
Early Fault-Detection in the Development of Exceedingly Complex
Reactive Systems
Assaf Marron
a
and David Harel
b
Department of Computer Science and Applied Mathematics, Weizmann Institute of Science, Rehovot, 76100, Israel
Keywords:
System Engineering, Software Engineering, LLM, Models, Specifications, Interaction, Simulation,
Verification, Autonomous Systems, Systems of Systems, Super-Reactive Systems.
Abstract:
Finding hidden faults in reactive systems early in planning and development is critical for human safety, the
environment, society and the economy. However, the ever growing complexity of reactive systems and their
interactions, combined with the absence of adequate technical details in early development stages, pose a great
obstacle. The problem is exacerbated by the constant evolution of systems, and by their extensive and growing
interwoven-ness with other systems and the physical world. Appropriately, such systems may be termed
super-reactive. We propose an architecture for models and tools that help overcome such barriers and enable
simulation, systematic analysis, and fault detection and handling, early in the development of super-reactive
systems. The main innovations are: (i) the allowing of natural language (NL) specifications in elements
of otherwise standard models and specification formalisms, while deferring the interpretation of such NL
elements to simulation and validation time; and (ii) a focus on early formalization of tacit interdependencies
among seemingly orthogonal requirements. The approach is facilitated by combining newly specialized tools
with standard development and verification facilities, and with the inference and abstraction capabilities of
large language models (LLMs) and associated AI techniques. An important ingredient in the approach is
the domain knowledge embedded in LLMs. Special methodological measures are proposed to mitigate well
known limitations of LLMs.
1 INTRODUCTION
Since the 1985 identification of the category of re-
active systems(Harel and Pnueli, 1984), a plethora of
methods, languages and tools have been introduced
to support the development of such systems. Today,
complex reactive systems penetrate almost every as-
pect of life, including communications, commerce, fi-
nance, healthcare, aviation, land transportation, man-
ufacturing, and more. The complexity of new systems
is compounded by the fact that they are interwoven
with other systems and with the physical world, and
are constantly changing and evolving.
In this paper, we term this kind of system as super-
reactive (SR). While system and software engineer-
ing (SySE) is benefitting from new developments in
generative AI and large language models (LLMs), the
challenge of building safe and reliable SR systems
remains open. Despite applying the best tools and
methodologies, any given system is likely to conceal
a
https://orcid.org/0000-0001-5904-5105
b
https://orcid.org/0000-0001-7240-3931
undesired and very often unsafe behaviors and im-
pending failures, with the risk of adverse effects on
human life, the environment, society and the econ-
omy. Thus, while early discovery and handling of
such faults is required, it remains a tantalizing chal-
lenge, growing alarmingly in severity as SR systems
grow in complexity.
In this position paper, we propose a way of tack-
ling this issue based on the following principles: (1)
Allow model elements that are expressed in natural
language (NL), benefitting from the expressive power
of NL, its sensitivity to delicate context variations and
its ability to navigate multiple levels of abstraction,
and carrying out just-in-time (JIT), deferred, interpre-
tation of such NL elements. (2) Discover and docu-
ment otherwise-tacit interdependencies among sepa-
rately specified, seemingly orthogonal requirements.
A key enabler for our approach is the availabil-
ity of large language models and other AI tools, the
power and breadth of which is also ever-growing. In
section 4 we propose steps that can help circumvent
known weaknesses in AI and LLM techniques.
Marron, A. and Harel, D.
Early Fault-Detection in the Development of Exceedingly Complex Reactive Systems.
DOI: 10.5220/0013369200003896
In Proceedings of the 13th International Conference on Model-Based Software and Systems Engineering (MODELSWARD 2025), pages 321-329
ISBN: 978-989-758-729-0; ISSN: 2184-4348
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
321
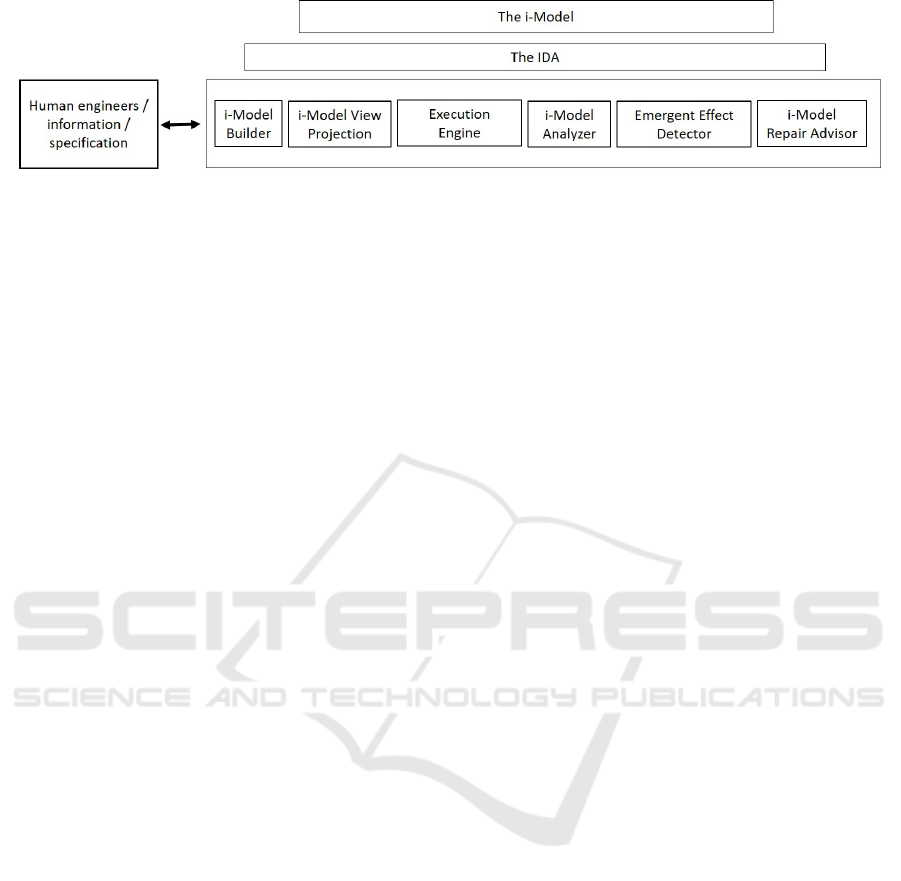
Figure 1: Solution architecture blueprint. See explanation in text.
