
ADA-Gen: Iterative and Incremental Generation of Full-Stack Apps for
Learning Agile/DevOps Software Development Practices
Ta Nguyen Binh Duong
a
School of Computing and Information Systems, Singapore Management University, Singapore
Keywords:
Full-Stack App Generation, Teaching and Learning Agile/DevOps Practices, Iterative and Incremental
Software Development, Large Language Models.
Abstract:
To learn Agile/DevOps practices effectively, students need to apply them in an actual software development
project. This is challenging if students are mostly from non-computing backgrounds and they do not have
time in the curriculum to learn programming and related tools. Therefore, it is important to help students who
do not possess programming foundations to develop fully functional software during the process of learning
Agile/DevOps concepts. We noted that existing low-code/no-code app development platforms have not been
designed to teach Agile/DevOps practices. On the other hand, recent AI-based tools for code generation such
as GitHub Copilot have been built mainly for programmers. In this work, we designed and implemented ADA-
Gen (Agile/DevOps App Generator), a teaching tool leveraging large language models (LLMs) to generate
full-stack web apps following an iterative and incremental development methodology widely practiced in
Agile/DevOps circles. ADA-Gen is integrated with Jira, one of the most popular platforms for software
project management, so students can use it right away without much further setup. This approach allows non-
computing students to experience the complete full-stack software development life cycle. We have conducted
extensive evaluations of ADA-Gen using various realistic project scenarios. The evaluations demonstrated the
capabilities of ADA-Gen in full-stack web app generation, and in providing plenty of learning opportunities
for students to appreciate key Agile/DevOps practices.
1 INTRODUCTION
Agile and DevOps practices have been widely used in
software development to enhance team productivity
and software quality (Mehta and Sood, 2023). Com-
mon Agile methodologies (Schwaber and Sutherland,
2011) are characterized by iterative and incremental
development of working software, frequent feedback,
and adaptability to changing requirements. They have
been shown to increase the success rates of software
projects (Palopak and Huang, 2024). On the other
hand, DevOps (Amaro et al., 2022) extends the Ag-
ile philosophy by leveraging automation to bridge the
gap between development and operations teams; en-
abling frequent releases of production software and
increased customer satisfaction.
Although there have been many variations of Ag-
ile (Al-Baik et al., 2024), in popular methods such as
Scrum (Schwaber and Sutherland, 2011), the project
is broken down into iterative and incremental cycles
called sprints, which typically last around 2-4 weeks.
a
https://orcid.org/0000-0002-2882-2837
The software requirements/features are usually de-
tailed in the form of user stories or epics (Cohn,
2004), which are descriptions of functionality from
the user’s perspective. In each sprint, several se-
lected user stories can be further broken down into
child tasks (or sub-tasks) and implemented. A work-
ing software prototype must be demonstrated by the
end of the sprint to the stakeholders. Agile’s em-
phasis on iterative/incremental development and fre-
quent release of working software can be supported
by DevOps practices (Amaro et al., 2022) such as
continuous integration (CI), which is basically the fre-
quent, automated integration and testing of small code
changes from team members in a shared repository.
Agile/DevOps practices have been covered widely
in software engineering courses at higher education
institutions. It has been noted that Agile teach-
ing should emphasize hands-on experience rather
than theoretical knowledge of specific Agile meth-
ods (Deved
ˇ
zi
´
c et al., 2010; Omidvarkarjan et al.,
2023). Other studies have also shown that project-
based learning approaches, where students engage in
Ta, D. N. B.
ADA-Gen: Iterative and Incremental Generation of Full-Stack Apps for Learning Agile/DevOps Software Development Practices.
DOI: 10.5220/0013422800003932
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 17th International Conference on Computer Supported Education (CSEDU 2025) - Volume 2, pages 363-370
ISBN: 978-989-758-746-7; ISSN: 2184-5026
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
363
actual software development, lead to improved under-
standing of Agile principles (Almeida, 2012). How-
ever, it is challenging for non-computing students
(e.g., in short courses for post-graduate certificates)
to obtain such hands-on experience as they are not
able to actually implement and demonstrate working
software in the short time frame of a semester. Low-
code or no-code development environments, e.g., Mi-
crosoft Power Apps, have been used to teach Agile
processes (Lebens and Finnegan, 2021). We note that
such approach might not be able to provide a realistic
hands-on development experience.
