
What Kind of Information Is Needed? Multi-Agent Reinforcement
Learning that Selectively Shares Information from Other Agents
Riku Sakagami
1
and Keiki Takadama
2,3
a
1
Department of Informatics, The University of Electro-Communications, Tokyo, Japan
2
Information Technology Center, The University of Tokyo, Tokyo, Japan
3
Department of Information & Communication E ngineering, The University of Tokyo, Tokyo, Japan
Keywords:
Multi-Agent Reinforcement Learning, Centralized Training with Decentralized Execution, Sharing Additional
Information.
Abstract:
Since agents’ learning affects others’ learning in multi -agent reinforcement learning (MARL), this paper aims
to clarify what kind of information helps to improve learning of agents throgh complex interactions among
them. For this purpose, this paper focuses on the information on observations/actions of other agents and
analyzes its effect in MARL with the centralized training with decentralized execution (CTDE), which con-
tributes to stabilizing agents’ learning. Concretely, this paper extends the conventional MARL algorithm with
CTDE (i.e., MADDPG in this research) to have the two mechanisms, each of which shares (i) information on
observations of all agents; (ii) i nformation on acti ons of all agents; and (iii) information on both t he obser-
vations and actions of the selected agents. MARL with these t hree mechanisms is compared with MADDPG
which shares information on both actions and observations of all agents and IDDPG which does not share any
information. The experiments on multi-agent particle environments (MPEs) have revealed that the proposed
method that selectively shares both observation and action information is superior to the other methods in both
the full and partial observation environments where information on observations of all and selected agents.
1 INTRODUCTION
Recently, Multi-Agent Reinforcement Learning
(MARL) (Z hang et al., 2021; Gronauer and Diep old,
2022) has attracted much attention on by successfu lly
applying them to many complex real-world prob-
lems, such as automated driving and autonomous
robot swarm control (Shalev-Shwartz et al., 2016;
Hernand ez-Leal et al., 2019). MARL aims at
adaptively controlling the learning of agents to cope
with given environments. However, it is hard for
agents in MARL to learn their appropriate policies
simultaneou sly due to nonstationary situations caused
by complex intera ctions among agents (Busoniu et
al., 200 8; Hernandez-Leal et al., 2017). Such a
non-stationarity in MARL is caused by updating the
policy of all agents at the same time, i.e., the state of
an agent is not always to be transited to the unique
one even if the agent selects the same action. This is
because the actions of o ther agents may be different.
The simplest way to tackle this difficulty in si-
multaneous lear ning is to employ global observation
a
https://orcid.org/0009-0007-0916-5505
(which includes the state of a ll agents) and the actions
of other agents when agents learn their policies. From
this v iewpoint, the Centralized Training with Decen-
tralized Execution (CTDE) method was proposed in
MARL (Lowe et al., 2017; Yu et al., 2 022), which as-
sumes that agents can access extra information (i.e.,
global observation and the actions of other agents)
only during learning (as the centralized training) and
determine their actions according to their individual
informa tion (as decentralized execution). This ap-
proach con tributes to not only stabilizin g the learning
of a gents but also shortening the learning time. T he
previous works of CTDE revealed its superiority to
conventional methods (L owe et a l., 2017; Foerster et
al., 201 8; Rashid et al., 2020; Yu et al., 2022). Such
informa tion of other agents helps agents to learn their
appropriate policies consistently in MARL.
What should be noted he re, however, is that too
much information (i.e., “both” the observation and ac-
tions o f “all” agents) in CTDE is not always needed
for learning policies of agents, but r ather it may have
a bad influence on their learning. To tackle this issue,
this paper aims to clarify what kind of information
Sakagami, R. and Takadama, K.
What Kind of Information Is Needed? Multi-Agent Reinforcement Learning that Selectively Shares Information from Other Agents.
DOI: 10.5220/0013390100003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 1, pages 235-242
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
235

helps age nts learn in CTDE. Con cretely, this paper fo-
cuses on the information on observations and actions
of other agents, which is essential for cooper a tion in
CTDE, and analyzes its effect by employing (i) infor-
mation on “o bservations” of “all” agents; ( ii) informa-
tion on “actions” of “all” agents; or (iii) information
on both the observations and actions of the “selected”
agents. This information classification aims at clari-
fying what is an essential difference between “obser-
vations” and “actions” from the viewpoint of learn-
ing, and h ow the performance of agents changes by
employing information of the “selected ” agents from
that of “all” agents.
