
A Multivocal Mapping Study on Artifact Traceability Complexities in
Practice
Zaki Pauzi
a
and Andrea Capiluppi
b
University of Groningen, The Netherlands
Keywords:
Software Traceability, Multivocal Mapping Study, Evidence-Based Software Engineering.
Abstract:
Artifact traceability is essential for managing the relationships between artifacts produced during the soft-
ware development lifecycle, yet achieving effective traceability in practice remains a complex challenge. This
study explores the multifaceted nature of traceability in real-world settings, providing actionable insights for
researchers, practitioners, and tool developers aiming to enhance traceability practices, improve software qual-
ity, and support project success. Drawing from 56 academic papers and 15 grey literature sources, this study
synthesises findings from scholarly research, industry reports, practitioner experiences, and expert opinions.
Key challenges include the lack of standardised processes and tools, difficulties in maintaining traceability
over time, balancing automation with human involvement, and fostering effective stakeholder communication
and collaboration. Two critical open challenges emerge: achieving semantic interoperability and managing
scalability in complex systems. To address these, we recommend targeted efforts towards standardisation and
the development of incremental, adaptive techniques for traceability management.
1 INTRODUCTION
Multivocal mapping studies (MMSs) in software en-
gineering research offer a unique approach to syn-
thesising diverse perspectives and insights on com-
plex topics within the software engineering field. Un-
like traditional systematic mapping studies that fo-
cus primarily on academic sources, MMSs incorpo-
rate a wide range of voices, including academic liter-
ature, industry reports, practitioner experiences, and
expert interviews (Garousi et al., 2016; Neto et al.,
2019). This was particularly chosen given that syn-
thesising the data including sources from grey lit-
erature (e.g., white papers, technical documentation,
blog posts) (Lefebvre et al., 2008) has immense value
as they provide timely, context-specific, and diverse
insights that complement academic research. This
supports evidence-based decision-making in industry
settings, given that our scope is focused on “in prac-
tice” (Garousi et al., 2016; Garousi et al., 2019) – we
are focused on experiences and reports. As we look
into the complexities of artifact traceability in prac-
tice, we considered sources outside of academic liter-
ature, albeit through a systematic process of scoping
a
https://orcid.org/0000-0003-4032-4766
b
https://orcid.org/0000-0001-9469-6050
with inclusion/exclusion criteria to reflect high qual-
ity data that is in scope for our study. Solely focus-
ing on scientific research will miss out on alternative
perspectives and diverse voices from industry practi-
tioners, consultants, and tool vendors. These are not
typically published in academic settings.
The following research questions were outlined
based on existing research and artifact traceability in
practice, and will be assessed as part of the MMS:
RQ1: What are the demographics of reviewed lit-
erature?
Rationale: This information gives us an overview of
the metadata of our sources. This is particularly im-
portant to better understand the impact and quality of
our papers in scope.
RQ2: What are the reported key complexities in
artifact traceability in practice?
Rationale: Through collating these, we are able to
consolidate pain points and challenges. This allows
us to understand the perils and pitfalls of artifact
traceability in practice, so we can benefit researchers
and practitioners alike in identifying these.
RQ3: What are the pertaining existing chal-
lenges?
Rationale: From the key complexities identified, we
collate the themes and denote these as pertaining
(open) challenges. This provides a collection of areas
754
Pauzi, Z. and Capiluppi, A.
A Multivocal Mapping Study on Artifact Traceability Complexities in Practice.
DOI: 10.5220/0013458400003928
In Proceedings of the 20th International Conference on Evaluation of Novel Approaches to Software Engineering (ENASE 2025), pages 754-761
ISBN: 978-989-758-742-9; ISSN: 2184-4895
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

to focus on for actionable insights to address them,
which are not in scope of this paper for now.
This paper aims to tackle these questions by con-
ducting a thoroughly focused, yet comprehensive,
multivocal mapping study. The scope of our study
specifically focuses on complexities and in practice –
relating to the difficulties of achieving traceability in
practice.
2 BACKGROUND
Artifact traceability in practice refers to the ability
to systematically document and track the relation-
ships and dependencies between various artifacts cre-
ated throughout the software development life cycle
(SDLC). These artifacts can include requirements, de-
sign documents, code modules, test cases, and more.
In practice, this involves establishing and maintaining
links between these artifacts to ensure that changes
made to one are reflected appropriately in others.
Secondary studies looking into traceability of soft-
ware artifacts are sporadic across different domains,
with varying directions and focus in terms of reported
findings and recommendations. For example, spe-
cific to requirements engineering (Tufail et al., 2017;
Wang et al., 2018; Lyu et al., 2023; Saleem and Min-
has, 2018) and focusing on machine learning applica-
tions (Pauzi and Capiluppi, 2023; Aung et al., 2020).
