
SLO and Cost-Driven Container Autoscaling on Kubernetes Clusters
Angelo Marchese
a
and Orazio Tomarchio
b
Dept. of Electrical Electronic and Computer Engineering, University of Catania, Catania, Italy
Keywords:
Cloud Computing, Container Technology, Kubernetes Autoscaler, Service Level Objectives, Cost Monitoring.
Abstract:
Modern web services must meet critical non-functional requirements such as availability, responsiveness,
scalability, and reliability, which are formalized through Service Level Agreements (SLAs). These agree-
ments specify Service Level Objectives (SLOs), which define performance targets like uptime, latency, and
throughput, essential for ensuring consistent service quality. Failure to meet SLOs can result in penalties and
reputational damage. Service providers also face the challenge of avoiding over-provisioning resources, as this
leads to unnecessary costs and inefficient resource use. To address this, autoscaling mechanisms dynamically
adjust the number of service replicas to match user demand. However, traditional autoscaling solutions typi-
cally rely on low-level metrics (e.g., CPU or memory usage), making it difficult for providers to optimize both
SLOs and infrastructure costs. This paper proposes an enhanced autoscaling methodology for containerized
workloads in Kubernetes clusters, integrating SLOs with a cost-driven autoscaling policy. This approach over-
comes the limitations of conventional autoscaling by making more efficient decisions that balance service-level
requirements with operational costs, offering a comprehensive solution for managing containerized applica-
tions and their infrastructure in Kubernetes environments. The results, obtained by evaluating a prototype of
our system in a testbed environment, show significant advantages over the vanilla Kubernetes Horizontal Pod
Autoscaler.
1 INTRODUCTION
Microservices architecture is a widely used architec-
tural style for enterprise software that breaks down
large applications into a series of small, modular,
independently deployable microservices (Salii et al.,
2023).
For such applications, the distribution of work-
load across a cluster of servers can be achieved in a
horizontal manner, obviating the necessity for a sin-
gle, costly server. The allocation of resources can be
managed with precision by replicating or allocating
greater resources to microservices experiencing the
highest demand or those requiring greater reliability.
It is evident that microservice applications exhibit
the characteristics that render them as ”cloud-native”,
that is to say, they possess the capability to exe-
cute and expand within contemporary, evolving en-
vironments such as public, private and hybrid clouds
(Hongyu and Anming, 2023).
Services developed and organized in such a way,
are complex systems designed to meet a wide range of
a
https://orcid.org/0000-0003-2114-3839
b
https://orcid.org/0000-0003-4653-0480
non-functional requirements that are critical to their
business operations, including service availability, re-
sponsiveness, scalability, and reliability. These re-
quirements are typically formalized through Service
Level Agreements (SLAs) between service providers
and consumers, which outline the operational bound-
aries within which a service must perform. An SLA
consists of one or more Service Level Objectives
(SLOs), which define high-level performance indi-
cators that must be maintained throughout the ser-
vice delivery period. These indicators represent the
desired state of service, such as uptime, latency, or
throughput, and are essential for ensuring consistent
service quality. Failing to meet SLOs can result
in contractual penalties and damage to the service
provider’s reputation.
Furthermore, it is also important, from a service
provider perspective not to over-provision resource
allocation in a deployment environment while consid-
ering a given SLO, as it would result in additional
costs and non-optimal resource utilization (Gupta
et al., 2017). Service providers are then challenged
to find the right balance between meeting SLOs and
optimizing resource usage and costs.
The adoption of cloud computing technology
72
Marchese, A. and Tomarchio, O.
SLO and Cost-Driven Container Autoscaling on Kubernetes Clusters.
DOI: 10.5220/0013482100003950
In Proceedings of the 15th International Conference on Cloud Computing and Services Science (CLOSER 2025), pages 72-79
ISBN: 978-989-758-747-4; ISSN: 2184-5042
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
and service orchestration systems has emerged as a
promising solution to address this challenge, thanks to
the cloud infrastructure’s reliability, availability, scal-
ability, and elasticity, as well as the automation ca-
pabilities in service management provided by orches-
tration systems (Mukherjee et al., 2024; Calcaterra
et al., 2021). In particular, the service autoscaling
mechanisms offered by orchestration systems, along
with the ability to rapidly provision and de-provision
cloud infrastructure, are key features for finding the
right balance between meeting SLOs and optimizing
costs.
