
A Hybrid Music Recommendation System Based on K-Means Clustering
and Multilayer Perceptron
Rafael Cintra de Araujo, Victor Moises Silveira Santos, Joao Fausto Lorenzato de Oliveira
and Alexandre M. A. Maciel
Universidade de Pernambuco, Recife - PE, Brazil
Keywords:
Music Recommendation Systems, Hybrid Models, K-Means Clustering, Multilayer Perceptron (MLP),
Similarity Matrix.
Abstract:
Music recommendation systems have become indispensable tools for enhancing user experiences by offering
personalized playlists tailored to individual preferences. However, traditional recommendation approaches
often struggle with challenges such as accurately capturing user tastes, maintaining diversity in recommen-
dations, and addressing the cold-start problem, where limited user data hampers effective predictions. To
address these issues, this study presents a hybrid recommendation model that integrates K-Means clustering
and a Multilayer Perceptron (MLP) neural network to deliver coherent and diverse music recommendations.
The model utilizes the all-MiniLM-L6-v2 embedding, a powerful sentence-transformer, to analyze semantic
similarities in textual data such as song titles, artist names, and lyrics, encoding them into a dense vector
space. Combined with normalized audio features, these embeddings enable clustering and similarity-based
recommendations. Extensive experiments, conducted on datasets from Spotify and Kaggle, employed key
metrics such as accuracy, F1 score, silhouette score, and cosine similarity to evaluate performance. The results
highlight the system’s ability to maintain genre coherence and acoustic feature consistency, minimize track
repetition, and foster user engagement. Addressing challenges like the cold-start problem and diverse user
preferences, the proposed model demonstrates its potential for real-world applications. Future extensions in-
clude incorporating user feedback and supporting multi-session recommendations to adapt to evolving music
trends, offering a robust and innovative approach to music recommendation systems.
1 INTRODUCTION
Recommender systems are essential for personalizing
user experiences by identifying preferences and sug-
gesting relevant content (Sharma and Gera, 2013). In
the music domain, they enhance discovery by con-
necting users to new songs and artists (Song et al.,
2012). However, challenges such as the cold-start
problem and capturing implicit user preferences per-
sist (Roberts et al., 2014). The growth of music
streaming platforms has increased data complexity,
making it difficult to balance diversity, coherence, and
accuracy in recommendations. Traditional collabora-
tive and content-based filtering methods often strug-
gle with large datasets, leading to less relevant sug-
gestions.
To address these issues, this study proposes a
hybrid recommendation model integrating clustering
techniques (Hartigan and Wong, 1979), neural net-
works (Vogels et al., 2005), and ensemble models. By
leveraging unsupervised learning (Pola et al., 2003),
the system uncovers hidden patterns in large datasets
while combining content-based and collaborative fil-
tering (Goto, nd), for improved recommendation rel-
evance and diversity. Additionally, it explores au-
dio features and metadata (Defferrard et al., 2017) to
process complex musical data, overcoming traditional
limitations like high dependence on user interaction
data and poor generalization to new content.
This study advances music recommendation sys-
tems by introducing a scalable, adaptable framework
capable of handling large-scale, heterogeneous data
while ensuring personalization and efficiency. The
paper is structured as follows: Introduction outlines
the study’s motivation and challenges; Related Work
reviews existing methodologies; Proposed Method
details the hybrid model, including K-Means and
MLP; Experimental Section describes datasets, eval-
uation metrics, and procedures; Results analyze the
system’s effectiveness in balancing personalization,
de Araúijo, R. C., Santos, V. M. S., Lorenzato de Oliveira, J. F. and Maciel, A. M. A.
A Hybrid Music Recommendation System Based on K-Means Clustering and Multilayer Perceptron.
DOI: 10.5220/0013436700003929
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 27th International Conference on Enterprise Information Systems (ICEIS 2025) - Volume 1, pages 335-342
ISBN: 978-989-758-749-8; ISSN: 2184-4992
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
335
diversity, and computational efficiency; and Conclu-
sions summarize findings, discuss limitations, and
suggest future improvements.
2 RELATED WORKS
Recent advances in recommender systems have lever-
aged machine learning and hybrid approaches to im-
prove personalization and scalability. Various stud-
ies address limitations in content-based and collabo-
rative filtering, introducing more efficient and accu-
rate methods.
The study by (Domingues et al., 2012). explores
hybrid recommendation algorithms as a solution to
overcome the limitations of content-based and col-
laborative filtering methods. By integrating multiple
data sources, the system achieved a 119% increase in
absolute acceptance rate (AAR) over content-based
methods and a 50% improvement over usage-based
approaches, with user loyalty rates (L3R) increasing
by 16%.
Godinho et al., addressed scalability and accu-
racy by clustering user behavior patterns, improv-
ing recommendation efficiency, though specific per-
formance metrics were not disclosed. (Wu et al.,
2024) applied deep neural networks to analyze audio
features and metadata, capturing implicit user pref-
erences and significantly improving recommendation
accuracy. Their model achieved an RMSE of 0.323 in
warm-start scenarios, outperforming traditional meth-
ods while maintaining precision in cold-start cases.
(Godinho and Vasconcelos, nd).
Chen et al. proposed an unsupervised learning
approach, using advanced clustering and deep learn-
ing to enhance scalability and efficiency for large
datasets. Although specific performance metrics were
not reported, the study emphasized the computational
benefits of clustering in large-scale platforms.
