
A Federated Approach to Enhance Calibration
of Distributed ML-Based Intrusion Detection Systems
Jacopo Talpini
a
, Nicol
`
o Civiero, Fabio Sartori
b
and Marco Savi
c
Department of Informatics, Systems and Communication, University of Milano-Bicocca, Milano, Italy
fi
Keywords:
Intrusion Detection, Federated Learning, Machine Learning, Model Calibration.
Abstract:
Network intrusion detection systems (IDSs) are a major component for network security, aimed at protecting
network-accessible endpoints, such as IoT devices, from malicious activities that compromise confidentiality,
integrity, or availability within the network infrastructure. Machine Learning models are becoming a popular
choice for developing an IDS, as they can handle large volumes of network traffic and identify increasingly
sophisticated patterns. However, traditional ML methods often require a centralized large dataset thus raising
privacy and scalability concerns. Federated Learning (FL) offers a promising solution by enabling a collabora-
tive training of an IDS, without sharing raw data among clients. However, existing research on FL-based IDSs
primarily focuses on improving accuracy and detection rates, while little or no attention is given to a proper
estimation of the model’s uncertainty in making predictions. This is however fundamental to increase the
model’s reliability, especially in safety-critical applications, and can be addressed by an appropriate model’s
calibration. This paper introduces a federated calibration approach that ensures the efficient distributed train-
ing of a calibrator while safeguarding privacy, as no calibration data has to be shared by clients with external
entities. Our experimental results confirm that the proposed approach not only preserves model’s performance,
but also significantly enhances confidence estimation, making it ideal to be adopted by IDSs.
1 INTRODUCTION
Network intrusions represent a significant threat to
modern communication systems, with their frequency
and complexity steadily increasing (European Union
Agency for Cybersecurity, 2023). These incidents
compromise data, disrupt services, and erode trust in
digital infrastructures. In this landscape, the Internet
of Things (IoT) represents a growing paradigm that
facilitates the connection of diverse devices and com-
putational capabilities through the Internet.
However, the ongoing expansion of IoT systems,
which often involve a substantial number of devices,
heightens even more the risk of cyber-attacks. As a
result, the development of effective detection strate-
gies and resilient countermeasures has become criti-
cal: proactively identifying vulnerabilities and imple-
menting adaptive defense mechanisms are essential to
safeguarding IoT networks (Hassija et al., 2019).
Intrusion Detection Systems (IDSs) play a primary
a
https://orcid.org/0000-0003-1556-6296
b
https://orcid.org/0000-0002-5038-9785
c
https://orcid.org/0000-0002-8193-0597
role to accomplish this task (Khraisat et al., 2019).
Traditional intrusion detection methods have mainly
relied on knowledge-based systems (Hassija et al.,
2019). However, as networks become more com-
plex, these methods are increasingly prone to errors
(Shone et al., 2018; Tsimenidids et al., 2022). To ad-
dress these challenges, data-driven approaches lever-
aging machine learning (ML) have gained significant
attention in recent years (Saranya et al., 2020), with a
strong focus on detecting attacks in IoT environments
(Al-Garadi et al., 2020), which is difficult given the
high data heterogeneity.
However, a limitation of current ML-based ap-
proaches is their reliance on centralized training,
where data and computational resources are pro-
cessed and managed by a single central node, such
as a server. Such a centralized framework is asso-
ciated with several challenges, including high com-
putational requirements, extended training times, and
heightened concerns over the security and privacy of
users’ data (Mothukuri et al., 2020).
To address these issues, federated learning (FL)
was originally proposed in (McMahan et al., 2017)
and has recently emerged as an effective model train-
840
Talpini, J., Civiero, N., Sartori, F. and Savi, M.
A Federated Approach to Enhance Calibration of Distributed ML-Based Intrusion Detection Systems.
DOI: 10.5220/0013376600003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 2, pages 840-848
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

ing paradigm in the context of network intrusion de-
tection to address the issues recalled above (Campos
et al., 2021; Talpini et al., 2023). It embodies the
principles of focused collection and data minimiza-
tion, and can especially mitigate many of the sys-
temic privacy risks and costs resulting from tradi-
tional, centralized machine learning, including high
communication efficiency and low-latency data pro-
cessing (Kairouz et al., 2021).
In addition, it is fundamental to note that net-
work intrusion detection is a safety-critical applica-
tion, where the consequences of wrong predictions
(i.e., attack yes/no, or which kind of attack) can be
severe and costly. In fact, a network administrator
would require a model that not only is accurate, but
also trustworthy, i.e., able to indicate when its pre-
dictions are likely to be incorrect. In literature, some
works have already pointed out the strong need for
models that are trustworthy (or reliable) in the con-
sidered domain (Talpini et al., 2024).
A fundamental aspect for enhancing the trustwor-
thiness of a ML model relies on its calibration prop-
erty. A model is said to be calibrated if the probabil-
ity associated with the predicted class label matches
the empirical frequency of its ground truth correct-
ness (Guo et al., 2017). As a concrete example, let
us consider an Internet Service Provider that wants to
offer IDS service to its customers and suppose that
the system relies on a ML model to identify whether
network traffic belongs to an attack or not. It would
be beneficial to ensure that the model is calibrated,
so that, out of a certain number of predictions with a
given confidence level, say 90%, we expect roughly
the 90% of samples to be correctly classified. Ensur-
ing such property makes it possible to understand to
what extent the ML model can be trusted in its classi-
fication activity.