Among the many MARL methods based on
CTDE, this paper starts to employ MADDPG (Multi-
Agent Deep Deterministic Policy Gradient) (Lowe et
al., 2017) which shares information on both obser-
vations and actions a nd of all agents, and extend s
it by changing three kinds of the above informatio n
from (i) to (iii). M A DD PG is the Actor-Critic based
MARL with CTDE and is focused on in this paper
because of the following reasons: (1) MADDPG is
the simple method developed in the early stage of
CTDE, which helps us to directly clarify an effect of
the three kin ds of the above information without con-
sidering any other effect caused by th e complex or so-
phisticated CTDE propo sed after MAD D PG; (2) Un-
like QMIX (Rashid et al., 2020 ) and VDN (Value De-
composition Network) (Sunehag et al., 2018) which
are based on IG M principle that assumes that an ac-
tion of an agent with the highest value from the local
(agent) viewpoint is the same as that f rom the global
(multi-age nt) viewpoint, MADDPG can de rive a co-
operation where some agents give u p to select their
own b est actions to improve a global performance be-
cause MADDPG is not based on the IGM (Individual
Global-Max) principle; (3) Unlike MAPPO (Multi-
Agent Proximal Policy Optimization) (Yu et al., 2022)
which share s parameters of n e ural networks of all
agents which is usef ul fo r homogeneous a gents ac-
quiring the same policy among the agents, MADDPG
can be applied for heterogene ous agents acquiring the
different policies among the agents because MAD-
DPG has independent policies of agen ts.
To clarify what kind of information helps agents
to lear n in CTDE, this paper cond ucts the experi-
ments on multi-agent particle envir onments (MPEs)
and co mpares the results of the modified MAD-
DPGs which share one of three kinds of information,
the original MADDPG which shares all information,
and I DD PG (Indep endent Deep Deter ministic Policy
Gradient) which d oes not share any info rmation as
MARL with decentralized training w ith decentralized
execution (DTDE).
The paper is organ iz ed as follows: Section 2 in-
troduces the r elated works of MARL with CTDE, and
Section 3 describes MADDPG as the conventional
method. Section 4 p roposes the information-sharing
methods. Section 5 conducts the expe riment and an-
alyzes the experimental results. Finally, the conclu-
sions and future work of this stu dy are discussed in
Section 6.
2 RELATEDWORK
2.1 Centralized-Training with
Decentralized-Execution
The Centralized-Training with Decentralized-
Execution (CTDE) para digm is an essential co ncept
in recent MARL. In a CTDE setting, each agen t i
has an independent policy π
i
and m akes independent
action decisions acc ording to local observations only.
This behavior is the same as that at execution time
(decentra lized execution). On the other hand, during
training, agents have access to additiona l information,
such as global observations and inf ormation sharing
among agents (centralized tr aining). This additional
informa tion is d iscarded at runtim e and never used.
The strength of CTDE lies in its potential to improve
learning speed and accur acy by mitigating the partial
observability and non-stationarity of multi-agent
systems with additional information during training.
Its potential application to real-world problems is also
high since it behaves as a fully independen t agent at
runtime. Many problems are still challenging to solve
with Decentr alized-Training with Decentr alized-
Execution (DTDE), and CTDE shows excellent
results while reducing the strong assumptions of
Centralized-Training with Centralized-Executio n
(CTCE)(Gronauer and Diepold, 2022; Zhang et al.,
2021).
MADDPG(Lowe et al., 2017), COMA(Foerster
et al., 2018), QMIX(Rashid e t al., 2020), and
MAPPO(Yu et al. , 2022) are known as representative
MARL methods based on CTDE. M A D DPG extends
DDPG((Lillicrap et al., 2015)) to a multi-agent envi-
ronment and, following the CTDE, stabilizes learning
in a multi-agent environment by allowing the central-
ized cr itic to use additional information (in the paper,
pairs of observations and actions of all other agents).
In addition to being usable in cooperative, adversar-
ial, and mixed tasks, the metho d has the advantage
of being a very versatile algorithm, supportin g both
homogeneous an d heterogeneous agents. COMA ad-
dresses the problem of multi-agent credit assignment
by training a single centralized critic to calculate each
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
236

agent’s advantage function based on a counterfac-
tual baseline inspired by difference rewards(Wolpert
and Tumer, 2001) . QMIX is a method proposed as
an improvement of the value decomposition network
(VDN)(Sunehag et al., 2018). It learns a joint action-
value fu nction that can be decomposed into individ-
ual action-value functions by using a centr alized net-
work called a mixing network that bundles the Q-
function networks of each agent. This decomposi-
tion is based on a monotonicity constraint between
each Q-function and joint Q-func tions. MAPPO is a
method that extends PPO(Schulman et al., 201 7) to
a multi-agent environment following the CTDE. The
original MAPPO uses additional information through
a shared po licy network, but can also consider in di-
vidual policy networks, as can MADDPG, a method
based on the same actor-critic. In that case, the ma jor
difference between the two methods is which algo-
rithm is used, on-policy PPO or off-policy DDPG. I n
general, on-policy methods are known to be inferior
to off-policy methods in terms of samp le efficiency.
As discussed in the previous paragraph for algo-
rithms that use CTDE, several types of ad ditional in-
formation can be used during learning in the CTDE ,
especially three commonly used typ es: network pa-
rameter sharing, value factorization, and informatio n
sharing.
