
Rethinking Deblurring Strategies for 3D Reconstruction: Joint
Optimization vs. Modular Approaches
Akash Malhotra
1,2
, Nac
´
era Seghouani
2
, Ahmad Abu Saiid
3
, Alaa Almatuwa
3
and Koumudi Ganepola
3
1
Amadeus, Sophia Antipolis, France
2
Universit
´
e Paris-Saclay, LISN, France
3
Universit
´
e Paris-Saclay, CentraleSup
´
elec, France
{akash.malhotra, nacera.seghouani}@lisn.fr, {ahmad.ahmad, alaa-jawad-abdulla-ali.almutawa,
Keywords:
Multiview Synthesis, 3D Reconstruction, Deblurring, Neural Radiance Fields (NeRF), Image Restoration.
Abstract:
In this paper, we present a comparison between joint optimization and modular frameworks for addressing
deblurring in multiview 3D reconstruction. Casual captures, especially with handheld devices, often contain
blurry images that degrade the quality of 3D reconstruction. Joint optimization frameworks tackle this issue by
integrating deblurring and 3D reconstruction into a unified learning process, leveraging information from over-
lapping blurry images. While effective, these methods increase the complexity and training time. Conversely,
modular approaches decouple deblurring from 3D reconstruction, enabling the use of stand-alone deblurring
algorithms such as Richardson-Lucy, DeepRFT, and Restormer. In this study, we evaluate the trade-offs be-
tween these strategies in terms of reconstruction quality, computational complexity, and suitability for varying
levels of blur. Our findings reveal that modular approaches are more effective for low to medium blur scenar-
ios, while Deblur-NeRF, a joint optimization framework, excels at handling extreme blur when computational
costs are not a constraint.
1 INTRODUCTION
Multiview photorealistic 3D reconstruction, used in
virtual reality, autonomous navigation, and visual ef-
fects, enables the creation of realistic 3D represen-
tations. These underlying 3D representations are of-
ten created by techniques such as Neural Radiance
Fields (NeRF) (Mildenhall et al., 2020) and 3D Gaus-
sian Splatting (Kerbl et al., 2023), which have in-
troduced learning-based algorithms. However, these
methods heavily rely on clean, high-quality input im-
ages that leads to poor performance for handheld cap-
tures, which often have out-of-focus blur and motion
blur. These degradations are particularly problematic
as they impair feature matching between views and
introduce uncertainties in geometry estimation, lead-
ing to inconsistent or incomplete 3D reconstruction.
Several methods address blur through integration
of deblurring directly into the reconstruction pipeline,
such as Deblur-NeRF (Ma et al., 2021), BAD-NeRF
(Wang et al., 2023), and PDRF (Peng and Chellappa,
2023). Although these approaches achieve higher re-
construction fidelity through joint optimization of im-
age deblurring and scene representation, they come
with significant drawbacks: increased number of pa-
rameters, longer training times, higher computational
complexity and more complex model architectures.
Alternatively, standalone deblurring algorithms can
be used to preprocess the images before 3D Recon-
struction. Recent deblurring methods have made sub-
stantial progress in enhancing the visual quality of
noisy images (Zhang et al., 2022). However, their im-
pact on downstream 3D reconstruction tasks remains
unexplored.
This work evaluates two approaches for address-
ing blur in 3D reconstruction: the modular frame-
work, where images are preprocessed with stan-
dalone deblurring models before training NeRF; and
the joint-optimization framework, where deblurring
and reconstruction are performed simultaneously in
Deblur-NeRF (Ma et al., 2021) framework. Through
experiments and complexity analysis on synthetic
and real-world scenes, we quantify the trade-offs be-
tween reconstruction quality and computational com-
plexity of the two approaches. For the modular
pipeline, we evaluated both traditional algorithms
such as Richardson-Lucy (Fish et al., 1995) and mod-
ern learning-based methods such as DeepRFT (Mao
816
Malhotra, A., Seghouani, N., Saiid, A. A., Almatuwa, A. and Ganepola, K.
Rethinking Deblurring Strategies for 3D Reconstruction: Joint Optimization vs. Modular Approaches.