Service autoscaling mechanisms help minimize
over or under provisioning issues by dynamically ad-
justing the number of service replicas to match the
current user request load (Chen et al., 2018). How-
ever, most orchestration solutions only allow to scale
the service based on the value of a low-level metric
(i.e., a metric considering low-level monitoring indi-
cators such as service CPU or memory usage) and in
this way it is hard for a service provider to control the
required high-level SLO and to optimize the infras-
tructure costs.
In this paper we propose an enhanced autoscaling
methodology, with particular reference to container-
ized workloads utilizing Kubernetes clusters. The
proposed approach addresses the limitations of con-
ventional autoscaling methodologies by integrating
an SLO and a cost-driven autoscaling policy. This fa-
cilitates more efficient autoscaling decisions that bal-
ance both service-level requirements and operational
costs, offering a more comprehensive solution for
managing containerized applications in Kubernetes
environments and the infrastructure required for their
execution.
The rest of the paper is organized as follows. Sec-
tion 2 provides some background information about
the Kubernetes autoscaling policy and discusses in
more detail some of its limitations that motivate our
work. Section 3 presents our proposed approach, de-
tailing its implementation, while Section 4 discusses
the evaluation results from a testbed environment. Re-
lated works are reviewed in Section 5, and Section 6
concludes the work.
2 KUBERNETES AUTOSCALING
Kubernetes is today the de-facto orchestration plat-
form for the lifecycle management of containerized
applications deployed on large-scale node clusters
(Kubernetes, 2024; Gannon et al., 2017). A typical
Kubernetes cluster comprises a control plane and a set
of worker nodes. The control plane encompasses vari-
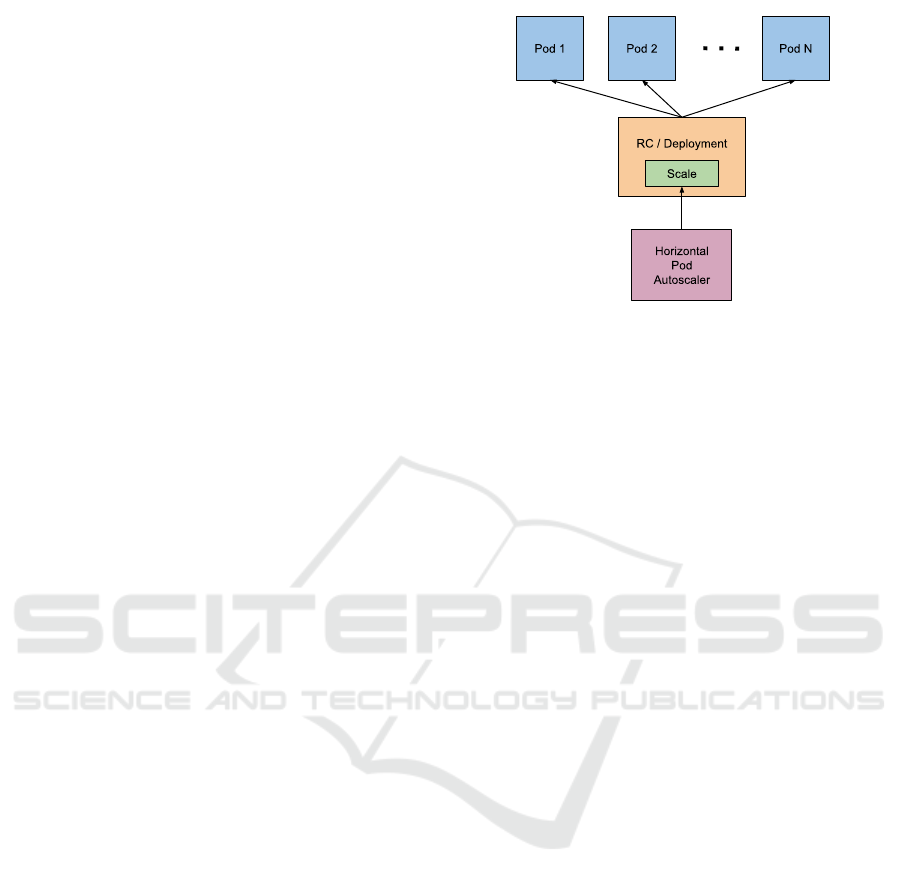
Figure 1: Kubernetes Horizontal Pod Autoscaler.
ous management services running within one or more
master nodes, while the worker nodes serve as the
execution environment for containerized workloads.
In Kubernetes, the fundamental deployment units are
Pods, each containing one or more containers and
managed by a Deployment resource.
