
Intelligent Anomaly Detection for Context-Oriented Data Brokerage
Systems
Rawaa Al-Wani
a
and Mays Al-Naday
b
School of Computer Science and Electronic Engineering, The University of Essex,Colchester, U.K.
Keywords:
Internet of Things, Publish/Subscribe, FIWARE, Context-Awareness, Anomaly Detection, Machine Learning.
Abstract:
Applications of the Internet of Things (IoT) face challenges related to interoperability and heterogeneity due to
variations in data representation formats and the absence of connectivity standards across wireless networks.
This has led to the emergence of context-oriented data brokering frameworks, with FIWARE being the most
widely adopted. However, such frameworks are not able to differentiate malicious from benign data. Conse-
quently, challenges related to data quality persist, and brokering overlays are susceptible to exploitation for the
distribution of malicious data assets. We propose a novel Artificial Intelligence (AI) anomaly detection service
that communicates with the FIWARE broker via the Fast Application Programming Interface (FastAPI). The
system also uses the Publish/Subscribe (Pub/Sub) model of FIWARE to allow networking between brokers to
validate data assets before disseminating them. This is to analyze the overhead that anomaly detection intro-
duces as a cost of the solution. The results show that the solution can detect around 95% malicious data, with
an approximate overhead of 12% increase in response time.
1 INTRODUCTION
The breakthrough that came with the Internet of
Things (IoT) has changed almost all aspects of life,
heralding a new era in which everyday objects are
interconnected to the Internet. The IoT applications
produce heterogeneous data at the device and network
levels, and the spontaneous occurrence of numerous
events, will pose a significant barrier for the develop-
ment of diverse applications and services (Razzaque
et al., 2015; Alberti et al., 2019). Consequently, to
coherently model IoT objects and data from multiple
sources with different formats, the Semantic Web of
Things (SWT) based on the standards and technology
of the World Wide Web Consortium (W3C) is used.
The W3C’s Web of Things (WoT) architecture
recommendations delineate the prerequisites for es-
tablishing a proxy that interlinks brokers with the
IoT network and cloud computing systems. Cloud-
based Publish/Subscribe (Pub/Sub) systems provide
reliable solutions for the deployment of IoT data in
the cloud and facilitate communication with applica-
tions or users subscribing to IoT entities (Amara et al.,
2022). FIWARE is the most prominent cloud-based
a
https://orcid.org/0000-0001-6420-0296
b
https://orcid.org/0000-0002-2439-5620
Pub/Sub platform. FIWARE facilitates data brokering
through Context Brokers that implement a Pub/Sub
model over entities using the Next Generation Service
Interface (NGSI) protocol. FIWARE defines crucial
components called Generic Enablers (GE). Orion GE
acts as the context broker of FIWARE. Orion broker
offers an Application Programming Interface (API)
that implements the NGSI Context API (Bellini et al.,
2023).
A context is defined as the information that char-
acterizes the IoT data, and context-awareness involves
using this information to comprehend the acquired
facts (Barriga et al., 2022). However, FIWARE se-
curity capabilities focus on authentication and ac-
cess control services using Keyrock GE and Wilma
GE, without anomaly detection support for data as-
sets (Munoz-Arcentales et al., 2021). As a result,
protecting the information sent between broker sys-
tems is crucial. Machine learning (ML) has been
used for anomaly detection in telecommunication net-
works, but it has not been applied yet in FIWARE-like
brokerage systems to provide such detection capabil-
ities.
This work proposes a novel Pub/Sub-based com-
munication framework across FIWARE brokers, for
anomaly detection in data assets. The framework en-
ables the integration of ML-based anomaly detector
442
Al-Wani, R. and Al-Naday, M.
Intelligent Anomaly Detection for Context-Oriented Data Brokerage Systems.
DOI: 10.5220/0013478800003944
In Proceedings of the 10th International Conference on Internet of Things, Big Data and Security (IoTBDS 2025), pages 442-449
ISBN: 978-989-758-750-4; ISSN: 2184-4976
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

as a “pluggable” service, allowing flexible incorpo-
ration of different ML models. ML service plugging
includes: entity pre-processing to extract its data from
the respective NGSI message and serve to the ML
model; and, post-processing to package the prediction
result as an NGSI feature update of the same entity,
maintained by the verifying broker.
The framework is implemented and evaluated ex-
perimentally using example dataset: the Canadian In-
stitute of Cybersecurity (CIC) IoT dataset (Neto et al.,
2023), which covers extensive attacks in IoT environ-
ments. Evaluation results show benefits of anomaly
detection in data brokerage systems, compared to the
overhead introduced by the detection framework.
We structure the rest of the paper as follows: Sec-
tion 2 reviews the state-of-the-art related work. Sec-
tion 3 describes the proposed Pub/Sub framework
for anomaly detection. Section 4 evaluates the per-
formance of the proposed solution, while Section 5
draws our conclusions.
2 RELATED WORK
Data interoperability and anomaly detection have
been active research topics within the IoT domain,
with a wide range of solutions being developed by
the community (Martins et al., 2022; Zyrianoff et al.,
2021; Baee et al., 2024). The work of (Anwar and
Saravanan, 2022) applies apache spark for big data
processing to classify network traffic and detect intru-
sions produced by IoT devices. To evaluate the effec-
tiveness of intrusion detection, this study compares
the performance of ML versus deep learning mod-
els. Both types of models are trained and evaluated
in the distributed computing environment provided by
Spark, ensuring scalability for handling the large vol-
ume of data in the BoT-IoT dataset. However, this
work does not support IDS services in context-aware
IoT networks.