However, calibrating a model is not always an
easy task. A model is typically calibrated after its
training by using a calibration dataset (B
¨
oken, 2021).
While this is not an issue in centralized settings,
where a lot of users’ data is made available for model
training, and part could also be used for calibration,
it becomes unfeasible in privacy-preserving scenarios
– such as those targeted by FL – where data cannot
be shared and must be kept local. On the other hand,
performing calibration locally on the globally-trained
model by means of FL may be only partially effective.
To tackle this problem we designed a novel feder-
ated calibration module based on a well-known cali-
bration method, i.e., Platt scaling (B
¨
oken, 2021). Our
strategy embraces the federated learning principles,
and it can be applied to any given pre-trained model.
Given its peculiarities, it is especially suitable in fed-
erated settings where also the calibration operation,
and not only the learning, exploits data from the local
clients. Especially, this module can operate in feder-
ated scenarios without requiring modifications to the
standard FedAvg (McMahan et al., 2017) model ag-
gregation procedure and without the need of changing
or retraining the base model.
We evaluated the effectiveness of our approach
using the ToN-IoT dataset (Sarhan et al., 2021), a
widely adopted benchmark for studying attacks on
IoT infrastructures (Alsaedi et al., 2020), focusing on
how data heterogeneity affects the calibration proper-
ties of the proposed approach. For comparison, we
included a baseline classifier trained in a federated
learning framework, which demonstrated poor cali-
bration properties, as well as a centralized calibration
approach where the calibration module is trained us-
ing data retrieved from clients (i.e., IoT devices) at
a centralized location. Additionally, we tested a per-
sonalized calibration approach where each client in-
dependently trains its own calibrator (i.e., local cali-
bration). Our results show that calibrating the model
is effective to enhance its reliability and that our fed-
erated calibration approach provides (i) better calibra-
tion performance than local calibration, and (ii) only
slightly worse performance than centralized calibra-
tion, which however breaks privacy-preserving con-
straints. In addition, this is obtained without signifi-
cantly altering the model’s classification performance
in terms of F1-Score and accuracy.
To summarize, our main contributions are:
• The definition of a federated calibration module
that works with any pre-trained classifier, but that
is best suited to a federated learning environment.
• An evaluation of the proposed calibration ap-
proach in IoT intrusion detection scenarios with
different clients’ data heterogeneity, and its com-
parison to other relevant baselines.
The structure of the paper is organized as follows.
Section 2 introduces the related work, while Section
3 introduces the proposed federated calibration ap-
proach. Section 4 describes the experimental setup
and the dataset utilized. In Section 5 we provide and
discuss the numerical results, and conclude the pa-
per by highlighting the main takeaways and lessons
learned in Section 6.
2 RELATED WORK
Intrusion Detection Systems are traditionally re-
garded as a secondary layer of defense, designed to
monitor network traffic and identify malicious activ-
A Federated Approach to Enhance Calibration of Distributed ML-Based Intrusion Detection Systems
841

ities that primary security measures (e.g., firewalls)
are not able to identify (Moustafa et al., 2018). IDSs
are typically categorized as either signature-based or
anomaly-based (Tauscher et al., 2021). Signature-
based IDSs, also known as misuse detection systems,
use pattern recognition techniques to compare cur-
rent network traffic against known attack signatures.
In contrast, anomaly-based IDSs build a model of
normal network behavior and identify any deviations
from this baseline as potential intrusions. However,
they often suffer from a high false positive rate (Al-
Garadi et al., 2020).
In this paper, we focus on signature-based intru-
sion detection, with a specific focus on IoT envi-
ronments, and in the following subsection we report
on the relevant work related to data-driven systems,
based on machine learning, in this context. Later, we
also recall relevant recent strategies that have been
proposed to improve the calibration of a model in a
federated setting.
2.1 ML-Based Intrusion Detection
Systems
In recent years, data-driven approaches for develop-
ing IDSs have received a lot of attention from the
research community (Shone et al., 2018; Liu and
Lang, 2019; Tauscher et al., 2021) considering differ-
ent methods such as random forests, support vector
machines, neural networks or clustering techniques.
In particular, machine learning and deep learning are
emerging as powerful data-driven approaches capable
of learning and identifying malicious patterns in net-
work traffic, making them highly effective for detect-
ing security threats in networks (Shone et al., 2018),
and in particular in IoT environments (Chaabouni
et al., 2019; Sarhan et al., 2022).
However, the majority of intrusion detection ap-
proaches proposed for the IoT domain rely on cen-
tralized architectures, where IoT devices transmit
their local datasets to cloud datacenters or centralized
servers. This setup leverages the substantial com-
puting power of these centralized systems for model
training (Campos et al., 2021). As a result, the fed-
erated learning paradigm emerged as a promising al-
ternative to traditional centralized approaches in this
domain, and it is possible to find a few examples in
the literature exploring its feasibility (Rahman et al.,
2020; Campos et al., 2021; Aouedi et al., 2022; Rey
et al., 2022; Talpini et al., 2023).