2 THE PROBLEM
As the complexity and pervasiveness of reactive sys-
tems and systems of systems keeps growing, so do
the risks associated with hidden faults: potential fail-
ure points, malfunctions, undesired behaviors and
absence of desired ones. Recent well-known cases
involving actual system code, maintenance proce-
dures, interfaces with other systems and with hu-
mans, etc., include: the Crowdstrike server failures
in July 2024 (George, 2024), the 2023 accident in
which a robotic taxi hit a pedestrian in San Fran-
cisco(Koopman, 2024), the failure of the USA FAA
notification system in 2023 (Kane et al., 2024, p.11),
and the crashes of 737 MAX airplanes (Herkert et al.,
2020). Similar kinds of problems obviously occur
frequently without gaining broad attention. Further-
more, beyond such direct effects, issues with an SR
system may inflict excessive rigidity and regulation
on the behavior of humans and of other systems, in an
effort to accommodate the system’s limitations. Take,
for example, the assignment of cars to driving sides
and lanes on roads; we would like to avoid enforc-
ing such restrictions enforced in sidewalks and hall-
ways shared by humans and robots as an emergency
response to unanticipated problematic reality.
Published discussions of such problems call for
early assessment and preemptive technical, economic,
and regulatory activities. Early in the days of
model-based system engineering (MBSE), France
and Rumpe wrote: It is our view that software en-
gineering is inherently a modeling activity, and that
the complexity of software will overwhelm our abil-
ity to effectively maintain mental models of a sys-
tem. (France and Rumpe, 2007). Over the years,
there was great progress in the ability to build ex-
ecutable models. Examples include UML, SysML,
Rhapsody, STATEMATE, fUML, xUML, Ptolemy,
MATLAB with Simulink and Stateflow, SCADE,
UPPAAL, BPMN, Arcadia, Cameo and others; see
also list of SySE tools in (Laplante and Kassab,
2022, pp.76,79,208)). In parallel, there were signif-
icant advances in applying formal methods to such
models (Oliveira et al., 2017; Fremont et al., 2023;
de Saqui-Sannes et al., 2021; Zahid et al., 2022; Wey-
ers et al., 2017; Huang et al., 2020; Rahim et al., 2021;
Li et al., 2020; Harel et al., 2013). Also, many orga-
nizations developed elaborate ad-hoc models to help
study the systems from early on in the development
process (Lattimore et al., 2022; Gorecki et al., 2019;
Lo et al., 2021).
However, despite such advances, ensuring the
safety and correctness of complex systems is still a
major problem. For example, in a 2024 workshop
on safety of autonomous transportation (summarized
in (Deshmukh et al., 2024)) many open SySE issues
and challenges were discussed, including: (i) incor-
porating general and domain knowledge in testing and
verification; (ii) ensuring that ML training data covers
rare but critical scenarios; (iii) exhaustively covering
all possible interactions; and, (iv) enhancing usability
of formal methods. Similar conclusions about gaps
in present methods for early issue identification ap-
pear in (Cederbladh et al., 2024; Horv
´
ath et al., 2023;
Harel et al., 2020; Lee, 2024).
Given that uncovering hidden faults in well-
specified or even fully developed systems is still
an open problem, it is evident that preemptive fault
discovery in super-reactive systems (e.g., extremely
complex systems of systems interwoven with their en-
vironment) at early development stages poses a major
challenge. The added difficulty stems in part from
the informal and imprecise nature of requirements in
early development stages, from the limited scalabil-
ity of the tools, and from the reliance on engineers
to infer at development time undocumented relations
among separately specified requirements. As to the
latter concern, these requirements are often specified
using different abstractions and a variety of termi-
nologies. Other issues that contribute to the problem
include the dependence of verification on a translation
to state machines or Petri nets, and the absence of ex-
ecutable and analyzable semantics of certain specifi-
cation artifacts.