Recently, pre-trained large language models
(LLMs) such as the GPT based models have been
widely used in software development tasks such as
code completion, test case generation, code review,
etc. (Ozkaya, 2023). Existing tools like Open-
Devin (Wang et al., 2024), GitHub Copilot, Ama-
zon CodeWhisperer (Li et al., 2024) have been in-
troduced to improve software development productiv-
ity. However they are designed primarily for soft-
ware engineers rather than non-computing students
without background in programming. More recent
AI-based tools (Brockenbrough and Salinas, 2024;
da Silva Neo et al., 2024) leverage LLMs to gener-
ate or improve user stories, but this is just one aspect
of Agile/DevOps practices. To the best of our knowl-
edge, there has been no LLM-based code generation
tool designed specifically for helping non-computing
students learn Agile/DevOps concepts more effec-
tively. This is the focus of our work.
2 ADA-GEN
2.1 Objectives
In this work, the goal is to assist students with no
or very little programming background to learn Ag-
ile/DevOps practices by experiencing a real-world,
typical software development life cycle. ADA-Gen
is not designed to generate very complex apps used
in critical business processes. This approach dif-
fers from existing frameworks like OpenDevin (Wang
et al., 2024), which focus on more advanced appli-
cation development and designed primarily for soft-
ware engineers. However, it is important that our tool
provides exposure to common technical issues, e.g.,
bug fixing, requirement improvement, testing, inte-
gration, etc., in real-world Agile/DevOps projects. To
this end, we consider the following key design objec-
tives of ADA-Gen:
• Generating code from popular project manage-
ment interfaces such as Jira. This is to help stu-
dents appreciate Agile practices without leaving
their familiar tools and environments.
• Providing learning opportunities for a deeper ap-
preciation of Agile/DevOps practices such as user
story writing, task breakdown, task estimation,
velocity, continuous integration, etc. This is be-
cause learning practices and theoretical processes
using only planning tools like Jira without experi-
encing real development is not sufficient (Omid-
varkarjan et al., 2023).
• Supporting iterative and incremental develop-
ment. The code generation process should be
carried out per sprint. In addition, subsequent
sprints should incorporate code generated in ear-
lier sprints for continuity and consistency. In
this way, students can appreciate the importance
of making continuous and incremental improve-
ments and adjustments based on feedback during
each sprint review.
• Generating ready-to-run, full-stack web apps with
both front-end and back-end components. This is
because students will need to do a demonstration
to stakeholders at the end of each sprint.
2.2 System Design
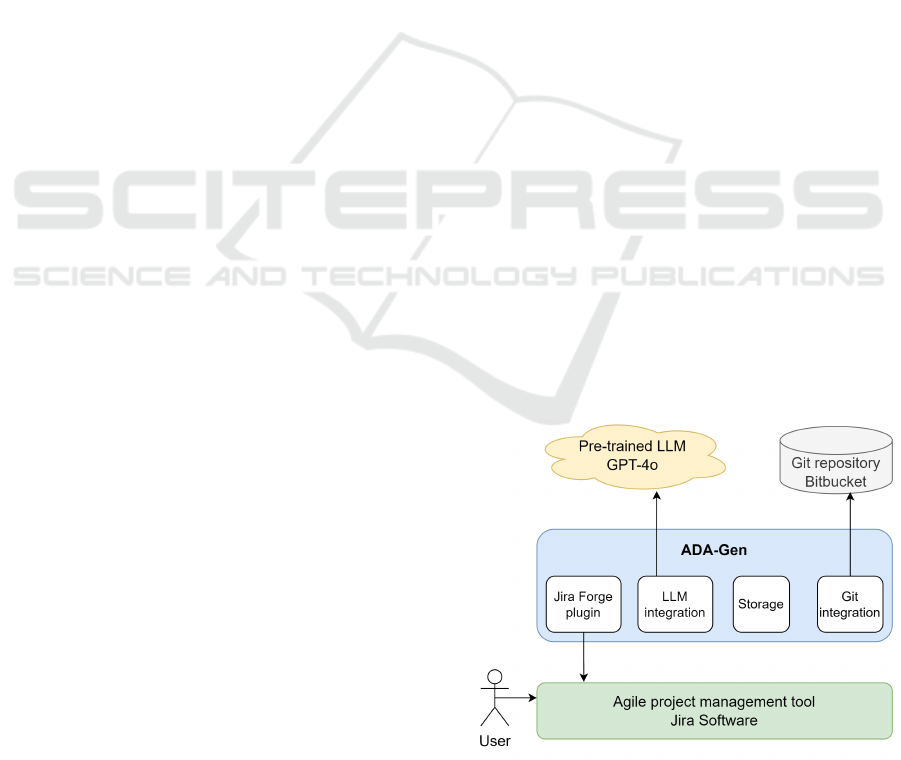
ADA-Gen integrates a software project management
platform (Jira), a hosted Git repository for code
version control (Bitbucket), and a pre-trained LLM
(OpenAI’s GPT-4o) into a learning tool that non-
computing students can use to learn and experience
incremental and iterative development practices used
in Agile/DevOps processes. Our design, as shown
in Figure 1, is based on a microservices architecture
which includes the following components:
Figure 1: Components in ADA-Gen’s software architecture.