For instance, in (Rey et al., 2022) the authors pro-
pose a FL-based framework to detect malware, based
on both supervised and unsupervised models. More
precisely, the authors perform a binary classification
with a multi-layer perceptron and an autoencoder on
balanced datasets, which present the same class pro-
portions for every client. Another contribution is rep-
resented by the paper (Campos et al., 2021), in which
the authors investigated a FL approach on a realistic
IoT dataset and showed the issues related to the so-
called statistical heterogeneity, arising from the fact
that typically different devices experience different
kinds of attacks.
Another relevant contribution in the realm of reli-
able models for intrusion detection is (Talpini et al.,
2024), where the authors show how uncertainty quan-
tification can enhance the trustworthiness of an IDS,
with a focus on the usual centralized setting. Our pa-
per is aligned with the vision of (Talpini et al., 2024),
as we propose a federated approach to obtain and de-
ploy calibrated models, which is a primary require-
ment for an uncertainty-aware model.
2.2 Model Calibration in Federated
Settings
Calibration has been extensively studied in the lit-
erature within the traditional centralized setting (see
(Guo et al., 2017) for a comprehensive overview), as
machine learning models, including deep neural net-
works, are often poorly calibrated. Approaches to ad-
dress calibration issues can either involve modifica-
tions to the model itself or adjustments to the standard
loss function (e.g., temperature scaling, focal loss), or
they can be applied post-training, assuming the avail-
ability of a fresh dataset independent of the training
set. In line with the latter approach, several meth-
ods exist to improve calibration, including isotonic
regression and Platt scaling (Guo et al., 2017).
However, the calibration of machine learning
models in federated settings has received limited at-
tention so far. Among the few relevant efforts, recent
research (Peng et al., 2024) demonstrated that existing
federated learning schemes often fail to ensure proper
model calibration following weight aggregation, rais-
ing concerns about the deployment of FL models in
safety-critical domains. To address this, they pro-
posed a post-hoc calibrator based on a multi-layer per-
ceptron with a substantial number of free parameters,
which introduces a risk of overfitting and leads to a
non-negligible communication overhead between the
clients and the central server.
Similarly, (Qi et al., 2023) explored the prob-
lem of model calibration in FL by proposing a strat-
egy that leverages prototype-based summaries of each
client’s data cluster to facilitate effective calibration.
However, their approach is designed for a cross-silo
FL setting, which permits peer-to-peer communica-
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
842

tion between clients. In contrast, this work focuses on
the cross-device FL scenario, where clients commu-
nicate exclusively with a central server.
Another recent study (Chu et al., 2024) proposed
modifying the local training loss by incorporating a
calibration loss to encourage better model calibra-
tion. While effective for neural network models, this
method is unsuitable when pre-trained classifiers are
involved, as envisioned in this paper, since it requires
access to the training process.
All the previous works are related to model cali-
bration without focusing on any specific application
domain. To the best of our knowledge, in the domain
of FL-based network intrusion detection, the issue of
proper model calibration remains unexplored, and this
paper tries to fill this gap.
3 OUR APPROACH TO
FEDERATED CALIBRATION
As mentioned earlier, proper calibration is a prereq-
uisite for reliable learning performance. While model
trustworthiness is typically studied in centralized set-
tings, here we propose a federated calibration mod-
ule (or federated calibrator) that can take as input
any pre-trained model. It operates in federated sce-
narios without requiring modifications to the standard
FedAvg (McMahan et al., 2017) aggregation architec-
ture. More specifically, the module adopts a novel
approach: not only is the model trained in a feder-
ated way, but it is also calibrated in the same manner,
leveraging local calibration information from the lo-
cal clients.
The desired goal of the calibrator module is as
follows: given any classifier that outputs predictive
scores across C classes [ f
0
, .., f
C−1
] (i.e., benign or
specific attacks) for a given input x (i.e., network
traffic sample), establish a meaningful mapping trans-
forming these scores into well-calibrated probabili-
ties. To achieve this goal, we chose to rely on Platt
scaling – also known as sigmoid or logistic calibra-
tion – due to its simplicity and parametric nature that
naturally fits the federated learning workflow.
More specifically, suppose a binary classification
problem and that our base classifier (e.g., a neural net-
work or a decision tree) predicts some score for the
0-th class, denoted as f
0
(x), for a given input x. Platt
scaling maps this score to a probability by means of
a sigmoid function with two learnable parameters, de-
noted here as a and b, as follows:
p(y = 0| f
0
(x)) = sigmoid(a · f
0
(x) + b) (1)
Those parameters are estimated through maxi-
Algorithm 1: Federated Calibrator.
Require: Pre-trained classifier, ˜y = f (x), and the calibra-
tion module ˆy = calibrator( ˜y, w)
Require: For each client k, a fresh calibration dataset D
k
=
{(x
i
, y
i
)}
N
k
i=1
and the corresponding predictions provided
by the base classifier { ˜y
i
}
N
k
i=1
Require: M federated training rounds, learning rate η
Server randomly initializes global model weights w
1
for m = 1, .., M do
for k = 1, .., K do
{ ˆy
i
= calibrator( f (x
i
), w
m
)}
N
k
i=1
▷ calibrator
predictions
L
k
(w) =
∑
N
k
i=1
cross-entropy[(y
i
, ˆy
i
)] ▷ local loss
estimation
w
m
k
← w
m
k
− η∇L
k
(w) ▷ weights update
end for
Server aggregates clients’ updates:
w
m+1
global
← FedAvg({w
m
k
, N
k
}
K
k=1
) ▷ Eq. (2)
end for
return w
M
global
▷ calibrator parameters global estimate
mum likelihood on a validation set D = {(x
i
, y
i
)}
N
i=1
of input-output pairs (x
i
and y
i
, respectively) that, in
this context, we call calibration dataset. In the case
of a classification task (i.e., the task considered in this
paper), the loss function reduces to the usual cross-
entropy loss between the predicted probabilities for a
given input, and the corresponding class label.