These studies highlight the evolution of recom-
mender systems, showcasing hybrid models, deep
learning, and clustering as effective techniques for
improving personalization, scalability, and accuracy
in music recommendation.(Yoshii et al., 2008).
The study by Yoshii et al. integrates usage data
and content features within a hybrid system, leverag-
ing a probabilistic generative model to enhance diver-
sity and precision in recommendations. Evaluated on
a Japanese music dataset, the model achieved a 93.5%
precision rate, slightly below the best collaborative
method (95.2%) but introduced 90% new artists in
top-ranked recommendations, effectively addressing
the cold-start problem (Goto, nd)
Finally, the article by (Goto, nd). presents an effi-
cient incrementally trainable probabilistic generative
model. This approach combines collaborative and
content-based data to overcome cold-start issues and
improve artist diversity in recommendations. The sys-
tem maintained high accuracy even when introducing
new users and additional data, achieving a balance be-
tween precision and variety while adapting to chang-
ing datasets (Pandya, 2024).
Table 1: Comparison of Related Works.
Author Problem Context Results
Domingues
et al.
Long-tail,
sparse
datasets
Real-time
hybrid
system
119%
AAR,
50% us-
age, 16%
L3R
Godinho
and F Vas-
concelos.
Scalability,
accuracy
Large user
behavior
datasets
High effi-
ciency; no
metrics
Zhang et
al.
Improve
deep
learning
accuracy
Audio and
metadata
features
RMSE
0.323;
cold-start
precision
Chen et al. Scalability,
personal-
ization
Large-
scale
clustering
Scalable;
no specific
metrics
Yoshii et
al.
Diversity,
cold-start
problem
Hybrid
collabora-
tive model
93.5%
precision;
90% di-
versity
Goto et al. Cold-start,
artist di-
versity
Dynamic
real-world
datasets
High
accuracy,
adaptable
In Table 1, the characteristics of each related work
are presented in a concise and objective manner, high-
lighting their problems, contexts, technologies, and
results. In the following section, we will delve into
the proposed method of this study.
3 PROPOSED METHOD
This study proposes a hybrid music recommendation
system that combines supervised and unsupervised
machine learning techniques, clustering analysis, and
recommendation algorithms to deliver a personalized
and diverse user experience. The steps of the pro-
posed pipeline are outlined, along with a detailed ex-
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
336
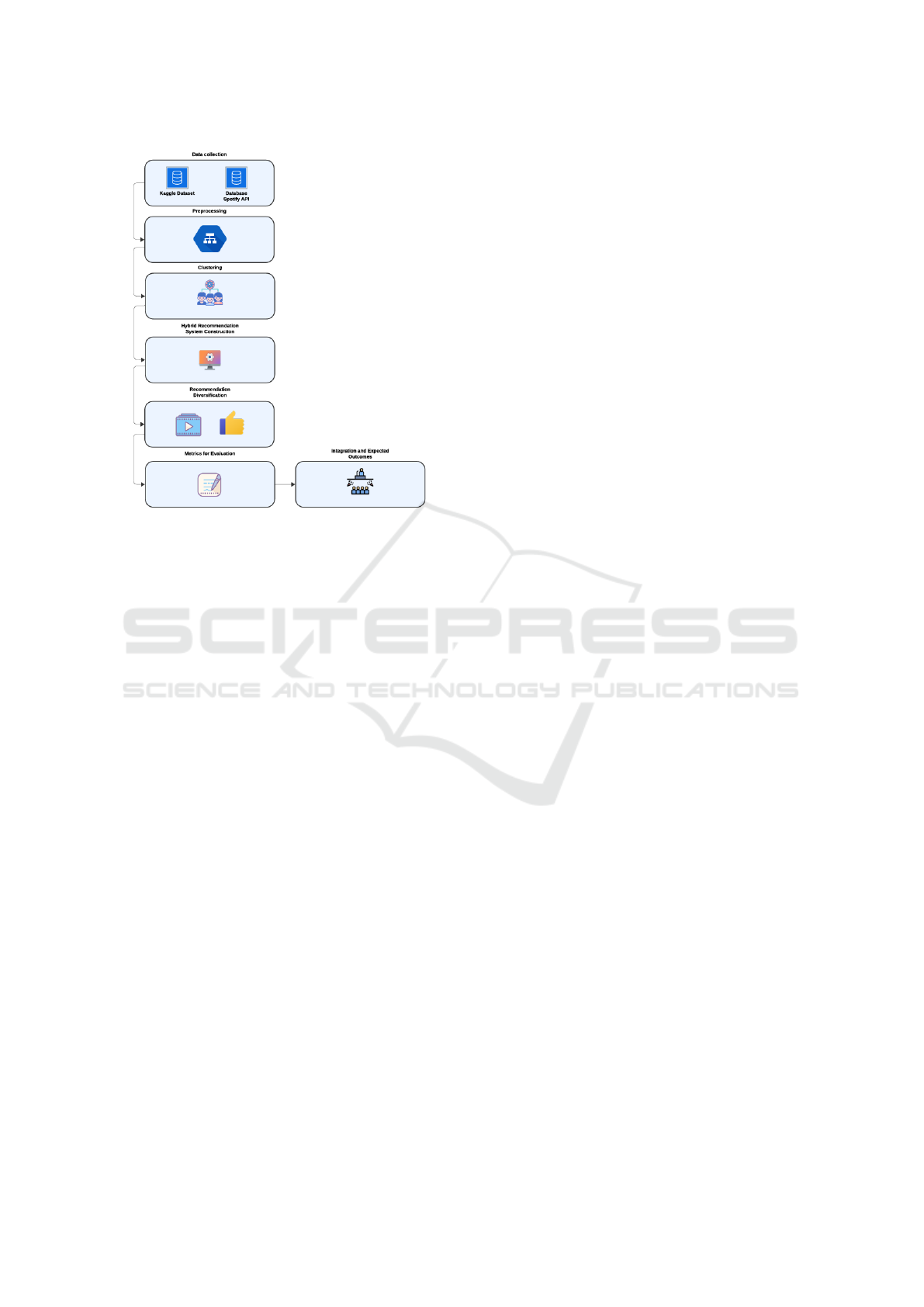
Figure 1: proposed method’s flowchart.