• Network Parameter Sharing. In parameter shar-
ing, a single network is used to optimize the poli-
cies of all agents, or each agent has its network for
policy improvement, and its p arameters are shared
(e.g., at regular learning inter vals); MAPPO (orig-
inal work) is classified as this me thod. This
method has the advantage of being insensitive to
the scalability of agen ts, but its network sharing
nature limits it to cooperative tasks performed by
homogeneous agents.
• Value Factorization. In value factoriz a tion, the
joint Q-function is learned to optimize individ-
ual Q-functions based on the IGM principle (Son
et al., 2019); VDN and QMIX are classified as
this method in which the joint Q-function is ad-
ditional information. This method allows for ac-
curate Q-function estimation but requires th e as-
sumption that the joint Q-function is factorizable.
Also, its application to competitive tasks is lim-
ited due to its natur e .
• Information Sharing. In info rmation sharing,
additional information such as the state, o bserva-
tion, a nd action of each agent and the global state
of the environment is used for information shar-
ing; MADDPG and MAPPO are classified as this
method. Since this method is a simple approa c h
to addin g environmental information, it can be
used regardless of the nature of the task (cooper-
ative/competitive) or the nature of the agents (h o-
mogene ous/heterogeneous) and can optimize the
agents’ policies independently. On the othe r hand,
loose constra ints tend to result in local solutions,
and the addition of envir onmental information is
easily influenced by the agent’s scalability.
In this study, we focus on information sharing,
which directly addresses non-stationarity an d partial
observability, and evaluate the impact of additional in-
formation on learning accuracy an d stability. To this
end, MADDPG is employed as the baseline algorithm
for comparison. T his choice is justified by its status
as the most concise actor-critic-based method capable
of leveraging informatio n sharing, as well as its high
versatility, being independe nt of the specific nature of
the problem or agents. In contrast, the other methods
discussed above have limitations, such as reliance on
the IGM principle or the assumption of homogeneous
agents.
3 BACKGROUND
3.1 Problem Settings
Stochastic games (sometimes called Markov
games)(Littman, 1994) is a natural extension of
Markov decision processes (MDP) to multi- agent
environment. In a more realistic setting, the
agent may not have access to information about
the complete environment, in which case it is
modeled b y Partially observable stocha stic games
(POSG)(Hansen et al., 2004). A POSG is defined by
a tuple hI , S , b
0
, {A
i
}
i∈I
, {O
i
}
i∈I
, P , {R
i
}
i∈I
i, where
I = {1, . . . , N} is a set of agents indexed, S is a set
of all states, b
0
is the initial state distribution, A
i
is
a set of actions available to agent i, O
i
is a set of
observations fo r agent i, P : S ×
−→
A × S ×
−→
O → [0, 1]
is a set of state transitions and observation prob-
abilities(, where
−→
A = A
1
× ··· × A
n
denotes a set
of joint actions,
−→
O = O
1
× ··· × O
n
denotes a set
of joint observations, P (s
′
,
−→
o | s,
−→
a ) denotes the
probability that taking joint action
−→
a ∈
−→
A in state
s ∈ S results in a tran sition to state s
′
∈ S and joint
observation
−→
o ∈
−→
O ), R
i
: S ×
−→
A × S → R is a reward
function for agent i, and each agent attempts to
maximize its expected sum of disco unted rewards,
E
Σ
T
t
γ
t
R
i
(s
t
,
−→
a
t
, s
t+1
)
, where γ is a discount factor
and T is the time horizon.
What Kind of Information Is Needed? Multi-Agent Reinforcement Learning that Selectively Shares Information from Other Agents
237

3.2 Multi-Agent Deep Deterministic
Policy Gradient (MADDPG)
In an N-agent POSG, if each agent employs a
policy µ = {µ
1
, . . . , µ
N
} parame terized by θ =
{θ
1
, . . . , θ
N
}, the gradient of the expected retur n for
agent i, J(µ
i
) = E[R
i
] in MADDPG is given by
∇
θ
i
J(µ
i
) =
E
−→
o ,
−→
a ∼D
∇
θ
i
µ
i
(a
i
| o
i
)∇
a
i
Q
µ
i
(
−→
o ,
−→
a ) |
a
i
=µ(o
i
)
.
(1)
Here Q
µ
i
(
−→
o ,
−→
a ) represents a centralized actio-value
function that takes a s input the observations and ac-
tions of all agents. The re play buffer D stores tuples
of the form (
−→
o ,
−→
a , r
1
, . . . , r
N
,
−→
o
′
), recording the ex-
periences o f all agen ts. The centralized actio n-value
function is update d by
L(θ
i
) = E
−→
o ,a,r,
−→
o
′
(Q
µ
i
(
−→
o ,
−→
a ) − y)
2
,
y = r
i
+ γQ
µ
′
i
(
−→
o
′
,
−→
a
′
) |
a
′
j
=µ
′
j
(o
j
)
. (2)
Here µ
′
= {µ
θ
′
1
, . . . , µ
θ
′
N
} is the set of target policies
with delayed parameters θ
′
i
.
