
Using Historical Information for Fuzzing JavaScript Engines
Bruno Gonc¸alves de Oliveira
1 a
, Andre Takeshi Endo
2 b
and Silvia Regina Vergilio
1 c
1
Department of Computer Science, Federal University of Paran
´
a, Curitiba, PR, Brazil
2
Computing Department, Federal University of S
˜
ao Carlos, S
˜
ao Carlos, SP, Brazil
Keywords:
Fuzzing, JavaScript Engine, Security, Vulnerabilities, Exploits.
Abstract:
JavaScript is a programming language commonly used to add interactivity and dynamic functionality to web-
sites. It is a high-level, dynamically-typed language, well-suited for building complex, client-side applications
and supporting server-side development. JavaScript engines are responsible for executing JavaScript code and
are a significant target for attackers who want to exploit vulnerabilities in web applications. A popular ap-
proach adopted to discover vulnerabilities in JavaScript is fuzzing, which involves generating and executing
large volumes of tests in an automated manner. Most fuzzing tools are guided by code coverage but they
usually treat the code parts equally, without prioritizing any code area. In this work, we propose a novel
fuzzing approach, namely JSTargetFuzzer, designed to assess JavaScript engines by targeting specific source
code files. It leverages historical information from past security-related commits to guide the input generation
in the fuzzing process, focusing on code areas more prone to security issues. Our results provide evidence
that JSTargetFuzzer hits these specific areas from 3.61% to 16.17% more than a state-of-the-art fuzzer, and
covers from 1.46% to 15.09% more branches. By the end, JSTargetFuzzer also uncovered one vulnerability
not found by the baseline approach within the same time frame.
1 INTRODUCTION
JavaScript is a predominant programming language
on the Web, commonly used to add interactivity and
dynamic functionality to websites. It is a high-
level, dynamically-typed language, well-suited for
building complex, client-side applications and sup-
porting server-side development. Most websites
use Javascript code to implement different tasks in
specific areas, including back-end servers with ap-
proaches like Node.js
1
, and front-end UIs like Re-
act.js
2
. One of the key advantages of JavaScript is
its widespread availability, as it is supported by all
modern web browsers, which can be used on various
devices. This makes it a popular choice for building
web applications accessible from any device with an
Internet connection.
JavaScript is always supported by JavaScript en-
gines in web browsers. The engines are embedded
and can interpret and execute JavaScript code during
a
https://orcid.org/0009-0008-4554-5166
b
https://orcid.org/0000-0002-8737-1749
c
https://orcid.org/0000-0003-3139-6266
1
https://nodejs.org
2
https://reactjs.org
Internet browsing. They generally share the same ar-
chitecture, which includes parser, interpreter, baseline
compiler, and Just-In-Time (JIT) compiler (or opti-
mizer) (Kienle, 2010). While these features enhance
performance, they also introduce unique or distinct
vulnerabilities that are not typically found in other
types of software (Park et al., 2020). The engines gen-
erally have particular security issues, from memory
allocations and protections to improper data valida-
tion (Kang, 2021; Lee et al., 2020; Groß et al., 2023).
The vulnerabilities stem directly from the dynamic
nature of JIT compilation and optimization processes,
which can create security gaps. A user could be de-
ceived into executing malicious JavaScript code em-
bedded within a web page’s payload designed to ex-
ploit vulnerabilities in a JavaScript engine, potentially
leading to remote command execution.
JavaScript engine is then an unquestionably sensi-
tive piece of software for security reasons. A vulner-
ability in a JavaScript engine can have far-reaching
consequences, including unauthorized data access,
code execution, and privacy breaches. Therefore, en-
suring the security of JavaScript engines is critical to
protecting users and systems from potential attacks.
Identifying and fixing vulnerabilities in JavaScript
Gonçalves de Oliveira, B., Endo, A. T. and Vergilio, S. R.
Using Historical Information for Fuzzing JavaScript Engines.
DOI: 10.5220/0013417700003929
In Proceedings of the 27th International Conference on Enterprise Information Systems (ICEIS 2025) - Volume 2, pages 59-70
ISBN: 978-989-758-749-8; ISSN: 2184-4992
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
59

engines as quickly as possible is fundamental, and
many researches have been conducted to help in this
task (He et al., 2021; Tian et al., 2021). Various tech-
niques and tools were proposed for testing and vali-
dation, code review and analysis
3
, and use of secu-
rity best practices
4
in the development process. One
of these most popular techniques is fuzzing, which
involves generating and executing large volumes of
tests in an automated manner to discover vulnerabil-
ities in the engine (Tian et al., 2021). Many fuzzing
tools have been released for JavaScript engines (Han
et al., 2019; Holler et al., 2012; Wang et al., 2019; Lee
et al., 2020); they usually have different methods to
solve the syntax and semantics problems during the
input generation. The mutational strategy generates
inputs based on an initial corpus of JavaScript code
and the generational is based on the JavaScript gram-
mar. Most fuzzing tools generally have static config-
uration and do not allow significant modifications in
the fuzzing process, which may limit their range of
found vulnerabilities.
Recent advances in the field emphasize the role of
code coverage in enhancing fuzzing strategies. Code
coverage metrics allow fuzzers to systematically ex-
plore the JavaScript engine, ensuring that various as-
pects of the codebase are tested thoroughly. This ap-
proach helps to reach unexplored parts of the pro-
gram and evaluate alternative methods for input gen-
eration during fuzzing campaigns (Eom et al., 2024).
Fuzzilli (Groß et al., 2023) is an example of coverage-
oriented tool, and is considered the state-of-the-art
fuzzing tool (Bernhard et al., 2022). It utilizes an
Intermediate Language (IL) to build test inputs with
valid syntax and semantics, which allows support for
various JavaScript engines. The tool implements a
mutational-based input generation with multiple oper-
ators defined separately. The algorithm implemented
by Fuzzilli ensures that new input programs remain
syntactically valid by evolving from previously suc-
cessful samples. This process helps maintain the in-
tegrity of JavaScript inputs while efficiently exploring
and covering new execution paths within the engine.