CSEDU 2025 - 17th International Conference on Computer Supported Education
364

Jira Forge Plugin. A Jira software plugin developed
using Atlassian Forge
1
, which is a cloud app devel-
opment platform provided by Atlassian. Apps built
with Forge are hosted entirely on Atlassian serverless
cloud infrastructure. This enables the creation of cus-
tom Jira apps integrated directly into the Jira user in-
terface. As most students should already be famil-
iar with the use of Jira for project management, the
learning curve is reduced for ADA-Gen. The plugin
is implemented in JavaScript and deployed on Atlas-
sian cloud. The Forge SDK allows the plugin to make
calls to the Jira APIs to fetch stories and other project
related information for code generation.
LLM Integration. A Java Spring Boot service which
can be hosted on any public clouds or locally. The
service provides integration with a selected LLM de-
ployment, e.g., OpenAI. In our implementation, we
use OpenAI’s GPT-4o APIs. This Spring Boot service
also handles requests from the Jira pages and commu-
nicates with the database storage.
Git Integration. ADA-Gen requires the integration
of a hosted Git repository such as GitHub or Bit-
bucket. This is essential for maintaining the generated
source code and configuration files for sprint by sprint
code generation, and continuous integration.
Storage. ADA-Gen has a storage component which
uses a relational database for important project-
related information such as LLM API keys and Git
repository access tokens.
2.3 Prompt Engineering
The main challenge in implementing ADA-Gen is
to generate incremental code in multiple consecutive
sprints while maintaining consistency and ensuring
that a proper working prototype can be created af-
ter a few sprints. ADA-Gen makes use of LLMs,
in particular OpenAI’s GPT-4o. A prompt is con-
structed with the required user story and sent to the
LLM, which will reply with generated code (HTML,
CSS, JavaScript, and Python) implementing the story.
Constructing appropriate LLM prompts for a partic-
ular application domain is referred to as prompt en-
gineering, which is a currently active research area
(Oppenlaender et al., 2024).
In ADA-Gen, we have devised a prompting strat-
egy with multiple stages. The prompt provides infor-
mation not just about the current story to be gener-
ated, but also the relevant context from sibling and/or
child tasks, desired repository structure and existing
code, templates for expected code structure, genera-
tion guidelines, and directives for potential bug pre-
vention. The below details are included in the prompt
1
https://developer.atlassian.com/platform/forge
sent to the LLM for code generation. Multiple sto-
ries in the same sprint can be generated sequentially
in this way.
Initial Setup. At the start of the prompt, we provide
instructions to set the overall guidelines for the LLM,
ensuring that generated code focuses on the main user
story and its child tasks while considering related sto-
ries for context. The following instructions are used
in the prompt:
Generate cod e s t r i c t l y for the
following user s t ory and its chil d
task s . Yo u wil l be provided with
sibling us er stories an d parent
epic s as a d d i t i o nal c ontext to
assist in g e n e r ating code for the
use r story . You will also r e c e i v e a
lis t of relevant files existe d in
the r e p o s i t o ry to ensur e the
generated files do not o v e rlap with
thos e a l r e a d y p r e s e n t . Mak e
necessary c h a n ges to thes e e x i s t i n g
file s to f ulfill the s p e c i f i c
requ i r e m e nts of the use r story and
its child tasks , but do not remove
or alter any e x i s t i n g fu n c t i o nal i t y
tha t s erves othe r user storie s .
Prompt Structure Information. In the next stage,
we provide a layout to help the LLM understand the
prompt structure and context of various tasks. This
could make it easier to generate more relevant and co-
herent responses. Below is the prompt structure given
to the LLM:
Use r story and its c hild tas k s
Parent e pic a nd sibling stories if any
Relevant files in r e p o s i t o ry if a ny
Cod e t e m p l a t e s for back - end and front -
end c o m p o n e n ts
Genera t i o n guideli n e s for code
Bug p r e v e n t i on d i r e c t i v e s
User Story Details. In this stage, we provide details
for the user story for which code has to be generated
by the LLM. The user story’s title, ID, and descrip-
tion are automatically retrieved from the Jira project
via the Forge plugin when user chooses to do code
generation. We specify the story as follows:
< U ser sto r y to generate code for >
Title , ID , and d e scrip t i o n of the
use r story
</ User s t ory to generate co de for >
Child Tasks, Parent Epics and Sibling Stories. In
this part of the prompt, we provide information about
child tasks, related sibling stories and parent epics to
provide the appropriate context for the LLM to do
code generation. The LLM is not supposed to gen-
erate code for the parent and sibling stories.
