
Topology-Driven Defense: Detecting Model Poisoning in Federated
Learning with Persistence Diagrams
Narges Alipourjeddi and Ali Miri
Department of Computer Science, Toronto Metropolitan University, Toronto, Canada
Keywords:
Federated Learning, Model Poisoning Attacks, Model Aggregation, Topological Data Analysis, Persistence
Homology, Anomaly Detection, Security Vulnerabilities, Robustness in FL, Machine Learning Security,
Model Integrity.
Abstract:
Federated Learning (FL) has emerged as a transformative approach for training machine learning models
across decentralized data sources while keeping client data localized. Despite its advantages, FL systems
remain vulnerable to various attacks and anomalies, including model poisoning attacks, which compromise
the integrity of the global model. In this paper, we introduce a novel approach for detecting such attacks by
leveraging persistence diagrams derived from topological data analysis (TDA). Our method provides a com-
prehensive solution for identifying anomalies in the training process by computing persistence diagrams in
high-dimensional spaces, effectively addressing the challenges of analyzing complex neural network architec-
tures. Through extensive experiments, we demonstrate that our approach achieves high accuracy in detecting
and mitigating attacks, even under non-IID and highly unbalanced data distribution scenarios. We evaluate our
method across various datasets and attack scenarios, and the results validate its robustness and effectiveness,
establishing it as a promising solution for enhancing the security of federated learning environments.
1 INTRODUCTION
Recent advances in machine learning have tradition-
ally relied on large, centralized datasets (Chowdhery
et al., 2023). However, this approach faces signifi-
cant challenges, particularly when dealing with sen-
sitive or private information that must remain dis-
tributed across various clients, such as mobile de-
vices, healthcare institutions, or smart buildings (Bhat
et al., 2023). To address these challenges, Federated
Learning (FL) has emerged as a promising paradigm
for leveraging distributed data while maintaining data
locality (McMahan et al., 2017). FL allows multi-
ple parties to collaboratively train machine learning
models without sharing raw data, instead exchanging
only model updates. By enabling local model train-
ing on edge devices using local datasets and aggre-
gating only model parameters, FL offers a potential
solution to privacy concerns in data-sensitive applica-
tions. However, recent research has revealed that FL
systems are vulnerable to various attacks, including
security and privacy attacks.
Once the FL is attacked, it can lead to privacy
leakage, model damage, system robustness degrada-
tion, and other adverse effects, ultimately causing a
loss of user trust.
To address these vulnerabilities, numerous meth-
ods have been proposed to defend against such attacks
and address the security and privacy anomalies in FL
(Ma et al., 2022). For example, in the context of se-
curity attacks, the (Xu et al., 2024) checked for client
updates in each iteration and discarded potentially
malicious clients as the server aggregated updates.
In terms of privacy attacks, (Gao et al., 2021) pro-
posed a defense against reconfiguration by searching
for privacy-preserving transformation functions and
pre processing training samples with such functions
to ensure an excellent performance from the trained
model.
In FL settings, sensitive information is vulnera-
ble to attacks on clients, communication processes,
and the central server. At the client level, attack-
ers may inject malicious updates or extract sensitive
data through methods like data poisoning or back-
door attacks. Data poisoning involves sending incor-
rect model parameters to the server, leading to com-
promised global model performance. Backdoor at-
tacks, more subtle, embed malicious functionality in
the global model while maintaining its performance
on main tasks, triggering undesirable behaviors only
Alipourjeddi, N. and Miri, A.
Topology-Driven Defense: Detecting Model Poisoning in Federated Learning with Persistence Diagrams.
DOI: 10.5220/0013367500003899
In Proceedings of the 11th International Conference on Information Systems Security and Privacy (ICISSP 2025) - Volume 1, pages 389-396
ISBN: 978-989-758-735-1; ISSN: 2184-4356
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
389

with specific inputs.
During communication, adversaries may intercept
or tamper with data transmitted between clients and
the server, causing data leakage or integrity breaches.
The central server in FL can be directly targeted
to compromise the integrity, confidentiality, and avail-
ability of the process. Unlike client-side attacks, these
server-level attacks, such as model poisoning, manip-
ulate aggregation by adding noise, altering weights,
or introducing patterns that degrade global model per-
formance. This paper proposes a novel method for de-
tecting central server attacks using advanced anomaly
detection techniques, including topological data anal-
ysis (TDA). By focusing on server-side detection, our
approach aims to improve FL security and reliability
while preserving its inherent privacy benefits.
TDA and persistence diagrams offer a promising
approach for detecting anomalies in model updates.
By capturing the topological features of data, per-
sistence diagrams serve as a robust tool for identi-
fying irregularities in the training process.(Carri
`
ere
et al., 2020). By analyzing the persistence diagrams
of global model updates, it is possible to detect and
mitigate attacks in FL environments. This method
leverages the unique properties of TDA to identify
deviations from normal model behaviour, enabling
timely detection of malicious activities. Our research
demonstrates the effectiveness of this approach in en-
hancing the security and robustness of FL systems.