4 METHODS
The most basic information shared during learning in
methods following the CTDE framework is the obser-
vations and actions of each agent. We consider that
there are stages in sharing this information, shown
in Table 1. Usually, independent information is used
when sharing is not assume d (e.g., IDDPG is shown
in Figure 1), and full informatio n is used when shar-
ing is assumed ( e .g., MADDPG is shown in Figure 2),
while
1. The case in which only observations are shared
(Ta ble 1 upper-right cell).
2. The case in which only actions are shared (Table 1
lower-left cell).
3. The case in which infor mation is selected and
shared (Table 1 middle- center cell).
Algorithms th a t rely on independent information face
challenges in addressing the non-stationa rity inherent
in multi-agent systems. Conversely, algorithms that
share and utilize all available information r isk having
critical information obscured by other excessive in-
formation. Building on the above, this paper outlines
the three types of sh aring methods that are the focus
of this stud y.
Table 1: Degree of sharing information.
act\obs non partial full
non IDDPG – target 1
partial – target 3 –
full target 2 – MADDPG
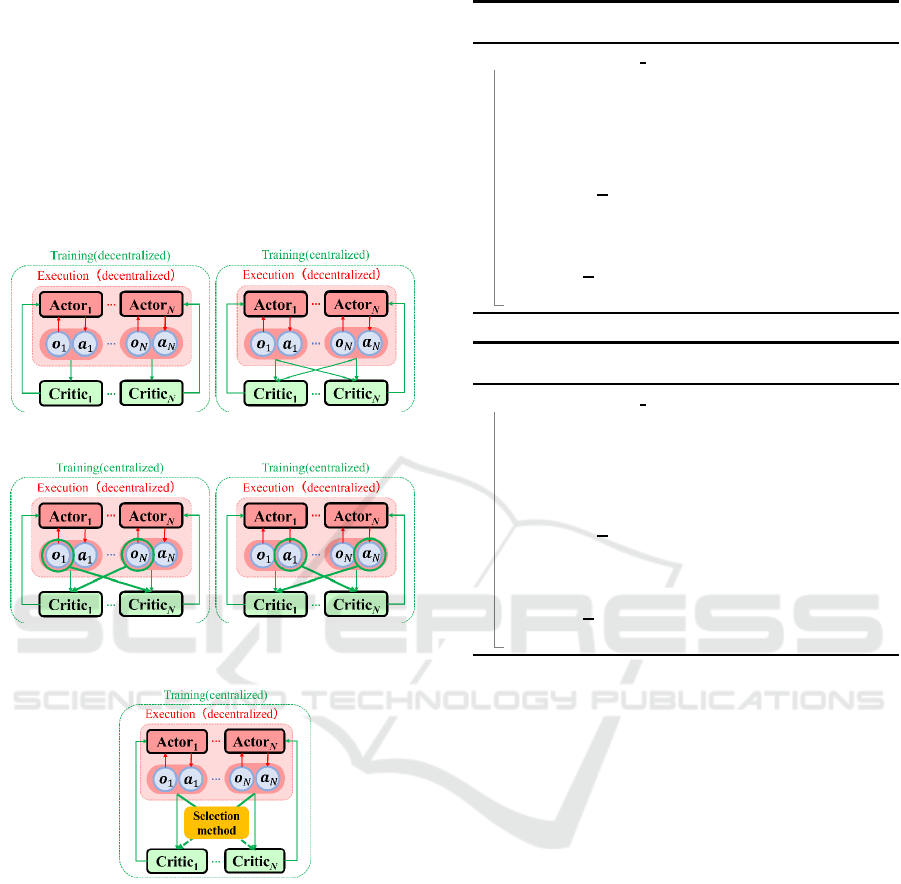
4.1 Sharing Full-Observations
In this sha red method, each agent estimates a Q-
function based on the joint observations of all other
agents and its own action, as illustrated in Figu re 3.
Specifically, the input to critic i is a vector compris-
ing the joint observations
−→
o and the agent’s own ac-
tion a
i
. Consequently, even in a partially observable
environment, the critic can a pproximate global envi-
ronmental information through the joint observations.
To be precise, the ability to derive an observation rep-
resentation that closely appro ximates the global ob-
servation from multiple local observations depends
on the neur al network training process and the spa-
tial distribution of agents. However, since the ac-
tions of other agents are not shared, the issue of non-
stationarity remains u nresolved. The Algorithm 1
represents the pseudocode for the update function of
this sh aring meth od with MADDPG.
4.2 Sharing Full-Actions
In this sharing method, e ach agent estimates a Q-
function based on its own observation and the joint
actions of all oth er agents, as illustrated in Figure 4.