The key features for the design and performance
metrics of several open-source systems are explained
in (Lazidis et al., 2022). These systems include Rab-
bitMQ and Apache Kafka. A significant contribu-
tion of this work is the comprehensive evaluation of
seven open-source systems. However, this work pro-
vides precise details on several Pub/Sub systems, but
does not offer substantial guidance on the implemen-
tation. The work of (Ataei et al., 2023) introduces a
comprehensive architectural framework based on the
Pub/Sub technique, designed for real-time data pro-
cessing in the broad field of Massive IoT (MIoT) uti-
lizing the powerful features of Apache Kafka for data
stream processing. However, this work does not sup-
port context awareness by itself. It needs to be in con-
junction with other frameworks and technologies to
create a context-aware system. The work of (Shukla
et al., 2024) introduces a new approach for detecting
distributed denial-of-service (DDoS) attacks on IoT
data. It operates within a Kafka framework. Kafka
is utilized to implement a portable, scalable, and dis-
tributed detection system. However, Apache Kafka
does not evaluate or infer context; it merely facilitates
the transfer and persistence of data, rather than adapt-
ing to changing contexts. Anomaly detection of IoT
applications is increasingly using machine learning
(ML). An Intrusion Detection System (IDS) based on
ML classifier algorithm is used in the work of (Sirisha
et al., 2021) to distinguish between normal and mali-
cious traffic and lowers the risk of malicious activity.
The ML algorithms used are trained on the UNSW-
NB15 dataset. However, this work haven’t addressed
the interoperability challenge of IoT (not supporting
context-aware platforms).
The work of (Mart
´
ın et al., 2023) evaluates the
compatibility of AI services with the FIWARE plat-
form. The integration of cognitive AI services with
IoT platforms is enabled by an abstraction layer that
incorporates cognitive components, enhancing inter-
operability across diverse IoT domains. This work is
particularly relevant to the research presented in this
work. However, it did not provide an IDS services-
based context-aware platform like FIWARE.
3 THE PROPOSED ANOMALY
DETECTION SYSTEM
The proposed framework (implemented as a sys-
tem) comprises: an off-line-trained machine learning
model that is served as a pluggable anomaly detector
service, verification brokers, and a Pub/Sub commu-
nication protocol to facilitate near-real-time anomaly
detection.
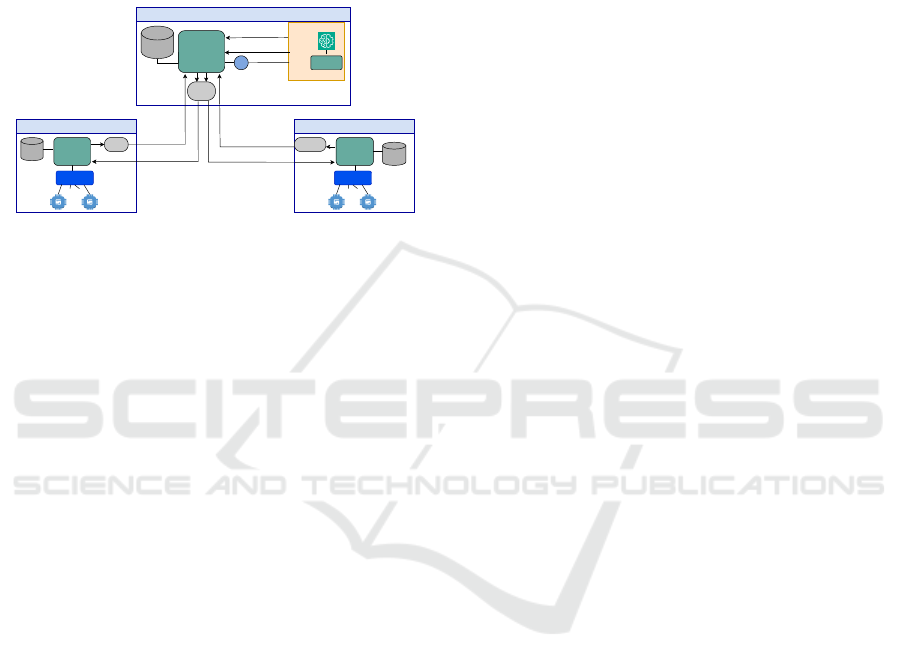
3.1 Functional Components
The proposed framework illustrated in Figure 1 con-
sists of: a collection of data verification brokers, each
representing a distinct environment; (edge) service
broker that enables the validation of data assets us-
ing an anomaly detector; and a modular ML-based
anomaly detection microservice that predicts the na-
ture of the data assets. The proposed brokers differ
from the baseline broker by incorporating verifica-
tion capabilities that regulate the management of data
assets. These brokers communicate via a Pub/Sub
paradigm facilitated by the NGSI-LD protocol. Fur-
Intelligent Anomaly Detection for Context-Oriented Data Brokerage Systems
443
thermore, the Fast Application Programming Inter-
face (FastAPI) web framework is utilized to deploy
the ML model as a pluggable microservice, facilitat-
ing flexible and modular integration of several ML
models according to the scenario. Moreover, FastAPI
is selected for its speed, high performance, and ro-
bustness, as well as its inherent capabilities for data
validation, JSON serialization, and OpenAPI integra-
tion.
Edge Environment
x
Environment
Broker
...