The Kubernetes Horizontal Pod Autoscaler (HPA)
is a control plane component that adjusts the number
of Pods managed by a Deployment based on the aver-
age CPU or memory usage of those Pods. Configured
with a target value, the HPA periodically scales the
number of Pods to ensure that their average resource
usage aligns with the desired target. Equation 1 shows
the HPA algorithm with a target value on the average
CPU usage.
r
d
= ceil(r
c
∗ (cpu
c
/cpu
d
)) (1)
where r
d
is the desired number of replicas, r
c
the
current number of replicas, cpu
c
the current average
CPU usage, cpu
d
the desired CPU usage and ceil()
is a function that gives as output the greatest integer
less than or equal to the input argument. The main
limitation of the HPA algorithm is that it relies on
target values specified for low-level resource usage
metrics, which are challenging to define and correlate
with high-level indicators such as SLOs and infras-
tructure costs. Incorrectly defining these target values
can lead to inefficient scaling decisions. Setting low
resource usage targets triggers frequent scaling up ac-
tions, improving service performance but resulting in
infrastructure over provisioning and higher costs. On
the other hand, setting high targets results in frequent
scaling down actions, reducing costs but potentially
causing frequent SLOs violations.
SLO and Cost-Driven Container Autoscaling on Kubernetes Clusters
73

3 PROPOSED APPROACH
3.1 General Model
Building on the limitations discussed in Section 2, this
work introduces an SLO and cost-driven autoscaling
policy specifically designed for containerized work-
loads running on Kubernetes clusters. The primary
goal is to address the shortcomings of traditional au-
toscaling methods, such as the Kubernetes Horizontal
Pod Autoscaler (HPA), which typically relies on low-
level service resource usage metrics (e.g., CPU and
memory utilization). These methods require contin-
uous monitoring and configuration with target values
for service resource consumption, and scaling deci-
sions are based on achieving these predefined targets.
Our proposed autoscaling policy, whose general
model is shown in Figure 2, aims to move beyond this
resource-centric approach by integrating performance
objectives (SLOs) and cost considerations into the
scaling process. This enables more efficient autoscal-
ing decisions that balance both service-level require-
ments and operational costs, offering a more compre-
hensive solution for managing containerized applica-
tions in Kubernetes environments and the infrastruc-
ture required for their execution.
The core idea of the proposed approach is based
on the principle that an effective service autoscal-
ing policy must ensure acceptable performance while
minimizing infrastructure costs, especially in the face
of fluctuating user request workloads. To achieve this,
the policy should continuously monitor both the ser-
vice’s response time and the associated infrastructure
costs through a monitoring framework, adjusting the
system to meet predefined targets for these metrics.
By dynamically balancing performance and cost, the
approach aims to optimize resource allocation in real-
time, ensuring both high-quality service delivery and
cost-efficiency. Further details on the proposed cus-
tom autoscaler and the monitoring framework are pro-
vided in the following subsections.
3.2 Custom Pod Autoscaler
The proposed custom Pod autoscaler operates as a
Deployment within the Kubernetes control plane and
is built on top of the open source Custom Pod Au-
toscaler framework
1
.
The autoscaler is configured through a CustomPo-
dAutoscaler Kubernetes custom resource which de-
fine a scaling configuration for a Deployment. A Cus-
tomPodAutoscaler resource, whose schema is shown
1
https://custom-pod-autoscaler.readthedocs.io
apiVersion: custompodautoscaler.com/v1
kind: CustomPodAutoscaler
metadata:
name: nginx-autoscaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
runPeriod: 30000
stabilizationWindow: 10000
cost: 100
slo:
p: 99th
window: 20
target: 300
Listing 1: Example of a CustomPodAutoscaler resource.
in Listing 1, contains a spec property with five sub-
properties: scaleTargetRef, runPeriod, stabilization-
Window, cost and slo. The scaleTargetRef property
identifies the target Deployment to scale. The runPe-
riod property determines the time interval, in millisec-
onds, between two consecutive executions of the au-
toscaling algorithm. The stabilizationWindow prop-
erty defines the time interval, in milliseconds, follow-
ing a scaling action during which the autoscaler can-
not take further scaling actions for the Deployment.
The cost property represents the desired target for the
overall hourly cost of the cluster nodes. The slo prop-
erty specifies a target SLO for the response time of the
Deployment and contains three sub-fields: p, window
and target. The target field represents the target SLO
value, in milliseconds, for the p-quantile of the De-
ployment response time over the time period defined
by the window field.
For each periodic execution of the autoscaling al-
gorithm the number of replicas for the Deployment is
determined by Equation 2.
r
d
= ceil(k ∗ r
c
) (2)
with:
k = w
rt
∗ (rt
c
/rt
d
) + w
c
∗ (c
d
/c
c
) (3)
where r
d
is the desired number of replicas, r
c
the
current number of replicas and k a multiplier factor.
