
Integrating Automated and Humanistic Approaches: A
Methodological Case Study of Teachers' Digital Professional Growth
Corrado Matta
1a
, Susanna Nordmark
2b
, Kristina Holmberg
1c
, John Rack
1d
,
Mattias Davidsson
2e
and Italo Masiello
2f
1
Department of Education, Linnaeus University, Universitetsplatsen 1, Växjö, Sweden
2
Department of Computer Science and Media Technology, Linnaeus University, Universitetsplatsen 1, Växjö, Sweden
Keywords: Methodological Integration, Digital Learning Materials, Text Mining, Discourse Analysis, AI-Supported
Qualitative Analysis, Large Language Models.
Abstract: This paper presents a methodological case study on teachers' digital professional development, emphasizing
the integration of automated and humanistic approaches. Drawing from a four-year pilot project led by the
research group, we explore how three distinct analytical methodologies—manual discourse analysis, text
mining, and large language model-assisted thematic analysis—were employed to examine teachers' discursive
practices regarding digital learning materials. The study investigates how integrating these methodologies
enhances our understanding of digital learning material-related discourses and their evolution over time. Key
findings reveal two primary conceptualizations: digital learning materials as pedagogical/effectivization tools
and as complementary to analogue resources. The integrated approach demonstrated advantages in mitigating
methodological biases, improving reliability, and enabling a richer analysis of diverse data sources. This work
contributes to the development of robust analytical frameworks for studying the intersection of technology
and pedagogy in educational settings.
1 INTRODUCTION
In this paper, we describe and discuss a case study of
methodological integration applied to a study of
teachers' digital professional development. The paper
aims (a) to describe how three different analytical
approaches – large language model (LLM), text
mining, and traditional humanistic discourse analysis
– were integrated to study the discursive dimension
of teachers' digital professional development and (b)
to discuss the methodological advantages of this
integration.
The paper begins in Section 2 with a description
of the background project of which the described
experiment is a part. Section 3 describes the three
different methodologies used in our case and their
results. In section 4, we explain how the results from
a
https://orcid.org/0000-0003-2282-8071
b
https://orcid.org/0000-0001-7313-1720
c
https://orcid.org/0000-0002-2924-4100
d
https://orcid.org/0000-0001-7525-6180
e
https://orcid.org/0000-0002-9474-6879
f
https://orcid.org/0000-0002-3738-7945
the three approaches were integrated and discuss the
advantages of our integrative approach.
2 BACKGROUND
Guided by principles of Implementation Science, the
research group at Linnaeus University has led a four-
year pilot project to enhance teachers’ digital
competencies, foster data-driven learning, and utilize
Visual Learning Analytics (Masiello et al., 2023;
Nordmark et al., 2024). This collaboration included
researchers, municipalities, schools, and leading
providers of Digital Learning Materials (DLMs) in
Sweden.
The project has involved extensive data
collection, including interviews, observations,
458
Matta, C., Nordmark, S., Holmberg, K., Rack, J., Davidsson, M. and Masiello, I.
Integrating Automated and Humanistic Approaches: A Methodological Case Study of Teachers’ Digital Professional Growth.
DOI: 10.5220/0013488100003932
In Proceedings of the 17th International Conference on Computer Supported Education (CSEDU 2025) - Volume 2, pages 458-464
ISBN: 978-989-758-746-7; ISSN: 2184-5026
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

logbooks, and surveys. As the data analysis phase
started, the team agreed on a set of sub-studies, each
providing a part of the picture of teachers' digital
professional development.
The first sub-study the team decided to work on is
the object of this paper. This first sub-study
investigates the participating teachers' discursive
practices centered on DLMs and was motivated by
the following research questions:
RQ1: What ideas about the concept and role of
DLMs emerge from the perspectives of actors
involved in a school digital transformation
project? How do these ideas vary over time and
across different participants?
RQ2: What expectations regarding DLMs are
reflected in the data? How do these expectations
differ over time and among various participants?
2.1 Methodology of the Sub-Study
The sub-study focused only on the teacher and school
principal interview data. This data set consisted of
transcripts from 22 semi-structured interviews with
44 teachers and three school principals. The
interviews were organized into three rounds over
three years, one round each year.
All interviews were transcribed, segmented (one
segment for each turn-taking), and diarized. The data
set was annotated specifying, for each segment:
speaker, school, municipality, taught subjects, grade,
date of the interview, interview round, and the DLM
used.