IoT
Gateway
Data
Generators
Env
x
Storage
Apollo
Proxy
Edge Verification Point
Aggregate
Storage
Edge Service
Broker
(Orion)
data
Format
API
Anomaly Detector
ML
Model
Apollo
Proxy
FastAPI
Sub (New Entity)
Post Update
Edge Environment
y
Environment
Broker
...
IoT
Gateway
Data
Generators
Apollo
Proxy
Env
y
Storage
Sub (New Entity) Subs cription (Sub) New Entity
Sub (Update Entity) Sub (Update Entity)
Figure 1: Agents-based System.
3.1.1 Data-Verifying Brokers
Each environment is represented by at least one bro-
ker, making it easier to verify data assets prior to pub-
lication. Data created in the environment is trans-
ferred to the broker via the appropriate gateway,
where it is represented as a context entity and mo-
mentarily added as a new entity to the environment
database (MongoDB). Before confirming the entity
admission to the brokerage system, the broker pub-
lishes the the new entity to a verification service bro-
ker and subscribes for the response channel with the
verification broker. The response channel is iden-
tified by a commonly agreed subscription identifier
between the environment and the service brokers.
The response itself is an entity update that confirms
whether a data entity is benign or malicious, and what
type of malicious attack it is likely to be caused by.
The entity is identified by its Entity Id. The service
broker directly informs the anomaly detector about
the new entity, as indicated by the subscription il-
lustrated in Figure 5 for the CIC entity. Upon no-
tification from the anomaly detector that the data is
benign, the service broker verifies the entity’s admis-
sion and processes the data in accordance with the
management policy specific to benign data within the
environment. Otherwise, if the entity is malicious,
the broker may act on it with an alternative man-
agement policy for malicious data. For example, to
delete the entity from the environment database and
raise an alarm to relevant systems; or redirect the
data to a honeypot. It should be noted that the in-
teraction between the environmental verification bro-
ker and the verification counterpart uses two subscrip-
tions (asynchronous Pub/Sub paradigm), as detailed
in Section 3.2. We implement the verifying broker as
a FIWARE Orion supported by Apollo proxy, which
handles data extraction and maintains context sub-
scriptions by turning broker notifications into context
entities.
3.1.2 Verification Service Broker
This broker interacts with an anomaly detector to ana-
lyze data entities for legitimacy assessment. The bro-
ker initially provides its services to the environment
by subscribing to the new entities obtained from the
environmental brokers. Specifically, the service bro-
ker subscribes once to each of the environment coun-
terparts for a particular type of entity, represented by a
common type attribute. This implies treating type as
a ‘context group’, and allows for verifying any num-
ber of entities of a particular type for the lifetime of
the subscription. This work assumes that each en-
vironment broker represents a distinct type of entity.
Consequently, the service broker establishes a number
of subscriptions that does not exceed the total num-
ber of environment brokers within the system. The
anomaly detector and the service broker subscribe to
new entities. When the service broker receives a pub-
lication of a new entity from an environment broker,
it extracts and passes the entity data to the anomaly
detector. The latter analyzes the data and responds to
the service broker with a prediction of the entity’s na-
ture. The prediction result is sent as an HTTP POST
message. Since the anomaly detector is accessed di-
rectly via an API, the service broker is not required to
explicitly subscribe to a response channel. The sub-
scription is presumed to be implied. Upon reception
of the prediction result from the anomaly detector, the
service broker updates the entity in its own database
and publishes the result to the respective environment
broker over the response channel. To this end, the
service broker is assumed to operate over less con-
strained infrastructure than environment brokers, and
can be managed by the same or different stakehold-
ers as the environment brokers. The broker is too in-
tegrated as an extended Orion, able to communicate
with the anomaly detector.
3.1.3 Pluggable Anomaly Detector (ML-Based)
The anomaly detector is represented as a self-
contained service that is pluggable to the service bro-
ker using the NGSI-LD interface on one direction and
RESTful API on the other. Firstly, the ML model is
trained offline through a separate pipeline as shown in
Figure 2. The pipeline includes applying data prepro-
cessing, feature reduction component that decreases
IoTBDS 2025 - 10th International Conference on Internet of Things, Big Data and Security
444
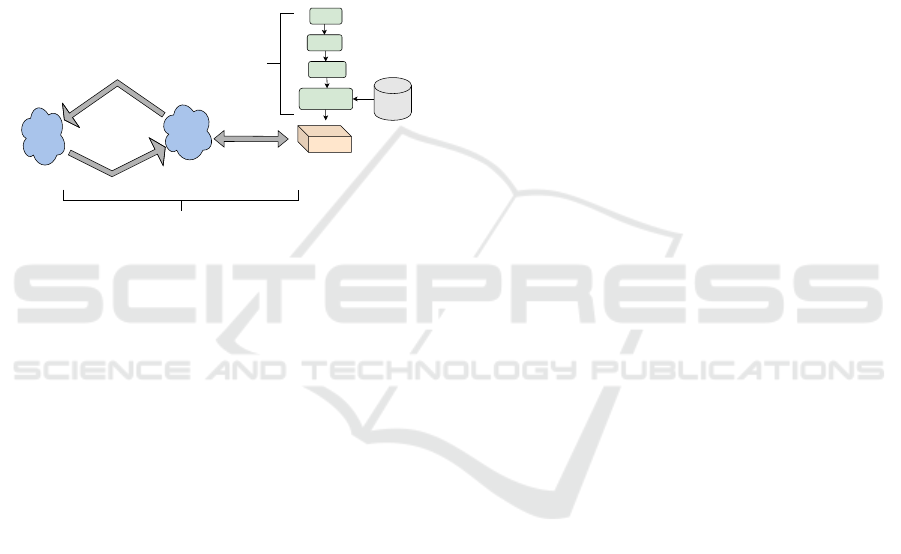
the data volume to the minimum required to provide
scalability-/efficiency-by-design. For this, we apply
the K-best feature selection technique. The (K-best
function) selects the features according to their rele-
vance to the output variable using one of these func-
tions (chi-squared, ANOVA F-test, and mutual in-
formation). Chi-square test has been chosen to se-
lect the features with the highest scores for the final
feature subset. Secondly, the produced (pluggable)
ML model is deployed as a microservice enabled by
FastAPI, which subscribes to new entities from the
service broker and provides, in return, an API end-
point to process incoming publications and post pre-
diction notifications.