Despite its potential, the code coverage based
technique is often underutilized. Existing tools (Han
et al., 2019; Wang et al., 2019) usually rely on sim-
plistic metrics that merely check if new code paths
have been reached, without delving deeper into other
characteristics of the covered code. Another limita-
tion inherent to these tools is the time taken to execute
the algorithms. They often do not provide features to
be configured for the fuzzing process, taking a generic
3
https://www.sonarsource.com/
4
https://www.ncsc.gov.uk/collection/
developers-collection
approach for all types of vulnerabilities (Holler et al.,
2012; Lee et al., 2020; Han et al., 2019). Newer
fuzzing tools target a unique type of vulnerability but
do not provide resources for others (Sun et al., 2022;
Bernhard et al., 2022). As a consequence, their effec-
tiveness and ability to detect certain types of vulnera-
bilities are reduced.
In light of these limitations, this paper introduces
a history-based approach, namely JSTargetFuzzer,
which enables targeted fuzzing in JavaScript engines
by leveraging historical data to guide the fuzzing pro-
cess. Historical data refers to past information on
security-related commits, bug reports and fixes, and
previous patches within JavaScript engine reposito-
ries. This data offers a window into the evolution-
ary patterns of software systems, highlighting areas
that have been repeatedly modified or inadequately
patched and, thus, more likely to harbor vulnerabili-
ties. This is particularly relevant in complex software
systems, where residual vulnerabilities often persist
after incomplete fixes and where patches can some-
times introduce new defects by focusing on these his-
torically vulnerable code segments (Li and Paxson,
2017; Shin and Williams, 2008).
We implemented our approach on the top of
Fuzilli (Groß et al., 2023). Our tool incorporating
historical data from security-related JavaScript engine
commits to guide the generation of programs or inputs
during the fuzzing campaigns. Our results provide
evidence that JSTargetFuzzer is capable of targeting
a specific code area, leading to concentrating efforts
and discovering more branches in the target code area
than Fuzzilli. Within the time frame of the experi-
ments, JSTargetFuzzer was also capable of uncover-
ing one vulnerability missed by Fuzzilli.
This paper is organized as follows: Section 2 re-
views related work; Section 3 introduces JSTarget-
Fuzzer; Section 4 presents implementation details of
our tool; Section 5 describes the experimental settings
of the evaluation conducted; Section 6 analyses the
obtained results; Section 7 discusses limitations and
possible threats to the results validity; and Section 8
concludes the paper.
2 RELATED WORK
Fuzzing JavaScript engines has been an active re-
search topic, receiving attention from practitioners
and researchers. Jsfunfuzz (Mozilla, 2022) is prob-
ably the first public fuzz testing tool for JavaScript
engine, developed for the JavaScript engine Mozilla’s
SpiderMonkey and released in 2007. The tool, even
today, is a benchmark for fuzzing techniques since it
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
60

demonstrated a great capability in discovering new
vulnerabilities. LangFuzz (Holler et al., 2012) is a
generic mutational fuzzing tool that can discover vul-
nerabilities in different programming languages, in-
cluding JavaScript. Both tools struggle to generate se-
mantically correct JavaScript code (Han et al., 2019).
To overcome this challenge, other fuzzers have
been proposed in the literature. CodeAlchemist (Han
et al., 2019) tries to solve semantics problems while
generating test cases. It takes JavaScript source files
as seeds and converts them to Abstract Syntax Trees
(ASTs). After that, it separates them into code blocks,
comprehends their order, and generates new code
snippets. Then, CodeAlchemist remounts the source
files and utilizes them for fuzzing using their marked
order. Superion (Wang et al., 2019), an extension
of American Fuzzy Lop (AFL)
5
, brings the grammar-
aware capability to AFL, allowing the fuzzer to gen-
erate input data that conform to specific syntactic
rules or grammar defined for the target program. An-
other research direction is to use Neural Network Lan-
guage Models, like Montage (Lee et al., 2020), to sup-
port the fuzzing process. It converts seed files into
ASTs, identifies their sequence, and use this informa-
tion to train the models. More recently, CovRL (Eom
et al., 2024) integrates coverage feedback directly into
Large Language Models (LLMs), along with a rein-
forcement learning algorithm to guide the mutation
process.
Other fuzzers are designed to reveal a specific
kind of vulnerability. For instance, KOP-Fuzzer (Sun
et al., 2022) is a fuzzing tool designed to target
Type Confusion vulnerabilities. There is also in-
terest on vulnerabilities related to JIT optimizations
in JavaScript engines (Park et al., 2020; Bernhard
et al., 2022; Wang et al., 2023). DIE (Park et al.,
2020) targets JIT vulnerabilities by maintaining two
aspects of Proof-of-Concepts (PoCs) used as seeds:
the preservation of data types and the structural in-
tegrity of the code during mutation. This approach en-
sures that the generated test cases closely mimic real-
world scenarios where specific data types and struc-
tures can trigger vulnerabilities in JIT-compiled code.
JIT-Picker (Bernhard et al., 2022) relies on differential
fuzzing, testing the engine against itself, by running
the program twice, with and without the JIT com-
piler enabled. Finally, FuzzJIT (Wang et al., 2023)
implements a sophisticated template-based approach,
ensuring that every generated program triggers the JIT
optimization process.
Among the several initiatives for fuzzing
JavaScript engines, one has been particularly suc-
cessful. Fuzzilli (Groß et al., 2023) is a fuzzing
5
https://github.com/google/AFL
tool developed by Google Project Zero
6
that targets
JavaScript engines. The tool tries to solve the se-
mantics problems by implementing an Intermediate
Language (IL) for handling JavaScript source code.
The IL is used to convert JavaScript code into a
simplified form for manipulation. The tool also
implements a guided technique by instrumenting
the JavaScript engines to obtain code coverage.
The algorithm implemented by Fuzzilli ensures that
new input programs remain syntactically valid by
evolving from previously successful samples. This
process helps maintain the integrity of JavaScript
programs while efficiently exploring new execution
paths within the engine.
Fuzzers for different domains have previously
explored historical code analysis to enhance their
fuzzing strategies (Xiang et al., 2024; Zhu and
B
¨
ohme, 2021).
However, to the best of our knowledge, no exist-
ing fuzzing tool utilizes historical information con-
cerning security-related commits to guide the fuzzing
process in JavaScript engines. This presents an op-
portunity to identify vulnerabilities by analyzing the
repository history of the JavaScript engine, allowing
prioritization of code areas more likely to contain se-
curity flaws.
3 PROPOSED APPROACH
This section introduces JSTargetFuzzer, an approach
that utilizes historical data to focus fuzzing efforts
on specific source code files within JavaScript en-
gines. Historical information, including detailed
records of past changes to the codebase, such as se-
curity patches, commit logs, and bug reports, can pro-
vide invaluable insights, and point out files and func-
tions that have been repeatedly modified in response
to vulnerabilities, highlighting areas of the code that
are potentially more prone to security flaws.
