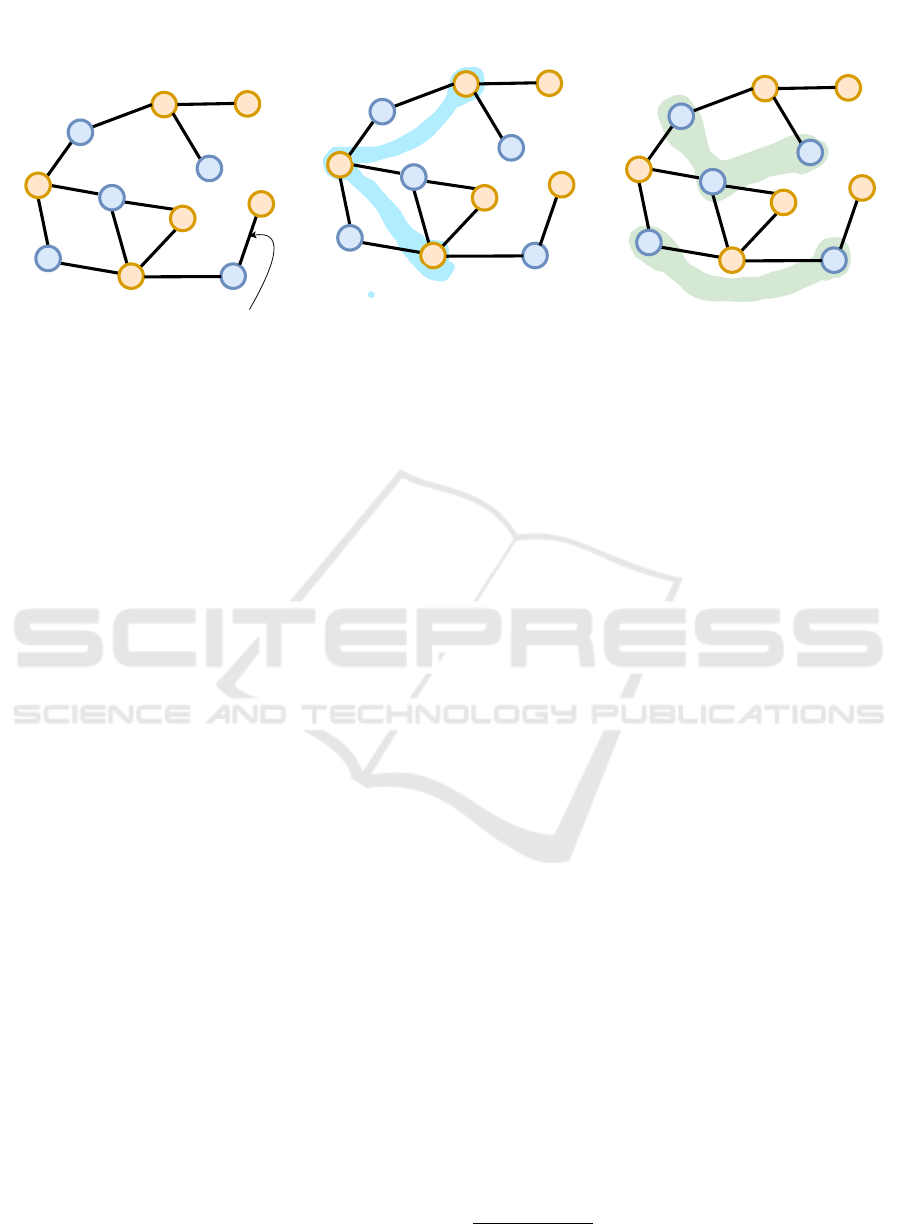
Figure 1 illustrates the role of similarity measures in
interactions between the app and the library. The left-
most graph represents an interaction graph, where
apps (A1–A6) are connected to libraries (L1–L5) based
on usage, with edges indicating app-library utiliza-
tion. The middle graph highlights Similar Apps (e.g.,
A1, A2, and A5), identified using measures like Jaccard
or Cosine, reflecting shared library usage. The right-
most graph identifies Similar Libraries (e.g., L1, L2,
and L4), representing frequently used libraries across
different apps. These similarity patterns improve the
recommendation process by identifying libraries rele-
vant to a given application.
This example demonstrates the importance of sim-
ilarity measures in capturing both low-order (direct)
and high-order (indirect) interactions within app-
library graphs:
• Low-order interactions: Libraries directly con-
nected to an app (e.g., L1 and L2 for A1) are pri-
mary recommendation candidates.