ADA-Gen: Iterative and Incremental Generation of Full-Stack Apps for Learning Agile/DevOps Software Development Practices
365

Repository Integration. This step is to provide the
LLM with context on existing code and configura-
tion files in the Git repository of the project. This
helps in understanding what has already been gener-
ated to avoid duplicated code and ensure consistency
and continuity in the code.
Code Templates. This stage provides templates to
guide the LLM on how to structure the generated
code for components of the application such as back-
end, front-end, testing, Docker files, and Bitbucket
pipeline configuration for continuous integration. The
prompt includes several sample code files to provide a
template for back-end code that should be generated.
Note that we do not show the complete code here due
to space limitation.
Generation Guidelines. This part specifies the styles
and standards for the generated code, such as code
review, common code smells to avoid, e.g., lengthy
code, etc. Examples includes: 1) if the script gets too
long, divide it into multiple scripts, 2) after generating
the code, it is crucial to perform a thorough review
and validation of the entire script, etc.
Bug Prevention Directives. List potential bugs that
frequently occur and may not be caught without ex-
plicit instructions during code generation. This helps
steer the LLM away from known issues, such as in-
correct targets in configuration files, or deprecated
code that might be generated. For example, some
Flask libraries used by the LLM during code gener-
ation such as before first request, have already
been deprecated at the time of our experiment. This
leads to compilation issues for the generated code.
3 EVALUATION
In the evaluation, we aimed to answer the following
research questions (RQs):
• RQ1. It is possible for those without program-
ming knowledge to use ADA-Gen to create a
complete, full-stack web app following an itera-
tive and incremental development process in Ag-
ile/DevOps?
• RQ2. Does ADA-Gen provide learning oppor-
tunities for students to identify, implement and
appreciate important Agile/DevOps practices in
building actual software?
To answer these RQs, we designed several scenar-
ios which usually occur when students run software
development projects, based on our experience teach-
ing a large number of non-computing students the Ag-
ile/DevOps methodology over the years at our univer-
sity. The students in our Agile/DevOps courses were
post-graduates with zero, or very little background
in programming. The project scenarios range from
a simple setup in which all stories are completed in
one sprint, to those with multiple sprints and a com-
plex story structure incorporating real-world applica-
tion features.
For both RQs, we played the role of a small stu-
dent team without any programming background. To
ensure a realistic evaluation, we did not attempt to fix
any issues in the generated code manually, instead we
just relied on ADA-Gen to do the generation and bug
fixing. For RQ1, we looked at the generated code
and considered the bugs with regard to the require-
ments defined in the stories, and compilation/runtime
errors encountered after the app has been generated
in a sprint. After all issues were fixed, we ran the
generated app and evaluated if it meets the desired re-
quirements.
For RQ2, while using ADA-Gen, we identified
and discussed the opportunities for students to learn
and reinforce Agile/DevOps concepts, e.g., ways to
write better stories, deferring requirement details until
needed, iterative and incremental development con-
cepts, task estimation, progress tracking, frequent
code integration, etc. For example, when there are
bugs and errors after code generation, the students
have to fix them by revising the story to incorporate
the error messages, adjust the task estimation, and
update the actual time spent fixing the bugs. Such
learning opportunities might not be available when
students do not attempt to create working prototypes
by themselves.
3.1 Scenario 1: A Single Sprint with
Stories Having Simple Description
The aim of this scenario is to quickly evaluate the ca-
pability of ADA-Gen to perform the generation of a
simple web app which includes both front-end and
back-end components. It is also for demonstrating the
DevOps concept of continuous integration and app
containerization with Docker. This scenario can be
used by students to get a basic understanding of vari-
ous components in a full-stack app, as well as relevant
Agile and DevOps concepts such as frequent code in-
tegration and delivery of working software after each
sprint.
Scenario 1 includes two simple user stories for a
book listing application, namely Book List, and Book
Detail. There are also two related operation stories
for continuous integration and containerization of the
generated app. We note that the stories do not contain
much details, i.e., they lack further description, child
task breakdown, and/or acceptance criteria which are
CSEDU 2025 - 17th International Conference on Computer Supported Education
366

usually captured from conversation with users (Cohn,
2004).