The key insight is to maximize the chances
of identifying vulnerabilities by covering security-
sensitive areas, where future issues may arise, as
the intrinsic complexity of software often means that
parts of code that have previously exhibited vulnera-
bilities are likely to do so again. Incomplete fixes can
leave residual vulnerabilities, and patches themselves
can sometimes introduce new defects (Li and Pax-
son, 2017; Shin and Williams, 2008). Persistent secu-
rity threats from incomplete fixes have been a notable
concern for JavaScript. For instance, the incomplete
6
https://googleprojectzero.blogspot.com
Using Historical Information for Fuzzing JavaScript Engines
61

resolution of CVE-2018-0776
7
in the Microsoft’s en-
gine ChakraCore resulted in the emergence of vul-
nerabilities CVE-2018-0933
8
and CVE-2018-0934
9
.
Notably, these patches involved revisions to the same
file.
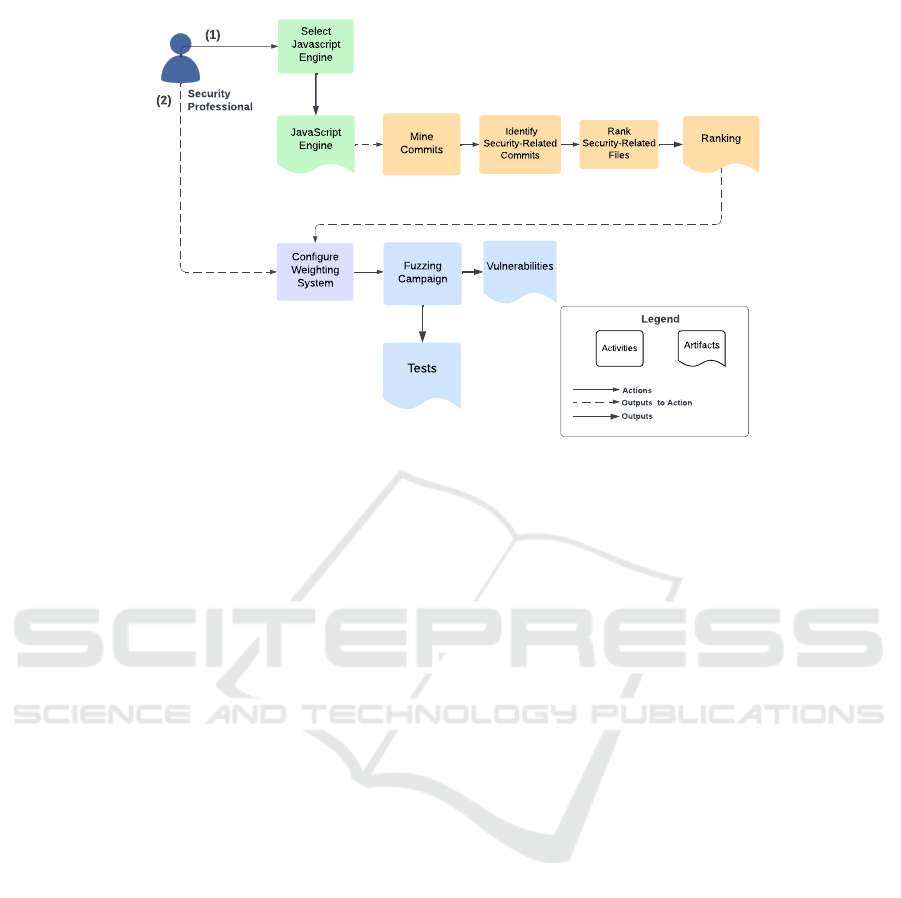
Figure 1 gives an overview of our fuzzing ap-
proach. Different colors in the diagram are used:
green to distinguish JavaScript engine elements, or-
ange for the historical contribution, purple to the
weighting system, and blue to the fuzzing process.
We can also see two main paths. The first one (1) is
related to historical information retrieval, and the sec-
ond (2)is related to the adoption of retrieved informa-
tion in the fuzzing process. To perform the first, the
security professional selects the target JavaScript en-
gine. Then the corresponding repository is mined, and
security-related commits are found. From these com-
mits, security-related files are identified and ranked.
In the second path, the security professional config-
ures the weighting system using the code coverage ca-
pability, which is informed by the ranking results. Ul-
timately, while focusing on specific files, the fuzzing
process may uncover new vulnerabilities and generate
additional test cases. The following sections describe
the elements of the approach in detail.
3.1 Historical Information Retrieval
The goal of this trial is to obtain security-related his-
torical information and rank the JavaScript files.
3.1.1 Mine Commits
Once the engine is provided, its corresponding com-
mit history of the JavaScript engine is collected from
its source code repository, such as GitHub
10
. The
availability of the source code is crucial, as well as
the access to the full commit history, for extracting
and classifying the relevant commits. This founda-
tional activity sets the stage for the subsequent phases
of our approach, where we analyze commit messages
and evaluate changes in the source code. Examin-
ing these commits provides valuable insights into the
engine’s evolution, particularly concerning security-
related modifications. This information is instrumen-
tal in shaping the weighting system that guides the
fuzzing process (see Section 3.2), allowing a focus on
7
https://msrc.microsoft.com/update-guide/en-US/
advisory/CVE-2018-0776
8
https://msrc.microsoft.com/update-guide/en-US/
advisory/CVE-2018-0933
9
https://msrc.microsoft.com/update-guide/en-US/
advisory/CVE-2018-0934
10
https://github.com
the most vulnerable and frequently altered areas of the
codebase.
3.1.2 Identify Security-Related Commits
At this point, we need to classify the commits as
security-related or not. This security-related classi-
fication implies that any vulnerability aspect is be-
ing handled within the commit. We can use different
techniques to achieve this goal, such as manual identi-
fication, searching for common security-related key-
words, and utilizing a Machine Learning (ML) clas-
sification model. In these cases, the classification is
done by recovering commits’ messages and titles and
inspecting the texts’ descriptions to recognize a secu-
rity aspect.
3.1.3 Rank Security-Related Files
The process involves enumerating and ranking the
files within the JavaScript engine frequently modified
in previously identified security-related commits. An-
alyzing the frequency of changes to these files helps
identify which parts of the codebase have been most
impacted by security fixes. This ranking provides in-
sight into the areas of the engine that are likely to con-
tain vulnerabilities.