The value of the k parameter is determined as the
weighted average between the response time SLO ra-
tio (rt
c
/rt
d
) and the cost ratio (c
d
/c
c
). The response
time SLO ratio represents the relationship between
the current p-quantile of the response time rt
c
and the
target SLO response time rt
d
. A ratio greater than one
indicates SLO violations, signaling the need to scale
up the number of replicas. Conversely, a ratio below
one indicates no SLO violations, allowing for a reduc-
tion in replicas to lower infrastructure costs. The cost
CLOSER 2025 - 15th International Conference on Cloud Computing and Services Science
74

Custom Autoscaler
R
1
R
2
R
3
S
Response
time SLO
Monitoring framework
Target
infrastructure
costs
Current response
time
Current
infrastructure
costs
Figure 2: General model of the proposed approach.
ratio reflects the relationship between the desired tar-
get cost c
d
and the currently predicted cost c
c
. A ratio
greater than one indicates that the current predicted
costs are below the target, allowing for scaling up the
number of replicas to improve performance. On the
other hand, a ratio lower than one indicates predicted
costs exceed the target, necessitating a scale down of
replicas to reduce costs.
The w
rt
and w
c
parameters are in the range be-
tween zero and one and their sum is equal to one. By
adjusting the values of the w
rt
and w
c
parameters, dif-
ferent weights are assigned to the response time SLO
and cost ratios, respectively, in determining the value
of the k parameter. A value of w
rt
significantly higher
than w
c
indicates that scaling actions are primarily
driven by the need to meet SLO targets. Conversely, if
w
c
is much higher than w
rt
, scaling actions are primar-
ily guided by the need to keep costs below the maxi-
mum target.
3.3 Monitoring Framework
The real-time service response times and infrastruc-
ture cost metrics are continuously collected by a
comprehensive monitoring framework (Marchese and
Tomarchio, 2024), as depicted in Figure 3, and are
made accessible to the custom autoscaler for dynamic
scaling decisions.
At the core of this monitoring framework is the
Prometheus
2
metrics server, a database designed to
collect, store, and query time series data. Prometheus
periodically gathers metrics from various exporters
and makes them available through the PromQL query
language, allowing for detailed insights and real-time
monitoring. The Prometheus server is deployed as a
Kubernetes Deployment within the control plane.
Service response time metrics are collected us-
ing the Istio
3
framework, a service mesh implemen-
2
https://prometheus.io
3
https://istio.io
tation that manages Pod communication within the
Kubernetes cluster. The Istio control plane is in-
stalled within the cluster and automatically injects a
sidecar container running an Envoy proxy into each
Pod upon creation. These Envoy proxies intercept all
traffic between Pods, providing fine-grained observ-
ability. They expose detailed traffic statistics through
metrics exporters, which can then be queried by the
Prometheus server to capture real-time service re-
sponse times.
Infrastructure cost metrics are collected using the
OpenCost agent and node exporters. OpenCost is
a vendor neutral framework designed for measur-
ing and allocating cloud infrastructure and container
costs. Specifically built for Kubernetes environments,
OpenCost enables real-time cost monitoring, show
back, and charge back, providing valuable insights
into resource consumption and associated expenses.
The OpenCost agent, which runs as a Deploy-
ment within the Kubernetes control plane, collects
node CPU and memory metrics from the Prometheus
server. It then generates infrastructure cost metrics
based on a a pricing model and the collected data,
which are subsequently stored within Prometheus for
further analysis. Node exporters, deployed as Dae-
monSets on each cluster node, continuously monitor
and report CPU and memory usage, and expose those
metrics to the Prometheus server.
