
Feature Selection for Stock Market Prediction: A Comparison of Relief
and Information Gain Methods
Humberto O. Braganc¸a
1 a
, Rafael A. Berri
1 b
, Bruno L. Dalmazo
1 c
, Eduardo N. Borges
1 d
,
Viviane L. D. de Mattos
1 e
, Richard F. Pinto
1 f
, Fabian C. Cardoso
2 g
and Giancarlo Lucca
3 h
1
Federal University of Rio Grande (FURG), Rio Grande, Brazil
2
University of Rio Verde (UniRV), Rio Verde, Brazil
3
Catholic University of Pelotas (UCPel), Pelotas, Brazil
Keywords:
Machine Learning, Feature Selection, Stocks, Technical Analysis, Financial Market.
Abstract:
This study explores an approach to predictive analysis in the financial market, using a data set composed of
financial information from different companies listed on the stock market, which provides a more detailed and
contextualized view of the behavior of shares. Based on these indicators, feature selection methods, such as
Relief and Information Gain, are applied to identify the most relevant variables for building predictive models.
One of the main contributions of this work is the use of cross-validation to evaluate attribute selection, a
technique that has not yet been explored in this context with this dataset. The results show that the combination
of new financial indicators and cross-validation offers a solid basis for more accurate analysis, with important
implications for investors, financial analysts and policymakers in the stock market. This work expands the
boundaries of the literature on feature selection and opens possibilities for future research in emerging markets.
1 INTRODUCTION
The Brazilian financial market, B3
1
, is a large and
dynamic emerging market with unique characteris-
tics that require adapted analytical and predictive ap-
proaches (Chen and Metghalchi, 2012). Its complex-
ity, driven by diverse economic sectors and volatil-
ity, presents challenges and opportunities for financial
analysis (Bouri et al., 2020).
In recent years, predictive analysis using machine
learning has proven effective for financial decision-
making. Supervised learning models help assess
risks and make informed decisions, emphasizing their
importance in managing corporate financial perfor-
mance (Cuervo, 2023).
a
https://orcid.org/0009-0006-6610-500X
b
https://orcid.org/0000-0002-3812-4186
c
https://orcid.org/0000-0002-6996-7602
d
https://orcid.org/0000-0003-1595-7676
e
https://orcid.org/0000-0002-3512-6290
f
https://orcid.org/0009-0007-0176-3383
g
https://orcid.org/0000-0002-2842-0387
h
https://orcid.org/0000-0002-3776-0260
1
https://www.b3.com.br/
Feature selection, a key step in improving model
efficiency and generalization, involves identifying the
most relevant variables to enhance prediction ac-
curacy and streamline the learning process (Chan-
drashekar and Sahin, 2014). This process is partic-
ularly important in financial markets, where the vol-
ume of data can overwhelm traditional methods, im-
proving model performance and reducing overfitting
(Htun et al., 2023).
Despite the importance of feature selection in
global markets, there is limited research on its appli-
cation in the Brazilian context. The country’s eco-
nomic and financial specificities, such as its regula-
tory environment and market structure, impact the be-
havior of financial indicators. Emerging technologies
and new indicators derived from detailed data can im-
prove financial analysis and provide deeper insights
into the Brazilian market (Kohn and Moraes, 2007).
The application of machine learning methods,
coupled with extensive datasets, can significantly en-
hance the accuracy and reliability of economic fore-
casts in Brazil, underscoring the importance of tai-
lored approaches for financial analysis in emerging
markets (Araujo and Gaglianone, 2023). The com-
996
Bragança, H. O., Berri, R. A., Dalmazo, B. L., Borges, E. N., D. de Mattos, V. L., Pinto, R. F., Cardoso, F. C. and Lucca, G.
Feature Selection for Stock Market Prediction: A Comparison of Relief and Information Gain Methods.
DOI: 10.5220/0013481300003929
In Proceedings of the 27th International Conference on Enterprise Information Systems (ICEIS 2025) - Volume 1, pages 996-1003
ISBN: 978-989-758-749-8; ISSN: 2184-4992
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

bination of cross-validation and feature selection in
Brazilian stock market data is still underexplored,
highlighting a research opportunity to enhance pre-
dictive models and forecasting precision.
To address this gap, this study proposes the uti-
lization of an dataset with financial indicators spe-
cific to Brazil, sourced from decades of detailed fi-
nancial data. This dataset is used to apply advanced
feature selection techniques and evaluate the predic-
tive performance of models using cross-validation, a
technique little explored in the national context.
The main objective of this work is to evaluate how
different feature selection methods, applied to this
set of financial data, can improve the performance of
predictive models in the Brazilian financial market.
Specifically, Information Gain and Relief methods are
used to choose the key features.
This document is organized as follows: Section
2 covers Feature Selection Techniques and Technical
Analysis Indicators, in the Literature Review. Sec-
tion 3 summarizes key prior studies. Our methodol-
ogy is detailed in Section 4, while Section 5 presents
the study’s findings. Finally, Section 6 discusses the
results and future research opportunities.
2 BACKGROUND
This section aims to give insight into key concepts
for the article, starting with the technical analysis in-
dicators used in the models, followed by the feature
selection methods.