planation of the technological decisions underpinning
the approach.
Figure 1 shows the flow diagram of the proposed
method, outlining the sequential steps of the system
construction. Begins with data collection, leverag-
ing both Spotify API and Kaggle datasets to enrich
the available data. This is followed by preprocessing,
which involves normalization and feature selection to
prepare the data for analysis. The clustering phase
organizes the data into meaningful groups using tech-
niques like K-Means, forming the foundation for the
next step.
3.1 Data Collection
The data used in this study were collected from the
Spotify API, which provides detailed information on
various musical attributes such as danceability, en-
ergy, valence, tempo, acousticness, liveness, loud-
ness, instrumentalness, speechiness, mode, key, du-
ration ms, time signature, and popularity. These at-
tributes were selected because they comprehensively
capture both the emotional and technical aspects of
music, such as how users perceive energy and valence
or respond to tempo and acousticness. By leverag-
ing these diverse features, the system is designed to
model user preferences more effectively and deliver
personalized music recommendations. To enhance
the richness of the dataset, additional information was
gathered from publicly available sources on Kaggle
(Pandya, 2024) .
This dataset includes tracks and user interaction
data not present in the Spotify API, allowing for a
broader representation of user preferences and musi-
cal diversity. The integration of external data ensures
that the system captures a wider spectrum of musical
genres and styles, improving the generalizability of
the recommendations.
3.2 Preprocessing
For preprocessing (Patro and Sahu, 2015) , normal-
ization (Huang et al., 2020) was performed using the
standard scaler (Aldi et al., 2023) . This step ensures
that all features are adjusted to a standard scale with
a mean of zero and a standard deviation of one. This
is particularly important for algorithms like K-Means,
which rely on distance-based measures and can be af-
fected by differences in the range of input features.
Additionally, feature selection was applied to reduce
the dimensionality of the data(Borges, nd) , retaining
only the most relevant information. This not only im-
proves computational efficiency but also enhances the
quality of the data used in the recommendation sys-
tem, aligning with best practices in machine learning.
3.3 Clustering
The clustering process utilized the K-Means algo-
rithm, chosen for its simplicity and efficiency in
smaller-scale datasets. However, K-Means is known
to face challenges when applied to large-scale data
due to the computational complexity involved in dis-
tance calculations. Despite these limitations, the algo-
rithm effectively groups songs into clusters by min-
imizing the variance within each cluster, creating
groups of songs with similar characteristics. These
clusters serve as a foundational step for generating
personalized recommendations.
3.4 Hybrid Recommendation System
Construction
The recommendation system combines both super-
vised and unsupervised learning methods to enhance
the relevance and diversity of its recommendations.
The supervised component involves the use of a Mul-
tilayer Perceptron (MLP) neural network. This model
was trained to predict the cluster to which a song most
likely belongs based on its features. The inclusion of
the MLP was essential to address potential shortcom-
ings of using K-Means alone on an extensive dataset,
such as its limitations in handling large-scale data and
its reliance on linear separability. By leveraging the
MLP’s ability to learn complex, nonlinear relation-
ships and adapt dynamically to new data, the system
A Hybrid Music Recommendation System Based on K-Means Clustering and Multilayer Perceptron
337

ensures improved accuracy and robustness in generat-
ing personalized recommendations.
3.5 Recommendation Diversification
Diversification is a key aspect of the proposed sys-
tem, aimed at enhancing the user experience by re-
ducing repetitive suggestions and promoting variety
in the recommendations. This concept has been ex-
plored extensively in the field of recommender sys-
tems, with various state-of-the-art methods designed
to balance relevance and diversity. Examples include
Determinantal Point Processes (DPP), which prob-
abilistically select diverse sets of items, and Max-
imal Marginal Relevance (MMR), which iteratively
reduces redundancy by balancing relevance and nov-
elty. Topic-based diversification methods are also
commonly used, ensuring that recommended items
span multiple categories or themes.
In the proposed system, diversification is achieved
through two complementary mechanisms. The first
mechanism, cluster expansion, identifies songs from
neighboring clusters that are related but distinct from
the user’s primary profile. By incorporating these
songs into the recommendations, the system main-
tains relevance while introducing variety. This ap-
proach encourages users to explore new music, align-
ing with findings in the literature that suggest un-
expected but relevant recommendations can enhance
user satisfaction and engagement.
The second mechanism, genre repetition penalty,
addresses the issue of over representation of songs
from a single genre. By applying a penalty to recom-
mendations that disproportionately feature one genre,
the system promotes a more balanced playlist. This
encourages users to explore a broader range of musi-
cal styles, which has been shown to improve satisfac-
tion and long-term retention. Together, these mech-
anisms create a system that balances familiarity with
novelty, catering to users’ evolving tastes and prefer-
ences.