3.2 Fuzzing Process
The fuzzing process is the core of our approach,
serving as mechanism for identifying vulnerabilities
within the JavaScript engine. Our approach integrates
historical information into the weighting system, en-
suring that the fuzzing campaigns are not just random
but strategically focused. Generating and executing a
diverse set of inputs (i.e., JavaScript programs), the
fuzzing process systematically probes the engine, tar-
geting areas that historical data has highlighted as par-
ticularly vulnerable. The weighting system then dy-
namically guides these fuzzing campaigns toward the
most critical sections of the codebase, optimizing the
chances of uncovering hidden flaws that might other-
wise go undetected.
3.2.1 Weighting System
A weighting system is a method for assigning impor-
tance or relevance to different elements, factors, or so-
lutions in a problem space. It is often used in contexts
like machine learning, decision-making, or optimiza-
tion to prioritize specific options or inputs over oth-
ers. In decision-making processes, weighting systems
help evaluate alternatives by emphasizing critical cri-
teria, ensuring that priorities are reflected accurately
in the outcome (Fagin and Wimmers, 2000).
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
62
Mine
Commits
Identify
Security-Related
Commits
Configure
Weighting
System
Select
Javascript
Engine
JavaScript
Engine
Ranking
Rank
Security-Related
Files
Vulnerabilities
Tests
(2)
Fuzzing
Campaign
Actions
Outputs
Outputs to Action
Activities
Artifacts
Legend
(1)
Security
Professional
Figure 1: Overview of JSTargetFuzzer.
We integrated a scoring system in JSTargetFuzzer
as described below.
• Each input is assessed based on its effectiveness
in targeting specific high-risk areas of the code, as
identified through historical analysis.
• Higher scores (Y ) are assigned to inputs that inter-
act with or impact ranked security-related files.
• Lower scores (X) are given to inputs that do not
target the identified areas.
• The user configures the weights for both X and Y ,
tailoring the scoring system to specific goals.
• Inputs are selected based on their scores, with
higher-scoring programs having a greater likeli-
hood of being chosen during the mutation process.
Integrating the weighting system into the ap-
proach ensures that the fuzzing process is continu-
ously driven toward exploring the target areas of the
code.
3.2.2 Fuzzing Campaign
The weighting system is triggered during the fuzzing
campaign in order to target specific address spaces
within JavaScript engines. Based on Fuzzilli’s orig-
inal algorithm (Groß et al., 2023), Algorithm 1 shows
how the JSTargetFuzzer fuzzing and weighting sys-
tem operate.
The algorithm receives as input X and Y , which
are weights, respectively for relevant programs and
programs that specifically hit security-related code.
Another input is targetCov, a data structure that stores
the security-related code areas (Section 3.1). Initially,
all programs are generated with weight X and added
to the population of relevant programs called Corpus
(line 3). Then, the fuzzing loop starts and continues
while the fuzzing is enabled (lines 4-24). In line 5,
a program P is selected from the corpus based on its
weight; so, programs with higher weights are more
likely to be selected. The selected program will pass
for N mutation iterations (lines 6-23). The selected
program is mutated (line 7) and executed in engine
under test (line 8). If the mutated program Pm causes
a crash, its results are saved to disk, and added to
the corpus with weight X (lines 9-11). Otherwise
(line 15), it checks if the program is considered in-
teresting; function isInteresting(), as in Fuzzilli,
is implemented as follows. It returns true if one of
the following conditions is met: (i) coverage of newly
discovered branches in the JavaScript engine’s code;
(ii) the program encounters assertion failures, which
are indicated by an exit code different from 0 (nor-
mal) without crashing. Instead, it produces an out-
put on STDERR, signaling an issue during execution;
and (iii) the program times-out during the execution.
If at least one of these conditions is satisfied, the pro-
gram is added to the corpus with weight X . When
the program hits new branches, it further checks for
security-related coverage in targetCov (line 17). If
security-related code is hit, the program is added to
the corpus with a higher weight Y (line 18).
Using Historical Information for Fuzzing JavaScript Engines
63

Algorithm 1: JSTargetFuzzer Fuzzing Process.
1: Input: weights X and Y , targetCov
2: Corpus ← []
3: Corpus.add(genSeedProgram(), weight(X))
4: while enabledFuzzing() do
5: P ← selectElementByWeight(Corpus)
6: for N iterations do
7: Pm ← mutate(P)
8: exec ← execute(Pm)
9: if exec.returnStatus == crash then
10: saveToDisk(Pm, exec)
11: Corpus.add(Pm, weight(X)) {Lower weight X for
crashing}
12: else
13: if exec.returnStatus == normal then
14: P ← Pm
15: if isInteresting(exec) then
16: Corpus.add(P, weight(X)) {Lower weight
X for assertions/timeouts/new branches}
17: if NCov in targetCov then
18: Corpus.add(P, weight(Y)) {Higher
weight for hitting target}
19: end if
20: end if
21: end if
22: end if
23: end for
24: end while
4 IMPLEMENTATION
In this section, we outline key implementation details
of our approach. This implementation was then used
to conduct the experiments.
For the Historical Information part, we adopted
scripts to download from GitHub and configure the
selected JavaScript engines. To rank the most rele-
vant security-related files for each engine, we reused
the experimental package provided by Oliveira et al.
(2023). The package provides ML classifiers to iden-
tify security-related commits, which we used to com-
pute the most-frequently changed files. We reused
the data for ChakraCore and JavaScriptCore engines.
Then, we re-executed existing scripts to collect data
for engines Duktape and JerryScript.
Concerning Fuzzing Process, we developed JS-
TargetFuzzer on top of state-of-the-art Fuzzilli (Groß
et al., 2023). Fuzzilli is an open-source and exten-
sible tool, enabling us to adapt its structure for our
fuzzing process. It is primarily written in Swift and
C. To define the address space of the security-related
files (targetCov in Algorithm 1), we utilized the GNU
Debugger (GDB) to run the selected JavaScript en-
gine with symbols enabled, allowing us to identify
the memory address ranges associated with the files
of interest.
To obtain coverage information about the exe-
cution of a given program (lines 14-21 in Algo-
rithm 1), we utilized Clang’s
11
built-in instrumenta-
tion, along with its sanitizer coverage functions. So,
the JavaScript engine is compiled with these con-
figurations, providing coverage information for the
fuzzing process.