After discussing which analytical approach to
use, the team determined to employ three different
approaches. Each approach and its results are
described in the next section.
3 ANALYSES AND RESULTS
This section contains a discussion of the three
analytical approaches used in three sub-studies of
Teachers' DLM discourses. The three different lines
of analysis are discussed in detail in the three separate
studies (Holmberg et al., 2025; Masiello et al., 2025;
Matta et al., 2025), while this article collects the
aggregate summary analysis. Each of the following
three subsections summarizes the methodology and
results of one of these three studies.
The summaries in this section are brief and only
describe the methodology and the most central results
of the separate studies. We discuss the validity of
each analytical approach in section 4.2 and refer the
reader to the individual studies for a discussion of the
reliability of the instruments.
3.1 First Approach: Manual Discourse
Analysis
This section presents the discourse analysis of the
interview data (Holmberg et al., 2025), guided by
Laclau and Mouffe's (1985) framework and Gee’s
procedural approach (Gee, 2001), which emphasize
agency and the creation of discursive patterns within
social practices. We call this approach humanistic to
emphasize the centrality of the researchers'
interpretive competence as the main analysis tool
(Pääkkönen & Ylikoski, 2021). Discourses are
conceived as semiotic dimensions of social practices
(in this case: the use of DLMs). Through participation
in the project, teachers and principals develop
linguistic repertoires that shape their representations
of what DLMs are, their functions, and their ideal
characteristics. These representations, termed
discursive formations, are inferred through
observable linguistic activities.
Two members of the research team worked on the
analysis of the data, which involved three steps. First,
the data were reduced by identifying all the segments
related to DLM concepts and functions. Secondly, the
reduced data were coded by grouping relevant
segments thematically to reflect participants'
conceptualizations, idealizations, and expectations of
DLMs. Finally, discursive formations were identified
by classifying themes into distinct discourses
representing conceptualizations, idealizations of,
and/or expectations about DLMs.
3.1.1 Results and Interpretation
The list of themes resulting from the coding process
and their classification into discursive formations is
found in the Appendix. The analysis resulted in three
representations of the concept and idealized image of
a DLM.
The first conceptualization conceives the DLM as
a Pedagogical Tool and focuses on DLMs as
instruments to enhance learning outcomes,
emphasizing DLMs as capable of improving teacher-
student interaction, generating multimodal
representation of subject contents, supporting and
scaffolding reasoning, and affecting learning goals.
Hence, DLMs have an active impact on students'
learning.
In contrast, the second conceptualization depicts
the DLM as an Effectivization Tool. According to this
Integrating Automated and Humanistic Approaches: A Methodological Case Study of Teachers’ Digital Professional Growth
459

idealization, DLMs are a means to streamline
educational processes, enabling task optimization,
monitoring, communication with students or parents,
and integration while maintaining teacher control.
This conceptualization differs from the first, as DLMs
have a more infrastructural and peripheral role in the
teacher's pedagogy. They do not impact learning
directly but support the teacher in all the activities that
are ultimately aimed at students' learning.
The final conceptualization focuses on DLM and
the Digital/Analog Divide. This final
conceptualization highlights tensions between digital
and analog materials, with "hybrid" uses of DLMs
conceptualized as a balance, especially towards the
end of the project.
The findings show that the teachers' discursive
practices changed over time. Participants gained
deeper insights into the strengths and limitations of
these tools, improving their ability to integrate them
effectively. Moreover, changes in the teachers'
conceptualizations might also be a result of a shift in
the broader social discourse concerning the
digitalization of the educational sector. This
interpretation concerns the third discursive formation,
which emerged towards the end of the project parallel
to an ongoing shift in the public discussion about the
use of digital tools in schools.
3.2 Second Approach: Text Mining
The second approach employed a text-mining
analysis of the interview data (Matta et al., 2025),
using statistical algorithms applied in Python (version
3.12.3) and R (version 2024.09.1+394).
A text corpus was built using the interview data
sets, where each segment constituted a document. The
annotated information was included in the corpus as
document variables. The resulting corpus consisted of
2262 documents, 8 variables, and 34730 tokens (i.e.,
the number of words in the whole corpus), with a
mean of 15.36 tokens per document and a standard
deviation of 17.64 tokens.
Four analytical tools were used to analyze the
corpus.