• High-order interactions: Libraries connected via
multiple hops (e.g., L4 and L5) capture broader
patterns of co-usage, providing additional recom-
mendations.
Despite their importance in the TPL recommenda-
tion, the impact of similarity measures remains under-
explored. This study investigates their role in shaping
app-library relationships and improving recommen-
dation effectiveness.
4 METHODOLOGY
The effectiveness of third-party library (TPL) recom-
mendation relies on accurately identifying libraries
most likely to be adopted by an application based on
app-library interaction patterns. This study integrates
K-Nearest Neighbor (KNN) similarity measures with
Graph Neural Networks (GNN) to analyze the im-
pact of different distance measures on recommenda-
tion performance, addressing the gap in understand-
ing their role in TPL recommendations.
At the core of this methodology is the app-library
interaction matrix, a binary representation that indi-
cates whether an application has utilized a particu-
lar library. From this matrix, App Similarity Matri-
ces and Library Similarity Matrices are constructed
ENASE 2025 - 20th International Conference on Evaluation of Novel Approaches to Software Engineering
636
L1
L2
A1
A2
A3
L4
L3
A4
A5
L5
A6
Similar Apps shown
by shaded regions
Similar Libraries shown
by shaded regions
Similar Apps: 𝐴1, 𝐴2, 𝐴5
Similar Apps: 𝐴3, 𝐴4, 𝐴6
Similar Libraries: L1, L2, L4
Similar Libraries: L3, L5
L1
L2
A1
A2
A3
L4
L3
A4
A5
L5
A6
Interaction Graph
App Node (A1, A2, etc)
Library Node (L1, L2, etc.)
App-Library Interaction
L1
L2
A1
A2
A3
L4
L3
A4
A5
L5
A6
Figure 1: Visualization of App-Library Interactions. The interaction graph (left) shows connections between apps and li-
braries. Similar apps (middle) and similar libraries (right) are identified using KNN similarity, highlighted by shaded regions.
using Jaccard, Cosine, Dice, Minkowski, and Man-
hattan similarity measures. As shown in Figure 2,
these matrices facilitate the identification of neigh-
bouring applications and libraries based on shared in-
teraction patterns. Recognizing such neighbors is es-
sential to generate accurate and relevant recommen-
dations, which form the foundation of the similarity-
driven recommendation process.
4.1 Impact of Similarity Measures
To quantify proximity between apps and libraries,
we employ similarity measures such as Jaccard, Co-
sine, Dice, Minkowski, and Manhattan. These mea-
sures construct neighbour matrices that capture inter-
actions between the app and the library, which form
the basis for structural analysis, as shown in Figure 2.
Jaccard similarity evaluates shared elements between
two sets, emphasizing common library usage, while
cosine similarity measures the alignment of interac-
tion vectors. The similarity of the slices, a vari-
ant of Jaccard, assigns greater weight to the shared
interactions. Manhattan distance computes absolute
differences, and the Minkowski distance generalizes
the Manhattan and Euclidean distances by adjusting
a sensitivity parameter. These measures identify app
and library neighbors, providing structural informa-
tion on app-library relationships.
The proposed framework integrates these simi-
larity measures into a GNN-based recommendation
pipeline, as shown in Figure 3. Interaction data
are preprocessed and split into training and test-
ing sets, with similarity-based neighbour identifi-
cation enhancing the app-library interaction graph.
The GNN propagates information through this aug-
mented graph, leveraging both direct interactions and
similarity-based neighbourhoods to learn node em-
beddings. These embeddings encode the relation-
ship between the application and the library, en-
abling ranked library recommendations. The frame-
work is evaluated using precision, recall, F1 score,
mean average precision (MAP), and mean reciprocal
rank (MRR) to systematically assess recommenda-
tion quality, ranking effectiveness, and retrieval per-
formance. This approach highlights the role of simi-
larity measures in improving the accuracy of the rec-
ommendation and capturing structural dependencies.
5 EXPERIMENTAL SETUP AND
RESULTS
This section presents the experimental setup used to
evaluate the framework, followed by the results ob-
tained. The evaluation is carried out on the publicly
available MALib-Dataset
2
, specifically designed for
third-party library (TPL) recommendation tasks. The
data set consists of 31,432 Android apps and 752
distinct TPLs, represented as nodes in a graph, with
537,011 app-library usage records forming the edges.