Load CIC
Data
Feature
Reduction
Model
Training
Model Evaluation
& Validation
Synthetic
Data
Generation
Pluggable ML
Subscription 1
Subscription
Environment
Broker
Service
Broker
Subscription 2
Online Proposed Pub/Sub Communication Protocol
Offline ML Training
Figure 2: Proposed Pub/Sub Communication Protocol and
Offline ML Training.
Secondly, the anomaly detector deploys the (plug-
gable) ML model as a microservice using FastAPI and
subscribes to the new entities from the service bro-
ker. Thirdly, in FASTAPI the received entity pub-
lished by the service broker is processed first to se-
rialize the data, remove message header(s) as well as
feature names from the entity leaving only the val-
ues of the features to be used in the loaded pluggable
ML. The latter analyzes the data and returns the pre-
diction of whether the entity is benign or malicious
and what type of malicious. The API endpoint pushes
the prediction result to the service broker as an HTTP
POST to update the existing entity using its ID. We
used CIC IoT 2023 dataset for training and testing the
ML model offline. CIC IoT dataset involves seven
groups of attacks, namely DDoS, DoS, Recon, Web-
based, brute force, spoofing, and Mirai.
3.2 Publish/Subscribe Message
Exchange
This work introduces an innovative online Pub/Sub
communication protocol to enhance interaction be-
tween the environment and the service brokers, as
well as between the service broker and the anomaly
detector. Using three subscriptions that circulate
the IoT entity through the proposed system begin-
ning from the environment broker and ending by re-
turning the prediction result back to the same bro-
ker as shown in Figure 2. First, the environment
broker creates a context entity of the data received
from IoT devices, and store the pending entity in
the environment database. The service broker sub-
scribes to the new entities under a specific type,
subscription 1 (new entity). The subscription
specifies: a name, an identifier (id) and an entity
type. This constitutes a form of service channel be-
tween the two brokers. The subscription further spec-
ifies the entity attributes to be included in the notifica-
tion along with the destination endpoint (for sending
the publication). An example of subscription 1 is
shown in Figure 4 based on CIC dataset. Similarly,
the anomaly detector subscribes to the service broker
(see Figure 5), using the name, id and endpoint of
the service channel between the service broker and
the anomaly detector. The cascade subscription en-
ables asynchronous forwarding of the new entity from
the environment broker to the anomaly detector.
When an environment broker receives
subscription 1, it responds back with notifi-
cation of any pending entity - i.e. for which there is
no prediction result - to the service broker. Following
that publication, the environment broker subscribes
to the prediction results, expected as an updates of the
existing (pending) entities. Meanwhile, the service
broker stores new entities in its aggregate database
and publishes them to FastAPI anomaly detector.
The latter processes the received entity to classify
it and post the predicted result back to the service
broker, as a new feature of this entity. Subscription
to the prediction result - by the service broker - is
implicit, as FastAPI sends the result back as an HTTP
POST message. When the service broker receives
the prediction result, it will notify the environment
broker due to subscription 2 (entity update)
- illustrated in Figure 6. This subscription does not
specify a specific entity; instead, each notification
response is anticipated to include an entity ID that
corresponds to an existing entity. The subscriptions
and alerts for each broker are managed by the
corresponding Apollo proxy linked to the broker. The
workflow of the Pub/Sub model is shown in Figure 3.
4 EVALUATION
This section evaluates the performance of the pro-
posed intelligent anomaly detection solution experi-
mentally, using our FIWARE-based implementation.
The overhead of achieving anomaly detection is quan-
tified as a solution cost, relative to its benefit in mit-
Intelligent Anomaly Detection for Context-Oriented Data Brokerage Systems
445

IoT Devices
Environment
Broker
Edge Service
Broker
FASTAPI ML
Post Entity
Subs cription (New Entity)
Subs cription (New Entity)
Notification
Post the Prediction
Subs cription (Update Entity)
Notification of Prediction
Notification
IoT Devices
Environment
Broker
Edge Service
Broker
FASTAPI ML
Figure 3: Pub/Sub model Workflow.
Figure 4: Subscription 1 from Edge Service Broker to En-
vironment Agent.