To the best of our knowledge, there is not yet a study
that includes grey literature to look into reported key
complexities in artifact traceability. Our contribution
to this area is much needed to formulate what needs to
be focused on to address the key challenges pertaining
artifact traceability in practice.
3 METHODOLOGY
For our MMS, we followed the published guide-
lines for conducting multivocal reviews by Garousi et
al. (Garousi et al., 2019), namely in the following:
1. Search strategy and source selection (including
study quality assessment)
2. Data extraction and synthesis
3. Report results (based on RQs)
Based on these steps, we present Figure 1, which
shows the overview of our MMS methodology.
3.1 Search Strategy and Planning
We extracted the content and metadata of each piece
of literature using a systematic approach and ap-
plied various tools to gather all publications necessary
within our scope. For the academic literature, multi-
ple library databases were used, such as ACM Dig-
ital Library and Scopus. For the grey literature, we
used the same search string as the academic library
database search, except a more manual approach had
to be done (further reported in this section). This
planning was done to ensure comprehensiveness in
the study; to address the research questions at hand.
Threats to the validity of our study strategy will be
discussed in Section 5.
3.2 Search String
Table 1 shows the terms relevant to our search and
their synonyms. These were derived to expand the
boundaries of semantic keywords that are relevant to
the research topics. We have separated the terms ac-
cording to the relevant theme it belongs to, and only
the most relevant synonyms (to our research ques-
tions) are shown in Table 1.
For any search strategy, the construction of the
string is necessary as is enables transparency for val-
idation and reproducibility. This search string is used
for library database searches (further explained in this
section) and used in web search engines for non-
academic sources. An effective search strategy is usu-
ally iterative and benefits from trial searches using
various combinations of search terms derived from
the research question(s) (Kitchenham and Charters,
2007).
3.2.1 Trial of Potential Candidate Terms
Synonym terms are then evaluated through a robust
process. Figure 2 shows the combination of terms that
were tested. We grouped the synonyms according to
common properties they share, denoted by the ovals.
Each of these groups are then evaluated on effective-
ness through trials and a decision is then made. Green
coloured groups were those chosen.
3.2.2 Decision and Final String Output
• Theme 1: (top-down order) Main term and types
of artifacts.
• Theme 2: (top-down order) Main term and off-
shoot terms.
• Theme 3: (top-down order) Main terms, types of
complexities.
• Theme 4: (top-down order) Main term, synonym
term (less common), synonym term (more com-