Constructed by collecting 61,722 Android ap-
plications from Google Play via AndroidZoo
3
, the
dataset captures app-library interactions, allowing a
comprehensive analysis of the use of third-party li-
braries (TPL). To ensure accuracy, TPL classifications
were cross-verified with libraries available in Maven
and GitHub, expanding the data set to 827 distinct
TPLs and 725,502 app library usage records. With its
extensive node and edge scale, the dataset supports
2
https://github.com/malibdata/MALib-Dataset
3
https://androzoo.uni.lu
Third-Party Library Recommendations Through Robust Similarity Measures
637

L1 L2 L3 L4 L5
A1
A2
A3
A4
A5
A6
A1
A2
A3
A4
A5
A6
L1
L2
L3
L4
L5
1
0
1
111
1 1
0
1
0 0 0
0
0
1
0
0
0
0
0
0
0
1
0
0
0
0
0
0
L1 L2 L3 L4 L5
A1 A2
A3 A4 A5
A6
Similarity Measure
L1
L2
L3
L4
L5
L1 L2 L3 L4 L5
A1
A2
A3
A4
A5
A6
A1 A2
A3 A4 A5
A6
1.0 0.25 0.0 0.0 0.5 0.0
0.0
0.00.330.51.00.25
0.0
0.0
0.0
0.5
0.0
0.0
0.33
0.5 1.0
1.0
1.0
1.0
0.0
0.0
0.0
0.33 0.33
0.0
0.33
0.0
0.33
0.0
0.0
0.0
App Similarity Matrix
Library Similarity Matrix
1.0
1.0
1.0
1.0
1.0
0.25 0.50 0.33 0.0
0.25
0.50
0.33
0.0
0.0
0.0
0.33
0.66 0.25
0.0
0.33
0.0
0.25 0.0
0.66
0.0
1 1
1
1
1 1
1
1
1
1
1
1
1
1
1
1
1
App neighbour Matrix
Library neighbour Matrix
SimApp ≥ 0.5
SimLib ≥ 0.5
App-Library Links
1 = connected, 0 = not connected
1
1
Figure 2: Illustration of identifying neighbouring nodes using similarity measures.
low- and high-order relationship modeling, making
it well suited for graph-based recommendation meth-
ods. The publicly accessible data set
2
ensures repro-
ducibility and validation by the research community.
5.1 Network Settings
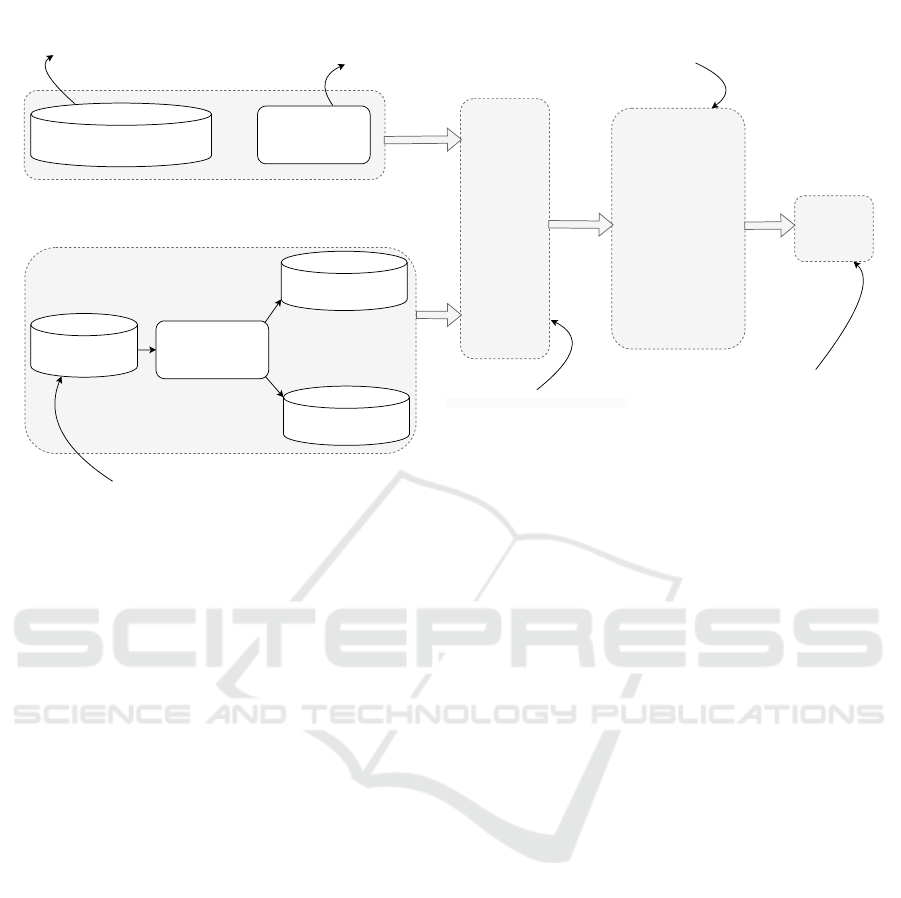
Figure 3 illustrates the architecture of the GNN-based
framework, integrating various KNN similarity mea-
sures (e.g., Jaccard, Cosine, Dice, Minkowski, Man-
hattan) to assess their impact on the TPL recommen-
dation. The framework begins with the app-library in-
teraction matrix, where KNN similarity is applied to
construct app- and library-neighbor matrices, enhanc-
ing the structural information within the graph. For
evaluation, a cross-validation approach is employed.