DOI: 10.5220/0013378800003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 3: VISAPP, pages
816-823
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

et al., 2023) and Restormer (Zamir et al., 2022).
Our experiments and analysis reveal several key
insights for practical applications:
1. For low to medium blur, also called decent blur, it
is better to use the modular pipeline with Deep-
RFT(Mao et al., 2023) as the deblurring algo-
rithm, especially in relation to the compute bud-
get.
2. For images with extreme blur, DeblurNeRF is
preferable, especially when the computing budget
is not constrained.
3. Larger models for preprocessing in the modular
framework are not always better, as evidenced
by DeepRFT outperforming Restormer and other
Transformer based methods.
The remainder of this paper is organized as fol-
lows. Section 2 reviews related work on various de-
blurring techniques. Section 3 provides background
information on the fundamentals of NeRF and blur
modeling. Section 4 details our methodology, includ-
ing datasets, experimental setup, and evaluation met-
rics. Section 5 presents our experimental results and
analysis of both joint optimization and modular ap-
proaches. Finally, Section 6 concludes on our main
results for practical applications.
2 RELATED WORK
Research in addressing blur for 3D reconstruction has
evolved from classical image restoration to modern
neural approaches, with recent work focusing on joint
optimization techniques.
Evolution of Image Deblurring
Early deblurring approaches relied on analytical
methods such as Fourier-based techniques (Richard-
son, 1972) and Bayesian deconvolution (Fergus et al.,
2006). While these methods established important
theoretical foundations, they struggled with spatially
varying blur and complex degradation patterns. Later
studies explored blur detection (Koik and Ibrahim,
2013) and kernel estimation (Smith, 2012), while
work on camera response functions (Grossberg and
Nayar, 2004) provided foundational understanding of
imaging systems. The field progressed to multi-image
techniques that leveraged information from multiple
views or frames (Li et al., 2023), showing improved
results but requiring careful image alignment and reg-
istration.
Modern Deblurring Approaches
Deep learning has revolutionized image deblurring
through two main approaches: single-image and
multi-image methods. Single-image techniques have
seen rapid advancement through architectures like
Restormer (Zamir et al., 2022), which employs
transformers for modeling long-range dependencies,
multi-stage progressive restoration frameworks like
MPRNet (Zamir et al., 2021), and DeepRFT (Mao
et al., 2023), which integrates frequency-domain pro-
cessing. These methods are often optimized for
perceptual quality metrics and standard image qual-
ity assessments (Zhang et al., 2022) rather than
downstream tasks. Multi-image approaches like
BiT (Zhong et al., 2023) and GShift-Net (Li et al.,
2023) leverage temporal consistency to handle com-
plex motion blur patterns and maintain consistency
across multiple views.
Joint Optimization with Neural Radiance Fields
The emergence of Neural Radiance Fields
(NeRF) (Mildenhall et al., 2020) has spurred
new approaches that jointly handle deblurring
and 3D reconstruction. Research has shown that
input image quality significantly impacts NeRF
performance (Liang et al., 2023) (Rubloff, 2023).
Deblur-NeRF (Ma et al., 2021) pioneered this di-
rection by incorporating deformable sparse kernels
into the NeRF framework. BAD-NeRF (Wang et al.,
2023) extended this approach by integrating bundle
adjustment, while PDRF (Peng and Chellappa,
2023) introduced progressive refinement. These
methods achieve high-quality results but at the cost
of increased computational complexity and training
time.
Scope of this Work
While previous studies have advanced deblurring
techniques or joint optimization frameworks indepen-
dently, there is no systematic comparison of these ap-
proaches in the context of 3D reconstruction. Our
work bridges this gap by evaluating when the added
complexity of joint optimization frameworks is jus-
tified versus when simpler, modular solutions using
state-of-the-art deblurring methods suffice. We ana-
lyze these trade-offs across different blur conditions
and computational constraints, providing practical in-
sights for choosing appropriate techniques in real-
world applications.
Rethinking Deblurring Strategies for 3D Reconstruction: Joint Optimization vs. Modular Approaches
817

Figure 1: Different types and levels of blur for the Blurball scene.