2.1 Technical Analysis Indicator
Technical analysis indicators are vital instruments
used to examine the price trends of various financial
assets, such as stocks, currencies, and commodities.
Their main goal is to predict future market move-
ments through graphical analysis, employing mathe-
matical formulas based on historical price and trading
volume data of the assets (Shi et al., 2022).
2.1.1 Moving Average
Moving average is a statistical technique used to
smooth the volatility of a time series of data (Billah
et al., 2024), facilitating the identification of patterns
and trends by reducing random variation. It computes
the average of a set of values within a sliding window
over time, offering a clearer insight into the underly-
ing movements within the time series.
2.1.2 Standard Deviation
The standard deviation is a key metric in stock tech-
nical analysis, measuring price volatility by calculat-
ing the variability of closing prices around their mov-
ing average (Altman and Bland, 2005). It is derived
from the variance, which averages the squared differ-
ences between prices and the mean, with its square
root yielding the standard deviation. This measure is
essential for constructing Bollinger Bands, identify-
ing overbought and oversold levels, and assessing as-
set risk—where higher values indicate greater volatil-
ity and risk, while lower values suggest stability.
2.1.3 MACD
The Moving Average Convergence Divergence
(MACD) is a key technical analysis tool used to iden-
tify changes in an asset’s trend strength, direction,
momentum, and duration. By leveraging historical
data, it helps forecast price movements in financial
markets. The MACD is computed using two exponen-
tial moving averages (EMAs) (Halilbegovic, 2016),
which assign greater weight to recent data. Typically,
these EMAs are based on 26-period and 12-period
time frames. Additionally, a signal line, which is a
nine-period EMA of the MACD line, is included in
the dataset as a feature.
Several indicators stem from the MACD, includ-
ing the MACD Slope and MACD Histogram. The
MACD Slope measures the rate of change of the
MACD over time, representing its angular coefficient.
A rising MACD Slope suggests a strengthening up-
trend, whereas a falling slope indicates a downtrend.
It is computed by measuring the variance between
MACD values at different time points. The MACD
Histogram, another derivative indicator, represents
the difference between the MACD and the signal line
(MACD - Signal) (Kang, 2021), visually depicting
momentum shifts and trend changes.
2.1.4 Relative Strenght Index (RSI)
The RSI, created by J. Welles Wilder in 1978, gauges
whether a stock is overbought or oversold by analyz-
ing recent closing prices.
It is considered as an oscillator, ranging from 0
to 100. commonly applied to identify swing points,
where it is an overbought or oversold conditions of
an asset, helping to predict potential trend reversals.
This indicator can effectively predict market move-
ments by identifying overbought or oversold condi-
tions, further supporting its practical application in fi-
nancial markets (Bansal, 2016).
It is also used the indicators VSDME12 and VS-
Feature Selection for Stock Market Prediction: A Comparison of Relief and Information Gain Methods
997

DME26, which are a variation of the moving aver-
age, it is an adaptive moving average, which incor-
porates volatility and speed in the calculation. The
VSDME (which stands for Volatility and Speed Di-
vergence Moving Average), utilizes α equal to 12 and
τ of 26 for VSDME12, and for VSDME26 utilize α
of 26 and τ equal to 52.
VSDME = VSDME
α
− VSDME
τ
(1)
2.2 Feature Selection Methods
Feature selection is vital in model development.
While more features can improve performance, too
many, especially with limited training data can hinder
learning and cause overfitting. The goal is to retain
only essential attributes, remove redundancies, and
improve model efficiency (Janecek et al., 2008).
Feature selection is vital in model development.
While more features can improve performance, too
many—especially with limited training data—can
hinder learning and cause overfitting. The goal is to
retain only essential attributes, remove redundancies,
and improve model efficiency.
2.2.1 Information Gain
Information Gain is a metric used to measure the re-
duction in uncertainty or entropy in a set of data when
a characteristic (or attribute) is chosen to divide the
data. It is often used in machine learning algorithms,
such as decision trees, to determine which feature
should be used at each node. The central idea is that
dividing the data based on a characteristic should re-
sult in purer subsets, that is, with less unpredictability.
Information Gain is calculated based on, the dif-
ference between the original entropy (before splitting)
and the sum of the entropies of the subsets generated
after splitting. The greater the Information Gain of a
feature, the more relevant it is to predict the target and,
therefore, the more useful it is in building the predic-
tive model. The effectiveness of Information Gain in
selecting relevant features in high-dimensional con-
texts, such as microarray data, demonstrates its appli-
cability in different domains (Yu and Liu, 2016).
2.2.2 Relief method
The Relief an individual valuation filter method (Ur-
banowicz et al., 2018), that evaluates the relevance of
attributes based on the proximity of instances of dif-
ferent classes. For each instance in the dataset, the
algorithm identifies the closest instance of the same
class (near neighbor) and the closest instance of a dif-
ferent class (far neighbor).
It then adjusts the attribute weights based on how
those attributes help differentiate instances of differ-
ent classes. Attributes that help distinguish between
classes receive greater weight, while those that do not
make a difference have reduced weight. This method
is useful in problems with complex, high-dimensional
data, as it selects the most informative features for the
learning model.