mon), parent term.
A Multivocal Mapping Study on Artifact Traceability Complexities in Practice
755
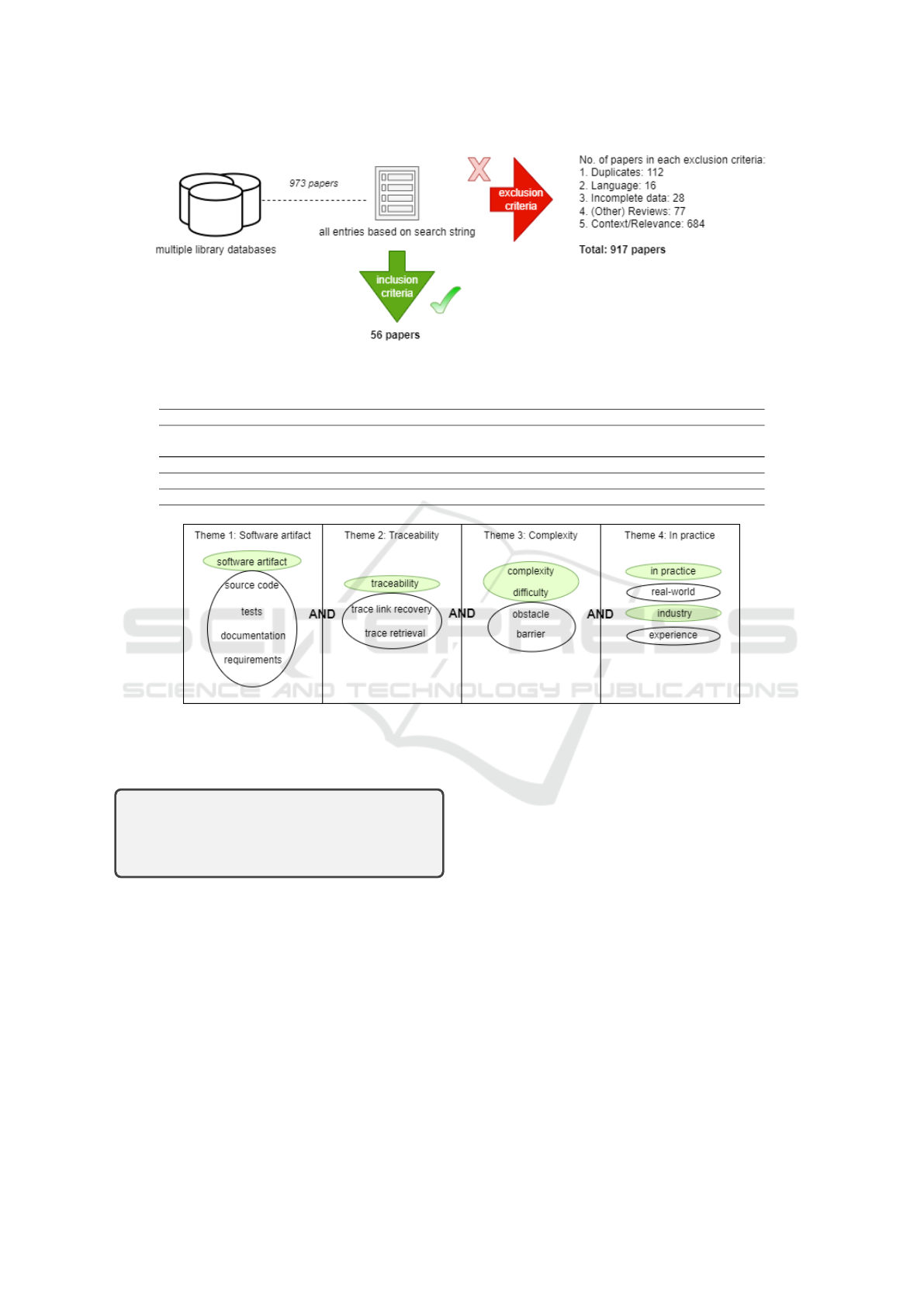
Figure 1: Filtering of academic literature based on selection process.
Table 1: Terms table.
Theme Term Synonyms
Software artifact software artifact source code, tests, documentation,
requirements
Traceability traceability trace link recovery, trace retrieval
Complexities complexity difficulty, obstacle, barrier
In practice in practice real-world, industry, experience
Figure 2: Grouped synonym terms: potential candidates for search string.
We specified the following search string (in order)
to extract all related publications within our scope:
(”software artifact” OR ”software artefact”) AND
(”traceability” OR ”trace link”) AND (”complex-
ity” OR ”difficulty”) AND (”in practice” OR ”in-
dustry”)
3.3 Source Selection – Inclusion and
Exclusion Criteria
To ensure our results are reflective of recent research,
we have imposed inclusion criteria in terms of pe-
riod scope: years 2014 to 2023 inclusive. Spanning
a period of a decade (ten years) in consideration, we
aim to fill in the gap of studies that predated our start
year and focus on more recent complexities of arti-
fact traceability in practice. For exclusion, we have
disregarded content that is unrelated to (software en-
gineering) traceability, such as other reviews and non-
complexities reported.
For the exclusion criteria, we used the following
filters to filter out the papers that are not within our
scope:
1. Duplicates: repeated entries
2. Language: non-English papers
3. Data: incomplete (missing) data
4. Reviews: other reviews, surveys, and mapping
studies
5. Context: irrelevance to our defined research topics
3.4 Data Extraction for Peer Reviewed
Literature
Table 2 shows the literature databases that were used
for our first step in data extraction. The aim was to
gather all relevant publications related to our study
topics by using the search string defined. The extrac-
ENASE 2025 - 20th International Conference on Evaluation of Novel Approaches to Software Engineering
756

tion was done either by exporting from the web page
(via manual extraction using the Web UI) or the API.
Table 2: Details of index databases used.
Database Extraction type Results
Scopus API 3
Google Scholar API 872
Springer Link Web UI 51
ACM Digital Library Web UI 35
IEEE Xplore Web UI 8
WorldCat Web UI 4
Total count 973
Google Scholar was first used to get the most re-
sults possible: despite the abundance of false pos-
itives, it has the potential to considerably extend
the outreach of the systematic search (Harzing and
van der Wal, 2008). What we observed was that
using Google Scholar was enough to capture more
than 95% of other results we obtained from the other
databases. Regardless, we expanded our search be-
yond the search engine to ensure the comprehensive-
ness of our search strategy.