3 BACKGROUND
Neural Radiance Fields
Neural Radiance Fields (NeRF) (Mildenhall et al.,
2020) provide a powerful paradigm for 3D recon-
struction by representing a scene as a continuous 5D
function that maps spatial coordinates and viewing di-
rections to color and density. Formally, let (x, y, z) and
(θ, φ) denote, respectively, a 3D location and a view-
ing direction. NeRF learns a function:
(c, σ) = F
Θ
(γ(x, y, z), φ(θ, φ)) (1)
where c is the emitted color, σ is the volume den-
sity, γ(·) is a positional encoding to map coordinates
into a higher-dimensional space, and Θ are the learn-
able parameters of the neural network. Rendering a
pixel color C(r) of a ray r cast into the scene involves
integrating the contributions of sampled points along
that ray:
C(r) =
N
∑
i=1
T
i
1 − exp(−σ
i
δ
i
)
c
i
(2)
where
T
i
= exp
−
i−1
∑
j=1
σ
j
δ
j
!
(3)
and δ
i
is the distance between consecutive sample
points along the ray. By optimizing NeRF parameters
to minimize the discrepancy between rendered and
captured images, one can achieve high-fidelity novel
view synthesis, provided the input images are sharp
and noise-free.
However, real-world captures often contain mo-
tion blur due to camera or subject movement during
exposure. Such blur distorts the observed pixel col-
ors, hindering NeRF’s ability to infer accurate scene
geometry and radiance distributions. Standard NeRF,
lacking mechanisms to account for blur, typically
yields suboptimal reconstruction quality under these
conditions.
Joint Optimization Framework
Addressing blur within the reconstruction pipeline
can follow two main strategies: joint optimization
and modular frameworks. Joint optimization frame-
works incorporate the modeling of blur directly into
the NeRF training process. Deblur-NeRF (Ma et al.,
2022) exemplifies this philosophy by introducing a
Deformable Sparse Kernel (DSK) that models spa-
tially varying blur kernels. Instead of a uniform con-
volution, Deblur-NeRF approximates the blur of a
pixel p as a sparse weighted combination of neigh-
boring colors:
b
p
= c
p
∗ h (4)
where b
p
and c
p
are blurred and sharp pixel col-
ors respectively, and h is a blur kernel. To improve
computational efficiency, it leverages a sparse set of
kernel points:
b
p
=
∑
q∈N(p)
w
q
c
q
(5)
with N(p) denoting the neighborhood of pixel p
and w
q
the learned weights. Additionally, Deblur-
NeRF refines the ray origins for each pixel by intro-
ducing offsets ∆o
q
:
r
q
= (o
q
+ ∆o
q
) +t d
q
(6)
allowing the model to compensate for spatially
varying blur patterns. This joint optimization of
NeRF parameters and kernel properties enables the
network to restore sharpness while simultaneously
improving reconstruction fidelity, effectively learning
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
818

Figure 2: Experimental workflow. Comparison of DeblurNeRF with the modular approach. Deblurring and 3D reconstruction
(using NeRF) are decoupled. Many non deep learning and deep learning based algorithms for deblurring are compared in the
modular approach.
a scene representation that is robust to blur. The trade-
off, however, is significantly increased complexity,
computational overhead, and resource usage, poten-
tially limiting scalability.
Modular Framework
In the modular framework, various deblurring tech-
niques are employed as pre-processing steps to en-
hance image quality before 3D reconstruction. In this
work, we evaluated and compared many approaches
based on deep learning and non-deep learning, which
are briefly explained in Section 2. They can take a
single image or multiple images as inputs. Multiple
images can be given as inputs if the images are in a
form of a video or are positionally close to each other
in a multiview setting.