3 RELATED WORK
With the huge amount of data generated by the finan-
cial market, more predictions are being made by Ma-
chine Learning algorithms (Jain and Vanzara, 2023).
A notable example is the application of deep learn-
ing techniques, particularly Long Short-Term Mem-
ory (LSTM) networks, to the S&P 500 dataset for
predicting stock price movements based on histori-
cal data (Kamalov et al., 2020). The study empha-
sizes the importance of daily closing values and trad-
ing volumes, analyzing data from 1990 to 2020.
The proposed model outperformed several bench-
mark models in predicting the directional movements
of the index. For example, one study applied Sup-
port Vector Regression (SVR) to predict stock prices,
focusing on preprocessing the NASDAQ (National
Association of Securities Dealers Automated Quota-
tions) dataset (Dash et al., 2023).
Technical analysis indicators like MACD, ADX,
Williams, and MFI were converted into correlation
tensors for enhanced processing in deep learning
models, including LSTM and DNN networks. This
method improved stock price predictions and buy/sell
signal detection (Kamalov et al., 2019).
A recent publication in the academic literature in-
troduces the BovDB as a benchmark dataset for re-
search in stock market prediction (Cardoso et al.,
2022). This dataset, which is publicly accessible and
pre-processed, encompasses daily stock data for all
companies listed on B3 from 1995 to 2020. Notably,
the authors have introduced a novel metric referred
to as the “factor” aimed at mitigating the influence of
significant events within the dataset. Utilizing both
the factor and the BovDB allows for a comprehensive
analysis of the historical time series of Brazilian stock
prices, tracing back to the inception of Brazil’s Real
monetary plan.
This article presents an innovative approach by in-
tegrating new financial indicators, developed from an
unprecedented dataset composed of detailed financial
information from Brazilian companies over several
decades. Unlike conventional indicators, these new
indicators capture nuances of local financial behavior,
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
998
providing a more in-depth and relevant view for pre-
dictive analysis in the national context. The creation
of this dataset not only fills a critical data gap, but
also establishes a solid foundation for future research,
allowing for more robust and contextualized analyses.
Furthermore, the use of cross-validation as part
of the methodology for feature selection is an inno-
vative approach in the context of the Brazilian stock
exchange. Although cross-validation is a technique
widely used in machine learning and feature selection
studies, its specific application in the selection of fi-
nancial attributes for analyzing the Brazilian market
is still rare.
By employing this technique, we ensure that the
results obtained are not only specific to the dataset
used, but also generalizable, increasing the reliability
and practical applicability of the conclusions. This
rigorous approach raises the methodological stan-
dard of research in emerging markets, encouraging
the adoption of more robust and replicable practices.
Theoretically, the work enriches the feature selection
literature by introducing a new perspective based on
financial indicators specific to the Brazilian market,
while, in practice, it offers valuable insights for in-
vestors, financial analysts and policymakers.
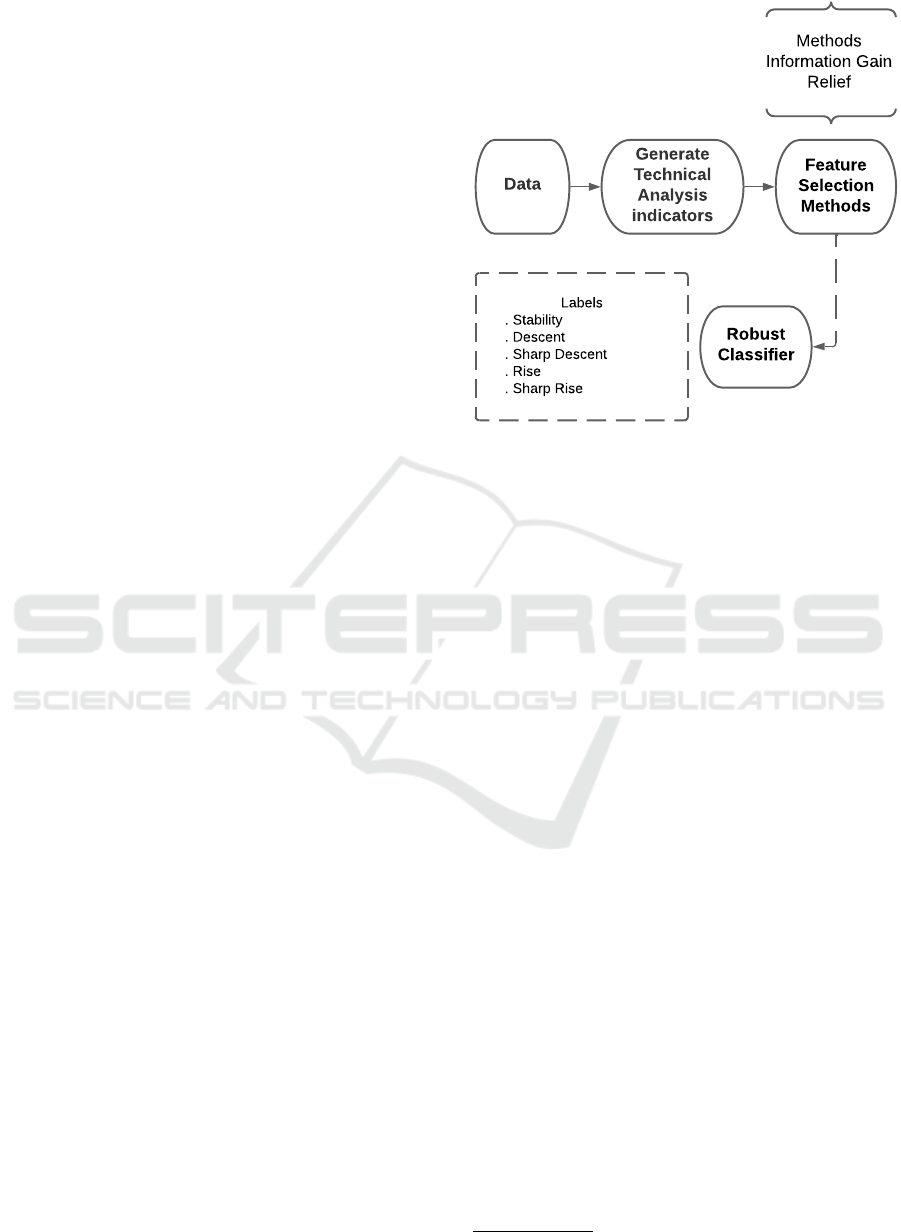
4 METHODOLOGY
This section presents the methodology for evaluating
predictive models in the Brazilian financial market.
The study constructs a dataset with daily trading data
from B3 (Brazilian Stock Exchange) covering 1995
to 2020, with a focus on 2010-2020. This dataset,
structured with price data, dates, and stock identifiers,
enables market trend analysis and serves as the foun-