Scenario 1:
Boo k List : I wa nt to see the t i t les
of al l books displayed on th e
hom epage , so t hat I can browse
through t he tit l e s q u i c k l y .
Boo k D etail : I wa nt to v iew all the
details of a book , nam e l y title ,
author , and a br i e f s u mmary when I
clic k on the title of a book liste d
in th e homepage .
Contin u o u s Integ r a t i o n : C reate
integ r a t i o n tes t cases to ensure
tha t l i s t ing books and v i e w i n g book
details wo rk co r r e c t l y . To
implement c o n t i nuous integrat i o n ,
create a YAM L file that sho u l d run
the testing code every t i me a
commit is done .
Con t a i ner i z a tio n : Generate a
Docker f i l e to c o n tain e r i z e the
appli c a t i o n .
For this scenario, ADA-Gen successfully gener-
ated a simple book listing application that lists all
books and allows users to view the details of each
book on a web page, without any bugs or errors.
In the generated app, there were proper back-end
and front-end components. ADA-Gen also gener-
ated several integration test cases, a Dockerfile, and
a YAML pipeline file for Bitbucket. When the gen-
erated code is committed to the Bitbucket repository
for the project, the continuous integration pipeline is
run automatically. We were able to run the web app
simply by using Docker commands.
This scenario shows that generating a simple full-
stack web app for demonstration purpose is entirely
possible with ADA-Gen (RQ1). It allows non-
computing students to play with the code and under-
stand key concepts in basic app components and con-
tinuous integration.
3.2 Scenario 2: Multiple Consecutive
Sprints with Simple Story
Description
In this scenario, the aim is to create a fairly complex
full-stack web app, in particular an online book cat-
alog. The app includes the usual CRUD operations,
some business logic, user registration, login, authen-
tication check, etc. There are more stories so they
cannot be completed in a single sprint. These stories
are organized into epics. However, similar to Sce-
nario 1, the story descriptions are shallow, i.e., they
lack details from conversations with user, task break-
down, and/or acceptance criteria (da Silva Neo et al.,
2024). This is typical in student teams just getting
started in Agile practices. As they do not have actual
coding and implementation experience, they tend to
over-simplify stories. This scenario is used to demon-
strate that creating a proper full stack app could be
difficult when you do not write appropriate user sto-
ries. It helps highlight a key learning point in Agile
otherwise neglected if students do not actually create
working software prototypes from user stories.
Below are the stories, their epics, and the sprint
structure used. Note that story descriptions, which
have a similar level of details to those in Scenario 1,
are omitted due to space limitation.
Scenario 2:
Sprint 1: Book List , Book D e t a i l s (
Epi c : B o ok Mana g e m e n t )
Sprint 2: User R e g i stration , Login
( Epic : Use r M a n a gement ) , A dding
Book s ( Epi c : Bo ok M a n a g e m e n t )
Sprint 3: A dding / Removing Favorite
Books , F a v o r i t e s Lis t Page ( Epi c :
Boo k M a n a g ement )
Sprint 4: Most P o p u l a r B ooks ( Epic :
Boo k M a n a g ement )
Contin u o u s Integ r a t i o n and
Con t a i ner i z a tio n are i n c l u d e d in
eac h s print .
In this scenario, sprint 1 does not have issues with
the code generation for the selected stories due to their
simplicity. In the subsequent sprints, ADA-Gen gen-
erated new code and also updated the existing code to
implement the new features requested in each sprint.
We encountered several errors/bugs in the code gener-
ated by ADA-Gen in the later sprints. A common is-
sue is the links to newly generated HTML pages were
not included in the homepage of the app for conve-
nient navigation. This is mainly because the user sto-
ries did not clearly specify such feature. This could
serve as a learning opportunity for students to appre-
ciate that details for stories should be fleshed out suf-
ficiently, and that a single line story is not sufficient
for actual implementation (RQ2).
We note that it was possible to fix the above is-
sue during the sprint by creating a new child task or
just by simply adding more description on the need
to include a navigation bar with all the required links,
then generating the code again with ADA-Gen. Sprint
ADA-Gen: Iterative and Incremental Generation of Full-Stack Apps for Learning Agile/DevOps Software Development Practices
367

2 had a bug involving the user registration feature,
and Sprint 4 had some failed test cases due to a miss-
ing import for generate password hash. Similarly,
these issues were fixed by adding child tasks con-
taining the error messages produced during continu-
ous integration, and re-generating the code. Through
clarifying user stories by adding more tasks or de-
scriptions when encountering errors from the gener-
ated code, students can learn to write better stories
(RQ2).