Current AI-based solutions assist in various ac-
tivities of development, including code generation
MODELSWARD 2025 - 13th International Conference on Model-Based Software and Systems Engineering
322

and debugging, with a prominent example being the
GitHub Copilot; see, also, e.g., (AIESE, 2024) and
references therein. However, applying such tools in
the context of early specification is mostly limited to
automated modeling, discussed in Section 3.3.
The roadmap presented here addresses these is-
sues by enabling rigorous execution and analysis sub-
ject to domain expertise and world knowledge, and
doing so at higher levels of abstraction. The ap-
proach uses natural language and relies on the ability
of AI-based tools to mimic humans’ flexible naviga-
tion of complex abstraction relations. It will extend
the present use of abstraction, as in object-oriented
inheritance relations and counter-example-guided ab-
straction refinement (CEGAR) in formal verifica-
tion (Clarke and Veith, 2003; Seipp and Helmert,
2018).
3 THE ROADMAP
In this section, we list the elements of an approach and
an architecture for modeling SR systems, including
a set of intelligent tools for simulation and analysis,
which, together, can enable the much desired early
preemptive discovery of hidden faults, while address-
ing the existing challenges and technology gaps.
In way of bounding the scope of the problem we
tackle and hence of our proposed solution, we exclude
the use of AI, ML and LLMs in runtime decision mak-
ing, monitoring, development operations (DevOps),
or the formal verification of final code. Moreover,
while some reasoning functions of the proposed so-
lution may be similar to those carried out by expert
human engineers and domain professionals, we focus
on enabling presently impractical or impossible anal-
yses, and much less on automation of manual tasks.
3.1 The Intelligent Development Aide
The Intelligent Development Aide (IDA) is a shared
layer of services that offers the following to the over-
all solution: (i) intelligence, including learning, in-
ference, and generative abilities; (ii) NL-based inter-
action; and, (iii) general world knowledge and cer-
tain domain-specific expertise. The IDA will rely
on present and future technologies that come under
the umbrella of AI, Generative AI, Machine Learn-
ing, Deep Learning, Large Language Models (LLMs),
etc. It will be constructed, among other things, by
fine-tuning, enhancing and extending AI-based tools,
relying on techniques like those of (Minaee et al.,
2024; Ding et al., 2023; Shani et al., 2023; Tamari
et al., 2020; Netz et al., 2024) and future emerging
ones. With inputs from specifications of diverse sys-
tems, with textual and visual depictions of normal and
faulty execution scenarios, the IDA will be trained to
recognize unique software and system engineering is-
sues and new delicate kinds of interdependencies.
3.2 The i-model
We introduce a new kind of model, termed i-model,
which offers fresh perspectives on some common
modeling maxims:
First, while precision is commonly needed to en-
sure correct system implementation, i-models will
take advantage of what may appear quite the oppo-
site. They will retain within model entities the ex-
pressive power of NL, which includes sensitivity to
context, flexible abstraction, generalization, associa-
tions, etc. Simulation and analysis tools will then rely
on deferred –just-in-time (JIT) – interpretation to en-
dow NL and NL-like behavioral specifications with
concrete meaning, aligned with the intended context,
and abstraction level.
Second, while logical flow and organization are
essential to engineering, conceptual abstractions may
not always lend themselves to being so depicted. For
example, consider the difficulty of modeling a com-
plex network of multiple class inheritances, combined
with natural language ambiguity, where, for instance,
the word stop could mean a condition of no motion at
all, or a process of slowing down to reach that condi-
tion, or the action of beginning to press the brake in
order to begin this process, etc. In contrast, i-models
will accommodate coexistence of multiple, diverse,
non-hierarchical, overlapping and dynamic abstrac-
tion lattices.
Finally, modularity, encapsulation, and logical
decomposition are central principles in engineering
in general and in software engineering in particu-
lar . However, separately specified requirements of-
ten have tacit, unstated dependencies, which show up
as exceptions, priorities, alternatives, complementary
or concurrent actions, mutually exclusive conditions,
etc. It is commonly up to the engineers to infer these
implicit relations, and to reflect their understanding
in the implementation. In our automated construc-
tion of i-models from a wide range of specifications,
special focus is put on discovering such unstated re-
lationships and capturing them in the model, despite
the entanglement that they may imply.
The i-models will store diverse information, in-
cluding requirements, goals, behaviors, scenarios and
emergent properties, as well as groupings, abstrac-
tions, and relations of such entities. It will also con-
tain meta information about potential changes due to
Early Fault-Detection in the Development of Exceedingly Complex Reactive Systems
323

the evolution of the system and its environment, al-
lowing further analysis of potential future trajectories.
Finally, the i-model will support unmodeling
(Marron et al., 2024), i.e., explicitly specifying en-
tities and assumptions that should be excluded or ig-
nored during execution and analysis, as well as opera-
tional environments in which the SR system is not ex-
pected to operate. Unmodeling will complement ca-
pabilities of existing modeling techniques to specify
the exact intended operational design domain (ODD),
directing IDA-based tools where to apply their vast
and important knowledge and where not to.