5 EXPERIMENTAL SETUP
In this section, we present the experimental setup
adopted to evaluate JSTargetFuzzer. We utilized
Fuzzilli as a baseline, as it is a recognized state-
of-the-art fuzzing tool integrated into well-known
JavaScript engines (Groß et al., 2023). We set out our
evaluation to answer the following Research Ques-
tions (RQs):
• RQ1: To what extent is JSTargetFuzzer capable
of guiding the fuzzing process to explore security-
related files? This RQ evaluates JSTargetFuzzer’s
effectiveness in directing its fuzzing efforts toward
security-critical areas. This question also examines
whether our approach is being properly executed and
if there is a significant difference in the concentration
of fuzzing efforts and branch discovery between cam-
paigns using JSTargetFuzzer and those using Fuzzilli.
• RQ2: What are the characteristics of the pro-
grams generated with JSTargetFuzzer? This RQ
examines the input generation process, focusing on
the structure of the generated programs in terms of
operations, parameters, and overall complexity. Our
goal is to compare programs produced by JSTarget-
Fuzzer with the ones generated by Fuzzilli, assessing
how the weighting influences the characteristics of the
programs.
• RQ3: To what extent is JSTargetFuzzer capable
of detecting vulnerabilities? This RQ aims to ana-
lyze whether JSTargetFuzzer can detect vulnerabili-
ties in the engines. If so, we want to verify if Fuzzilli
can detect them too.
As subjects, we selected four JavaScript engines
based on various criteria: popularity, complexity, se-
curity features, and code availability. They are de-
scribed next:
• ChakraCore
12
is the core part of the Chakra
JavaScript engine that powers Microsoft Edge and
Internet Explorer browsers. It is still a very pop-
ular engine with a high market share, making it a
valuable target.
11
https://clang.llvm.org
12
https://github.com/chakra-core/ChakraCore
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
64

• JavaScriptCore
13
is the JavaScript engine that
forms the backbone of the WebKit framework,
which is integral to Apple’s Safari browser and a
variety of other applications on macOS and iOS.
• Duktape
14
is an embeddable JavaScript engine
designed for simplicity and low memory usage.
Despite its smaller footprint, it remains popular
in embedded systems and Internet of Things (IoT)
devices, presenting unique security challenges.
• JerryScript
15
is a lightweight JavaScript engine
for IoT devices. It is designed to run on devices
with constrained resources, making it a critical
component in IoT security research.
For each engine we use the builds shown in Ta-
ble 1. This table also presents the corresponding num-
bers of Lines of Code (LoC) and source code files.
Notice that ChakraCore is the biggest engine with re-
spect to LoC, having more than 2.9 MLoC of C/C++
code. Next is JavaScriptCore, Duktape, and finally
JerryScript. We configured each engine with Address-
Sanitizer (ASAN) to identify issues stemming from
improper memory access and utilized debug mode to
uncover vulnerabilities related to undefined behavior.
For this study, we opted to identify the Top-1 most
frequently modified security-related file from each
engine, following the procedure described in Sec-
tion 4. Table 2 shows the security-related file selected
for each engine, along with its LoC. Hence, JSTar-
getFuzzer would give a greater weight to programs
generated during the fuzzing campaigns that hit the
address space of these files. In experiments, we set
up JSTargetFuzzer using weight X = 1 and weight
Y = 1000. Since only a small percentage of programs
can hit new branches in the target address space, we
applied a significantly higher value for weight Y to en-
sure these programs are prioritized during the fuzzing
campaigns. The aforementioned decisions are sup-
ported by preliminary tests conducted to find balance
in the fuzzing process.
We established fuzzing campaigns of 120 min-
utes, for both JSTargetFuzzer and Fuzzilli, running
for the selected engines. Acknowledging the inherent
randomness in fuzzing, we executed each campaign
three times and averaged results were computed and
presented. We employed an Intel(R) i9 14900F CPU
(24-cores) computer with 64-bit Kali 2024.1 OS.
In RQ1, we assess the approach’s effectiveness by
measuring (1) the frequency with which it visits the
targeted areas, and (2) its ability to reach unique ad-
dresses within the target address space. To capture
13
https://github.com/WebKit/WebKit
14
https://github.com/svaarala/duktape
15
https://github.com/jerryscript-project/jerryscript
these two main capacities, we adopt the following
metrics:
• HitCount. The total number of accesses to the
address space of the selected security-related file
during fuzzing campaigns. It indicates how fre-
quent branches in the targeted address space are
hit.
• UniqueHitCount. The number of unique ac-
cesses to the address space of the selected
security-related file during fuzzing campaigns. It
reflects the discovery of new branches within the
targeted address space.
As we intend to analyze how these metrics evolve
over time, we collected these metrics after each itera-
tion of the fuzzing campaign, associating timestamps.
Concerning RQ2, we analyzed the characteristics
of the generated programs. To do so, we modified the
fuzzers’ implementation so that all programs included
in the corpus are persisted. We adopted the following
metrics: number of parameters, number of operations,
number of loops, and Cyclomatic Complexity (CC).
The number of parameters reflects the count of dis-
tinct parameters used within the functions, shedding
light on the program’s data manipulation and poten-
tial for variable interactions. The number of opera-
tions includes all statements and expressions within
the programs, providing an overall measure of pro-
gram size. Loop operations specifically refer to the
frequency of loop constructs, such as for and while
loops. The Cyclomatic Complexity refers to the num-
ber of linearly independent paths through the pro-
gram’s source code. We implemented a Python script
with the Lizard library
16
that computes these metrics
from the programs and utilized cloc
17
utility to deter-
mine the LoC values.
To address RQ3, we look at potential vulnerabili-
ties in the form of engine crashes or corruption mem-
ory issues pointed out by ASAN, observed during the
fuzzing campaigns. We also tracked the time taken
until those events occurred. For the potential vulner-
ability, we conducted an in-depth investigation. Ini-
tially, we reproduced the issue to confirm the report
by the fuzzer. Then, we searched the engine reposi-
tory for reports about the potential vulnerability, and
tested it in the most recent version of the engine.
The raw data, scripts, fuzzers’ imple-
mentations, and other related artifacts re-
quired to replicate this study are avail-
able at https://github.com/brunogoliveira-
ufpr/JSTargetFuzzer. The experimental package
was anonymized due to the double-blind process.
16
https://github.com/terryyin/lizard
17
https://github.com/AlDanial/cloc
Using Historical Information for Fuzzing JavaScript Engines
65

Table 1: JavaScript engines.