In addition, students would be able to experience
first-hand the possible technical issues occurring in a
sprint. They would also be able to carry out bug fix-
ing which requires them to look at the code and er-
rors, and to spend actual time during the sprint. These
learning opportunities could contribute to their un-
derstanding of task estimation and realistic progress
tracking techniques used in Agile practices (RQ2).
Such opportunities might not be available if they do
not implement a working software in each sprint, or
use a no-code platform to create apps.
Providing shallow descriptions to stories could
lead to difficult issues when we need to actually re-
alize a working software (da Silva Neo et al., 2024).
Sprints 2, 3 and 4 all have the same authentication
check issue, in which users could perform any CRUD
operations without proper authentication. We were
not able to resolve this issue using ADA-Gen given
the current story structure and level of details in Sce-
nario 2. Possible resolutions would require a com-
plete rewriting of most of the stories to specify the
child tasks such as what the front-end should return
when user logins, what the back-end should check
for, and so on. This scenario demonstrates that it
might not be possible to create a fully working soft-
ware when you do not write the proper stories as re-
quirements. This is a good learning point for students
trying to practice Agile development (RQ2).
In the next scenario, we would show that by writ-
ing clear stories with detailed task breakdown would
enable ADA-Gen to generate better code, which we
could fix to produce a fully working software at the
end of each sprint.
3.3 Scenario 3: Multiple Sprints, Stories
with More Detailed Description
The sprint structure and story organization here are
similar to those of Scenario 2. However, more de-
tails are provided for stories, which include child task
breakdown, confirmations, i.e., acceptance criteria,
and the separation of front-end and back-end tasks in
a story. An example is provided below.
Use r R e g istr a t i o n : As a visi tor , I w ant
to register a u ser account u s i ng
my email and passw ord , so tha t I
can login l a ter .
Frontend tasks : 1) Provide a
regi s t r a t ion form with f i e l d s for
email , passw ord , an d password
conf i r m a t ion . 2) D i s p l ay
regi s t r a t ion p r o b l e m s if any from
the backend output .
Backend tas k s : 1) I m p l e m ent role -
base d a c c ess control so t hat use r s
can create accounts to l o gin int o
the system . 2) Create a RES T API
endpoint which a c c e p t s e mail and
password to c r e a t e a u ser account .
3) Th e email has to be in a val i d
format . 4) The emai l must not e xist
in th e database b efore use r
account creation . 5) The p a s s w o r d
has to be at least 8 cha r a c t e r s
whic h i n c l u d e at least one d igit
and at leas t one s p e c i a l c h a r a c t e r .
6) Th e password has to be s t o r e d
securely wit h h a s h ing . 7)
Appro p r i a t e error m e s s a g e s and
status c ode to be r e t u r n e d when
ther e are p r o b l e m s w ith u ser
regi s t r a t ion .
In this scenario, Sprint 1 and 3 had no issues with
code generation. Sprints 2 and 4 had several errors
that we were able to fix in a similar way used in Sce-
nario 2. For example, the User Registration story
required additional details to explain how to imple-
ment role-based access control by specifying the pos-
sible user roles such as regular and admin. The orig-
inal user story, as shown above, did not have such de-
tails, which led to authentication implementation is-
sues.
Halfway through the project, we were compelled
to introduce more new stories to response to issues
in ADA-Gen such as incomplete implementation and
accidental removal of features implemented in previ-
ous sprints. These stories were not part of the original
backlog. This highlights a key agile learning point in
which we need to handle changes that happens during
a project (RQ2). For example, new user stories titled
Page Accessibility and Personalized Content
were introduced to provide instructions on what data
should be maintained after users successfully login,
and how it should make use of those data to perform
access control. Due to the additional stories, one more
sprint was introduced in this scenario instead of just
four planned initially. This demonstrates the uncer-
tainty inherent in software projects and the applica-
tion of Agile practices to build working prototype in-
CSEDU 2025 - 17th International Conference on Computer Supported Education
368

crementally and iteratively to discover new require-
ments (RQ2). With actual development work assisted
by ADA-Gen, students would be able to better appre-
ciate this kind of challenges, and how Agile practices
are used to handle them.