3.6 Metrics for Evaluation
The effectiveness of the proposed system is evaluated
using a combination of clustering and recommenda-
tion metrics. For clustering, the silhouette score is
used to assess the quality of the clusters by measur-
ing how well each song fits within its assigned clus-
ter compared to others. Higher silhouette scores in-
dicate better-defined clusters. In addition, inertia is
calculated to evaluate the compactness of the clusters,
with lower inertia values reflecting tighter groupings.
These metrics provide a clear indication of the clus-
tering performance.
For the recommendation component, precision
measures the proportion of relevant songs among the
top K recommendations, while recall evaluates the
system’s ability to retrieve relevant songs from the to-
tal relevant set. These metrics ensure that the recom-
mendations are both accurate and comprehensive. A
diversity index is also applied to quantify the variety
of the recommendations, with higher scores indicat-
ing greater diversity. For the supervised learning com-
ponent, the root mean square error evaluates the pre-
diction accuracy of the Multilayer Perceptron model,
while the F1-score provides a balanced measure of
precision and recall. These metrics collectively en-
sure a thorough evaluation of the system’s perfor-
mance, focusing on precision, diversity, and user sat-
isfaction (Dehak et al., nd) .
3.7 Integration and Expected Outcomes
The hybrid recommendation system integrates su-
pervised learning through the Multilayer Perceptron
model and unsupervised learning via K-Means clus-
tering to achieve a balance between personalization
and exploration. The supervised component facili-
tates recommendations that closely align with user
preferences, while the unsupervised component en-
courages the discovery of new content through clus-
ter analysis. By incorporating diversification mech-
anisms and evaluating the system with well-defined
metrics, the approach demonstrates potential as a vi-
able strategy to address the challenges of modern mu-
sic recommendation systems. This combination of
methods provides a foundation for creating recom-
mendations that are both relevant and varied, address-
ing user needs in a flexible and scalable manner.
Figure 1 illustrates the proposed method’s
flowchart, outlining the sequential steps of the sys-
tem’s construction. It begins with data collection,
leveraging both Spotify API and Kaggle datasets to
enrich the available data. This is followed by pre-
processing, which involves normalization and feature
selection to prepare the data for analysis. The cluster-
ing phase organizes the data into meaningful groups
using techniques like K-Means and PCA, forming the
foundation for the next step.
The hybrid recommendation system construction
integrates clustering results with supervised mod-
els to enhance recommendation accuracy and rele-
vance. Next, recommendation diversification mech-
anisms ensure a balance between variety and person-
alization. Finally, metrics for evaluation and integra-
tion provide quantitative feedback and insights into
the outcomes, guiding further refinements.
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
338
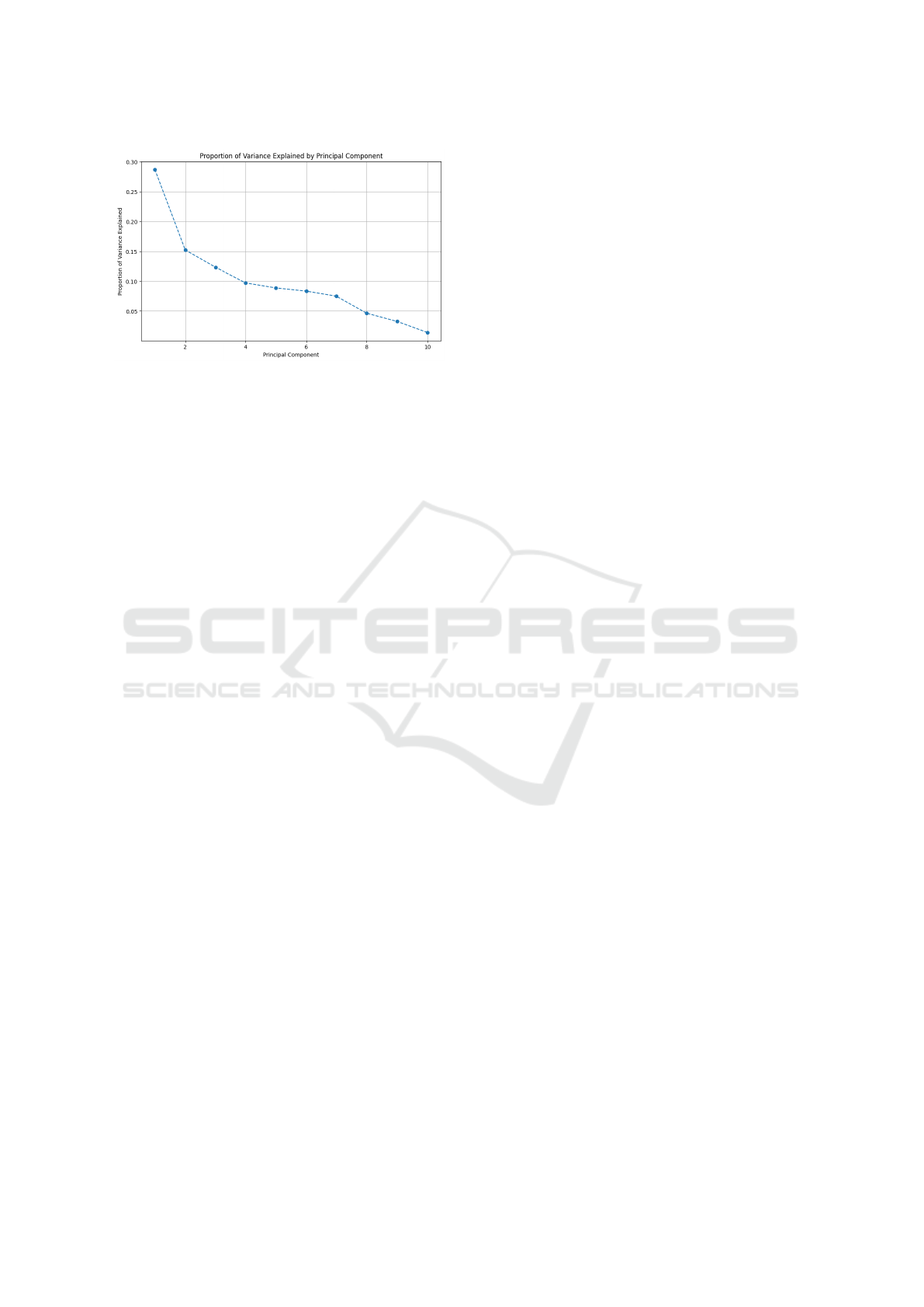
Figure 2: Elbow Method
In the following section, we will detail the experi-
mental setup, discussing the datasets, evaluation met-
rics, and methodologies employed to validate the sys-
tem’s effectiveness.