First, we performed sentiment analysis using the
KBLab Sentiment Analysis classifier, a transformer-
based neural network developed by KBLab at the
Swedish Royal Library (Hägglöf, 2023). Trained on
a dataset of 165,000 manually labeled Swedish texts.
The classifier categorizes sentiment into positive,
neutral, or negative with an estimated accuracy of
80%.
The second approach we employed was
Correspondence Analysis (FactoMineR, Factoextra).
This approach explores associations between
sentiment – i.e., values of the categorical variable
"sentiment" – and project rounds. Using dimension
reduction (Singular Value Decomposition), it mapped
the co-occurrence of categorical values in a two-
dimensional space (Husson et al., 2024; Kassambara
& Mundt, 2020).
The third analysis we applied was Keyness
Analysis (Quanteda Textstats). Here, we identified
words and phrases significantly differing across
rounds. Terms from the final round were compared
with earlier ones using Chi-squared statistics (Benoit
et al., 2024).
Finally, we used Topic Modeling (SeededLDA),
and, more specifically, Applied Latent Dirichlet
Allocation (LDA) to uncover thematic clusters in the
data, identifying topics as word groups with shared
themes (Watanabe & Xuan-Hieu, 2024).
3.2.1 Results and Interpretation
Correspondence Analysis: Sentiment evolved from
neutral in the early stages to negative mid-project and
positive near the end. This reflected initial technical
concerns, giving way to constructive views as
participants adapted to DLMs.
Keyness Analysis: Early discussions focused on
technical issues (“computer,” “platform”), while later
rounds emphasized pedagogical aspects
(“understand,” “exercise”) and the complementary
role of DLMs alongside traditional materials
(“complement,” “book”). Participants increasingly
framed DLMs as supplementary resources rather than
replacements.
Topic Modeling: Identified five relevant topics,
forming two main thematic clusters: (1) DLMs as
pedagogical/effectivization tools and (2) DLMs in
relation to analog materials.
Keyness analysis and topic modeling revealed two
primary representations of DLMs: DLMs as
pedagogical/effectivization tools and as
complementary to analog teaching materials. The first
representation emphasizes the use of DLMs either as
tools that impact learning directly or as tools that
simplify teachers' work. The choice of merging these
two conceptions into a single representation and not
as two different ideas as in the case of manual
discourse analysis was mainly based on topic
modeling, which indicated that the pedagogical and
effectivization features often occurred together.
The second representation, more clearly emerging
as an independent thematic cluster, emphasized the
CSEDU 2025 - 17th International Conference on Computer Supported Education
460

tension between digital and analog pedagogical tools,
where DLMs were discussed only in relation to this
tension. We introduced here the concept of boundary
object (Fleischmann, 2006; Fox, 2011) to describe the
DLMs. According to this theory, the way of using
language to conceptualize and idealize DLMs
emphasizes the ongoing debate in the educational
sector concerning the primacy of digital or analog
pedagogical approaches and sees the DLM as an
object that constitutes and maintains this tension.
Correspondence analysis indicated that sentiment
shifted towards positive over time, which is
consistent with the interpretation of the data in the
manual discourse analysis, indicating that teachers
developed a deeper understanding of educational
technologies.
3.3 Third Approach: LLMs
The third analytical approach was to employ LLMs to
support the thematic analysis of the interview data
(Masiello et al., 2025).
The analysis was conducted using the ChatGPT-
4o, guided by Braun and Clarke's (2013) thematic
analysis framework. This third analysis focused on
teachers' and school principals' systems of
expectations about DLMs. The analysis started with
an initial coding, where relevant data segments were
identified based on recurring topics and phrases, and
a custom stop-word list was applied during
preprocessing. To assess thematic relevance,
recurring terms (e.g., we have, has been, not really)
were extracted. The second step involved developing
themes from the initial codes. Codes were grouped
into themes such as Teacher Confidence, DLM
Integration, Student Engagement, Challenges, and
Outcomes. Themes were refined iteratively for
accuracy. The analysis concluded by focusing on
temporal comparisons. Themes were analyzed across
different stages (e.g., early vs. late project phases) to
identify shifts in perspectives.
3.3.1 Results and Interpretation
The analysis highlighted key themes, categories, and
codes:
Expectations and Idealized Views
Interactive and Dynamic Learning:
Anticipated enhanced student engagement
through features like multimedia,
interactivity, and gamified learning (fun,
interactive, video, and games).