As the field evolves, researchers are exploring novel
techniques to improve attack detection in FL, balanc-
ing the trade-offs between model performance, com-
munication efficiency, and security. These advance-
ments aim to make FL a more robust and secure
framework for collaborative machine learning across
diverse and sensitive datasets.
Existing models are typically trained on known
data types, which are assumed to be Independent and
Identically Distributed (IID). However, in real-world
scenarios, data often exhibits significant heterogene-
ity, and models cannot anticipate the complete spec-
trum of data distribution. Data frequently manifests
in Non-Independent and Identically Distributed (Non-
IID) forms. TDA offers powerful tools for under-
standing the structure of data. Integrating TDA into
FL can provide insights into data distributions, en-
hance model performance, and address issues like
data heterogeneity.
In this paper, we present a novel approach for
detecting attacks in FL systems by leveraging per-
sistence diagrams to capture and analyze topologi-
cal features of model updates. Our method integrates
topological data analysis to extract persistent homol-
ogy features and compare differences. Section 2 cov-
ers the background and notations, Section 3 reviews
related work, Section 4 presents our framework, Sec-
tion 5 demonstrates its practical capabilities, and Sec-
tion 6 concludes with a summary and insights.
2 PRELIMINARIES
Federated Learning Framework
Federated Learning (FL) is a decentralized machine
learning approach designed to preserve data privacy
by enabling model training across multiple clients
(e.g., mobile devices or organizations) without trans-
ferring local data to a central server (McMahan et al.,
2017). Each client trains a model locally and shares
updates, such as gradients or weights, with a cen-
tral server, which aggregates them to create a global
model.
Formally, the goal of FL is to obtain a global ob-
jective function that aggregates local objectives across
N clients:
min
w
F(w) =
N
∑
k=1
p
k
F
k
(w)
where w is the global model’s parameter vector and
F
k
(w) is a local loss function for client k.
F
k
(w) =
1
n
k
∑
i∈D
k
l(w, x
i
, y
i
)
with n
k
= |D
k
| being the number of data samples
for client k and l(w, x
i
, y
i
) being a loss for data data
sample (x
i
, y
i
) and p
k
=
n
k
∑
N
j=1
n
j
represents the rela-
tive weight of client k’s data in the global objective.
Each client k updates its local model based on the
current global model w
t
received from the server. Us-
ing Stochastic Gradient Descent (SGD) (Xiong et al.,
2021), this can be expressed as:
w
t+1
k
= w
t
k
− η∇F
k
(w
t
k
)
where w
t
k
is the local model of client k at iteration t,
η is a global learning rate applied by the parameter
server, to control learning speed and ∇F
k
(w
t
k
) is the
gradient of the local loss function with respect to w
t
k
.
The central server aggregates the local models
from the participating clients to update the global
model. This is commonly done using Federated Av-
eraging (FedAvg)(McMahan et al., 2017):
w
t+1
=
N
∑
k=1
p
k
w
t+1
k
where w
t+1
k
is the updated model from client k after
local training.
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
390

Central Server Attacks in FL
In a FL setup, the central server is vital for aggregat-
ing updates from clients and distributing the global
model. However, this centralization also makes the
server vulnerable to attacks. Key threats include ma-
licious server activities and non-robust aggregation
processes. The server must be rigorously secured to
prevent exploitation of potential vulnerabilities.
Malicious server attacks occur when adversaries
manipulate the aggregation process or global model
to degrade performance or introduce vulnerabilities.
Noise injection is a prominent attack method, where
attackers add crafted noise to disrupt model perfor-
mance. This can include:
• Random Noise Injection: Using Gaussian-
distributed noise ε ∼ N(µ, σ
2
) to destabilize the
aggregation process.
• Strategic Noise Injection: Introducing tailored
noise to subtly influence the global model, po-
tentially causing specific biases or performance
degradation.
Noise injection attacks are particularly insidious be-
cause they can be subtle and hard to distinguish from
natural variations in the FL process. They exploit the
trust placed in the central server and can have long-
lasting effects on the model’s performance and relia-
bility. Defending against such attacks requires a mul-
tifaceted approach. By using TDA methods, we can
enhance the robustness of FL systems.
Persistence Diagram
Persistence Diagram summarizing topological fea-
tures within a dataset across varying scales. They
capture the evolution of features such as connected
components (0-dimensional), loops (1-dimensional),
and voids (2-dimensional) as the scale of analysis
changes. This is achieved through a filtration, a
sequence of nested topological spaces (e.g., simpli-
cial complexes) that progressively incorporate more
data. This process reveals how topological features
emerge, evolve, and eventually disappear within the
filtration. For instance, the Vietoris-Rips complex,
a common simplicial complex, is constructed based
on a distance threshold d among points in a met-
ric space. A Vietoris-Rips filtration tracks how the
topological structure evolves as d increases. An-
other crucial concept is homology, a mathematical
framework for identifying and counting ”holes” in
spaces. Homology classifies features by their dimen-
sionality: 0-dimensional for connected components,
1-dimensional for loops, and so on. The technique of
persistent homology tracks these features across the
filtration, recording their birth (appearance) and death
(appearance).