The immense knowledge stored in the i-model
will be divided among three realms: (i) the entities
themselves, including structured data and unstruc-
tured NL documents; (ii) the relationships between
entities, represented in the i-model database; and,
(iii) the general and application-specific knowledge
captured in the IDA components, both in advance,
and following the building and analysis of a given i-
model.
3.3 The i-model Builder
Inputs to i-model building will include: require-
ments documents, specifications of reusable compo-
nents (Benveniste et al., 2018), manual risk analy-
ses (Bjerga et al., 2016; Haimes, 2018), entire models
in various modeling languages, program code, docu-
mentation, example run logs of early prototypes, test
cases, etc. Additional information, corrections and
guidance provided interactively by engineers during
model building will also be retained. Furthermore,
the i-model builder can initiate queries, asking the en-
gineers to supply missing information or to confirm
intermediate engine inferences. For example, when
preparing a model for simulating complex traffic sce-
narios in a busy intersection, the system may remind
the domain experts to include various combinations
of weather conditions, and road surface states.
Beyond the now increasingly common translation
of NL specifications into basic object models and
computer programs, a unique feature of the i-model
builder will be the automated, and optionally interac-
tive, discovery and recording of undocumented tacit
interdependencies among separately specified enti-
ties. For example, consider separately specified rules
for an autonomous vehicle (AV), which may cause
the AV to accelerate, as when entering a highway or
when instructed to follow another vehicle, or when re-
turning to normal speed after a temporary slow down;
consider a second set of rules specifying maximum
legal speed and maximum recommended speed under
certain conditions. The fact that the rules in the sec-
ond set constrain or may be in conflict with rules in
the first set, will be automatically captured and ex-
plicitly specified at model-building time. When the
effect is clear, e.g., that one rule takes priority over the
other, this explicit specification will be generated au-
tomatically up front (where today it may be left as an
implementation detail). When the relation is in ques-
tion – say, what to do if the leader of a convoy exceeds
the legal speed limit – the i-model builder will consult
the engineers.
The builder will provide succinct summaries of
the input information and elaborate on its inferences,
applying logic and domain knowledge. The added
information will also be stored in the i-model. For
example, in our experiments with an LLM in creat-
ing a model from the description of a traffic scenario,
the LLM added pedestrian objects, which were absent
from the original requirements.
The i-model will use a rich modern database to
store the structured and unstructured information and
the associated connections and relationships. As this
structure will likely be too complex for humans to
navigate and maintain directly, it will be supported
by a multi-view presentation (see, e.g., slices in (Ne-
jati et al., 2012)), projecting requested information
as stand alone succinct text descriptions and dynami-
cally created diagrams (e.g., Statecharts). Since many
entities will already be in NL, the projection itself will
be intuitive, but will still require other components
and human review for confirmed interpretation (see
also Section 4). Once confirmed, such projections can
also serve as concise memory, to be fed back to the i-
model.
We expect the construction of the i-model builder
to extend the growing amount of research on using
GAI and LLMs for creating models from NL inputs;
see, e.g. (Ramackers et al., 2021; Netz et al., 2024;
Yaacov et al., 2024; Harel. et al., 2024; Cosler et al.,
2023; Kourani et al., 2024).
3.4 The i-model Execution and
Simulation Engine
This component performs dynamic, deferred, just-in-
time (JIT) interpretation of the definite and the NL in-
formation in the i-model, and outputs descriptions of
possible runs and the unfolding of “what if” scenarios
at desired abstraction levels, as narratives, event logs,
and even synthetic videos.
For illustration, consider the following example,
which we ran on OpenAI ChatGPT. Prompt (slightly
edited): “Consider a 3 lane street. 30 equal-size pas-
senger cars are filling the street, standing in front of a
traffic light. No cars arrive from the back of the queue
MODELSWARD 2025 - 13th International Conference on Model-Based Software and Systems Engineering
324

throughout this scenario. The third car in the middle
lane stalls and cannot move. No one stops to help.
Describe the behaviors and positions of the 30 cars
after the light turns green. Assume the light is green
for a very long time.”
Here are a few excerpts from the LLM’s response:
“When the traffic light turns green:...1. Cars in the
Middle Lane...: (a) The first two cars in the mid-
dle lane (Cars 1 and 2) will start moving forward as
the light turns green. (b) The third car in the middle
lane (Car 3) will not move...(c) The cars behind the
third car...will initially wait, expecting the third car to
move. After realizing that it is not moving, they will
either: (i) Start honking,...; (ii) Some drivers may try
to change lanes...(iii) Some drivers may remain stuck
behind the third car if changing lanes is not possible...
2. Cars in the Left Lane...and Right Lane...: (a) The
cars in these lanes...will begin moving forward... (b)
The first few cars...positioned parallel to the station-
ary third car, will drive past it without much issue. (c)
The cars behind them will continue moving forward,
potentially picking up speed...”
When we divided the road into small virtual cells,
the LLM was able to describe car movements through
the numbered cells, making the scenario more mathe-
matically analyzable.