dation for generating technical analysis indicators.
Feature selection methods, including Relief and
Information Gain, are applied to identify the most rel-
evant attributes. Sequential techniques such as Se-
quential Forward and Backward Selection refine the
feature set further (Aha and Bankert, 1995). Features
are eliminated iteratively, prioritizing model accuracy.
Cross-Validation ensures robust performance evalua-
tion by dividing data into k subsets, reducing bias and
improving generalization.
Stratified K-Fold Cross-Validation is used at key
feature selection points, preserving class distribu-
tions. Performance metrics such as accuracy and F1-
score are averaged across folds. Visualization tools
highlight critical feature contributions, and models
undergo final training on the entire dataset before de-
ployment. This approach minimizes overfitting and
enhances predictive reliability for the Brazilian finan-
Data
Labels
. Stability
. Descent
. Sharp Descent
. Rise
. Sharp Rise
Generate
Technical
Analysis
indicators
Feature
Selection
Methods
Robust
Classifier
Methods
Information Gain
Relief
Figure 1: Diagram methodology.
cial market.
5 RESULTS
In this chapter, we present the findings and insights
obtained from the research, organizing the discussion
into two subsections. The first subsection 5.1 focuses
on the BovDb (Cardoso et al., 2022) and (Souza et al.,
2024), offering a detailed examination of the included
tables and how we managed it. The second subsec-
tion outlines the results from the cross-validation pro-
cess and evaluates the feature selection methods em-
ployed.
5.1 Input Data
The data of Brazilian Stocks are available to the pub-
lic in text files format, organized in a raw form. The
raw data is available in B3’s website. This study
utilizes data collected from BovDb (Cardoso et al.,
2022)
2
, which is a preprocessed dataset, from the
shares in the B3, it allows a better understanding of
the market and its behave. It contains data of daily
exchange of all shares in B3 from 1995 to 2020, but
we focused on the 7 most representative shares on the
Brazilian stock market and considered only the pe-
riod of 2010 to 2020. During this shorter period of
time, the companies generated an ample amount of
data, ensuring the relevance of the analysis. BovDb
comprise five distincts tables, providing a deep view
of the market landscape.
2
https://sol.sbc.org.br/index.php/dsw/article/view/17411
Feature Selection for Stock Market Prediction: A Comparison of Relief and Information Gain Methods
999

First table is the Company table, this table cor-
relates the name and identification for every com-
pany that has had a presence in B3 between the
years of 1995 and 2020. It encompasses a total of
1728 companies within this database. The column
“id company” is the auto-incremented integer, serves
as the unique identifier for the company, functioning
as the primary key. Additionally, it is utilized as a
foreign key on the Ticker to reference the aforemen-
tioned company. And the other column is the “Com-
pany” column, refering to the company’s name.
The Ticker table stores the data of the stocks. It
relates the code of the stock for each company, the
codes are formed by a pattern of numbers and letters
that helps the investor to identify each company and
the type of share that corresponds with it, the table
contains 2540 stocks in it. The difference between
the amount of companies and stocks, is due to the fact
that a single company can have more than one type
of share. The first column is the “id ticker”, whis
is an auto incremented integer serving as the Ticker
identifier, acting as a primary key. It is also utilized
as a foreign key in both the EventPrice and Price ta-
bles to reference the former. The other column is the
“ticker”, being the company’s stock symbol. The “co-
disi” column is the stock code in B3.