The formulation of Equation (1) can be easily ex-
tended to a multi-class classification task by applying
the same equation to each class independently, and
then normalizing the output to ensure a valid probabil-
ity interpretation. The great advantage of Platt scaling
is that it has only a few parameters (as it scales lin-
early with the number of classes) making it suitable
even for calibration datasets of small size. Addition-
ally, it is versatile and, as already pointed out, it can
be applied to any pre-trained model.
Our simple yet effective proposal is to train this
calibrator following the standard federated learning
pipeline, e.g. by adopting FedAvg (McMahan et al.,
2017) in a centralized server. Specifically, the server
(i.e., FL model aggregator) sends to the clients (or
to a random subset of them) a pre-defined calibra-
tor model (in terms of parameters a and b of the sig-
moid function) for local training. Each client trains
the given model with its own data, by minimizing
a given loss function (i.e., cross-entropy) and hence
computing a local update of the weights, here denoted
as w ≡ [a, b] following Equation (1).
At the end of each round, the server collects all
local updates related to a and b and combines them
to update the central model parameters. Following
this iterative process, an arbitrary number of clients
can concur to model calibration without transferring
A Federated Approach to Enhance Calibration of Distributed ML-Based Intrusion Detection Systems
843

the collected data (i.e., calibration dataset) to a cen-
tralized location, since only locally-trained sigmoid
function parameters need to be sent. As said, the com-
mon aggregation function adopted in this paper for
federated calibration is FedAvg, which computes the
global updated weights w
global
as a weighted average
over all clients’ weights w
k
.
w
global
=
1
∑
K
k=1
n
k
·
K
∑
k=1
n
k
w
k
. (2)
Overall, the proposed calibration workflow is co-
ordinated by the central server. It takes as input a
pre-trained base model and provides, as output, a cali-
brated version of it by executing the federated calibra-
tion module and the related workflow, whose details
are reported in Algorithm 1.
Note that the base model may have been trained
following any possible training paradigm. However,
given its peculiarities, our calibration procedure is es-
pecially recommended in the case of a model trained
by means of federated learning, as it follows the
same workflow. Specifically, the model could first be
trained using FL, and then calibrated giving it as input
to our federated calibration module.
4 DATASET AND
EXPERIMENTAL SETUP
4.1 Dataset Description
For exploring the feasibility of our approach, the
choice of a realistic dataset plays a crucial role. In
(Campos et al., 2021) it is possible to find an exten-
sive review of different existing datasets related to in-
trusion detection in the IoT domain. As done in that
paper and given its properties, here we exploit the NF-
ToN-IoT dataset (Sarhan et al., 2021) version 2, which
is based on the ToN IoT set (Alsaedi et al., 2020). Ev-
ery row of the dataset represents a network flow char-
acterized by 43 features, and each flow is labeled as
belonging to one over a total of 10 classes, including
benign traffic and nine different attacks. In the dataset
there are approximately 17 million rows with 63.99%
representing attack samples and 36.01% representing
benign samples.
To distribute data among clients we exploited
a common partition method used in the literature,
which is based on a symmetrical Dirichlet distribu-
tion, governed by a concentration parameter α. Such
a parameter can be used to indicate the statistical het-
erogeneity, where lower values of α (say < 1) lead
to more heterogeneous settings (i.e., more different
sample distributions across classes for the different
clients). In particular, we considered 10 clients with
varying α between 0.2 and 0.9. It is worth mention-
ing that in a network intrusion detection scenario it
is common to have statistical heterogeneity (Campos
et al., 2021) and therefore we concentrated our analy-
sis on a heterogeneous scenario, i.e., with α < 1.
Moreover, to leverage the simplicity of the cali-
bration module, which allows training the calibration
with a small amount of data, we applied a random
sub-sampling of the classes except for the minority
one, so that all the classes are equally represented at
calibration time.
4.2 Adopted Classifier and Calibrator
Implementation
As a base model, we considered an extreme gradient-
boosted decision tree classifier implemented in the
library XGBoost (Chen and Guestrin, 2016). This
model often outperforms more complex models (e.g.,
deep learning models) on tabular data such as the
one considered here (Shwartz-Ziv and Armon, 2022;
Markovic et al., 2022), being very appealing in the
case of network traffic classification.
Each client locally trains its own XGBoost model,
then the central server aggregates the local models to
define a single global model following the federated
learning schema. Boosted decision trees are aggre-
gated as follows: at each FL round, each client sends
its boosted tree to a central server; the server then
treats these trees as bootstrapped versions of a classi-
fier and combines them into an ensemble to create the
final model. So, if we have K clients and M rounds,
the final classifier will consist of K · M trees. The
model aggregation procedure is performed exploiting
the Flower library (Beutel et al., 2020), and the fed-
erated training of the three-based model required 50
training rounds and 10 local epochs per round.