Personalized Learning: Belief in digital
tools’ ability to tailor lessons to individual
needs (adjust content, tailor lessons,
review).
Teaching Efficiency: Expected to simplify
workloads with automated grading and
resource organization (automate tasks, save
time).
Challenges with Content and Implementation
Content Quality and Alignment: Digital
materials often lacked depth or curriculum
alignment (not aligned, fit to lesson).
Technical and Logistical Barriers: Teachers
faced platform difficulties, glitches, and
steep learning curves (troubleshooting, not
simple).
Student Engagement and Digital Literacy:
Not all students adapted well to digital tools,
with varying competence levels (not
comfortable, not engaging).
Temporal Evolution of Perspectives
Early Phase (2021): Optimism about digital
tools’ potential for innovation, engagement,
and personalization (transform teaching,
make it easier).
Later Phase (2024): A pragmatic focus on
high-quality content and effective
integration, with less emphasis on
transformative change (takes time, need to
adapt).
This analysis revealed how expectations of DLMs
evolved over time, providing valuable insights into
their adoption and integration into educational
practices.
4 METHODOLOGICAL
DISCUSSION
This section describes the approach used to integrate
and compare the three different lines of analysis and
discusses the advantages and limitations of this
approach.
4.1 Integrative Procedure
After having decided to approach our research
questions from three different analytical perspectives,
the team agreed on using an iterative and explorative
Integrating Automated and Humanistic Approaches: A Methodological Case Study of Teachers’ Digital Professional Growth
461

procedure as a methodological approach for
comparing and integrating the different insights.
The first stage of the procedure, after having
determined the research questions, was to form three
teams (each working with one of the analytical
approaches), and each team would generate
preliminary insights on their own. Next, a first
comparison meeting was arranged in which each team
presented their preliminary insights. Then, it was
decided to interpret each insight not as a result that
could be interpreted as an answer – albeit tentative –
to our research questions, but rather as a new point of
departure, an avenue for further analysis. This
entailed ascribing limited credibility to the
preliminary results and going forward with the three
separate lines of analysis. Finally, a final meeting was
arranged to compare the outcomes of the different
analyses.
The results described in Section 3 represent the
outcomes of this iterative and exploratory approach.
The comparison of these outcomes revealed that the
three lines of analysis converged on two discursive
formations: the pedagogical/effectivization tool
discourse and the analog/digital discourse. The next
section discusses what level of credibility can be
ascribed to the claim that these discourses indeed
represent the structure of language use among the
participants.
4.2 Advantages of Our Approach
The issue of the credibility of an interpretive theory,
such as that which was generated by our
iterative/explorative approach, is, in essence, a matter
of distinguishing a plausible interpretation from an
interpretive artifact. An interpretation is credible if it
is likely to represent the actual social phenomena it
targets. According to an inferentialist/pragmatist
perspective (Suárez, 2004), which we assume,
representation allows agents to make inferences about
its target phenomenon. This means that an
interpretation is credible if it can be used to make
fruitful explanations and projections about the target.
In contrast, an interpretive artifact is simply a result
of forcing a narrative onto the data, which typically
results in unreliable inferences.
7
Assessing the credibility of an interpretation is
best done by assessing the risks of interpretive
7
For instance, someone could interpret a chair as a jacket.
This interpretation will allow the interpreter to infer that
wearing it will warm her/him. The interpretation is made
less credible by the fact that it generates unreliable
inferences.
artifacts and discussing the methodological ways to
manage these risks. Three types of methodological
risks affect our case, one for each of the lines of
analysis.
Manual analysis relies on the interpretive
schemes of the researcher and is, therefore, easily
affected by individual biases. Humanistic
interpretation rests on selecting what interpretations
seem to best fit the data (Matta, 2022). Individual
selection criteria can be biased towards explanatory
schemes that are familiar or otherwise preferred,
which introduces implicit weights or bias in the
selection. As the process advances in the ladder of
interpretation (coding → thematization →
interpretation in terms of discursive formations), the
risk of a researcher projecting such preconceptions on
the data increases.
Text mining is based on statistical algorithms,
which involve a risk of generating statistical artifacts.