Given an app u in the interaction matrix M, the rm li-
braries (rm ∈ {1, 3, 5}) are randomly removed to cre-
ate an incomplete representation of the app, and the li-
braries removed serve as the ground truth. The model
is trained on the remaining interactions and the num-
ber of selected neighbors k is varied to analyze its ef-
fect on performance. The evaluation is carried out us-
ing the metrics calculated at K = [5, 10, 20], ensuring
a comprehensive assessment of the similarity mea-
sures. This experimental setup enables a systematic
evaluation of KNN similarity measures to improve the
accuracy of the TPL recommendation.
5.2 Result Analysis
This study investigates the impact of different sim-
ilarity measures, namely Cosine, Dice, Minkowski,
Jaccard, and Manhattan, on TPL recommendation.
The evaluation was carried out on datasets with vary-
ing levels of sparsity (rm = 1, 3, 5), where rm rep-
resents the number of libraries removed from the
record of each app during the training phase. Met-
rics such as mean precision (MP), mean recall (MR),
mean F1 score (MF), mean reciprocal rank (MRR)
and mean average precision (MAP) were calculated
at K = 5, 10, 20. The results are summarized in Ta-
ble 1, and the trends in these metrics are visualized in
Figure 4.
The results reveal that the Jaccard similarity con-
sistently outperformed the other measures in multiple
evaluation scenarios. For rm = 1, Jaccard achieved
an MF of 0.263, an MRR of 0.646, and a MAP
of 0.646 in K = 5, outperforming the Cosine, Dice,
Minkowski, and Manhattan similarity measures. At
K = 10 and K = 20, Jaccard maintained its superi-
ority, demonstrating its robustness in accurately cap-
turing shared interactions between the app and the li-
brary even at higher values of K. In contrast, cosine
and Dice similarity measures struggled to achieve
competitive performance, with lower MF values of
0.223 and 0.226 at K = 5, respectively. These results
reflect their limitations in handling sparse data scenar-
ios.
For rm = 3, the advantage of the Jaccard similar-
ity became even more pronounced. It achieved an MF
ENASE 2025 - 20th International Conference on Evaluation of Novel Approaches to Software Engineering
638
GNN
algorithm
Recommendations
and Evaluation
Results
Distance Measure
Selecting the
Distance
measure
Dataset
Preparation
Similarity
Calculation
Train Dataset
Test Dataset
Collect app-library interaction data in matrix form,
capturing the relationships between apps and libraries.
Similarity between
apps or libraries
Split the dataset
Define the similarity metric to evaluate
relationships (e.g., Jaccard, Cosine, Manhattan)
Choose the optimal
similarity measure
Use a Graph Neural Network (GNN)
to learn embeddings and predict
library recommendations
Rank libraries for each app using GNN-generated
embeddings and recommend top-N libraries
Present the final output as the
top-N recommended libraries
for each app
Figure 3: The framework of our experiments designed to evaluate the impact of various distance measures on the performance
of the GNN-based recommendation system.
of 0.570 and an MAP of 0.841 at K = 5, which differ-
entiates it as the most effective similarity measure in
moderate sparsity. Minkowski and Manhattan mea-
sures showed competitive performance, with compa-
rable MAP scores of K = 10 and K = 20. However,
Jaccard consistently ranked higher in MF and MRR,
highlighting its ability to balance precision and recall
while maintaining consistency in ranking. The cosine
and Dice measures continued to lag, particularly in re-
call and MAP, showing their limitations in effectively
capturing app-library interactions.