Figure 5: Subscription from Fast API to Edge Service Bro-
ker.
igating the spread of malicious data. We illustrate
our argument by comparing the system performance
with and without the proposed solution. We refer to
the FIWARE system without our solution as baseline,
whereas a system that integrates our solution is identi-
fied as proposed. Experiments are conducted in a con-
tainerized virtual environment utilizing the generated
load from the custom-built entity generator and/or
Figure 6: Subscription 2 from Environment Agent to Edge
Service Broker.
the Locust load tester
1
. The entity generator enables
adaptive creation of entities, according to the response
rate of the service broker; while Locust was used to
scale the load introduced in the system. Moreover,
the entity generator resembles the behavior of realis-
tic data generators (IoT devices). The rate of entity
generation and the total number of entities have been
configured differently to assess each of the KPIs, and
it has been described in their respective sections be-
low. A set of Key Performance Indicators (KPIs) have
been used: Response Time; Response Throughput ;
and ML model performance. The physical edge node
runs on Linux Ubuntu 24.04, using intel(R), Xeon(R)
core CPU of 1.60GHz - 2.11 GHz, and 8GB RAM.
4.1 Response Time
Response Time is the elapsed time between sending a
notification of a new entity from an environment bro-
ker to its service counterpart and receiving a predic-
tion result back.
4.1.1 Per Entity
The empirical cumulative distribution function
(ECDF) is used to present the response time per
entity in the Baseline versus Proposed system.
The response time of 30 entities was collected
independently to be analyzed as shown in Figure 7.
Generally, the distribution pattern in both systems is
analogous with ≈ 12.5% proposed system overhead.
Additionally, (≈ 90%) of baseline responses are re-
ceived with ≈ 70 msec compared to ≈ 95 − 97 msec
for the proposed system. The maximum baseline
response time was recorded at ≈ 97 msec, as opposite
to the maximum proposed system response time
at ≈ 120 msec. The proposed system overhead is
1
https://locust.io/
IoTBDS 2025 - 10th International Conference on Internet of Things, Big Data and Security
446
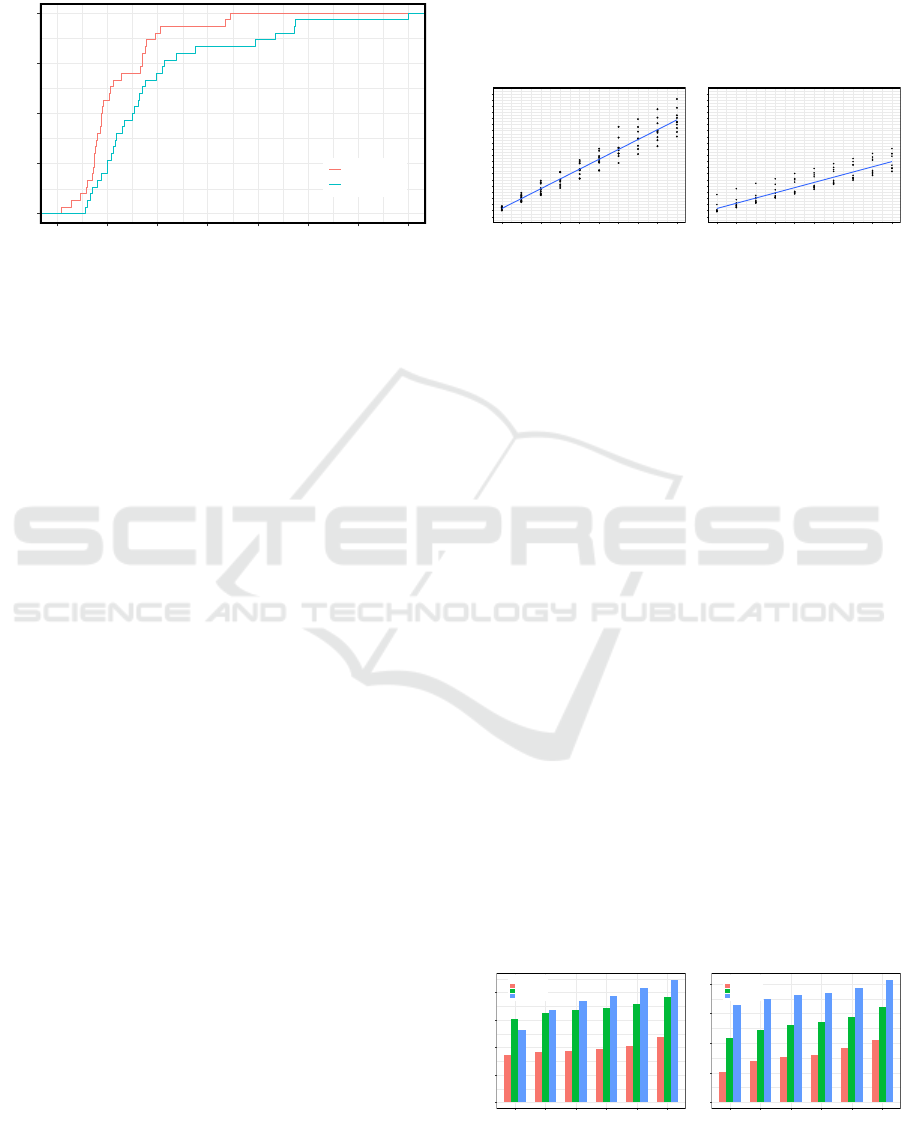
mainly driven by the processing delay of the anomaly
detector and the communication time between the
service broker and the detector.
0.00
0.25
0.50
0.75
1.00
0.05 0.06 0.07 0.08 0.09 0.10 0.11 0.12
Response Time (second)
Ratio of Responses
Baseline
proposed
Figure 7: ECDF comparison of Response Time.