The “Price” table stores the data negotiation of the
trading floor for each stock, providing us with enough
information to understand the movement of the stock
throughout the trading flor. The “date” column is the
date of trade for a stock, serves as a crucial component
in conjunction with the id ticker, collectively form-
ing a composite primary key for identifying a specific
ticket on any given date. Within the context of Event-
Price, the date, along with the id ticker and id event,
forms a composite primary key signifying the occur-
rence date of a particular event.
Each one is a column of a given date,“open” rep-
resents the opening price, ’high’ represents the high-
est price, ’low’ represents the lowest price, ’average’
represents the average price, ’close’ represents the
closing price, ’buy offer’ represents the best offering
price, ’business’ represents the quantity of transac-
tions executed with the stock, ’sell offer’ represents
the best selling price, ’amount stock’ represents the
aggregate trading volume on the stock. The last col-
umn is the “Factor” which is the combined effect of
events is considered from the most recent to the old-
est until a particular date is attained, showcasing the
chronological progression
The “Event” table presents different types of
events, containing 12 occurrences. The “id
event”
is the auto-incremented integer serves as the unique
identifier for the Event, making it the primary key.
Additionally, it functions as a foreign key on the
EventPrice to reference the aforementioned Event.
The “description” column is a description of the
event. And the “ds bovespa” is the abbreviated Event
designation, as indicated in the documentation sup-
plied by B3.
The last table is the “Eventprice” table, showing
that over time a stock can undergo different events,
this table presents the trading floor days that hap-
pened a event. It also presents if factor was applied
in a stock, and its value. For example, stock split,
in which the number of shares increases to provide
greater liquidity without affecting the total value of
the company’s capital, factor is applied in this case,
so it spossible to perform a better analysis of the stock
over time. The “factor” column is how significant is
the event on a specific stock and trade. The ”applied”
column represents if an event has occurred or not in a
specific day.
The “Price” table was used to build the Techni-
cal Analysis Indicators, that serves as features for
the Train and Test dataset. For the Moving Aver-
age and Standard Deviation calculations, we con-
ducted a thorough analysis of various stock mar-
ket trading sessions, each lasting window size of γ
length. We examined the opening, maximum, mini-
mum, average, closing, offer/buy, offer/sell, volume,
and business amount data. To determine the values for
MACD, MACD Histogram, MACD Slope, MACD
DF, MACD VSDME12, and MACD VSDME26, we
captured the opening, closing, maximum, average,
and minimum. Additionally, for the MACD Signal,
we utilized the prices from the other MACD indi-
cators, considering 9 stock market trading windows.
Similarly, for RSI, we performed analogous calcula-
tions using β stock market trading sessions for each
data point.
The lenght of the stock market trading sessions are
β lenght = 7, 14 and 21 γ lenght = 5, 10, 15, 20, 25,
30, 60, and 90 (representing the previous prices for
the ongoing analysis).
This resulted in 194 features of Technical Anal-
ysis Indicators, being necessary to normzalize it be-
cause the data was not in the same range. After ana-
lyzing the price table and considering the percentage
of gain or loss in the stock market trading sessions
ahead, we have identified 5 distinct labels. Descent
indicates a 0.5% decrease in the stock value, while
Sharp Descent signifies a 1% decrease. On the other
hand, Rise denotes a 0.5% increase, and Sharp Rise
indicates a 1% increase. Lastly, Stability represents a
negligible fluctuation in the stock value, either up or
down, by less than 0.5%.
With these data, we build the train and test dataset,
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
1000

the train dataset is composed of 15237 rows in total,
being 2756 rows of Stability, 3314 of Descent, 2612
of Sharp Descent, 3472 of Rise and 3083 of Sharp
Rise. The test dataset is composed of 3810 rows,
being 689 rows of Stability, 829 of Descent, 653 of
Sharp Descent, 868 of Rise, and 771 of Sharp Rise.
5.2 Evaluation
The prediction was performed using Random For-
est, a machine learning technique (Breiman, 2001).
The algorithm combines multiple decision trees to
improve accuracy and reduce the risk of overfitting,
making it ideal for classification and regression tasks.
In this study, we use Random Forest to evaluate the
performance of the model based on selected attribute
data. The model was configured to generate 100 deci-
sion trees, without depth restriction, allowing the trees
to grow to their maximum height to capture complex
interactions in the data. Data sampling was performed
with 100% of the dataset in each tree, ensuring a com-
plete view during the construction of each tree. We
did not calculate the importance of attributes and all
characteristics were used in the trees without restric-
tion. Additionally, out-of-bag validation has been dis-
abled, with a focus on other evaluation metrics to en-
sure model robustness.
The model performance evaluation was carried
out using accuracy and F1-Score metrics. To calcu-
late these metrics, a simple average of the results ob-
tained in the 9 folds of the cross-validation process
was applied. The final accuracy was calculated as the
simple average of the accuracies of each of the k-fold
cross-validation iterations.
Specifically, in the first set of experiments, the k-
fold cross-validation technique with 9 folds was used.