At the highest level of sparsity, rm = 5, the Jaccard
similarity once again emerged as the leading mea-
sure. It achieved an MF of 0.672 and a MAP of
0.879 at K = 5, underscoring its robustness even in
highly sparse data sets. Manhattan and Minkowski’s
measures followed closely, delivering competitive re-
sults but falling slightly short in recall and ranking-
based metrics. The dice and cosine measures strug-
gled to adapt to the sparse setting, with their best MF
values reaching only 0.599 and 0.598, respectively.
The performance gap between Jaccard and other mea-
sures was more pronounced at K = 20, where Jaccard
achieved superior MAP and MRR scores, demon-
strating its effectiveness in retrieving relevant libraries
even under challenging conditions.
The trends observed in Figure 4 further validate
these findings. The Mean Precision (MP) curves in-
dicate that Jaccard consistently achieved the high-
est MP, reflecting its ability to effectively prioritize
relevant libraries. Similarly, the Mean Recall (MR)
curves highlight the superior recall values achieved
by the Jaccard and Manhattan measures, particularly
at K = 20. This demonstrates their ability to capture
a higher proportion of relevant libraries. The Mean
F1 Score (MF) curves reinforce Jaccard’s dominance,
as its harmonic balance of precision and recall con-
sistently exceeded that of other measures. The Mean
Reciprocal Rank (MRR) and Mean Average Precision
(MAP) metrics further emphasize Jaccard’s ability to
rank relevant libraries higher in the recommendation
list, ensuring that developers receive accurate and ac-
tionable recommendations.
The loss reduction curve shown in Figure 4(f) pro-
vides additional insights into the training dynamics of
each similarity measure. Jaccard and Manhattan mea-
sures demonstrated the fastest and most stable loss re-
duction, reflecting their ability to effectively minimize
errors and converge to an optimal solution. In con-
trast, the cosine and Dice measures exhibited slower
convergence and less stable loss reduction, indicating
challenges in learning high-quality embeddings under
sparse conditions. The superior loss reduction per-
formance of Jaccard and Manhattan highlights their
efficiency in leveraging the structural and interaction
information encoded in the app-library dataset.
The analysis demonstrates the critical role of sim-
ilarity measures in influencing the quality of TPL
Third-Party Library Recommendations Through Robust Similarity Measures
639
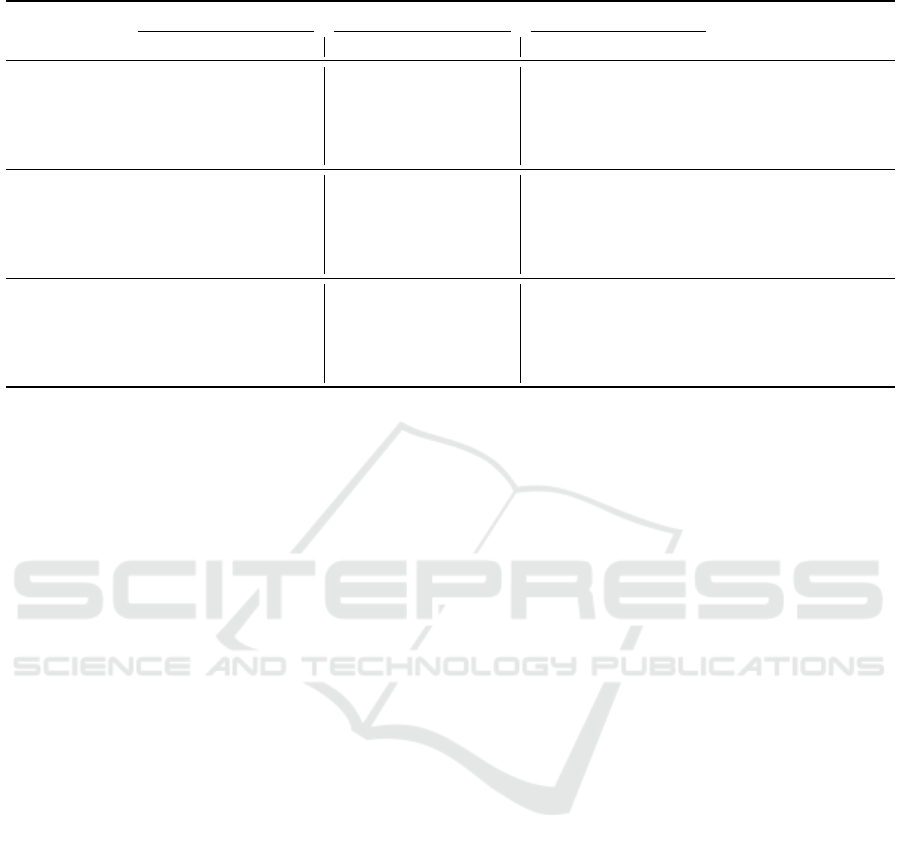
Table 1: Performance Comparison of Different Similarity Measures.