Regarding the calibration module, Platt scaling
has been implemented through Pytorch (Paszke et al.,
2019) as a fully-connected neural network without
hidden layers, with a diagonal weight matrix and with
a sigmoid (i.e., the Platt scaling sigmoid of Equation
(1)) as an activation function. This allowed an easy
implementation of the calibration module directly in
the Flower workflow. The calibrator’s FL training
rounds took 20 rounds and 10 local epochs per round.
4.3 Baseline Strategies
To evaluate the effectiveness of our proposed ap-
proach, we considered the following baselines:
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
844
Federated
Calibrator
Base
model
Server
Local
Calibrator
Client 1
Local
Calibrator
Client 𝑘
…
Centralized
Calibrator
Base
model
Server
Client 1
Client 𝑘
…
Server
Local
Calibrator
Client 1
Local
Calibrator
Client 𝑘
…
Base
model
Network
traffic
data
Network
traffic
data
Base
model
(a) (b) (c)
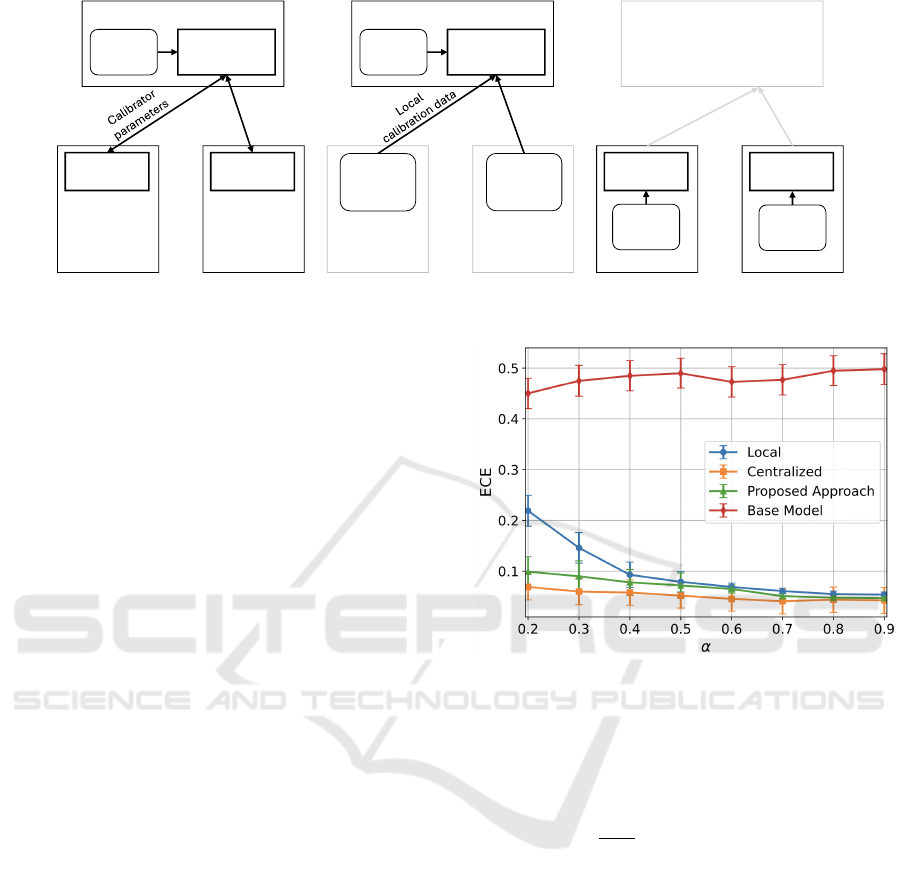
Figure 1: Architectural view of our federated calibration approach (a), centralized calibration (b) and local calibration (c).
• Base model. This is the classifier obtained in a
federated way, as specified in Section 4.2, without
any calibration module.
• Centralized calibration. It represents the most
favorable scenario in terms of calibration perfor-
mance, where the central server has access to a
calibration dataset so that calibration can be per-
formed in the usual centralized setting. However,
this is not a privacy-preserving strategy as a por-
tion of clients’ data needs to be shared with the
central server.
• Local calibration. In this strategy, each client in-
dependently trains its own calibrator using its own
local data. In this way, the calibration is personal-
ized with respect to each client.
• Proposed approach. This is the federated cali-
bration approach proposed in Section 3.
A comparison of the different calibration ap-
proaches is shown in Fig. 1. All the model param-
eters, such as the number of local training epochs
and the number of federation training rounds, are kept
fixed to the values specified in Section 4.2 across the
different baselines and across each value of α, to en-
sure a fair comparison of the models’ performance.
5 PERFORMANCE EVALUATION
The main goal of this paper is to improve the cali-
bration of a given classifier. To assess how much a
model is calibrated, a commonly adopted metric is
the so-called Expected Calibration Error (ECE) (Guo
et al., 2017). To compute it, the predicted proba-
bility is divided into a set of bins and the discrep-
ancy between the empirical probability (i.e., the frac-
tion of correctly-classified samples belonging to the
given confidence range) and the predicted probability
Figure 2: Expected Calibration Error for the considered
models as a function of the clients’ data statistical hetero-
geneity. The curves represent the mean ECE along with the
95% confidence intervals, calculated over 20 experiments
with different random seeds.
is evaluated. More precisely, it is defined as:
ECE =
|B
m
|
N
s
N
b
∑
n=1
|acc(B
n
) − conf(B
n
)| (3)
where N
b
is the number of bins (typically 10), N
s
is
the total number of samples, ACC, and conf represent
the accuracy and the confidence for the samples be-
longing to the n-th bin, denoted as B
n
. ECE values
lie in the range [0, 1], with lower values indicating a
better calibrated model.