Then, in the second part of the experiment, we ap-
plied stratified k-fold cross-validation, ensuring that
the distribution of classes was maintained in each of
the 9 folds, which is particularly important in unbal-
anced data sets. During this process, performance
metrics, such as accuracy and F1-Score, were cal-
culated and the simple average of these metrics was
used to evaluate the overall performance of the model.
This ensures that the model is trained and tested on
representative distributions of classes across all folds,
avoiding any variation that may occur randomly in
balanced datasets. Furthermore, the use of stratifica-
tion helps to reduce variation in performance metrics,
such as accuracy and F1-score, providing a more con-
sistent evaluation of the model.
Figure 2 and 3 shows the performance of the mod-
els as features are removed according to the Informa-
tion Gain and Relief method, respectively. It is worth
highlighting that, it was employed Random Forest as
the classifier, in which, using all available features
(194 total) achieved an average F1-Score of 0.475 and
an accuracy of 0.476 in the test data. Each graph ilus-
tration presents an orange dot and an green dot, which
means, the highest accuracy and a limit indicating that
the removal of features from that point onwards dras-
tically reduces the accuracy of the models. Showing
the importance of the remaining features.
Our first analysis addresses the Information Gain
method. Initially the accuracy increases as the fea-
tures are being removed, until reaching its peak, and
then declining. The order in which the features were
eliminated corresponds to the reverse sequence ob-
tained from the Information Gain feature selection
approach. The accuracy results shown in the graphs
are derived from Cross-Validation conducted without
stratification.
Figure 2: Information Gain features removal.
In this analysis, the OD indicates that the fea-
ture count stands at 79. Initially, the model trained
achieved an accuracy of 0.493, in the GD, where the
feature count was 38, the model delivered an accuracy
of 0.483.
In sequence, the same approach is adopted with
the Rellief method. The accuracy increases as the fea-
tures are being removed, the OD and GD are closer
to each other, in comparison to the Information Gain
method.
In our analysis, the OD on the chart includes
73 distinct features. We initially employed Cross-
Validation, which yielded an accuracy of 0.498, then
we applied this methodology to the GD, which con-
sists of 52 features, the model’s first accuracy mea-
surement was 0.490.
Note that the Relief method initially performs bet-
ter, achieving higher heals as it removes the initial
features. However, after obtaining these initial accu-
racies superior to the Information Gain method, the
Relief method models were unable to maintain them
over time, causing the curve of accuracies to begin
Feature Selection for Stock Market Prediction: A Comparison of Relief and Information Gain Methods
1001
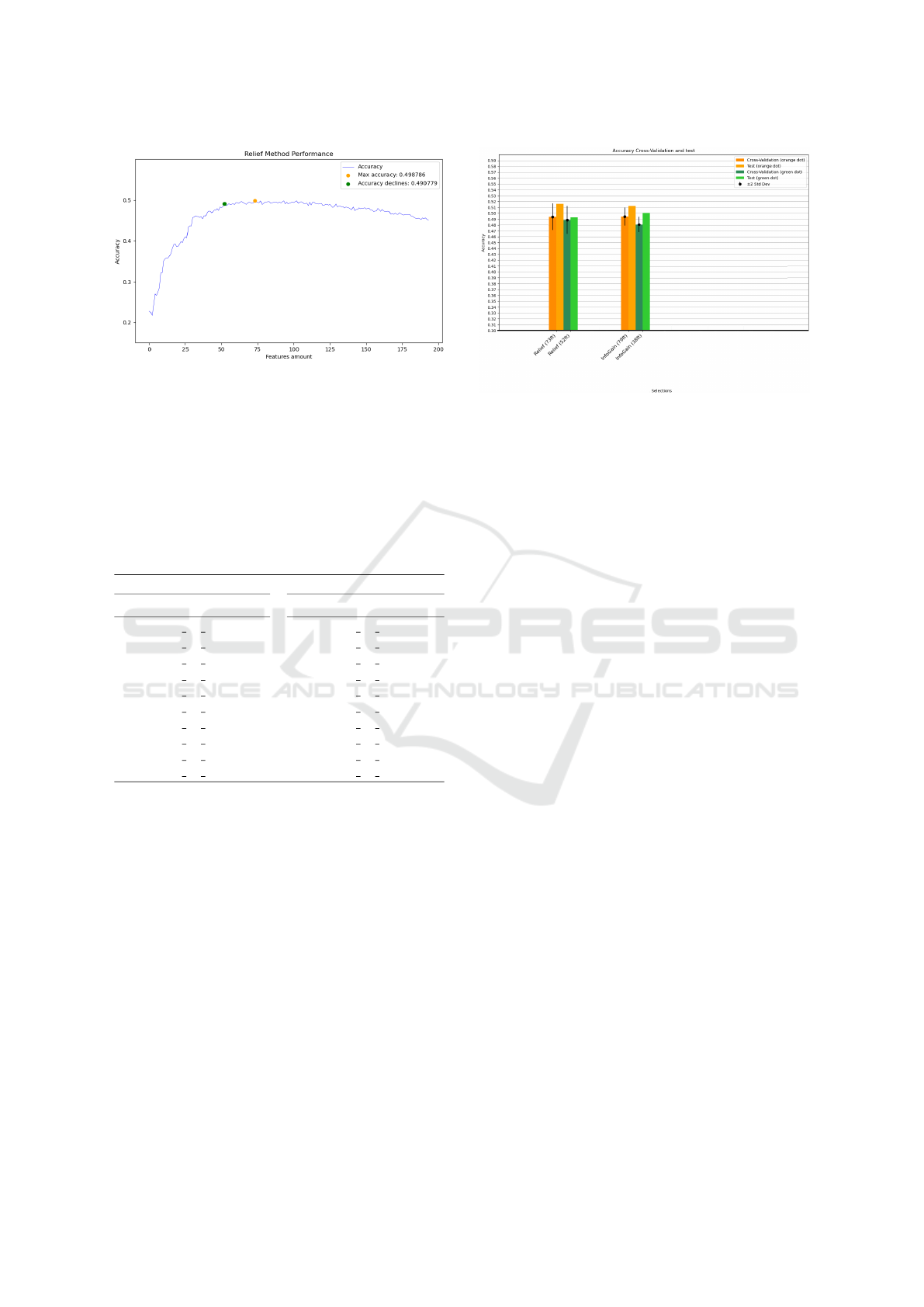
Figure 3: Relief method features removal.