Dataset Similarity K = 5 K = 10 K = 20
MP MR MF MRR MAP MP MR MF MRR MAP MP MR MF MRR MAP
rm=1
Cosine 0.134 0.668 0.223 0.510 0.510 0.076 0.761 0.138 0.523 0.523 0.042 0.843 0.080 0.529 0.529
Dice 0.136 0.679 0.226 0.524 0.524 0.077 0.773 0.141 0.536 0.536 0.043 0.853 0.081 0.542 0.542
Manhattan 0.154 0.768 0.256 0.622 0.622 0.084 0.837 0.152 0.632 0.632 0.044 0.889 0.085 0.635 0.635
Minkowski 0.154 0.769 0.256 0.625 0.625 0.084 0.840 0.153 0.634 0.634 0.044 0.888 0.085 0.638 0.638
Jaccard 0.158 0.789 0.263 0.646 0.646 0.085 0.854 0.155 0.655 0.655 0.045 0.907 0.086 0.658 0.658
rm=3
Cosine 0.399 0.672 0.500 0.824 0.780 0.231 0.779 0.356 0.828 0.740 0.127 0.854 0.221 0.829 0.704
Dice 0.400 0.675 0.502 0.826 0.781 0.233 0.784 0.358 0.830 0.739 0.128 0.860 0.222 0.832 0.703
Manhattan 0.404 0.681 0.506 0.829 0.785 0.233 0.784 0.359 0.833 0.745 0.127 0.855 0.221 0.834 0.711
Minkowski 0.406 0.684 0.509 0.827 0.782 0.233 0.785 0.359 0.830 0.744 0.127 0.856 0.221 0.832 0.711
Jaccard 0.454 0.766 0.570 0.882 0.841 0.250 0.843 0.386 0.885 0.811 0.133 0.894 0.231 0.886 0.785
rm=5
Cosine 0.590 0.597 0.593 0.899 0.850 0.364 0.736 0.487 0.900 0.795 0.205 0.827 0.328 0.901 0.746
Dice 0.595 0.603 0.599 0.894 0.848 0.365 0.739 0.489 0.896 0.795 0.205 0.830 0.329 0.896 0.746
Manhattan 0.567 0.575 0.571 0.874 0.825 0.357 0.722 0.478 0.877 0.768 0.202 0.818 0.324 0.877 0.719
Minkowski 0.566 0.573 0.569 0.872 0.824 0.356 0.720 0.476 0.875 0.767 0.202 0.817 0.324 0.876 0.718
Jaccard 0.668 0.676 0.672 0.916 0.879 0.393 0.795 0.526 0.918 0.834 0.214 0.865 0.343 0.918 0.796
recommendations. Among the evaluated measures,
the Jaccard similarity consistently emerged as the
most effective, excelling in all metrics and K-values.
Its robustness and reliability in capturing both low-
order and high-order interactions make it the pre-
ferred choice for TPL recommendation tasks. Al-
though Manhattan and Minkowski’s measures offered
competitive alternatives, their performance lagged be-
hind Jaccard’s. The findings emphasize the impor-
tance of selecting an appropriate similarity measure to
ensure accurate and efficient recommendations, par-
ticularly in sparse data scenarios.
6 DISCUSSION
This study underscores the critical role of similarity
measures in third-party library (TPL) recommenda-
tion systems. Among the measures evaluated, the Jac-
card similarity consistently outperformed others in all
metrics and values of K, as shown in Table 1 and Fig-
ure 4. Its ability to capture low-order (direct) and
high-order (multi-hop) interactions makes it particu-
larly effective in sparse datasets. The high mean F1
score (MF), the mean reciprocal rank (MRR), and the
mean average precision (MAP) further highlight its
balanced precision-recall trade-off and ranking effec-
tiveness.