After the cleaning step instrumented by the exclu-
sion criteria, we gathered a total of 56 papers held
by libraries worldwide. We have also ensured that all
these were peer-reviewed publications. These were
extracted, along with the metadata, and compiled into
a spreadsheet consisting of all the information and
content for each paper. The full list of all selected
papers in scope can be found online
1
.
3.5 Data Extraction for Grey Literature
Beyond academic literature, we also expanded our
search to official technical documentation, white pa-
pers, and case studies published by companies and
reputable institutions. We specifically chose these
outlets as our inclusion criteria for grey literature
(first tier literature), following the quality assessment
checklist for grey literature (Garousi et al., 2019).
However, we make an exception for blog posts (orig-
inally categorised as the lowest tier in the guidelines)
that are authored by the organisation themselves pub-
lishing about their products, as these sources do fulfil
the criteria for a Tier 1 source. Given that our scope is
targeted to “in practice”, we evaluated sources of re-
ports and conclude that only those published officially
will be included in our study – this is based on the cri-
teria of authority and outlet type, which complements
our academic sources.
On top of the inclusion and exclusion criteria
listed above, we added the following exclusion cri-
1
https://github.com/zakipauzi/enase-2025/blob/main/
papers.csv
teria for technical documentation and white papers:
1. Tool/platform does not present or mention trace-
ability.
2. Tool/platform does not support end-to-end trace-
ability.
3. Unofficial documentation (not authored by an of-
ficial affiliate or endorsed).
For case studies, the following exclusion criteria
were added:
1. Post/report not authored by official affiliate or en-
dorsed.
2. Case study does not address fully or part thereof
artifact traceability.
We ensured that these do not impede on our pur-
suit of comprehensive literature sourcing by including
grey literature sources, while simultaneously ensuring
high-quality reviewing by conforming to these crite-
ria. The complete list of grey literature in the scope of
our study is shown online
2
, due to space constraints.
4 RESULTS
4.1 RQ1: Demographics
As part of the impact and quality analysis, we look
into the sources and publishers of our academic liter-
ature. Our pie chart
3
shows the distribution of papers
selected in scope for our study. The majority of our
papers are from journals and conference proceedings.
We have also included students’ theses that have made
the selection criteria.
For citation count per year, we can see 3 out-
liers in our box plot
4
– these are top cited publi-
cations per year, corresponding to the papers (Guo
et al., 2017; Mahmoud and Niu, 2014; Abbas et al.,
2022b). Correction has been made on one of the pa-
pers recently (Abbas et al., 2022a). Despite the ci-
tation count to be, arguably, a weak indicator of re-
search quality for some (Aksnes et al., 2019), for the
purpose of our study, we consider citation count as a
factor in research impact, and we will analyse these
further in Section 5.
2
https://github.com/zakipauzi/enase-2025/blob/main/
gl source.csv
3
https://github.com/zakipauzi/enase-2025/blob/main/
rq1 pie.png
4
https://github.com/zakipauzi/enase-2025/blob/main/
rq1 box.png
A Multivocal Mapping Study on Artifact Traceability Complexities in Practice
757

4.2 RQ2: Key Complexities
Based on the academic literature in scope, we have
identified and grouped together four key complexities
to effective artifact traceability in practice. We chose
to only present the most common of them where each
of these have been present in the papers (for sim-
plification purposes). Although there are also cases
where papers cover more than one complexity, we
only present the main complexity that is the most rel-
evant for each paper. Due to space constraints, we
have uploaded the mappings between complexities to
the papers online
5
.
1. Lack of standardised processes and tools
2. Difficulty in maintaining traceability over time
3. Trade-offs between automation and human in-
volvement
4. The need for effective communication and collab-
oration among stakeholders
4.3 RQ3: Open Challenges
Based on the key complexities identified in the pre-
vious section, we have also uncovered the following
open challenges that organisations struggle with: se-
mantic interoperability and scalability in complexity.
Achieving consistent and meaningful links be-
tween artifacts across diverse tools and domains re-
mains a challenge due to differences in terminology,
evolving artifacts, and varied stakeholder perspec-
tives. Overcoming this challenge requires standardis-
ation efforts, integrated frameworks, and automation
techniques to ensure seamless communication and in-
terpretation of traceability information. Managing
traceability becomes increasingly difficult in large-
scale software projects due to the sheer volume of
artifacts, varying levels of granularity, and dynamic
nature of software development. To address this chal-
lenge, efficient storage and retrieval mechanisms, in-
tuitive visualisation tools, and adaptive traceability
techniques are needed to cope with the complexities
and scale of traceability information effectively.
5 DISCUSSION
In this section, we discuss the results of our MMS and
the threats to the validity of our study.