Ultimately, the choice between joint optimiza-
tion and modular solutions involves balancing com-
putational complexity, model capacity, and recon-
struction fidelity. Joint optimization methods such
as Deblur-NeRF closely align the blur compensation
process with scene representation but demand sub-
stantial computational resources. Modular pipelines,
by contrast, allow users to exploit off-the-shelf de-
blurring models to preprocess images before training
a standard NeRF, improving scalability and ease of
use. Understanding these complementary strategies
sets the stage for informed pipeline design, partic-
ularly as the field moves toward more practical and
resource-efficient solutions for robust 3D reconstruc-
tion under real-world conditions of motion and other
kind of blurs.
Metrics
When all or some of the reference images (sharp or
noiseless) are available, the standard 3D reconstruc-
tion metrics PSNR, SSIM (Wang et al., 2004), and
LPIPS (Zhang et al., 2018) are utilized to evaluate the
reconstructions.
To compare the standalone deblurring algorithms
used in the modular framework, we utilize FFT Blur
Score (Rosebrock, 2020). It provides a frequency-
domain perspective by quantifying the residual blur
in images based on their high-frequency content and
is calculated as:
Blur Score =
Max FFT
d
− FFT Value
i
Max Blur Dist
(7)
where Max FFT
d
is the maximum FFT score in
the dataset, FFT Value
i
is the FFT score for the cur-
rent image, and Max Blur Dist is an empirically de-
termined constant that captures the maximum FFT
distance between clear and blurry frames. This met-
ric normalizes the blur score between 0 (sharpest) and
1 (most blurred). Unlike PSNR, SSIM, and LPIPS,
which rely on reference images, the FFT Blur Score
can evaluate blur independently, making it particu-
larly useful in scenarios lacking sharp ground truth.
4 METHODOLOGY
Our methodology systematically evaluates the joint
optimization framework using DeblurNeRF, and the
Rethinking Deblurring Strategies for 3D Reconstruction: Joint Optimization vs. Modular Approaches
819

Figure 3: Qualitative comparison of different deblurring models on Blurball scene for spatially varying blur.
modular approach that combines standalone deblur-
ring techniques with NeRF, as shown in Figure 2.
We employed a two-stage evaluation process. In the
first stage, using the synthetic Blurwine scene, we
comprehensively tested a broad range of deblurring
techniques in the modular approach. Among tradi-
tional deblurring algorithms, the sharpening filter, the
Wiener filter, a combination of both, and the blind
Richardson-Lucy were tested. From the deep learn-
ing approaches that act on a single image at a time,
MPRNet, Restormer and DeepRFT were tested. We
also considered multi-image or temporal models such
as GShift-Net and the Blur Interpolation Transformer
(BiT), which exploit additional frames or viewpoints
to improve deblurring quality (cf. Section 3). In ad-
dition to applying GShift-Net to the video of the blur-
wine scene, we also tested GShift-Net with the neigh-
boring images instead with respect to the camera po-
sitions, and call it ”GShift-Net Adjusted”.
Based on the performance results from the Blur-
wine scene, we selected the most promising algo-
rithms - DeepRFT, Restormer, and MPRNet - for
evaluation on the more challenging real-world scenes
(Blurball and Blurobject). This selective testing ap-
proach allowed us to focus computational resources
on the most effective methods while maintaining ex-
perimental rigor. After applying these methods on the
input images, we use NeRF for 3D reconstruction and
record the reconstruction quality. In parallel, we use
DeblurNeRF as a joint optimization framework and
record its reconstruction quality. The comparison be-
tween them is discussed in Section 5.
Our experiments utilize the following three
scenes, each designed to evaluate the performance
of joint optimization and modular frameworks under
varying blur conditions. Examples of different types
and levels of blur are shown in Figure 1. The scenes
are as follows:
1. Blurwine: Introduced by (Ma et al., 2021), this
synthetic motion blur scene consists of 34 images,
split into 29 for training and 5 for testing. Im-
ages were generated with controlled motion blur
to facilitate quantitative evaluation against ground
truth. Each scene contains both blurred and sharp
(reference) images.
2. Blurball: Also introduced by (Ma et al., 2021),
it is a real-world blurry scene with 27 images,
split into 23 for training and 4 for testing. These
images were captured under extreme motion blur
conditions using deliberate camera shake. Ground
truth reference images were captured using a tri-
pod setup to ensure stability.