Specifically, the input to critic i is a vector comprising
the agent’s own ob servation o
i
and the joint actions
−→
a . Consequently, the closer the local observations
are to the global observations, the more effectively
this critic c a n mitig ate n on-stationar ity. However, this
approa c h cann ot address the issue of partial observ-
ability. The Algo rithm 2 represents the pseudocode
for the update functio n of this sharing method with
MADDPG.
4.3 Sharing Selected Observations and
Actions
In this sharing method, e ach agent estimates a Q-
function based on its own observations and actions, as
well as those of selected agents, as illustrated in Fig-
ure 5. Specifica lly, the in put to critic i is a vector com-
prising the selected observations {o
i
, o
j
}
j∈I
i,select
and
the selected actions {a
i
, a
j
}
j∈I
i,select
, where I
i,select
⊆ I
denotes the set of indices corresponding to the se-
lected agents for each agen t i. The criteria for se-
lecting agents can be arbitrary (e.g., based on dis-
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
238
tance, role, attention, etc.). Consequen tly, this critic
cannot completely mitigate non-stationarity and par-
tial observability unless the numbe r of selected agents
matches the total number of other agents in the en-
vironm ent. Nevertheless, excluding agents that are
weakly related to the ta rget agent may alleviate scala-
bility issues while reducing redundancy in the sha red
informa tion. The Algorithm 3 represents the pseu-
docod e for the update function of this sharing method
with MADDPG.
Figure 1: IDDPG Figure 2: MADDPG.
Figure 3: MADDPG with
Sharing Full-Observations
Figure 4: MADDP G with
Sharing Full-Actions.
Figure 5: MADDPG with Sharing selected Observations &
Actions.
5 EXPERIMENTS
5.1 Multi-Agent Particle Environments
For the experimental environment, we use coopera-
tive navigation, one of the multi-agent pa rticle envi-
ronments (MPEs) provided in (Lowe et al., 201 7).
Cooperative Navigation. This environment is a co-
operative task in which multiple agents and an equal
number of goals are placed in a two-dimensional real-
valued space, and the target is for all agents to cover
Algorithm 1: Update actor and critic function for ”Sharing
Full-Observations”.
function UPDATE AGENT( i)
Sample a random minib atch of S samples
(
−→
o
j
,
−→
a
j
, r
j
,
−→
o
′ j
) from replay buffer D
Set y
j
= r
j
i
+ γQ
µ
′
i
(
−→
o
′ j
, a
′ j
i
) |
a
′
k
=µ
′
k
(o
′
k
)
Update critic by mini mizing the loss:
L(θ
i
) =
1
S
∑
j
y
j
− Q
µ
i
(
−→
o
j
, a
j
i
)
2
Update actor using the sampled policy gradient:
∇
θ
i
J ≈
1
S
∑
j
∇
θ
i
µ
i
(o
j
i
)∇
a
i
Q
µ
i
(
−→
o
j
, a
j
i
) |
a
i
=µ
i
(o
j
i
)
Algorithm 2: Update actor and critic function for ”Sharing
Full-Actions”.
function UPDATE AGENT( i)
Sample a random minib atch of S samples
(
−→
o
j
,
−→
a
j
, r
j
,
−→
o
′ j
) from replay buffer D
Set y
j
= r
j
i
+ γQ
µ