Note how the LLM incorporated into the re-
sponses its domain knowledge; for example, adding
the possibilities of changing lanes and honking, which
were not in the original specification.
The LLM responses also contained errors; for ex-
ample, they suggested that cars blocked behind the
stalled car may not be able to change lanes at all,
ignoring the specification that the traffic light stays
green indefinitely, and no new cars arrive during the
scenario. In Section 4 we discuss approaches for deal-
ing with such issues.
This example and others show that LLMs can pro-
duce execution logs, both in structured form and as a
continuous narrative, which can then be checked us-
ing a variety of techniques.
The execution engine will, of course, benefit from
state-of-the-art execution and simulation techniques,
like those in SysML, Statecharts, and Scenario-based
programming, or in direct execution of NL specifi-
cations, as in (Tamari et al., 2020) and references
therein. Borrowing from techniques for test-case gen-
eration (Wang et al., 2024), the execution engine will
also automatically generate and process batches of di-
verse, yet relevant, “what if” scenarios, and store their
execution results for further processing.
3.5 The i-model Analysis Engine
The i-model analyzer will carry out the equivalent of
formal model-checking, searching – proactively – for
execution trajectories that lead to fault states. Treating
the model as an NL-enriched graph, it will traverse its
paths, interpreting entities and relationships subject to
general and domain knowledge, including causalities,
interdependencies and risks, while abiding by unmod-
eling – explicit specifications of what to exclude.
For example, assume that the model includes rules
like “a vehicle should never proceed into an intersec-
tion when the traffic light is red”, and “drivers and ve-
hicles should always obey police person’s directives’.
NL processing combined with domain knowledge can
equate terms that appear in the model, like “go”, “pro-
ceed”, “drive forward”, and others, into a single con-
cept, and can categorize the possible directives of a
police person into categories like “go”, “stop”, “turn”,
etc. During simulation of actual scenarios, the be-
havior of the vehicle, e.g., changing location coordi-
nates, can then be described in words and associated
with the recognized terminology. The system can then
detect when a vehicle’s behavior violates such rules.
Furthermore, a model checker or an SMT constraint
solver may then be able to detect that there is a po-
tential conflict between these two rules, which would
require prioritization or some other means of resolu-
tion.
In addition, the analyzer will offer query capabil-
ities, e.g., for investigating complex scenarios, or the
many connections of a given entity. It will also inter-
face with classical model checkers and satisfiability
modulo theory (SMT) constraint solvers for inspect-
ing well-structured subsets and projections of the i-
model, and for presenting the answers back in NL.
For example, we described to ChatGPT two paral-
lel synchronous state machines. With some trial and
error, aided by checking and corrections by engineers,
the LLM was able to say whether certain composite
states were reachable or not, describe relevant paths,
and construct the full state graph of the composite ma-
chine with all composite states and transitions.
Other analytic LLM capabilities that can support
i-model analysis are described in papers like (Harel.
et al., 2024; Sultan and Apvrille, 2024). These
include computing when two independent periodic
events may occur simultaneously, explaining behav-
ior, articulating system properties, checking model
consistency, etc. Furthermore, it is expected that
LLM general and domain-specific analytical capabili-
ties will be extended and deepened, and they are likely
to be intertwined with ongoing research in software
and system engineering. Developments along the
Early Fault-Detection in the Development of Exceedingly Complex Reactive Systems
325

present roadmap can incorporate such enhancements,
and target them specifically at early fault-detection.
Still, automated validation techniques must con-
tinue to be researched and developed. Even if our
fault-detection solution is found to work well on rea-
sonably tractable models, like compositions of small
specifications, can one trust the solution’s answers for
larger problems? And wouldn’t a trusted automated
external validation tool make the AI-based solution
actually unnecessary? We believe that with a combi-
nation of well-documented abstraction relations, AI-
explainability, randomized testing of model answers,
and powerful projection of relevant model perspec-
tives, one can create high confidence in the model’s
answers. See Section 4 for further details.
3.6 Emergent Effect Detector
This component accepts outputs of system simula-
tions, looking for expected and unexpected patterns
and emergent effects, both structural/spatial and be-
havioral/temporal. Such effects may be previously
specified as desired, undesired, or perhaps acceptable,
or they may require assessment.
The tool will rely on the immense body of work
in recognizing patterns, emergent effects, anomalies,
etc., in formally organized sequential data, like dis-
crete event logs or continuous signals, and in spatial
and structural information, like images and videos.
See, e.g., (Pang et al., 2021; Fieguth, 2022; Noer-
ing et al., 2021; Bartocci et al., 2022). The results
will be presented formally and in NL for manual and
automated analysis.
3.7 Repair Advisor
The i-model’s sheer size may interfere with its main-
tenance, calling for a repair advisor that accepts a de-
scription of an issue and proposes changes to the sys-
tem or to its technical and physical environment. A
key distinction from common program repair (Zhang
et al., 2023) is the primary focus on pinpointing the
model components that should be changed and on
describing the ensuing impact on system behavior,
while the technical details of the actual change are
secondary.