3. Blurobject: For the current study, we created a
novel real-world motion blur scene, containing 33
images, divided into 28 for training and 5 for test-
ing. These images were captured using a Canon
2000D camera under manual exposure, introduc-
ing mild blur levels reflective of everyday scenar-
ios. Unlike Blurball, these images were not de-
rived from videos but from individual image cap-
tures for a generalized scenario.
Each scene includes a combination of sharp and
blurred reference images. The blurred images re-
flect varying levels of motion blur, ranging from con-
trolled synthetic settings in Blurwine to moderate
and extreme real-world conditions in Blurobject and
Blurball, respectively. Scenes were processed using
COLMAP (Schonberger and Frahm, 2016) scripts to
compute camera poses, which are also given as input
to NeRF.
We employ multiple complementary metrics to
comprehensively evaluate reconstruction quality. For
the scene with ground truth images (Blurwine), we
use PSNR, SSIM, and LPIPS to evaluate reconstruc-
tions. For real-world scenes (Blurball and Blurob-
ject), we assess reconstruction quality using the sub-
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
820

set of sharp images as reference. In the absence of
sharp reference images, as in the case of Blurobjects
scene, we employ FFT Blur Score. These metrics
are explained in Section 3. All experiments main-
tain consistent NeRF training protocols. We also an-
alyze computational efficiency through floating point
operations per second (FLOPs) counts, memory us-
age, and total training time to understand the practical
implications of each approach.
Figure 4: Qualitative comparison of different deblurring
models on Blurobject scene.
Table 1: Blur FFT Scores on Blurobject scene (Lower
scores are better).
Deblurring Technique Blur FFT Score
Original 0.71
Restormer 0.54
MPRNet 0.57
DeepRFT 0.42
5 RESULTS AND DISCUSSION
Our experiments evaluated the effectiveness of joint
optimization and modular frameworks in handling
motion blur for 3D reconstruction across synthetic
and real-world scenes.
As shown in Table 2, in the Blurwine scene,
with controlled blur, Deblur-NeRF’s joint optimiza-
tion strategy achieved superior reconstruction qual-
ity with a PSNR of 27.47, SSIM of 0.86, and LPIPS
of 0.14. Among modular approaches, DeepRFT per-
formed best with a PSNR of 22.89, SSIM of 0.73,
and LPIPS of 0.23. Traditional methods like Wiener
filter and Blind Richardson-Lucy performed poorly,
often worse than the original blurred inputs used with
NeRF, possibly due to their inability to model com-
plex, spatially varying blur patterns. While GShift-
Net showed some improvement over traditional meth-
Table 2: Quantitative comparison of various deblurring
techniques on the Blurwine scene.
Model PSNR SSIM LPIPS
NeRF 21.11 0.63 0.36
Deblur-NeRF 27.47 0.86 0.14
Filtering 10.33 0.10 0.63
Sharpening 21.53 0.67 0.28
Wiener Filter 19.75 0.54 0.41
Wiener + Sharpening 19.67 0.54 0.36
Richardson-Lucy 20.84 0.61 0.34
Restormer 22.88 0.73 0.23
GShift-Net 20.49 0.61 0.34
GShiftNet Adjusted 21.46 0.66 0.31
MPRNet 22.36 0.70 0.26
BiT 16.85 0.47 0.35
DeepRFT 22.89 0.73 0.23
ods (PSNR: 20.49), it still lagged significantly behind
other deep learning approaches.
As shown in Table 3, for the Blurball scene with
extreme motion blur, Deblur-NeRF maintained strong
performance (PSNR: 27.39, SSIM: 0.77) through its
joint optimization of NeRF parameters and spatially
varying blur kernels. DeepRFT demonstrated ro-
bustness to severe blur (PSNR: 24.90, SSIM: 0.66).
However, in the Blurobject scene with moderate blur,
DeepRFT slightly outperformed Deblur-NeRF with
a PSNR of 22.11 and SSIM of 0.47, compared to
Deblur-NeRF’s PSNR of 21.14 and SSIM of 0.44.