4.1.2 For Multiple Entities
We evaluate the overall response time for multiple en-
tities. We measure this parameter by calculating the
total time required to publish multiple entities and re-
ceive their responses. To evaluate this KPI, we per-
form 10 experiments for both the baseline and pro-
posed systems. Each experiment involves generating
several entities, ranging from 1 to 10. The custom en-
tity generator has been used here to control the num-
ber of entities. The results are presented in Figure 8
as scatterplots. The response time of the two systems
shows an upward trend along with the increase in the
number of successful responses (entities). It is worth
mentioning that the elapsed time in Figure 8 is in the
order of 500-750 msec as compared to 70-100 msec
in Figure 7; this difference is because the latter pre-
sented the response time of getting one entity while
Figure 8 presented the total elapsed time for getting
responses of multiple entities, ranging from one en-
tity to ten. The total elapsed time of the baseline sys-
tem is between 50 msec for 1-entity experiments and
450 msec for 10-entity experiments, with a variation
of ≈ 70 − 100 msec. Whereas, the total proposed sys-
tem elapsed time is recorded at ≈ 750 msec when the
number of entities is 10, with ≈ 200 msec variation.
The maximum difference in the average response time
was ≈ 300 msec when the number of entities was 10.
This shows that under light load conditions, both sys-
tems have similar response times, with overhead from
the proposed becoming observable as load increases.
This is due to the additive effect of the processing de-
lay taken by the anomaly detector and the commu-
nication latency between the service broker and the
anomaly detector. Moreover, the response time in-
creases at a slower rate in the baseline system, with
a slope percentage of ≈ 4.4%. The growth rate is
faster in the proposed system, with a slope percent-
age of ≈ 7.7%. This shows that under light load con-
ditions, both systems perform relatively similar, with
overhead of the proposed becoming observable as the
load increases. This is due to the additive effect of the
processing delay taken by the anomaly detector and
the communication latency between the service bro-
ker and the anomaly detector.
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0.45
0.50
0.55
0.60
0.65
0.70
0.75
0.80
0.85
0.90
0.95
1.00
1 2 3 4 5 6 7 8 9 10
Total Number of Entities
Elapsed Time (seconds)
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0.45
0.50
0.55
0.60
0.65
0.70
0.75
0.80
0.85
0.90
0.95
1.00
1 2 3 4 5 6 7 8 9 10
Total Number of Entities
Elapsed Time (second)
Figure 8: (a) Response Time of Proposed System (b) Re-
sponse Time of Baseline System.
4.2 Response Time Percentile
Here, the overall response time is assessed when the
entities are published concurrently. We used the lo-
cust load tester to scale the number of users within a
designated time period and obtain the response time
percentile for completed entities. Locust configu-
ration involved specifying the number of users, the
ramp-up users, and the run time. We extract the eval-
uation report as a Comma Separated Values (CSV)
file and use it to produce the results. Each active user
uses the client.post method to submit one entity to
the environment broker. The entity could be benign or
malicious, classified as an attack in the experimental
dataset.
The proposed and baseline response time per-
centiles are depicted in Figure 9. We tested three
scales of active users (50, 500, 2000). In the baseline
system, 50% of the entities received responses within
≈ 10 msec when the number of users is 50. Whereas,
in the proposed system, it reaches ≈ 90 msec for the
same ratio of completed entities. The proposed sys-
tem response time was ≈ 250 msec or below, com-
pared to ≈ 130 msec in the baseline, when the ratio of
completed entities reached 99%. Overall, for all three
scales of active users and at the 90% − 99% of com-
pleted entities, the response time almost doubles in
the proposed system compared to the baseline. This
1
10
100
1000
10000
50% 66% 75% 80% 90% 99%
Response Time (millisecond)
Number of Users
50
500
2000
1
10
100
1000
10000
50% 66% 75% 80% 90% 99%
Response Time (millisecond)
Number of Users
50
500
2000
Figure 9: (a) Proposed System Response Time Percentile
(b) Baseline System Response Time Percentile.
Intelligent Anomaly Detection for Context-Oriented Data Brokerage Systems
447
0
5
10
15
20
25
30
1 2 3 4 5 6 7 8 9 10
Time(second)
Throughput (Response Per Second)
0
5
10
15
20
25
30
1 2 3 4 5 6 7 8 9 10
Time(second)
Throughput (Response Per Second)
Figure 10: (a) Proposed system RPS over 10 seconds for 10
experiments (b) Baseline system RPS over 10 seconds for
10 experiments.
is similar to the results shown earlier in Figure 8. The
anomaly detector, with its single deployment instance
in the testbed, drives this processing and queuing de-
lay.