4 EVALUATION
The proposed solution has been evaluated by us-
ing a sample application generated using the µBench
benchmarking tool (Detti et al., 2023). µBench
enables the generation of Kubernetes manifests for
service-mesh topologies with one or multiple mi-
croservices, each running a specific function. Among
the pre-built functions in µBench, the Loader func-
tion models a generic workload that stresses node re-
SLO and Cost-Driven Container Autoscaling on Kubernetes Clusters
75
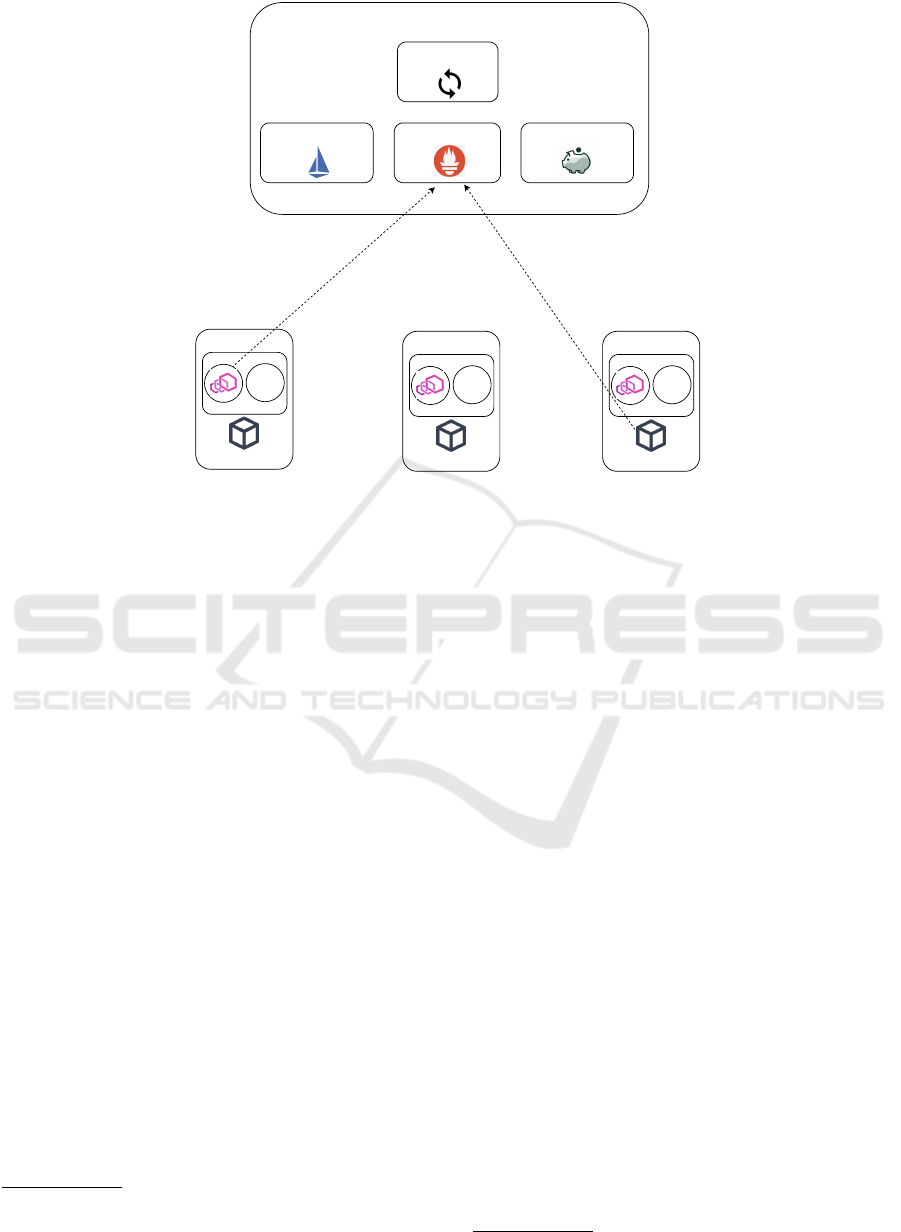
Kubernetes control plane
worker node
Prometheus server
Custom autoscaler
node exporter
Istio control plane OpenCost agent
node resource metrics
C
1
worker node
node exporter
C
1
worker node
node exporter
C
1
Pod
Envoy proxy
response time metrics
Figure 3: Monitoring framework.
sources when processing HTTP requests. When in-
voked, the Loader function computes an N number of
decimals of π. The larger the interval, the greater the
complexity and stress on the CPU. Additional stress
on node memory can be configured by adjusting the
amount of memory required by the function for each
computation. For this work, a single-service applica-
tion has been generated as a Kubernetes Deployment
with resource requirements of 0.5 vCPU and 250MB
of memory.
The test bed environment for the experiments con-
sists of a Rancher Kubernetes Engine 2 (RKE2)
4
Ku-
bernetes cluster with one master node for the con-
trol plane and a pool of worker nodes. These nodes
are deployed as virtual machines on a Proxmox
5
en-
vironment and configured with 2 vCPU and 8GB of
RAM. Autoscaling of worker nodes is managed by
the kproximate
6
cluster autoscaler, which communi-
cates with the Proxmox API server to dynamically
provision and de-provision virtual machines based on
the resource required by the service replicas. A pric-
ing model that charges one unit of cost per vCPU/hour
and one unit of cost per 1GB of RAM/hour is used to
calculate the overall cost of provisioned cluster nodes.