Our experiments revealed several unexpected
findings. DeepRFT, despite having a smaller model
size than Restormer, consistently achieved better re-
construction quality across all scenes. This is also
seen in Table 1. This suggests that incorporating
Fourier domain processing into neural architectures
can be more effective than simply increasing model
capacity. Another surprising result was that single-
image methods (DeepRFT and Restormer) outper-
formed multi-image approaches like BiT and GShift-
Net. While BiT achieved a PSNR of 16.85 and
GShift-Net 20.49 on the synthetic scene, DeepRFT
and Restormer achieved 22.89 and 22.88 respectively,
indicating that additional temporal information did
not necessarily translate to better deblurring perfor-
mance for 3D reconstruction.
The computational analysis reveals significant dif-
ferences between the approaches, as can be seen in
Table 4. Deblur-NeRF requires substantial resources
due to its deformable sparse kernel optimization and
increased ray rendering, resulting in approximately
five times the FLOPs per pixel compared to Vanil-
laNeRF. This complexity demands at least 32 GB
memory and training times spanning multiple days
for large scenes. In contrast, the modular approach
Rethinking Deblurring Strategies for 3D Reconstruction: Joint Optimization vs. Modular Approaches
821
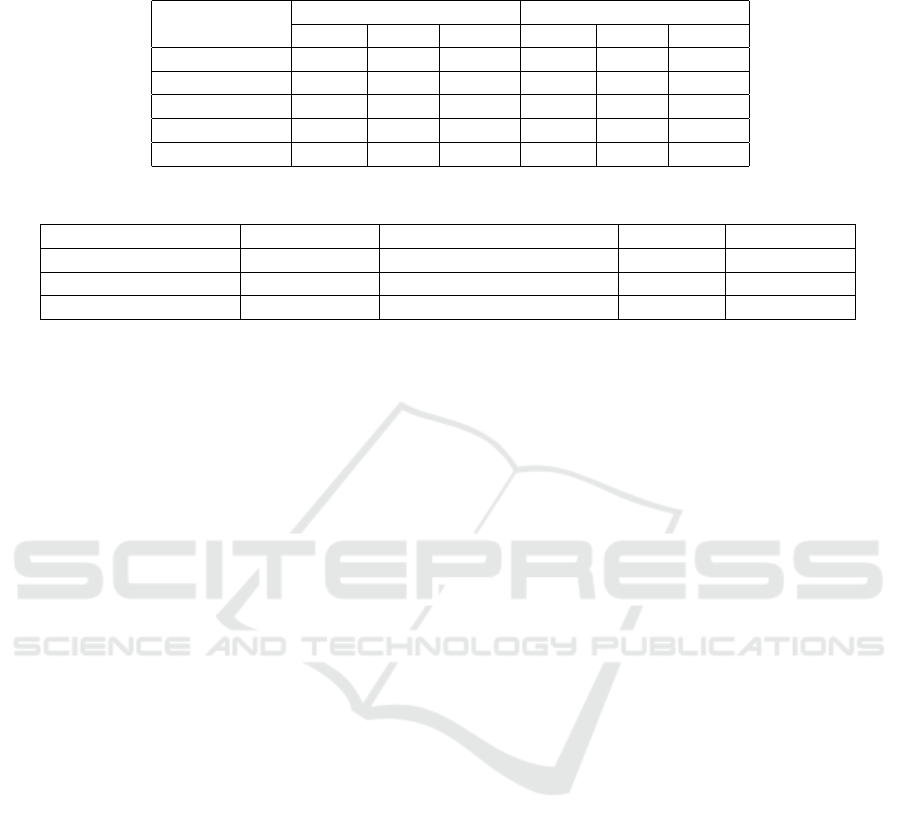
Table 3: Reconstruction results on Blurball and Blurobject scene without any Deblurring (NeRF), with DeblurNeRF and with
modular approach using vaious deblurring models.