In addition, we also evaluated the resulting mod-
els with standard predictive performance metrics such
as accuracy and F1-scores, including both the Macro
F1-Score (F1-Macro) and the Weighted F1-Score
(F1-Weighted), which accounts for the class imbal-
ance by weighting each class’s contribution propor-
tionally to its sample size.
Figure 2 shows the ECE as a function of the het-
erogeneity parameter α for the considered baselines.
It can be seen that the base model is highly un-
calibrated for all the values of α, thus raising concerns
A Federated Approach to Enhance Calibration of Distributed ML-Based Intrusion Detection Systems
845
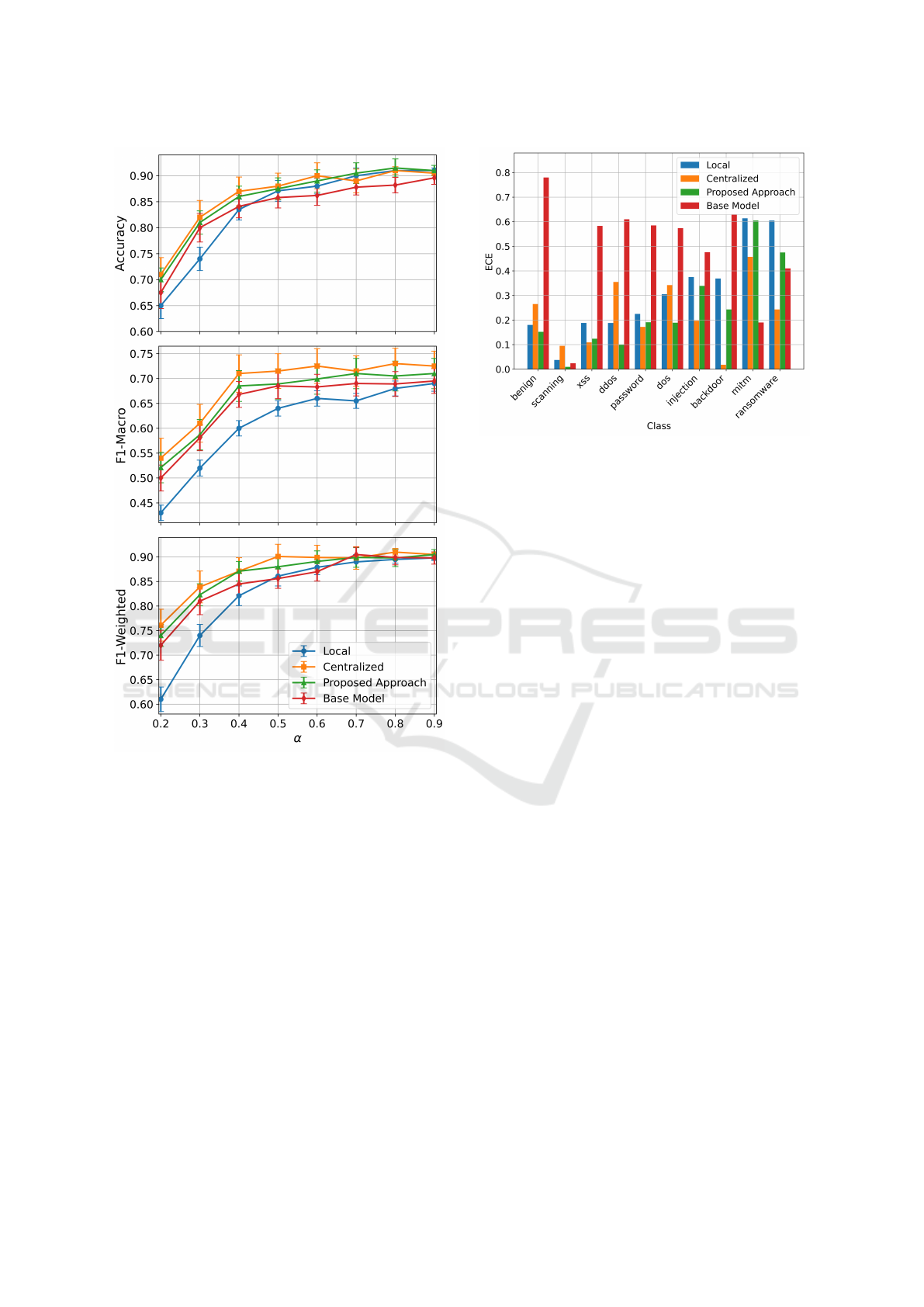
Figure 3: Accuracy and F1-Scores for the considered mod-
els as a function of the clients’ data statistical heterogeneity.
The curves represent the mean values of each metric along
with the 95% confidence interval, computed over 20 differ-
ent experiments with varying random seeds.
about the reliability of standard FL-based models. On
the other hand, we can see that the proposed approach
shows a comparable behavior to centralized calibra-
tion, but without the need for a centralized calibra-
tion dataset, thus guaranteeing privacy and efficiency
since data remains local.