Persistence diagrams visualize these data by plot-
ting each feature as a point, with its birth on the x-axis
and death on the y-axis. This visualization effectively
highlights the robust topological features within the
dataset, distinguishing them from transient ones.
d
1
d
2
d
3
Figure 1: The three step filtration of Vietoris-Rips complex
on the set of 10 points with increasing radius.
Figure 2: The persistence diagram corresponds to the filtra-
tion shown in the Figure 1. Blue points represent connected
components, while orange points represent loops.
Figure 1 shows the three steps of Vietoris-Rips fil-
tration in the set of 10 data points and Figure 2 shows
the persistence diagram of our dataset. We detect po-
tential attacks by analyzing key features in persistence
diagrams and their topological signatures. Using the
bottleneck distance, which measures the largest dif-
ferences in feature birth and death times between dia-
grams, we detect deviations caused by attacks, distin-
guishing normal from anomalous.
3 RELATED WORKS
In FL, the central server’s aggregation algorithm is
vital for enabling collaborative learning without data
sharing. However, adversaries can exploit vulnera-
bilities in these methods, particularly through model
poisoning attacks. This section explores significant
Topology-Driven Defense: Detecting Model Poisoning in Federated Learning with Persistence Diagrams
391

related works addressing such threats.
Several model poisoning attack strategies have
been proposed to compromise FL systems. Bag-
dasaryan et al.(Bagdasaryan et al., 2020) introduced
a model replacement attack to scale malicious up-
dates before submission. Xie et al.(Xie et al., 2024)
proposed a distributed backdoor attack (DBA), where
adversaries embed local triggers in separate clients.
Fang et al. (Fang et al., 2020) demonstrated the effec-
tiveness of local model poisoning, where a few com-
promised clients can significantly affect the global
model. Wang et al. (Wang et al., 2020) analyzed ag-
gregation methods, highlighting their susceptibility to
Byzantine attacks and the need for robust aggregation
techniques. Model poisoning attacks can have severe
consequences on FL systems. kairouz et al. (Kairouz
et al., 2021) showed that targeted attacks could in-
troduce specific biases or backdoors into the aggre-
gated model, affecting predictions. Defending against
these attacks poses significant challenges. While sig-
nificant progress has been made in understanding and
addressing model poisoning attacks in FL, develop-
ing comprehensive and effective strategies remains
an active area of research. Recent advancements in
computational topology, including persistent homol-
ogy (PH), have been applied to machine learning. It
was leveraged to analyze the topological feature of
various kinds of data structures. In the (Alipourjeddi
and Miri, 2023), proposed a method to compare gen-
erative models by persistent diagrams for analyzing
the similarities and differences in the birth and death
times of topological features, to determine how each
model captures the underlying structure of the data at
various scales. Alipourjeddi and Miri (Alipourjeddi
and Miri, 2024) experimented on high dimensional
datasets to unveil hidden patterns and captures the
persistent topological features of the data, allowing
to study its shape and structure across different scale.
Ma and Gao (Ma and Gao, 2024) trained a classifier
based on the PH features of neural network models
and composing a secure FL mechanism. Building
on previous research, this paper proposes a PD-based
method for detecting attacks in the uploads from
4 METHODOLOGY
Our methodology for investigating model poisoning
attacks on the central server in FL using persistence
diagrams includes the following phases:
• FL Setup: Establish an FL environmen using a
suitable framework, such as TensorFlow Feder-
ated. This involves defining the model archi-
tecture, determining the number of participat-
ing clients, and specifying the communication
rounds. Appropriate datasets, such as MNIST and
CIFAR-10, are carefully selected under a non-IID
setting to ensure relevance and comparability with
existing research.
• Attack Design: Develop targeted model poisoning
attacks to manipulate updates at the server, ensur-
ing persistence across training rounds while min-
imizing detectability.
• TDA Application: A key innovation in our
methodology is applying TDA to generate persis-
tence diagrams from model updates, effectively
capturing the topological features of both benign
and poisoned updates. This step is foundational
for subsequent analysis and detection efforts.
• Detection Mechanism: To detect attacks, we
compute persistence diagrams for the aggregated
weights after each round. If the bottleneck dis-
tance between consecutive diagrams exceeds a
threshold, it is flagged as a potential attack.
• Performance Evaluation: The performance of the
persistence diagram-based detection method is
evaluated using metrics, including detection rate
and false positive rate. Experiments are conducted
with varying noise levels, communication rounds,
client participation, and non-IID data distributions
to assess the robustness of the approach.