earlier. This can be better observed when we com-
pare the two GDs, where the Relief method with 52
features achieved an accuracy of 0.490 and the Infor-
mation Gain method with 14 fewer features achieved
an accuracy of 0.483.
The Table 1 presents the top 10 most relevant fea-
tures according to Information Gain and the Relief
method.
Table 1: Features selected by Information Gain and relief.
Information Gain Relief
Rank Features Rank Features
1 sd 90 average 1 sd 90 offer/sell
2 sd 90 minimum 2 sd 90 offer/buy
3 sd 90 opening 3 sd 90 minimum
4 sd 90 closing 4 sd 90 opening
5 sd 90 maximum 5 sd 90 closing
6 sd 60 opening 6 sd 90 average
7 sd 90 offer/sell 7 sd 90 maximum
8 sd 90 offer/buy 8 sd 60 offer/buy
9 sd 60 maximum 9 sd 60 offer/sell
10 sd 60 minimum 10 rsi 21 average
The standard deviation financial indicator stands
out as extremely relevant in both methods, occupying
all positions in the top 10 in each of them, except the
tenth position in the Relief method. In the information
gain method, eight standard deviation indicators refer
to the period of 90 windows and two to the period of
60 windows. In the Relief method, seven indicators
correspond to the period of 90 windows, two to the
period of 60 windows, while the tenth place was oc-
cupied by the RSI in 21 windows.
The Relief method with 73 features utilizing Strat-
ified K-fold Cross-Validation achieved an accuracy of
0.493. And the model developed through Stratified
K-fold Cross-Validation was evaluated using a test
dataset, where it achieved an accuracy of 0.515 and
an F1-Score of 0.516. Applying the same approach
to the GD, representing a model with 52 features, it
initially achieved an accuracy of 0.488 with Strati-
Figure 4: Graphic Information Gain and Relief methods.
fied K-fold Cross-Validation and the model developed
through Stratified K-Fold Cross-Validation was eval-
uated using a test dataset, where it achieved an accu-
racy of 0.492 and an F1-Score of 0.493
In this case of Information Gain, the OD is mark-
ing where the number of features is 79. Then it
is utilized Stratified K-fold Cross-Validation to build
a new model, after the training it achieved an ac-
curacy of 0.494. The model built with Stratified
Cross-Validation was assessed using the test dataset,
it achieved an accuracy of 0.512 and F1-Score of
0.512. The same procedure was adopted for the GD,
with Stratified Cross-Validation it achieved an accu-
racy of 0.480, and then this model was assessed using
the test dataset, it achieved an accuracy of 0.500 and
F1-Score of 0,501.
The accuracy values around 50% can be partially
explained by the complexity of the financial market,
but also by the multiclass nature of our classifica-
tion problem. The dataset was structured to predict
five distinct price movement classes which inherently
makes the classification task more challenging. In fi-
nancial prediction, price movements are often subtle
and influenced by numerous external factors, and dis-
tinguishing between similar classes, such as Stability
and small rises or descents, adds complexity.
6 CONCLUSIONS
This research explored the effectiveness of Informa-
tion Gain and Relief methods in improving predictive
performance in the Brazilian financial market, using
Random Forest models. The data set, composed of
194 technical analysis indicators, was subjected to at-
tribute selection processes, with the methods evalu-
ated by progressive attribute removal and validation
by Cross-Validation.
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
1002

The results presented provide valuable insights for
the development of more efficient models in the con-
text of the Brazilian financial market, and future stud-
ies could explore the application of other attribute se-
lection methods or the adaptation of the methodology
in different financial scenarios.
For future works, we intend to explore the poten-
tial of the selected features for new analyses, lever-
aging these optimized features in advanced machine
learning models, such as deep learning architectures,
to enhance prediction accuracy.