4 EXPERIMENTS
The Experimental HE Section offers a thorough ex-
amination of the experimental setup and findings from
evaluating the proposed hybrid music recommenda-
tion system. It covers the computational environment
configuration, datasets, pre-processing steps, and em-
ployed methods. Additionally, it details the evalu-
ation metrics, presents results in tables and graphs,
and analyzes computational complexity. This section
aims to highlight the ensemble approach’s effective-
ness and efficiency in improving recommendation ac-
curacy.
4.1 Experimental Environment
Configuration
The recommendation system implemented a hybrid
approach, combining K-Means for initial data seg-
mentation with a Multi-Layer Perceptron neural net-
work to refine predictions and enhance accuracy. This
integration of techniques leverages the strengths of
both methods to optimize the recommendation pro-
cess.
4.1.1 Model and Method Settings
The K-Means algorithm was employed for initial data
segmentation, partitioning data into clusters by min-
imizing the sum of squared distances between points
and centroids. The n-clusters parameter was deter-
mined using the elbow analysis method (Cui, nd), en-
suring an evidence-based selection. Hyperparameters
were fine-tuned: k-means++ improved centroid se-
lection and convergence stability, while a predefined
threshold controlled termination to balance computa-
tional efficiency and clustering precision.
Figure 2 represents the Elbow Method applied to
K-Means clustering, where inertia, defined as the sum
of squared distances between points and their cen-
troids, decreases as the number of clusters increases.
The ”elbow” point, where the rate of decline signifi-
cantly slows, indicates the optimal number of clusters.
This method (Cui, nd) determined that four clusters
were the most suitable choice, balancing model com-
plexity and variance explanation.
For similarity computation, the allMiniLM-L6-v2
Transformer-based model was used, generating high-
dimensional vector representations of song metadata
and user preferences. Cosine similarity measured
song relevance, forming the foundation for personal-
ized recommendations.
The MLP model was structured for performance
efficiency, aligning input features with segmented
data to capture intra-cluster relationships. ReLU acti-
vation improved nonlinearity (Nair & Hinton, 2010),
while softmax in the output layer ensured probabilis-
tic classification. The Adam optimizer was elected
for its adaptive learning rate, improving convergence
stability. Categorical cross-entropy measured diver-
gence between predicted and true distributions. These
optimizations ensured a scalable and effective recom-
mendation system.
4.1.2 Metrics of Models Evaluation
Model performance was assessed using three key
metrics: accuracy, categorical cross-entropy loss, and
inertia.
For classification, accuracy measured the propor-
tion of correctly classified instances, while categorical
cross-entropy loss quantified the difference between
predicted and actual probability distributions, guiding
the Adam optimizer in refining model weights. F1
score, which combines precision (proportion of rele-
vant recommendations) and recall (ability to retrieve
all relevant songs), was particularly useful for imbal-
anced datasets.
For clustering, inertia measured the sum of
squared distances between data points and their cen-
troids, ensuring compact clusters. The gap statistic
validated segmentation quality by comparing cluster
dispersion to a random distribution. The silhouette
score further assessed clustering quality, with higher
values indicating well-defined, cohesive groups.