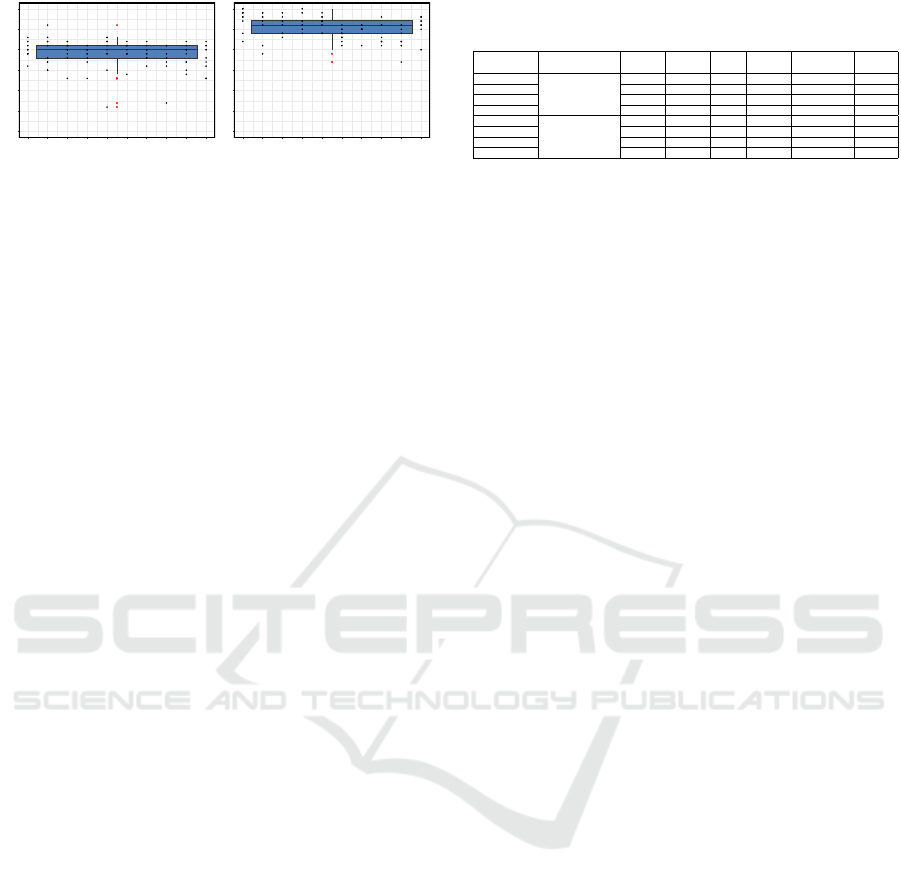
4.3 Throughput
Throughput is the number of responses within each
second is recorded as the RPS. Figure 10 shows the
throughput received by an environment broker, mea-
sured during 10 experiments. Each experiment runs
for a total duration of 10 seconds. Each second in-
volves sequential generation and posting of a new en-
tity after successfully receiving a response of the pre-
vious entity. Figure 10-(a) shows that the average
RPS achieved by the proposed system is 20 RPS and
the maximum is 26. This is ≈ 20% lower than the
RPS achieved by the baseline, shown in Figure 10-
(b). The latter exhibits an average RPS of 26 with
a maximum of 30. In general, the throughput of the
proposed system is lower than the throughput of the
baseline counterpart as a result of the added overhead
of the anomaly detector component, along with com-
munication overhead on the forwarding channel from
the service broker to the detector.
4.4 Offline ML Performance Evaluation
Two ML training and testing pipelines have been as-
sessed: one without a dimensionality reduction func-
tion, hence including the full feature set, and one with
the reduction function to minimize the processing re-
quirement of the model. The goal is to quantify the
performance loss associated with the reduction, rather
than the training cost in CPU resources and training
time. We have trained and tested each pipeline offline
using four distinct classification algorithms: K Near-
est Neighbors (KNN), Decision Trees (DT), Gradient
Boosting (GB), and Random Forest (RF). An example
dataset, CIC IoT 2023, has been used to train and val-
idate each model. We measured four ML KPIs: Ac-
curacy, which shows the percentage of correct predic-
tions; Precision and Recall, which show the percent-
age of fewer false alarms; and F1-score, which shows
Table 1: Comparison of the full-feature and feature-
reduction pipelines for the CIC dataset.
ML Algorithm Number of features Accuracy Precision Recall F1-Score Train Time (s)
CPU
Usage %
KNN 0.9705 0.6611 0.9705 0.9691 4.7541 14.5
DT 15 Features 0.9925 0.8557 0.8351 0.8436 6.5025 11.9
GB 0.9786 0.6899 0.9786 0.9798 1157.1868 16.8
RF 0.9926 0.9925 0.9926 0.9921 253.0454 11.7
KNN 0.9705 0.6611 0.9705 0.9691 4.6831 14.0
DT 41 Features 0.9925 0.8538 0.8378 0.8445 7.5184 13.4
GB 0.9786 0.6899 0.9786 0.9798 1329.2544 17.1
RF 0.9927 0.9926 0.9927 0.9922 368.8559 15.8
how accurate the models really are. Table 1 presents
the performance and cost results of the two pipelines
over the CIC validation dataset. The first pipeline in-
cludes all 41 features, while the second includes only
the 15 most important ones. Cost is measured by the
time it takes to train a model and the percentage of
CPU used in training. First, the results show that
the average accuracy of all models is ≈ 98%. Both
pipelines exhibit this, with negligible differences be-
tween them. On the other hand, the F1 score exhibits
higher variation across models, with RF achieving the
highest score of ≈ 99% and DT achieving the low-
est counterpart of ≈ 84%. Across pipelines, there
is a negligible reduction in F1-score, except for DT,
where the score is less by ≈ 0.1%. Cost-wise, the RF
feature-reduction pipeline requires ≈ 30% less train-
ing time of ≈ 253 seconds than its full-feature coun-
terpart, taking ≈ 369 seconds. Similarly, the CPU per-
centage required for the RF feature-reduction pipeline
is ≈ 26% less than that of the full-feature counterpart.
The three other models have yielded comparable re-
sults. Overall, the results show that similar perfor-
mance can be achieved with considerably fewer re-
sources and reduced training time, promoting better
sustainable ML edge models.