Engine Build #LoC #Files
ChakraCore c3ead3f8a6e0bb8e32e043adc091c68cba5935e9 2,951,664 820
JavaScriptCore c6a5bcca33e3147a0aaa5ea1f3aa2384aae383da 698,537 1,190
Duktape 50af773b1b32067170786c2b7c661705ec7425d4 170,256 479
JerryScript 8ba0d1b6ee5a065a42f3b306771ad8e3c0d819bc 102,632 342
Table 2: Top-1 security-related files.
Engine Top-1 File #LoC
ChakraCore GlobOpt.cpp 18,028
JavaScriptCore JSGlobalObject.cpp 3,092
Duktape duk api stack.c 6,897
JerryScript ecma-function-object.c 2,093
6 ANALYSIS OF RESULTS
In this section we analyse the results in order to an-
swer our RQs.
6.1 RQ1: Exploring Security-Related
Files
Figure 2 shows how HitCount (y-axis) evolves over
the elapsed time (x-axis) in minutes. HitCount grows
over time for both approaches, though it increases
faster in JSTargetFuzzer. For JavaScriptCore (b), the
better performance of JSTargetFuzzer is more notice-
able after approximately 30 minutes of fuzzing. By
the end, JSTargetFuzzer achieved average HitCounts
that were 16.17% higher for JavaScriptCore and
6.83% higher for JerryScript compared to Fuzzilli.
For the ChakraCore (a) and Duktape (c) engines,
Fuzzilli and JSTargetFuzzer appear to have closer re-
sults over time. Nevertheless, JSTargetFuzzer had
better HitCount by the end: 3.61% higher for Duk-
tape. In ChakraCore, JSTargetFuzzer achieved results
comparable to Fuzzilli, though its performance was,
on average, 1.70% lower.
Figure 3 shows how UniqueHitCount (y-axis)
evolves over the elapsed time (x-axis) in minutes. For
both approaches, UniqueHitCount grows fast for the
first 5 minutes, and then grows slowly afterwards.
This is expected once there is a large number of un-
covered branches at the beginning, and this num-
ber is reduced in subsequent iterations of the fuzzing
campaigns. Observe that JSTargetFuzzer had a per-
formance better than Fuzzilli after the first minutes.
By the end, JSTargetFuzzer was slightly better than
Fuzzilli by uncovering more unique branches within
the target address space during the fuzzing cam-
paigns, for all JavaScript engines. The greatest dif-
ference is in ChakraCore, where JSTargetFuzzer had
(a) ChakraCore.
(b) JavaScriptCore.
(c) Duktape.
(d) JerryScript.
Figure 2: HitCount (y-axis) over time (x-axis).
a UniqueHitCount 15.09% higher than Fuzzilli; this
accounts for approximately 306 more branches. Next
JavaScriptCore (18 branches – 4.84%), JerryScript (3
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
66

more branches – 1.89%), and Duktape (11 branches –
1.46%).
(a) ChakraCore.
(b) JavaScriptCore.
(c) Duktape.
(d) JerryScript.
Figure 3: UniqueHitCount (y-axis) over time in (x-axis).
The particularities of each engine, like modu-
larization, project size, runtime, and optimizations,
caused great variations in the metrics. For instance,
fuzzing campaigns for JavaScriptCore had up to 80M
HitCount, while ChakraCore had campaigns with up
to 8M. The number of branches in the security-related
file is also a factor. For example, JerryScript had up
to 159 explored branches (UniqueHitCount) of 1,256
in total, while JavaScriptCore was limited to around
386 branches of 12,467 in total.
Response to RQ1: JSTargetFuzzer is capa-
ble of guiding the fuzzing process to explore
more security related areas when compared to
Fuzilli. During the fuzzing campaigns, JSTar-
getFuzzer hit more branches in security-related
files’ address space. For HitCount, the im-
provements varied from 3.61% (Duktape) to
16.17% (JavaScriptCore). While in Chakra-
Core, Fuzzilli hits in average more than JS-
TargetFuzzer 1.70%. JSTargetFuzzer also ex-
plores more unique branches over time, with im-
provements from 1.46% (Duktape) to 15.09%
(ChakraCore).
6.2 RQ2: Characteristics of Generated
Programs
We herein analyzed the corpus of programs generated
by JSTargetFuzzer compared with the one generated
by Fuzzilli. In addition to this, we also analyze part
of this corpus composed of the programs that received
the higher weight Y .
JSTargetFuzzer generated an average of 1,371
programs for ChakraCore (X : 1,258, Y : 113), 2,742
for Duktape (X: 2,711, Y : 31), 11,722 for JavaScript-
Core (X : 11,685, Y : 37), and 138,713 for JerryScript
(X: 272,383, Y : 55). Y -programs constitute a small
fraction of the corpus, ranging from 0.02% (Jer-
ryScript) to 9.04% (ChakraCore). Despite their lim-
ited numbers, Y -programs are more likely to be se-
lected and mutated, significantly influencing the char-
acteristics of programs generated in subsequent itera-
tions.
Table 3 shows the metrics values for the corpus of
programs generated by JSTargetFuzzer and Fuzzilli,
per engine. For JSTargetFuzzer, we also present the
values for programs with weight Y (third column) and
the totality of the programs (corpus) (fourth column).
One aspect of Fuzzilli (also reflected on JSTarget-
Fuzzer) is that the fuzzing process starts with simple
programs that grow with complexity as they are mu-
tated.
In general, the metrics values for the programs of
the JSTargetFuzzer’s corpus are smaller than the val-
ues of the Fuzzilli’s corpus. This means that the pro-
grams generated by JSTargetFuzzer are simpler and
this may imply fast execution during the fuzzing cam-
paign, allowing more iterations in less time. This
should be better investigate in future work.
Using Historical Information for Fuzzing JavaScript Engines
67

We also observe that the values are smaller for
the corpus of Y -programs. Y -programs have smaller
mean numbers of parameters (≈22%), operations
(≈23%), loops (≈20%), and cyclomatic complexity
(≈21%). This may have occurred because most Y -
programs are added to the corpus earlier in the fuzzing
campaigns, as branches in the target code area be-
come harder to cover. Only programs that can hit new
addresses in the target space will be given a higher
weight.
A different behavior was noticed in the mean CC
values of JavaScriptScore. The values of Fuzilli are
lower than the ones of JSTargetFuzzer. In JavaScript-
Core, JSTargetFuzzer generates fewer loops; how-
ever, these loops often feature deeper nesting or in-
clude additional branching logic within their bodies,
significantly increasing CC. This behavior is likely
driven by the weighting system, which prioritizes pro-
grams that target specific, security-related branches in
the code. In this instance, JSTargetFuzzer generates
programs with more complex control flow structures
to effectively trigger the target address space, result-
ing in more independent execution paths and, conse-
quently, increased cyclomatic complexity.