Moreover, the proposed approach leads to better
calibration with respect to a personalized, local cali-
bration. The difference, as expected, is higher in more
heterogeneous settings, where local data are not rep-
resentative of the overall population as typically hap-
pens in a network intrusion detection scenario. In
fact, for instance, certain regions may be more ex-
posed to certain cyber attacks than others, leading to
imbalances in the data collected from each client. The
Figure 4: Per-class ECE for the evaluated models with fixed
data heterogeneity (α = 0.3). The classes are ordered in de-
creasing order based on their sample size. The ECE repre-
sents a mean value, computed over 20 different experiments
with varying random seeds.
ability of the model to perform well under these con-
ditions is important to ensure its effectiveness in prac-
tical, large-scale intrusion detection systems.
It is worth noting that the calibration module does
not negatively impact the classification performance,
as shown in Figure 3, for accuracy, F1-Macro and F1-
Weighted. Here, we can see that our approach guaran-
tees similar classification performance to the central-
ized calibration case and to the base model. Again,
local calibration shows a sub-optimal behavior, es-
pecially in more heterogeneous settings. In addition,
similar results are obtained for the Weighted F1-score,
with even closer performance between our approach,
centralized calibration and base model.
Finally, to further investigate the relationship be-
tween ECE and class imbalance, we report in Figure
4 the per-class ECE, with classes sorted in decreasing
order of sample size. The results highlight that mi-
nority classes (e.g., ransomwere, mitm, etc.) exhibit
significantly higher ECE values, indicating a stronger
calibration challenge in these cases for all the base-
lines, showing how Platt scaling struggles in perform-
ing its task.
6 CONCLUSION
In this paper, we proposed a novel federated calibra-
tion module relying on a calibrator that can be trained
following the standard federated learning pipeline.
The proposed module demonstrates good calibration
performance at small α values, i.e., with heteroge-
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
846

neous client’s data, and maintains comparable perfor-
mance to server-based centralized calibration as α in-
creases (i.e., α > 0.4), while offering advantages in
terms of privacy, as no calibration data must be shared
with the server. At the same time, our federated cali-
bration outperforms a local calibration strategy, where
each client calibrates separately the base model (e.g.
trained by means of FL): separate calibration steps at
different nodes might leverage partially representative
data and, hence, result in non-trustworthy models.
In addition, the classification performance in
terms of accuracy and F1-score of our proposed ap-
proach is not affected with respect to the base model,
and it is comparable to that of a model obtained by
performing centralized calibration.
These features make our approach particularly
well-suited for the deployment of reliable ML-based
Intrusion Detection Systems, where data are typically
unbalanced and where privacy and efficient resource
usage are essential. However, it still faces challenges
to work well with under-represented classes, high-
lighting an area for potential improvements. In ad-
dition, for future works, we plan to investigate other
approaches to calibration in a federated learning set-
ting, like isotonic regression and/or methods based on
the conformal prediction framework.
ACKNOWLEDGMENT
The research leading to these results has been par-
tially funded by the Italian Ministry of University and
Research (MUR) under the PRIN 2022 PNRR frame-
work (EU Contribution – NextGenerationEU – M.
4,C. 2, I. 1.1), SHIELDED project, ID P2022ZWS82.
REFERENCES
Al-Garadi, M. A., Mohamed, A., Al-Ali, A. K., Du, X., Ali,
I., and Guizani, M. (2020). A Survey of Machine and
Deep Learning Methods for Internet of Things (IoT)
Security. IEEE Communications Surveys Tutorials,
22(3):1646–1685.
Alsaedi, A., Moustafa, N., Tari, Z., Mahmood, A., and
Anwar, A. (2020). TON-IoT Telemetry Dataset: A
New Generation Dataset of IoT and IIoT for Data-
Driven Intrusion Detection Systems. IEEE Access,
8:165130–165150.
Aouedi, O., Piamrat, K., Muller, G., and Singh, K. (2022).
Intrusion detection for Softwarized Networks with
Semi-supervised Federated Learning. In ICC 2022.
Beutel, D. J., Topal, T., Mathur, A., Qiu, X., Fernandez-
Marques, J., Gao, Y., Sani, L., Li, K. H., Parcol-
let, T., de Gusm
˜
ao, P. P. B., et al. (2020). Flower:
A Friendly Federated Learning Research Framework.
arXiv preprint arXiv:2007.14390.
B
¨
oken, B. (2021). On the Appropriateness of Platt Scal-
ing in Classifier Calibration. Information Systems,
95:101641.
Campos, E. M., Saura, P. F., Gonz
´
alez-Vidal, A.,
Hern
´
andez-Ramos, J. L., and et al. (2021). Evaluat-
ing Federated Learning for Intrusion Detection in In-
ternet of Things: Review and Challenges. Computer
Networks, page 108661.
Chaabouni, N., Mosbah, M., Zemmari, A., Sauvignac,
C., and Faruki, P. (2019). Network Intrusion De-
tection for IoT Security Based on Learning Tech-
niques. IEEE Communications Surveys Tutorials,
21(3):2671–2701.
Chen, T. and Guestrin, C. (2016). Xgboost: A Scalable Tree
Boosting System. In KDD 2016.