4 DEALING WITH LLM
SHORTCOMINGS
We offer the following methodological principles in
order to counteract known weaknesses in AI- and
LLM-based techniques, justifying their inclusion in
a foundation of a robust engineering tool. The weak-
nesses include the possibility of faulty inference and
“hallucination”, scalability issues, and vulnerability
to various attacks:
Abstraction. In early stages of development, many
aspects of the specification are aggregated in high-
level abstractions, which by their very nature reduce
complexity and the magnitude of the state space. In
addition, at any stage, when the available knowledge
is cluttered by excessive amounts of detail, stakehold-
ers can raise the level of abstraction in the available
specification to achieve the necessary ad-hoc, tempo-
rary simplification.
Modularity. Designers can limit the scope of the
challenges delegated to AI and LLM techniques by
dealing with encapsulated components, and abstract-
ing each component’s view of the behavior of the rest
of the system and the environment.
Human Review. Recall that in a classical develop-
ment process, any failure in testing or formal verifica-
tion is subject to human review: Is the problem real?
Was there a problem in the definition of execution of
the test and the verification? Can we recreate the is-
sue? etc.
Indeed, at all development stages, from initial re-
quirement elicitation to advanced sprints in agile de-
velopment, domain experts and engineers may raise
“what if” questions, and point at issues, some of
which may be irrelevant due to misunderstandings,
mismatching assumptions, or simply the forgetting of
already-specified elements. The team, including the
person raising the issue, then check if the issue at
hand is indeed one that should be fixed, whether doc-
umentation of other details and assumptions should
be improved, whether the issue can be dismissed by a
succinct answer, etc.
Explainable AI. Applying state of the art explainabil-
ity tools to the IDA observations can assist in dismiss-
ing erroneous or superfluous ones, and focusing on
relevant ones. This process can also help in enhancing
both the IDA and the system i-model at hand to im-
prove the overall quality of the automated engineering
process.
For example assume that in observing real world
or simulated behavior of an AV being developed, the
IDA reports an unsafe, unexpected slowing down in
the middle of a highway. Applying explainable AI to
the vehicle’s logic may supply the reason, such as its
having detected a pothole in the road. This can then
be translated into simply dismissing the observation,
or improving the observation abilities of the IDA, or
in case of a false detection by the vehicle, fixing its
sensors and the associated logic.
MODELSWARD 2025 - 13th International Conference on Model-Based Software and Systems Engineering
326

Standard Security Procedures. The vulnerabilities
of neural networks to various kinds of attacks, in
training and in adversarial use, should be addressed
with standard practices for this well studied area, in-
cluding data controls, access controls, diverse moni-
toring, etc.
Domain Specific Training. The LLMs and other AI
techniques involved in the proposed solution should
be further trained and updated with domain-specific
knowledge, and with extensive background about
software engineering practices. Such training should
cover also the specific accumulated experience in us-
ing the new architecture and methods.
Redundancy. Especially when safety is an issue, im-
portant decisions, tests and validation should be done
by several tools that rely on different resources and
designs. Furthermore, the decisions of AI based sys-
tems may be guarded by safety rules programmed
from more classical specifications (Harel et al., 2024).
Training Data Filtering and Curation. Special care
should be taken to ensure that the IDA is trained on
valid, clean data. For example, the IDA should not
learn from malicious inputs, and when learning from
valid systems and processes, it should not violate pro-
prietary rights associated with such sources.
5 CONCLUSION
We are currently in the process of initiating a research
project following the roadmap presented here. De-
velopment of models and tools that enable simulation
and analysis of highly complex systems based only
on early specifications can dramatically enhance our
ability to develop reliable, safe, and productive super-
reactive systems. A combination of the recent ad-
vances in AI and a fresh perspective on what may and
may not qualify as a model entity, or be acceptable
as a simulation result, may enable the achievement of
this tantalizing goal.
ACKNOWLEDGMENTS
This research was funded in part by an NSFC-ISF
grant to DH, issued jointly by the National Natu-
ral Science Foundation of China (NSFC) and the Is-
rael Science Foundation (ISF grant 3698/21). Addi-
tional support was provided by a research grant to DH
from Louis J. Lavigne and Nancy Rothman, the Carter
Chapman Shreve Family Foundation, Dr. and Mrs.
Donald Rivin, and the Estate of Smigel Trust.
REFERENCES
AIESE (2024). 15th Int. Conf. on AI-empowered Software
Engineering – AIESE 2024 (Formerly JCKBSE).
https://easyconferences.eu/aiese2024/; Accessed
Aug. 2024.
Bartocci, E., Mateis, C., Nesterini, E., and Nickovic, D.
(2022). Survey on mining signal temporal logic speci-
fications. Information and Computation, 289:104957.
Benveniste, A., Caillaud, B., Nickovic, D., Passerone,
R., Raclet, J.-B., Reinkemeier, P., Sangiovanni-
Vincentelli, A., Damm, W., Henzinger, T. A., Larsen,
K. G., et al. (2018). Contracts for system design.
Foundations and Trends® in Electronic Design Au-
tomation, 12(2-3):124–400.
Bjerga, T., Aven, T., and Zio, E. (2016). Uncertainty treat-
ment in risk analysis of complex systems: The cases
of stamp and fram. Reliability Engineering & System
Safety, 156:203–209.