5
https://github.com/zakipauzi/enase-2025/blob/main/
mapping complexities.csv
5.1 RQ1: Demographics
As illustrated in our pie chart
6
, the distribution of
publication types reveals that the majority of selected
papers are sourced from journal articles and confer-
ence proceedings. This finding underscores the sig-
nificance of academic research in shaping our under-
standing of artifact traceability, with peer-reviewed
journals and conference venues serving as primary
outlets. Additionally, the inclusion of student theses
and grey literature meeting our selection criteria high-
lights the diverse range of sources considered in our
study, particularly as they report on case studies and
tools. The analysis of citation counts per year further
contributes to our understanding of the impact and in-
fluence of publications within the domain of artifact
traceability. It is notable that three outliers (Guo et al.,
2017; Mahmoud and Niu, 2014; Abbas et al., 2022b)
emerge as the top-cited publications per year. In all of
these papers, the authors employed machine learning
in the semantic representation of artifacts to automate
traceability.
5.2 RQ2: Key Complexities
The key issue of standardised processes and tools is
reported as one of the key hindrances to effective
artifact traceability in practice. Without established
guidelines and uniform methodologies, organisations
struggle to maintain consistency and synchrony in
traceability practices across different stages of the
software development life cycle (SDLC). The lack of
standardisation often results in ad-hoc approaches to
trace link creation, leading to inconsistencies, errors,
and inefficiencies in traceability management. Conse-
quently, stakeholders face difficulties in tracking and
managing trace links, impeding their ability to accu-
rately understand relationships between artifacts and
make informed decisions based on traceability infor-
mation.
The difficulty of maintaining traceability over
time commonly relates to the increasing complexi-
ties of ever-evolving artifacts and their dependencies.
Establishing trace links is commonly focused more
during the early stages of the life cycle, and in some
cases, visualisation tools are used to represent these
traces. The issue becomes compounded when these
traces are not maintained, and it becomes laborious
and difficult to ensure traceability is updated. Most
of the papers tagged to this issue propose tools and
solutions to address this difficulty, although the chal-
lenge that comes with this does not necessarily dis-
6
https://github.com/zakipauzi/enase-2025/blob/main/
rq1 pie.png
ENASE 2025 - 20th International Conference on Evaluation of Novel Approaches to Software Engineering
758

appear. What used to be a manual task, traceability
solutions using automated techniques with machine
learning have taken the limelight in recent publica-
tions. The key issue with this, however, is the compro-
mise between automation and human involvement.
The distribution of papers relevant to each iden-
tified issue is fairly equal with the exception of the
fourth key issue: The need for effective communica-
tion and collaboration among stakeholders, which is
also the main reported issue for all the grey litera-
ture in our scope. We have also observed that there
are multiple instances where these issues overlap and
lead to one another.
In answering RQ2, we had to cherry-pick the key
complexities surrounding artifact traceability in prac-
tice, which is typically not the main focus of these
papers, and sometimes can be obscured in the text.
Nonetheless, these four that were identified enabled
us to map to and derive existing open challenges that
were considered to be persisting in practice. Figure 3
shows the mapping of these links.
5.3 RQ3: Open Challenges
5.3.1 Semantic Interoperability
In the context of artifact traceability, achieving
semantic interoperability involves establishing and
maintaining meaningful links between artifacts across
various tools, platforms, and domains involved in
the software development process. One of the key
complexities contributing to the challenge of seman-
tic interoperability is the heterogeneity of tools and
data models used in software development. Differ-
ent teams and organisations often employ a variety of
tools for requirements management, version control,
issue tracking, and testing, each with its own termi-
nology and data structures. This diversity makes it
challenging to establish meaningful connections be-
tween artifacts, as the same concept may be repre-
sented differently across different tools.
To address the challenge of semantic interoper-
ability, efforts are needed in several areas, such as the
following:
• Standardisation: Developing standardised ontolo-
gies, vocabularies, and data models that can be
shared and reused across tools and domains to fa-
cilitate consistent interpretation and exchange of
traceability information.
• Integration and Middleware: Building integra-
tion frameworks or middleware layers that enable
seamless communication and data exchange be-
tween heterogeneous tools and systems, abstract-
ing away the underlying differences in data for-
mats and structures.
• Automation and Machine Learning: Leveraging
automation techniques, such as natural language
processing (NLP) and machine learning, to au-
tomatically infer and maintain traceability links
based on textual, structural, and semantic sim-
ilarities between artifacts (Pauzi and Capiluppi,
2023).