′
i
(o
′ j
i
,
−→
a
′ j
) |
a
′
k
=µ
′
k
(o
′
k
)
Update critic by mini mizing the loss:
L(θ
i
) =
1
S
∑
j
y
j
− Q
µ
i
(o
j
i
,
−→
a
j
)
2
Update actor using the sampled policy gradient:
∇
θ
i
J ≈
1
S
∑
j
∇
θ
i
µ
i
(o
j
i
)∇
a
i
Q
µ
i
(o
j
i
,
−→
a
j
) |
a
i
=µ
i
(o
j
i
)
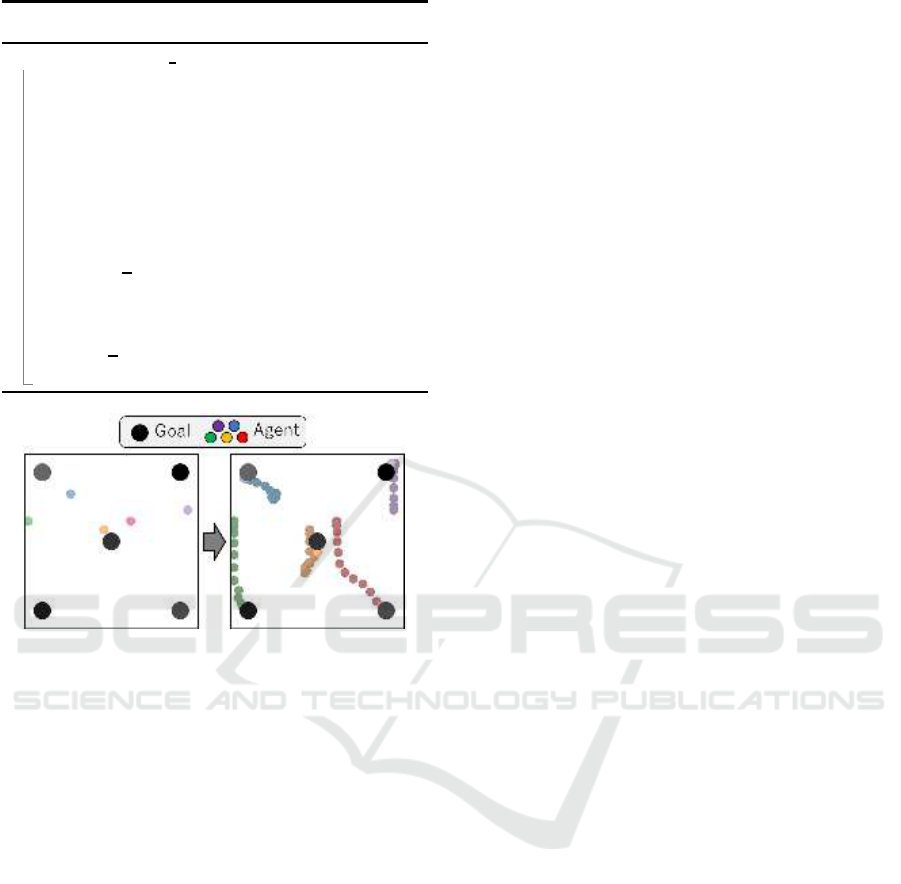
all goals. In this task, the goal of each agent is not
explicitly specified, so it must decide its action while
considerin g the goals of other agents. In our setting,
the initial state is as in Figure 6 (left), where each
agent is placed at random coordinates and the goal
position is set uniformly in the environment. When
the time step is t, and th e agent ID is i, each agent r e -
ceives an observation o
i
t
, which includes its absolute
position, the relative positions of each goa l, and th e
relative positions of other agents. Based on the pol-
icy µ
i
, the agent determines its action a
i
t
, specifying
movement in the x and y directions. The reward for
each agen t is given b y r
i
= −
∑
N
j=0
(min
k∈I
||g
j
pos
−
a
k
pos
||) − collision-penalty, where N represen ts the
number of agen ts and the numbe r of goals, g
pos
de-
notes the position vector of a goal, a
pos
denotes the
position vector of an ag ent, and collision-penalty
refers to the pen a lty reward assigned for agent col-
lisions.
5.2 Settings and Parameters
The actor and critic networks consisted of thre e and
four fully connected layers, respectively, with a unit
What Kind of Information Is Needed? Multi-Agent Reinforcement Learning that Selectively Shares Information from Other Agents
239
Algorithm 3: Update actor and critic function for ”Sharing
Selected Observations and Actions”.
function UPDATE AGENT(i)
Sample a random minibatch of S samples
(
−→
o
j
,
−→
a
j
, r
j
,
−→
o
′ j
, I
select
) from replay buffer D
−→
o
j
i
← {o
j
i
, o
j
k
}
k∈I
i,select
−→
a
j
i
← {a
j
i
, a
j
k
}
k∈I
i,select
−→
o
′ j
i
← {o
′ j
i
, o
′ j
k
}
k∈I
i,select
Set y
j
= r
j
i
+ γQ
µ
′
i
(
−→
o
′ j
i
,
−→
a
′ j
i
) |
a
′
k
=µ
′
k
(o
′
k
)
Update critic by mini mizing the loss:
L(θ
i
) =
1
S
∑
j
y
j
− Q
µ
i
(
−→
o
j
i
,
−→
a
j
i
)
2
Update actor using the sampled policy gradient:
∇
θ
i
J ≈
1
S
∑
j
∇
θ
i
µ
i
(o
j
i
)∇
a
i
Q
µ
i
(
−→
o
j
i
,
−→
a
j
i
) |
a
i
=µ
i
(o
j
i
)
Figure 6: Cooperative navigation (5 agents).
size 64 for the hidden layer and an Adam optimizer
with a learning rate of α = 0.01 for updating the net-
work and τ = 0.01 for updating the target n e twork.
The discount factor γ = 0.95. The replay buffer size
is 10
6
, and the network parameters are updated a fter
every 100 sample is added to the replay buffer. The
batch size before updating is 1024 episode s, with one
episode having a maximum of 25 steps, an d the en-
vironm ent is updated every episod e . Each agent has
an indepen dent network and does not sh are network
parameters. These p arameters are following MAD-
DPG(Lowe et al., 2017).