Black box experiments are conducted by evaluat-
ing the end-to-end response time of the sample appli-
cation and the overall infrastructure costs when HTTP
requests are sent to the application service with a
4
https://docs.rke2.io
5
https://www.proxmox.com
6
https://github.com/jedrw/kproximate
specified number of virtual users each sending one
request every second in parallel. Requests to the ap-
plication are sent through the k6 load testing utility
7
from a node inside the same network where cluster
nodes are located. This setup minimizes the impact
of network latency on the application response time.
Each experiment consists of 10 trials, during which
the k6 tool sends requests to the application for 30
minutes. For each trial, statistics about the application
response time are measured and averaged with those
of the other trials of the same experiment. An SLO of
300ms for the 90th of the application response time
and an overall cost of 40 units both over a 30 minutes
window are fixed as target values. For each experi-
ment, we compare the performances of the proposed
custom autoscaler with those of the Kubernetes Hor-
izontal Pod Autoscaler. The custom autoscaler has a
run period and stabilization window set to 30 seconds,
with the autoscaling algorithm parameters w
rt
and w
c
each assigned a value of 0.5.
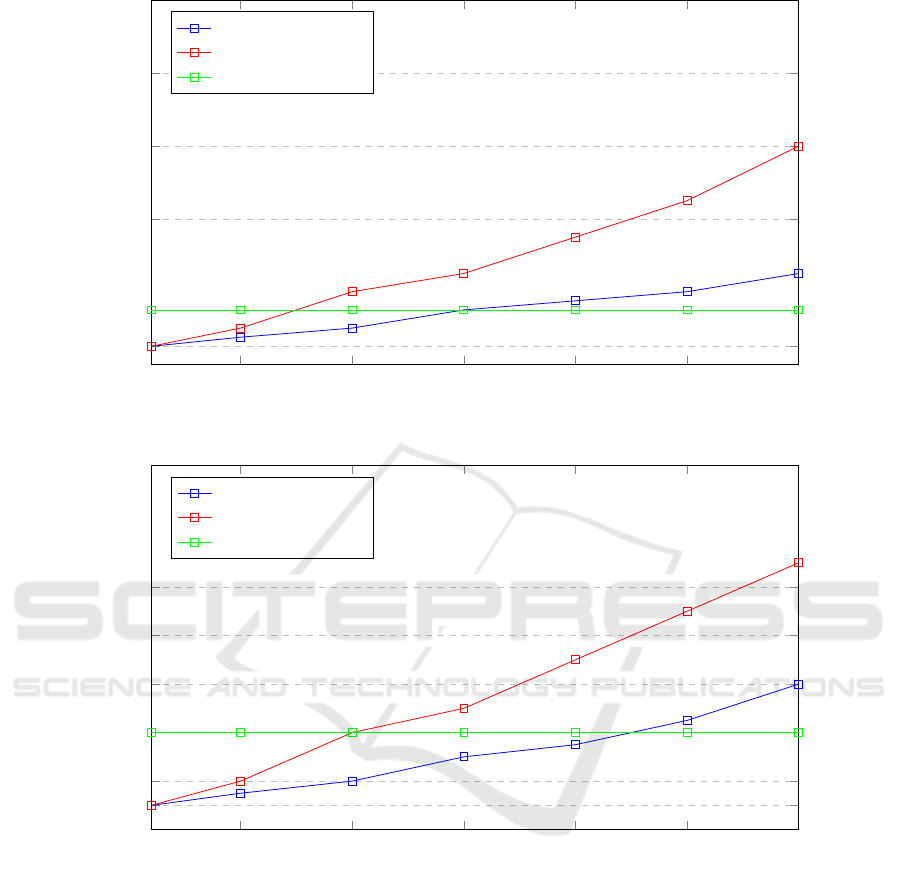
Figures 4 and 5 present the results of the experi-
ments. The first graph shows the 90th percentile of
the application response time in relation to the num-
ber of virtual users concurrently sending requests,
while the second graph illustrates the cumulative in-
frastructure costs for each experiment. Across all ex-
periments, the proposed approach consistently out-
performs the Kubernetes HPA in both application re-
sponse time and infrastructure costs. At lower vir-
tual user counts, the performance of the proposed ap-
7
https://k6.io
CLOSER 2025 - 15th International Conference on Cloud Computing and Services Science
76
10
50
100
150
200
250
300
0.1
0.3
0.8
1.2
1.6
2
Virtual users
90th percentile response time (ms)
Custom autoscaler
Kubernetes HPA
SLO target
Figure 4: Service response time.