Through this comprehensive methodology, we aim
to provide a detailed investigation of model poison-
ing attacks at the central server in federated learning
while demonstrating the potential of persistence dia-
grams as a novel tool for enhancing the security of
such systems.
5 EXPERIMENTAL EVALUATION
In this part, we carry out extensive experiments to
demonstrate the performance of our mechanism. We
have implemented the federated learning environment
with FedAvg introduced in (Sun et al., 2022) which
allows multiple edge devices to collaboratively train
a model without sharing data. It involves running
stochastic gradient descent (SGD) locally on client
devices and then averaging the model updates on a
central server. The experiment modifies a model poi-
soning attack by adding noise to the aggregate weight,
which is a technique used to compromise the integrity
of the federated learning process.The Persistent Di-
agram (PD) is calculated using the Ripser package,
which is known for its efficiency in computing per-
sistent homology introduced by (Bauer, 2021). The
bottleneck distance is used to measure the difference
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
392
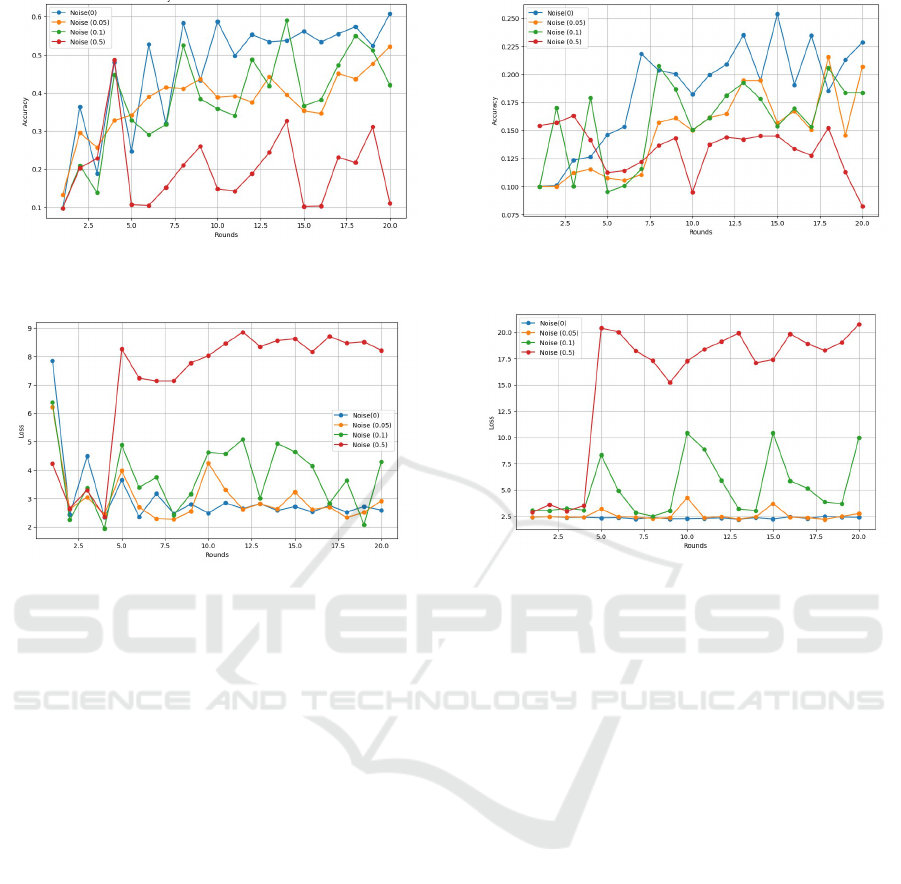
Figure 3: Accuracy vs. Rounds: Performance Evaluation
on the MNIST Dataset.
Figure 4: Loss vs. Rounds: Performance Evaluation on the
MNIST Dataset.
between PDs, helping to identify the presence and im-
pact of attacks on the federated learning model (Che
et al., 2024). This setup aims to demonstrate how
adding noise to aggregated weights can affect feder-
ated learning models and uses advanced mathematical
tools to quantify these effects.
Datasets: In this section, we begin by generat-
ing a synthetic dataset with 1,000 points to simulate
clients in a non-IID federated learning (FL) setting.
Subsequently, we perform extensive experiments us-
ing real-world datasets, MNIST and CIFAR-10, to
validate our analysis of privacy leakage in FL. Both
MNIST and CIFAR-10 are widely-used datasets for
classification tasks, each containing 10 classes. To
emulate a non-IID environment in the FL system, we
distribute the datasets among clients based on class
labels. This ensures that the local datasets assigned to
each client follow heterogeneous distributions, effec-
tively reflecting real-world non-IID scenarios.
Attack Setting: We explore server-side attacks in
FL, where an adversary manipulates the global model
aggregation process by injecting additional noise.