To enhance recommendation accuracy, similarity
measures such as cosine similarity and Euclidean dis-
tance (Song et al., 2012) were applied to track meta-
data. The allMiniLM-L6-v2 model (Bagal et al., nd)
A Hybrid Music Recommendation System Based on K-Means Clustering and Multilayer Perceptron
339
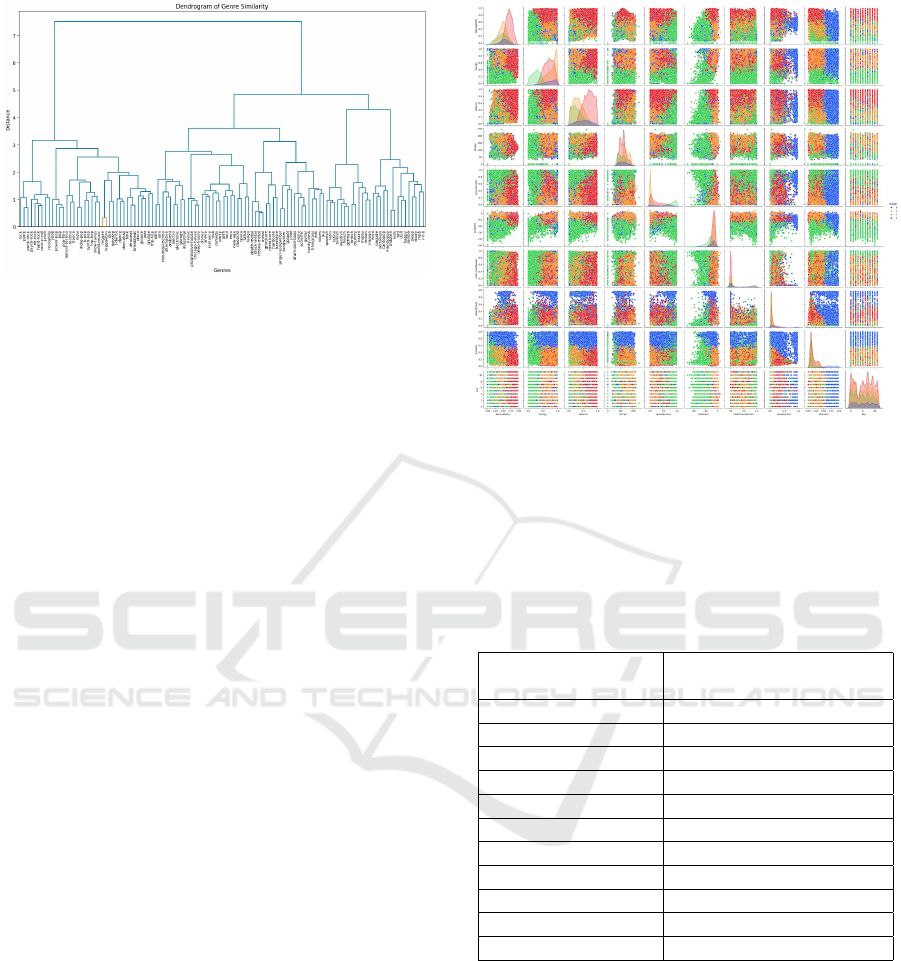
Figure 3: Dendogram of Similarity Matrix.
transformed metadata into dense vector embeddings,
forming the basis for precise recommendations. Fig-
ure 3 presents a similarity matrix (Department of
Computer Science and Engineering, The Maharaja
Sayajirao University of Baroda, India, 2019), visually
representing genre relationships based on embedding-
generated scores.
These metrics collectively provided a comprehen-
sive evaluation framework, balancing clustering ef-
fectiveness and recommendation accuracy to refine
the hybrid system.
4.2 Complexity Analysis
The complexity analysis of the hybrid model, inte-
grating K-Means clustering and MLP classification,
highlights its computational efficiency. While K-
Means required more processing time due to its itera-
tive centroid recalculations, it played a crucial role in
structuring the dataset, streamlining the MLP classifi-
cation phase.
The MLP model achieved rapid training times of
19 milliseconds per epoch, benefiting from reduced
input complexity due to pre-clustered data. This effi-
ciency resulted from its lightweight architecture and
optimized configuration, enabling fast and effective
learning.
Despite K-Means being computationally demand-
ing, its contribution to organizing data into meaning-
ful clusters significantly enhanced MLP performance.
This balance between clustering complexity and clas-
sification speed showcases the hybrid system’s ability
to efficiently handle large datasets while ensuring ac-
curate music recommendations.
5 RESULTS
This section presents the results of the hybrid music
recommendation system, evaluating its performance
Figure 4: Pairplot of clusters.
and prediction quality. Metrics such as accuracy, clus-
tering effectiveness, and similarity scores assess the
system’s ability to provide relevant recommendations.
Visualizations and comparisons illustrate the contri-
butions of K-Means, MLP, and the similarity matrix
in improving recommendation quality.
Table 2: Comparison of Features.
Feature Average Rate of Change
Between Features
Danceability 0.115
Energy 0.070
Valence 0.222
Time 28.635
Acousticness 0.052
Loudness 0.938
Instrumentalness 0.183
Speechiness 0.084
Liveness 0.140
Key 1.042
Total Media 3.148
A table summarizes the average rate of change
across musical features. Acousticness (0.052) and
energy (0.070) exhibit the lowest variations, indicat-
ing stable characteristics across tracks, which helps
maintain smooth playlist transitions. Conversely, time
(28.635) and key (1.042) show the highest variation,
reflecting diversity in track duration and tonal struc-
ture. These findings highlight the system’s ability to
balance cohesion and diversity.