10
50
100
150
200
250
300
10
20
40
60
80
100
150
Virtual users
cost units
Custom autoscaler
Kubernetes HPA
SLO target
Figure 5: Infrastructure costs.
proach is similar to that of the Kubernetes HPA, as
the application experiences limited load and minimal
infrastructure requirements. However, as the number
of virtual users increases, the proposed approach be-
gins to significantly outperform the Kubernetes HPA,
with more noticeable improvements at higher user
counts. Both response time and infrastructure costs
grow more rapidly with the Kubernetes HPA com-
pared to the proposed approach.
5 RELATED WORK
In the literature, there is a variety of works that pro-
pose extensions of the Kubernetes platform in order
to devise custom Pod autoscaling solutions aimed at
ensure service response times while minimizing in-
frastructure costs (Tran et al., 2022; Do et al., 2025).
In (Marie-Magdelaine and Ahmed, 2020) authors
propose a proactive autoscaling framework that uses
a learning-based forecast model to dynamically ad-
just the resource pool, both horizontally and verti-
cally. The framework uses a proactive autoscaling al-
SLO and Cost-Driven Container Autoscaling on Kubernetes Clusters
77

gorithm based on Long Short-Term Memory (LSTM)
to improve the end-to-end latency for cloud-native ap-
plications.
Libra (Balla et al., 2020) is an adaptive autoscaler,
which automatically detects the optimal resource set
for a single Pod, then manages the horizontal scaling
process. Additionally, if the load or the underlying
virtualized environment changes, Libra adapts the re-
source definition for the Pod and adjusts the horizon-
tal scaling process accordingly.
In (Yuan and Liao, 2024) authors propose a pre-
dictive autoscaling Kubernetes operator based on time
series forecasting algorithms, aimed to dynamically
adjust the number of running instances in the cluster
to optimize resource management. In this work, the
Holt–Winter forecasting method and the Gated Re-
current Unit (GRU) neural network, two robust time
series forecasting algorithms, are employed and dy-
namically managed.
Gwydion (Santos et al., 2025), is a microservices-
based application autoscaler that enables different au-
toscaling goals through Reinforcement Learning (RL)
algorithms. Gwydion is based on the OpenAI Gym
library and is aimed to bridge the gap between RL
and autoscaling research by training RL algorithms
on real cloud environments for two opposing reward
strategies: cost-aware and latency-aware. Gwydion
focuses on improving resource usage and reducing the
service response time by considering microservice in-
ter dependencies when scaling horizontally.
In (Pramesti and Kistijantoro, 2022) an autoscaler
based on response time prediction is proposed for mi-
croservice applications running in Kubernetes envi-
ronments. The prediction function is developed using
a machine learning model that features performance
metrics at the microservice and node levels. The re-
sponse time prediction is then used to calculate the
number of Pods required by the application to meet
the target response time.
StatuScale (Wen et al., 2024) is a status-aware and
elastic scaling framework which is based on a load
status detector that can select appropriate elastic scal-
ing strategies for differentiated resource scheduling in
vertical scaling. Additionally, StatuScale employs a
horizontal scaling controller that utilizes comprehen-
sive evaluation and resource reduction to manage the
number of replicas for each microservice.
6 CONCLUSIONS
In this work, we propose extending the Kubernetes
platform with a custom Pod autoscaling strategy
aimed at minimizing SLO violations in the response
times of containerized applications running in cloud
environments, while simultaneously reducing infras-
tructure costs. Our primary goal is to address the lim-
itations of the Kubernetes Horizontal Pod Autoscaler,
which scales Pod replicas based on low-level resource
usage metrics. This approach makes it challenging to
define scaling targets that are properly correlated with
the desired response time SLOs and maximum infras-
tructure costs. The idea is to propose a Pod autoscal-
ing policy based on high-level metrics, such as actual
application response times and infrastructure costs, to
more accurately achieve the desired SLO and cost tar-
gets.
For future work, we plan to enhance the efficiency
of the proposed autoscaling policy by using AI and
time series analysis techniques to identify patterns in
user requests and predict their trends. This will enable
the development of a proactive autoscaling policy that
scales up the number of replicas to ensure improved
service performance, while minimizing infrastructure
over provisioning and reducing unnecessary costs.