Method
Blurball Blurobject
PSNR SSIM LPIPS PSNR SSIM LPIPS
NeRF 24.03 0.62 0.40 17.32 0.32 0.44
Deblur-NeRF 27.38 0.77 0.24 21.14 0.44 0.39
Restormer 23.17 0.61 0.41 21.51 0.47 0.32
MPRNet 23.24 0.62 0.39 21.57 0.47 0.33
DeepRFT 24.89 0.66 0.35 22.11 0.47 0.29
Table 4: Approximate computational complexity comparison of DeblurNeRF and modular approach with DeepRFT.
Metric Deblur-NeRF DeepRFT + VanillaNeRF DeepRFT VanillaNeRF
Training Time 4x 1x Pretrained Baseline (1x)
Memory Requirement 32 GB 16 GB 8 GB 8 GB
FLOPs per Pixel 5x 1.1x 0.1x Baseline (1x)
using DeepRFT with VanillaNeRF is more efficient.
DeepRFT’s FFT-based operations and single forward
pass during inference keep computational and mem-
ory requirements low while maintaining competitive
reconstruction quality.
These results highlight the complementary
strengths of each approach. Deblur-NeRF excels with
extreme blur, but requires significant computational
resources, limiting its scalability. The modular
approach with DeepRFT offers a practical alternative,
particularly effective for moderate blur scenarios and
resource-constrained environments. For applications
with extreme blur and abundant computational
resources, Deblur-NeRF is optimal. However, when
dealing with moderate blur or limited resources,
the modular approach with DeepRFT provides an
efficient and effective solution.
6 CONCLUSION
This study investigated the trade-offs between joint
optimization and modular frameworks for mitigat-
ing blur in 3D reconstruction. Our experiments re-
vealed that Deblur-NeRF excels at handling extreme
blur through joint optimization, while the modular
approach with DeepRFT offers an efficient alterna-
tive for moderate blur scenarios. Traditional methods
proved inadequate for complex blur patterns found in
the real world scenes, while modern deep learning
methods showed better performance. Surprisingly,
DeepRFT outperformed both the larger Restormer
model and multi-image approaches like BiT and
GShift-Net, suggesting that incorporating Fourier do-
main processing into neural networks is a promising
yet underexplored direction.
Our contribution of the Blurobject scene dataset
provides a compelling benchmark based on real world
scenarios. This dataset fills a critical gap between
synthetic and extreme blur datasets, providing a valu-
able resource for evaluating deblurring techniques.
The findings emphasize the importance of matching
deblurring strategies to application requirements.
Future work could extend this analysis to a
broader range of scenes and newer 3D reconstruc-
tion techniques like Gaussian Splatting. The strong
performance of DeepRFT could motivate further re-
search into efficient architectures that can maintain
high quality of reconstruction with reduced compu-
tational demands.
Supplementary. Please refer to the following
github repository for more code and more details.
https://github.com/AlaaAlmutawa/BDRP.
REFERENCES
Fergus, R., Singh, B., Hertzmann, A., Roweis, S. T., and
Freeman, W. T. (2006). Removing camera shake from
a single photograph. ACM Transactions on Graphics
(TOG), 25(3):787–794.
Fish, D. A., Brinicombe, A. M., Pike, E. R., and Walker,
J. G. (1995). Blind deconvolution by means of the
richardson-lucy algorithm. JOSA A, 12(1):58–65.
Grossberg, M. D. and Nayar, S. K. (2004). Modeling the
space of camera response functions. IEEE Transac-
tions on Pattern Analysis and Machine Intelligence,
26(10):1272–1282.
Kerbl, B., Kopanas, G., Leimk
¨
uhler, T., and Drettakis, G.
(2023). 3d gaussian splatting for real-time radiance
field rendering. ACM Trans. Graph., 42(4):139–1.
Koik, B. T. and Ibrahim, H. (2013). A literature survey on
blur detection algorithms for digital imaging. In 2013
1st International Conference on Artificial Intelligence,
Modelling and Simulation, pages 272–277.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
822

Li, D., Shi, X., Zhang, Y., Cheung, K.-T., See, S., Wang, X.,
and Li, H. (2023). A simple baseline for video restora-
tion with grouped spatial-temporal shift. In Proceed-
ings of the IEEE/CVF Conference on Computer Vision
and Pattern Recognition (CVPR), pages 9822–9832.