We noted that in Scenario 3 with better story writ-
ing, ADA-Gen was able to generate code for more
complicated features like authentication and access
control. However, if too much details are provided
in the stories, the LLM might skip some complex in-
structions (He et al., 2024). This can lead to missing
features during code generation. For example, in our
experiments, if authentication and access control were
implemented in a single story, there would be a sig-
nificant amount of details regarding user registration,
user login and authentication, user session manage-
ment, role-based access control to restrict accesses,
etc. With all these details, the LLM often failed to
fully implement the correct features, or even acciden-
tally removed previously implemented features. In
our experiments with ADA-Gen, it was usually better
to perform code generation and observed the bugs/er-
rors with simple story structure first, before trying to
add more details to fix these issues. This learning op-
portunity enables students to appreciate well-known
Agile practices such as breaking down large stories
into smaller ones, and deferring details until they are
needed (RQ2).
3.4 Evaluation Summary
Summary-RQ1. From the evaluation scenarios, we
have observed that it is entirely possible for ADA-Gen
to generate functional full-stack web applications fol-
lowing a typical sprint-based software development
process. The generated apps consist of proper front-
end and back-end components which can be used for
demonstration purposes at the end of each sprint. In
this way, ADA-Gen could be useful to students with-
out programming background in their journey to learn
Agile/DevOps concepts.
Summary-RQ2. ADA-Gen provides plenty of op-
portunities for students to appreciate key Agile/De-
vOps software development practices such as writ-
ing better stories with well-defined child tasks so that
working code can be generated, deferring requirement
details until necessary, code review, bug fixing, con-
tinuous integration, etc. These learning opportunities
would have been limited if students were not able to
create working software prototypes by themselves.
3.5 Threats to Validity
We note that there are a few limitations which may
affect the validity of this study. First, the output from
LLMs such as GPT-4o could be non-deterministic,
which may impact the consistency of the generated
code. We have tried to consider this by generating
and evaluating the generated apps using a number of
different practical scenarios and user stories. Second,
while state-of-the-art LLMs such as GPT-4o are pow-
erful, they are unlikely to generate perfect code for
all situations and requirements. Therefore it is pos-
sible that in some cases students will not be able to
obtain a fully functional app for demonstration. Fi-
nally, although we role-played as a student team dur-
ing the evaluation and did not attempt to modify the
code manually using our programming knowledge to
make the evaluation realistic, it might be possible that
student teams with zero coding knowledge will find
it difficult to use ADA-Gen. We plan to address this
issue with a larger scale evaluation in the upcoming
semester.
4 RELATED WORK
As far as we know, there is not much recent work
that attempted to address the challenge of teaching
Agile/DevOps to novice or non-computing students.
One approach is to leverage low-code/no-code de-
velopment platforms (Guthardt et al., 2024), which
are visual tools enabling people without program-
ming background to build their own software sys-
tems. The application of low-code/no-code platforms,
namely Microsoft Power Apps and OutSystems, to
teach Agile processes have been explored (Lebens
and Finnegan, 2021; Metr
ˆ
olho et al., 2020). How-
ever, we note that such platforms do not expose stu-
dents to actual coding and integration issues. This
may affect the learning experience and appreciation
of Agile/DevOps practices in real-world software de-
velopment projects.
There has been a recent trend to incorporate AI
advancements into the computer science curriculum
(Ozkaya, 2023) to cover real-world complex software
tasks instead of just basic app development. LLMs
have also been used to help students learn program-
ming (Ta et al., 2023; Cambaz and Zhang, 2024) and
write user stories (Brockenbrough and Salinas, 2024).
To our knowledge, there has been no existing work
making use of LLM code generation to offer a realis-
tic teaching and learning platform for Agile/DevOps
concepts.
ADA-Gen: Iterative and Incremental Generation of Full-Stack Apps for Learning Agile/DevOps Software Development Practices
369

5 CONCLUSION
In this work, we have developed a tool called ADA-
Gen that performs automatic full-stack app generation
in an incremental and iterative manner. ADA-Gen is
designed for individuals without coding knowledge to
learn Agile/DevOps software development practices.
Student teams using ADA-Gen can actually execute
a full software development lifecycle incrementally
and iteratively. Through the usage of ADA-Gen, non-
computing students can learn to appreciate important
Agile/DevOps practices such as continuous integra-
tion, deferring requirement details until necessary, or
to write better stories with sufficient breakdown of
technical tasks so that working code can be generated
via the state-of-the-art LLMs. We plan to conduct a
larger scale evaluation of ADA-Gen with multiple stu-
dent teams from non-computing backgrounds during
the next semester at our institution.
ACKNOWLEDGMENT
We would like to thank Chen Kun and the CS480 un-
dergraduate team SMU Zealand All Blacks for their
initial contributions to this work.
REFERENCES
Al-Baik, O., Abu Alhija, M., Abdeljaber, H., and Ovais Ah-
mad, M. (2024). Organizational debt—roadblock to
agility in software engineering: Exploring an emerg-
ing concept and future research for software excel-
lence. PloS one, 19(11):e0308183.