ACKNOWLEDGEMENTS
This work was partially funded by the European
Union under the Italian National Recovery and Re-
silience Plan (NRRP) of NextGenerationEU, Mission
4 Component C2 Investment 1.1 - Call for tender No.
1409 of 14/09/2022 of Italian Ministry of University
and Research - Project ”Cloud Continuum aimed at
On-Demand Services in Smart Sustainable Environ-
ments” - CUP E53D23016420001.
REFERENCES
Balla, D., Simon, C., and Maliosz, M. (2020). Adap-
tive scaling of kubernetes pods. In NOMS 2020 -
2020 IEEE/IFIP Network Operations and Manage-
ment Symposium, pages 1–5.
Calcaterra, D., Di Modica, G., Mazzaglia, P., and Tomar-
chio, O. (2021). TORCH: a TOSCA-Based Orchestra-
tor of Multi-Cloud Containerised Applications. Jour-
nal of Grid Computing, 19(1).
Chen, T., Bahsoon, R., and Yao, X. (2018). A survey and
taxonomy of self-aware and self-adaptive cloud au-
toscaling systems. ACM Comput. Surv., 51(3).
Detti, A., Funari, L., and Petrucci, L. (2023). µbench: An
open-source factory of benchmark microservice ap-
plications. IEEE Transactions on Parallel and Dis-
tributed Systems, 34(3):968–980.
Do, T. V., Do, N. H., Rotter, C., Lakshman, T., Biro, C., and
B
´
erczes, T. (2025). Properties of horizontal pod au-
toscaling algorithms and application for scaling cloud-
CLOSER 2025 - 15th International Conference on Cloud Computing and Services Science
78

native network functions. IEEE Transactions on Net-
work and Service Management, pages 1–1.
Gannon, D., Barga, R., and Sundaresan, N. (2017). Cloud-
native applications. IEEE Cloud Computing, 4:16–21.
Gupta, H., Vahid Dastjerdi, A., Ghosh, S. K., and Buyya,
R. (2017). ifogsim: A toolkit for modeling and
simulation of resource management techniques in
the internet of things, edge and fog computing en-
vironments. Software: Practice and Experience,
47(9):1275–1296.
Hongyu, Y. and Anming, W. (2023). Migrating from mono-
lithic applications to cloud native applications. In
2023 8th International Conference on Computer and
Communication Systems (ICCCS), pages 775–779.
Kubernetes (2024). Production-Grade Container Orchestra-
tion. https://kubernetes.io. Last accessed 3 Jun 2024.
Marchese, A. and Tomarchio, O. (2024). Telemetry-driven
microservices orchestration in cloud-edge environ-
ments. In 2024 IEEE 17th International Conference
on Cloud Computing (CLOUD), pages 91–101, Shen-
zhen, China. IEEE Computer Society.
Marie-Magdelaine, N. and Ahmed, T. (2020). Proactive au-
toscaling for cloud-native applications using machine
learning. In GLOBECOM 2020 - 2020 IEEE Global
Communications Conference, pages 1–7.
Mukherjee, A., De, D., and Buyya, R. (2024). Cloud Com-
puting Resource Management, pages 17–37. Springer
Nature Singapore, Singapore.
Pramesti, A. A. and Kistijantoro, A. I. (2022). Autoscaling
based on response time prediction for microservice
application in kubernetes. In 2022 9th International
Conference on Advanced Informatics: Concepts, The-
ory and Applications (ICAICTA), pages 1–6.
Salii, S., Ajdari, J., and Zenuni, X. (2023). Migrating to
a microservice architecture: benefits and challenges.
In 2023 46th MIPRO ICT and Electronics Convention
(MIPRO), pages 1670–1677.
Santos, J., Reppas, E., Wauters, T., Volckaert, B., and De
Turck, F. (2025). Gwydion: Efficient auto-scaling
for complex containerized applications in kubernetes
through reinforcement learning. Journal of Network
and Computer Applications, 234:104067.
Tran, M.-N., Vu, D.-D., and Kim, Y. (2022). A survey of
autoscaling in kubernetes. In 2022 Thirteenth Interna-
tional Conference on Ubiquitous and Future Networks
(ICUFN), pages 263–265.
Wen, L., Xu, M., Gill, S. S., Hilman, M. H., Srirama, S. N.,
Ye, K., and Xu, C. (2024). Statuscale: Status-aware
and elastic scaling strategy for microservice applica-
tions.
Yuan, H. and Liao, S. (2024). A time series-based approach
to elastic kubernetes scaling. Electronics, 13(2).
SLO and Cost-Driven Container Autoscaling on Kubernetes Clusters
79