Table 3: Metric values for RQ2, per engine.
Metric Engine JSTargetFuzzer Fuzzilli
Weight Y Corpus
# parameters
ChakraCore 1.76 2.47 2.98
JavaScriptCore 3.68 4.13 3.11
JerryScript 3.61 4.35 5.76
Duktape 4.04 4.60 7.10
# operations
ChakraCore 40.96 58.33 71.98
JavaScriptCore 95.35 107.41 76.59
JerryScript 78.56 98.83 141.81
Duktape 85.40 94.96 180.05
# loops
ChakraCore 0.49 0.45 0.52
JavaScriptCore 0.42 0.57 0.54
JerryScript 0.32 0.48 0.63
Duktape 0.52 0.61 0.98
CC
ChakraCore 1.90 2.59 3.42
JavaScriptCore 4.50 4.78 3.45
JerryScript 3.55 4.36 5.88
Duktape 4.18 4.81 8.80
Response to RQ2: JSTargetFuzzer generates pro-
grams with characteristics distinct from Fuzzilli,
with Y -programs generally exhibiting lower met-
ric values overall.
6.3 RQ3: Uncovered Vulnerabilities
No vulnerability was detected in ChakraCore,
JavaScriptCore, and Duktape; this result was ex-
pected once these engines were widely used and
tested in practice. On the other hand, JSTargetFuzzer
revealed a vulnerability in JerryScript. In comparison,
Fuzzilli could not uncover any vulnerability within
the same time frame.
The vulnerability found in JerryScript is a stack-
overflow, caused by infinite recursion within the en-
gine. This occurs when a function repeatedly calls it-
self (directly or indirectly) without a proper exit con-
dition, eventually consuming all available stack mem-
ory. In this case, the recursion seems to involve two
functions, which repeatedly call each other until the
stack is exhausted. This issue is no longer present in
the latest version we tested
18
. We observed that JS-
TargetFuzzer uncovered the vulnerability in all three
repetitions of the fuzzing campaigns and took an av-
erage of 23 minutes to detect it.
Response to RQ3: JSTargetFuzzer detected a
vulnerability in JerryScript. For the same time
frame, Fuzzilli did not uncover any vulnerability.
7 DISCUSSION
In this section, we discuss some limitations observed
during our study, as well as, possible threats to the
validity of our results.
7.1 Threats to Validity
Although we attempted to mitigate them to the best
of our ability, this work contains some threats to its
validity, as follows.
Internal Validity: The fuzzers employed in the ex-
periments took a lot of random choices, so its impact
introduces a threat. To mitigate this, all results were
based on mean values of three executions. However,
more executions would be better to deal with random-
ness. A period of two hours was used for the fuzzing
campaigns. We decided to adopt this short period be-
cause time reduction is a motivation for proposing our
approach. However, this may lead to incomplete cov-
erage in engines that require more time for effective
exploration. Consequently, the results might not ac-
curately reflect the comparative effectiveness of the
18
https://github.com/jerryscript-project/jerryscript/
commit/2dbb6f7
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
68

tools over extended testing periods. Another threat is
related to possible implementation errors in our code
to identify the security-related files, and collect the
metrics. Moreover, the values for the weights X and
Y were obtained empirically. Other configurations
should be better explored in future work.
Conclusion Validity: Our findings depend on the
used indicators and metrics adopted in the analysis
of the results. The use of other indicators may lead to
different results. To minimize this threat, we make the
experimental package available for future replication.
External Validity: We analyze only four engines.
Therefore, it is not possible to generalize our results.
Our engines should be considered in a future experi-
ment.
7.2 Limitations
In our study we observed some points that need to be
deeply studied in future research, or to be considered
for practical use of JSTargetFuzzer. The effectiveness
of the weighting system used to prioritize programs
during the fuzzing process is heavily influenced by
the number of programs generated during the fuzzing
campaign. Specifically, for smaller JavaScript en-
gines like Duktape and JerryScript, which tend to gen-
erate more programs within a given time frame due to
their compact size, the predetermined weight values
might require significant adjustment to maintain effi-
cacy.
If the weights are set too low, the fuzzer might not
sufficiently prioritize the programs targeting critical
areas, potentially missing vulnerabilities. Conversely,
if the weights are set too high, the fuzzer could over-
prioritize certain programs, leading to an inefficient
allocation of resources and possibly overlooking other
critical parts of the engine.
Focusing specific parts of the code may lead
to overlook vulnerabilities in other parts of the
JavaScript engine. JSTargetFuzzer may miss out on
discovering security issues outside these targeted re-
gions while concentrating on specific areas identified
through historical data. This narrowed focus could
lead to an incomplete assessment of the engine’s over-
all security posture. However, it’s important to note
that JSTargetFuzzer still incorporates a comprehen-
sive fuzzing approach by allowing other programs
to interact with the engine. This broader interaction
helps ensure that while the primary focus is on critical
areas, the rest of the engine is not neglected, maintain-
ing a balance between targeted and general fuzzing
efforts.
Smaller engines like JerryScript and Duktape,
which have less overhead, may allow for faster ex-
ecution of fuzzing campaigns, potentially leading to
quicker detection of vulnerabilities or more efficient
coverage metrics. This variability across different en-
gines could skew the results, making JSTargetFuzzer
appear more effective or efficient than it might be in
other contexts, particularly in larger or more complex
engines.
8 CONCLUDING REMARKS
This paper introduces JSTargetFuzzer, an approach
that incorporates a novel weighting system designed
to target specific areas of interest during fuzzing cam-
paigns using historical information. These areas are
identified by mining security information from the
commit history. Our evaluation revealed that JSTar-
getFuzzer directs fuzzing campaigns toward specified
security-related code areas. This capability enables
the fuzzer to concentrate on particular areas of the
JavaScript engine, increasing the likelihood of un-
covering vulnerabilities in those regions. JSTarget-
Fuzzer found one vulnerability in JerryScript, which
was missed by the baseline fuzzer. This is particularly
significant given that two hours is a very limited time
to detect vulnerabilities, highlighting a promising ef-
ficiency.