Researchers might be tempted to interpret statistical
patterns as meaningful insofar as they are statistical
patterns, but this increases the risk that some of the
observed patterns in the data are simply statistical
artifacts – that is patterns detected by the algorithm
that depend systematic errors in the analysis or the
data collection – and not existing relationships in the
target phenomenon. For instance, the LDA algorithm
used in our study can sometimes generate spurious
topics by clustering terms that are lexically identical
but used in different ways in different contexts.
Finally, using LLMs in research can be affected
by different types of biases. Several sources (Ashwin
et al., 2023; Schroeder et al., 2024) have discussed
how using LLM for qualitative analysis might
increase such risk. One source of bias can be the
natural language data that is used to train the LLMs,
which can be representative of other social groups
than that which is analyzed. This will increase the
probability that the chosen LLM produces
interpretations that fit the context of the training data.
Another source of bias can originate from the
concepts and theories used to train the LLMs. It is
important to highlight that LLMs do not generate
analyses but report a statistical synthesis of the
formulations used in training texts that the algorithm
categorizes as analyses. Hence, whenever a LLM
proposes a thematization, it is not proposing a model
of the data but rather trying to summarize the textual
CSEDU 2025 - 17th International Conference on Computer Supported Education
462

behavior of interpretations included in the LLMs'
training data. As a result, LLMs will more likely
"interpret" the interview data according to more
recurring interpretive frameworks, which introduces
a conservative bias in the interpretation (bolder
interpretations are systematically excluded).
Our approach has several rewards, some of which
provide strategies that manage – although do not
eliminate – all of these risks. First, it exploits the
advantages of automatized and humanistic
approaches by combining the depth of humanistic
interpretation with the breadth of automatized
procedures. Manual interpretations are more
sophisticated but cannot manage large datasets,
whereas automatized methods allow for the analysis
of large datasets but are typically superficial. Our
approach establishes a balance between these two
dimensions.
Secondly, its explorative and iterative character
contributes to the outcome's reliability. Ascribing a
lower level of credibility to the preliminary insights
decreases the risk of falling for compelling narratives.
Moreover, it harnesses the value of
methodological pluralism as an analytical tool by
working with three separate lines of analysis and
comparing iteratively the insights of all the
approaches; there is no single method of analysis that
acquires a leading position. This avoids the typical
bias toward quantitative analyses, which affects many
mixed-methods studies. This bias is the result of a
methodological assumption, according to which
qualitative methods are appropriate for hypothesis
generation and quantitative methods are best for
theory testing. We challenge this view by focusing on
how the target phenomenon was modeled using the
different approaches and reflecting on the
assumptions that these models inherit from each
approach.
Our approach provides a management strategy for
the bias risks mentioned above. The iterative and
comparative approach decreases the risk for both
individual, statistical, and LLM-based biases by
letting each line of analysis work as a watchdog for
all others. If the LLM generates an analysis that is
biased toward a social group, the humanistic analysis
is likely to pick up that bias in virtue of its sensitivity
for context. In the same way, if the humanistic
interpretation is biased by the researcher's interpretive
scheme, there is a chance that both the LLM and the
text mining analyses will fail to confirm that insight,
as the latter are less prone to cherry-picking.
Furthermore, if the text mining analysis is based on a
statistical artifact, the humanistic interpretation will
plausibly find that pattern far-fetched by identifying
spurious topics. Finally, the inclusion of a humanistic
component in the analysis allows for bolder
interpretation, decreasing the risk of interpretive
conservatism.
It is important to highlight that our integrative
approach provides strategies that manage epistemic
risks but cannot eliminate these risks. We cannot
exclude the possibility that the individual researchers
who apply the humanistic interpretive approach will
not suffer the same kind of biases that could affect the
LLMs and text mining approaches. A human
researcher can suffer from a conservative bias or miss
a spurious topic by failing to catch that the same word
is used in different ways throughout a data set.
However, by pluralizing the analysis of qualitative
data, the risk of such biases is arguably lower than
when working with any of the three approaches in our
substudy.
5 CONCLUSIONS
The integration of manual, automated, and LLM-
assisted methodologies in this study has highlighted
the value of methodological pluralism in educational
research. By combining humanistic insights with
automated and AI-supported approaches, we were
able to uncover teachers' perspectives on the evolving
roles of DLMs in school. This iterative and
exploratory approach not only mitigated biases
inherent in individual methodologies but also helped
in generating a comprehensive understanding of
DLM discourses.