The study developed a recommendation model
that ensures personalized playlists with high coher-
ence between genres. Cosine similarity measured the
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
340
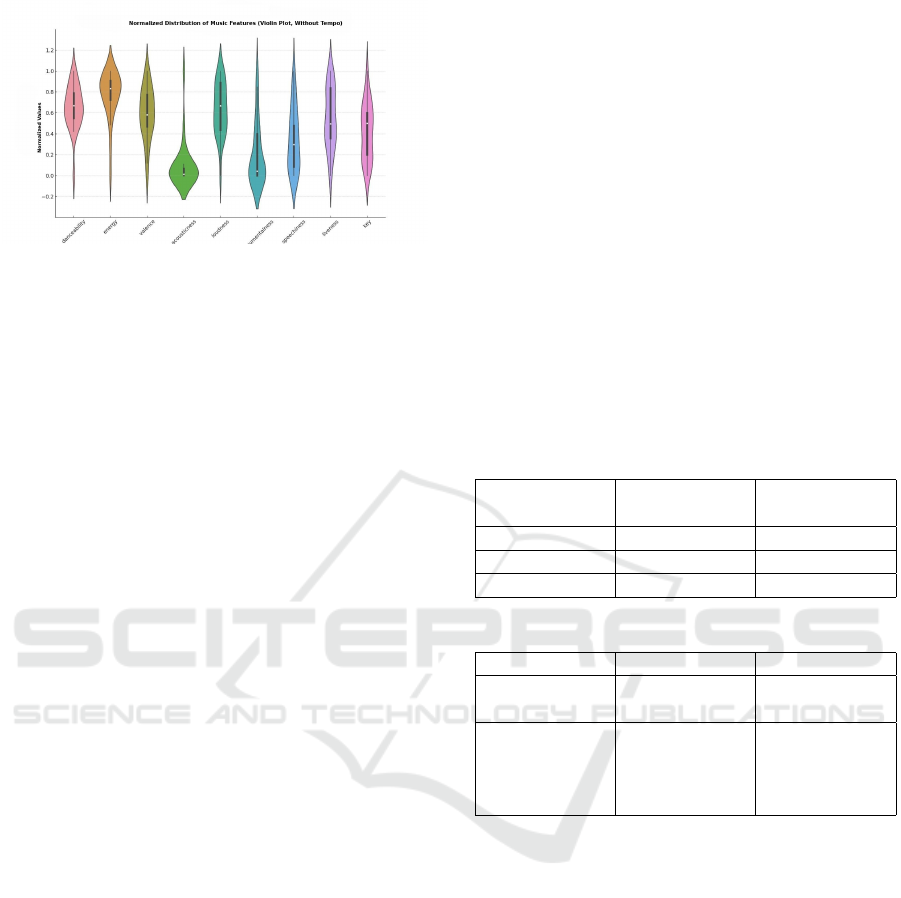
Figure 5: Violin plot of clusters.
proximity of recommended tracks, both in sequence
and in relation to the initial song. Variation anal-
ysis showed minimal differences between consecu-
tive tracks (0.0000414) and the initial song (0.00044),
ensuring smooth transitions and a consistent musical
narrative.
Further analysis of danceability, energy, tempo,
and valence confirmed well-controlled variability,
with tempo and key exhibiting the highest fluctua-
tions. Boxplot visualizations demonstrated an aver-
age feature variation of 3.148, validating the model’s
ability to balance diversity while maintaining align-
ment with the initial track.
A key finding from the repetition rate analysis
showed that in extensive playlists (2000 songs), pre-
viously known tracks appeared at a rate of 1.10%, re-
inforcing the system’s exploration mode, similar to
Spotify’s recommendation feature. This ensures new
recommendations while preserving structural similar-
ity to user preferences, minimizing excessive repeti-
tion. The model effectively balances coherence and
diversity, making it well-suited for music discovery
applications.
Figure 4 presents a pairplot visualization, illus-
trating feature relationships across clusters. It high-
lights clear separations in features like danceability
and energy, while valence and acousticness exhibit
more overlap, providing insights into clustering com-
plexity. Figure 5, a violin plot, visualizes the normal-
ized distributions of key musical features (excluding
tempo). It integrates density with a box plot summary,
showing that energy and loudness have tighter dis-
tributions, while instrumentalness and acousticness
display greater variation, reflecting musical diversity.
These visualizations offer a deeper understanding of
the dataset’s acoustic and musical properties.
6 CONCLUSIONS
This study introduced and evaluated a hybrid music
recommendation system integrating K-Means cluster-
ing and an MLP neural network, successfully generat-
ing personalized playlists that balanced genre coher-
ence and track diversity. Evaluations using accuracy,
silhouette score, and similarity metrics confirmed the
system’s robustness, enabling smooth transitions be-
tween tracks while maintaining low repetition (1.10%
overlap in 2000 recommendations), making it ideal
for music exploration applications like Spotify’s “Dis-
cover” feature.
A comparative analysis with Yoshii et al.’s hy-
brid system contextualized these results, with Table
3 highlighting key recommendation accuracy metrics.
The system’s ability to seamlessly transition between
genres while preserving consistency was reinforced
by correlation matrices (all-MiniLM-L6-v2) and co-
sine similarity, validating the relevance of recommen-
dations and demonstrating the effectiveness of hybrid
models in personalization.
Table 3: Recommendation Accuracy.
Ranking (x) Our Method
(Percent)
Yoshii et al.
(Percent)
Top 1 99.99% 93.5%
Top 3 99.95% 86.4%
Top 10 99.38% 80.7%
Table 4: Recommendation Diversity/Overlap.
Metric Our Method Yoshii et al.
Overlap with
user dataset
1.10% Not Reported
Diversity in
artist/genres
High (Consis-
tency with
Genre Prox-
imity Matrix)
High (Based
on
Collaborative
Filtering)
Future improvements include expanding the
dataset to incorporate diverse genres, languages, and
user demographics for better generalization. Integrat-
ing user feedback loops (e.g., ratings, skip behavior)
could improve adaptability, while transformers and
graph neural networks could enhance track-user rela-
tionship modeling. Context-aware recommendations
(e.g., mood, time, location) would create more dy-
namic playlists, and multi-session recommendations
would allow the system to evolve with user prefer-
ences.