5.3.2 Scalability in Complexity
Scaling with complexities is not unique to artifact
traceability, yet it remains as an open challenge that
organisations have to handle daily. The sheer vol-
ume and dynamic nature of traceability information
in large-scale software projects is a major contribut-
ing factor. As software systems grow in size and
complexity, the number of artifacts, relationships be-
tween artifacts, and traceability links increases, pos-
ing significant challenges in managing, querying, and
visualising traceability information effectively. More-
over, traceability information may need to be cap-
tured at various levels of granularity, from high-level
requirements to low-level code elements. Managing
traceability at different levels of abstraction and detail
while preserving meaningful relationships between
artifacts adds to the complexity of traceability man-
agement. This is also compounded with continuous
changes, updates, and revisions throughout the devel-
opment life cycle. To address scalability in complex-
ity, we recommend innovative approaches and tech-
nologies that can do the following:
• Visualisation and Exploration: Develop intuitive
visualisation techniques and exploration tools that
enable stakeholders to navigate and analyse com-
plex traceability networks, identify dependencies,
and gain insights into the relationships between
artifacts.
• Incremental and Adaptive Techniques: As trace-
ability is ever evolving, so does the need for main-
taining and managing the links. By focusing on
techniques and tools that allow incremental and
adaptive methods to manage traceability, we re-
duce the burden of tracing complexities as they
evolve real-time. Smaller and more frequent trace
link recoveries are much simpler to handle and
maintain overtime.
At the backdrop of these challenges that were
identified, there is some overlap with the grand chal-
lenge in traceability that was published more than a
decade ago: making traceability ubiquitous in soft-
ware and systems (Gotel et al., 2012).
A Multivocal Mapping Study on Artifact Traceability Complexities in Practice
759
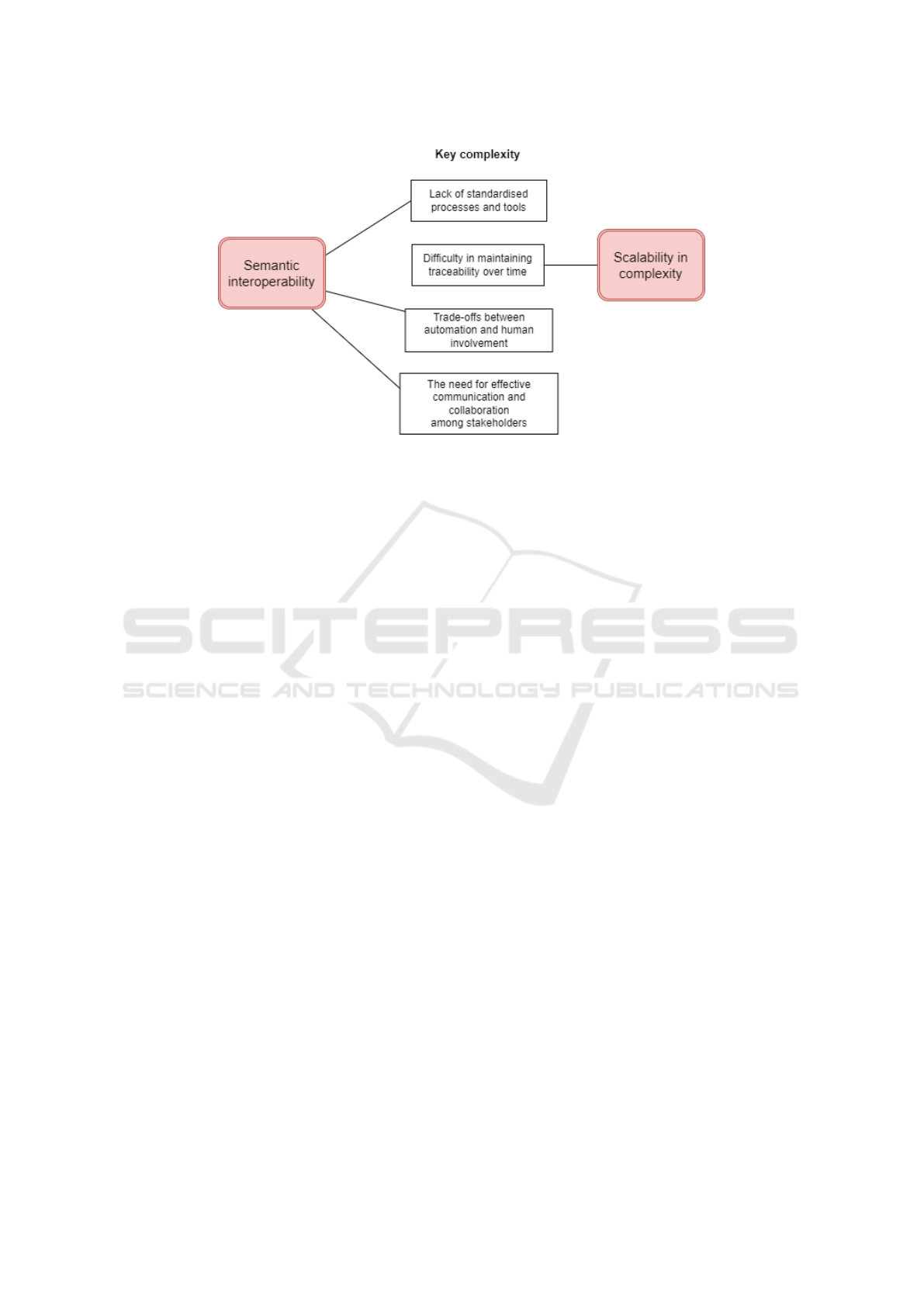
Figure 3: Mapping of key complexities to open challenges.