This deliberate interference introduces malicious up-
dates, degrading the system’s performance before the
manipulated global model is broadcast back to the
clients. Specifically, we simulate a global model poi-
soning attack, characterized by the following noise in-
Figure 5: Accuracy vs. Rounds: Performance Evaluation
on the CIFAR-10 Dataset.
Figure 6: Loss vs. Rounds: Performance Evaluation on the
CIFAR-10 Dataset.
jection details: Adjust the noise based on the number
of clients and the total number of iteration, consid-
ering the initialized model (Xiong et al., 2021). In
our experiment, we simulate an attack scenario over
20 rounds, with 10 clients participating in each round
for all three datasets. We introduce adversarial be-
havior every fifth round by injecting noise into the
aggregation process. These attacks aim to degrade
the model’s utility by either biasing the global model
or disrupting convergence. To assess the model’s re-
silience, we varied the intensity of the attacks us-
ing two parameters: the proportion of clients and
the magnitude of the adversarial updates. Our strat-
egy was to evaluate how much adversarial influence
the model could tolerate while maintaining acceptable
utility. We focused on identifying the thresholds at
which the model began to degrade significantly under
attack. Convergence slowed down as the attack inten-
sity increased, especially during rounds where mali-
cious updates were introduced. However, the training
loss continued to decrease after each round of feder-
ated training, indicating that the model was still con-
verging, albeit more slowly. Figures 3 and 4 demon-
strate that for the MNIST dataset with 10 expected
clients per round, the model tolerated a noise multi-
plier of up to 0.05 without significant degradation in
model quality. A noise multiplier of 0.1 introduced
Topology-Driven Defense: Detecting Model Poisoning in Federated Learning with Persistence Diagrams
393
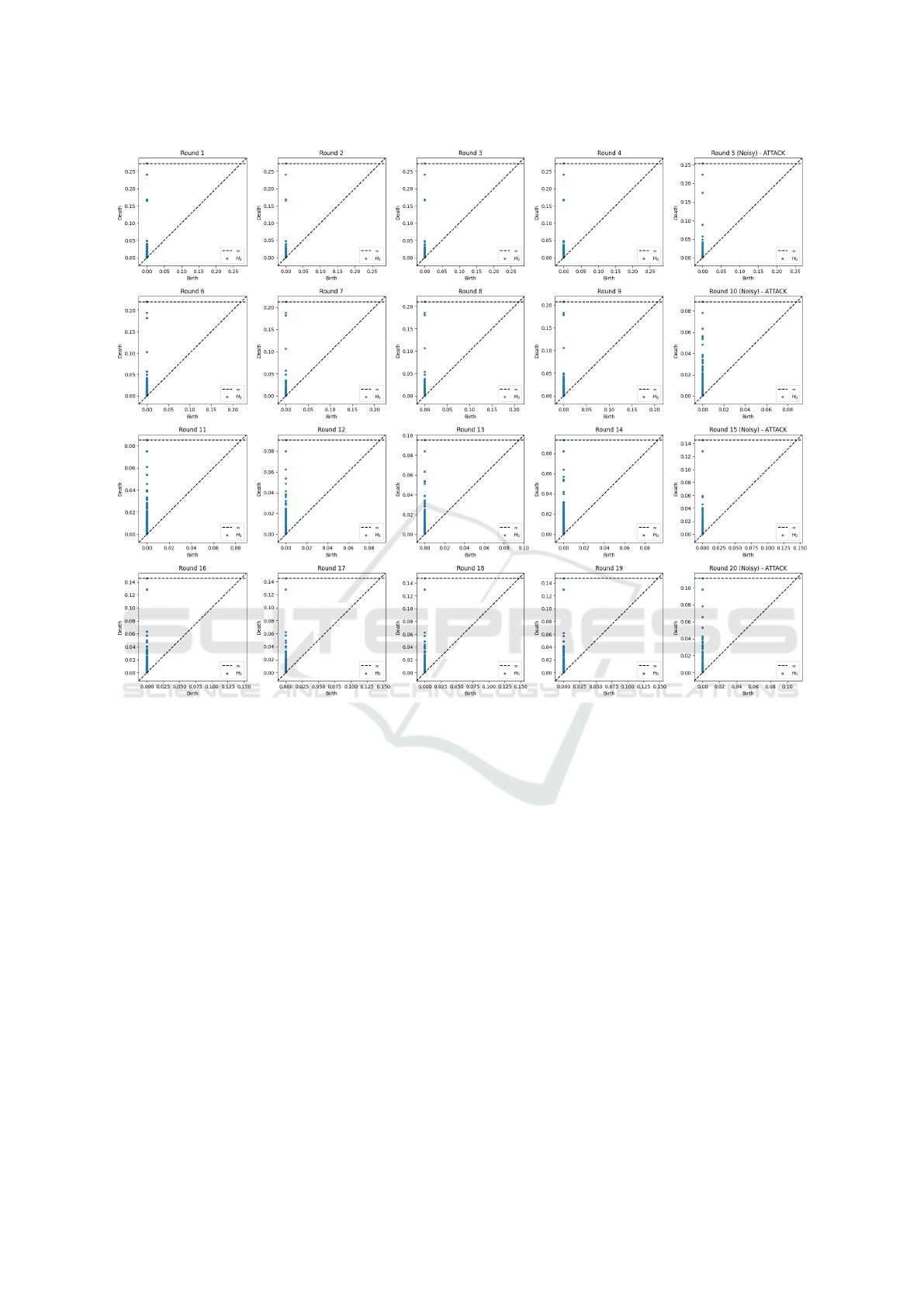
Figure 7: Persistence diagrams for the first 20 rounds on the MNIST dataset. Noise was introduced in rounds 5, 10, 15 and
20 leading to detected attacks with threshold 0.05 revealing significant changes in the topological features of the aggregated
model weights.