Chu, Y.-W., Han, D.-J., Hosseinalipour, S., and Brin-
ton, C. (2024). Unlocking the Potential of Model
Calibration in Federated Learning. arXiv preprint
arXiv:2409.04901.
European Union Agency for Cybersecurity (2023). ENISA
Threat Landscape 2023. https://www.enisa.europa.eu/
publications/enisa-threat-landscape-2023. [Accessed:
09-December-2024].
Guo, C., Pleiss, G., Sun, Y., and Weinberger, K. Q. (2017).
On Calibration of Modern Neural Networks. In ICML
2017.
Hassija, V., Chamola, V., Saxena, V., Jain, D., and et al.
(2019). A Survey on IoT Security: Application Areas,
Security Threats, and Solution Architectures. IEEE
Access, 7:82721–82743.
Kairouz, P., McMahan, H. B., Avent, B., Bellet, A., et al.
(2021). Advances and Open Problems in Feder-
ated Learning. Foundations and Trends® in Machine
Learning, 14(1–2):1–210.
Khraisat, A., Gondal, I., Vamplew, P., and Kamruzzaman,
J. (2019). Survey of Intrusion Detection Systems:
Techniques, Datasets and Challenges. Cybersecurity,
2(1):1–22.
Liu, H. and Lang, B. (2019). Machine Learning and Deep
Learning Methods for Intrusion Detection Systems: A
Survey. Applied Sciences, 9:4396.
Markovic, T., Leon, M., Buffoni, D., and Punnekkat, S.
(2022). Random Forest based on Federated Learning
for Intrusion Detection. In AIAI 2022. Springer.
McMahan, B., Moore, E., Ramage, D., Hampson, S.,
and y Arcas, B. A. (2017). Communication-efficient
Learning of Deep Networks from Decentralized Data.
In Artificial Intelligence and Statistics, pages 1273–
1282.
Mothukuri, V., Parizi, R., Pouriyeh, S., Huang, Y., and et al.
(2020). A survey on Security and Privacy of Federated
Learning. Future Generation Computer Systems.
Moustafa, N., Hu, J., and Slay, J. (2018). A Holistic Review
of Network Anomaly Detection Systems: A Compre-
hensive Survey. Journal of Network and Computer
Applications, 128.
A Federated Approach to Enhance Calibration of Distributed ML-Based Intrusion Detection Systems
847

Paszke, A. et al. (2019). PyTorch: An Imperative
Style, High-Performance Deep Learning Library. In
NeurIPS 2019.
Peng, H., Yu, H., Tang, X., and Li, X. (2024). FedCal:
Achieving Local and Global Calibration in Federated
Learning via Aggregated Parameterized Scaler. In
ICML 2024.
Qi, Z., Meng, L., Chen, Z., Hu, H., Lin, H., and Meng, X.
(2023). Cross-silo Prototypical Calibration for Feder-
ated Learning with Non-iid Data. In Multimedia 2023.
Rahman, S. A., Tout, H., Talhi, C., and Mourad, A. (2020).
Internet of Things Intrusion Detection: Centralized,
On-Device, or Federated Learning? IEEE Network,
34(6):310–317.
Rey, V., S
´
anchez, P. M. S., Celdr
´
an, A. H., and Bovet, G.
(2022). Federated Learning for Malware Detection in
IoT devices. Computer Networks, 204:108693.
Saranya, T., Sridevi, S., Deisy, C., Chung, T. D., and Khan,
M. (2020). Performance Analysis of Machine Learn-
ing Algorithms in Intrusion Detection System: A Re-
view. Procedia Computer Science, 171:1251–1260.
Sarhan, M., Layeghy, S., Moustafa, N., Gallagher, M., and
Portmann, M. (2022). Feature Extraction for Machine
Learning-based Intrusion Detection in IoT Networks.
Digital Communications and Networks.
Sarhan, M., Layeghy, S., and Portmann, M. (2021).
Evaluating Standard Feature Sets Towards Increased
Generalisability and Explainability of ML-based
Network Intrusion Detection. arXiv preprint
arXiv:2104.07183.
Shone, N., Ngoc, T. N., Phai, V. D., and Shi, Q. (2018). A
Deep Learning Approach to Network Intrusion Detec-
tion. IEEE Transactions on Emerging Topics in Com-
putational Intelligence, 2(1):41–50.
Shwartz-Ziv, R. and Armon, A. (2022). Tabular Data: Deep
Learning is not All You Need. Information Fusion,
81:84–90.
Talpini, J., Sartori, F., and Savi, M. (2023). A Clustering
Strategy for Enhanced FL-Based Intrusion Detection
in IoT Networks. In ICAART 2023.
Talpini, J., Sartori, F., and Savi, M. (2024). Enhancing
Trustworthiness in ML-Based Network Intrusion De-
tection with Uncertainty Quantification. Journal of
Reliable Intelligent Environments, pages 1–20.
Tauscher, Z., Jiang, Y., Zhang, K., Wang, J., and Song, H.
(2021). Learning to Detect: A Data-driven Approach
for Network Intrusion Detection. In IPCCC 2021.
Tsimenidids, S., Lagkas, T., and Rantos, K. (2022). Deep
Learning in IoT Intrusion Detection. Journal of Net-
work and Systems Management, 30.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
848