5.4 Threats to Validity of MMS
In this section, we outline the threats to validity iden-
tified throughout our mapping study process. Based
on a recent map of threats to validity in systematic lit-
erature reviews in software engineering (Zhou et al.,
2016), we looked into all possible similar threats that
would emerge from conducting our MMS. The fol-
lowing are some key threats identified:
Construct validity – The chosen inclusion and ex-
clusion criteria for evaluating literature may not ac-
curately capture the nuances of complexities in arti-
fact traceability in practice, leading to biased results.
This is particularly true for published reports and case
studies, given that the majority of published articles
are biased towards successes and improvements. Re-
gardless, we focused heavily on these challenges that
may not be explicit in the literature; this is done with
a thorough analysis and synthesis of available infor-
mation.
Internal validity – The literature selected for our
study may not be representative of the entire body of
research on artifact traceability complexities, poten-
tially skewing the conclusions drawn from the avail-
able evidence. By introducing grey literature, we ex-
pand the search scope to beyond academic literature,
which is necessary given that our focus is “in prac-
tice”.
External validity – The papers in scope of our
MMS may not be representative of the broader pop-
ulation, limiting the generalisability of the findings.
Comprehensiveness of search is pivotal to address this
threat, and this is why we used a search aggregate en-
gine for literature that indexes multiple databases. Al-
though more work is needed to be done to remove the
false positives, we wanted to ensure that our findings
can be generalisable.
6 CONCLUSION
In this paper, we conducted a multivocal mapping
study (MMS) to explore the complexities of artifact
traceability in software engineering practice. Our
study addressed three key research questions: (1) the
demographics of reviewed literature, (2) reported key
complexities in artifact traceability, and (3) existing
challenges pertaining to traceability.
Regarding the demographics of the reviewed lit-
erature, our analysis revealed that the majority of se-
lected papers are from journal articles and conference
proceedings, with a notable inclusion of student the-
ses meeting our selection criteria. Furthermore, an
examination of citation counts per year highlighted
several top-cited publications. In terms of key com-
plexities, our study identified several common chal-
lenges faced in achieving effective artifact traceabil-
ity in practice. These include the lack of standardised
processes and tools, difficulties in maintaining trace-
ability over time, trade-offs between automation and
human involvement, and the importance of effective
communication and collaboration among stakehold-
ers.
Our exploration of open challenges revealed two
significant areas of concern: semantic interoperabil-
ity and scalability in complexity. These challenges
underscore the need for standardisation efforts, in-
tegrated frameworks, and automation techniques to
address semantic inconsistencies and manage trace-
ability at scale effectively. Overall, our findings pro-
vide valuable insights into the current state of artifact
traceability in software engineering practice and high-
ENASE 2025 - 20th International Conference on Evaluation of Novel Approaches to Software Engineering
760

light areas for further research and improvement.
6.1 Future Work
While our MMS has provided a comprehensive
overview of the current landscape of artifact traceabil-
ity, there are several avenues for future research and
exploration in this area. First, future studies could
delve deeper into specific industries or domains to
understand how traceability challenges vary across
different contexts. Additionally, further longitudinal
studies could investigate the evolution of traceabil-
ity practices over time and assess the effectiveness of
interventions and tools in addressing identified chal-
lenges. It is clear that there is an imminent need
for continued research and development of innovative
tools and techniques to support artifact traceability in
practice. This includes the exploration of automated
tracing algorithms, integration of traceability mecha-
nisms into existing development workflows, and the
development of frameworks for assessing the quality
and completeness of traceability information.