slight degradation, while a multiplier of 0.5 caused
the model to diverge completely.
Similarly, for the CIFAR-10 dataset, we applied
the same approach to identify tolerable noise levels
within our attack setting. Unlike MNIST, CIFAR-
10 required a more sophisticated model architecture
due to its higher complexity, including color chan-
nels and intricate image features. To achieve better
accuracy, we developed a model with additional con-
volutional layers featuring larger filter sizes, along
with advanced components such as batch normaliza-
tion and dropout layers. These enhancements were
designed to address the greater variability and rich-
ness of the CIFAR-10 dataset, ensuring improved per-
formance while maintaining robustness under noise.
Figures 5 and 6 demonstrate that, for the CIFAR-
10 dataset, the model remains robust with a noise mul-
tiplier of up to 0.05, showing no significant degrada-
tion in performance. However, increasing the noise
multiplier to 0.1 introduces moderate performance
degradation, and a multiplier of 0.5 causes the model
to diverge entirely.
Attack Detection with PDs: To detect attacks
in our system, we use persistence diagrams, a tool
that captures the shape and structure of the data.
Our approach leverages the sensitivity of persistence
diagrams to perturbations in the aggregated model
weights, allowing us to identify potential attacks. We
construct persistence diagrams from the aggregated
weights of the federated model after each round of
training. The weight matrices are flattened into a
high-dimensional point cloud, and we compute the
persistent homology using the Vietoris-Rips filtration.
This process captures the topological features of the
weight distribution across multiple scales.
Our attack detection mechanism is based on the
observation that malicious perturbations in the aggre-
gated weights alter the topological structure of the
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
394
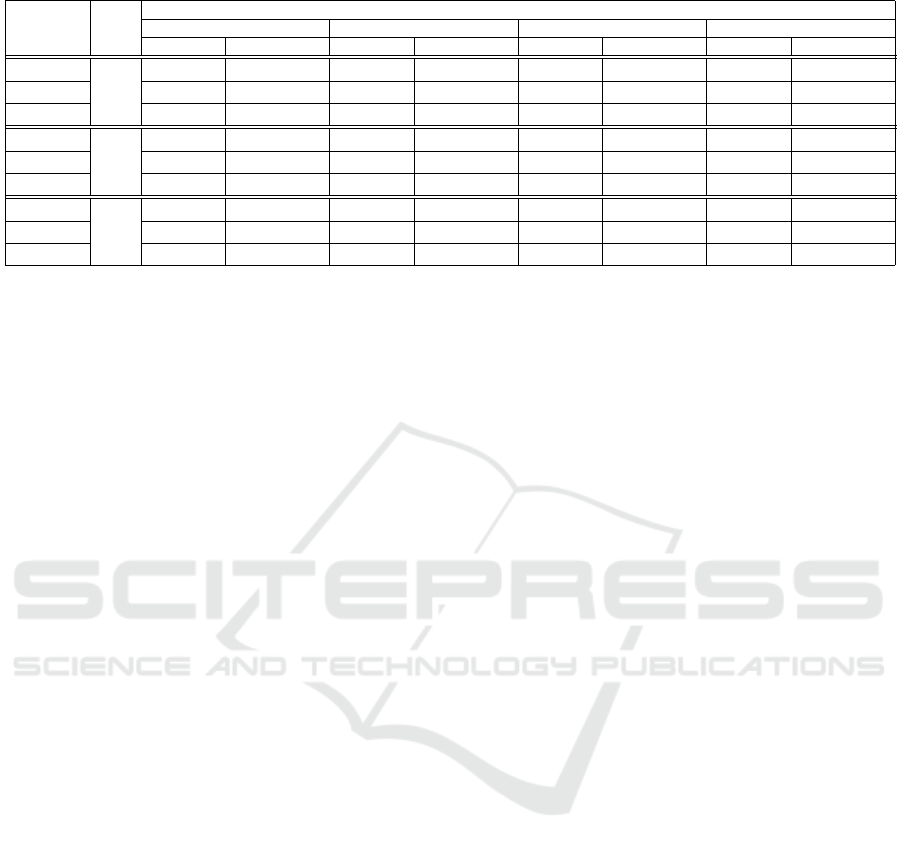
Table 1: Performance metrics for detecting attacks using persistence diagrams under varying noise levels across three datasets.