The findings emphasize the potential of DLMs as
tools for both pedagogical enhancement and
operational efficiency while also revealing ongoing
tensions between digital and analog educational
resources. Our study underscores the importance of
an interdisciplinary lens in addressing complex
educational challenges, offering a methodological
approach for integrating diverse analytical
perspectives. Future research could expand this
framework to other educational contexts, further
validating its applicability and effectiveness.
ACKNOWLEDGMENTS
An initial sketch of the abstract and conclusion of this
paper was generated using an AI tool (ChatGPT-4o).
The sketch was substantially revised, and the present
versions of the abstract and conclusion retained less
than 40% of these initial sketches.
Integrating Automated and Humanistic Approaches: A Methodological Case Study of Teachers’ Digital Professional Growth
463
REFERENCES
Ashwin, J., Chhabra, A., & Rao, V. (2023). Using Large
Language Models for Qualitative Analysis can
Introduce Serious Bias (arXiv:2309.17147). arXiv.
https://doi.org/10.48550/arXiv.2309.17147
Benoit, K., Watanabe, K., Wang, H., Lua, J. W., Kuha, J.,
& Council (ERC-2011-StG 283794-QUANTESS), E.
R. (2024). quanteda.textstats: Textual Statistics for the
Quantitative Analysis of Textual Data (Version 0.97.2)
[Computer software]. https://cran.r-
project.org/web/packages/quanteda.textstats/index.htm
l
Braun, V., & Clarke, V. (2013). Successful qualitative
research: A practical guide for beginners (1. ed.).
SAGE Publications.
Fleischmann, K. R. (2006). Boundary Objects with
Agency: A Method for Studying the Design–Use
Interface. The Information Society, 22(2), 77–87.
https://doi.org/10.1080/01972240600567188
Fox, N. J. (2011). Boundary Objects, Social Meanings and
the Success of New Technologies. Sociology, 45(1),
70–85. https://doi.org/10.1177/0038038510387196
Gee, J. P. (2001). An introduction to discourse analysis
[Elektronisk resurs] theory and method. Routledge.
Hägglöf, H. (2023). The KBLab Blog: A robust, multi-label
sentiment classifier for Swedish. https://kb-
labb.github.io/posts/2023-06-16-a-robust-multi-label-
sentiment-classifier-for-swedish/
Holmberg, K., Matta, C., Nordmark, S., Masiello, I., Rack,
J., & Davidsson, M. (2025). From Balance to Informed
Criticism – Discursive Transformations in a
Development Project on Digital Learning Material in
Primary School. Proceedings of INTED Conference.
Husson, F., Josse, J., Le, S., & Mazet, J. (2024).
FactoMineR: Multivariate Exploratory Data Analysis
and Data Mining (Version 2.11) [Computer software].
https://cran.r-
project.org/web/packages/FactoMineR/index.html
Kassambara, A., & Mundt, F. (2020). factoextra: Extract
and Visualize the Results of Multivariate Data Analyses
(Version 1.0.7) [Computer software]. https://cran.r-
project.org/web/packages/factoextra/index.html
Laclau, E., & Mouffe, C. (1985). Hegemony & socialist
strategy. Verso.
Masiello, I., Fixsen, D. L., Nordmark, S., Mohseni, Z.
(Artemis), Holmberg, K., Rack, J., Davidsson, M.,
Andersson-Gidlund, T., & Augustsson, H. (2023).
Digital transformation in schools of two southern
regions of Sweden through implementation-informed
approach: A mixed-methods study protocol. PLOS
ONE, 18(12), e0296000.
https://doi.org/10.1371/journal.pone.0296000
Masiello, I., Matta, C., Holmberg, K., Nordmark, S., Rack,
J., & Mohseni, Z. (2025). An AI Chat-Bot Thematic
Analysis of Teachers’ Expectations of Digital Learning
Materials in Primary Schools. Proceedings of INTED
Conference.
Matta, C. (2022). Tolkningens metodologi och selektiv
abduktion. Pedagogisk forskning i Sverige,
27(4), 37–
61. https://doi.org/10.15626/pfs27.04.03
Matta, C., Nordmark, S., Holmberg, K., Davidsson, M.,
Rack, J., & Masiello, I. (2025). The Discursive
Mechanisms of Teachers’ Digital Professional
Development: A Quantitative Approach. Proceedings
of INTED Conference.