Despite its success, limitations remain. K-Means
clustering exhibited longer training times, affecting
scalability, which could be improved through opti-
mized clustering techniques or alternative unsuper-
vised learning methods. Additionally, reliance on
predefined audio features may limit adaptability to
emerging trends, such as non-Western music styles or
genre mashups.
A Hybrid Music Recommendation System Based on K-Means Clustering and Multilayer Perceptron
341

A key constraint is the focus on single-session
recommendations, whereas real-world users interact
with music over time. Temporal models would be
necessary to track evolving preferences, and collab-
orative filtering could enhance recommendations by
incorporating community-driven insights. Address-
ing these challenges would improve scalability, ro-
bustness, and user satisfaction.
Despite these limitations, this study represents a
significant step forward in hybrid music recommen-
dation systems, effectively balancing personalization
and diversity while maintaining computational effi-
ciency. These findings establish a foundation for fu-
ture research, enabling more adaptive and enriched
user experiences in music recommendation.
ACKNOWLEDGEMENTS
This paper was financed in part by the Coordenac¸
˜
ao
de Aperfeic¸oamento de Pessoal de N
´
ıvel Superior -
Brazil (CAPES) - Finance Code 001, Fundac¸
˜
ao de
Amparo a Ci
ˆ
encia e Tecnologia do Estado de Pernam-
buco (FACEPE), the Conselho Nacional de Desen-
volvimento Cient
´
ıfico e Tecnol
´
ogico (CNPq) - Brazil-
ian research agencies.
REFERENCES
Aldi, F., Hadi, F., Rahmi, N. A., and Defit, S. (2023). Stan-
dardscaler’s potential in enhancing breast cancer accu-
racy using machine learning. JAETS, 5(1):401–413.
Bagal, V., Aggarwal, R., Vinod, P. K., and Priyakumar,
U. D. (n.d.). Liggpt: Molecular generation using a
transformer-decoder model.
Borges, H. B. (n.d.). Reduc¸
˜
ao de dimensionalidade em
bases de dados de express
˜
ao g
ˆ
enica. Technical report
or unpublished work.
Cui, M. (n.d.). Introduction to the k-means clustering algo-
rithm based on the elbow method.
Defferrard, M., Benzi, K., Vandergheynst, P., and Bresson,
X. (2017). Fma: A dataset for music analysis. arXiv.
Dehak, N., Dehak, R., Glass, J., Reynolds, D., and Kenny,
P. (n.d.). Cosine similarity scoring without score nor-
malization techniques.
Department of Computer Science and Engineering, The
Maharaja Sayajirao University of Baroda, India
(2019). Research advances in computer science and
engineering. International Journal of Computer Sci-
ence. et al.
Domingues, M. A., Trevisani, P. L., Duarte, F. M. N., and
Cunha, A. M. (2012). Combining usage and content
in an online music recommendation system for mu-
sic in the long-tail. In Proceedings of the 21st Inter-
national Conference on World Wide Web, pages 925–
930, Lyon, France. ACM.
Godinho, A. and Vasconcelos, F. (n.d.). Recomendac¸
˜
ao mu-
sical para grupos baseada em modelo h
´
ıbrido.
Goto, M. (n.d.). Rwc music database: Music genre database
and musical instrument sound database.
Hartigan, J. A. and Wong, M. A. (1979). Algorithm as 136:
A k-means clustering algorithm. Applied Statistics,
28(1):100.
Huang, L., Qin, J., Zhou, Y., Zhu, F., Liu, L., and Shao,
L. (2020). Normalization techniques in training dnns:
Methodology, analysis and application. arXiv.
Pandya, M. (2024). Spotify tracks dataset. Accessed on
December 8, 2024.
Patro, S. G. K. and Sahu, K. K. (2015). Normalization:
A preprocessing stage. International Advanced Re-
search Journal in Science, Engineering and Technol-
ogy, 2(3):20–22.
Pola, G., Bujorianu, M. L., Lygeros, J., and Di Benedetto,
M. D. (2003). Stochastic hybrid models: An overview.
IFAC Proceedings Volumes, 36(6):45–50.
Roberts, A., Brooks, R., and Shipway, P. (2014). Internal
combustion engine cold-start efficiency: A review of
the problem, causes and potential solutions. Energy
Conversion and Management, 82:327–350.
Sharma, L. and Gera, A. (2013). A survey of recommenda-
tion system: Research challenges. International Jour-
nal of Engineering Trends and Technology.
Song, Y., Dixon, S., and Pearce, M. (2012). A survey of mu-
sic recommendation systems and future perspectives.
In Proceedings of the International Society for Mu-
sic Information Retrieval Conference (ISMIR), pages
395–400.
Vogels, T. P., Rajan, K., and Abbott, L. F. (2005). Neural
network dynamics. Annual Review of Neuroscience,
28(1):357–376.
Wu, L., Wang, J., Xie, Y., and He, X. (2024). A survey on
large language models for recommendation. arXiv.
Yoshii, K., Goto, M., Komatani, K., Ogata, T., and Okuno,
H. G. (2008). An efficient hybrid music recommender
system using an incrementally trainable probabilis-
tic generative model. IEEE Transactions on Audio,
Speech, and Language Processing, 16(2):435–447.
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
342