5.3 Comparison of Learning Accuracy
by Grade of Information Sharing
5.3.1 Experiment 1: Cooperative Navigation
with Fully Observable
The results of the comparison of IDDPG, MAD-
DPG, and the thre e proposed methods (Sharing Full-
Observations: -fo, Sharing Full-Actions: -fa, and
Sharing selected Observations& Actio ns: -soa) in
the cooperative navigation task shown in Figure 6
for learning 100, 000 episodes (about 2.5M steps) are
shown in Figure 7 (top). The horizo ntal axis sh ows
the learning progress [steps], the vertica l axis shows
the task completion rate [%] , the solid graph shows
the average of the 31 trials, and the ba nd shows
the standard deviation. Figure 7 (bottom) shows
the boxplots of the 31 trials, and Table 2 shows the
Mann-Whitn ey U test results for M A DD PG and each
method. In addition, Figure 7 (bottom) shows the
boxplots of average task completion rates fo r the eval-
uation experiments using the learned model for all 31
trials, and Table 2 shows the results of the Mann-
Whitney U-tests for M A DD PG and each method.
Evaluation experiments were cond ucted on the latest
20% of the learned models (a total of 20 models from
80, 000 to 100, 000 episo des).
Figure 7, Table 2 shows that M A DD PG-fa has
the h ighest achievement rate at 73.63 ± 9.51[%],
followed by MADDPG-soa (71.58 ± 17.42), MAD-
DPG (63.89 ± 12.28), IDDPG (44.58 ± 1 3.31) and
MADDPG-fo (36.89 ± 21.56). These results indi-
cate that sharing the ob servations of other agents
in an envir onment wher e complete observations are
available creates redundan cy and leads to undesirable
results (MADDPG-fa > MADDPG and IDDPG >
MADDPG-fo). The comparison of MAD DPG an d
MADDPG-soa may serve as a basis for estimating
the impact of reduced shared information. In this ex-
periment, the performance of MADDPG-soa, where
shared information is limited, was statistically signif-
icantly better than that of MADDPG. These results in-
dicate that unnecessary information sharing has detri-
mental effects on perform a nce and that perform a nce
gains can be achieved through appropriate selection.
Specifically, in a fully observable environment, shar-
ing observational in formation fr om other agents in-
troduces redundancy and potentially degrades perfor-
mance.
5.3.2 Experiment 2: Cooperative Navigation
with Partially Observable
A fully observable environment is unrealistic in prac-
tical scenarios. Since the lack of observation may al-
ter the prioritization of additional information, a simi-
lar experiment was conducted by exten ding the coop-
erative navigation task shown in Figure 1 to a partially
observable environmen t. In this experiment, partial
observability is repre sented b y restricting the observ-
able informatio n to the relative coordinates of two ad-
jacent agents. The results o f the comparison of ID-
DPG, MAD D PG, and the three proposed methods in
the same setting as in Experiment 1 are shown in Fig-
ure 8 (top). The horizontal a xis shows the learning
progress [steps], the vertical axis shows the task com-
pletion rate [%], the solid graph shows the average of
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
240

Table 2: Mean success rate (standard deviation) and Mann-Whitney U Test results.
MADDPG IDDPG MADDPG-fo MADDPG-fa MADDPG-soa
Exp. 1 63.89(12.28) **44.58(13.31) **36.89(21.56) **73.63(9.51) *71.58(17.42)
Exp. 2 70.11(21.58) **51.02(12.38) 67.7(20.78) **51.88(18.28) 74.99(17.51)
*: p < .05, **: p < .01 (Mann-Whitney U)
Figure 7: Results of 5 agents cooperative navigation with
the fully observable setting. Top: Learning progress and
success rate. Bottom: Distribution of task success rates in
evaluation experiments.
the 31 trials, and the band shows the standard devi-
ation. Figure 8 shows the boxplots of average task
completion rates for the evaluation experiments us-
ing the learned model for all 31 trials, and Table 2
shows the results of the Mann-Whitney U-tests for
MADDPG and each method. Evaluation experiments
were conducted on the latest 20% of the learned mod-
els (a total of 30 mo dels from 120, 000 to 150, 000
episodes).
Figure 8, Table 2 shows that MADDPG-soa had
the highest achievem e nt rate at 74.99 ± 17.51[%], fol-
lowed by MADDPG (70 .11 ± 21.58), MADDPG-fo
(67.7 ± 20.78), MADDPG-fa (51.88 ± 18.28) and ID-
DPG (5 1.02 ± 12.38). These results indicate that in
one of the partially obser vable enviro nments, obser-
vational information has a higher priority for sharing
than action information (MADDPG-fo ¿ M A D DPG-
fa). This finding contr asts with the results of Exp er-
iment 1 and highlights the importance of ad dressing
the issue of partial o bservability. Nonetheless, the su-
perior performa nce of MADDPG and MADDPG-soa
over MADDPG-fo clearly demonstrates that sharing
behavioral information remains effective even in par-
tially observable environments. As in Experiment 1,
the comparison between MADDPG and MADDPG-
soa in Experiment 2 further suggests that selective in-
formation sharing can enhance accuracy.