Almeida, F. (2012). Using agile practice for student soft-
ware projects. Journal of Education and Vocational
Research, 3(9):280–290.
Amaro, R., Pereira, R., and da Silva, M. M. (2022). Capa-
bilities and practices in devops: a multivocal literature
review. IEEE Transactions on Software Engineering,
49(2):883–901.
Brockenbrough, A. and Salinas, D. (2024). Using genera-
tive ai to create user stories in the software engineer-
ing classroom. In 2024 36th International Confer-
ence on Software Engineering Education and Train-
ing (CSEE&T), pages 1–5. IEEE.
Cambaz, D. and Zhang, X. (2024). Use of ai-driven code
generation models in teaching and learning program-
ming: a systematic literature review. In Proceedings
of the 55th ACM Technical Symposium on Computer
Science Education V. 1, pages 172–178.
Cohn, M. (2004). User stories applied: For agile software
development. Addison-Wesley Professional.
da Silva Neo, G., Moura, J. A. B., Almeida, H. O.,
da Silva Neo, A. V. B., and J
´
unior, O. d. G. F. (2024).
User story tutor (ust) to support agile software devel-
opers. In CSEDU (2), pages 51–62.
Deved
ˇ
zi
´
c, V. et al. (2010). Teaching agile software develop-
ment: A case study. IEEE transactions on Education,
54(2):273–278.
Guthardt, T., Kosiol, J., and Hohlfeld, O. (2024). Low-code
vs. the developer: An empirical study on the devel-
oper experience and efficiency of a no-code platform.
In Proceedings of the ACM/IEEE 27th International
Conference on Model Driven Engineering Languages
and Systems, pages 856–865.
He, Q., Zeng, J., Huang, W., Chen, L., Xiao, J., He, Q.,
Zhou, X., Liang, J., and Xiao, Y. (2024). Can large
language models understand real-world complex in-
structions? In Proceedings of the AAAI Conference
on Artificial Intelligence, volume 38, pages 18188–
18196.
Lebens, M. and Finnegan, R. (2021). Using a low code
development environment to teach the agile method-
ology. In International Conference on Agile Software
Development, pages 191–199. Springer.
Li, S., Cheng, Y., Chen, J., Xuan, J., He, S., and Shang,
W. (2024). Assessing the performance of ai-generated
code: A case study on github copilot. In 2024 IEEE
35th International Symposium on Software Reliability
Engineering (ISSRE), pages 216–227. IEEE.
Mehta, K. and Sood, V. M. (2023). Agile software develop-
ment in the digital world–trends and challenges. Agile
Software Development: Trends, Challenges and Ap-
plications, pages 1–22.
Metr
ˆ
olho, J. C., Ribeiro, F. R., and Pass
˜
ao, P. (2020). Teach-
ing agile software engineering practices using scrum
and a low-code development platform–a case study. In
Proceedings of the 15th Conference on Software En-
gineering Advances, pages 160–165.
Omidvarkarjan, D., Hofelich, M., Conrad, J., Klahn, C., and
Meboldt, M. (2023). Teaching agile hardware devel-
opment with an open-source engineering simulator:
An evaluation with industry participants. Computer
Applications in Engineering Education, 31(4):946–
962.
Oppenlaender, J., Linder, R., and Silvennoinen, J. (2024).
Prompting ai art: An investigation into the creative
skill of prompt engineering. International Journal of
Human–Computer Interaction, pages 1–23.
Ozkaya, I. (2023). Application of large language models to
software engineering tasks: Opportunities, risks, and
implications. IEEE Software, 40(3):4–8.
Palopak, Y. and Huang, S.-J. (2024). Perceived impact of
agile principles: Insights from a survey-based study
on agile software development project success. Infor-
mation and Software Technology, 176:107552.
Schwaber, K. and Sutherland, J. (2011). The scrum guide.
Scrum Alliance, 21(1):1–38.
Ta, N. B. D., Nguyen, H. G. P., and Gottipati, S. (2023). Ex-
gen: Ready-to-use exercise generation in introductory
programming courses. In International Conference on
Computers in Education.
Wang, X., Li, B., Song, Y., Xu, F. F., Tang, X., Zhuge, M.,
Pan, J., Song, Y., Li, B., Singh, J., et al. (2024). Open-
devin: An open platform for ai software developers as
generalist agents. arXiv preprint arXiv:2407.16741.
CSEDU 2025 - 17th International Conference on Computer Supported Education
370