Manhattan and Minkowski measures performed
well in moderately sparse scenarios (rm = 3) but
showed reduced effectiveness in highly sparse set-
tings (rm = 5). Cosine and Dice similarity, relying
on vector alignment and weighted intersections, ex-
hibited consistent limitations across all sparsity lev-
els, particularly in capturing complex app-library in-
teractions. Jaccard’s efficiency in learning optimal
embeddings and its faster convergence during training
reinforce its suitability for the TPL recommendation.
These findings emphasize the importance of selecting
appropriate similarity measures to improve the preci-
sion and efficiency of recommendations.
7 CONCLUSION
This study evaluated the impact of similarity mea-
sures on TPL recommendation, focusing on mean
precision (MP), mean recall (MR), mean F1 score
(MF), mean reciprocal rank (MRR) and mean aver-
age precision (MAP) at varying sparsity levels. The
results show that Jaccard similarity is the most ef-
fective, capturing both low-order (direct) and high-
order (multihop) app-library interactions. Its empha-
sis on shared interactions and balanced union enables
superior performance in all metrics. Although Man-
hattan and Minkowski performed well in moderately
sparse scenarios, they were outperformed by Jaccard
in highly sparse datasets. The cosine and Dice mea-
sures struggled with sparse interaction matrices, re-
sulting in lower performance. These insights high-
light the strengths and limitations of different simi-
larity measures, which guide the optimization of TPL
recommendation systems. Future work may explore
additional similarity measures and hybrid approaches
to enhance adaptability across diverse datasets.
ENASE 2025 - 20th International Conference on Evaluation of Novel Approaches to Software Engineering
640
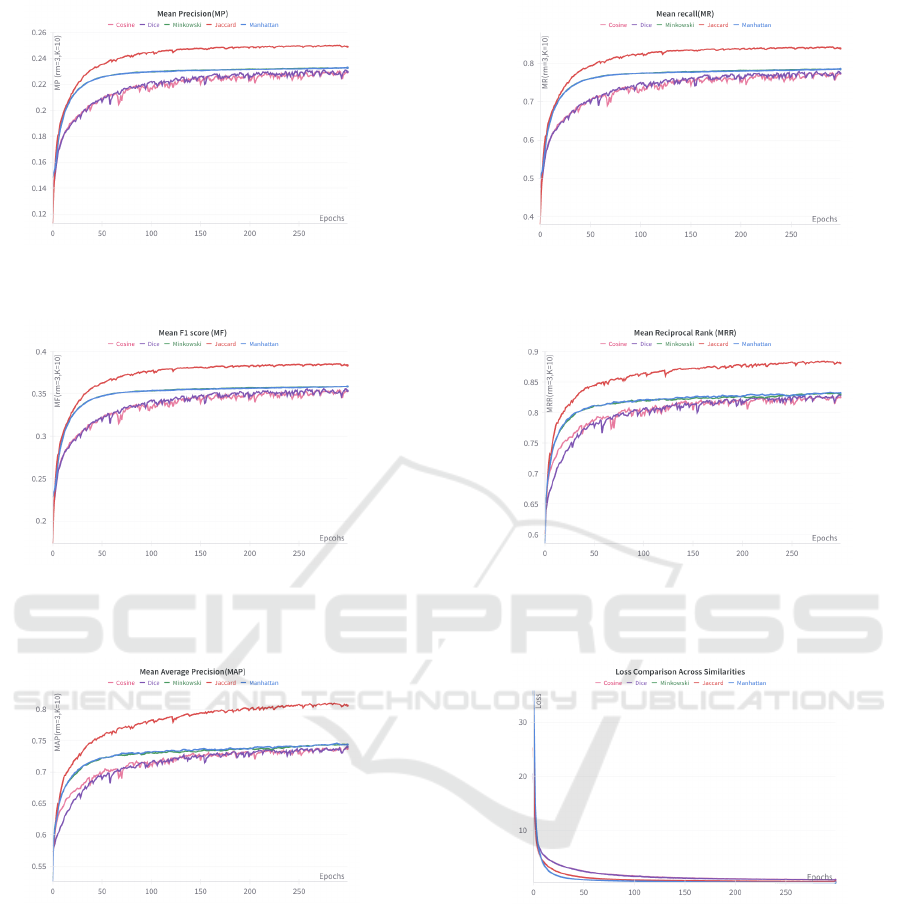
(a) Mean Precision (MP) for Different Similarity Mea-
sures.