As a limitation, JSTargetFuzzer may miss out on
discovering security issues outside these targeted re-
gions. To reduce this limitation, we intend to inves-
tigate strategies based on historical information, en-
compassing every stage of fuzzer development, in-
cluding seed generation, mutation operators, and in-
tegration of our weighting system, along with consid-
ering different oracles. The seeds, mutation opera-
tors, and oracles should be tailored to specific types
of vulnerabilities. The idea is to carefully consider
the characteristics of these vulnerabilities when creat-
ing initial seeds and designing mutation operators that
align with the vulnerability patterns. In some cases,
we will define oracles capable of detecting anomalous
behaviors to identify security issues more effectively.
In future, one potential direction is to explore dif-
ferent historical information so that other aspects of
the JavaScript engines are considered like robustness,
performance, and so on. Furthermore, the idea of us-
ing historical information to leverage fuzzing could
be applied to other kinds of software systems.
ACKNOWLEDGMENTS
Andre T. Endo is partially supported by grant
#2023/00577-8, S
˜
ao Paulo Research Foundation
Using Historical Information for Fuzzing JavaScript Engines
69

(FAPESP); Silvia Regina Vergilio is supported by
grant #310034/2022-1, CNPq. This work was also
supported by Coordination for the Improvement of
Higher Education Personnel (CAPES) - Program of
Academic Excellence (PROEX).
REFERENCES
Bernhard, L., Scharnowski, T., Schl
¨
ogel, M., Blazytko, T.,
and Holz, T. (2022). JIT-Picking: Differential fuzzing
of JavaScript engines. In ACM Conference on Com-
puter and Communications Security CCS, pages 351–
364. ACM.
Eom, J., Jeong, S., and Kwon, T. (2024). Fuzzing
JavaScript interpreters with coverage-guided rein-
forcement learning for LLM-based mutation. In Pro-
ceedings of the 33rd ACM SIGSOFT International
Symposium on Software Testing and Analysis (ISSTA
’24), pages 1–13, New York, NY, USA. ACM.
Fagin, R. and Wimmers, E. L. (2000). A formula for incor-
porating weights into scoring rules. Theoretical Com-
puter Science, 239(2):309–338.
Groß, S., Koch, S., Bernhard, L., Holz, T., and Johns, M.
(2023). Fuzilli: Fuzzing for JavaScript JIT compiler
vulnerabilities. In Network and Distributed Systems
Security (NDSS) Symposium 2023, pages 10–25, San
Diego, CA, USA.
Han, H., Oh, D., and Cha, S. (2019). CodeAlchemist:
Semantics-aware code generation to find vulnerabili-
ties in JavaScript engines. In Network and Distributed
System Security Symposium.
He, X., Xie, X., Li, Y., Sun, J., Li, F., Zou, W., Liu,
Y., Yu, L., Zhou, J., Shi, W., et al. (2021). Sofi:
Reflection-augmented fuzzing for JavaScript engines.
In Proceedings of the 2021 ACM SIGSAC Conference
on Computer and Communications Security, pages
2229–2242.
Holler, C., Herzig, K., and Zeller, A. (2012). Fuzzing with
code fragments. In 21st USENIX Security Symposium
(USENIX Security 12), pages 445–458, Bellevue, WA.
USENIX Association.
Kang, Z. (2021). A review on JavaScript engine vulnerabil-
ity mining. In Journal of Physics: Conference Series,
volume 1744, page 042197. IOP Publishing.
Kienle, H. M. (2010). It’s about time to take JavaScript
(more) seriously. IEEE Software, 27(3):60–62.
Lee, S., Han, H., Cha, S. K., and Son, S. (2020). Montage:
A neural network language Model-Guided JavaScript
engine fuzzer. In 29th USENIX Security Symposium
(USENIX Security 20), pages 2613–2630. USENIX
Association.
Li, F. and Paxson, V. (2017). A large-scale empirical study
of security patches. In Proceedings of the 2017 ACM
SIGSAC Conference on Computer and Communica-
tions Security, CCS ’17, page 2201–2215, New York,
NY, USA. Association for Computing Machinery.
Mozilla (2022). jsfunfuzz. https://github.com/
MozillaSecurity/funfuzz. Accessed in 08/24/2022.
Oliveira, B. G., Endo, A. T., and Vergilio, S. (2023).
Characterizing security-related commits of JavaScript
engines. In In Proceedings of the 25th Interna-
tional Conference on Enterprise Information Systems
(ICEIS), volume 2, pages 86–97.
Park, S., Xu, W., Yun, I., Jang, D., and Kim, T. (2020).
Fuzzing JavaScript engines with aspect-preserving
mutation. In 2020 IEEE Symposium on Security and
Privacy (SP), pages 1629–1642.
Shin, Y. and Williams, L. (2008). Is complexity really the
enemy of software security? In Proceedings of the
4th ACM Workshop on Quality of Protection, QoP
’08, page 47–50, New York, NY, USA. Association
for Computing Machinery.
Sun, L., Wu, C., Wang, Z., Kang, Y., and Tang, B. (2022).
KOP-Fuzzer: A key-operation-based fuzzer for type
confusion bugs in JavaScript engines. In 2022 IEEE
46th Annual Computers, Software, and Applications
Conference (COMPSAC), pages 757–766.
Tian, Y., Qin, X., and Gan, S. (2021). Research on fuzzing
technology for JavaScript Engines. In Proceedings
of the 5th International Conference on Computer Sci-
ence and Application Engineering, pages 1–7.
Wang, J., Chen, B., Wei, L., and Liu, Y. (2019). Superion:
Grammar-aware greybox fuzzing. In 2019 IEEE/ACM
41st International Conference on Software Engineer-
ing (ICSE), pages 724–735.
Wang, J., Zhang, Z., Xin, Q. A., Liu, S., Du, X., and
Chen, J. (2023). FuzzJIT: Oracle-Enhanced fuzzing
for JavaScript engine JIT compiler. In 32nd USENIX
Security Symposium (USENIX Security 23), Anaheim,
CA. USENIX Association.
Xiang, Y., Zhang, X., Liu, P., Ji, S., Liang, H., Xu, J., and
Wang, W. (2024). Critical code guided directed grey-
box fuzzing for commits. In 33rd USENIX Security
Symposium (USENIX Security 24), pages 2459–2474,
Philadelphia, PA. USENIX Association.
Zhu, X. and B
¨
ohme, M. (2021). Regression greybox
fuzzing. In Proceedings of the 2021 ACM SIGSAC
Conference on Computer and Communications Secu-
rity, CCS ’21, page 2169–2182, New York, NY, USA.
Association for Computing Machinery.
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
70