Dataset Rounds
Noise Level
0.0 0.05 0.1 0.5
Detection Rate False Positive Rate Detection Rate False Positive Rate Detection Rate False Positive Rate Detection Rate False Positive Rate
Synthetic Data
20
0.00 0.00 0.75 0.0625 1.00 0.0625 1.00 0.0625
MNIST 0.60 0.02 0.75 0.05 1.0 0.0 0.95 0.15
CIFAR-10 0.55 0.10 0.65 0.15 0.75 0.18 0.85 0.22
Synthetic Data
50
0.00 0.00 0.8 0.05 0.6 0.0 1.00 0.1
MNIST 0.70 0.01 0.80 0.05 0.85 0.1 0.95 0.05
CIFAR-10 0.80 0.05 0.85 0.1 0. 0.00 0.00 0.00
Synthetic Data
100
0.00 0.0125 0.65 0.0 0.75 0.00 1.00 0.0875
MNIST 0.75 0.00 0.80 0.05 0.90 0.05 1.0 0.0675
CIFAR-10 0.60 0.08 0.70 0.12 0.85 0.14 0.95 0.15
persistence diagram. Key aspects include:
• Bottleneck Distance: We compute the bottleneck
distance between the persistence diagrams of con-
secutive training rounds.
• Attack Threshold: We establish a threshold to flag
ongoing attacks when the bottleneck distance ex-
ceeds it.
This methodology allows us to effectively detect
attacks by analyzing topological variations in the
model’s aggregated weights.
Figure 7 shows persistence diagrams for the first
20 rounds of federated learning in the MNIST dataset.
Each subplot represents a round, with the x-axis
showing the birth times and the y-axis showing the
death times of topological features. In particular, in
rounds 5, 10, 15 and 20, where noise level of 0.1 was
introduced to the aggregated weights at the server,
we observe significant changes in the distribution of
points. This pattern aligns with our attack detection
threshold of 0.05, suggesting that the injected noise
has measurably altered the topological structure of the
model weights. The progression of diagrams across
rounds illustrates the evolution of the model’s topo-
logical features throughout the federated learning pro-
cess, with rounds 5, 10, 15 and 20 clearly demonstrat-
ing the impact of simulated attacks on the model’s
structure.
Quantitatively, Table 1 summarizes the perfor-
mance metrics for detecting attacks using persis-
tence diagrams under varying noise levels across three
datasets: Synthetic Data, MNIST, and CIFAR-10. For
synthetic data, the detection rate increases signifi-
cantly with noise, reaching perfect detection (1.00) at
higher noise levels (0.1 and 0.5) across all round con-
figurations, while maintaining a relatively low false
positive rate (0.0625-0.1). The MNIST dataset shows
robust performance, with detection rates ranging from
0.60 to 1.0 and generally low false positive rates, par-
ticularly at 100 rounds where it achieves perfect de-
tection at 0.5 noise level with a 0.0675 false posi-
tive rate. CIFAR-10 presents more challenges, with
lower detection rates at low noise levels but improv-
ing performance as noise increases, reaching up to
0.95 detection rate at 0.5 noise level in 100 rounds, al-
beit with higher false positive rates compared to other
datasets. Interestingly, CIFAR-10 shows anomalous
behavior at 50 rounds with 0.1 and 0.5 noise levels,
suggesting potential instability or data peculiarities.
Overall, the method’s performance tends to improve
with increased noise levels and more federated learn-
ing rounds, demonstrating its effectiveness in detect-
ing attacks in federated learning systems, especially
under higher noise conditions.
6 CONCLUSION
In this paper, we introduced a novel approach to de-
tect server-side attacks in FL using persistence dia-
grams. Our method successfully identified noise in-
jections every fifth round with a threshold of 0.05,
demonstrating its effectiveness in capturing topologi-
cal changes in aggregated model weights. Our work
contributes to the growing body of research on feder-
ated learning security. While existing methods focus
on client-side attacks or network intrusions, our ap-
proach addresses the critical issue of server-side ma-
nipulations. The use of topological data analysis of-
fers a unique perspective on model integrity, comple-
menting traditional distance-based or gradient-based
anomaly detection techniques.
The results show that persistence diagrams can ef-
fectively visualize and quantify the impact of adver-
sarial perturbations on model structure. This provides
researchers and practitioners with a new tool for mon-
itoring federated learning systems and detecting sub-
tle attacks that may evade other detection methods.