ACKNOWLEDGEMENTS
The authors would like to thank FAPERGS
(24/2551-0001396-2, 23/2551-0000773-8), CNPq
(305805/2021-5) and FAPERGS/CNPq (23/ 2551-
0000126-8). Fabian thanks to Fesurv-UniRV for the
pay leave, which helped to collaborate in this work.
REFERENCES
Aha, D. W. and Bankert, R. L. (1995). A comparative eval-
uation of sequential feature selection algorithms. In
Pre-proceedings of the Fifth International Workshop
on Artificial Intelligence and Statistics.
Altman, D. G. and Bland, J. M. (2005). Standard deviations
and standard errors. In Bmj. British Medical Journal
Publishing Group.
Araujo, G. S. and Gaglianone, W. P. (2023). Machine learn-
ing methods for inflation forecasting in brazil: New
contenders versus classical models. In Latin Ameri-
can Journal of Central Banking. Elsevier.
Bansal, S. (2016). Investigating the efficacy of rsi in the
nifty 50 index. In Global journal of Business and In-
tegral Security.
Billah, M. M., Sultana, A., Bhuiyan, F., and Kaosar, M. G.
(2024). Stock price prediction: comparison of dif-
ferent moving average techniques using deep learn-
ing model. In Neural Computing and Applications.
Springer.
Bouri, E., Demirer, R., Gupta, R., and Sun, X. (2020).
The predictability of stock market volatility in emerg-
ing economies: Relative roles of local, regional, and
global business cycles. In Journal of Forecasting. Wi-
ley Online Library.
Breiman, L. (2001). Random forests. In Machine learning.
Springer.
Cardoso, F. C., Malska, J. A. V., Ramiro, P. J., Lucca, G.,
Borges, E. N., de Mattos, V. L. D., and Berri, R. A.
(2022). Bovdb: a data set of stock prices of all com-
panies in b3 from 1995 to 2020. In Journal of Infor-
mation and Data Management.
Chandrashekar, G. and Sahin, F. (2014). A survey on fea-
ture selection methods. In Computers & electrical en-
gineering. Elsevier.
Chen, C.-P. and Metghalchi, M. (2012). Weak-form market
efficiency: Evidence from the brazilian stock market.
In International Journal of Economics and Finance.
Citeseer.
Cuervo, R. (2023). Predictive ai for sme and large enterprise
financial performance management. In arXiv preprint
arXiv:2311.05840.
Dash, R. K., Nguyen, T. N., Cengiz, K., and Sharma, A.
(2023). Fine-tuned support vector regression model
for stock predictions. In Neural Computing and Ap-
plications. Springer.
Halilbegovic, S. (2016). Macd-analysis of weaknesses of
the most powerful technical analysis tool. In Indepen-
dent Journal of Management & Production. Instituto
Federal de Educac¸
˜
ao, Ci
ˆ
encia e Tecnologia de S
˜
ao
Paulo.
Htun, H. H., Biehl, M., and Petkov, N. (2023). Survey of
feature selection and extraction techniques for stock
market prediction. In Financial Innovation. Springer.
Jain, R. and Vanzara, R. (2023). Emerging trends in
ai-based stock market prediction: A comprehensive
and systematic review. In Engineering Proceedings.
MDPI.
Janecek, A., Gansterer, W., Demel, M., and Ecker, G.
(2008). On the relationship between feature selection
and classification accuracy. In New challenges for fea-
ture selection in data mining and knowledge discov-
ery. PMLR.
Kamalov, F., Smail, L., and Gurrib, I. (2019). Stock
price prediction using technical indicators: a predic-
tive model using optimal deep learning. In Learning.
Kamalov, F., Smail, L., and Gurrib, I. (2020). Forecasting
with deep learning: S&p 500 index. In 2020 13th In-
ternational Symposium on Computational Intelligence
and Design (ISCID). IEEE.
Kang, B.-K. (2021). Improving macd technical analysis by
optimizing parameters and modifying trading rules:
evidence from the japanese nikkei 225 futures market.
In Journal of Risk and Financial Management. MDPI.
Kohn, K. and Moraes, C. d. (2007). O impacto das
novas tecnologias na sociedade: conceitos e carac-
ter
´
ısticas da sociedade da informac¸
˜
ao e da sociedade
digital. In XXX Congresso Brasileiro de Ci
ˆ
encias da
Comunicac¸
˜
ao.
Shi, Y., Li, B., Long, W., and Dai, W. (2022). Method for
improving the performance of technical analysis indi-
cators by neural network models. In Computational
Economics. Springer.
Souza, A. S., Lucca, G., Borges, E. N., Cardoso, F. C., Dal-
mazo, B. L., and Berri, R. (2024). Dataset for Intraday
Analysis of B3 stock prices.
Urbanowicz, R. J., Olson, R. S., Schmitt, P., Meeker, M.,
and Moore, J. H. (2018). Benchmarking relief-based
feature selection methods for bioinformatics data min-
ing. In Journal of biomedical informatics. Elsevier.
Yu, L. and Liu, H. (2016). Feature selection for high-
dimensional data: A fast correlation-based filter so-
lution. In Proceedings of the 20th international con-
ference on machine learning (ICML-03).
Feature Selection for Stock Market Prediction: A Comparison of Relief and Information Gain Methods
1003