5 CONCLUSION
Context-oriented data brokerage platforms, like FI-
WARE, offer standard contextual representations of
data assets. This platform makes it easy to share
and use IoT data. However, so far FIWARE sys-
tems lack the ability to verify the legitimacy of data
before acting on them. This involves determining
whether a data asset is benign or malicious, as well
as the specific type of malicious activity. This limi-
tation poses a critical risk of exploiting FIWARE to
spread malicious data and significantly impact data
consumers, AI applications being the most promi-
nent ones. This work addressed the limitation with
a novel, edge-native, solution for intelligent anomaly
detection. The proposed solution integrates a ML-
based microservice anomaly detector, in a pluggable
manner using FastAPI. The solution also had a group
of data-verifying brokers that leverage the FIWARE
Pub/Sub model and the NGSI-LD to make it possi-
IoTBDS 2025 - 10th International Conference on Internet of Things, Big Data and Security
448

ble for data and verification messages to be sent and
received in a flexible, asynchronous way. The pro-
totype implementation of the solution has been eval-
uated experimentally to analyze the overhead of the
solution as a cost indicator, compared to the bene-
fit of reducing the spread of malicious data. Evalua-
tion results have shown the solution to require ≈ 12%
longer response time per data entity and reduce the
response throughput by ≈ 20%. At the same time, the
results show the ability to accurately detect over 95%
of malicious data, allowing FIWARE to handle them
accordingly.
REFERENCES
Alberti, A. M., Santos, M. A., Souza, R., Da Silva, H.
D. L., Carneiro, J. R., Figueiredo, V. A. C., and Ro-
drigues, J. J. (2019). Platforms for smart environments
and future internet design: A survey. IEEE Access,
7:165748–165778.
Amara, F. Z., Hemam, M., Djezzar, M., and Maimor, M.
(2022). Semantic web and internet of things: Chal-
lenges, applications and perspectives. Journal of ICT
Standardization, 10(2):261–291.
Anwar, F. and Saravanan, S. (2022). Comparison of artifi-
cial intelligence algorithms for iot botnet detection on
apache spark platform. Procedia Computer Science,
215:499–508.
Ataei, M., Eghmazi, A., Shakerian, A., Landry Jr, R., and
Chevrette, G. (2023). Publish/subscribe method for
real-time data processing in massive iot leveraging
blockchain for secured storage. Sensors, 23(24):9692.
Baee, M. A. R., Simpson, L., and Armstrong, W. (2024).
Anomaly detection in the key-management interoper-
ability protocol using metadata. IEEE Open Journal
of the Computer Society.
Barriga, J. A., Clemente, P. J., Hern
´
andez, J., and P
´
erez-
Toledano, M. A. (2022). Simulateiot-fiware: Domain
specific language to design, code generation and ex-
ecute iot simulation environments on fiware. IEEE
Access, 10:7800–7822.
Bellini, P., Palesi, L. A. I., Giovannoni, A., and Nesi, P.
(2023). Managing complexity of data models and per-
formance in broker-based internet/web of things ar-
chitectures. Internet of Things, 23:100834.
Lazidis, A., Tsakos, K., and Petrakis, E. G. (2022). Publish–
subscribe approaches for the iot and the cloud: Func-
tional and performance evaluation of open-source sys-
tems. Internet of Things, 19:100538.
Mart
´
ın, D. G., Florez, S. L., Gonz
´
alez-Briones, A., and Cor-
chado, J. M. (2023). Cosibas platform—cognitive ser-
vices for iot-based scenarios: Application in p2p net-
works for energy exchange. Sensors, 23(2):982.
Martins, I., Resende, J. S., Sousa, P. R., Silva, S., Antunes,
L., and Gama, J. (2022). Host-based ids: A review
and open issues of an anomaly detection system in iot.
Future Generation Computer Systems, 133:95–113.
Munoz-Arcentales, A., L
´
opez-Pernas, S., Conde, J.,
Alonso,
´
A., Salvach
´
ua, J., and Hierro, J. J. (2021).
Enabling context-aware data analytics in smart envi-
ronments: An open source reference implementation.
Sensors, 21(21):7095.
Neto, E. C. P., Dadkhah, S., Ferreira, R., Zohourian, A., Lu,
R., and Ghorbani, A. A. (2023). Ciciot2023: A real-
time dataset and benchmark for large-scale attacks in
iot environment. Sensors, 23(13):5941.
Razzaque, M. A., Milojevic-Jevric, M., Palade, A., and
Clarke, S. (2015). Middleware for internet of things:
a survey. IEEE Internet of things journal, 3(1):70–95.
Shukla, P., Krishna, C. R., and Patil, N. V. (2024). Kafka-
shield: Kafka streams-based distributed detection
scheme for iot traffic-based ddos attacks. Security and
Privacy, 7(6):e416.
Sirisha, A., Chaitanya, K., Krishna, K., and Kanumalli,
S. S. (2021). Intrusion detection models using super-
vised and unsupervised algorithms-a comparative es-
timation. International Journal of Safety and Security
Engineering, 11(1):51–58.
Zyrianoff, I., Heideker, A., Sciullo, L., Kamienski, C., and
Di Felice, M. (2021). Interoperability in open iot plat-
forms: Wot-fiware comparison and integration. In
2021 IEEE International Conference on Smart Com-
puting (SMARTCOMP), pages 169–174. IEEE.
Intelligent Anomaly Detection for Context-Oriented Data Brokerage Systems
449