Further research is needed to explore the scalabil-
ity of our approach with more complex models and
investigate higher-dimensional homology to capture
Topology-Driven Defense: Detecting Model Poisoning in Federated Learning with Persistence Diagrams
395

intricate topological features in model updates. Addi-
tionally, evaluating the method’s performance against
more sophisticated attack strategies would help assess
its robustness in real-world scenarios.
ACKNOWLEDGEMENTS
This work was partially funded by the Canada First
Research Excellence Fund (CFREF) Bridging Di-
vides program.
REFERENCES
Alipourjeddi, N. and Miri, A. (2023). Evaluating gener-
ative adversarial networks: A topological approach.
In 2023 International Conference on Computing, Net-
working and Communications (ICNC), pages 202–
206. IEEE.
Alipourjeddi, N. and Miri, A. (2024). Preserving privacy in
high-dimensional data publishing. In ICISSP, pages
845–852.
Bagdasaryan, E., Veit, A., Hua, Y., Estrin, D., and
Shmatikov, V. (2020). How to backdoor federated
learning. In International conference on artificial in-
telligence and statistics, pages 2938–2948. PMLR.
Bauer, U. (2021). Ripser: efficient computation of vietoris–
rips persistence barcodes. Journal of Applied and
Computational Topology, 5(3):391–423.
Bhat, P., MM, M. P., and Pai, R. M. (2023). Anomaly
detection using federated learning: A performance
based parameter aggregation approach. In 2023 3rd
International Conference on Intelligent Technologies
(CONIT), pages 1–6. IEEE.
Carri
`
ere, M., Chazal, F., Ike, Y., Lacombe, T., Royer, M.,
and Umeda, Y. (2020). Perslay: A neural network
layer for persistence diagrams and new graph topo-
logical signatures. In International Conference on Ar-
tificial Intelligence and Statistics, pages 2786–2796.
PMLR.
Che, M., Galaz-Garc
´
ıa, F., Guijarro, L., Membrillo Solis, I.,
and Valiunas, M. (2024). Basic metric geometry of the
bottleneck distance. the Proceedings of the American
Mathematical Society.
Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra,
G., Roberts, A., Barham, P., Chung, H. W., Sutton, C.,
Gehrmann, S., et al. (2023). Palm: Scaling language
modeling with pathways. Journal of Machine Learn-
ing Research, 24(240):1–113.
Fang, M., Cao, X., Jia, J., and Gong, N. (2020). Local
model poisoning attacks to {Byzantine-Robust} fed-
erated learning. In 29th USENIX security symposium
(USENIX Security 20), pages 1605–1622.
Gao, W., Guo, S., Zhang, T., Qiu, H., Wen, Y., and Liu,
Y. (2021). Privacy-preserving collaborative learning
with automatic transformation search. In the Proceed-
ings of the IEEE/CVF Conference on Computer Vision
and Pattern Recognition, pages 114–123.
Kairouz, P., McMahan, H. B., Avent, B., Bellet, A., Bennis,
M., Bhagoji, A. N., Bonawitz, K., Charles, Z., Cor-
mode, G., Cummings, R., et al. (2021). Advances and
open problems in federated learning. Foundations and
trends® in machine learning, 14(1–2):1–210.
Ma, X., Zhou, Y., Wang, L., and Miao, M. (2022). Privacy-
preserving byzantine-robust federated learning. Com-
puter Standards & Interfaces, 80:103561.
Ma, Z. and Gao, T. (2024). Federated learning backdoor
attack detection with persistence diagram. Computers
& Security, 136:103557.
McMahan, B., Moore, E., Ramage, D., Hampson, S., and
y Arcas, B. A. (2017). Communication-efficient learn-
ing of deep networks from decentralized data. In Ar-
tificial intelligence and statistics, pages 1273–1282.
PMLR.
Sun, T., Li, D., and Wang, B. (2022). Decentralized feder-
ated averaging. IEEE Transactions on Pattern Analy-
sis and Machine Intelligence, 45(4):4289–4301.
Wang, H., Sreenivasan, K., Rajput, S., Vishwakarma, H.,
Agarwal, S., Sohn, J.-y., Lee, K., and Papailiopoulos,
D. (2020). Attack of the tails: Yes, you really can
backdoor federated learning. Advances in Neural In-
formation Processing Systems, 33:16070–16084.
Xie, Y., Fang, M., and Gong, N. Z. (2024). Poi-
sonedfl: Model poisoning attacks to federated learn-
ing via multi-round consistency. arXiv preprint
arXiv:2404.15611.
Xiong, Z., Cai, Z., Takabi, D., and Li, W. (2021). Privacy
threat and defense for federated learning with non-iid
data in aiot. IEEE Transactions on Industrial Infor-
matics, 18(2):1310–1321.
Xu, J., Jiang, Y., Fan, H., and Wang, Q. (2024). Svfldetec-
tor: a decentralized client detection method for byzan-
tine problem in vertical federated learning. Comput-
ing, pages 1–21.
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
396