Liang, H., Wu, T., Hanji, P., Banterle, F., Gao, H., Mantiuk,
R., and Oztireli, C. (2023). Perceptual quality assess-
ment of nerf and neural view synthesis methods for
front-facing views. arXiv preprint arXiv:2303.15206.
Ma, L., Li, X., Liao, Z., Zhang, Q., Wang, X., Wang,
J., and Sander, P. V. (2021). Deblur-nerf: Neural
radiance fields from blurry images. arXiv preprint
arXiv:2111.14292.
Mao, X., Liu, Y., Liu, F., Li, Q., Shen, W., and Wang, Y.
(2023). Intriguing findings of frequency selection for
image deblurring. In Proceedings of the AAAI Con-
ference on Artificial Intelligence, volume 37, pages
1905–1913.
Mildenhall, B., Srinivasan, P. P., Tancik, M., Barron, J. T.,
Ramamoorthi, R., and Ng, R. (2020). Nerf: Repre-
senting scenes as neural radiance fields for view syn-
thesis. In Proceedings of the European Conference on
Computer Vision (ECCV), pages 405–421. Springer.
Peng, C. and Chellappa, R. (2023). Pdrf: Progressively
deblurring radiance field for fast scene reconstruction
from blurry images. In Proceedings of the AAAI Con-
ference on Artificial Intelligence, volume 37, pages
2029–2037.
Richardson, W. H. (1972). Bayesian-based iterative method
of image restoration. JOSA, 62(1):55–59.
Rosebrock, A. (2020). Opencv fast fourier transform (fft)
for blur detection in images and video streams. Ac-
cessed: 2024-12-16.
Rubloff, M. (2023). What are the nerf metrics? Accessed:
2023-12-19.
Schonberger, J. L. and Frahm, J.-M. (2016). Structure-
from-motion revisited. In Proceedings of the IEEE
conference on computer vision and pattern recogni-
tion, pages 4104–4113.
Smith, L. (2012). Estimating an image’s blur kernel from
edge intensity profiles. Technical report, Naval Re-
search Laboratory.
Wang, P., Zhao, L., Ma, R., and Liu, P. (2023). Bad-nerf:
Bundle adjusted deblur neural radiance fields. In Pro-
ceedings of the IEEE/CVF Conference on Computer
Vision and Pattern Recognition (CVPR), pages 4170–
4179.
Wang, Z., Bovik, A. C., Sheikh, H. R., and Simoncelli, E. P.
(2004). Image quality assessment: From error visi-
bility to structural similarity. IEEE Transactions on
Image Processing, 13(4):600–612. Accessed: 2023-
12-19.
Zamir, S. W., Arora, A., Khan, S., Hayat, M., Khan, F. S.,
and Yang, M.-H. (2022). Restormer: Efficient trans-
former for high-resolution image restoration. In Pro-
ceedings of the IEEE/CVF Conference on Computer
Vision and Pattern Recognition (CVPR), pages 5728–
5739.
Zamir, S. W., Arora, A., Khan, S., Hayat, M., Khan, F. S.,
Yang, M.-H., and Shao, L. (2021). Multi-stage pro-
gressive image restoration. CoRR, abs/2102.02808.
Zhang, K., Ren, W., Luo, W., Lai, W.-S., Stenger, B., Yang,
M.-H., and Li, H. (2022). Deep image deblurring: A
survey. arXiv preprint arXiv:2202.10881.
Zhang, R., Isola, P., Efros, A. A., Shechtman, E., and Wang,
O. (2018). The unreasonable effectiveness of deep
features as a perceptual metric. In Proceedings of
the IEEE conference on computer vision and pattern
recognition, pages 586–595.
Zhong, Z., Cao, M., Ji, X., Zheng, Y., and Sato, I. (2023).
Blur interpolation transformer for real-world motion
from blur. In Proceedings of the IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition
(CVPR), pages 5713–5723.
Rethinking Deblurring Strategies for 3D Reconstruction: Joint Optimization vs. Modular Approaches
823