Figure 8: Results of 5 agents cooperative navigation w ith
the partially observable setting. Top: Learning progress and
success rate. Bottom: Distribution of task success rates in
evaluation experiments.
6 CONCLUSIONS
This paper extends MADDPG, a MARL algorithm
with CTDE, to propose three me thods, i.e., MAD-
DPG with sha ring (i) information on actions of all
agents, (ii) information on observations of all agents,
and (iii) information on both the actions and observa-
tions of the selected agents to investigate the extent
of informatio n sharing in CTDE compr e hensively.
To o ur knowledge, the degree of information shar-
ing varies by task setting and application destination.
Since no exhaustive survey ha s been conducted, we
believe this validation is essential. Expe rimental re-
sults show that selective additional information reduc-
tion can maintain learning accura cy, especially when
sharing actions of all agents, a nd is best performed
in a fully observable environmen t. We also showed
What Kind of Information Is Needed? Multi-Agent Reinforcement Learning that Selectively Shares Information from Other Agents
241

cases where redun dant additiona l information wors-
ens learning accuracy and identified priorities for ad-
ditional information in fu lly an d partially observable
environments.
In this paper, experiments were conduc ted with
additional informa tion limited to agent observations
and actions. Future research should consider ap-
plying this approach to other types of additional in-
formation. Furthermore, the inform ation selection
method in this study was defined at runtime and re-
mained fixed throughout the learning process. Given
the complexity of multi-agent reinf orcement learn-
ing (MARL), it is likely that the critical information
may vary depending on the learning stage. Therefore,
dynamic selection based on the progress of learning
would be a valuable direction for future work.
REFERENCES
Foerster, J., Farquhar, G., Afouras, T., Nardelli, N., and
Whiteson, S. (2018). Counterfactual multi-agent pol-
icy gradients. In Proceedings of the AAAI conference
on artificial intelligence, volume 32.
Gronauer, S. and D iepold, K. (2022). Multi-agent deep re-
inforcement learning: a survey. Artificial Intelligence
Review, 55(2):895–943.
Hansen, E. A., Bernstein, D. S., and Zilberstein, S.
(2004). Dynamic programming for partially observ-
able stochastic games. In AA AI, volume 4, pages 709–
715.
Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T.,
Tassa, Y., Silver, D., and Wierstra, D. (2015). Contin-
uous control w ith deep reinforcement learning. arXi v
preprint arXiv:1509.02971.
Littman, M. L. (1994). Markov games as a f ramework
for multi-agent reinforcement learning. In Machine
learning proceedings 1994, pages 157–163. Elsevier.
Lowe, R., Wu, Y. I., Tamar, A., Harb, J., Pieter Abbeel,
O., and Mordatch, I. (2017). Multi-agent actor-critic
for mixed cooperative-competitive environments. Ad-
vances in neural information processing systems, 30.
Rashid, T., Samvelyan, M., De Witt, C. S., Farquhar, G.,
Foerster, J., and Whiteson, S. (2020). Monotonic
value function factorisation for deep multi-agent re-
inforcement learning. Journal of Machine Learning
Research, 21(178):1–51.
Schulman, J., Wolski, F., Dhariwal, P., Radford, A. , and
Klimov, O. (2017). Proximal policy optimization al-
gorithms. arXiv preprint arXiv:1707.06347.
Son, K., Kim, D., Kang, W. J., Hostallero, D. E., and Yi, Y.
(2019). Qtran: Learning to factorize with transforma-
tion for cooperative multi-agent reinforcement learn-
ing. In International conference on machine learning,
pages 5887–5896. PMLR.
Sunehag, P., Lever, G., Gruslys, A., Czarnecki, W. M.,
Zambaldi, V., Jaderberg, M., Lanctot, M., Sonnerat,
N., L eibo, J. Z., Tuyls, K., and Graepel, T. (2018).
Value-decomposition networks for cooperative multi-
agent learning based on team reward. In Proceedings
of the 17th International Conference on Autonomous
Agents and MultiAgent Systems, AAMAS ’18, pages
2085–2087, Richland, SC. I nternational Foundation
for Autonomous Agents and Multiagent Systems.
Wolpert, D. H. and Tumer, K. (2001). Optimal payoff func-
tions for members of collectives. Advances in Com-
plex Systems, 4(02n03):265–279.
Yu, C., Velu, A ., Vinitsky, E., Gao, J., Wang, Y., Bayen, A.,
and Wu, Y. (2022). The surprising effectiveness of ppo
in cooperative multi-agent games. Advances i n Neural
Information Processing Systems, 35:24611–24624.
Zhang, K., Yang, Z., and Bas¸ ar, T. (2021). Multi-agent rein-
forcement learning: A selective overview of theories
and algorithms. Handbook of Reinforcement Learning
and Control, pages 321–384.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
242