Nordmark, S., Augustsson, H., Davidsson, M., Andersson-
Gidlund, T., Holmberg, K., Mohseni, Z. (Artemis),
Rack, J., & Masiello, I. (2024). Piloting Systematic
Implementation of Educational Technology in Swedish
K-12 Schools – Two-Years-In Report. Global
Implementation Research and Applications, 4(3), 309–
323. https://doi.org/10.1007/s43477-024-00130-w
Pääkkönen, J., & Ylikoski, P. (2021). Humanistic
interpretation and machine learning. Synthese, 199(1),
1461–1497. https://doi.org/10.1007/s11229-020-
02806-w
Schroeder, H., Quéré, M. A. L., Randazzo, C., Mimno, D.,
& Schoenebeck, S. (2024). Large Language Models in
Qualitative Research: Can We Do the Data Justice?
(arXiv:2410.07362). arXiv.
https://doi.org/10.48550/arXiv.2410.07362
Suárez, M. (2004). An Inferential Conception of Scientific
Representation. Philosophy of Science, 71(5), 767–779.
https://doi.org/10.1086/421415
Watanabe, K., & Xuan-Hieu, P. (2024). seededlda: Seeded
Sequential LDA for Topic Modeling (Version 1.4.1)
[Computer software]. https://cran.r-
project.org/web/packages/seededlda/index.html
APPENDIX
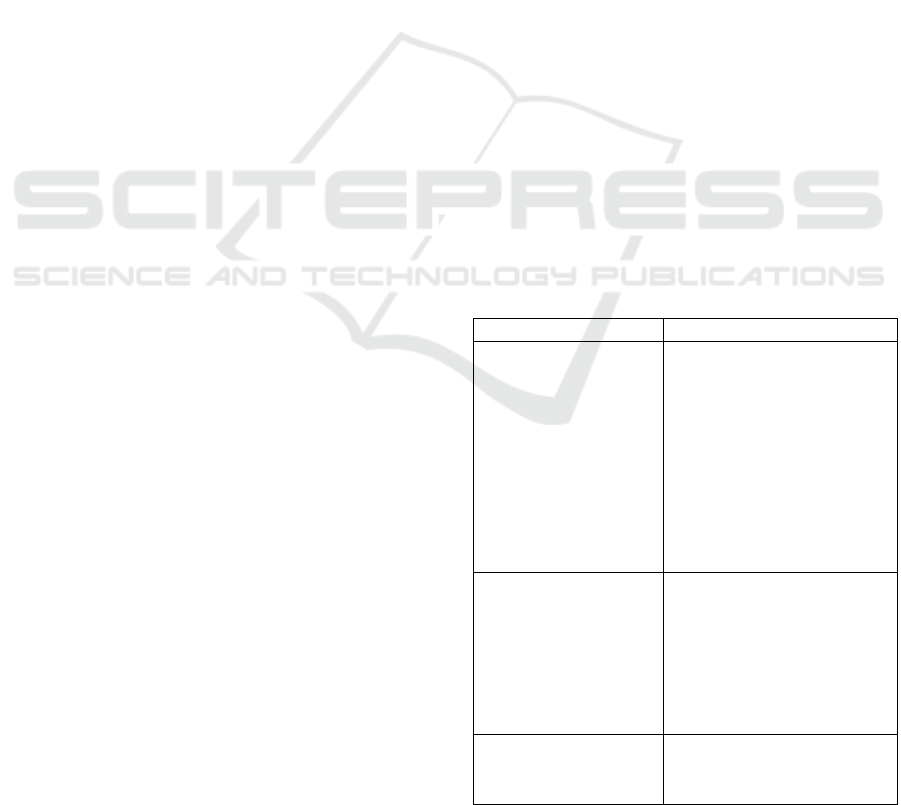
Discourse Themes
DLM as a
Pedagogical Tool
Teacher-adapted,
Language functions,
Multimodality, Learning
analytics,
Fun/Lively/Interesting,
Students' Digital
Competence, Reasoning,
Flexibility, Explanations,
Goal Fulfillment,
Repetition, La
y
out.
DLM as an
Effectivization Tool
Efficiency, Assessment,
Specific Applications,
Integration, Monitoring,
Family, Language
functions, Repetition,
Teacher-adapted,
Updated.
DLM and the
Digital/Analog
Divide
The divide between
digital and analog
materials, h
y
brid solutions
CSEDU 2025 - 17th International Conference on Computer Supported Education
464