REFERENCES
Abbas, M., Ferrari, A., Shatnawi, A., Enoiu, E., Saadat-
mand, M., and Sundmark, D. (2022a). Correction to:
On the relationship between similar requirements and
similar software: A case study in the railway domain.
Requirements Engineering, 27(3):399–399.
Abbas, M., Ferrari, A., Shatnawi, A., Enoiu, E., Saadat-
mand, M., and Sundmark, D. (2022b). On the re-
lationship between similar requirements and similar
software: A case study in the railway domain. Re-
quirements Engineering.
Aksnes, D. W., Langfeldt, L., and Wouters, P. (2019). Ci-
tations, citation indicators, and research quality: An
overview of basic concepts and theories. SAGE Open,
9(1):2158244019829575.
Aung, T. W. W., Huo, H., and Sui, Y. (2020). A literature re-
view of automatic traceability links recovery for soft-
ware change impact analysis. In Proceedings of the
28th International Conference on Program Compre-
hension, ICPC ’20, page 14–24, New York, NY, USA.
Association for Computing Machinery.
Garousi, V., Felderer, M., and M
¨
antyl
¨
a, M. V. (2016). The
need for multivocal literature reviews in software en-
gineering: complementing systematic literature re-
views with grey literature. In Proceedings of the 20th
International Conference on Evaluation and Assess-
ment in Software Engineering, EASE ’16, New York,
NY, USA. Association for Computing Machinery.
Garousi, V., Felderer, M., and M
¨
antyl
¨
a, M. V. (2019).
Guidelines for including grey literature and conduct-
ing multivocal literature reviews in software engineer-
ing. Information and Software Technology, 106:101–
121.
Gotel, O., Cleland-Huang, J., Hayes, J. H., Zisman, A.,
Egyed, A., Gr
¨
unbacher, P., Dekhtyar, A., Antoniol,
G., and Maletic, J. (2012). The Grand Challenge of
Traceability (v1.0), pages 343–409. Springer London,
London.
Guo, J., Cheng, J., and Cleland-Huang, J. (2017). Semanti-
cally enhanced software traceability using deep learn-
ing techniques. In 2017 IEEE/ACM 39th International
Conference on Software Engineering (ICSE), pages 3–
14.
Harzing, A. W. K. and van der Wal, R. (2008). Google
scholar as a new source for citation analysis. Ethics
Sci. Environ. Polit., 8:61–73.
Kitchenham, B. A. and Charters, S. (2007). Guidelines for
performing systematic literature reviews in software
engineering. Technical Report EBSE 2007-001, Keele
University and Durham University Joint Report.
Lefebvre, C., Manheimer, E., and Glanville, J. (2008).
Searching for studies. Cochrane handbook for system-
atic reviews of interventions: Cochrane book series,
pages 95–150.
Lyu, Y., Cho, H., Jung, P., and Lee, S. (2023). A systematic
literature review of issue-based requirement traceabil-
ity. Ieee Access, 11:13334–13348.
Mahmoud, A. and Niu, N. (2014). On the role of seman-
tics in automated requirements tracing. Requirements
Engineering, 20(3):281–300.
Neto, G. T. G., Santos, W. B., Endo, P. T., and Fagundes,
R. A. (2019). Multivocal literature reviews in soft-
ware engineering: Preliminary findings from a tertiary
study. In 2019 ACM/IEEE International Symposium
on Empirical Software Engineering and Measurement
(ESEM), pages 1–6.
Pauzi, Z. and Capiluppi, A. (2023). Applications of natural
language processing in software traceability: A sys-
tematic mapping study. Journal of Systems and Soft-
ware, 198:111616.
Saleem, M. and Minhas, N. M. (2018). Information retrieval
based requirement traceability recovery approaches-a
systematic literature review. University of Sindh Jour-
nal of Information and Communication Technology,
2(4):180–188.
Tufail, H., Masood, M. F., Zeb, B., Azam, F., and Anwar,
M. W. (2017). A systematic review of requirement
traceability techniques and tools. In 2017 2nd inter-
national conference on system reliability and safety
(ICSRS), pages 450–454. IEEE.
Wang, B., Peng, R., Li, Y., Lai, H., and Wang, Z. (2018).
Requirements traceability technologies and technol-
ogy transfer decision support: A systematic review.
Journal of Systems and Software, 146:59–79.
Zhou, X., Jin, Y., Zhang, H., Li, S., and Huang, X. (2016).
A map of threats to validity of systematic literature
reviews in software engineering. In 2016 23rd Asia-
Pacific Software Engineering Conference (APSEC),
pages 153–160, Hamilton, New Zealand. IEEE.
A Multivocal Mapping Study on Artifact Traceability Complexities in Practice
761