Cederbladh, J., Cicchetti, A., and Suryadevara, J. (2024).
Early validation and verification of system behaviour
in model-based systems engineering: a systematic lit-
erature review. ACM Transactions on Software Engi-
neering and Methodology, 33(3):1–67.
Clarke, E. and Veith, H. (2003). Counterexamples revisited:
Principles, algorithms, applications. Springer.
Cosler, M., Hahn, C., Mendoza, D., Schmitt, F., and Trip-
pel, C. (2023). nl2spec: interactively translating un-
structured natural language to temporal logics with
large language models. In CAV, pages 383–396.
Springer.
de Saqui-Sannes, P., Apvrille, L., and Vingerhoeds, R.
(2021). Checking SysML models against safety and
security properties. Journal of Aerospace Information
Systems, 18(12):906–918.
Deshmukh, J., K
¨
onighofer, B., Ni
ˇ
ckovi
´
c, D., and Cano,
F. (2024). Safety Assurance for Autonomous Mo-
bility (Dagstuhl Seminar 24071). Dagstuhl Reports,
14(2):95–119.
Ding, N., Qin, Y., Yang, G., Wei, F., Yang, Z., Su, Y.,
Hu, S., Chen, Y., Chan, C.-M., Chen, W., et al.
(2023). Parameter-efficient fine-tuning of large-scale
pre-trained language models. Nature Mach. Intel.,
5(3):220–235.
Fieguth, P. (2022). An introduction to pattern recognition
and machine learning. Springer.
France, R. and Rumpe, B. (2007). Model-driven devel-
opment of complex software: A research roadmap.
In Future of Software Engineering (FOSE’07), pages
37–54. IEEE.
Fremont, D. J., Kim, E., Dreossi, T., Ghosh, S., Yue,
X., Sangiovanni-Vincentelli, A. L., and Seshia, S. A.
(2023). Scenic: A language for scenario specification
and data generation. Machine Learning, 112(10).
George, A. S. (2024). When trust fails: Examining systemic
risk in the digital economy from the 2024 Crowd-
Strike outage. Partners Universal Multidisciplinary
Research Journal, 1(2):134–152.
Gorecki, S., Ribault, J., Zacharewicz, G., Ducq, Y., and
Perry, N. (2019). Risk management and distributed
Early Fault-Detection in the Development of Exceedingly Complex Reactive Systems
327

simulation in papyrus tool for decision making in in-
dustrial context. Comput. & Indus. Engineering, 137.
Haimes, Y. Y. (2018). Risk modeling of interdependent
complex systems of systems: Theory and practice.
Risk Analysis, 38(1):84–98.
Harel, D., Kantor, A., Katz, G., Marron, A., Mizrahi, L.,
and Weiss, G. (2013). On composing and proving the
correctness of reactive behavior. In EMSOFT 2013,
pages 1–10. IEEE.
Harel., D., Katz., G., Marron., A., and Szekely., S. (2024).
On augmenting scenario-based modeling with gener-
ative AI. In MODELSWARD 2024, pages 235–246.
Harel, D., Marron, A., and Sifakis, J. (2020). Auto-
nomics: In search of a foundation for next-generation
autonomous systems. Proceedings of the National
Academy of Sciences, 117(30):17491–17498.
Harel, D. and Pnueli, A. (1984). On the development of
reactive systems. In Logics and models of concur. sys.,
pages 477–498. Springer.
Harel, D., Yerushalmi, R., Marron, A., and Elyasaf, A.
(2024). Categorizing methods for integrating machine
learning with executable specifications. Science China
Information Sciences, 67(1):111101.
Herkert, J., Borenstein, J., and Miller, K. (2020). The Boe-
ing 737 MAX: Lessons for engineering ethics. Sci-
ence and engineering ethics, 26:2957–2974.
Horv
´
ath, B., Moln
´
ar, V., Graics, B., Hajdu,
´
A., R
´
ath, I.,
Horv
´
ath,
´
A., Karban, R., Trancho, G., and Micskei, Z.
(2023). Pragmatic verification and validation of indus-
trial executable SysML models. Systems Engineering,
26(6):693–714.
Huang, E., McGinnis, L. F., and Mitchell, S. W. (2020).
Verifying SysML activity diagrams using formal
transformation to petri nets. Systems Engineering,
23(1):118–135.
Kane, B. R., Webber, S., Tucker, K. H., Wallace, S., Chang,
J., Mccarthy, D., Murphy, D., Egel, D., and Wingfield,
T. (2024). Threats to critical infrastructure. Rand Cor-
poration Research Reports.
Koopman, P. (2024). Anatomy of a robotaxi crash: Lessons
from the Cruise pedestrian dragging mishap. arXiv
preprint arXiv:2402.06046.
Kourani, H., Berti, A., Schuster, D., and van der Aalst,
W. M. (2024). Process modeling with large language
models. In International Conference on Business Pro-
cess Modeling, Development and Support, pages 229–
244. Springer.
Laplante, P. A. and Kassab, M. (2022). What every engineer
should know about software engineering. CRC Press.