(b) Mean Recall (MR) for Different Similarity Measures.
(c) Mean F1 Score (MF) for Different Similarity Mea-
sures.
(d) Mean Reciprocal Rank (MRR) for Different Similar-
ity Measures.
(e) Mean Average Precision (MAP) for Different Simi-
larity Measures.
(f) Overall Loss Reduction Across Similarity Measures.
Figure 4: Comparison of trends across different similarity measures, highlighting their performance and loss.
REFERENCES
Abu Alfeilat, H. A., Hassanat, A. B., Lasassmeh, O.,
Tarawneh, A. S., Alhasanat, M. B., Eyal Salman,
H. S., and Prasath, V. S. (2019). Effects of distance
measure choice on k-nearest neighbor classifier per-
formance: a review. Big data, 7(4):221–248.
He, Q., Li, B., Chen, F., Grundy, J., Xia, X., and Yang,
Y. (2020). Diversified third-party library prediction
for mobile app development. IEEE Transactions on
Software Engineering, 48(1):150–165.
Kangas, S. (2002). Collaborative filtering and recommen-
dation systems. VTT information technology, pages
18–20.
Lamothe, M. and Shang, W. (2020). When apis are in-
tentionally bypassed: An exploratory study of api
workarounds. In Proceedings of the ACM/IEEE 42nd
International Conference on Software Engineering,
pages 912–924.
Li, B., He, Q., Chen, F., Xia, X., Li, L., Grundy, J., and
Third-Party Library Recommendations Through Robust Similarity Measures
641

Yang, Y. (2021). Embedding app-library graph for
neural third party library recommendation. In Pro-
ceedings of the 29th ACM Joint Meeting on European
Software Engineering Conference and Symposium on
the Foundations of Software Engineering, pages 466–
477.
Li, D., Gao, Y., Wang, Z., Qiu, H., Liu, P., Xiong, Z., and
Zhang, Z. (2024). Homogeneous graph neural net-
works for third-party library recommendation. Infor-
mation Processing & Management, 61(6):103831.
Nguyen, P. T., Di Rocco, J., Di Ruscio, D., and Di Penta,
M. (2020). Crossrec: Supporting software develop-
ers by recommending third-party libraries. Journal of
Systems and Software, 161:110460.
Ouni, A., Kula, R. G., Kessentini, M., Ishio, T., German,
D. M., and Inoue, K. (2017). Search-based soft-
ware library recommendation using multi-objective
optimization. Information and Software Technology,
83:55–75.
Saied, M. A., Ouni, A., Sahraoui, H., Kula, R. G., Inoue,
K., and Lo, D. (2018). Improving reusability of soft-
ware libraries through usage pattern mining. Journal
of Systems and Software, 145:164–179.
Saied, M. A. and Sahraoui, H. (2016). A cooperative ap-
proach for combining client-based and library-based
api usage pattern mining. In 2016 IEEE 24th In-
ternational Conference on Program Comprehension
(ICPC), pages 1–10. IEEE.
Salza, P., Palomba, F., Di Nucci, D., De Lucia, A., and Fer-
rucci, F. (2020). Third-party libraries in mobile apps:
When, how, and why developers update them. Empir-
ical Software Engineering, 25:2341–2377.
Thung, F., Lo, D., and Lawall, J. (2013a). Automated li-
brary recommendation. In 2013 20th Working confer-
ence on reverse engineering (WCRE), pages 182–191.
IEEE.
Thung, F., Wang, S., Lo, D., and Lawall, J. (2013b). Au-
tomatic recommendation of api methods from feature
requests. In 2013 28th IEEE/ACM International Con-
ference on Automated Software Engineering (ASE),
pages 290–300. IEEE.
Zhang, S. (2021). Challenges in knn classification. IEEE
Transactions on Knowledge and Data Engineering,
34(10):4663–4675.
Zheng, W., Zhang, Q., and Lyu, M. (2011). Cross-library
api recommendation using web search engines. In
Proceedings of the 19th ACM SIGSOFT symposium
and the 13th European conference on Foundations of
software engineering, pages 480–483.
ENASE 2025 - 20th International Conference on Evaluation of Novel Approaches to Software Engineering
642