Lattimore, M., Karban, R., Gomez, M. P., Bovre, E., and
Reeves, G. E. (2022). A model-based approach for
Europa lander mission concept exploration. In 2022
IEEE Aerospace Conference (AERO), pages 1–13.
IEEE.
Lee, E. A. (2024). Certainty or intelligence: Pick one! In
Design, Automation & Test in Europe (DATE), pages
1–2. IEEE.
Li, N., Tsigkanos, C., Jin, Z., Hu, Z., and Ghezzi, C. (2020).
Early validation of cyber–physical space systems via
multi-concerns integration. Journal of Systems and
Software, 170:110742.
Lo, C., Chen, C.-H., and Zhong, R. Y. (2021). A review of
digital twin in product design and development. Adv.
Eng. Informatics, 48:101297.
Marron, A., Cohen, I. R., Frankel, G., Harel, D., and
Szekely, S. (2024). Challenges in modeling and un-
modeling complex reactive systems: Interaction net-
works, reaction to emergent effects, reactive rule com-
position, and multiple time scales. Springer CCIS.
Minaee, S., Mikolov, T., Nikzad, N., Chenaghlu, M.,
Socher, R., Amatriain, X., and Gao, J. (2024).
Large language models: A survey. arXiv preprint
arXiv:2402.06196.
Nejati, S., Sabetzadeh, M., Falessi, D., Briand, L., and Coq,
T. (2012). A SysML-based approach to traceability
management and design slicing in support of safety
certification: Framework, tool support, and case stud-
ies. Information and Software Technology, 54(6):569–
590.
Netz, L., Michael, J., and Rumpe, B. (2024). From nat-
ural language to web applications: Using large lan-
guage models for model-driven software engineering.
In Modellierung 2024, pages 179–195. Gesellschaft
f
¨
ur Informatik eV.
Noering, F. K.-D., Schroeder, Y., Jonas, K., and Klawonn,
F. (2021). Pattern discovery in time series using au-
toencoder in comparison to nonlearning approaches.
Integrated Computer-Aided Engineering, 28(3).
Oliveira, R., Palanque, P., Weyers, B., Bowen, J., and Dix,
A. (2017). State of the art on formal methods for in-
teractive systems. The handbook of formal methods in
human-computer interaction, pages 3–55.
Pang, G., Shen, C., Cao, L., and Hengel, A. V. D. (2021).
Deep learning for anomaly detection: A review. ACM
comput. surv., 54(2):1–38.
Rahim, M., Boukala-Ioualalen, M., and Hammad, A.
(2021). Hierarchical colored Petri nets for the veri-
fication of SysML designs-activity-based slicing ap-
proach. In Advances in Computing Systems and Ap-
plications: Proc. 4th Conf. on Comp. Sys. and App.,
pages 131–142. Springer.
Ramackers, G. J., Griffioen, P. P., Schouten, M. B., and
Chaudron, M. R. (2021). From prose to prototype:
synthesising executable UML models from natural
language. In MODELS-C, pages 380–389. IEEE.
Seipp, J. and Helmert, M. (2018). Counterexample-guided
cartesian abstraction refinement for classical planning.
J. of Artificial Intel. Res., 62.
Shani, C., Vreeken, J., and Shahaf, D. (2023). Towards
concept-aware large language models. arXiv preprint
arXiv:2311.01866.
Sultan, B. and Apvrille, L. (2024). Ai-driven consistency
of sysml diagrams. In Proceedings of the ACM/IEEE
27th International Conference on Model Driven Engi-
neering Languages and Systems, pages 149–159.
Tamari, R., Shani, C., Hope, T., Petruck, M. R. L., Abend,
O., and Shahaf, D. (2020). Language (re)modelling:
Towards embodied language understanding. In Juraf-
MODELSWARD 2025 - 13th International Conference on Model-Based Software and Systems Engineering
328

sky, D., Chai, J., Schluter, N., and Tetreault, J., editors,
Proc. of the 58th Annual Meeting of the ACL. ACL.
Wang, J., Huang, Y., Chen, C., Liu, Z., Wang, S., and Wang,
Q. (2024). Software testing with large language mod-
els: Survey, landscape, and vision. IEEE Transactions
on Software Engineering.
Weyers, B., Bowen, J., Dix, A., and Palanque, P. (2017).
The handbook of formal methods in human-computer
interaction. Springer.
Yaacov, T., Elyasaf, A., and Weiss, G. (2024). Boosting
LLM-Based Software Generation by Aligning Code
with Requirements. In Proc. 14th Int. Model-Driven
Requirements Engineering Workshop (MoDRE).
Zahid, F., Tanveer, A., Kuo, M. M., and Sinha, R. (2022). A
systematic mapping of semi-formal and formal meth-
ods in requirements engineering of industrial cyber-
physical systems. J. of Intel. Mfg., 33(6).
Zhang, Q., Fang, C., Ma, Y., Sun, W., and Chen, Z. (2023).
A survey of learning-based automated program re-
pair. ACM Transactions on Software Engineering and
Methodology, 33(2):1–69.
Early Fault-Detection in the Development of Exceedingly Complex Reactive Systems
329
